قال موسيقي روسي معروف في إحدى المرات: "نحن نعمل على الكذب والبصق على السقف". لا يسعني إلا أن أتفق مع هذا البيان ، لأن حقيقة أن الكسل هو القوة الدافعة في تطوير التكنولوجيا لا يمكن القول. في الواقع ، انتقلنا فقط في القرن الماضي من المحركات البخارية إلى التصنيع الرقمي ، والآن أصبح الذكاء الاصطناعي ، الذي وصفه كتاب الخيال العلمي وعلماء المستقبل في القرن الماضي ، حقيقة متزايدة باستمرار لعالمنا كل يوم. ألعاب الكمبيوتر والأجهزة المحمولة والساعات الذكية وأكثر من ذلك بكثير بشكل أساسي ، استخدم الخوارزميات المرتبطة بآليات التعلم الآلي.
في الوقت الحاضر ، بسبب نمو القدرات الحسابية للمعالجات الرسومية والكمية الكبيرة من البيانات التي ظهرت ، اكتسبت الشبكات العصبية شعبية ، بمساعدة من خلالها على حل مشاكل التصنيف والانحدار ، وتدريبهم على البيانات المعدة. لقد تم بالفعل كتابة العديد من المقالات حول كيفية تدريب الشبكات العصبية والأطر التي يجب استخدامها لهذا الغرض. ولكن هناك مهمة سابقة تحتاج أيضًا إلى حل ، وهذه هي مهمة تشكيل مجموعة بيانات - مجموعة بيانات ، لمزيد من التدريب للشبكة العصبية. سيتم مناقشة هذا في هذه المقالة.
منذ وقت ليس ببعيد ، كانت هناك حاجة لبناء مصنّف ضوضاء للسيارة الصوتية قادر على استخراج البيانات من دفق صوتي شائع: الزجاج المكسور ، وفتح الأبواب وتشغيل محرك السيارة في أوضاع مختلفة. لم يكن تطوير المصنف صعبًا ، ولكن أين يمكن الحصول على مجموعة البيانات بحيث تلبي جميع المتطلبات؟
بدأت Google في الإنقاذ (لا يسيء إلى Yandex - سأتحدث عن مزاياها بعد ذلك بقليل) ، حيث كان من الممكن بمساعدة العديد من المجموعات الرئيسية التي تحتوي على البيانات الضرورية. أود أن أشير مقدمًا إلى أن المصادر المشار إليها في هذه المقالة تتضمن كمية كبيرة من المعلومات الصوتية ، مع فئات مختلفة ، مما يسمح لك بإنشاء مجموعة بيانات لمختلف المهام. ننتقل الآن إلى نظرة عامة على هذه المصادر.
Freesound.org
على الأرجح ، يوفر
Freesound.org أكبر حجم للبيانات الصوتية ، كونه مستودعًا مشتركًا لعينات الموسيقى المرخصة ، والتي تحتوي حاليًا على أكثر من 230،000 نسخة من المؤثرات الصوتية. يمكن توزيع كل عينة سليمة بموجب ترخيص مختلف ، لذلك من الأفضل التعرف على
اتفاقية الترخيص مسبقًا. على سبيل المثال ، الرخصة
الصفرية (cc0) لها حالة "لا حقوق نشر" ، وتسمح لك بنسخ وتعديل وتوزيع ، بما في ذلك الاستخدام التجاري ، وتسمح لك باستخدام البيانات بشكل قانوني تمامًا.
من أجل راحة العثور على عناصر المعلومات الصوتية في مجموعة متنوعة من freesound.org ، قدم المطورون
واجهة برمجة تطبيقات مصممة لتحليل البيانات والبحث عنها وتنزيلها من المستودعات. للعمل معه ، تحتاج إلى الوصول ، لهذا تحتاج إلى الذهاب إلى
النموذج وملء جميع الحقول الضرورية ، وبعد ذلك سيتم إنشاء المفتاح الفردي.

