التحقق من خادم واحد ليس مشكلة. يمكنك أخذ قائمة التحقق والتحقق من الترتيب: المعالج والذاكرة والأقراص. ولكن مع وجود مائة خادم ، من غير المرجح أن تعمل هذه الطريقة بشكل جيد. لاستبعاد العامل البشري ، لجعل الشيكات أكثر موثوقية وأسرع ، من الضروري أتمتة العملية. من يحتاج إلى معرفة كيفية القيام بذلك أفضل من مزود الاستضافة. أخبر Artyom Artemyev على HighLoad ++ Siberia الطرق التي يمكن استخدامها ، وما هو الأفضل للتشغيل بيديك ، وما الذي يعمل بشكل جيد للأتمتة. علاوة على ذلك ، يمكن تكرار نسخة نصية من التقرير مع نصائح يمكن لأي شخص يعمل مع الحديد ويحتاج إلى التحقق من أدائه بانتظام.
 حول المتحدث:
حول المتحدث: المدير الفني Artyom Artemyev (
artemirk ) في مزود استضافة كبير FirstVDS ، يعمل مع الحديد.
لدى FirstVDS مركزين للبيانات. الأول هو خاص بهم ، قاموا ببناء مبنى خاص بهم ، وأحضروا وركبوا رفوفهم ، وهم أنفسهم يحافظون ، ويقلقون بشأن التيار والتبريد لمركز البيانات. مركز البيانات الثاني عبارة عن غرفة كبيرة في مركز بيانات كبير مستأجر ، وكل شيء أسهل معه ، ولكنه موجود أيضًا. في المجموع 60 رفًا وحوالي 3000 خادم حديد. كان هناك شيء للتدريب على واختبار نهج مختلفة ، مما يعني أننا ننتظر توصيات مؤكدة عمليا. لنبدأ في عرض أو قراءة التقرير.
منذ حوالي 6-7 سنوات ، أدركنا أن وضع نظام التشغيل على الخادم ببساطة لا يكفي. نظام التشغيل قيد التشغيل ، الخادم مستيقظ وجاهز للمعركة. نطلقه عند الإنتاج - تبدأ عمليات إعادة التشغيل والتجميد غير المفهومة. ما يجب فعله ، ليس واضحًا - العملية جارية ، نقل مسودة العمل بالكامل إلى قطعة معدنية جديدة أمر صعب ومكلف ومؤلم. إلى أين أركض؟
تسمح لنا طرق النشر الحديثة بتجنب ذلك ونقل الخادم في 5 ثوانٍ ، لكن عملائنا (خاصة قبل 6 سنوات) لم يطيروا في الغيوم ، وساروا على الأرض واستخدموا قطعًا عادية من الحديد.

