مرحبا يا هبر! أقدم لكم ترجمة مقالة "تدريب شبكتك العصبية الأولى: التصنيف الأساسي" .

هذا هو دليل تدريب نموذج الشبكة العصبية لتصنيف صور الملابس مثل الأحذية الرياضية والقمصان. لإنشاء شبكة عصبية ، نستخدم python ومكتبة TensorFlow.
قم بتثبيت TensorFlow
للعمل ، نحن بحاجة إلى المكتبات التالية:
- numpy (في سطر الأوامر الذي نكتبه: pip تثبيت numpy)
- matplotlib (في سطر الأوامر الذي نكتبه: تثبيت pip matplotlib)
- keras (في سطر الأوامر نكتب: pip install keras)
- jupyter (في سطر الأوامر نكتب: pip تثبيت jupyter)
باستخدام pip: في سطر الأوامر ، اكتب tensorflow
إذا تلقيت خطأ ، فيمكنك تنزيل ملف .whl وتثبيته باستخدام pip: pip install file_path \ file_name.whl
دليل التثبيت الرسمي لـ TensorFlow
قم بتشغيل Jupyter. للبدء في سطر الأوامر ، اكتب مفكرة jupyter.
الشروع في العمل
يستخدم هذا الدليل مجموعة بيانات Fashion MNIST ، والتي تحتوي على 70،000 صورة ذات درجات رمادية في 10 فئات. تُظهر الصور عناصر فردية من الملابس بدقة منخفضة (28 × 28 بكسل):

سنستخدم 60،000 صورة لتدريب الشبكة و 10،000 صورة لتقييم مدى دقة تعلم الشبكة لتصنيف الصور. يمكنك الوصول إلى Fashion MNIST مباشرة من TensorFlow بمجرد استيراد البيانات وتنزيلها:
fashion_mnist = keras.datasets.fashion_mnist (train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
تحميل مجموعة بيانات يُرجع أربعة صفائف NumPy:
- صفائف train_images و train_labels هي البيانات التي يستخدمها النموذج للتدريب
- يتم استخدام صفائف test_images و test_labels لاختبار النموذج.
الصور عبارة عن مصفوفات 28x28 NumPy تتراوح قيم البكسل من 0 إلى 255. التسميات عبارة عن مجموعة من الأعداد الصحيحة من 0 إلى 9. وهي تتوافق مع فئة الملابس:
| التسمية | فئة |
| 0 | تي شيرت (تي شيرت) |
| 1 | بنطلون (بنطلون) |
| 2 | كنزة صوفية (سترة) |
| 3 | فستان |
| 4 | معطف (معطف) |
| 5 | صندل |
| 6 | قميص |
| 7 | حذاء رياضة (حذاء رياضي) |
| 8 | حقيبة |
| 9 | جزمة الكاحل (أحذية الكاحل) |
لا يتم تضمين أسماء الفئات في مجموعة البيانات ، لذلك فنحن نصفها بأنفسنا:
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
استكشاف البيانات
ضع في اعتبارك تنسيق مجموعة البيانات قبل تدريب النموذج.
train_images.shape
معالجة البيانات
قبل إعداد النموذج ، يجب معالجة البيانات مسبقًا. إذا تحققت من الصورة الأولى في مجموعة التدريب ، فسترى أن قيم البكسل تقع في النطاق من 0 إلى 255:
plt.figure() plt.imshow(train_images[0]) plt.colorbar() plt.grid(False)

نقيس هذه القيم إلى نطاق من 0 إلى 1:
train_images = train_images / 255.0 test_images = test_images / 255.0
نعرض أول 25 صورة من مجموعة التدريب ونعرض اسم الفصل تحت كل صورة. تأكد من أن البيانات بالتنسيق الصحيح.
plt.figure(figsize=(10,10)) for i in range(25): plt.subplot(5,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(train_images[i], cmap=plt.cm.binary) plt.xlabel(class_names[train_labels[i]])

