
كل منا يدرك النصوص بطريقته الخاصة ، سواء كانت أخبار على الإنترنت أو شعر أو روايات كلاسيكية. وينطبق الشيء نفسه على الخوارزميات وأساليب التعلم الآلي ، والتي ، كقاعدة ، تدرك النصوص في شكل رياضي ، في شكل فضاء متجه متعدد الأبعاد.
المقالة مخصصة للتصور باستخدام تمثيل Word2Vec المحسوب متعدد الأبعاد للكلمات t-SNE. سيساعد التصور على فهم مبدأ Word2Vec بشكل أفضل وكيفية تفسير العلاقة بين نواقل الكلمات قبل الاستخدام الإضافي في الشبكات العصبية وخوارزميات التعلم الآلي الأخرى. تركز المقالة على التصور ، لا تعتبر مزيد من البحث وتحليل البيانات. كمصدر بيانات ، نستخدم مقالات من أخبار Google والأعمال الكلاسيكية التي كتبها L.N. تولستوي. سنكتب الرمز في Python في دفتر ملاحظات Jupyter.
تضمين الجوار العشوائي الموزع على شكل حرف T
T-SNE هي خوارزمية التعلم الآلي لتصور البيانات على أساس طريقة تقليل الأبعاد غير الخطي ، والتي تم وصفها بالتفصيل في المقالة الأصلية [1] وفي
حبري . المبدأ الأساسي لعملية t-SNE هو تقليل المسافات الزوجية بين النقاط مع الحفاظ على موقعها النسبي. بمعنى آخر ، تقوم الخوارزمية بتعيين بيانات متعددة الأبعاد إلى مساحة ذات بعد أقل ، مع الحفاظ على بنية حي النقاط.
تمثيلات متجهية للكلمات و Word2Vec
بادئ ذي بدء ، نحن بحاجة إلى تقديم الكلمات في شكل متجه. لهذه المهمة ، اخترت أداة دلالات توزيع Word2Vec ، والتي تم تصميمها لعرض المعنى الدلالي للكلمات في مساحة المتجه. يجد Word2Vec العلاقات بين الكلمات من خلال افتراض أن الكلمات ذات الصلة دلالة تم العثور عليها في سياقات مماثلة. يمكنك قراءة المزيد عن Word2Vec في المقالة الأصلية [2] ، وكذلك
هنا وهنا .
كمدخلات ، نأخذ مقالات من أخبار Google وروايات L.N. تولستوي. في الحالة الأولى ، سنستخدم المتجهات التي تم تدريبها مسبقًا على مجموعة بيانات أخبار Google (حوالي 100 مليار كلمة) التي نشرتها Google
في صفحة المشروع .
import gensim model = gensim.models.KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)
بالإضافة إلى المتجهات المدربة مسبقًا باستخدام مكتبة Gensim [3] ، سنقوم بتدريب نموذج آخر في نصوص L.N. تولستوي. نظرًا لأن Word2Vec يقبل مجموعة من الجمل كمدخلات ، فإننا نستخدم نموذج Punkt Sentence Tokenizer المدرب مسبقًا من حزمة NLTK لتقسيم النص تلقائيًا إلى جمل. يمكن تنزيل نموذج اللغة الروسية
من هنا .
import re import codecs def preprocess_text(text): text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() def prepare_for_w2v(filename_from, filename_to, lang): raw_text = codecs.open(filename_from, "r", encoding='windows-1251').read() with open(filename_to, 'w', encoding='utf-8') as f: for sentence in nltk.sent_tokenize(raw_text, lang): print(preprocess_text(sentence.lower()), file=f)
بعد ذلك ، باستخدام مكتبة Gensim ، سنقوم بتدريب نموذج Word2Vec بالمعلمات التالية:
- الحجم = 200 - بُعد مسافة السمة ؛
- window = 5 - عدد الكلمات من السياق التي تحللها الخوارزمية ؛
- min_count = 5 - يجب أن تحدث الكلمة خمس مرات على الأقل حتى يأخذها النموذج في الاعتبار.
