 جولة كاملة للتعلم الآلي في بايثون: الجزء الثاني
جولة كاملة للتعلم الآلي في بايثون: الجزء الثانييمكن أن يكون تجميع كل أجزاء مشروع التعلم الآلي معًا أمرًا صعبًا. في هذه السلسلة من المقالات ، سنتناول جميع مراحل تنفيذ عملية تعلُّم الآلة باستخدام بيانات حقيقية ، ونكتشف كيف يتم الجمع بين التقنيات المختلفة مع بعضها البعض.
في
المقالة الأولى ، قمنا بتنظيف البيانات وتنظيمها ، وإجراء تحليل استكشافي ، وجمع مجموعة من السمات لاستخدامها في النموذج ، وتعيين خط أساس لتقييم النتائج. بمساعدة هذه المقالة ، سنتعلم كيفية التنفيذ في Python ومقارنة العديد من نماذج تعلُّم الآلة ، وإجراء الضبط الفوقي لتحسين أفضل نموذج ، وتقييم أداء النموذج النهائي في مجموعة بيانات اختبار.
كل كود المشروع موجود
على جيثب ،
وهنا هو دفتر الملاحظات الثاني المتعلق بالمقال الحالي. يمكنك استخدام وتعديل الكود كما يحلو لك!
تقييم واختيار النموذج
مذكرة: نحن نعمل على مهمة انحدار خاضعة للرقابة ، باستخدام
معلومات الطاقة من المباني في نيويورك لإنشاء نموذج يتنبأ
بنتيجة Energy Star التي سيحصل عليها مبنى معين. نحن مهتمون بكل من دقة التنبؤ وإمكانية تفسير النموذج.
اليوم يمكنك الاختيار من بين
العديد من نماذج التعلم الآلي المتاحة ، وهذه الوفرة يمكن أن تكون مخيفة. بالطبع ، هناك
مراجعات مقارنة على الشبكة ستساعدك في التنقل عند اختيار خوارزمية ، لكنني أفضل تجربة القليل منها في العمل ومعرفة أيهما أفضل. بالنسبة للجزء الأكبر ، يعتمد التعلم الآلي على النتائج
التجريبية بدلاً من النتائج النظرية ، ويكاد
يكون من المستحيل فهم أي نموذج أكثر دقة مقدمًا .
يُنصح عادةً بالبدء بنماذج بسيطة قابلة للتفسير ، مثل الانحدار الخطي ، وإذا كانت النتائج غير مرضية ، فانتقل إلى طرق أكثر تعقيدًا ، ولكن عادةً ما تكون أكثر دقة. يوضح هذا الرسم البياني (المناهض للعلم جدًا) العلاقة بين دقة بعض الخوارزميات وتفسيرها:
 التفسير والدقة ( المصدر ).
التفسير والدقة ( المصدر ).سنقوم بتقييم خمسة نماذج بدرجات متفاوتة من التعقيد:
- الانحدار الخطي.
- طريقة اقرب الجيران.
- "غابة عشوائية".
- تعزيز التدرج.
- طريقة دعم ناقلات.
لن ننظر في الجهاز النظري لهذه النماذج ، ولكن تنفيذها. إذا كنت مهتمًا بالنظرية ، فاطلع على
مقدمة في التعلم الإحصائي (متاحة مجانًا) أو
التعلم الآلي عن طريق استخدام برنامج Scikit-Learn و TensorFlow . في كلا الكتابين ، تم شرح النظرية بشكل مثالي ، وتظهر فعالية استخدام الطرق المذكورة في لغتي R و Python ، على التوالي.
املأ القيم المفقودة
على الرغم من قيامنا بمسح البيانات ، إلا أننا تجاهلنا الأعمدة التي يفتقد فيها أكثر من نصف القيم ، إلا أنه لا يزال لدينا الكثير من القيم. لا يمكن أن تعمل نماذج تعلُم الآلة مع البيانات الناقصة ، لذا نحتاج إلى
ملؤها .
أولاً ، نعتبر البيانات ونتذكر كيف تبدو:
import pandas as pd import numpy as np
كل قيمة
NaN هي سجل مفقود في البيانات.