في هذه المقالة ، سأخبرك عن الطرق التي جربناها ، وأي الطرق التي جذرناها ، والتي لم تترسخ ، وأيها جيد للتشغيل بيديك ، وكيفية أتمتة كل هذا. سأقدم لك النصيحة ، ويمكنك تكرارها في شركتك إذا كنت تعمل بالحديد ولديك مثل هذه الحاجة.
ما هي المشكلة؟
من الناحية النظرية ، لا يمثل التحقق من الخادم مشكلة. في البداية ، كانت لدينا عملية ، كما في الصورة أدناه. يجلس الرجل ، يأخذ قائمة مراجعة ، يتحقق: المعالج ، الذاكرة ، الأقراص ، التجاعيد في جبهته ، يتخذ القرار.
ثم تم تثبيت 3 خوادم شهريًا. ولكن ، عندما يكون هناك المزيد والمزيد من الخوادم ، يبدأ هذا الشخص في البكاء ويشكو من أنه يموت في العمل. يخطئ الشخص بشكل متزايد ، لأن التحقق أصبح روتينًا.
لقد اتخذنا قرارًا: أتمتة! يقوم الشخص بأشياء أكثر فائدة.
رحلة قصيرة
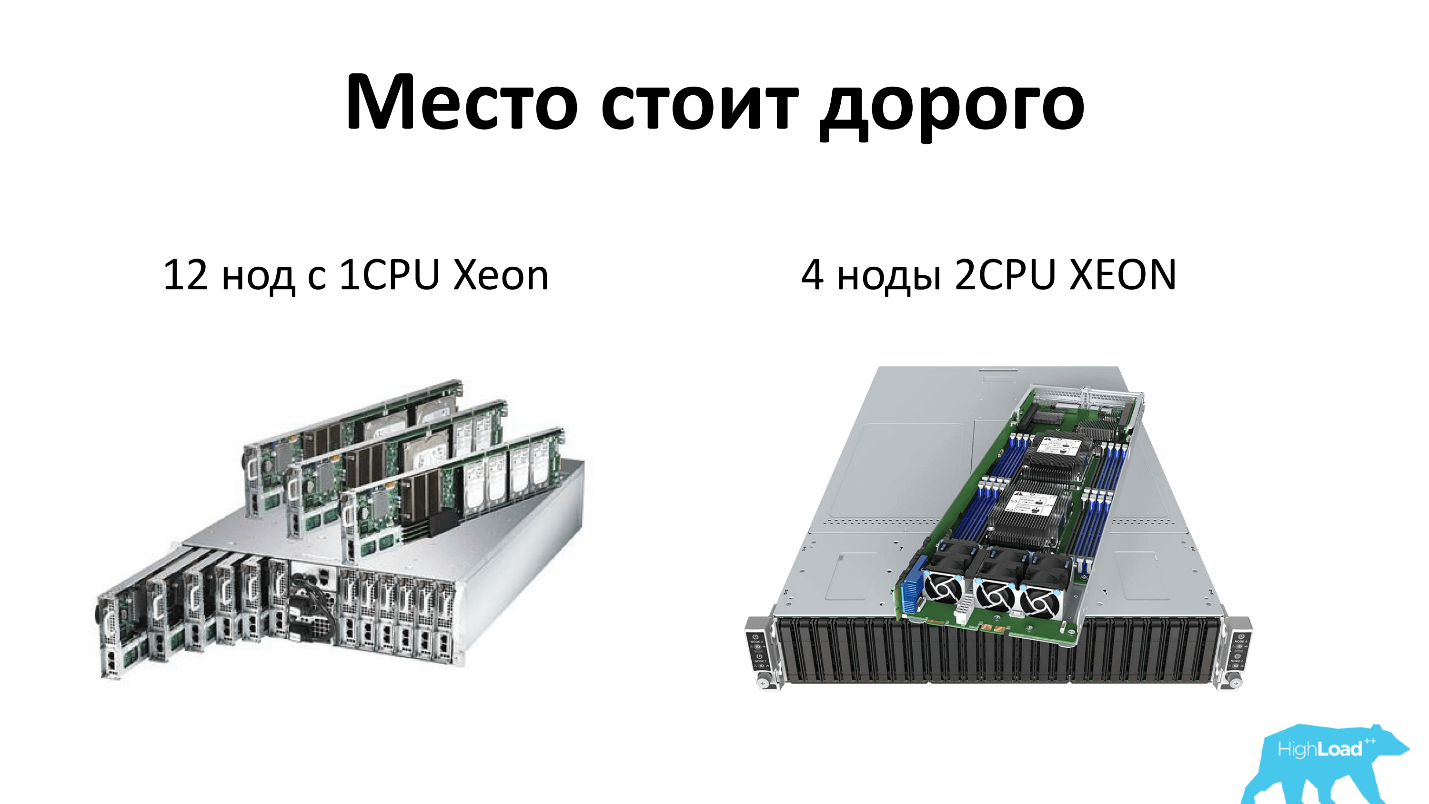
سأوضح ما أعنيه عندما أتحدث عن الخادم اليوم. نحن ، مثل أي شخص آخر ، نوفر مساحة الرف ونستخدم خوادم عالية الكثافة. اليوم تتكون من وحدتين ، والتي يمكن أن تناسب إما 12 عقدًا من خوادم المعالج الواحد ، أو 4 عقد من الخوادم ثنائية المعالج. أي أن كل خادم يحصل على 4 أقراص - كل ذلك بصدق. بالإضافة إلى ذلك ، يوجد حاملان للطاقة في الحامل ، أي أن كل شيء فائض ويحبه الجميع.
من أين الحديد؟
يتم جلب الحديد إلى مركز البيانات الخاص بنا من قبل موردينا - عادة ما يكون سوبرمايكرو وإنتل. في مركز البيانات ، يقوم العاملون لدينا بتثبيت الخوادم في مساحة فارغة في الرف وتوصيل سلكين وشبكة وقوة. كما أنه من مسؤولية المشغلين تكوين BIOS في الخادم. أي توصيل لوحة المفاتيح ومراقبة وتكوين معلمتين:
Restore on AC/Power Loss — [Power On] ، بحيث يتم تشغيل الخادم دائمًا بمجرد ظهور الطاقة. يجب أن تعمل بدون توقف.
First boot device — [PXE] الثاني
First boot device — [PXE] ، أي أننا نضع جهاز التمهيد الأول على الشبكة ، وإلا فلن نتمكن من الوصول إلى الخادم ، نظرًا لأنه ليس حقيقة أنه يحتوي على أقراص على الفور ، وما إلى ذلك.

