 جولة كاملة للتعلم الآلي في بايثون: الجزء الثالث
جولة كاملة للتعلم الآلي في بايثون: الجزء الثالثكثير من الناس لا يحبون أن نماذج التعلم الآلي هي
صناديق سوداء : نضع البيانات فيها وبدون أي تفسير نحصل على إجابات - غالبًا إجابات دقيقة للغاية. في هذه المقالة ، سنحاول فهم كيف يقوم النموذج الذي أنشأناه بعمل تنبؤات وما يمكن أن يخبرنا عن المشكلة التي نحلها. ونختتم بمناقشة أهم جزء من مشروع التعلم الآلي: نوثق ما قمنا به ونقدم النتائج.
في
الجزء الأول ، درسنا تنظيف البيانات والتحليل الاستكشافي والتصميم واختيار الميزات. في
الجزء الثاني ، درسنا ملء البيانات الناقصة ، وتنفيذ ومقارنة نماذج التعلم الآلي ، وضبط البارامترات باستخدام البحث العشوائي مع التحقق المتبادل ، وأخيرًا ، تقييم النموذج الناتج.
كل
كود المشروع موجود على جيثب. وتوجد هنا مفكرة جوبيتر الثالثة المتعلقة بهذه المقالة. يمكنك استخدامه لمشاريعك!
لذلك ، نحن نعمل على حل المشكلة باستخدام التعلم الآلي ، أو بالأحرى ، باستخدام الانحدار تحت الإشراف. استنادًا إلى
بيانات الطاقة من المباني في نيويورك ، أنشأنا نموذجًا يتنبأ بـ Energy Star Score. لقد حصلنا على نموذج "
الانحدار القائم على تعزيز التدرج " ، القادر على التنبؤ ضمن نطاق 9.1 نقاط (في النطاق من 1 إلى 100) بناءً على بيانات الاختبار.
تفسير النموذج
يقع الانحدار بناءً على تعزيز التدرج تقريبًا في منتصف
مقياس قابلية تفسير النموذج : النموذج نفسه معقد ، ولكنه يتكون من مئات
أشجار القرار البسيطة إلى حد ما. هناك ثلاث طرق لفهم كيفية عمل نموذجنا:
- قيم أهمية الأعراض .
- تصور إحدى أشجار القرار.
- قم بتطبيق طريقة LIME - التفسيرات المحلية النموذجية التفسيرية ، التفسيرات المحلية المستقلة عن النموذج.
تعتبر الطريقتان الأوليتان من خصائص مجموعات الأشجار ، والثالثة ، كما يمكنك فهمها من اسمها ، يمكن تطبيقها على أي نموذج للتعلم الآلي. LIME هو نهج جديد نسبيًا ، إنه خطوة مهمة إلى الأمام في محاولة
لشرح عملية التعلم الآلي .
أهمية الأعراض
تتيح لك أهمية العلامات رؤية علاقة كل علامة بهدف التنبؤ. التفاصيل الفنية لهذه الطريقة معقدة (
يُقاس متوسط انخفاض الشوائب أو
انخفاض الخطأ بسبب إدراج سمة ) ، ولكن يمكننا استخدام القيم النسبية لفهم السمات الأكثر صلة. في Scikit-Learn ، يمكنك
استخراج أهمية السمات من أي مجموعة "طالب" قائمة على الأشجار.