يمكنك ملؤها بطرق مختلفة ، وسوف نستخدم طريقة حساب متوسط بسيطة إلى حد ما ، والتي تستبدل البيانات المفقودة بمتوسط القيم للأعمدة المقابلة.
في الكود أدناه ، سنقوم بإنشاء
Imputer Scikit
-Learn Imputer باستراتيجية متوسطة. ثم نقوم بتدريبها على بيانات التدريب (باستخدام
imputer.fit ) ، وتطبيقها لملء القيم المفقودة في مجموعات التدريب والاختبار (باستخدام
imputer.transform ). أي أن السجلات المفقودة في
بيانات الاختبار سيتم ملؤها بالقيمة المتوسطة المقابلة من
بيانات التدريب .
نقوم بالتعبئة ولا ندرب النموذج على البيانات كما هي ، من أجل تجنب مشكلة
تسرب بيانات الاختبار عندما تذهب المعلومات من مجموعة بيانات الاختبار إلى التدريب.
الآن تمتلئ جميع القيم ، لا توجد فجوات.
تحجيم الميزة
التحجيم هو العملية العامة لتغيير نطاق خاصية.
هذه خطوة ضرورية ، لأن العلامات تقاس بوحدات مختلفة ، مما يعني أنها تغطي نطاقات مختلفة. وهذا يشوه إلى حد كبير نتائج مثل هذه الخوارزميات مثل طريقة
ناقل الدعم وطريقة الجوار k الأقرب ، والتي تأخذ في الاعتبار المسافات بين القياسات. والتدرج يسمح لك بتجنب ذلك. على الرغم من أن أساليب مثل
الانحدار الخطي و "الغابة العشوائية" لا تتطلب تحجيم الميزات ، فمن الأفضل عدم تجاهل هذه الخطوة عند مقارنة العديد من الخوارزميات.
سنقوم بالقياس باستخدام كل سمة إلى نطاق من 0 إلى 1. نأخذ جميع قيم السمة ونختار الحد الأدنى ونقسمه على الفرق بين الحد الأقصى والحد الأدنى (النطاق). غالبًا ما تسمى طريقة القياس هذه
بالتطبيع ، والطريقة الرئيسية الأخرى هي التوحيد .
هذه العملية سهلة التنفيذ يدويًا ، لذلك
MinMaxScaler كائن
MinMaxScaler من
MinMaxScaler -Learn. يتطابق رمز هذه الطريقة مع التعليمات البرمجية لملء القيم المفقودة ، ويتم استخدام القياس فقط بدلاً من اللصق. تذكر أننا تعلمنا النموذج فقط في مجموعة التدريب ، ثم قمنا بتحويل جميع البيانات.
الآن ، تحتوي كل سمة على الحد الأدنى للقيمة 0 ، والحد الأقصى 1. ملء القيم المفقودة وتوسيع نطاق السمات - هناك حاجة إلى هاتين المرحلتين في أي عملية تعلم آلي تقريبًا.
ننفذ نماذج التعلم الآلي في Scikit-Learn
بعد كل الأعمال التحضيرية ، فإن عملية إنشاء النماذج وتشغيلها بسيطة نسبيًا. سنستخدم مكتبة
Scikit-Learn في Python ، والتي تم توثيقها بشكل جميل ومع بناء جملة مفصل لبناء النماذج. من خلال تعلم كيفية إنشاء نموذج في Scikit-Learn ، يمكنك تنفيذ جميع أنواع الخوارزميات بسرعة.
.fit عملية الإنشاء والتدريب (
.fit ) والاختبار (
.predict ) باستخدام تعزيز التدرج:
from sklearn.ensemble import GradientBoostingRegressor
سطر واحد فقط من التعليمات البرمجية لإنشاء والتدريب والاختبار. لبناء نماذج أخرى ، نستخدم نفس البنية ، مع تغيير اسم الخوارزمية فقط.

من أجل التقييم الموضوعي للنماذج ، قمنا بحساب المستوى الأساسي باستخدام القيمة المتوسطة للهدف وحصلنا على 24.5. وكانت النتائج أفضل بكثير ، لذا يمكن حل مشكلتنا باستخدام التعلم الآلي.
