إن تطوير شبكات عصبية عميقة للتعرف على الصور يبعث حياة جديدة في مجالات البحث المعروفة بالفعل في التعلم الآلي. أحد هذه المجالات هو التكيف مع المجال. جوهر هذا التكيف هو تدريب النموذج على البيانات من المجال المصدر (المجال المصدر) بحيث يظهر جودة قابلة للمقارنة على المجال المستهدف (المجال الهدف). على سبيل المثال ، يمكن أن يكون مجال المصدر بيانات اصطناعية يمكن إنشاؤها بثمن زهيد ، ويمكن أن يكون المجال المستهدف صور المستخدم. ثم تتمثل مهمة تكييف المجال في تدريب النموذج على البيانات الاصطناعية ، والتي ستعمل بشكل جيد مع الكائنات "الحقيقية".
في مجموعة Vision Vision ، نحن نعمل على حل المشاكل التطبيقية المختلفة ، ومن بينها غالبًا ما يكون هناك القليل من البيانات التدريبية. في هذه الحالات ، يمكن أن يساعد توليد البيانات الاصطناعية وتكييف النموذج المدرب عليها بشكل كبير. مثال جيد على هذا النهج هو مهمة الكشف عن البضائع على الرفوف في المتجر والتعرف عليها. إن الحصول على صور لهذه الرفوف وترميزها أمر شاق إلى حد ما ، ولكن يمكن إنشاؤها ببساطة. لذلك ، قررنا الخوض في مزيد من التعمق في موضوع التكيف مع المجال.

تؤثر الدراسات في مجال التكيف على استخدام الخبرة السابقة التي اكتسبتها الشبكة العصبية في مهمة جديدة. هل ستكون الشبكة قادرة على استخراج بعض الميزات من المجال المصدر واستخدامها في المجال المستهدف؟ على الرغم من أن الشبكة العصبية في التعلم الآلي ترتبط فقط بعيدًا بالشبكات العصبية في الدماغ البشري ، ومع ذلك ، فإن الكأس المقدسة للباحثين في الذكاء الاصطناعي هي تعليم الشبكات العصبية الإمكانيات التي يمتلكها الشخص. والناس قادرون على استخدام الخبرة السابقة والمعرفة المتراكمة لفهم مفاهيم جديدة.
بالإضافة إلى ذلك ، يمكن أن يساعد تكييف المجال في حل إحدى المشاكل الأساسية للتعلم العميق: لتدريب الشبكات الكبيرة بجودة التعرف العالية ، هناك حاجة إلى كمية كبيرة جدًا من البيانات ، والتي لا تتوفر دائمًا في الواقع. قد يكون أحد الحلول هو استخدام طرق تكيف المجال على البيانات الاصطناعية التي يمكن إنشاؤها بكميات غير محدودة تقريبًا.
في كثير من الأحيان في المشاكل التطبيقية هناك حالة حيث تتوفر البيانات من مجال واحد فقط للتدريب ، ويجب تطبيق النموذج على مجال آخر. على سبيل المثال ، يمكن تدريب الشبكة التي تحدد الجودة الجمالية للتصوير الفوتوغرافي على قاعدة بيانات متاحة على الشبكة ، تم جمعها من موقع الهواة. ومن المخطط استخدام هذه الشبكة في صور عادية ، يختلف مستوى جودتها في المتوسط عن مستوى صورة من موقع صور متخصص. كحل ، يمكننا التفكير في تكييف النموذج مع الصور الفوتوغرافية العادية غير المصنفة.
تكمن هذه الأسئلة النظرية والتطبيقية في مجال التكيف. في هذه المقالة ، سأتحدث عن البحث الرئيسي في هذا المجال ، بناءً على التعلم العميق ، ومجموعات البيانات لمقارنة الطرق المختلفة. الفكرة الرئيسية للتكيف في النطاق العميق هي تدريب شبكة عصبية عميقة على المجال المصدر ، والتي ستترجم الصورة إلى مثل هذا التضمين (عادة الطبقة الأخيرة من الشبكة) التي عند استخدامها في المجال المستهدف ، سيتم الحصول على جودة عالية.
المعايير الأساسية
كما هو الحال في أي مجال من مجالات التعلم الآلي ، يتم تجميع قدر معين من البحث في تكييف المجال بمرور الوقت ، والتي يجب مقارنتها مع بعضها البعض. لهذا ، يقوم المجتمع بتطوير مجموعات البيانات ، على الجزء التدريبي الذي يتم تدريب النماذج منه ، وعلى جزء الاختبار الذي تتم مقارنته. على الرغم من حقيقة أن مجال البحث للتكيف في النطاق العميق لا يزال صغيرًا نسبيًا ، إلا أن هناك بالفعل عددًا كبيرًا إلى حد ما من المقالات وقواعد البيانات التي يتم استخدامها في هذه المقالات. وسأذكر أهمها ، مع التركيز على تكييف مجال البيانات الاصطناعية مع "حقيقي".