بعد ذلك ، يفتح المشغل لوحة المحاسبة لخوادم الحديد ، والتي تحتاج فيها إلى تسجيل حقيقة تثبيت الخادم ، والتي يشار إليها:
- رف.
- ملصقا
- منافذ الشبكة
- منافذ الطاقة
- رقم الوحدة.
بعد ذلك ، ينتقل منفذ الشبكة حيث قام المشغل بتثبيت الخادم الجديد ، لأغراض أمنية ، إلى وحدة عزل خاصة للشبكة المحلية الظاهرية VLAN ، والتي تقوم أيضًا بتعليق DHCP و Pxe و TFtp. بعد ذلك ، يقوم الخادم بتحميل Linux المفضل لدينا ، والذي يحتوي على جميع الأدوات المساعدة اللازمة ، وتبدأ عملية التشخيص.
نظرًا لأن الخادم لا يزال يحتوي على جهاز التمهيد الأول على الشبكة ، بالنسبة للخوادم التي تدخل حيز الإنتاج ، يتحول المنفذ إلى شبكة محلية ظاهرية أخرى. لا يوجد DHCP في شبكة محلية ظاهرية أخرى ، ولا نخشى أن نعيد تثبيت خادم الإنتاج عن طريق الخطأ. لهذا ، لدينا شبكة محلية ظاهرية منفصلة.
يحدث أنه تم تثبيت الخادم ، كل شيء على ما يرام ، لكنه لم يتم التمهيد في نظام التشخيص. يحدث هذا ، كقاعدة عامة ، بسبب حقيقة أنه مع التأخير في تبديل شبكات VLAN ، لا تقوم جميع محولات الشبكة بتبديل شبكات VLAN بسرعة ، إلخ.

ثم يتلقى المشغل مهمة إعادة تشغيل الخادم بيديه. في السابق ، لم يكن هناك IPMI ، قمنا بإعداد مآخذ عن بعد وثبت في أي منفذ منفذ مآخذ الخادم ، وسحب المقبس عبر الشبكة ، وإعادة تشغيل الخادم.
لكن المنافذ المدارة لا تعمل دائمًا بشكل جيد ، لذلك ندير الآن طاقة الخادم عبر IPMI. ولكن عندما يكون الخادم جديدًا ، لا يتم تكوين IPMI ، ولا يمكن إعادة تشغيله إلا من خلال الصعود والضغط على الزر. لذلك ، يجلس الرجل ، وينتظر - يضيء الضوء - يعمل ويضغط على الزر. هذه هي وظيفته.
إذا لم يتم تشغيل الخادم بعد ذلك ، يتم إدخاله في قائمة خاصة للإصلاح. تتضمن هذه القائمة خوادم لم يبدأ التشخيص عليها ، أو كانت نتائجها غير مرضية. إن الشخص - الذي يحب الحديد - يجلس ويفكك كل يوم - يجمع وينظر ولماذا لا يعمل.
وحدة المعالجة المركزية
كل شيء على ما يرام ، بدأ الخادم ، بدأنا في الاختبار. أولاً نقوم باختبار المعالج كواحد من أهم العناصر.

الدافع الأول هو استخدام التطبيق من البائع. لدينا جميع معالجات Intel تقريبًا - ذهبنا إلى الموقع ، وقمنا بتنزيل أداة تشخيص المعالج من Intel - كل شيء على ما يرام ، ويظهر الكثير من المعلومات المثيرة للاهتمام ، بما في ذلك ساعات عمل الخادم في الساعات والرسم البياني لاستهلاك الطاقة.
لكن المشكلة هي أن Intel PTD تعمل تحت Windows ، والتي لم نعد نحبها. لبدء اختبار فيه ، ما عليك سوى تحريك الماوس ، والضغط على زر "START" ، وسيبدأ الاختبار. يتم عرض النتيجة على الشاشة ، ولكن لا توجد طريقة لتصديرها في أي مكان. هذا لا يناسبنا ، لأن العملية ليست آلية.

ذهبنا لقراءة المنتديات ووجدنا أسهل طريقتين.
- القط الأبدي / dev / zero> / dev / null . يمكنك تسجيل الوصول في الأعلى - يتم استهلاك 100٪ من قلب واحد. نحسب عدد النوى ، ونقوم بتشغيل العدد المطلوب من cat / dev / zero ، مضروبًا في العدد المطلوب من النوى. كل شيء يعمل بشكل رائع!
- فائدة / بن / إجهاد . تبني المصفوفات في الذاكرة وتبدأ في تسليمها باستمرار. كل شيء على ما يرام أيضًا - المعالج يسخن ، هناك حمولة.
نعطي الخوادم في الإنتاج ، ويعود المستخدمون ويقولون أن المعالج غير مستقر. تم الفحص - المعالج غير مستقر. بدأوا في التحقيق ، وأخذوا الخادم ، الذي يجتاز الاختبارات ، لكنه تعطل في المعركة ، وشغّل نواة التصحيح في Linux ، وجمع تفريغ Core. الخادم قبل إعادة التشغيل يتدفق إلى الملف كل ما كان في الذاكرة قبل التحطم.