في حالتنا ، تبين أن
تعزيز التدرج (MAE = 10.013) أفضل قليلاً من "الغابة العشوائية" (10.014 MAE). على الرغم من أن هذه النتائج لا يمكن اعتبارها صادقة تمامًا ، لأنه بالنسبة للمعلمات الفائقة نستخدم القيم الافتراضية في الغالب. تعتمد فعالية النماذج بشدة على هذه الإعدادات ،
خاصة في طريقة ناقل الدعم . ومع ذلك ، استنادًا إلى هذه النتائج ، سنختار تعزيز التدرج ونبدأ في تحسينه.
تحسين نموذج القياس الفوقي
بعد اختيار نموذج ، يمكنك تحسينه للمهمة التي سيتم حلها عن طريق ضبط المعلمات المفرطة.
ولكن قبل كل شيء ، دعنا نفهم
ما هي المعايير الفائقة وكيف تختلف عن المعلمات العادية ؟
- يمكن اعتبار المعلمات الفائقة للموديل إعدادات الخوارزمية ، التي نضعها قبل بدء التدريب. على سبيل المثال ، يمثل hyperparameter عدد الأشجار في "الغابة العشوائية" ، أو عدد الجيران في طريقة k- الجوار الأقرب.
- معلمات النموذج - ما تتعلمه أثناء التدريب ، على سبيل المثال ، الأوزان في الانحدار الخطي.
من خلال التحكم في المعلمة المفرطة ، نؤثر على نتائج النموذج ، ونغير التوازن بين
نقص التعليم وإعادة التدريب . تحت التعلم هو موقف حيث النموذج ليس معقدًا بما فيه الكفاية (لديه درجات قليلة جدًا من الحرية) لدراسة مطابقة الإشارات والأهداف. النموذج غير المدرّب لديه انحياز
كبير ، يمكن تصحيحه من خلال تعقيد النموذج.
إعادة التدريب هي حالة يتذكر فيها النموذج بشكل أساسي بيانات التدريب. يحتوي النموذج المعاد تدريبه على تباين
كبير ، والذي يمكن تعديله عن طريق الحد من تعقيد النموذج من خلال التنظيم. لن تتمكن كل من النماذج التي لم يتم تدريبها جيدًا وإعادة تدريبها من تعميم بيانات الاختبار جيدًا.
تتمثل الصعوبة في اختيار المعلمات الفائقة المناسبة في أنه سيكون هناك مجموعة مثالية فريدة لكل مهمة. لذلك ، فإن الطريقة الوحيدة لاختيار أفضل الإعدادات هي تجربة مجموعات مختلفة في مجموعة البيانات الجديدة. لحسن الحظ ، يحتوي Scikit-Learn على عدد من الطرق التي تسمح لك بتقييم المعلمات المفرطة بشكل فعال. علاوة على ذلك ، تحاول مشاريع مثل
TPOT تحسين البحث عن
المعلمات الفائقة باستخدام مناهج مثل
البرمجة الجينية . في هذه المقالة ، نقتصر على استخدام Scikit-Learn.
تحقق من البحث العشوائي
دعنا ننفذ طريقة ضبط معلمة مفرطة تسمى عمليات البحث العشوائي للتحقق المتبادل:
- البحث العشوائي - تقنية لاختيار المعاملات الفائقة. نحدد شبكة ، ثم نختار عشوائيًا مجموعات مختلفة منها ، على النقيض من بحث الشبكة ، حيث نجرب كل تركيبة على التوالي. بالمناسبة ، يعمل البحث العشوائي تقريبًا مثل بحث الشبكة ، ولكن بشكل أسرع.
- التدقيق المشترك هو طريقة لتقييم المجموعة المختارة من المعلمات المفرطة. بدلاً من تقسيم البيانات إلى مجموعات تدريب واختبار ، مما يقلل من كمية البيانات المتاحة للتدريب ، سنستخدم التحقق المتقاطع من k-block (التحقق المتقاطع من K-Fold). للقيام بذلك ، سنقوم بتقسيم بيانات التدريب إلى كتل k ، ثم تشغيل العملية التكرارية ، حيث نقوم أولاً بتدريب النموذج على كتل k-1 ، ثم مقارنة النتيجة عند التعلم على الكتلة k. سنكرر العملية k مرة ، وفي النهاية سنحصل على متوسط قيمة الخطأ لكل تكرار. سيكون هذا التقييم النهائي.
