
هذا المنشور هو ترجمة
للمقال الأصلي من
قبل Paid Nidrinhouse ، مهندس برمجيات مكدس بالكامل. تخصصه الرئيسي هو JavaScript ، لكن Paige يدرس أيضًا لغات وأطرًا أخرى. ويشارك تجربته مع قرائه. بالمناسبة ، ستكون المقالة مثيرة للاهتمام للمبتدئين.
واجهت مؤخرًا مهمة أثارت اهتمامي - كان من الضروري استخراج بيانات معينة من الحجم الهائل للملفات غير المنظمة للجنة الانتخابات الفيدرالية الأمريكية. لم أعمل كثيرًا مع البيانات الأولية ، لذلك قررت مواجهة التحدي وتولي هذه المهمة. كأداة لحلها ، اخترت Node.js.
توصي Skillbox بما يلي: دورة Frontend Developer Profession عبر الإنترنت.
نذكرك: لجميع قراء "هبر" - خصم 10000 روبل عند التسجيل في أي دورة من دورات Skillbox باستخدام الكود الترويجي "هبر".
تم وصف المهمة في أربع نقاط:
- يجب أن يحسب البرنامج إجمالي عدد الأسطر في الملف.
- يحتوي كل عمود ثامن على اسم الشخص. تحتاج إلى تحميل هذه البيانات وإنشاء مصفوفة بكل الأسماء الموجودة في الملف. من الضروري عرض الاسم 432 و 43243.
- يحتوي كل عمود خامس على تاريخ التبرع من قبل المتطوعين. احسب عدد التبرعات التي يتم تقديمها كل شهر ، واطبع النتيجة الإجمالية.
- يحتوي كل عمود ثامن على اسم الشخص. قم بإنشاء مصفوفة بتحديد الاسم الأول فقط ، بدون الاسم الأخير. تعرف على الاسم الذي يتم العثور عليه في الغالب وكم مرة؟
(يمكن
الاطلاع على المهمة الأصلية
هنا على هذا الرابط .)
الملف الذي تحتاج للعمل معه هو txt عادي 2.55 جيجا بايت. هناك أيضًا مجلد يحتوي على أجزاء من الملف الرئيسي (يمكنك تصحيح البرنامج عليها دون الحاجة إلى تحليل المجموعة الضخمة بالكامل).
حلان ممكنان على Node.js
من حيث المبدأ ، لا يخيف العمل مع الملفات الكبيرة أخصائي جافا سكريبت. بالإضافة إلى ذلك ، هذه إحدى الوظائف الرئيسية لـ Node.js. هناك العديد من الحلول الممكنة للقراءة من الملفات والكتابة إليها.
المألوف هو fs.readFile (). يسمح لك بقراءة الملف بأكمله ، ووضعه في الذاكرة ، ثم استخدام العقدة.
البديل هو fs.createReadStream () ، وهي وظيفة تقوم بتمرير بيانات مشابهة لكيفية تنظيمها بلغات أخرى - على سبيل المثال ، في Python أو Java.
الحل الذي اخترته
نظرًا لأنني كنت بحاجة إلى حساب إجمالي عدد الأسطر وتحليل البيانات لتحليل الأسماء والتواريخ ، فقد قررت التوقف عند الخيار الثاني. هنا يمكنني استخدام دالة rl.on ('line'، ...) للحصول على البيانات الضرورية من الخطوط.
Node.js CreateReadStream () & ReadFile () الرمز
أدناه هو الرمز الذي كتبته باستخدام Node.js والدالة fs.createReadStream ().
