من بين الشبكات الاجتماعية ، يعد Twitter أكثر ملاءمة من غيرها لاستخراج البيانات النصية بسبب القيود الصارمة على طول الرسالة التي يضطر المستخدمون لوضعها في غاية الأهمية.
أقترح تخمين ما هي التكنولوجيا هذه الإطارات سحابة الإطارات؟
باستخدام واجهة برمجة تطبيقات Twitter ، يمكنك استخراج وتحليل مجموعة متنوعة من المعلومات. مقال حول كيفية القيام بذلك مع لغة البرمجة ر.
لا تستغرق كتابة الشفرة الكثير من الوقت ، وقد تنشأ صعوبات بسبب التغييرات وتشديد واجهة برمجة تطبيقات Twitter ، على ما يبدو أن الشركة كانت قلقة للغاية بشأن القضايا الأمنية بعد سحبها في الكونجرس الأمريكي بعد التحقيق في تأثير "الهاكرز الروس" على الانتخابات الأمريكية في عام 2016.
واجهة برمجة تطبيقات الوصول
لماذا يحتاج شخص ما لاسترداد البيانات الصناعية من تويتر؟ حسنًا ، على سبيل المثال ، يساعد في عمل تنبؤات أكثر دقة فيما يتعلق بنتائج الأحداث الرياضية. لكني متأكد من وجود سيناريوهات مستخدم أخرى.
للبدء ، من الواضح أنك بحاجة إلى حساب Twitter برقم هاتف. هذا ضروري لإنشاء التطبيق ، هذه هي الخطوة التي تمنح حق الوصول إلى واجهة برمجة التطبيقات.
نذهب إلى صفحة المطور وننقر على زر إنشاء تطبيق . التالي هو الصفحة التي تحتاج فيها لملء معلومات حول التطبيق. تتكون الصفحة حاليًا من الحقول التالية.
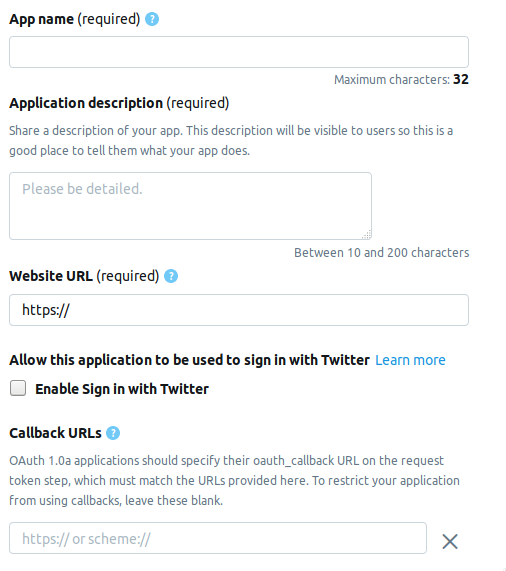
- AppName - اسم التطبيق (مطلوب).
- وصف التطبيق - وصف التطبيق (مطلوب).
- عنوان URL لموقع الويب - صفحة موقع الويب الخاص بالتطبيق (مطلوب) ، يمكنك إدخال أي شيء يشبه عنوان URL.
- تمكين تسجيل الدخول باستخدام Twitter (مربع الاختيار) - يمكن حذف تسجيل الدخول من صفحة التطبيق على Twitter.
- عناوين URL للاستدعاء - إعادة الاتصال بالتطبيق أثناء المصادقة (مطلوب) وضروري ، يمكنك ترك
http://127.0.0.1:1410 .
فيما يلي الحقول الاختيارية: عنوان الصفحة لشروط الخدمة ، اسم المؤسسة ، إلخ.
عند إنشاء حساب مطور ، اختر أحد الخيارات الثلاثة الممكنة.
- قياسي - الإصدار الأساسي ، يمكنك البحث عن سجلات بعمق ≤ 7 أيام مجانًا.
- Premium - خيار أكثر تقدمًا ، يمكنك البحث عن السجلات على عمق ≤ 30 يومًا ومنذ عام 2006. مجانًا ، ولكنها لا تقدم حقًا عند التفكير في تقديم طلب.
- المؤسسة - درجة رجال الأعمال ، والتعريفات المدفوعة والموثوقة.