فيما يلي توضيح بياني للتحقق المتقاطع من k-block عند k = 5:

تبدو عملية البحث العشوائي عن التحقق المتبادل بالكامل كما يلي:
- قمنا بتعيين شبكة من المعلمات المفرطة.
- اختيار مجموعة من المعلمات المفرطة بشكل عشوائي.
- قم بإنشاء نموذج باستخدام هذا المزيج.
- نقوم بتقييم نتيجة النموذج باستخدام التحقق المتقاطع من كتلة k.
- نقرر أي معلمات مفرطة تعطي أفضل نتيجة.
بالطبع ، كل هذا لا يتم يدويًا ، ولكن باستخدام
RandomizedSearchCV من Scikit-Learn!
سنستخدم نموذج الانحدار القائم على تعزيز التدرج. هذه طريقة جماعية ، أي أن النموذج يتكون من العديد من "المتعلمين الضعفاء" ، في هذه الحالة ، من أشجار قرارات منفصلة. إذا تعلم الطلاب في
خوارزميات متوازية
مثل "الغابة العشوائية" ، ثم تم تحديد نتيجة التنبؤ عن طريق التصويت ،
فعند تعزيز الخوارزميات مثل تعزيز التدرج ، يتعلم الطلاب بالتسلسل ، و "يركز" كل منهم على الأخطاء التي ارتكبها أسلافهم.
في السنوات الأخيرة ، أصبح تعزيز الخوارزميات شائعًا وغالبًا ما يفوز في مسابقات التعلم الآلي.
تعزيز التدرج هو أحد التطبيقات التي تستخدم فيها Gradient Descent لتقليل تكلفة الوظيفة. يعتبر تطبيق تعزيز التدرج في Scikit-Learn غير فعال كما هو الحال في المكتبات الأخرى ، على سبيل المثال ، في
XGBoost ، ولكنه يعمل بشكل جيد على مجموعات البيانات الصغيرة ويعطي تنبؤات دقيقة إلى حد ما.
العودة إلى إعداد hyperparametric
في الانحدار باستخدام تعزيز التدرج ، هناك العديد من المعاملات الفائقة التي تحتاج إلى تكوين ، للحصول على التفاصيل ، أحيلك إلى وثائق Scikit-Learn. سنقوم بتحسين:
loss : التقليل من وظيفة الخسارة ؛n_estimators : عدد أشجار القرار الضعيفة المستخدمة (أشجار القرار) ؛max_depth : أقصى عمق لكل شجرة قرارات ؛min_samples_leaf : الحد الأدنى لعدد الأمثلة التي يجب أن تكون في العقدة min_samples_leaf لشجرة القرار ؛min_samples_split : الحد الأدنى من الأمثلة اللازمة لتقسيم عقدة شجرة القرار ؛max_features : الحد الأقصى لعدد الميزات المستخدمة لفصل العقد.
لست متأكدًا مما إذا كان أي شخص يفهم حقًا كيف يعمل كل شيء ، والطريقة الوحيدة للعثور على أفضل تركيبة هي تجربة خيارات مختلفة.
في هذا الكود ، نقوم بإنشاء شبكة من المعاملات الفائقة ، ثم نقوم بإنشاء كائن
RandomizedSearchCV والبحث باستخدام التحقق المتقاطع من 4 كتل لـ 25 مجموعة مختلفة من المعاملات الفائقة:
يمكنك استخدام هذه النتائج للبحث عن شبكة بتحديد معلمات الشبكة القريبة من هذه القيم المثلى. ولكن من غير المرجح أن يؤدي الضبط الإضافي إلى تحسين النموذج بشكل كبير. هناك قاعدة عامة: سيكون للإنشاءات المختصة للميزات تأثير أكبر بكثير على دقة النموذج من إعداد المعلمات المفرطة الأكثر تكلفة. هذا هو
قانون تقليل الربحية فيما يتعلق بالتعلم الآلي : يعطي تصميم السمات أعلى عائد ، ويجلب الضبط الفائق للمعاملات فوائد متواضعة فقط.