في الكود أدناه ،
model هو نموذجنا المدرب ، وباستخدام
model.feature_importances_ يمكنك تحديد أهمية السمات. ثم نرسلها إلى إطار بيانات Pandas ونعرض أهم 10 سمات:
import pandas as pd
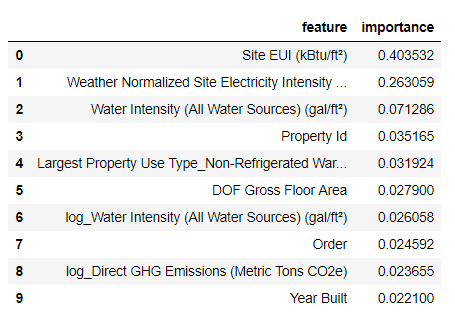
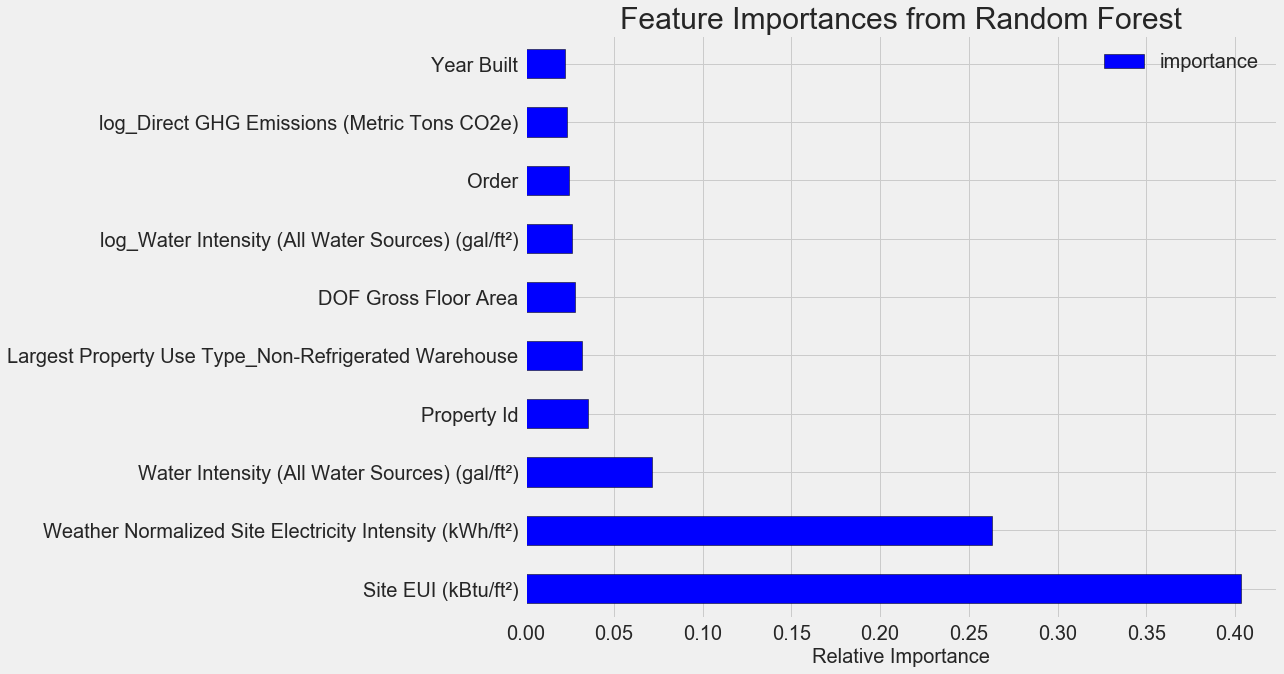
أهم الميزات هي
Site EUI (
كثافة استهلاك الطاقة )
Weather Normalized Site Electricity Intensity ، وهو ما يمثل أكثر من 66 ٪ من إجمالي الأهمية. بالفعل في الميزة الثالثة ، تنخفض الأهمية بشكل كبير ، وهذا
يشير إلى أننا لسنا بحاجة إلى استخدام جميع الميزات الـ 64 لتحقيق دقة تنبؤ عالية (في
دفتر Jupyter تم اختبار هذه النظرية باستخدام أهم 10 ميزات فقط ، ولم يكن النموذج دقيقًا جدًا).
استنادًا إلى هذه النتائج ، يمكن الإجابة على أحد الأسئلة الأولية في النهاية: من أهم مؤشرات نقاط Energy Star هي موقع EUI وكثافة كهرباء الموقع المعتاد. لن نتعمق
في غابة أهمية السمات ، سنقول فقط أنه يمكنك أن تبدأ معهم في فهم آلية التنبؤ بالنموذج.