بناء نموذجي
يتطلب بناء شبكة عصبية ضبط طبقات النموذج.
الطبقة الأساسية للشبكة العصبية هي الطبقة. يتكون معظم التعلم العميق من الجمع بين طبقات بسيطة. تحتوي معظم الطبقات ، مثل tf.keras.layers.Dense ، على معلمات يتم تعلمها أثناء التدريب.
model = keras.Sequential([ keras.layers.Flatten(input_shape=(28, 28)), keras.layers.Dense(128, activation=tf.nn.relu), keras.layers.Dense(10, activation=tf.nn.softmax) ])
الطبقة الأولى في الشبكة tf.keras.layers.Flatten تحول تنسيق الصورة من مصفوفة ثنائية الأبعاد (28 × 28 بكسل) إلى مصفوفة ثنائية الأبعاد من 28 * 28 = 784 بكسل. لا تحتوي هذه الطبقة على معلمات للدراسة ، فهي تعيد تنسيق البيانات فقط.
الطبقتان التاليتان هما tf.keras.layers.Dense. هذه طبقات عصبية متصلة بشكل وثيق أو متصلة بالكامل. تحتوي الطبقة الكثيفة الأولى على 128 عقدة (أو خلايا عصبية). المستوى الثاني (والأخير) هو طبقة تحتوي على 10 عقد tf.nn.softmax ، والتي تُرجع مصفوفة من عشرة تقديرات احتمالية ، مجموعها 1. تحتوي كل عقدة على تقدير يشير إلى احتمال أن الصورة الحالية تنتمي إلى واحدة من 10 فئات.
تجميع نموذج
قبل أن يصبح النموذج جاهزًا للتدريب ، سيحتاج إلى بعض الإعدادات الإضافية. تتم إضافتها خلال مرحلة تجميع النموذج:
- وظيفة الخسارة - تقيس مدى دقة النموذج أثناء التدريب
- المُحسِّن هو كيفية تحديث النموذج بناءً على البيانات التي يراها ووظيفة الخسارة.
- المقاييس (المقاييس) - تستخدم للتحكم في مراحل التدريب والاختبار
model.compile(optimizer=tf.train.AdamOptimizer(), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
تدريب نموذجي
يتطلب تعلم نموذج الشبكة العصبية الخطوات التالية:
- تقديم بيانات التدريب النموذجية (في هذا المثال ، صفائف train_images و train_labels)
- يتعلم النموذج ربط الصور والعلامات.
- نطلب من النموذج عمل تنبؤات حول مجموعة الاختبار (في هذا المثال ، المصفوفة test_images). نتحقق من مطابقة توقعات الملصقات من مصفوفة الملصقات (في هذا المثال ، مصفوفة test_labels)
لبدء التدريب ، اتصل بالطريقة model.fit:
model.fit(train_images, train_labels, epochs=5)
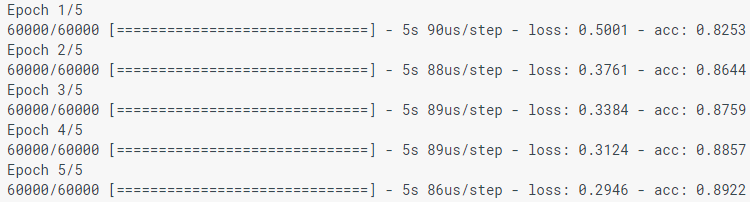
عند نمذجة النموذج ، يتم عرض مؤشرات الخسارة (الخسارة) والدقة (acc). يحقق هذا النموذج دقة تبلغ حوالي 0.88 (أو 88٪) وفقًا لبيانات التدريب.
تصنيف الدقة
قارن كيفية عمل النموذج في مجموعة بيانات اختبار:
test_loss, test_acc = model.evaluate(test_images, test_labels) print('Test accuracy:', test_acc)