لتغيير عدد المُقدرين (أشجار القرار) مع الحفاظ على قيم المعلمات المفرطة الأخرى ، يمكن إجراء تجربة واحدة ستوضح دور هذا الإعداد. يتم تنفيذ التنفيذ
هنا ، ولكن هنا هي النتيجة:
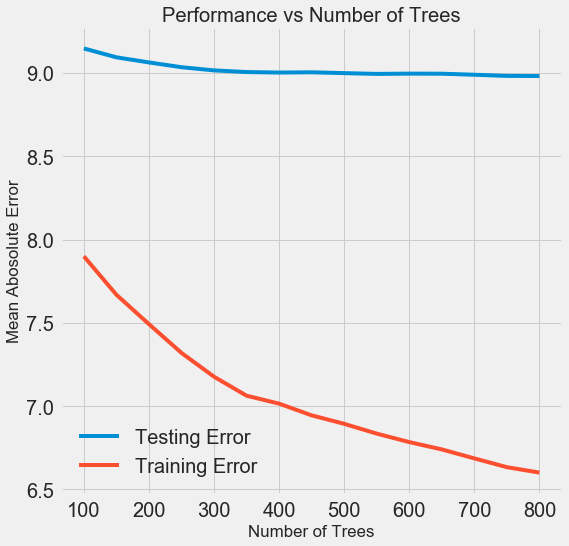
كلما زاد عدد الأشجار التي يستخدمها النموذج ، انخفض مستوى الأخطاء أثناء التدريب والاختبار. لكن أخطاء التعلم تنخفض بشكل أسرع بكثير ، ونتيجة لذلك ، يتم إعادة تدريب النموذج: فهو يظهر نتائج ممتازة على بيانات التدريب ، ولكنه يعمل بشكل أسوأ على بيانات الاختبار.
في بيانات الاختبار ، تقل الدقة دائمًا (لأن النموذج يرى الإجابات الصحيحة لمجموعة بيانات التدريب) ، ولكن الانخفاض الكبير
يشير إلى إعادة التدريب . يمكن حل هذه المشكلة عن طريق زيادة كمية بيانات التدريب أو
تقليل تعقيد النموذج باستخدام المعلمات الفائقة . هنا لن نتطرق إلى المعلمات المفرطة ، ولكن أوصي بأن تنتبه دائمًا إلى مشكلة إعادة التدريب.
بالنسبة لنموذجنا النهائي ، سنأخذ 800 مقيم ، لأن هذا سيعطينا أدنى مستوى من الخطأ في التحقق المتقاطع. اختبار النموذج الآن!
التقييم باستخدام بيانات الاختبار
كأشخاص مسؤولين ، تأكدنا من أن نموذجنا لم يتمكن بأي حال من الأحوال من الوصول إلى بيانات الاختبار أثناء التدريب. لذلك ،
يمكننا استخدام الدقة عند العمل مع بيانات الاختبار كمؤشر لجودة النموذج عندما يتم قبوله في مهام حقيقية.
نحن نطعم بيانات اختبار النموذج ونحسب الخطأ. في ما يلي مقارنة بين نتائج خوارزمية تعزيز التدرج الافتراضية ونموذجنا المخصص:
ساعد ضبط فرط المعلمات على تحسين دقة النموذج بحوالي 10٪. اعتمادًا على الموقف ، يمكن أن يكون هذا تحسنًا كبيرًا للغاية ، ولكنه يستغرق الكثير من الوقت.