import multiprocessing from gensim.models import Word2Vec def train_word2vec(filename): data = gensim.models.word2vec.LineSentence(filename) return Word2Vec(data, size=200, window=5, min_count=5, workers=multiprocessing.cpu_count())
تصور تمثيل متجه الكلمات باستخدام t-SNE
T-SNE مفيد للغاية لتصور أوجه التشابه بين الأجسام في مساحة متعددة الأبعاد. مع زيادة كمية البيانات ، يصبح من الصعب أكثر فأكثر إنشاء رسم بياني مرئي ، لذلك يتم دمج الكلمات ذات الصلة في الممارسة العملية في مجموعات لمزيد من التصور. خذ على سبيل المثال بضع كلمات من قاموس نموذج Word2Vec الذي تم تدريبه مسبقًا على أخبار Google.
keys = ['Paris', 'Python', 'Sunday', 'Tolstoy', 'Twitter', 'bachelor', 'delivery', 'election', 'expensive', 'experience', 'financial', 'food', 'iOS', 'peace', 'release', 'war'] embedding_clusters = [] word_clusters = [] for word in keys: embeddings = [] words = [] for similar_word, _ in model.most_similar(word, topn=30): words.append(similar_word) embeddings.append(model[similar_word]) embedding_clusters.append(embeddings) word_clusters.append(words)
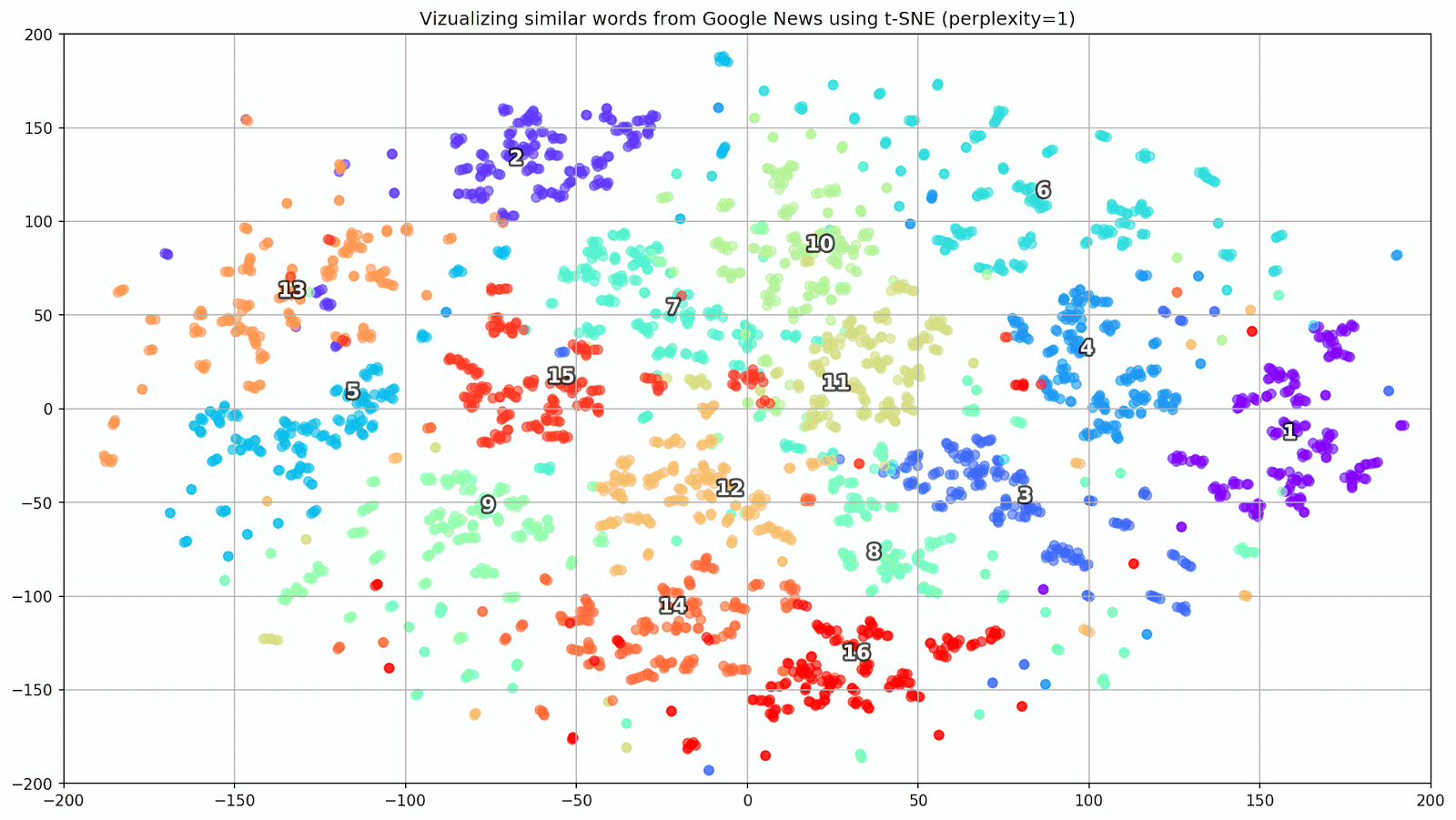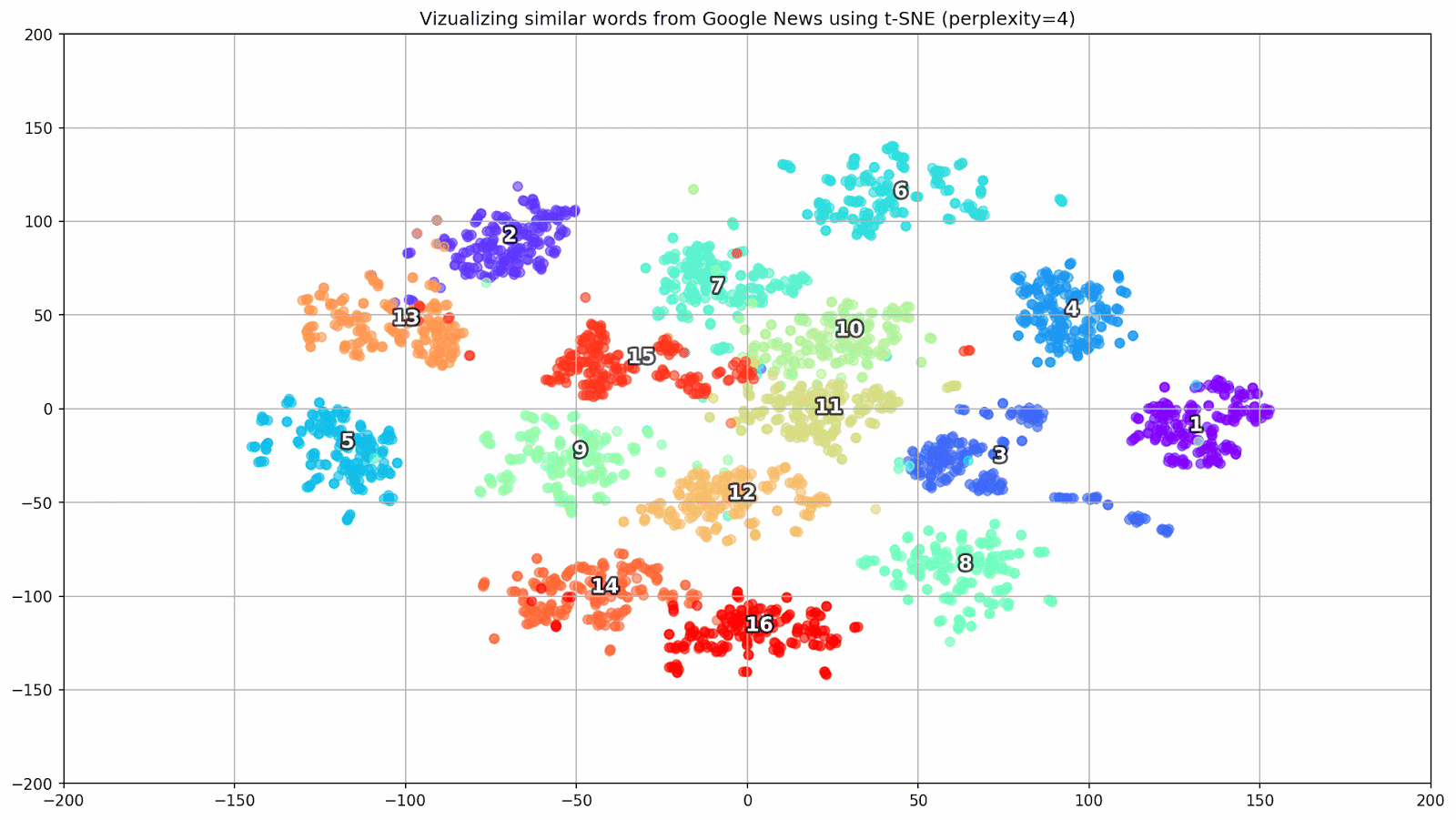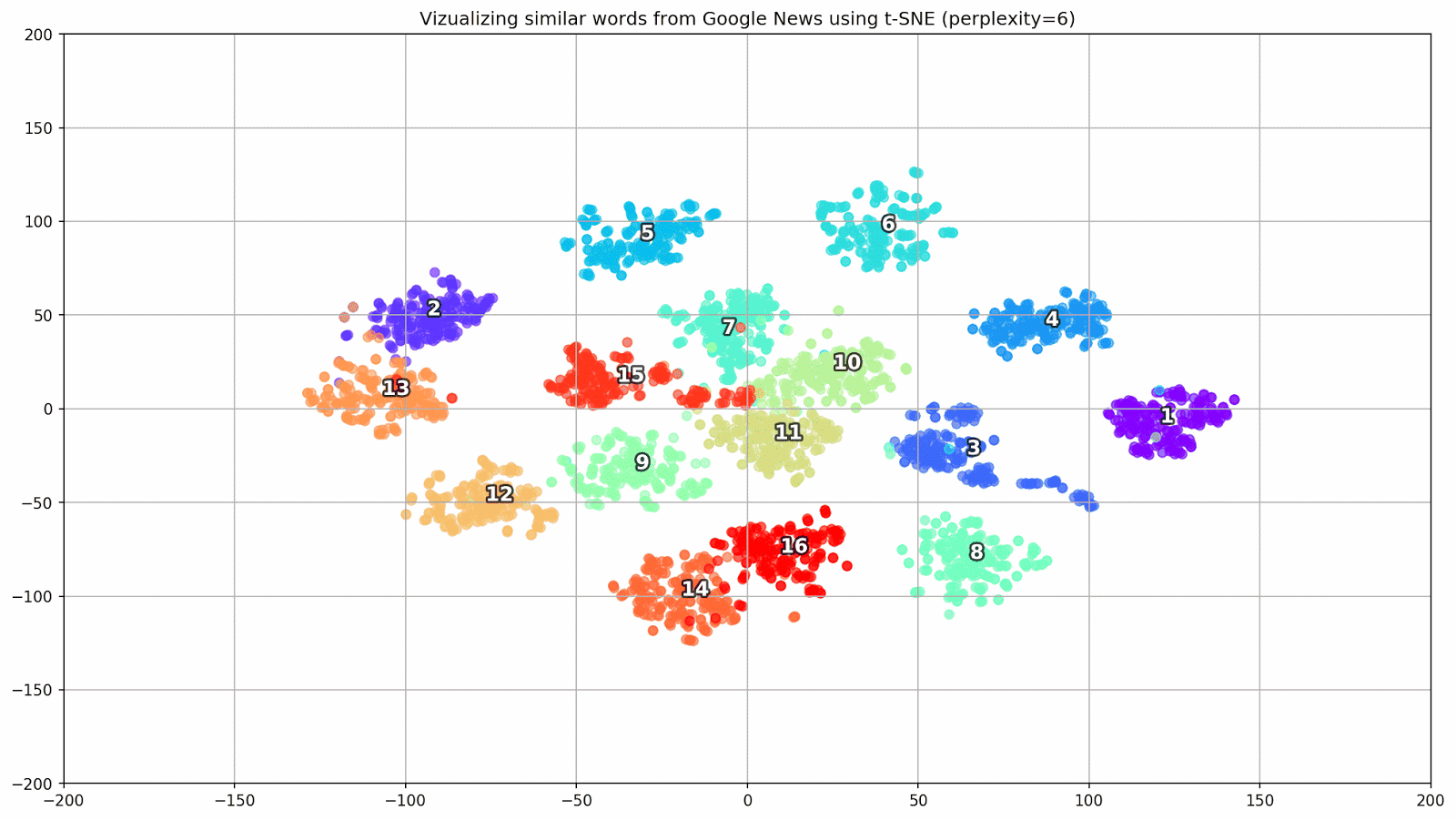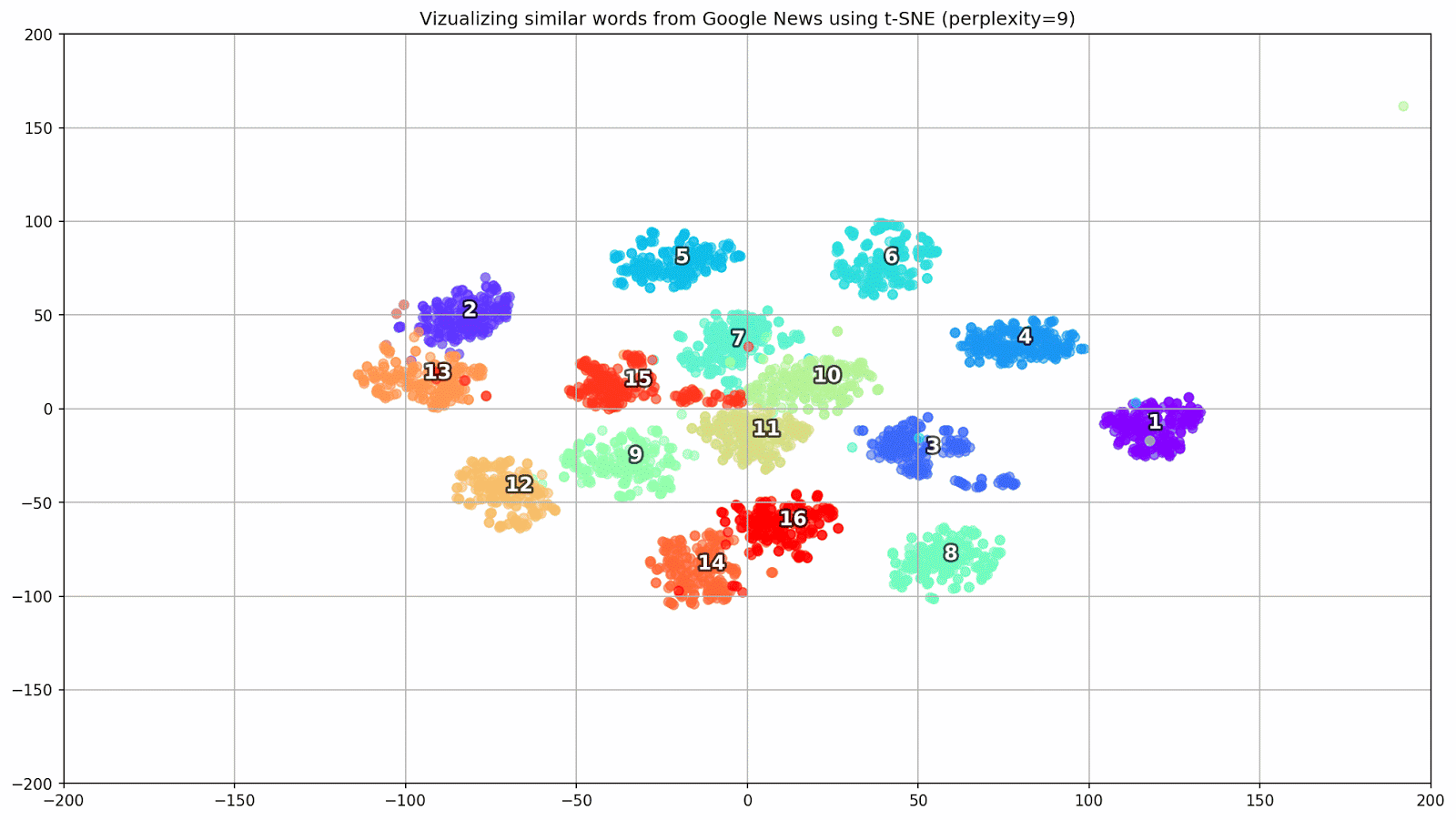 الشكل 1. مجموعات من الكلمات المتشابهة من أخبار Google ذات قيم ما قبل البداية المختلفة.