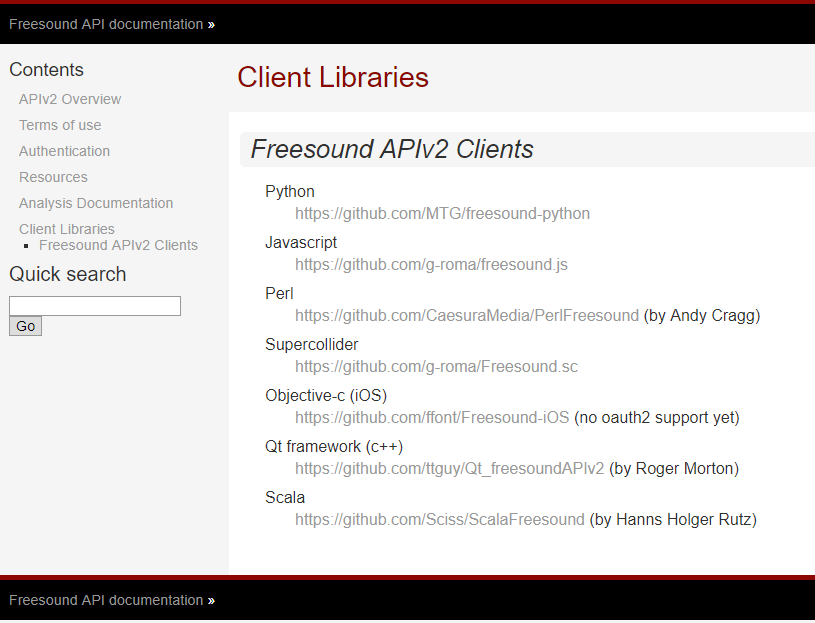
يوفر مطورو Freesound.org
واجهات برمجة التطبيقات (API) للعديد من لغات البرمجة ، مما يسمح بحل نفس المشكلة باستخدام أدوات مختلفة. قائمة اللغات والروابط المدعومة للوصول إليها على GitHub مدرجة أدناه.
لتحقيق الهدف ، تم استخدام python ، حيث اكتسبت لغة برمجة الكتابة الديناميكية الجميلة هذه الشعبية بسبب سهولة استخدامها ، ومحو أسطورة تعقيد تطوير البرمجيات. يمكن استنساخ
الوحدة النمطية للعمل مع freesound.org للبايثون من مستودع github.com.
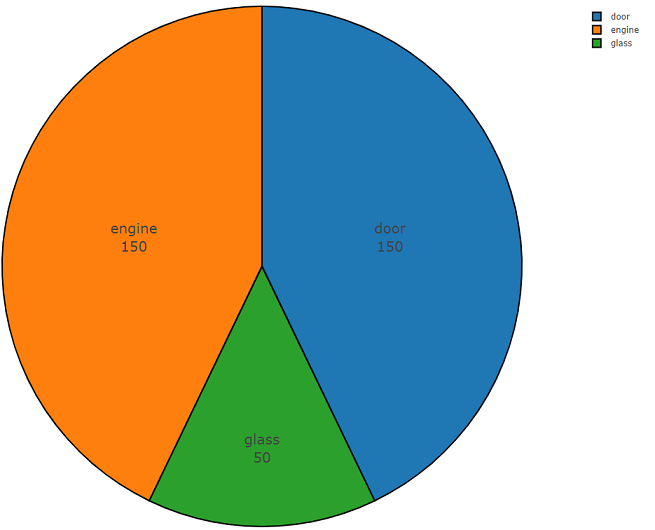
يوجد أدناه رمز مكون من جزأين يوضح سهولة استخدام واجهة برمجة التطبيقات هذه. يقوم الجزء الأول من رمز البرنامج بمهمة تحليل البيانات ، والنتيجة هي كثافة توزيع البيانات لكل فئة مطلوبة ، والجزء الثاني يقوم بتحميل البيانات من مستودعات freesound.org للفئات المحددة. يتم عرض كثافة التوزيع عند البحث عن المعلومات الصوتية مع الكلمات الرئيسية
الزجاج ، المحرك ، الباب أدناه في مخطط دائري كمثال.
كود عينة تحليل بيانات Freesound.org
import plotly import plotly.graph_objs as go import freesound import os import termcolor
نموذج كود لتنزيل بيانات freesound.org
تتمثل إحدى ميزات Freeesound في أنه يمكن إجراء تحليل البيانات الصوتية دون تنزيل ملف صوتي ، مما يسمح لك بالحصول على MFCC ، والطاقة الطيفية ، والنقطية الطيفية ، والمعاملات الأخرى. اقرأ المزيد عن المعلومات ذات المستوى
المنخفض في وثائق freesound.ord .
باستخدام واجهة برمجة تطبيقات freesound.org ، يتم تقليل الوقت المنقضي في جلب البيانات وتنزيلها ، مما يتيح لك توفير ساعات العمل في دراسة مصادر أخرى للمعلومات ، حيث تتطلب المصنفات الصوتية عالية الدقة مجموعة بيانات كبيرة ذات تنوع كبير ، تمثل البيانات ذات التوافقيات المختلفة في واحد و نفس فئة الأحداث.
يوتيوب 8M ومجموعة الصوت
أعتقد أن youtube ليس مطلوبًا بشكل خاص في العرض التقديمي ، ولكن مع ذلك ، تخبرنا ويكيبيديا أن youtube هو موقع استضافة فيديو يوفر للمستخدمين خدمات عرض الفيديو ، متناسين أن نقول أن youtube هو قاعدة بيانات ضخمة ، ويجب استخدام هذا المصدر في التعلم الآلي ، و Google Inc تزودنا بمشروع يسمى
YouTube-8M Dataset .