تم دمج التحسينات المختلفة في المعالجات للعمليات المتكررة. يمكننا أن نرى إشارات تعكس التحسينات التي يدعمها المعالج ، على سبيل المثال ، التحسينات للعمل مع أرقام الفاصلة العائمة ، وتحسينات الوسائط المتعددة ، إلخ. لكن لدينا / بن / الإجهاد ، والدورة الأبدية مجرد حرق المعالج في عملية واحدة ولا تستخدم ميزات إضافية. أظهر التحقيق أن وحدة المعالجة المركزية تتعطل عند محاولة استخدام وظيفة أحد الأعلام المدمجة.
كان الدافع الأول هو ترك / بن / إجهاد - دع المعالج يسخن. ثم في دورة نركض عبر جميع الأعلام ، وسحبها. أثناء التفكير في كيفية تنفيذ ذلك ، وهو الأمر الذي يتم الاتصال به لاستدعاء وظائف كل علم ، نقرأ المنتديات.
في منتدى overclockers ، تعثرنا في مشروع مثير للاهتمام للبحث عن الأعداد الأولية
Great Internet Mersenne Prime Search . قام العلماء بإنشاء شبكة موزعة يمكن لأي شخص الاتصال بها والمساعدة في العثور على رقم أولي. لا يصدق العلماء أي شخص ، لذلك يعمل البرنامج بذكاء شديد: أولاً تقوم بتشغيله ، فهو يحسب الأعداد الأولية التي يعرفها بالفعل ، ويقارن النتيجة بما يعرفه. إذا لم تتطابق النتيجة ، فإن المعالج به خلل. لقد أحببنا حقًا هذا العقار: مع أي هراء من المحتمل أن يسقط.
بالإضافة إلى ذلك ، فإن الهدف من المشروع هو العثور على أكبر عدد ممكن من الأعداد الأولية ، وبالتالي يتم تحسين البرنامج باستمرار لخصائص المعالجات الجديدة ، ونتيجة لذلك فإنه يسحب الكثير من الأعلام.
Mprime ليس لديه حد زمني ، إذا لم يتوقف ، فإنه يعمل إلى الأبد. نقوم بتشغيله لمدة 30 دقيقة.
/usr/bin/timeout 30m /opt/mprime -t /bin/grep -i error /root/result.txt
بعد الانتهاء من العمل ، نتحقق من عدم وجود أخطاء في result.txt ، ونلقي نظرة على سجلات kernel ، على وجه الخصوص ، في ملف / proc / kmsg الذي نبحث فيه عن الأخطاء.
رحلة أخرى

في 3 يناير 2018 ، وجدوا الرقم الأساسي الخمسين لمرسين (2
ص -1). من هذا الرقم ، فقط 23 مليون رقم. يمكنك تنزيله لمشاهدته -
هذا أرشيف بسعة 12 ميجا بايت .
لماذا نحتاج إلى الأعداد الأولية؟ أولاً ، يستخدم أي تشفير RSA الأعداد الأولية. كلما عرفنا أكثر ، كلما كان موثوقًا بمفتاح SSH الخاص بك. ثانيًا ، يختبر العلماء فرضياتهم ونظرياتهم الرياضية ، ولا مانع لدينا من مساعدة العلماء - لا يكلفنا ذلك شيئًا. اتضح تاريخ الفوز.

لذا ، المعالج يعمل ، كل شيء على ما يرام. يبقى لمعرفة نوع المعالج. نستخدم معالج dmidecode -t ونرى جميع الفتحات الموجودة في اللوحة الأم ، والمعالجات الموجودة في هذه الفتحات. تدخل هذه المعلومات إلى نظام المحاسبة لدينا ، وسوف نقوم بتفسيرها لاحقًا.
قبض
وهكذا ، من المثير للدهشة ، يمكن العثور على الساقين المكسورة. / بن / الإجهاد والدورة الدائمة عملت ، وسقط مريم. قادوا لفترة طويلة ، بحثوا ، اكتشفوا - النتيجة في الصورة أدناه - كل شيء واضح هنا.

مثل هذا المعالج ببساطة لم يبدأ. كان عامل الهاتف قويًا جدًا ، وأخذ المعالج الخاطئ - ولكنه كان بإمكانه التوصيل.

حالة جميلة أخرى. الصف الأسود في الصورة أدناه هو المراوح ، ويظهر السهم كيف ينفخ الهواء. نرى: المبرد يقف عبر الدفق. بالطبع ، كل شيء محموم وإيقافه.

الذاكرة
مع الذاكرة ، كل شيء بسيط للغاية. هذه هي الخلايا التي نكتب فيها المعلومات ، وبعد فترة نقرأها مرة أخرى. إذا بقي هناك نفس الشيء الذي كتبناه ، فإن هذه الخلية تعمل.

يعلم الجميع برنامج
Memtest86 + الجيد والكلاسيكي مباشرة ، والذي يعمل من أي وسيط أو عبر الشبكة أو حتى من قرص مرن. يتم ذلك من أجل فحص أكبر عدد ممكن من خلايا الذاكرة. لم يعد من الممكن فحص أي خلايا مشغولة. لذا فإن memtest86 + لها حجم أدنى حتى لا تشغل الذاكرة. لسوء الحظ ،
يعرض memtest86 + إحصائياته فقط على الشاشة . حاولنا توسيعه بطريقة أو بأخرى ، ولكن كل هذا يرجع إلى حقيقة أنه لم يكن هناك حتى مكدس شبكة داخل البرنامج. لتوسيعها ، يجب على المرء إحضار نواة لينكس وكل شيء آخر.
هناك نسخة مدفوعة من هذا البرنامج تعرف بالفعل كيفية إسقاط المعلومات إلى القرص. لكن خوادمنا لا تحتوي دائمًا على قرص ، ولا يوجد دائمًا نظام ملفات على هذه الأقراص. لكن محرك الشبكة ، كما اكتشفنا بالفعل ، لا يمكن توصيله.
بدأنا في البحث أكثر ووجدنا برنامج
Memtester مماثل. يعمل هذا البرنامج من مستوى نظام التشغيل من Linux. أكبر ناقص هو أن نظام التشغيل نفسه و Memtester يشغلان بعض خلايا الذاكرة ، ولن يتم فحص هذه الخلايا.
يبدأ Memtester بالأمر: memtester `cat / proc / meminfo | grep MemFree | awk '{print $ 2-1024}' 'ك 5
ننقل هنا مقدار الذاكرة الخالية ناقص 1 ميجابايت. يتم ذلك ، لأنه بخلاف ذلك يأخذ Memtester كل الذاكرة ويقتلها القاتل السفلي. نحن نقود هذا الاختبار لمدة 5 دورات ، عند الإخراج لدينا لوحة إما موافق أو فشل.
| عنوان عالق | حسنًا |
| قيمة عشوائية | حسنًا |
| قارن XOR | حسنًا |
| قارن SUB | حسنًا |
| قارن MUL | حسنًا |
| قارن DIV | حسنًا |
| قارن أو | حسنًا |
| قارن AND | حسنًا |
نحفظ النتيجة النهائية ونواصل تحليل الفشل.

لفهم حجم المشكلة - أصغر خادم لدينا يحتوي على 32 جيجا بايت من الذاكرة ، صورة Linux الخاصة بنا مع Memtester تستهلك 60 ميجا بايت ،
نحن لا نتحقق من 2 ٪ من الذاكرة . ولكن وفقا للإحصاءات على مدى السنوات الست الماضية ، لم يكن هناك شيء من هذا القبيل دخلت الذاكرة الضرب بصراحة في الإنتاج. هذا هو الحل الوسط الذي نوافق عليه ، وهو مكلف بالنسبة لنا لإصلاحه ، ونحن نعيش معه.
على طول الطريق ، نجمع أيضًا ذاكرة dmidecode -t ، والتي تمنح جميع بنوك الذاكرة الموجودة على اللوحة الأم (عادةً ما يصل إلى 24 قطعة) ، والتي تموت في كل بنك. هذه المعلومات مفيدة إذا أردنا ترقية الخادم - سنعرف إلى أين نضيف ما ، وعدد الشرائط التي نأخذها والخادم الذي نذهب إليه.
أجهزة التخزين
قبل 6 سنوات ، كانت جميع الأقراص مع الفطائر التي نسج. قصة أخرى هي تجميع قائمة بكل الأقراص. كانت هناك عدة طرق مختلفة ، حيث لم يكن يعتقد أنه يمكنك فقط إلقاء نظرة على ls / dev / sd. ولكن في النهاية ، توقفنا عن النظر إلى ls / dev / sd * و ls / dev / cciss / c0d *. في الحالة الأولى ، هو جهاز SATA ، في الحالة الثانية - SCSI و SAS.

حرفيا هذا العام ، بدأوا في بيع أقراص nvme وإضافة قائمة nvme هنا.
بعد تجميع قائمة الأقراص ، نحاول قراءة 0 بايت منها لفهم أن هذا جهاز كتلة وكل شيء على ما يرام. إذا لم تستطع قراءته ، فنحن نعتقد أن هذا نوع من الأشباح ، وليس لدينا مثل هذا القرص ولم يكن لدينا أبدًا.
كانت الطريقة الأولى لفحص الأقراص واضحة: "دعنا نكتب بيانات عشوائية على القرص ونرى السرعة" -
dd -o nocache -o direct if=/dev/urandom of=${disk} . كقاعدة ، تعطي أقراص فطيرة 130-150 ميجا بت / ثانية. لقد أحدقنا أعيننا وقررنا لأنفسنا أن 90 ميجابايت / ثانية هي الرقم الذي يوجد بعده أقراص قابلة للخدمة ، وكلها أصغر تعمل بشكل سليم.
ولكن مرة أخرى ، بدأ المستخدمون في العودة ويقولون إن محركات الأقراص سيئة. اتضح أن الفيزياء الخبيثة كانت تمزح معنا مرة أخرى.
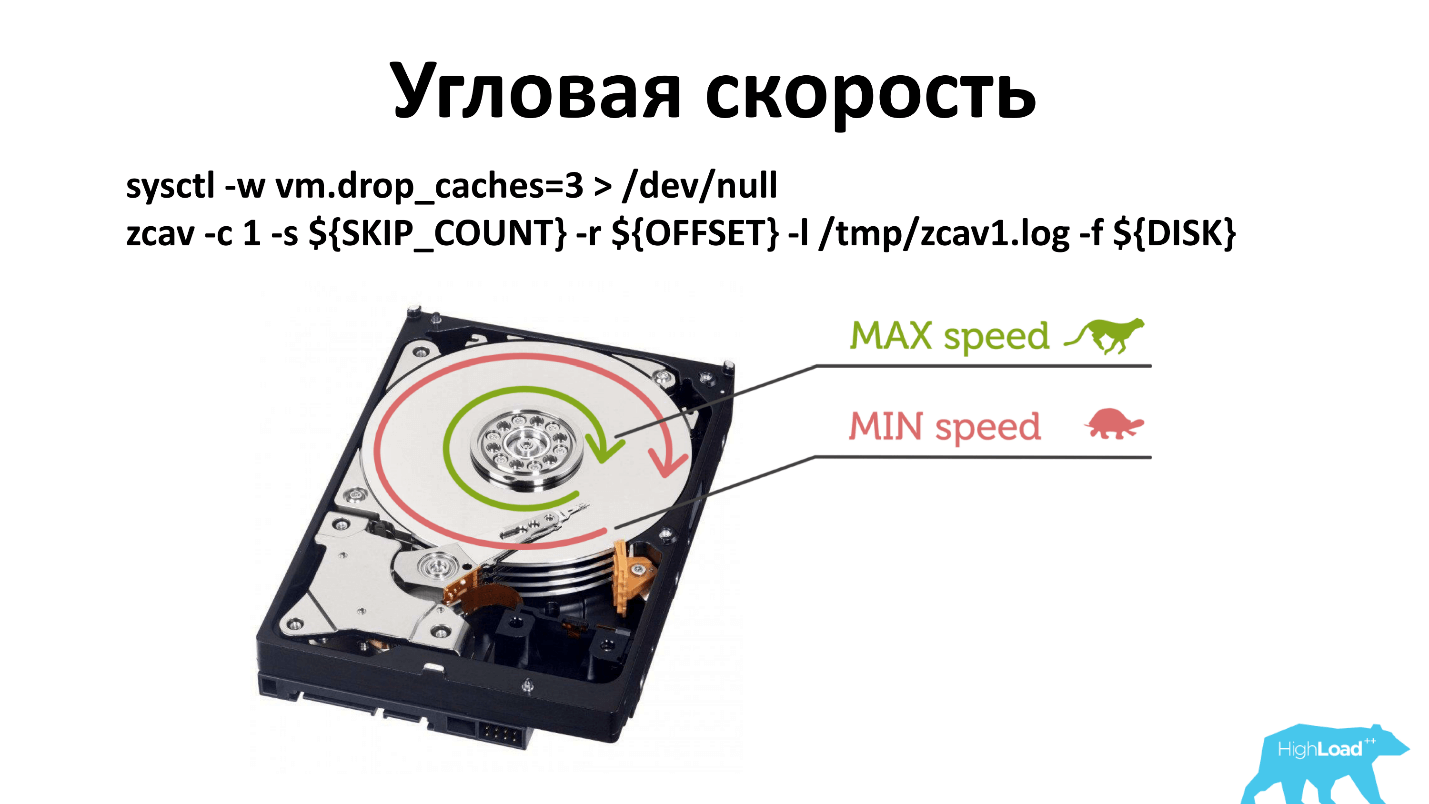
هناك سرعة زاوية ، وكقاعدة عامة ، عند تشغيل -dd ، فإنه يكتب بالقرب من المغزل. إذا تدهورت سرعة المغزل لسبب ما ، فهذا أقل وضوحًا مما لو كنت تكتب من حافة القرص.
اضطررت إلى تغيير مبدأ التحقق. الآن نتحقق في ثلاثة أماكن: بالقرب من المغزل ، في الوسط والخارج. ربما يمكن فحصه من الخارج فقط ، ولكن هذا ما حدث تاريخيًا. وما يعمل ، لا تلمس.
يمكنك استخدام
smartctl ليسأل القرص كيف يفعل. نعتقد أن محرك جيد:
- لا توجد قطاعات معاد تخصيصها ( عدد القطاعات المعاد تخصيصها = 0) ، أي جميع القطاعات التي تركت عمل المصنع.
- لا نستخدم أقراص أقدم من 4 سنوات ، على الرغم من أنها تعمل بشكل جيد. قبل أن نقدم هذه الممارسة ، كان لدينا أقراص لمدة 7 سنوات. الآن نعتقد أنه بعد 4 سنوات قد دفع القرص ثماره ، ونحن لسنا مستعدين لقبول خطر التآكل.
- لا توجد قطاعات سيتم إعادة تخصيصها ( Current_Pending_Sector = 0 ).
- عدد أخطاء UltraDMA CRC = 0 - هذه أخطاء في كبل SATA. إذا كان هناك خطأ ، تحتاج فقط إلى تغيير السلك ، لا تحتاج إلى تغيير القرص.