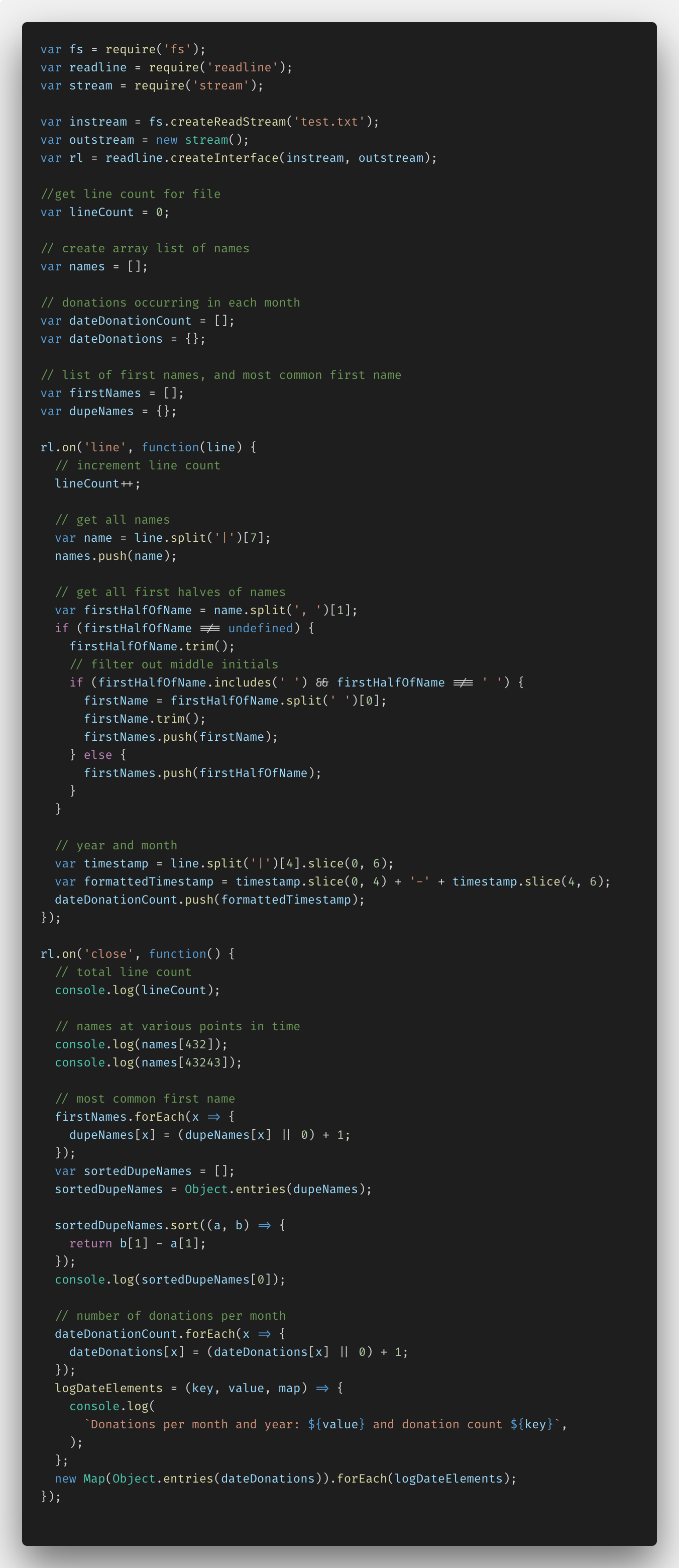
في البداية ، كنت بحاجة إلى إعداد كل شيء ، مدركًا أن استيراد البيانات يتطلب وظائف Node.js مثل fs (نظام الملفات) ، readline و stream. بعد ذلك ، تمكنت من إنشاء بث مباشر وخارجي مع readLine.createInterface (). جعل الكود الناتج من الممكن تحليل الملف سطرًا بسطر ، مع أخذ البيانات اللازمة.
بالإضافة إلى ذلك ، أضفت العديد من المتغيرات والتعليقات للعمل مع بيانات محددة. هذه هي lineCount والأسماء المزدوجة ومصفوفات الأسماء والتبرع والأسماء الأولى.
في دالة rl.on ('line'، ...) ، تمكنت من تعيين تحليل الملف سطراً بسطر. لذا ، أدخلت متغير lineCount لكل سطر. استخدمت طريقة JavaScript split () لتحليل الأسماء عن طريق إضافتها إلى مجموعة الأسماء الخاصة بي. بعد ذلك ، قمت بفصل الأسماء فقط بدون ألقاب ، مع إبراز الاستثناءات ، مثل وجود أسماء مزدوجة ، الأحرف الأولى في منتصف الاسم ، إلخ. بعد ذلك ، قمت بفصل السنة والتاريخ من عمود البيانات ، وتحويل كل هذا إلى تنسيق YYYY-MM وإضافة dateDonationCount إلى الصفيف.
في دالة rl.on ("إغلاق" ، ...) ، أجريت جميع تحويلات البيانات المضافة إلى المصفوفات ، مع تلقي المعلومات في console.log.
مطلوب lineCount والأسماء لتحديد الاسمين 432 و 43،243 ؛ لا يلزم إجراء تحويلات هنا. لكن تحديد الاسم الأكثر شيوعًا في المصفوفة وتحديد عدد التبرعات هو مهام أكثر تعقيدًا.
من أجل تحديد الاسم الأكثر شيوعًا ، كان علي إنشاء كائن من أزواج القيمة لكل اسم (مفتاح) وعدد المراجع إلى Object.entries (). (القيمة) ثم تحويلها كلها إلى مصفوفة من الصفائف باستخدام الدالة ES6. بعد ذلك ، لم تعد مهمة فرز الأسماء وتحديد أكثرها تكرارًا صعبة.
بالتبرعات ، فعلت نفس الخدعة: لقد أنشأت كائنًا من أزواج القيمة ووظيفة logDateElements () ، مما سمح لي ، باستخدام الاستيفاء ES6 ، بعرض المفاتيح والقيم لكل شهر. ثم قمت بإنشاء Map () جديد ، وتحويل كائن dateDonations إلى metamarray ، والتكرار عبر كل صفيف باستخدام logDateElements (). (اتضح أنه ليس بهذه البساطة كما بدا في البداية).