YouTube-8M Dataset هي مجموعة بيانات تتضمن أكثر من مليون ملف فيديو من YouTube بجودة عالية ، لتقديم معلومات أكثر دقة ، اعتبارًا من مايو 2018 ، كان هناك 6.1 مليون مقطع فيديو مع 3862 فئة. مجموعة البيانات هذه مرخصة بموجب
Creative Commons Attribution 4.0 International (CC BY 4.0) . يسمح لك هذا الترخيص بنسخ وتوزيع المواد على أي وسيط وشكل.
ربما تتساءل: أين تأتي بيانات الفيديو عندما تكون هناك حاجة إلى معلومات صوتية للمهمة ، وستكون على حق. والحقيقة هي أن Google لا توفر محتوى فيديو فحسب ، بل تخصص أيضًا بشكل منفصل مشروعًا فرعيًا مع بيانات صوتية تسمى
AudioSet .
 AudioSet
AudioSet - يوفر مجموعة بيانات تم الحصول عليها من مقاطع فيديو YouTube ، حيث يتم تقديم الكثير من البيانات في تسلسل هرمي للصف باستخدام
ملف الأنطولوجيا ، يوجد تمثيله البياني أدناه.
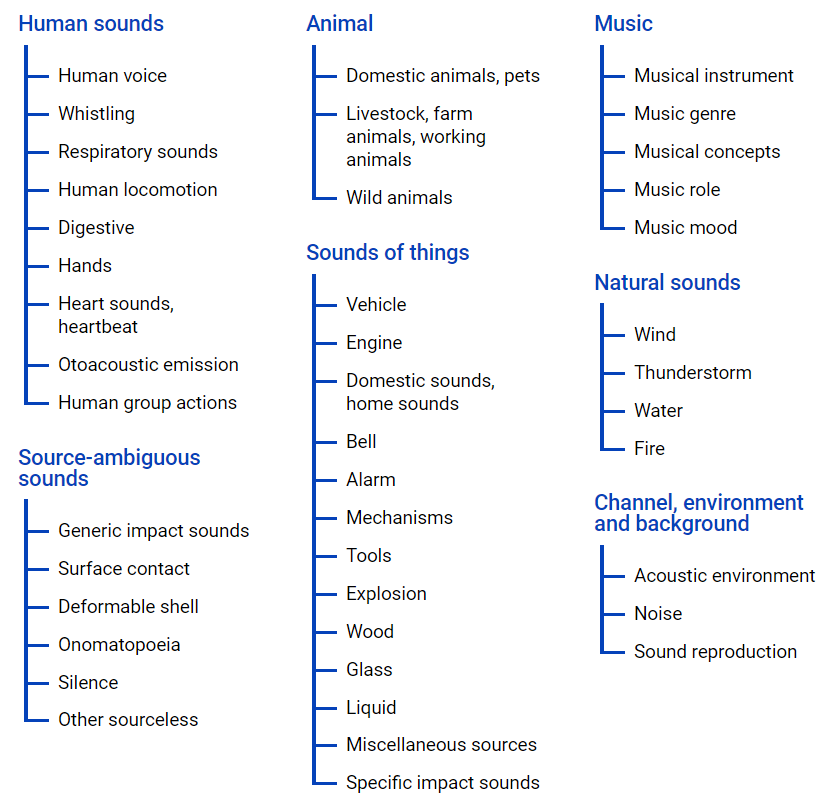
يتيح لك هذا الملف الحصول على فكرة عن تداخل الفصول الدراسية ، بالإضافة إلى الوصول إلى مقاطع فيديو youtube. لتحميل البيانات من مساحة الإنترنت ، يمكنك استخدام وحدة python - youtube-dl ، والتي تتيح لك تنزيل محتوى الصوت أو الفيديو ، بناءً على المهمة المطلوبة.
تمثل AudioSet مجموعة مقسمة إلى ثلاث مجموعات: مجموعة بيانات الاختبار والتدريب (المتوازن) والتدريب (غير المتوازن).
دعونا نلقي نظرة على هذه المجموعة ونحلل كل من هذه المجموعات على حدة للحصول على فكرة عن الفئات الواردة.