الشكل 1. مجموعات من الكلمات المتشابهة من أخبار Google ذات قيم ما قبل البداية المختلفة.بعد ذلك ، ننتقل إلى الجزء الأكثر روعة من المقالة ، تكوين t-SNE. هنا ، أولاً وقبل كل شيء ، يجب الانتباه إلى المعايير الفائقة التالية:
- n_components - عدد المكونات ، أي بُعد مسافة القيمة ؛
- الحيرة - الحيرة ، التي يمكن أن تعادل قيمتها في t-SNE العدد الفعال للجيران. يتعلق الأمر بعدد أقرب الجيران ، والذي يستخدم في نماذج أخرى تتعلم على أساس الأصناف (انظر الصورة أعلاه). ينصح بقيمته [1] في حدود 5-50 ؛
- الحرف الأول - نوع التهيئة الأولية للمتجهات.
tsne_model_en_2d = TSNE(perplexity=15, n_components=2, init='pca', n_iter=3500, random_state=32) embedding_clusters = np.array(embedding_clusters) n, m, k = embedding_clusters.shape embeddings_en_2d = np.array(tsne_model_en_2d.fit_transform(embedding_clusters.reshape(n * m, k))).reshape(n, m, 2)
فيما يلي نص برمجي لبناء رسم بياني ثنائي الأبعاد باستخدام Matplotlib ، وهي واحدة من المكتبات الأكثر شيوعًا لتصور البيانات في Python.
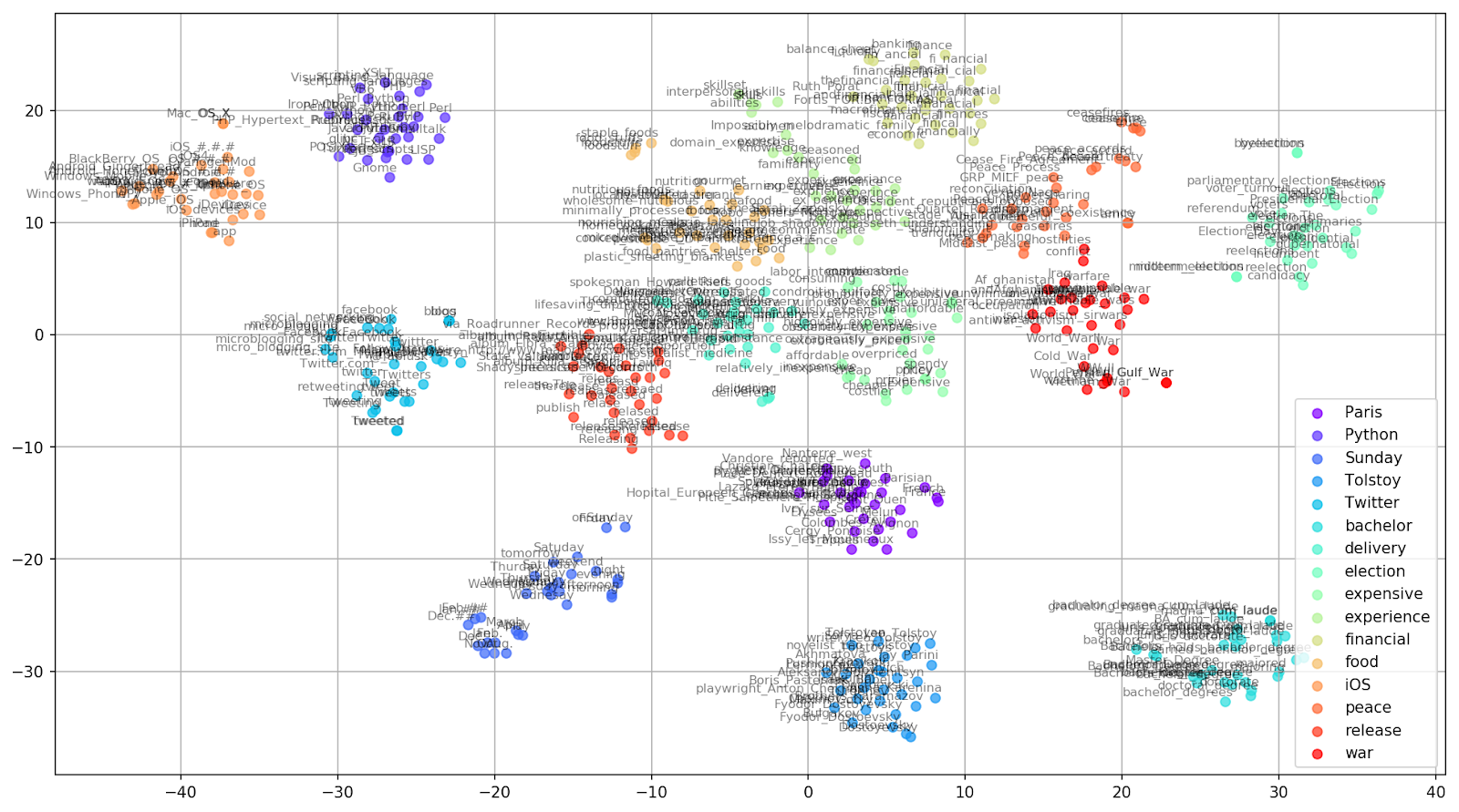 الشكل 2. مجموعات من الكلمات المتشابهة من أخبار Google (preplexity = 15).