لقد اخترت Premium ، استغرق الأمر حوالي أسبوع لانتظار الموافقة. لا أستطيع أن أقول للجميع ما إذا كانوا يعطونني لي على التوالي ، ولكن الأمر يستحق المحاولة على أي حال ، ولن يذهب ستاندرد إلى أي مكان.
اتصال تويتر
بعد إنشاء التطبيق ، ستظهر مجموعة تحتوي على العناصر التالية في علامة التبويب المفاتيح والرموز المميزة . فيما يلي أسماء ومتغيرات R.
مفاتيح واجهة برمجة تطبيقات المستهلك
- مفتاح API -
api_key - مفتاح سر API -
api_secret
رمز الوصول و رمز الوصول السري السري
- رمز الوصول -
access_token - سر رمز الوصول -
access_token_secret
قم بتثبيت الحزم اللازمة.
install.packages("rtweet") install.packages("tm") install.packages("wordcloud")
سيبدو هذا الجزء من التعليمات البرمجية على هذا النحو.
library("rtweet") api_key <- "" api_secret <- "" access_token <- "" access_token_secret <- "" appname="" setup_twitter_oauth ( api_key, api_secret, access_token, access_token_secret)
بعد المصادقة ، سيطالبك R بحفظ رموز OAuth على القرص لاستخدامها لاحقًا.
[1] "Using direct authentication" Use a local file to cache OAuth access credentials between R sessions? 1: Yes 2: No
كلا الخيارين مقبول ، اخترت الأول.
نتائج البحث والتصفية
tweets <- search_tweets("hadoop", include_rts=FALSE, n=600)
يسمح لك مفتاح include_rts بالتحكم في ما إذا كان يتم تضمين إعادة التغريد أو استبعادها من البحث. في الإخراج نحصل على جدول يحتوي على العديد من الحقول التي توجد فيها تفاصيل وتفاصيل لكل سجل. هنا أول 20.
> head(names(tweets), n=20) [1] "user_id" "status_id" "created_at" [4] "screen_name" "text" "source" [7] "display_text_width" "reply_to_status_id" "reply_to_user_id" [10] "reply_to_screen_name" "is_quote" "is_retweet" [13] "favorite_count" "retweet_count" "hashtags" [16] "symbols" "urls_url" "urls_t.co" [19] "urls_expanded_url" "media_url"
يمكنك إنشاء سلسلة بحث أكثر تعقيدًا.
search_string <- paste0(c("data mining","#bigdata"),collapse = "+") search_tweets(search_string, include_rts=FALSE, n=100)
يمكن حفظ نتائج البحث في ملف نصي.
write.table(tweets$text, file="datamine.txt")
نندمج في نص النصوص ، ونقوم بالفلترة من كلمات الخدمة وعلامات الترقيم ونترجم كل شيء إلى أحرف صغيرة.
هناك وظيفة بحث أخرى - searchTwitter ، والتي تتطلب مكتبة twitteR . في بعض النواحي ، يكون الأمر أكثر ملاءمة من search_tweets ، ولكن في بعض النواحي أدنى منه.
زائد - وجود عامل تصفية حسب الوقت.
tweets <- searchTwitter("hadoop", since="2017-09-01", n=500) text = sapply(tweets, function(x) x$getText())
ناقص - الإخراج ليس جدولاً ، ولكنه كائن من نوع status . من أجل استخدامه في مثالنا ، نحتاج إلى استخراج حقل نص من الإخراج. هذا يجعل sapply في السطر الثاني.
corpus <- Corpus(VectorSource(tweets$text)) clearCorpus <- tm_map(corpus, function(x) iconv(enc2utf8(x), sub = "byte")) tdm <- TermDocumentMatrix(clearCorpus, control = list(removePunctuation = TRUE, stopwords = c("com", "https", "hadoop", stopwords("english")), removeNumbers = TRUE, tolower = TRUE))
في السطر الثاني ، هناك حاجة إلى وظيفة tm_map لتحويل جميع أنواع أحرف الرموز التعبيرية إلى أحرف صغيرة ، وإلا سيفشل التحويل إلى أحرف صغيرة باستخدام tolower .