التدريب (متوازن)وفقًا للوثائق ، تتكون مجموعة البيانات هذه من
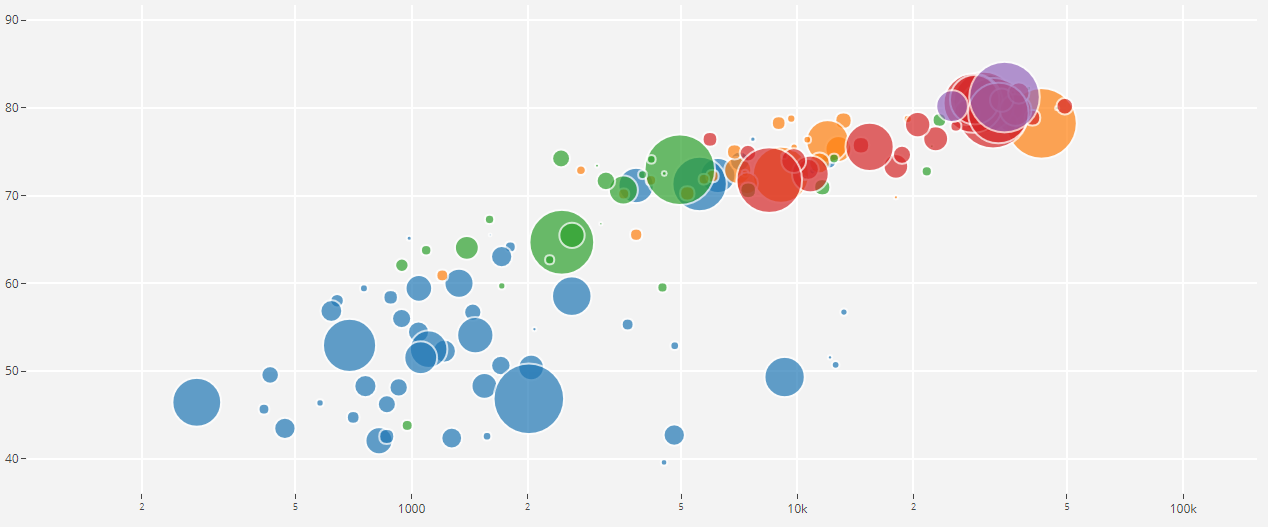
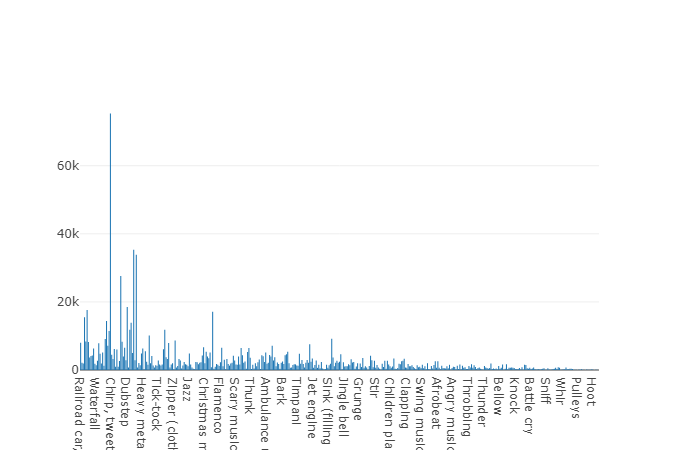
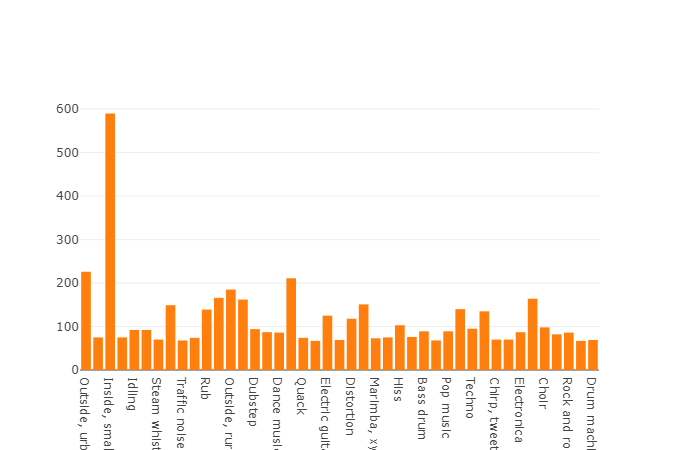
22،176 مقطعًا تم الحصول عليها من مقاطع فيديو مختلفة تم اختيارها بواسطة الكلمات الرئيسية ، مما يوفر لكل فئة 59 نسخة على الأقل. إذا نظرنا إلى كثافة التوزيع لفئات الجذر في التسلسل الهرمي للمجموعة ، فسوف نرى أن فئة الموسيقى هي أكبر مجموعة من الملفات الصوتية.