الشكل 2. مجموعات من الكلمات المتشابهة من أخبار Google (preplexity = 15). from sklearn.manifold import TSNE import matplotlib.pyplot as plt import matplotlib.cm as cm import numpy as np % matplotlib inline def tsne_plot_similar_words(labels, embedding_clusters, word_clusters, a=0.7): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, len(labels))) for label, embeddings, words, color in zip(labels, embedding_clusters, word_clusters, colors): x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=color, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.5, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=8) plt.legend(loc=4) plt.grid(True) plt.savefig("f/.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_similar_words(keys, embeddings_en_2d, word_clusters)
في بعض الأحيان يكون من الضروري إنشاء مجموعات منفصلة من الكلمات ، وليس القاموس بأكمله. لهذا الغرض ، دعونا نحلل آنا كارنينا ، القصة العظيمة للعاطفة والخيانة والمأساة والتكفير.
prepare_for_w2v('data/Anna Karenina by Leo Tolstoy (ru).txt', 'train_anna_karenina_ru.txt', 'russian') model_ak = train_word2vec('train_anna_karenina_ru.txt') words = [] embeddings = [] for word in list(model_ak.wv.vocab): embeddings.append(model_ak.wv[word]) words.append(word) tsne_ak_2d = TSNE(n_components=2, init='pca', n_iter=3500, random_state=32) embeddings_ak_2d = tsne_ak_2d.fit_transform(embeddings)
def tsne_plot_2d(label, embeddings, words=[], a=1): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, 1)) x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=colors, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.3, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=10) plt.legend(loc=4) plt.grid(True) plt.savefig("hhh.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_2d('Anna Karenina by Leo Tolstoy', embeddings_ak_2d, a=0.1)
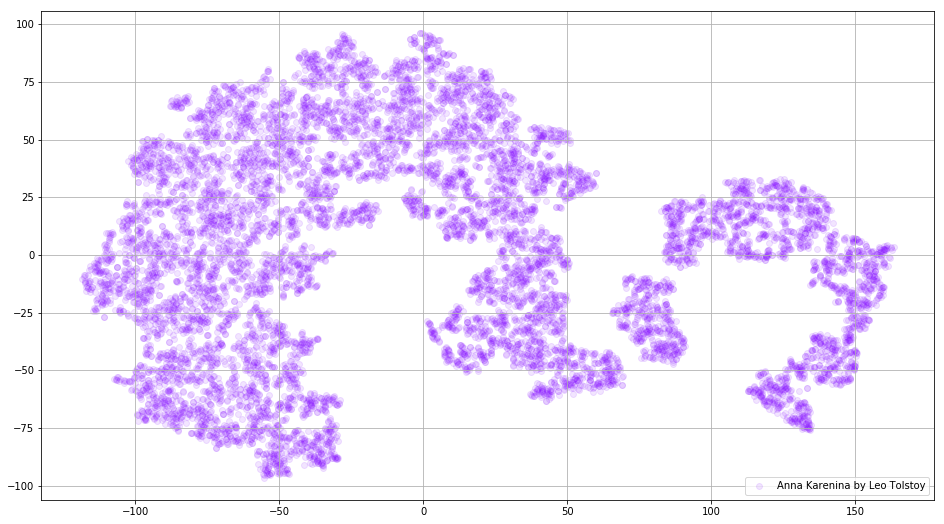
 الشكل 3. تصور قاموس نموذج Word2Vec ، مدربة على رواية "آنا كارنينا".