أرقام
على ما يبدو ، وفقًا للتقاليد التي أنشأها Yann LeCun (أحد رواد التعلم العميق ، مدير Facebook AI Research) ، في رؤية الكمبيوتر ، ترتبط أبسط مجموعات البيانات بأرقام أو أحرف مكتوبة بخط اليد. هناك العديد من مجموعات البيانات ذات الأرقام التي ظهرت أصلاً للتجربة مع نماذج التعرف على الصور. في المقالات حول التكيف مع المجال ، يمكن للمرء أن يجد مجموعة متنوعة من مجموعاتها في أزواج المجال المصدر والهدف. من بين مجموعات البيانات هذه:
- MNIST - أرقام مكتوبة بخط اليد ، لا تحتاج إلى عرض إضافي ؛
- USPS - الأرقام المكتوبة بخط اليد بدقة منخفضة ؛
- SVHN - أرقام المنازل باستخدام Google Street View ؛
- أرقام المركب هي أرقام اصطناعية ، كما يوحي الاسم.
من وجهة نظر مهمة التدريب على البيانات الاصطناعية لاستخدامها في العالم "الحقيقي" ، الأكثر إثارة للاهتمام هي الأزواج:
- المصدر: MNIST ، الهدف: SVHN ؛
- المصدر: USPS ، الهدف: MNIST؛
- المصدر: أرقام مركبة ، الهدف: SVHN.

معظم الأساليب لديها معايير على مجموعات البيانات "الرقمية". ولكن يمكن العثور على الأنواع الأخرى من المجالات في جميع المقالات.
مكتب
تحتوي مجموعة البيانات هذه على 31 فئة من العناصر المختلفة ، يتم تمثيل كل منها في 3 نطاقات: صورة من أمازون وصورة من كاميرا ويب وصورة من كاميرا رقمية.

من المفيد التحقق من كيفية استجابة النموذج لإضافة الخلفية والجودة إلى المجال الهدف.
إشارات المرور
زوج آخر من مجموعات البيانات لتدريب النموذج على البيانات الاصطناعية وتطبيقه على البيانات "الحقيقية":
- المصدر: إشارات موالفة - صور لافتات الطرق التي تم إنشاؤها بحيث تبدو كعلامات حقيقية في الشارع ؛
- الهدف: GTSRB هي قاعدة التعرف المعروفة إلى حد ما تحتوي على لافتات من الطرق الألمانية.

ميزة هذا الزوج من قواعد البيانات هي أن البيانات من Synth Signs تكون مشابهة تمامًا للبيانات "الحقيقية" ، لذا فإن المجالات قريبة جدًا.
من نافذة السيارة
مجموعات البيانات للتجزئة. زوجان مثيران للاهتمام ، الأقرب إلى الظروف الحقيقية. يتم الحصول على البيانات المصدر باستخدام محرك اللعبة (GTA 5) ، والبيانات المستهدفة من واقع الحياة. يتم استخدام أساليب مماثلة لتدريب النماذج المستخدمة في السيارات المستقلة.