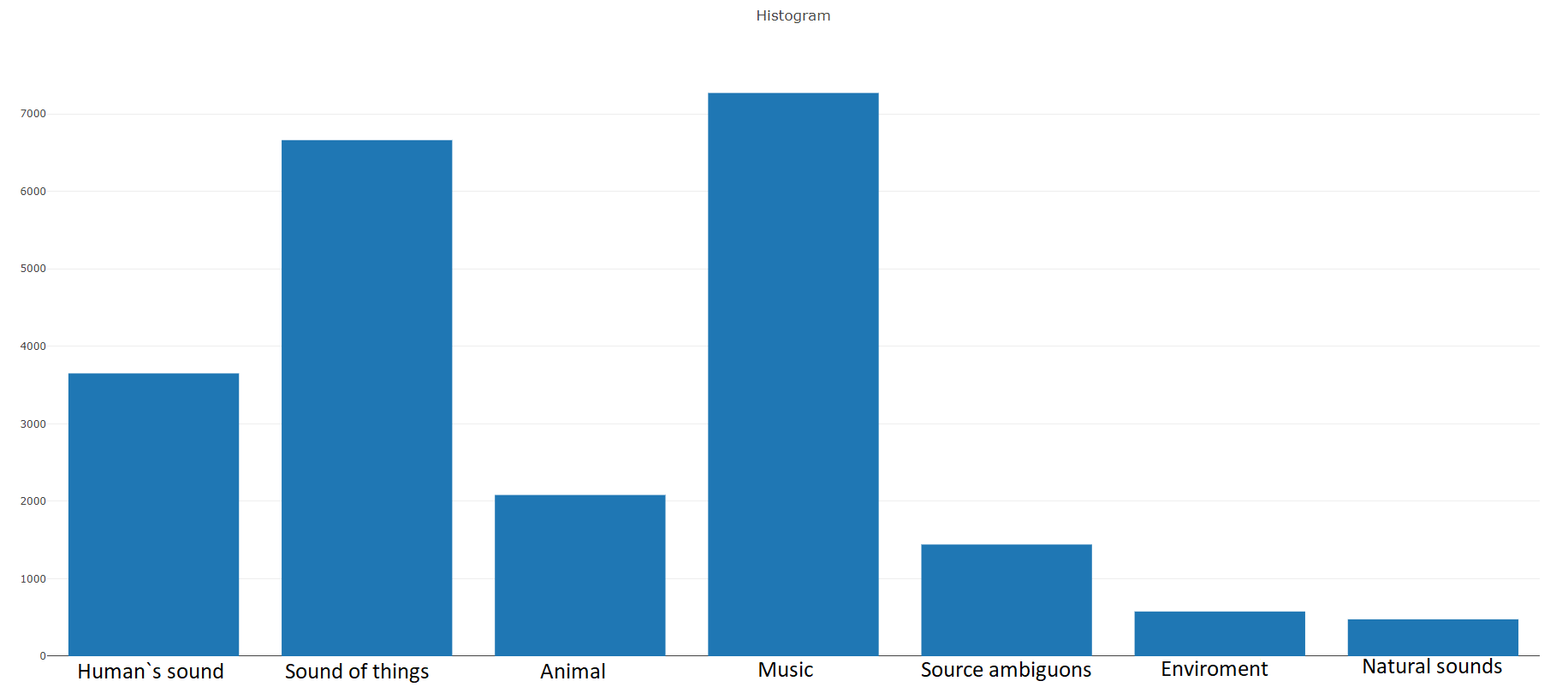
تتحلل الفصول المنظمة إلى مجموعات فرعية من الفصول ، مما يتيح لك الحصول على معلومات أكثر تفصيلاً عند استخدامها. تتميز مجموعة التدريب المتوازن هذه بكثافة توزيع يتضح من خلالها أن التوازن موجود ، ولكن تتميز الفصول الفردية أيضًا عن النظرة العامة.
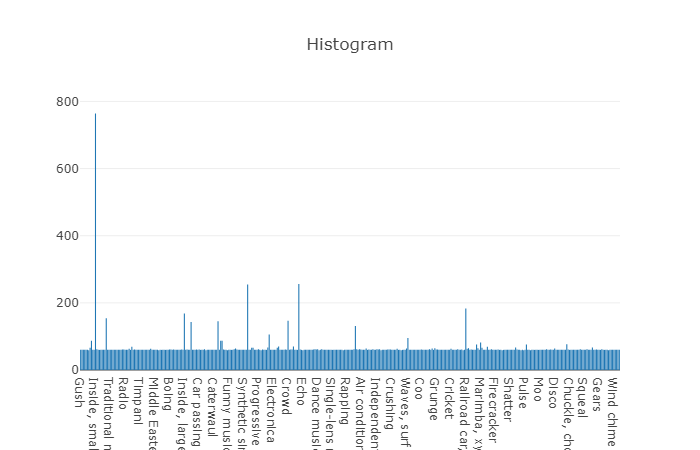
توزيع الفئات التي يتجاوز عدد عناصرها متوسط القيمة
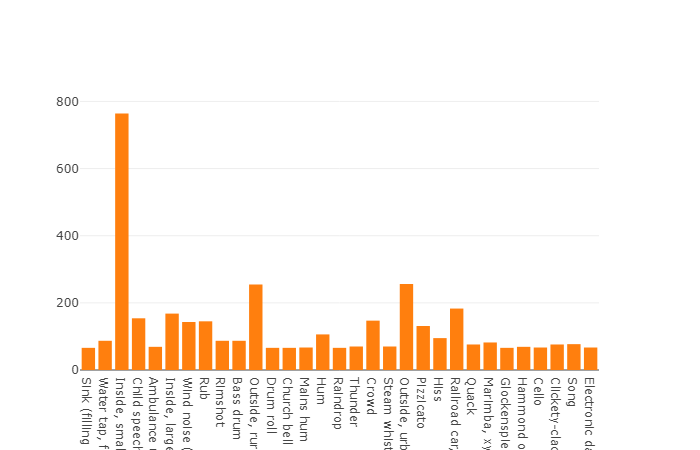
يبلغ متوسط مدة كل ملف صوتي 10 ثوانٍ ، ويتم تقديم معلومات أكثر تفصيلاً من خلال الرسم البياني للقرص ، مما يوضح أن مدة بعض الملفات تختلف عن المجموعة الرئيسية. يتم تقديم هذا الرسم البياني أيضًا.