الشكل 3. تصور قاموس نموذج Word2Vec ، مدربة على رواية "آنا كارنينا".يمكن أن تصبح الصورة أكثر إفادة إذا استخدمنا مساحة ثلاثية الأبعاد. ألق نظرة على الحرب والسلام ، إحدى الروايات الرئيسية للأدب العالمي.
prepare_for_w2v('data/War and Peace by Leo Tolstoy (ru).txt', 'train_war_and_peace_ru.txt', 'russian') model_wp = train_word2vec('train_war_and_peace_ru.txt') words_wp = [] embeddings_wp = [] for word in list(model_wp.wv.vocab): embeddings_wp.append(model_wp.wv[word]) words_wp.append(word) tsne_wp_3d = TSNE(perplexity=30, n_components=3, init='pca', n_iter=3500, random_state=12) embeddings_wp_3d = tsne_wp_3d.fit_transform(embeddings_wp)
from mpl_toolkits.mplot3d import Axes3D def tsne_plot_3d(title, label, embeddings, a=1): fig = plt.figure() ax = Axes3D(fig) colors = cm.rainbow(np.linspace(0, 1, 1)) plt.scatter(embeddings[:, 0], embeddings[:, 1], embeddings[:, 2], c=colors, alpha=a, label=label) plt.legend(loc=4) plt.title(title) plt.show() tsne_plot_3d('Visualizing Embeddings using t-SNE', 'War and Peace', embeddings_wp_3d, a=0.1)
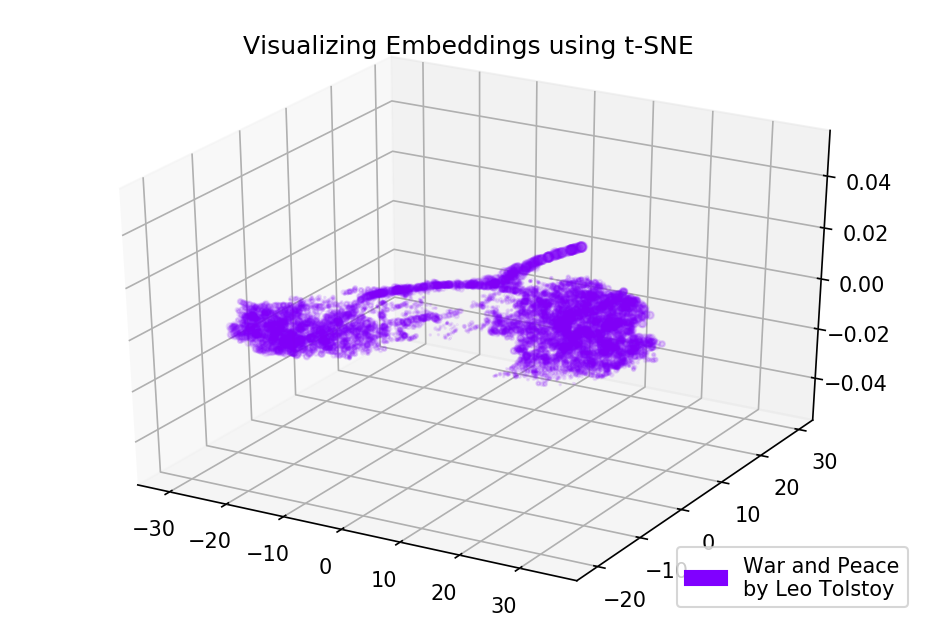 الشكل 4: تصور قاموس نموذج Word2Vec ، المدربين على رواية "الحرب والسلام".
الشكل 4: تصور قاموس نموذج Word2Vec ، المدربين على رواية "الحرب والسلام".كود المصدر
الكود متاح على
جيثب . هناك يمكنك العثور على رمز عرض الرسوم المتحركة.
مصادر
- Maaten L.، Hinton G. تصور البيانات باستخدام t-SNE // Journal of the learning learning research. - 2008. - T. 9. - S. 2579-2605.
- التمثيلات الموزعة للكلمات والعبارات وتكوينها // التقدم في نظم معالجة المعلومات العصبية . - 2013. - س 3111-3119.
- Rehurek R. ، Sojka P. إطار برنامج لنمذجة الموضوعات مع الشركات الكبيرة // في وقائع ورشة عمل LREC 2010 حول التحديات الجديدة لأطر البرمجة اللغوية العصبية. - 2010.