VisDA
تُستخدم مجموعة البيانات هذه في تحدي التكيف مع المجال المرئي ، والذي يعد جزءًا من ورشة عمل حول ECCV و ICCV. يحتوي المجال المصدر على 12 فئة من الكائنات المصنفة التي تم إنشاؤها باستخدام CAD ، مثل طائرة أو حصان أو شخص ، إلخ. يحتوي المجال المستهدف على صور غير مسماة من نفس الفئات الـ 12 المأخوذة من ImageNet. في المسابقة التي أقيمت عام 2018 تم إضافة الفئة الثالثة عشر: غير معروف.
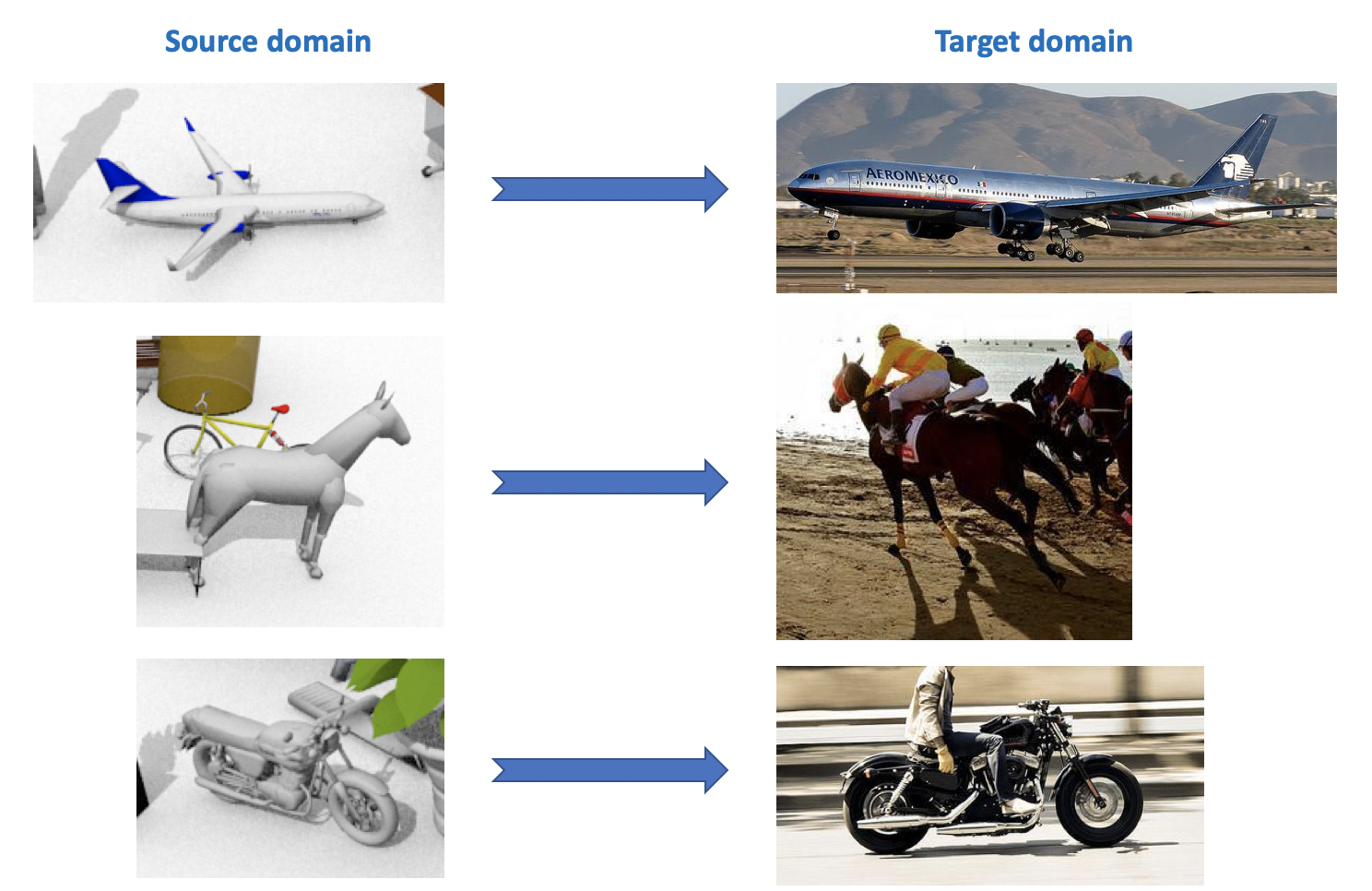
كما ترى من كل ما سبق ، هناك الكثير من مجموعات البيانات المثيرة للاهتمام والمتنوعة لتكييف المجال ، يمكنك تدريب واختبار نماذج لها لمختلف المهام (التصنيف ، التصنيف ، الكشف) وظروف مختلفة (البيانات الاصطناعية ، الصور ، طرق عرض الشوارع).
تكيف المجال العميق
هناك تصنيف واسع ومتنوع إلى حد ما لطرق تكييف المجال (على سبيل المثال ، انظر هنا ). سأقدم في هذه المقالة تقسيمًا مبسطًا للطرق وفقًا لسماتهم الرئيسية. يمكن تقسيم الأساليب الحديثة للتكيف في المجال العميق إلى 3 مجموعات كبيرة:
- القائم على التناقض : المقاربات القائمة على تقليل المسافة بين تمثيلات المتجه على نطاقات المصدر والهدف عن طريق إدخال هذه المسافة في دالة الخسارة.
- القائم على الخصومة: تستخدم هذه الأساليب وظيفة خسارة الخصومة التي تم تقديمها في شبكات GAN لتدريب شبكة ثابتة النطاق. تم تطوير أساليب هذه الأسرة بنشاط في العامين الماضيين.
- طرق مختلطة لا تستخدم الخسارة العدائية ، ولكنها تطبق أفكارًا من العائلة القائمة على التناقض ، بالإضافة إلى أحدث التطورات من التعلم العميق: التكتل الذاتي ، والطبقات الجديدة ، ووظائف الخسارة ، وما إلى ذلك. تظهر هذه الأساليب أفضل النتائج في مسابقة VisDA.
من كل قسم ، سيتم النظر في العديد من النتائج الأساسية ، في رأيي ، على مدى السنوات 1-3 الماضية.
القائم على التناقض
عندما تنشأ مشكلة تكييف نموذج مع بيانات جديدة ، فإن أول ما يتبادر إلى الذهن هو استخدام الضبط الدقيق ، أي إعادة تدريب النموذج على البيانات الجديدة. للقيام بذلك ، ضع في الاعتبار التناقض بين المجالات. يمكن تقسيم هذا النوع من تكيف المجال إلى ثلاثة مناهج: معيار الصف ، والمعيار الإحصائي ومعيار العمارة.