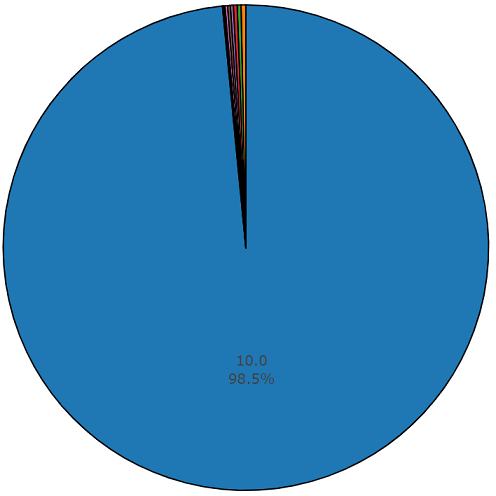
رسم تخطيطي لمدة ونصف في المائة لمدة غير متوسطة من مجموعة متوازنة من مجموعة صوتيات
 التدريب (غير متوازن)
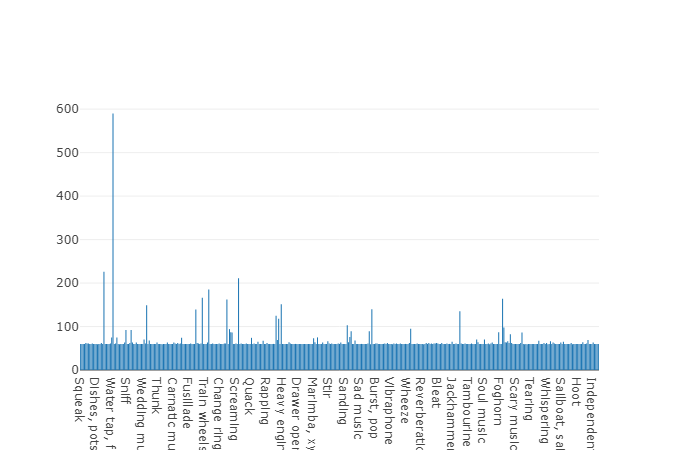
التدريب (غير متوازن)ميزة مجموعة البيانات هذه هي حجمها. فقط تخيل أنه وفقًا للوثائق ، تتضمن هذه المجموعة 2042،985 مقطعًا ، وبالمقارنة مع مجموعات البيانات المتوازنة ، فإنها تمثل تغيرًا كبيرًا ، ولكن إنتروبيا هذه المجموعة أعلى بكثير.
في هذه المجموعة ، يساوي متوسط مدة كل ملف صوتي أيضًا 10 ثوانٍ ، يتم عرض الرسم التخطيطي للقرص لمجموعة البيانات هذه أدناه.
مخطط غير متوسط المدة من مجموعة صوتيات غير متوازنة
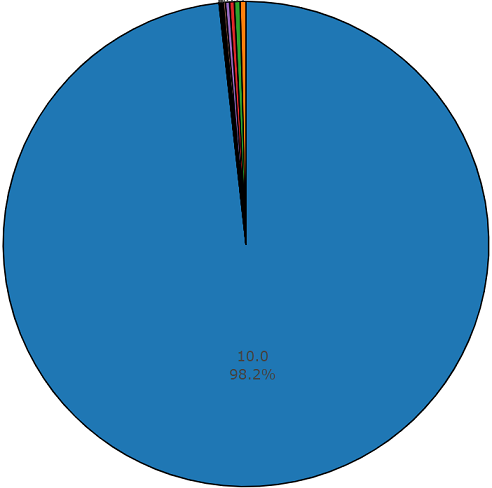
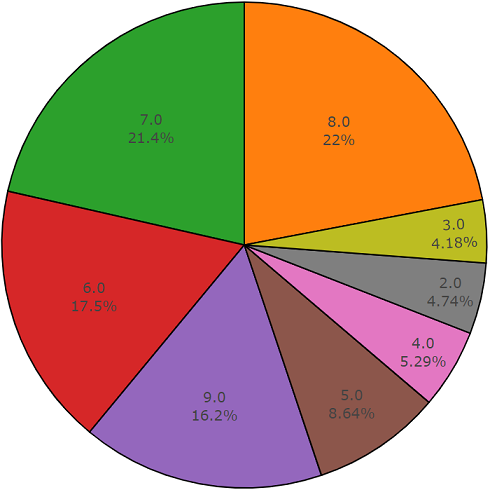
 مجموعة الاختبار
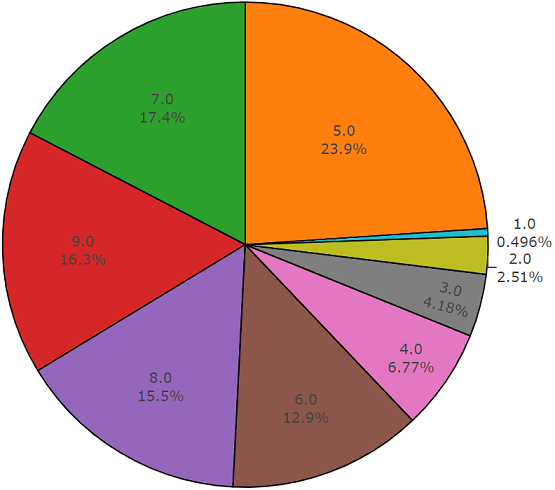
مجموعة الاختبارهذه المجموعة تشبه إلى حد كبير مجموعة متوازنة مع ميزة عدم تقاطع عناصر هذه المجموعات. يتم توزيعها أدناه.