يمكنك مقارنة وقت التدريب لكلا الطرازين باستخدام الأمر magic
%timeit في Jupyter Notebooks. أولاً ، قم بقياس المدة الافتراضية للنموذج:
%%timeit -n 1 -r 5 default_model.fit(X, y) 1.09 s ± 153 ms per loop (mean ± std. dev. of 5 runs, 1 loop each)
ثانية واحدة للدراسة لائقة للغاية. لكن النموذج المضبوط ليس بهذه السرعة:
%%timeit -n 1 -r 5 final_model.fit(X, y) 12.1 s ± 1.33 s per loop (mean ± std. dev. of 5 runs, 1 loop each)
يوضح هذا الموقف الجانب الأساسي للتعلم الآلي:
كل شيء يتعلق بالتنازلات . من الضروري باستمرار اختيار التوازن بين الدقة والقدرة على التفسير ، وبين
الإزاحة والتشتت ، وبين الدقة ووقت التشغيل ، وما إلى ذلك. يتم تحديد التركيبة الصحيحة تمامًا من خلال المهمة المحددة. في حالتنا ، تكون الزيادة 12 مرة في مدة العمل من الناحية النسبية كبيرة ، ولكنها من حيث القيمة المطلقة غير ذات أهمية.
لقد حصلنا على نتائج التنبؤ النهائية ، والآن دعنا نحللها ومعرفة ما إذا كان هناك أي انحرافات ملحوظة. على اليسار رسم بياني لكثافة القيم المتوقعة والحقيقية ، على اليمين هو رسم بياني للخطأ:
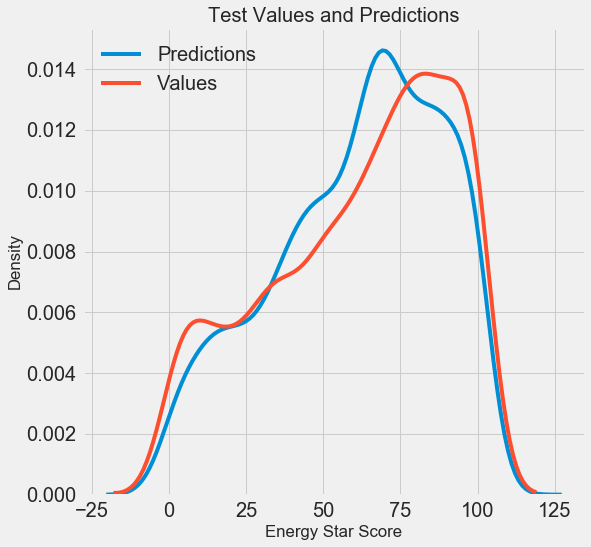

تكرار توقعات النموذج جيدًا توزيع القيم الحقيقية ، بينما في بيانات التدريب ، تقع ذروة الكثافة أقرب إلى القيمة المتوسطة (66) من ذروة الكثافة الحقيقية (حوالي 100). تحتوي الأخطاء على توزيع عادي تقريبًا ، على الرغم من وجود العديد من القيم السلبية الكبيرة عندما تختلف توقعات النموذج تمامًا عن البيانات الحقيقية. في المقالة التالية ، سوف نفحص بمزيد من التفصيل تفسير النتائج.
الخلاصة
في هذه المقالة ، درسنا عدة مراحل من حل مشكلة التعلم الآلي:
- ملء القيم المفقودة وميزات التحجيم.
- تقييم ومقارنة نتائج عدة نماذج.
- ضبط فرط المعلمات باستخدام البحث العشوائي في الشبكة والتحقق المتبادل.
- تقييم أفضل نموذج باستخدام بيانات الاختبار.
تشير النتائج إلى أنه يمكننا استخدام التعلم الآلي للتنبؤ بنجم إنرجي ستار بناءً على الإحصائيات المتاحة. بمساعدة تعزيز التدرج ، تم تحقيق خطأ 9.1 في بيانات الاختبار. يمكن لضبط فرط المعلمات أن يحسن النتائج بشكل كبير ، ولكن على حساب تباطؤ كبير. هذه واحدة من العديد من المقايضات التي يجب مراعاتها في التعلم الآلي.
في المقالة التالية ، سنحاول معرفة كيفية عمل نموذجنا. سنلقي نظرة أيضًا على العوامل الرئيسية التي تؤثر على نتيجة إنرجي ستار. إذا علمنا أن النموذج دقيق ، فسوف نحاول أن نفهم لماذا يتنبأ بهذه الطريقة وما يخبرنا به هذا عن المشكلة نفسها.