وتبين أن الدقة في مجموعة بيانات الاختبار أقل بقليل من الدقة في مجموعة بيانات التدريب. هذه الفجوة بين دقة التدريب ودقة الاختبار هي مثال على إعادة التدريب. إعادة التدريب هو عندما يعمل نموذج التعلم الآلي بشكل أسوأ مع البيانات الجديدة من البيانات التدريبية.
التنبؤ
نستخدم النموذج للتنبؤ ببعض الصور.
predictions = model.predict(test_images)
هنا ، توقع النموذج التسمية لكل صورة في حالة الاختبار. دعونا نلقي نظرة على التنبؤ الأول:
predictions[0]

التوقع عبارة عن مصفوفة من 10 أرقام. يصفون "ثقة" النموذج بأن الصورة تتوافق مع كل قطعة من الملابس العشرة المختلفة. يمكننا أن نرى أي تصنيف له أعلى قيمة ثقة:
np.argmax(predictions[0])
وبالتالي ، فإن النموذج أكثر ثقة في أن هذه الصورة هي التمهيد الكاحل (أحذية الكاحل) ، أو class_names [9]. ويمكننا التحقق من ملصق الاختبار للتأكد من صحة ذلك:
test_labels[0]
سنكتب وظائف لتصور هذه التنبؤات.
def plot_image(i, predictions_array, true_label, img): predictions_array, true_label, img = predictions_array[i], true_label[i], img[i] plt.grid(False) plt.xticks([]) plt.yticks([]) plt.imshow(img, cmap=plt.cm.binary) predicted_label = np.argmax(predictions_array) if predicted_label == true_label: color = 'blue' else: color = 'red' plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label], 100*np.max(predictions_array), class_names[true_label]), color=color) def plot_value_array(i, predictions_array, true_label): predictions_array, true_label = predictions_array[i], true_label[i] plt.grid(False) plt.xticks([]) plt.yticks([]) thisplot = plt.bar(range(10), predictions_array, color="#777777") plt.ylim([0, 1]) predicted_label = np.argmax(predictions_array) thisplot[predicted_label].set_color('red') thisplot[true_label].set_color('blue')
لنلق نظرة على الصورة والتنبؤات ومجموعة من التنبؤات.
i = 0 plt.figure(figsize=(6,3)) plt.subplot(1,2,1) plot_image(i, predictions, test_labels, test_images) plt.subplot(1,2,2) plot_value_array(i, predictions, test_labels)

دعونا نبني بعض الصور مع توقعاتهم. تسميات التوقعات الصحيحة باللون الأزرق ، وتسميات التوقعات غير الصحيحة حمراء. يرجى ملاحظة أن هذا قد يكون خاطئًا حتى عندما يكون واثقًا جدًا.
num_rows = 5 num_cols = 3 num_images = num_rows*num_cols plt.figure(figsize=(2*2*num_cols, 2*num_rows)) for i in range(num_images): plt.subplot(num_rows, 2*num_cols, 2*i+1) plot_image(i, predictions, test_labels, test_images) plt.subplot(num_rows, 2*num_cols, 2*i+2) plot_value_array(i, predictions, test_labels)

أخيرًا ، نستخدم نموذجًا مدربًا للتنبؤ بصورة واحدة.
تم تحسين نماذج Tf.keras لعمل تنبؤات للحزم (المجموعة) أو المجموعات (المجموعة). لذلك ، على الرغم من أننا نستخدم صورة واحدة ، نحتاج إلى إضافتها إلى القائمة:
توقعات الصورة:
predictions_single = model.predict(img) print(predictions_single)

plot_value_array(0, predictions_single, test_labels) _ = plt.xticks(range(10), class_names, rotation=45)

np.argmax(predictions_single[0])
كما كان من قبل ، يتوقع النموذج التسمية 9.
إذا كانت لديك أسئلة ، فاكتب في التعليقات أو في الرسائل الخاصة.