توزيع الفئات التي يتجاوز عدد عناصرها متوسط القيمة
متوسط مدة مقطع واحد من مجموعة البيانات هذه يساوي أيضًا 10 ثوانٍ
والباقي لديه المدة الموضحة في مخطط القرص
مثال على رمز لتحليل وتنزيل البيانات الصوتية وفقًا لمجموعة البيانات المحددة:
import plotly import plotly.graph_objs as go from collections import Counter import numpy as np import os import termcolor import csv import json import youtube_dl import subprocess
للحصول على معلومات أكثر تفصيلاً حول تحليل بيانات مجموعة الصوت ، أو لتحميل هذه البيانات من مساحة YouTube وفقًا
لملف الأنطولوجيا ومجموعة
مجموعة الصوت المحددة ،
يتوفر رمز البرنامج مجانًا
في مستودع GitHub .
urbansound
تعد Urbansound واحدة من أكبر مجموعات البيانات مع الأحداث الصوتية الموسومة ، التي تنتمي فصولها إلى البيئة الحضرية. تسمى هذه المجموعة التصنيف (القاطع) ، أي تنقسم كل فئة إلى فئاتها الفرعية. يمكن تمثيل هذا العدد الكبير في شكل شجرة.
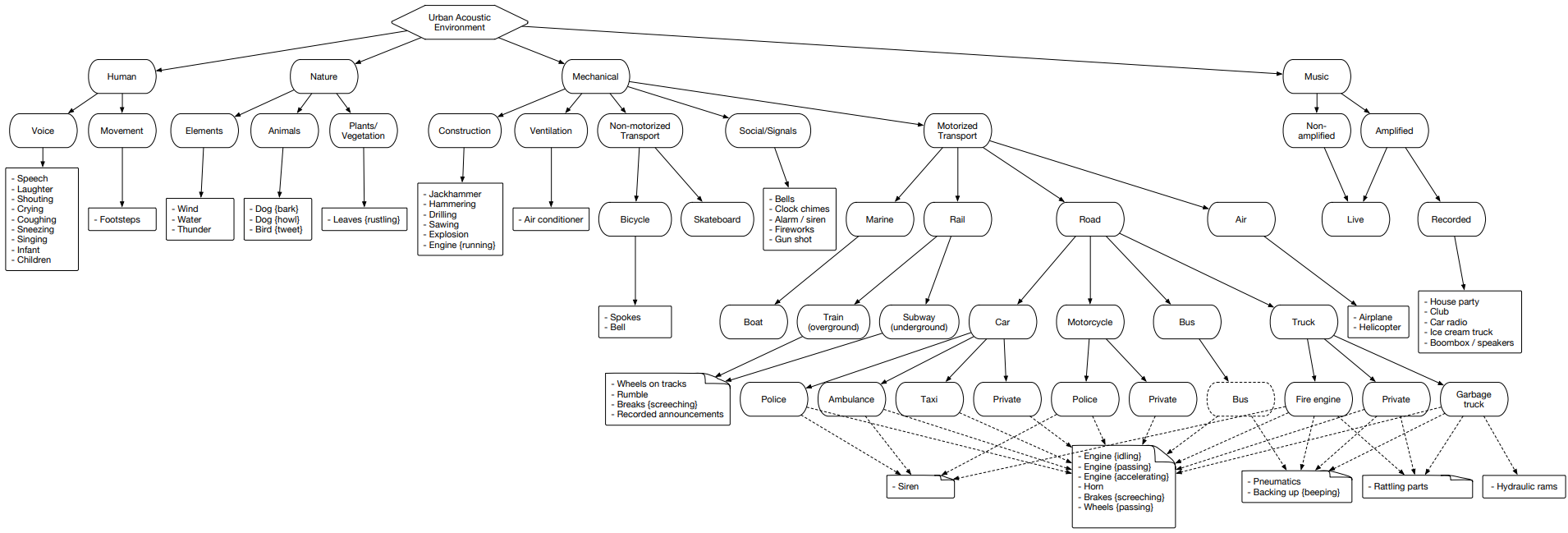
لتحميل بيانات urbansound لاستخدامها لاحقًا ، ما عليك سوى الانتقال إلى الصفحة والنقر فوق
تنزيل .
نظرًا لأن المهمة لا تحتاج إلى استخدام جميع الفئات الفرعية ، ولا يلزم سوى فئة واحدة مرتبطة بالسيارات ، فمن الضروري أولاً تصفية الفئات اللازمة باستخدام ملف التعريف الموجود في جذر الدليل الذي تم الحصول عليه عند فك ضغط الملف الذي تم تنزيله.
بعد تفريغ جميع البيانات الضرورية من المصادر المدرجة ، اتضح أنها شكلت مجموعة بيانات تحتوي على أكثر من 15000 ملف. يسمح لنا هذا الحجم من البيانات بالانتقال إلى مهمة تدريب المصنف الصوتي ، ولكن لا تزال هناك مشكلة لم يتم حلها فيما يتعلق "بنقاء" البيانات ، أي تتضمن مجموعة التدريب بيانات لا تتعلق بالفئات الضرورية من المشكلة التي يتم حلها. على سبيل المثال ، عند الاستماع إلى ملفات من فصل "كسر الزجاج" ، يمكنك العثور على أشخاص يتحدثون عن "كيف ليس من الجيد كسر الزجاج". لذلك ، نواجه مهمة تصفية البيانات ، وكأداة لحل هذا النوع من المشاكل ، أداة مناسبة تمامًا ، تم تطوير جوهرها من قبل الرجال البيلاروسيين وتلقى الاسم الغريب "Yandex.Toloka".
Yandex.Toloka
Yandex.Toloka هو مشروع تمويل جماعي تم إنشاؤه في عام 2014 لترميز أو جمع كمية كبيرة من البيانات لاستخدامها بشكل أكبر في التعلم الآلي. في الواقع ، تسمح لك هذه الأداة بجمع البيانات ووضع علامة عليها وتصفيتها باستخدام الموارد البشرية. نعم ، هذا المشروع لا يسمح لك فقط بحل المشكلات ، ولكنه يسمح أيضًا لأشخاص آخرين بكسب المال. يقع العبء المالي في هذه الحالة على عاتقك ، ولكن نظرًا لحقيقة أن أكثر من 10000 شخص يعملون من جانب فناني الأداء ، سيتم تلقي نتائج العمل في المستقبل القريب. يمكن العثور على وصف جيد لتشغيل هذه الأداة على
مدونة Yandex .
بشكل عام ، ليس استخدام السحق صعبًا بشكل خاص ، لأن نشر مهمة يتطلب التسجيل على
الموقع فقط ، بحد أدنى 10 دولارات أمريكية ، ومهمة يتم تنفيذها بشكل صحيح. كيفية صياغة مهمة بشكل صحيح ، يمكنك الاطلاع على
وثائق Yandex.Tolok أو لا توجد
مقالة سيئة
في Habr . من نفسي إلى هذه المقالة ، أود أن أضيف أنه حتى إذا كان هناك نموذج مناسب لمتطلبات مهمتك مفقودًا ، فإن تطويره لن يستغرق أكثر من بضع ساعات من العمل ، مع استراحة للقهوة والسجائر ، ويمكن الحصول على نتائج الأداء بحلول نهاية يوم العمل.
الخلاصةفي التعلم الآلي ، عند حل مشكلة التصنيف أو الانحدار ، تتمثل إحدى المهام الأساسية في تطوير مجموعة بيانات موثوقة - مجموعة بيانات. في هذه المقالة ، تم اعتبار مصادر المعلومات التي تحتوي على كمية كبيرة من البيانات الصوتية التي جعلت من الممكن تشكيل وموازنة مجموعة البيانات الضرورية لمهمة معينة. يسمح لنا رمز البرنامج المعروض بتبسيط عملية تحميل البيانات إلى الحد الأدنى ، وبالتالي تقليل الوقت اللازم لاستلام البيانات وقضاء الباقي على تطوير مصنف.
بالنسبة لمهمتي ، بعد جمع البيانات من جميع المصادر الواردة في هذه المقالة والتصفية اللاحقة للبيانات ، تمكنت من تشكيل مجموعة البيانات اللازمة لتدريب المصنف الصوتي ، الذي يعتمد على شبكة عصبية. آمل أن تسمح هذه المقالة لك ولفريقك بتوفير الوقت وقضاء الوقت في تطوير تقنيات جديدة.
PS وحدة برمجية تم تطويرها في python ، لتحليل وتحميل البيانات الصوتية لكل من المصادر المقدمة ، يمكنك العثور عليها في
مستودع github