تصور شجرة قرار واحد
من الصعب فهم نموذج الانحدار بأكمله بناءً على تعزيز التدرج ، والذي لا يمكن قوله عن أشجار القرار الفردية. يمكنك تصور أي شجرة باستخدام
Scikit-Learn- export_graphviz . أولاً ، قم باستخراج الشجرة من المجموعة ، ثم احفظها كملف نقطي:
from sklearn import tree
باستخدام
متخيل Graphviz ، قم بتحويل ملف النقطة إلى png بكتابة:
dot -Tpng images/tree.dot -o images/tree.pngحصلت على شجرة قرارات كاملة:

مرهق قليلا! على الرغم من أن هذه الشجرة بعمق 6 طبقات فقط ، إلا أنه من الصعب تتبع جميع التحولات. دعونا نغير
export_graphviz دالة
export_graphviz عمق الشجرة إلى طبقتين:
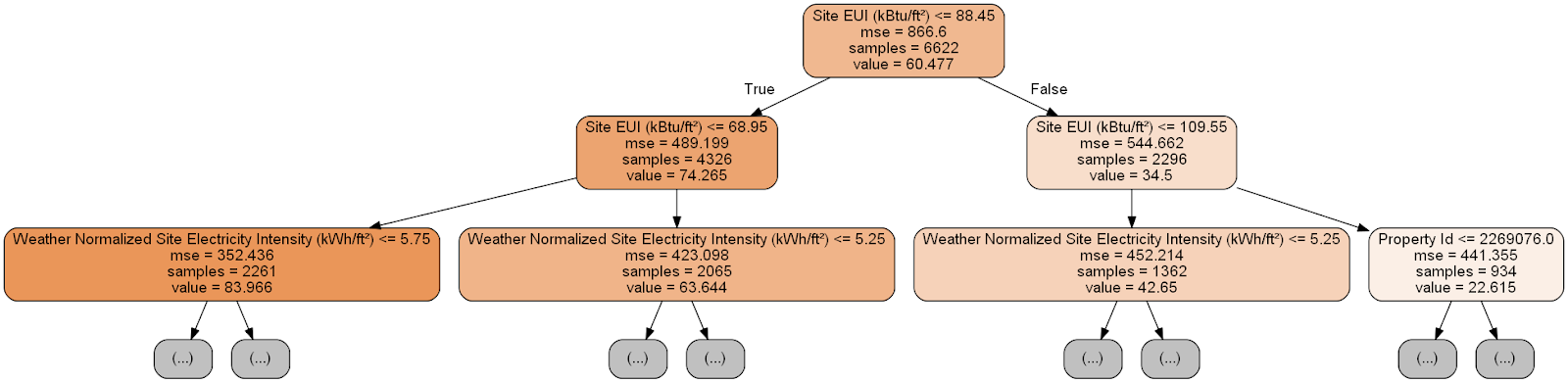
تحتوي كل عقدة (مستطيل) للشجرة على أربعة أسطر:
- سؤال حول قيمة إحدى علامات بعد معين: يعتمد على الاتجاه الذي سنخرج فيه من هذه العقدة.
Mse هو مقياس الخطأ في العقدة.Samples - عدد عينات البيانات (القياسات) في العقدة.- تقييم
Value - الهدف لجميع عينات البيانات في العقدة.
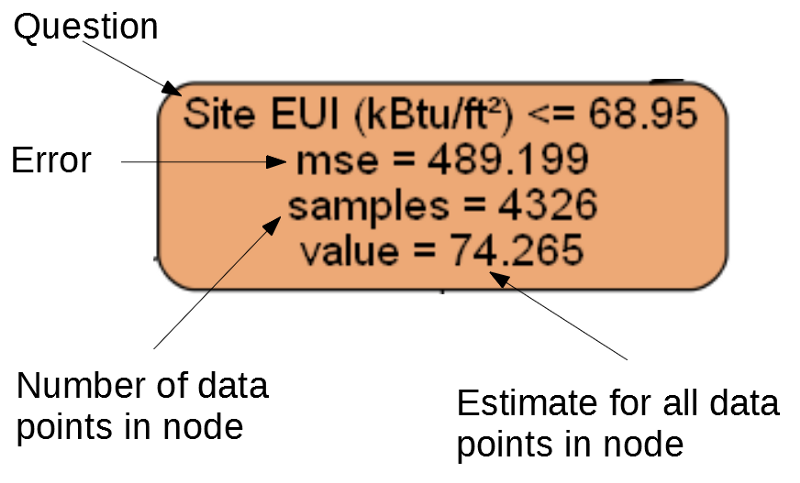 عقدة منفصلة.