معيار الفئة
تُستخدم الأساليب من هذه العائلة بشكل أساسي عندما يكون لدينا إمكانية الوصول إلى البيانات التي تم وضع علامة عليها من المجال المستهدف. أحد الخيارات الشائعة لمعيار الفصل الدراسي هو نهج التعلم المتري لمقياس النقل العميق . كما يوحي الاسم ، فإنه يعتمد على التعلم المتري ، وجوهره هو تدريب مثل هذا التمثيل المتجه الذي تم الحصول عليه من شبكة عصبية يكون ممثلو فئة واحدة قريبين من بعضهم البعض في هذا التمثيل وفقًا لمقياس معين (غالبًا ما يستخدمون أو مقاييس جيب التمام). في المقال ، يتم استخدام التعلم المقياسي العميق (DTML) ، خسارة تتكون من مجموع المصطلحات لتنفيذ هذا النهج:
- قرب ممثلي فئة من بعضهم البعض (الدمج داخل الطبقة) ؛
- زيادة المسافة بين ممثلي الفئات المختلفة (قابلية الفصل بين الطبقات) ؛
- قياس الحد الأقصى لمتوسط التباين (MMD) بين المجالات. ينتمي هذا المقياس إلى عائلة المعيار الإحصائي (انظر أدناه) ، ولكنه يستخدم أيضًا في معيار الفئة.
مكتوب MMD بين المجالات كما
أين - هذا جوهر ، في حالتنا - تمثيل متجه للشبكة ، - البيانات من المجال المصدر ، - بيانات من المجال المستهدف. وبالتالي ، عند تصغير مقياس MMD أثناء التدريب ، يتم اختيار هذه الشبكة بحيث يكون متوسط تمثيلات المتجه في كلا المجالين قريبين. الفكرة الرئيسية لـ DTML:
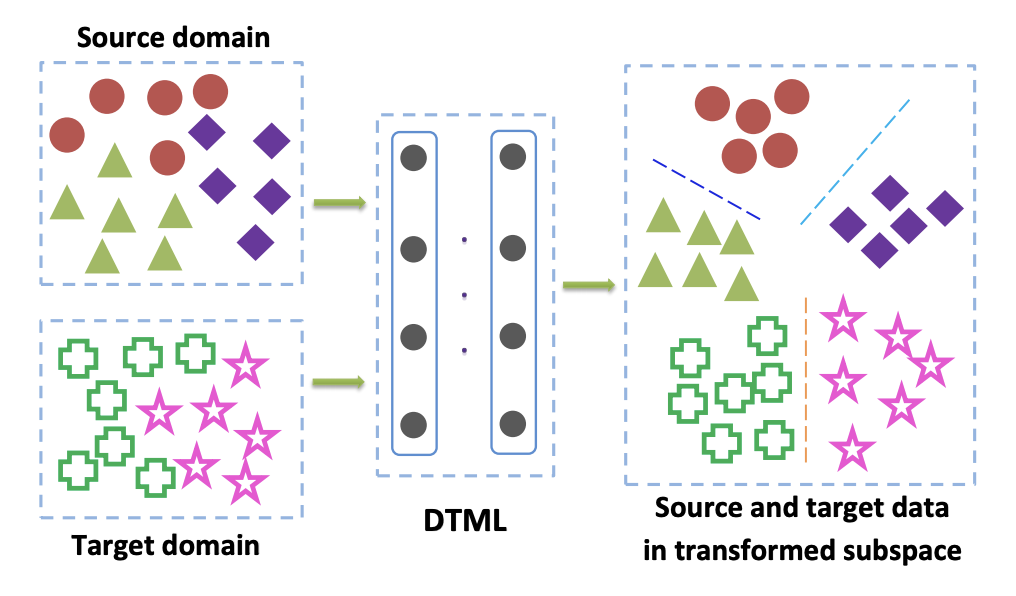
إذا كانت البيانات في المجال المستهدف غير مصنفة (تكيف المجال غير الخاضع للرقابة) ، فإن الطريقة الموضحة في الاعتبار انحياز وزن الصف: التفاوت الأقصى المتوسط المرجح للتكيف غير الخاضع للرقابة يقدم عروض لتدريب النموذج على المجال المصدر واستخدامه للحصول على ملصقات زائفة (زائفة- التسميات) على المجال المستهدف. على سبيل المثال يتم تشغيل البيانات من المجال الهدف من خلال الشبكة وتسمى النتيجة تسميات زائفة. ثم يتم استخدامها كترميز للمجال المستهدف ، مما يسمح بتطبيق معيار MMD في دالة الخسارة (بأوزان مختلفة للمكونات المسؤولة عن المجالات المختلفة).
المعيار الإحصائي
تُستخدم الأساليب المتعلقة بهذه العائلة لحل مشكلة تكيف المجال غير الخاضعة للإشراف. تحدث الحالة عندما يكون المجال المستهدف غير مخصص في العديد من المشاكل ، وجميع طرق تكييف المجال ، والتي سيتم مناقشتها لاحقًا في هذه المقالة ، تحل مثل هذه المشكلة.
تحاول المقاربات القائمة على المعايير الإحصائية قياس الفرق بين توزيعات تمثيل المتجه للشبكة التي تم الحصول عليها من بيانات مجالات المصدر والهدف. ثم يستخدمون الفرق المحسوب لجمع هذين التوزيعين معًا.
أحد هذه المعايير هو الحد الأقصى لمتوسط التباين (MMD) الموصوف أعلاه. يتم استخدام المتغيرات في عدة طرق:
يتم عرض الرسوم البيانية لهذه الطرق الثلاث أدناه. تستخدم فيها متغيرات MMD لتحديد الفرق بين التوزيعات على طبقات الشبكة العصبية التلافيفية المطبقة على نطاقات المصدر والهدف. يرجى ملاحظة أن كل واحد منهم يستخدم تعديل MMD كخسارة بين طبقات شبكات الالتواء (الأشكال الصفراء في الرسم التخطيطي).