محركات أقراص SSD الموزعة هي محركات ممتازة بشكل عام ، فهي تعمل بسرعة ، ولا تصدر ضوضاء ، ولا تسخن. نحن نعتقد أن SSD الجيد لديه سرعة كتابة تزيد عن 200 ميجابايت / ثانية. يحب عملاؤنا الأسعار المنخفضة ، ولا تصل إلينا دائمًا نماذج الخادم التي تصدر 320-350 ميجابايت / ثانية.
بالنسبة لأقراص SSD ، فإننا ننظر أيضًا إلى smartctl. نفس المعاد تخصيصها ، Power_On_Hours ، Current_Pending_Sector. جميع محركات الأقراص ذات الحالة الصلبة قادرة على عرض درجة التآكل ، وتظهر المعلمة Media_Wearout_Indicator. نقوم بمسح الأقراص حتى 5٪ من الحياة ، وعندها فقط نخرجها. تجد هذه الأقراص أحيانًا حياة ثانية في الاحتياجات الشخصية للموظفين. على سبيل المثال ، اكتشفت مؤخرًا أنه في غضون عامين تآكل هذا القرص بنسبة 1٪ أخرى في الكمبيوتر المحمول الخاص بالموظف ، على الرغم من أنه في بلدنا يستهلك ذاكرة التخزين المؤقت SSD 95٪ في حوالي 10 أشهر.
ولكن المشكلة هي أنه لم توافق جميع الشركات المصنعة للأقراص على أسماء المعلمات ، وهذا Media_Wearout_Indicator ، على سبيل المثال ، يسمى Percent_Lifetime_Used لتوشيبا ، أو عدد التآكل الآخر ، أو النسبة المئوية المتبقية مدى الحياة للشركات المصنعة الأخرى ، أو ببساطة. * Wear. *.
لا يملك Crucial هذا الخيار على الإطلاق. ثم نأخذ بعين الاعتبار مقدار إعادة كتابة القرص - "بايت مكتوب" - عدد البايتات التي كتبناها بالفعل على هذا القرص. علاوة على ذلك ، وفقًا للمواصفات ، نحن نحاول معرفة عدد عمليات إعادة كتابة هذا القرص التي تم حسابها من قبل الشركة المصنعة. بالرياضيات الابتدائية نحدد كم سيعيش أكثر. إذا حان الوقت للتغيير - التغيير.
RAID
لا أعرف لماذا لا يزال عملاؤنا في العالم الحديث يريدون RAIDs. يشتري الناس RAID ، ويضعون 4 SSDs ، وهي أسرع بكثير من RAID (6 جيجابايت). لديهم نوع من التعليمات ، ويقومون بجمعها. أعتقد أن هذا أمر غير ضروري تقريبًا.
كان هناك 3 مصنعين: Adaptec؛ 3ware. إنتل كان لدينا 3 مرافق ، ونحن نتعب أنفسنا ، لكننا أجرينا التشخيص للجميع. الآن LSI اشترى الجميع - لم يتبق سوى أداة واحدة.
عندما يرى نظام التشخيص لدينا RAID ، فإنه يوزع الحجم المنطقي في أقراص منفصلة بحيث يمكنك قياس سرعة كل قرص وقراءة Smart الخاصة به. بعد ذلك ، يبقى على RAID أن يفحص البطارية. من لا يعرف - هناك ما يكفي من البطاريات على RAID لتدوير جميع الأقراص لمدة ساعتين أخريين. أي أنك تقوم بإيقاف تشغيل الخادم وإزالته وتدوير القرص لمدة ساعتين إضافيتين لإكمال جميع التسجيلات.
شبكة
مع الشبكة ، كل شيء بسيط للغاية - يجب أن يكون هناك أقل من 300 ميغابت داخل مركز البيانات. إذا كان أقل ، فأنت بحاجة إلى إصلاحه. نحن ننظر أيضًا إلى أخطاء الواجهة.
لا ينبغي أن تكون الأخطاء على واجهة الشبكة على الإطلاق ، وإذا كانت كذلك ، فإن كل شيء سيء.
نحن نحاول تحديث البرامج الثابتة BIOS و IPMI على طول الطريق. اتضح أننا لا نحب جميع BIOS. لا يزال لدينا BIOS لا تعرف كيفية UEFI والميزات الأخرى التي نستخدمها. نحاول تحديثه تلقائيًا ، ولكن هذا لا يعمل دائمًا ، كل شيء ليس بسيطًا جدًا هناك. إذا لم يفلح ذلك ، يذهب الشخص ويقوم بالتحديث بيديه.
نحن لا نعطي IPMI Supermicro للعالم ، لدينا عناوين رمادية من خلال OpenVPN. ومع ذلك ، نخشى أن يخرج ضعف آخر في يوم من الأيام وسوف نعاني. لذلك ، نحاول فقط إبقاء البرنامج الثابت IPMI هو الأخير دائمًا. إذا لم يكن الأمر كذلك ، فقم بالتحديث.
من شيء غريب ، فقد ظهر مؤخرًا أن Intel على بطاقات شبكة 10 و 40 gigabit لا تتضمن تمهيد PXE. اتضح أنه إذا كان الخادم في رف لا توجد فيه سوى بطاقة 40 غيغابايت ، فمن المستحيل التمهيد عبر الشبكة ، لأنك تحتاج إلى التمهيد في بطاقة غيغابت. نقوم بتفريغ بطاقات الشبكة بشكل منفصل على 40G بحيث يكون لديهم PXE ويمكنهم الاستمرار في العيش.
بعد فحص كل شيء ، يبدأ الخادم في البيع فورًا . يتم حساب سعره ، حيث يتم وضعه على الموقع وبيعه.