عقدة منفصلة.(تحتوي الأوراق على 2. –4. فقط ، لأنها تمثل النتيجة النهائية ولا تحتوي على عقد تابعة).
يبدأ التنبؤ بقياس معين في شجرة القرار من العقدة العليا - الجذر ، ثم ينزل إلى أسفل الشجرة. في كل عقدة ، تحتاج إلى إجابة السؤال "نعم" أو "لا". على سبيل المثال ، يسأل الرسم التوضيحي السابق: "هل مبنى EUI أقل من أو يساوي 68.95؟" إذا كانت الإجابة بنعم ، تنتقل الخوارزمية إلى العقدة الفرعية اليمنى ، إذا لم تكن كذلك ، ثم إلى اليسار.
يتم تكرار هذا الإجراء على كل طبقة من الشجرة حتى تصل الخوارزمية إلى عقدة الورقة في الطبقة الأخيرة (لا تظهر هذه العقد في الرسم التوضيحي مع الشجرة المصغرة). القيمة المتوقعة لأي بُعد في ورقة العمل هي
value . إذا جاءت عدة قياسات إلى الورقة ، فسيحصل كل منها على نفس التوقعات. مع زيادة عمق الشجرة ، سينخفض الخطأ في بيانات التدريب ، حيث سيكون هناك المزيد من الأوراق وسيتم تقسيم العينات بعناية أكبر. ومع ذلك ، فإن شجرة عميقة جدًا ستؤدي إلى
إعادة التدريب على بيانات التدريب ولن تكون قادرة على تعميم بيانات الاختبار.
في
المقالة الثانية ، قمنا بإعداد عدد معلمات النموذج الفائقة التي تتحكم في كل شجرة ، على سبيل المثال ، أقصى عمق للشجرة والحد الأدنى لعدد العينات اللازمة لكل ورقة. تؤثر هاتان المعلمتان بشدة على التوازن بين التعلم الزائد وقلة التعلم ، وسيتيح لنا تصور شجرة القرار فهم كيفية عمل هذه الإعدادات.
على الرغم من أننا لا نستطيع دراسة جميع الأشجار في النموذج ، إلا أن تحليل إحداها سيساعد على فهم كيفية توقع كل "طالب". هذه الطريقة المستندة إلى مخطط التدفق تشبه إلى حد كبير كيفية اتخاذ الشخص للقرار. تجمع مجموعات
أشجار القرار بين التوقعات للعديد من الأشجار الفردية ، مما يسمح لك بإنشاء نماذج أكثر دقة بأقل قدر من التباين. هذه الفرق
دقيقة للغاية ويسهل شرحها.
تفسيرات تابعة لنموذج محلي قابل للتفسير (ليمي)
الأداة الأخيرة التي يمكنك من خلالها محاولة معرفة كيف "يفكر" نموذجنا. يتيح لك LIME شرح
كيفية إنشاء توقعات فردية لأي نموذج لتعلم الآلة . للقيام بذلك ، محليًا ، بجوار بعض القياس ، يتم إنشاء نموذج مبسط على أساس نموذج بسيط مثل الانحدار الخطي (يتم وصف التفاصيل في هذا العمل:
https://arxiv.org/pdf/1602.04938.pdf ).
سنستخدم طريقة LIME لدراسة التوقعات الخاطئة تمامًا لنموذجنا وفهم سبب خطأها.