يهدف معيار CORAL (محاذاة CORrelation) وتوسيعه بمساعدة شبكات Deep CORAL إلى تعلم مثل هذا التمثيل للبيانات بحيث تتطابق إحصائيات الدرجة الثانية بين المجالات حتى الحد الأقصى. لهذا ، يتم استخدام مصفوفات التغاير لتمثيلات ناقلات الشبكة. إن تقارب إحصائيات الدرجة الثانية في كلا المجالين في بعض الحالات يسمح للمرء بالحصول على نتائج تكيف أفضل من MMD.
أين هو مربع قاعدة مصفوفة Frobenius ، و و - بيانات مصفوفة التباين من المجال المصدر والهدف ، على التوالي ، - بعد تمثيل النواقل.
في مجموعة بيانات Office ، يبلغ متوسط جودة التكيف باستخدام Deep CORAL لأزواج Amazon و Webcam مجالات 72.1٪. في الإشارات المركبة -> نطاقات إشارات الطريق GTSRB ، تكون النتيجة أيضًا متوسطة جدًا: دقة تبلغ 86.9٪ على المجال المستهدف.
إن تطوير أفكار MMD و CORAL هو معيار تناقض اللحظات المركزية (CMD) ، والذي يقارن اللحظات المركزية للبيانات من نطاقات المصدر والهدف لجميع الطلبات حتى ضمنا ( - معلمة الخوارزمية). في مجموعة بيانات Office ، يبلغ متوسط جودة تكيف CMD لأزواج Amazon و Webcam 77.0٪.
معيار العمارة
تعتمد الخوارزميات من هذا النوع على افتراض أن المعلومات الأساسية المسؤولة عن التكيف مع مجال جديد مضمنة في معلمات الشبكة العصبية.
في عدد من الأوراق [1] ، [2] ، عندما يتم تدريب شبكات للمجالات المصدر والهدف باستخدام وظائف الخسارة لكل زوج من الطبقات ، يتم دراسة المعلومات الثابتة فيما يتعلق بالمجال على أوزان هذه الطبقات. يتم إعطاء مثال على مثل هذه المعماريات أدناه.
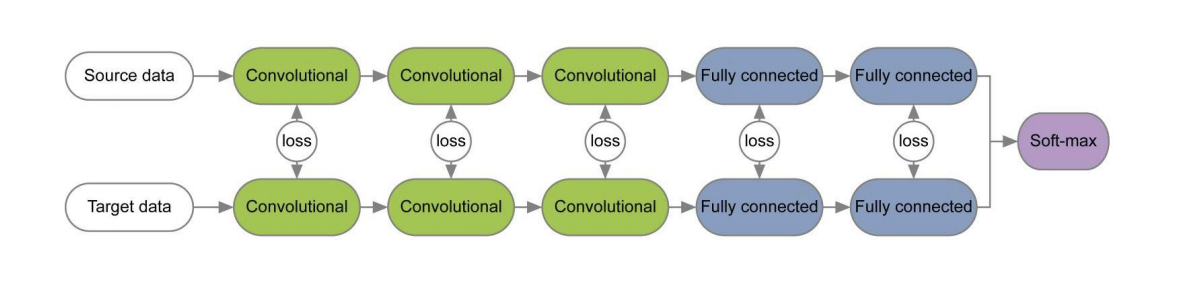
في مقالة " إعادة النظر في تطبيع الدفعة للتكيف العملي للمجال" ، تم طرح فكرة أن مقاييس الشبكة تحتوي على معلومات تتعلق بالفئات التي تدرس عليها الشبكة ، وأن معلومات النطاق مضمنة في الإحصائيات (المتوسط والانحراف المعياري) لطبقات تطبيع الدفعة (BN). لذلك ، من أجل التكيف ، من الضروري إعادة حساب هذه الإحصاءات على البيانات من المجال المستهدف. يمكن أن يؤدي استخدام هذه التقنية مع CORAL إلى تحسين جودة التكيف في مجموعة بيانات Office لأزواج Amazon و Webcam حتى 75.0٪. ثم تبين أن استخدام طبقة تطبيع المثيل (IN) بدلاً من BN يعمل على تحسين جودة التكيف. على عكس BN ، التي تطبيع موتر الإدخال بدُفعة ، تقوم IN بحساب إحصائيات التطبيع بواسطة القنوات ، وبالتالي فهي مستقلة عن الدُفعة.
المناهج القائمة على الخصومة
في السنوات 1-2 الماضية ، ترتبط معظم النتائج في التكيف مع المجال العميق بالنهج القائم على الخصومة. ويرجع ذلك إلى حد كبير إلى التطور السريع وشعبية شبكات الخصومة التوليدية (GAN) ، لأن النهج القائم على الخصومة في التكيف مع المجال يستخدم نفس وظيفة الهدف العدائية في التدريب مثل GAN. من خلال تحسينها ، تقلل طرق تكيف المجال العميقة هذه المسافة بين التوزيعات التجريبية لتمثيل بيانات المتجه على نطاقات المصدر والهدف. من خلال تدريب الشبكة بهذه الطريقة ، يحاولون جعلها ثابتة فيما يتعلق بالنطاق.
يتكون GAN من نموذجين: مولد ، عند إخراج البيانات التي يتم الحصول عليها من توزيع هدف معين ؛ ومميز ، والذي يحدد ما إذا كانت البيانات من مجموعة التدريب أو ولدت باستخدام . يتم تدريب هذين النموذجين باستخدام وظيفة الهدف العدائي:
مع هذا التدريب ، يتعلم المولد "خداع" المميّز ، والذي يسمح لك بتقريب توزيع الهدف ومجالات المصدر.
هناك طريقتان كبيرتان في تكييف المجال القائم على الخصومة تختلف في استخدام المولد أم لا. .
نماذج غير مولدة
السمة الرئيسية للطرق من هذه العائلة هي تدريب شبكة عصبية مع تمثيل متجه ثابت بالنسبة لمجالات المصدر والهدف. ثم يمكن استخدام الشبكة المدربة على مجال المصدر المحدد على المجال المستهدف ، بشكل مثالي - عمليًا دون فقدان جودة التصنيف.
تم تقديمها في عام 2015 ، وتتكون خوارزمية ( رمز ) التدريب على الخصومة من الشبكات العصبية (DANN) من 3 أجزاء:
- الشبكة الرئيسية ، التي يتم من خلالها الحصول على تمثيل ناقل (مستخرج الميزة) (الجزء الأخضر في الرسم التوضيحي أدناه) ؛
- "الرؤساء" المسؤولون عن التصنيف في مجال المصدر (الجزء الأزرق في الرسم التوضيحي) ؛
- "رأس" يتعلم تمييز البيانات من مجال المصدر عن المجال المستهدف (الجزء الأحمر في الرسم التوضيحي).
عند التدريب باستخدام منحدر التدرج (SGD) (أسهم الإدخال في الرسم التوضيحي) ، يتم تقليل خسائر التصنيف والمجال. بالإضافة إلى ذلك ، أثناء الانتشار العكسي لخطأ في التعلم لـ "الرأس" المسؤول عن المجالات ، يتم استخدام طبقة انعكاس التدرج (الجزء الأسود في الرسم التوضيحي) ، مما يضاعف التدرج الذي يمر عبره بواسطة ثابت سلبي ، مما يزيد من فقدان المجال. هذا يضمن أن توزيعات تمثيلات المتجهات في كلا المجالين تصبح قريبة.
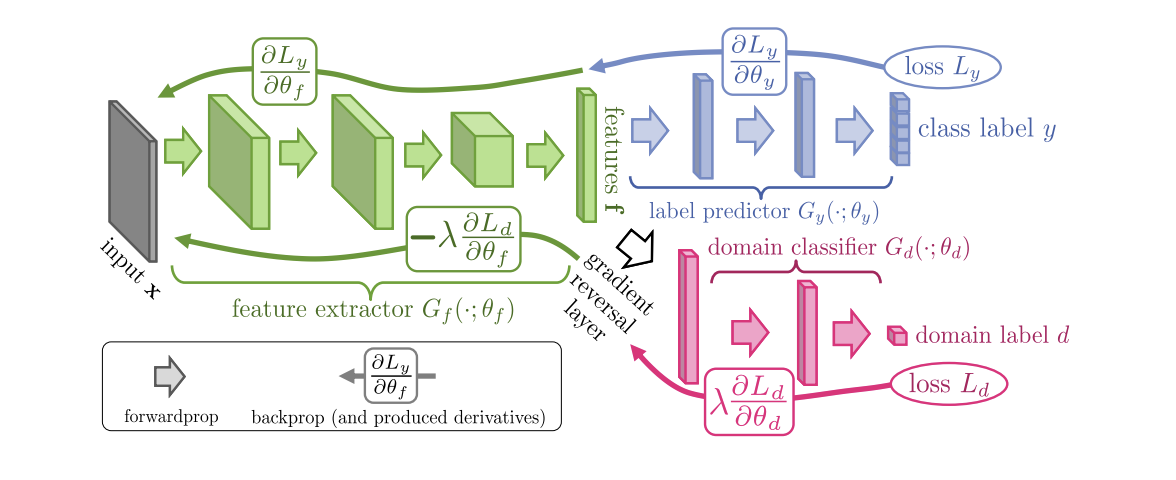
نتائج DANN المرجعية:
- على زوج من المجالات الرقمية أرقام موالفة -> SVHN: 91.09٪.
- على لافتات المركب -> إشارات الطريق GTSRB ، تتجاوز CORAL بنسبة 88.7 ٪.
- في مجموعة بيانات Office ، يبلغ متوسط جودة التكيف لأزواج Amazon و Webcam 73.0٪.
الممثل المهم التالي لعائلة النماذج غير التوليدية هو طريقة التكييف العدائي التمييزي (ADDA) ( رمز ) ، والتي تنطوي على فصل الشبكة للمجال المصدر والشبكة للمجال المستهدف. تتكون الخوارزمية من الخطوات التالية:
- أولاً ، نقوم بتدريب شبكة التصنيف على المجال المصدر. نشير إلى تمثيل ناقلات و - مجال المصدر.