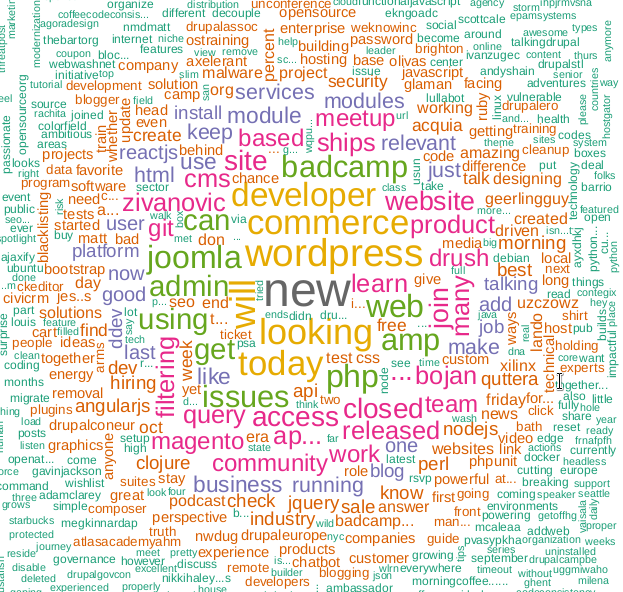
بناء سحابة كلمة
ظهرت سحابة الكلمات لأول مرة على استضافة فليكر للصور ، على حد علمي ، واكتسبت منذ ذلك الحين شعبية. لهذه المهمة ، نحن بحاجة إلى مكتبة wordcloud .
m <- as.matrix(tdm) word_freqs <- sort(rowSums(m), decreasing=TRUE) dm <- data.frame(word=names(word_freqs), freq=word_freqs) wordcloud(dm$word, dm$freq, scale=c(3, .5), random.order=FALSE, colors=brewer.pal(8, "Dark2"))
تتيح لك وظيفة search_string تعيين اللغة كمعلمة.
search_tweets(search_string, include_rts=FALSE, n=100, lang="ru")
ومع ذلك ، نظرًا لحقيقة أن حزمة NLP لـ R ضعيفة الترويس ، على وجه الخصوص ، لا توجد قائمة بالخدمة أو كلمات التوقف ، لم أتمكن من بناء سحابة كلمات مع البحث باللغة الروسية. سأكون سعيدًا إذا وجدت حلاً أفضل في التعليقات.
حسنًا ، في الواقع ...
النص برمته library("rtweet") library("tm") library("wordcloud") api_key <- "" api_secret <- "" access_token <- "" access_token_secret <- "" appname="" setup_twitter_oauth ( api_key, api_secret, access_token, access_token_secret) oauth_callback <- "http://127.0.0.1:1410" setup_twitter_oauth (api_key, api_secret, access_token, access_token_secret) appname="my_app" twitter_token <- create_token(app = appname, consumer_key = api_key, consumer_secret = api_secret) tweets <- search_tweets("devops", include_rts=FALSE, n=600) corpus <- Corpus(VectorSource(tweets$text)) clearCorpus <- tm_map(corpus, function(x) iconv(enc2utf8(x), sub = "byte")) tdm <- TermDocumentMatrix(clearCorpus, control = list(removePunctuation = TRUE, stopwords = c("com", "https", "drupal", stopwords("english")), removeNumbers = TRUE, tolower = TRUE)) m <- as.matrix(tdm) word_freqs <- sort(rowSums(m), decreasing=TRUE) dm <- data.frame(word=names(word_freqs), freq=word_freqs) wordcloud(dm$word, dm$freq, scale=c(3, .5), random.order=FALSE, colors=brewer.pal(8, "Dark2"))
المواد المستعملة.
روابط قصيرة:
الروابط الأصلية:
https://stats.seandolinar.com/collecting-twitter-data-getting-started/
https://opensourceforu.com/2018/07/using-r-to-mine-and-analyse-popular-sentiments/
http://dkhramov.dp.ua/images/edu/Stu.WebMining/ch17_twitter.pdf
http://opensourceforu.com/2018/02/explore-twitter-data-using-r/
https://cran.r-project.org/web/packages/tm/vignettes/tm.pdf
PS Hint ، لا يتم استخدام الكلمة الرئيسية السحابية على KDPV في البرنامج ، فهي مرتبطة بمقالي السابق .