أولاً نجد هذه التوقعات غير الصحيحة. للقيام بذلك ، سوف نقوم بتدريب النموذج ، وتوليد توقعات وتحديد القيمة مع أكبر خطأ:
from sklearn.ensemble import GradientBoostingRegressor
التنبؤ: 12.8615
القيمة الفعلية: 100.0000ثم ننشئ مُفسِّرًا ونمنحه بيانات التدريب ومعلومات الوضع والعلامات الخاصة ببيانات التدريب وأسماء السمات. من الممكن الآن نقل بيانات المراقبة ووظيفة التنبؤ إلى المُفسِّر ، ثم اطلب منهم شرح سبب خطأ التنبؤ.
import lime
مخطط شرح التوقعات:
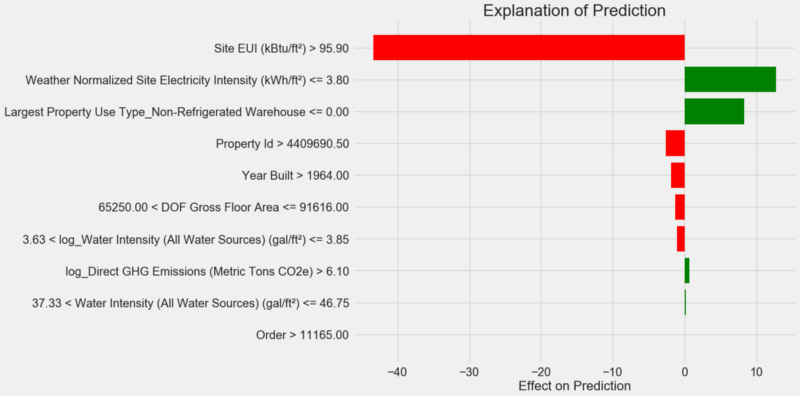
كيفية تفسير الرسم التخطيطي: يشير كل سجل على المحور ص إلى قيمة واحدة للمتغير ، وتعكس الأشرطة الحمراء والخضراء تأثير هذه القيمة على التوقعات. على سبيل المثال ، وفقًا للسجل العلوي ، فإن تأثير
Site EUI يزيد عن 95.90 ، ونتيجة لذلك ، يتم طرح حوالي 40 نقطة من التوقعات. وفقًا للسجل الثاني ، فإن تأثير
Weather Normalized Site Electricity Intensity أقل من 3.80 ، وبالتالي يتم إضافة حوالي 10 نقاط إلى التوقعات. التوقعات النهائية هي مجموع التقاطع وتأثيرات كل من القيم المدرجة.
لنلق نظرة عليه بالطريقة الأخرى وندعو طريقة
.show_in_notebook() :

تظهر عملية اتخاذ القرار من قبل النموذج على اليسار: يتم عرض التأثير على توقعات كل متغير بشكل مرئي. يوضح الجدول على اليمين القيم الفعلية للمتغيرات لقياس معين.
في هذه الحالة ، توقع النموذج حوالي 12 نقطة ، لكنه في الواقع كان 100. في البداية قد تتساءل عن سبب حدوث ذلك ، ولكن إذا قمت بتحليل التفسير ، اتضح أن هذا ليس افتراضًا جريئًا للغاية ، ولكن نتيجة الحساب تستند إلى قيم محددة.
Site EUI مرتفعًا نسبيًا ويمكن للمرء أن يتوقع درجة نجمة طاقة منخفضة (لأنه يتأثر بشدة بـ EUI) ، وهو ما فعله نموذجنا. ولكن في هذه الحالة ، تبين أن هذا المنطق خاطئ ، لأنه في الواقع حصل المبنى على أعلى نتيجة لنجم إنيرجي - 100.
يمكن أن تزعجك أخطاء النموذج ، لكن مثل هذه التفسيرات ستساعدك على فهم سبب خطأ النموذج. علاوة على ذلك ، وبفضل التفسيرات ، يمكنك البدء في اكتشاف سبب حصول المبنى على أعلى الدرجات على الرغم من ارتفاع موقع EUI. ربما سنتعلم شيئًا جديدًا حول مهمتنا يراعي انتباهنا إذا لم نبدأ في تحليل أخطاء النموذج. هذه الأدوات ليست مثالية ، ولكنها يمكن أن تسهل إلى حد كبير فهم النموذج
واتخاذ قرارات أفضل .
توثيق العمل وعرض النتائج
العديد من المشاريع لا تولي اهتماما كبيرا للوثائق والتقارير. يمكنك إجراء أفضل تحليل في العالم ، ولكن إذا لم
تقدم النتائج بشكل صحيح ، فلن يهم!