في المجموع ، نجري ما يقرب من 350 فحصًا شهريًا ، 69 ٪ من الخوادم قابلة للخدمة ، و 31 ٪ غير قابلة للخدمة. هذا يرجع إلى حقيقة أن لدينا تاريخًا ثريًا ، فقد كانت بعض الخوادم واقفة لمدة 10 سنوات. معظم الخوادم التي لم تجتز الاختبار ، نرميها فقط.
للفضول: لدينا 3 عملاء لا يزالون يعيشون على بنتيوم 4 ولا يريدون المغادرة في أي مكان. لديهم 512 ميغا بايت من ذاكرة الوصول العشوائي.
لقد حان المستقبل! لو كنت سأسيج هذا النظام اليوم ...

تم إصدار أداة رائعة ،
Hardware Lister (lshw) ، والتي يمكنها التواصل مع النواة ، وتعرض بشكل جميل نوع الأجهزة الموجودة في النواة ، وما يمكن أن تكتشفه النواة. ليست كل هذه الرقصات مطلوبة. إذا كررت - أنصحك بشدة بالنظر إلى هذه الأداة واستخدامها. كل شيء سيصبح أبسط بكثير.
ملخص:
- التسوية ليست سيئة ، إنها مجرد مسألة سعرية. إذا كان الحل مكلفًا للغاية ، فأنت بحاجة إلى البحث عن مستوى يكون فيه كل من الموثوقية والسعر مقبولًا.
- أحيانًا تكون البرامج غير الأساسية رائعة للاختبار. يبقى فقط للعثور عليهم.
- اختبر كل شيء تصل إليه!
سيكون HighLoad ++ الكبير التالي بالفعل في يومي 8 و 9 نوفمبر في موسكو. يشمل البرنامج المتخصصين المشهورين والأسماء الجديدة والمهام التقليدية والجديدة. في قسم DevOps ، على سبيل المثال ، يتم قبول ما يلي بالفعل:
ادرس قائمة التقارير و اسرع للانضمام. أو اشترك في نشرتنا الإخبارية وستتلقى مراجعات منتظمة للتقارير والتقارير حول المقالات ومقاطع الفيديو الجديدة.