- الآن تهيئة الشبكة العصبية للمجال الهدف باستخدام الشبكة المدربة من الخطوة السابقة. دعها و - المجال المستهدف.
- دعنا ننتقل إلى التدريب العدائي: سوف ندرب المميّز في ثابت و باستخدام الوظيفة الموضوعية التالية:
- تجميد التمييز وإعادة التدريب على المجال المستهدف:
3 4 . ADDA , , adversarial- , . :
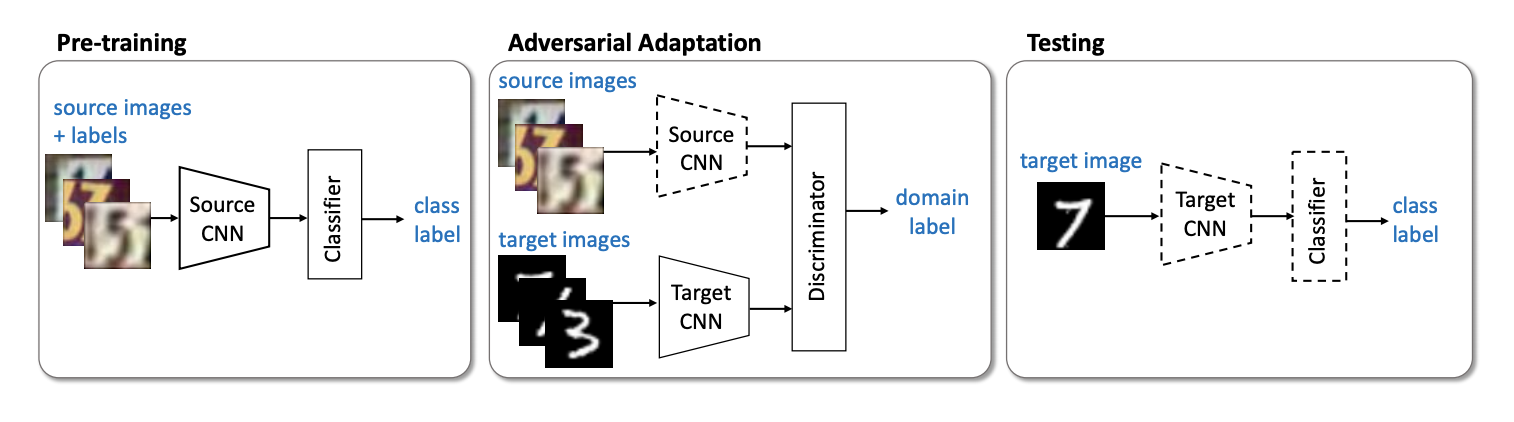
USPS -> MNIST ADDA 90,1 % .
ADDA ICML-2018 M-ADDA: Unsupervised Domain Adaptation with Deep Metric Learning ( ).
, M-ADDA metric learning, -. 1 ADDA - Triplet loss ( ( ) ). , ( — ). .
ADDA, .. 2-4. 4 , , :
.
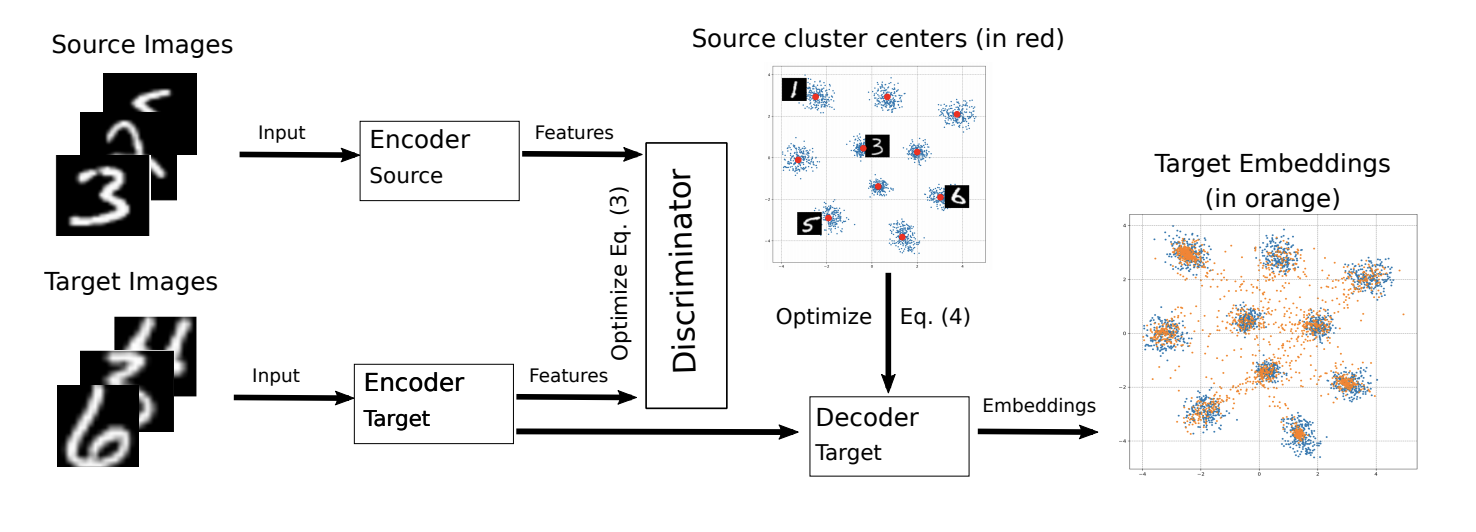
M-ADDA USPS -> MNIST 94,0 %.
non-generative Maximum Classifier Discrepancy for Unsupervised Domain Adaptation ( ). (), . , , .
— , و — , . , ، و -; , ; , ; و .
, adversarial-, , .
(Discrepancy Loss)
— , — softmax - و .
3 :
- أ. ، و .
- ب. , .
- C . , , Discrepancy Loss.
( ). B C:
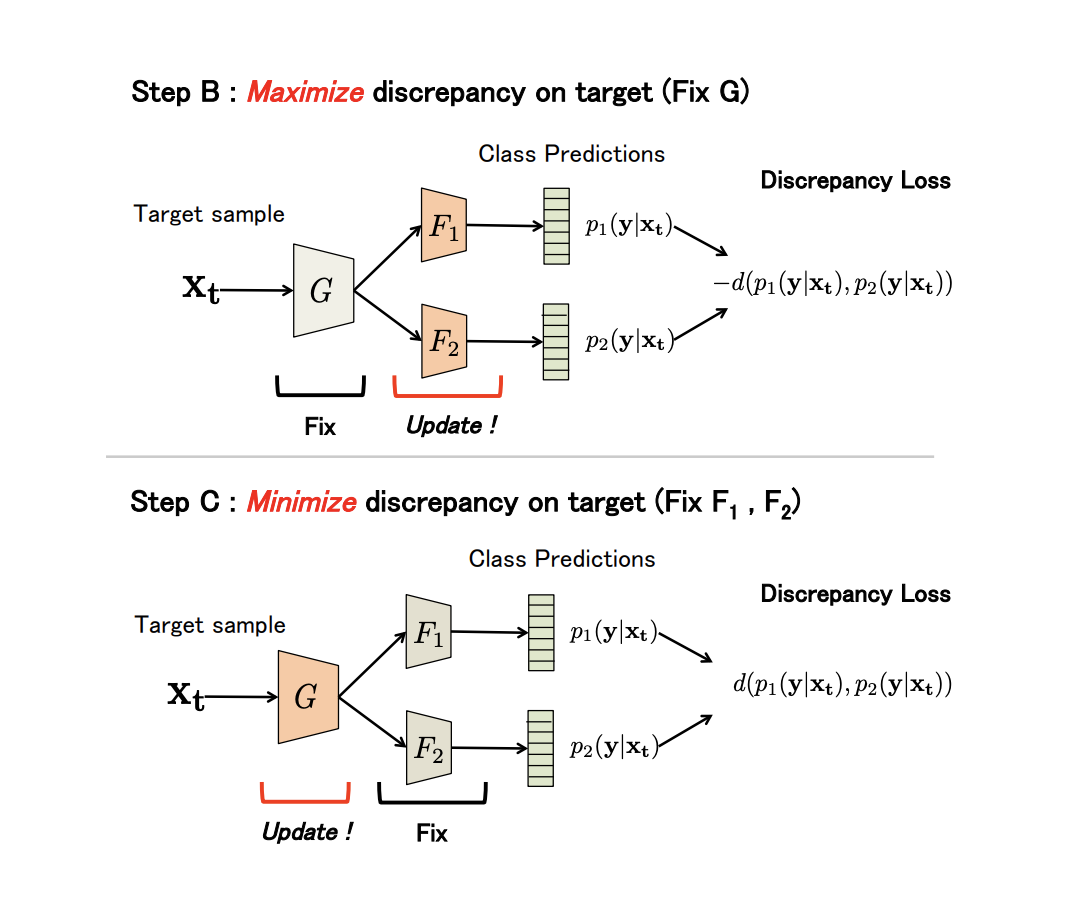
:
- USPS -> MNIST: 94,1 %.
- Synth Signs -> GTSRB : 94,4 %.
- VisDA 12 Unknown: 71,9 %.
- GTA 5 -> Cityscapes: Mean IoU = 39,7 %, Synthia -> Cityscapes: Mean IoU = 37,3 %
non-generative models:
.
لقد درسنا مجموعات البيانات الرئيسية لتكييف المجال ، والمناهج القائمة على التناقض: معيار الفئة ، والمعيار الإحصائي ومعيار العمارة ، وكذلك أول عائلة غير مولدة من الطرق القائمة على الخصومة. تظهر نماذج من هذه الأساليب أداءً جيدًا على المعايير ويمكن تطبيقها على العديد من مهام التكيف. في الجزء التالي ، سننظر في أكثر الأساليب تعقيدًا وفعالية: النماذج التوليدية والأساليب المختلطة غير القائمة على الخصومة.