من خلال توثيق مشروع تحليل البيانات ، نقوم بتعبئة جميع إصدارات البيانات والرمز حتى يتمكن الآخرون من إعادة إنتاج أو جمع المشروع. تذكر أن الرمز يقرأ في كثير من الأحيان أكثر من كتابته ، لذلك يجب أن يكون عملنا واضحًا للآخرين ، ولنا ، إذا عدنا إليه في غضون بضعة أشهر. لذلك ، أدخل تعليقات مفيدة في التعليمات البرمجية واشرح قراراتك.
Jupyter Notebooks هي أداة رائعة للتوثيق ؛ فهي تتيح لك شرح الحلول أولاً ثم إظهار الكود.
أيضًا ، يعد Jupyter Notebook منصة جيدة للتفاعل مع المتخصصين الآخرين. باستخدام
ملحقات أجهزة الكمبيوتر المحمولة ، يمكنك
إخفاء الرمز من التقرير النهائي ، لأنه بغض النظر عن مدى صعوبة الاعتقاد ، لا يرغب الجميع في رؤية مجموعة من التعليمات البرمجية في المستند!
قد لا ترغب في الضغط ، ولكن اعرض جميع التفاصيل. ومع ذلك ، من المهم
فهم جمهورك عند تقديم مشروعك
وإعداد تقرير وفقًا لذلك . فيما يلي مثال لملخص جوهر مشروعنا:
- باستخدام البيانات المتعلقة باستهلاك الطاقة في المباني في نيويورك ، يمكنك بناء نموذج يتنبأ بعدد نقاط إنرجي ستار بخطأ يبلغ 9.1 نقاط.
- موقع EUI وكثافة الطقس العادية للكهرباء هي العوامل الرئيسية التي تؤثر على التوقعات.
كتبنا وصفًا تفصيليًا واستنتاجات في دفتر ملاحظات Jupyter ، ولكن بدلاً من PDF ، قمنا بتحويل ملف .tex إلى
Latex ، ثم قمنا بتحريره في
texStudio ،
وتم تحويل
النسخة الناتجة إلى PDF. والحقيقة هي أن نتيجة التصدير الافتراضية من Jupyter إلى PDF تبدو جيدة جدًا ، ولكن يمكن تحسينها بشكل كبير في بضع دقائق فقط من التحرير. بالإضافة إلى ذلك ، يعد Latex نظامًا قويًا لإعداد المستندات من المفيد امتلاكه.
في النهاية ، يتم تحديد قيمة عملنا من خلال القرارات التي تساعد على اتخاذها ، ومن المهم جدًا أن تكون قادرًا على "توصيل البضائع شخصيًا". من خلال التوثيق الصحيح ، نساعد الآخرين على إعادة إنتاج نتائجنا وإعطائنا ملاحظات ، مما سيتيح لنا أن نصبح أكثر خبرة ويعتمدون على النتائج التي تم الحصول عليها في المستقبل.
الاستنتاجات
في سلسلة منشوراتنا ، قمنا بتغطية برنامج تعليمي للتعلم الآلي من البداية إلى النهاية. بدأنا بمسح البيانات ، ثم أنشأنا نموذجًا ، وفي النهاية تعلمنا كيفية تفسيره. تذكر الهيكل العام لمشروع التعلم الآلي:
- تنظيف وتنسيق البيانات.
- تحليل البيانات الاستكشافية.
- تصميم واختيار الميزات.
- مقارنة مقاييس العديد من نماذج التعلم الآلي.
- ضبط أفضل من المعلمات.
- تقييم أفضل نموذج في مجموعة بيانات الاختبار.
- تفسير نتائج النموذج.
- الاستنتاجات وتقرير موثق جيدًا.
قد تختلف مجموعة الخطوات اعتمادًا على المشروع ، وغالبًا ما يكون التعلم الآلي تكراريًا وليس خطيًا ، لذلك سيساعدك هذا الدليل في المستقبل. نأمل أن تتمكن الآن من تنفيذ مشاريعك بثقة ، ولكن تذكر: لا أحد يعمل بمفرده! إذا كنت بحاجة إلى المساعدة ، فهناك العديد من المجتمعات المفيدة جدًا حيث سيتم تقديم المشورة لك.
يمكن أن تساعدك هذه المصادر: