مرحبا يا هبر! اسمي نيكولاي إيزيكوف ، أعمل لدى Sberbank Technologies في فريق تطوير حلول المصادر المفتوحة. خلف 15 عامًا من التطوير التجاري في جاوة. أنا عضو في Apache Ignite ومساهم في Apache Kafka.
تحت القطة ، ستجد نسخة فيديو ونص من تقريري عن Apache Ignite Meetup حول كيفية استخدام Apache Ignite مع Apache Spark والميزات التي قمنا بتنفيذها لهذا الغرض.
ما يمكن أن يفعله أباتشي سبارك
ما هو أباتشي سبارك؟ هذا منتج يسمح لك بإجراء استعلامات الحوسبة والتحليل الموزعة بسرعة. في الأساس ، تمت كتابة Apache Spark في Scala.
يحتوي Apache Spark على واجهة برمجة تطبيقات غنية للاتصال بأنظمة التخزين المختلفة أو استقبال البيانات. واحدة من ميزات المنتج هي محرك استعلام عالمي يشبه SQL للبيانات المستلمة من مصادر مختلفة. إذا كان لديك العديد من مصادر المعلومات ، فأنت تريد دمجها والحصول على بعض النتائج ، فإن Apache Spark هو ما تحتاجه.
واحدة من التجريدات الرئيسية التي توفرها Spark هي Data Frame و DataSet. من حيث قاعدة البيانات العلائقية ، هذا جدول ، مصدر يوفر البيانات بطريقة منظمة. الهيكل ونوع كل عمود واسمه ، وما إلى ذلك ، معروف. يمكن إنشاء إطارات البيانات من مصادر مختلفة. تتضمن الأمثلة ملفات json وقواعد البيانات العلائقية وأنظمة hadoop المختلفة و Apache Ignite.
يدعم Spark الصلات في استعلامات SQL. يمكنك الجمع بين البيانات من مصادر مختلفة والحصول على نتائج وإجراء استعلامات تحليلية. بالإضافة إلى ذلك ، هناك واجهة برمجة تطبيقات لحفظ البيانات. عند الانتهاء من الاستعلامات ، وإجراء دراسة ، يوفر Spark القدرة على حفظ النتائج إلى جهاز الاستقبال الذي يدعم هذه الميزة ، وبالتالي ، حل مشكلة معالجة البيانات.
ما هي الميزات التي قمنا بتطبيقها لدمج Apache Spark مع Apache Ignite
- قراءة البيانات من جداول Apache Ignite SQL.
- كتابة البيانات على Apache Ignite جداول SQL.
- IgniteCatalog داخل IgniteSparkSession - القدرة على استخدام جميع جداول Ignite SQL الموجودة دون تسجيل "يدويًا".
- تحسين SQL - القدرة على تنفيذ عبارات SQL داخل Ignite.
يمكن لـ Apache Spark قراءة البيانات من Apache Ignite جداول SQL وكتابتها في شكل مثل هذا الجدول. يمكن حفظ أي DataFrame تم تكوينه في Spark كجدول Apache Ignite SQL.
يسمح لك Apache Ignite باستخدام جميع جداول Ignite SQL الموجودة في Spark Session دون تسجيل "يدويًا" - باستخدام IgniteCatalog داخل امتداد SparkSession القياسي - IgniteSparkSession.
هنا تحتاج إلى التعمق أكثر في جهاز Spark. من حيث قاعدة البيانات العادية ، الدليل هو مكان يتم فيه تخزين المعلومات الوصفية: الجداول المتاحة ، والأعمدة الموجودة فيها ، إلخ. عند وصول طلب ، يتم سحب معلومات التعريف من الكتالوج ويقوم مشغل SQL بشيء مع الجداول والبيانات. بشكل افتراضي ، في Spark ، يجب تسجيل جميع جداول القراءة (لا يهم ، من قاعدة بيانات علائقية ، Ignite ، Hadoop) يدويًا في الجلسة. ونتيجة لذلك ، تحصل على فرصة لإجراء استعلام SQL على هذه الجداول. اكتشف سبارك عنهم.
للعمل مع البيانات التي قمنا بتحميلها إلى Ignite ، نحتاج إلى تسجيل الجداول. ولكن بدلاً من تسجيل كل طاولة بأيدينا ، قمنا بتنفيذ القدرة على الوصول تلقائيًا إلى جميع جداول Ignite.
ما هي الميزة هنا؟ لسبب ما لا أعرفه ، فإن الدليل في Spark عبارة عن واجهة برمجة تطبيقات داخلية ، أي لا يمكن لشخص غريب أن يأتي وإنشاء تطبيق الكتالوج الخاص به. وبما أن سبارك خرج من Hadoop ، فإنه يدعم Hive فقط. ويجب عليك تسجيل كل شيء آخر بيديك. غالبًا ما يسأل المستخدمون كيف يمكنك الالتفاف حول هذا وإجراء استعلامات SQL على الفور. لقد قمت بتطبيق دليل يسمح لك بتصفح جداول Ignite والوصول إليها دون تسجيل ~ ورسائل sms ~ ، وقد اقترحت هذا التصحيح في البداية في مجتمع Spark ، والذي تلقيت إجابة عليه: مثل هذا التصحيح غير مثير للاهتمام لبعض الأسباب الداخلية. ولم يعطوا API الداخلي.
يعد كتالوج Ignite الآن ميزة مثيرة للاهتمام يتم تنفيذها باستخدام واجهة برمجة تطبيقات Spark الداخلية. لاستخدام هذا الدليل ، لدينا تنفيذنا الخاص للجلسة. هذا هو SparkSession المعتاد ، الذي يمكنك من خلاله تقديم الطلبات ومعالجة البيانات. الاختلافات هي أننا دمجنا ExternalCatalog فيه للعمل مع جداول Ignite ، بالإضافة إلى IgniteOptimization ، والذي سيتم وصفه أدناه.
تحسين SQL - القدرة على تنفيذ عبارات SQL داخل Ignite. بشكل افتراضي ، عند إجراء الانضمام والتجميع والحساب التجميعي واستعلامات SQL المعقدة الأخرى ، يقرأ Spark البيانات في وضع الصف تلو الآخر. الشيء الوحيد الذي يمكن لمصدر البيانات القيام به هو تصفية الصفوف بكفاءة.
إذا كنت تستخدم الانضمام أو التجميع ، فإن Spark تسحب جميع البيانات من الجدول إلى ذاكرتها للعامل ، باستخدام عوامل التصفية المحددة ، وعندئذ فقط تقوم بتجميعها أو إجراء عمليات SQL أخرى. في حالة Ignite ، ليس هذا هو الأمثل ، لأن Ignite نفسها لديها بنية موزعة ولديها معرفة بالبيانات المخزنة فيها. لذلك ، يمكن لـ Ignite نفسها حساب التجميعات بكفاءة وتنفيذ التجميع. بالإضافة إلى ذلك ، يمكن أن يكون هناك الكثير من البيانات ، ولجمعها ، ستحتاج إلى طرح كل شيء ، ورفع جميع البيانات في Spark ، وهو أمر مكلف للغاية.
يوفر Spark واجهة برمجة تطبيقات يمكنك من خلالها تغيير الخطة الأولية لاستعلام SQL ، وإجراء التحسين وإعادة توجيه جزء استعلام SQL الذي يمكن تنفيذه هناك في Ignite. سيكون هذا فعالًا من حيث السرعة وكذلك استهلاك الذاكرة ، لأننا لن نستخدمه لسحب البيانات التي سيتم تجميعها على الفور.
كيف يعمل
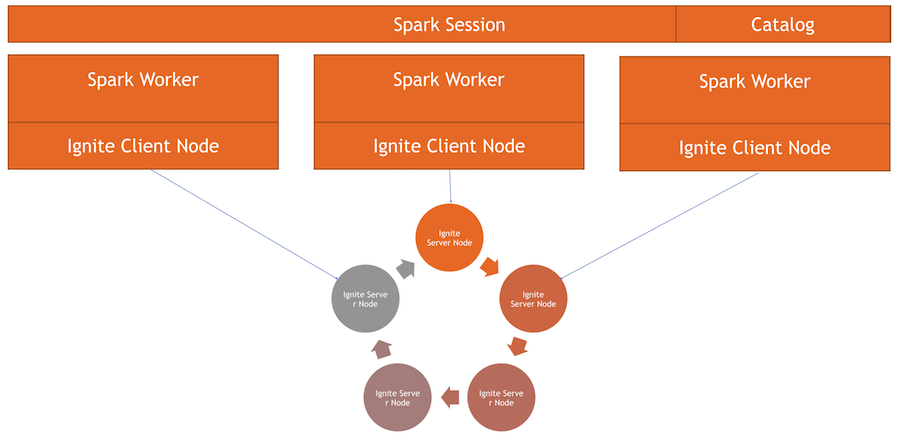
لدينا مجموعة Ignite - هذا هو النصف السفلي من الصورة. لا يوجد Zookeeper ، حيث لا يوجد سوى خمس عقد. هناك عمال شرارة ، داخل كل عامل يتم رفع عقدة عميل إيجنايت. من خلاله ، يمكننا تقديم طلب وقراءة البيانات والتفاعل مع الكتلة. أيضا ، ترتفع عقدة العميل داخل IgniteSparkSession للدليل للعمل.
إشعال إطار البيانات
ننتقل إلى الرمز: كيف تقرأ البيانات من جدول SQL؟ في حالة Spark ، كل شيء بسيط جدًا وجيد: نقول إننا نريد حساب بعض البيانات ، والإشارة إلى التنسيق - هذا ثابت معين. علاوة على ذلك ، لدينا العديد من الخيارات - المسار إلى ملف التكوين لعقدة العميل ، والذي يبدأ عند قراءة البيانات. نشير إلى الجدول الذي نريد قراءته ونطلب من Spark تحميله. نحصل على البيانات ويمكننا أن نفعل ما نريد معها.
spark.read .format(FORMAT_IGNITE) .option(OPTION_CONFIG_FILE, TEST_CONFIG_FILE) .option(OPTION_TABLE, "person") .load()
بعد إنشاء البيانات - اختياريًا من Ignite ، من أي مصدر - يمكننا حفظ كل شيء بسهولة عن طريق تحديد التنسيق والجدول المقابل. نحن نأمر سبارك بالكتابة ، نحدد التنسيق. في التكوين ، نصف المجموعة التي سيتم الاتصال بها. حدد الجدول الذي نريد حفظه فيه. بالإضافة إلى ذلك ، يمكننا وصف خيارات الأداة المساعدة - حدد المفتاح الأساسي الذي نقوم بإنشائه في هذا الجدول. إذا كانت البيانات مضطربة ببساطة دون إنشاء جدول ، فلن تكون هذه المعلمة مطلوبة. في النهاية ، انقر فوق حفظ وكتابة البيانات.
tbl.write. format(FORMAT_IGNITE). option(OPTION_CONFIG_FILE, CFG_PATH). option(OPTION_TABLE, tableName). option(OPTION_CREATE_TABLE_PRIMARY_KEY_FIELDS, pk). save
الآن دعونا نرى كيف يعمل كل شيء.
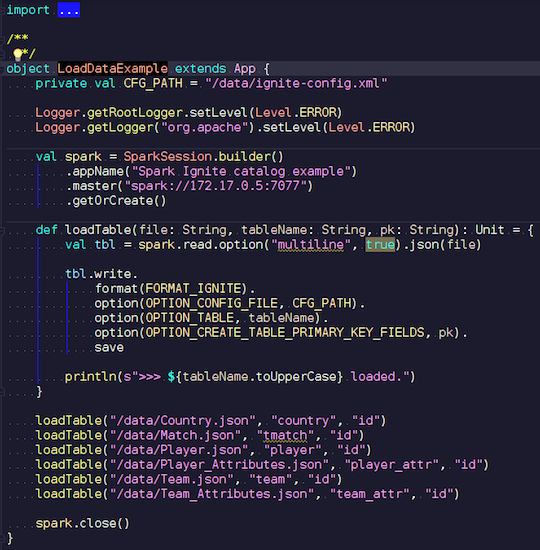 LoadDataExample.scala
LoadDataExample.scalaسيوضح هذا التطبيق الواضح أولاً قدرات التسجيل. على سبيل المثال ، اخترت البيانات الخاصة بمباريات كرة القدم والإحصائيات التي تم تنزيلها من مورد معروف. يحتوي على معلومات عن البطولات: الدوريات ، المباريات ، اللاعبين ، الفرق ، سمات اللاعب ، سمات الفريق - البيانات التي تصف مباريات كرة القدم في الدوريات الأوروبية (إنجلترا ، فرنسا ، إسبانيا ، إلخ).
أريد تحميلها على Ignite. نقوم بإنشاء جلسة Spark ، وتحديد عنوان المعالج واستدعاء تحميل هذه الجداول ، وتمرير المعلمات. المثال موجود في Scala ، وليس Java ، لأن Scala يكون مطولًا وأفضل على سبيل المثال.
نقوم بنقل اسم الملف ، وقراءته ، والإشارة إلى أنه متعدد الخطوط ، وهذا ملف json قياسي. ثم نكتب في Ignite. لا يمكن وصف هيكل ملفنا - يحدد Spark نفسه البيانات المتوفرة لدينا وماهيتها. إذا سار كل شيء بسلاسة ، يتم إنشاء جدول فيه جميع الحقول اللازمة لأنواع البيانات المطلوبة. بهذه الطريقة يمكننا تحميل كل شيء داخل Ignite.
عندما يتم تحميل البيانات ، يمكننا رؤيتها في Ignite واستخدامها على الفور. كمثال بسيط ، استعلام يتيح لك معرفة الفريق الذي لعب أكبر عدد من المباريات. لدينا عمودين: hometeam و awayteam ، المضيفين والضيوف. نختار البيانات ونجمعها ونحسبها ونجمعها وننضم إليها باستخدام البيانات - لإدخال اسم الأمر. Ta-dam - والبيانات من json-chiks التي حصلنا عليها في Ignite. نرى باريس سان جيرمان ، تولوز - لدينا الكثير من البيانات عن الفرق الفرنسية.
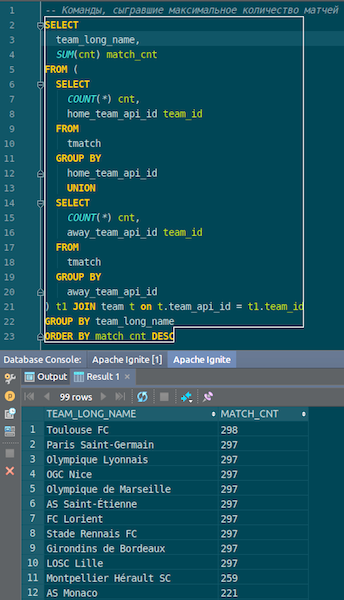
نلخص. لقد قمنا الآن بتحميل البيانات من المصدر ، ملف json ، إلى Ignite ، وبسرعة كبيرة. ربما ، من وجهة نظر البيانات الضخمة ، هذا ليس كبيرًا جدًا ، ولكنه لائق لجهاز الكمبيوتر المحلي. يتم أخذ مخطط الجدول من ملف json في شكله الأصلي. تم إنشاء الجدول ، تم نسخ أسماء الأعمدة من الملف المصدر ، وتم إنشاء المفتاح الأساسي. المعرف في كل مكان ، والمفتاح الأساسي هو المعرف. دخلت هذه البيانات في Ignite ، يمكننا استخدامها.
IgniteSparkSession و IgniteCatalog
دعونا نرى كيف يعمل.
 CatalogExample.scala
CatalogExample.scalaبطريقة بسيطة إلى حد ما ، يمكنك الوصول إلى جميع البيانات الخاصة بك والاستعلام عنها. في المثال الأخير ، بدأنا جلسة الشرر القياسية. ولم يكن هناك خصوصية Ignite هناك - باستثناء أنه يجب عليك وضع برطمان مع مصدر البيانات الصحيح - عمل قياسي تمامًا من خلال واجهة برمجة التطبيقات العامة. ولكن ، إذا كنت تريد الوصول إلى جداول Ignite تلقائيًا ، فيمكنك استخدام الامتداد الخاص بنا. الفرق هو أنه بدلاً من SparkSession نكتب IgniteSparkSession.
بمجرد إنشاء كائن IgniteSparkSession ، سترى في الدليل جميع الجداول التي تم تحميلها للتو في Ignite. يمكنك رؤية الرسم البياني الخاص بهم وجميع المعلومات. يعرف Spark بالفعل عن الجداول الموجودة في Ignite ، ويمكنك بسهولة الحصول على جميع البيانات.
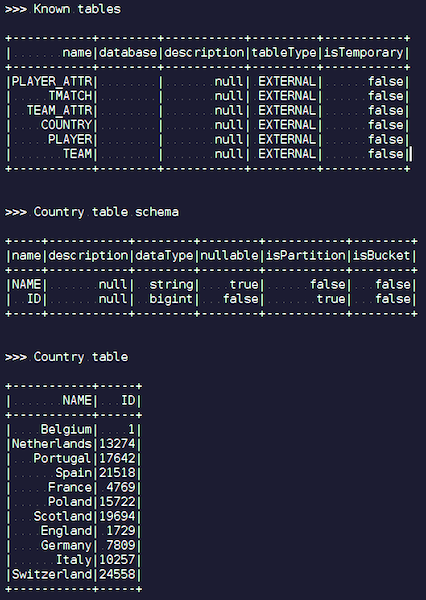
الاشتعال
عندما تقوم بعمل استعلامات معقدة في Ignite باستخدام JOIN ، يقوم Spark بسحب البيانات أولاً ، وبعد ذلك فقط يقوم JOIN بتجميعها. لتحسين العملية ، قمنا بعمل ميزة IgniteOptimization - إنها تعمل على تحسين خطة استعلام Spark وتسمح لك بإعادة توجيه أجزاء الطلب التي يمكن تنفيذها داخل Ignite داخل Ignite. نظهر التحسين على طلب محدد.
SQL Query: SELECT city_id, count(*) FROM person p GROUP BY city_id HAVING count(*) > 1
نلبي الطلب. لدينا طاولة شخص - بعض الموظفين والناس. يعرف كل موظف هوية المدينة التي يعيش فيها. نريد أن نعرف عدد الأشخاص الذين يعيشون في كل مدينة. نقوم بالتصفية - في أي مدينة يعيش أكثر من شخص واحد. فيما يلي الخطة الأولية التي يبنيها Spark:
== Analyzed Logical Plan == city_id: bigint, count(1): bigint Project [city_id#19L, count(1)#52L] +- Filter (count(1)#54L > cast(1 as bigint)) +- Aggregate [city_id#19L], [city_id#19L, count(1) AS count(1)#52L, count(1) AS count(1)#54L] +- SubqueryAlias p +- SubqueryAlias person +- Relation[NAME#11,BIRTH_DATE#12,IS_RESIDENT#13,SALARY#14,PENSION#15,ACCOUNT#16,AGE#17,ID#18L,CITY_ID#19L] IgniteSQLRelation[table=PERSON]
العلاقة هي مجرد جدول Ignite. لا توجد فلاتر - نقوم ببساطة بضخ جميع البيانات من جدول الشخص عبر الشبكة من الكتلة. ثم يجمع Spark كل هذا - وفقًا للطلب ويعيد نتيجة الطلب.
من السهل أن نرى أنه يمكن تنفيذ كل هذه الشجرة الفرعية مع الفلتر والتجميع داخل Ignite. سيكون هذا أكثر كفاءة من سحب جميع البيانات من جدول كبير محتمل في Spark - وهذا ما تفعله ميزة IgniteOptimization. بعد تحليل الشجرة وتحسينها ، نحصل على الخطة التالية:
== Optimized Logical Plan == Relation[CITY_ID#19L,COUNT(1)#52L] IgniteSQLAccumulatorRelation( columns=[CITY_ID, COUNT(1)], qry=SELECT CITY_ID, COUNT(1) FROM PERSON GROUP BY city_id HAVING count(1) > 1)
ونتيجة لذلك ، نحصل على علاقة واحدة فقط ، حيث قمنا بتحسين الشجرة بأكملها. وفي الداخل يمكنك أن ترى بالفعل أن Ignite سيرسل طلبًا قريبًا بما فيه الكفاية للطلب الأصلي.
لنفترض أننا ننضم إلى مصادر بيانات مختلفة: على سبيل المثال ، لدينا واحد DataFrame من Ignite ، والثاني من json ، والثالث مرة أخرى من Ignite ، والرابع من نوع ما من قاعدة البيانات العلائقية. في هذه الحالة ، سيتم تحسين الشجرة الفرعية فقط في الخطة. نقوم بتحسين ما نستطيع ، وإسقاطه في Ignite ، وسيقوم Spark بالباقي. نتيجة لذلك ، نحصل على مكاسب في السرعة.
مثال آخر مع JOIN:
SQL Query - SELECT jt1.id as id1, jt1.val1, jt2.id as id2, jt2.val2 FROM jt1 JOIN jt2 ON jt1.val1 = jt2.val2
لدينا جدولين. نحن نتمسك بالقيمة ونختار منها جميعًا - المعرفات والقيم. تقدم سبارك مثل هذه الخطة:
== Analyzed Logical Plan == id1: bigint, val1: string, id2: bigint, val2: string Project [id#4L AS id1#84L, val1#3, id#6L AS id2#85L, val2#5] +- Join Inner, (val1#3 = val2#5) :- SubqueryAlias jt1 : +- Relation[VAL1#3,ID#4L] IgniteSQLRelation[table=JT1] +- SubqueryAlias jt2 +- Relation[VAL2#5,ID#6L] IgniteSQLRelation[table=JT2]
نرى أنه سيسحب كل البيانات من جدول واحد ، كل البيانات من الجدول الثاني ، ينضم إليها داخل نفسه ويعطي النتائج. بعد المعالجة والتحسين ، نحصل على نفس الطلب بالضبط الذي يذهب إلى Ignite ، حيث يتم تنفيذه بسرعة نسبية.
== Optimized Logical Plan == Relation[ID#84L,VAL1#3,ID#85L,VAL2#5] IgniteSQLAccumulatorRelation(columns=[ID, VAL1, ID, VAL2], qry= SELECT JT1.ID AS id1, JT1.VAL1, JT2.ID AS id2, JT2.VAL2 FROM JT1 JOIN JT2 ON JT1.val1 = JT2.val2 WHERE JT1.val1 IS NOT NULL AND JT2.val2 IS NOT NULL)
سأريكم مثالا.
 التحسين Example.scala
التحسين Example.scalaنحن نقوم بإنشاء جلسة IgniteSpark حيث يتم تضمين جميع إمكانات التحسين الخاصة بنا تلقائيًا تلقائيًا. الطلب هنا هو: البحث عن اللاعبين الحاصلين على أعلى تصنيف وعرض أسمائهم. في جدول اللاعب ، صفاتهم وبياناتهم. نحن ننضم ونصفي البيانات غير المرغوب فيها ونعرض اللاعبين الحاصلين على أعلى تصنيف. دعونا نرى نوع الخطة التي حصلنا عليها بعد التحسين ونعرض نتائج هذا الاستعلام.
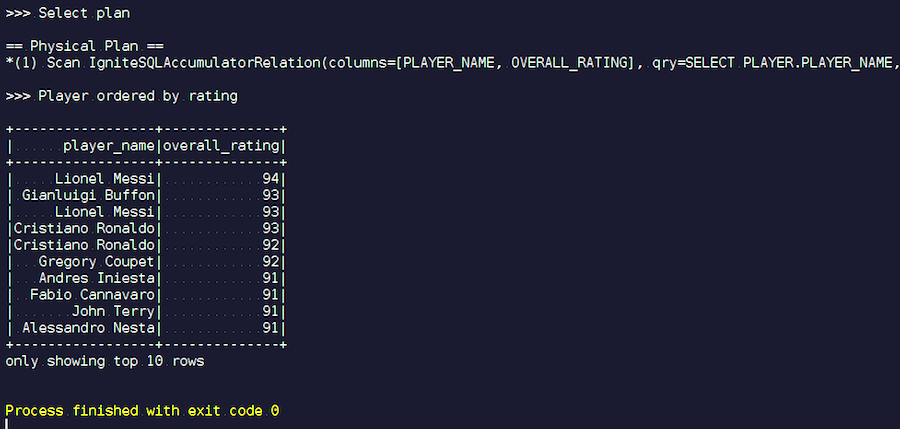
نبدأ. نرى ألقاب مألوفة: ميسي ، بوفون ، رونالدو ، إلخ. بالمناسبة ، يلتقي البعض لسببين في شكلين - ميسي ورونالدو. قد يجد عشاق كرة القدم أنه من الغريب أن يظهر لاعبون غير معروفين في القائمة. هؤلاء هم حراس المرمى ، واللاعبون ذوو الخصائص العالية إلى حد ما - على خلفية لاعبين آخرين. الآن نلقي نظرة على خطة الاستعلام التي تم تنفيذها. في Spark ، لم يتم فعل أي شيء تقريبًا ، أي أننا أرسلنا الطلب بالكامل مرة أخرى إلى Ignite.
تطوير Apache Ignite
مشروعنا منتج مفتوح المصدر ، لذلك نحن دائمًا سعداء بالتصحيحات والتعليقات من المطورين. مساعدتك وملاحظاتك وتصحيحاتك مرحب بها للغاية. نحن في انتظارهم. 90٪ من مجتمع إيجنايت يتحدثون الروسية. على سبيل المثال ، بالنسبة لي ، حتى بدأت العمل على Apache Ignite ، لم تكن أفضل معرفة باللغة الإنجليزية رادعة. بالكاد تستحق الكتابة باللغة الروسية في قائمة التطوير ، ولكن حتى إذا كتبت شيئًا خاطئًا ، فسيجيبون ويساعدونك.
ما الذي يمكن تحسينه في هذا التكامل؟ كيف يمكنني المساعدة إذا كان لديك مثل هذه الرغبة؟ القائمة أدناه. تشير العلامات النجمية إلى التعقيد.

لاختبار التحسين ، تحتاج إلى كتابة اختبارات مع استعلامات معقدة. أعلاه ، عرضت بعض الاستفسارات الواضحة. من الواضح أنه إذا كتبت الكثير من التجمعات والكثير من الصلات ، فقد يسقط شيء ما. هذه مهمة بسيطة للغاية - تعال وافعلها. إذا وجدنا أي أخطاء استنادًا إلى نتائج الاختبار ، فستحتاج إلى إصلاحها. سيكون هناك أصعب هناك.
مهمة أخرى واضحة ومثيرة للاهتمام هي دمج Spark مع عميل رفيع. إنه قادر في البداية على تحديد بعض مجموعات عناوين IP ، وهذا يكفي للانضمام إلى مجموعة Ignite ، وهو مناسب في حالة التكامل مع نظام خارجي. إذا كنت تريد فجأة الانضمام إلى حل هذه المشكلة ، فسأساعدك شخصيًا في ذلك.
إذا كنت تريد الانضمام إلى مجتمع Apache Ignite ، فإليك بعض الروابط المفيدة:
لدينا قائمة مطورة متجاوبة ، ستساعدك. إنها لا تزال بعيدة عن المثالية ، ولكن بالمقارنة مع المشاريع الأخرى ، فهي حقًا حية.
إذا كنت تعرف Java أو C ++ ، فأنت تبحث عن عمل وتريد تطوير Open Source (Apache Ignite ، Apache Kafka ، Tarantool ، إلخ) اكتب هنا: join-open-source@sberbank.ru.