لكنها نجحت ، تمكنت من قراءة ملف صغير نسبيًا يبلغ 400 ميجابايت ، مع تسليط الضوء على المعلومات الضرورية.
بعد ذلك جربت fs.createReadStream () - قمت بتنفيذ المهمة على fs.readFile () لمعرفة الفرق. هذا هو الرمز:
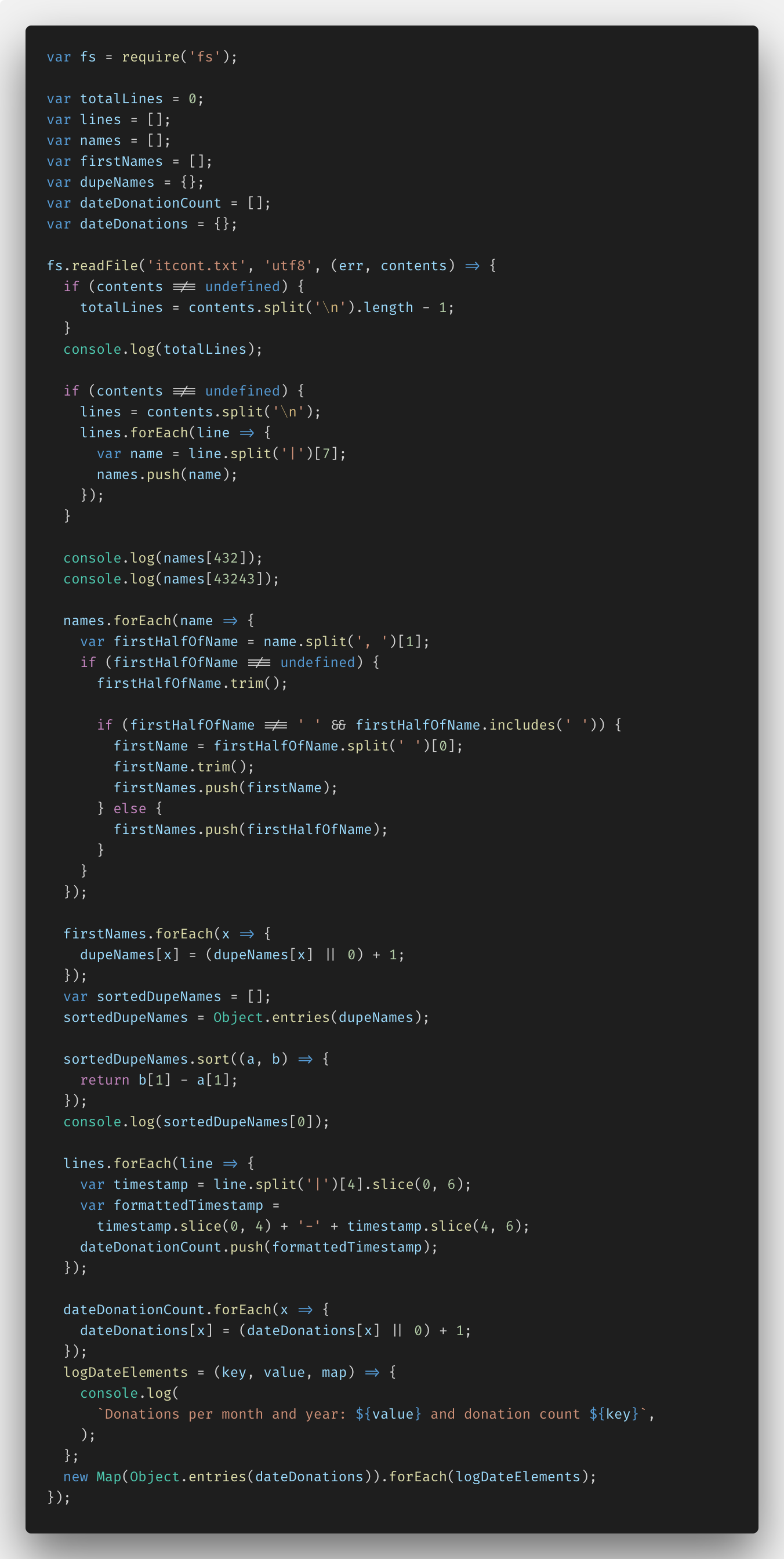
يمكنك رؤية الحل بالكامل
هنا .
نتائج العمل مع Node.js
اتضح أن الحل يعمل. أضفت المسار إلى ملف readFileStream.js و ... شاهدت تعطل خادم Node مع كومة JavaScript نفدت من الذاكرة.

اتضح أنه على الرغم من أن كل شيء يعمل ، لكن هذا الحل حاول نقل محتويات الملف بالكامل إلى الذاكرة ، وهو أمر مستحيل بسعة 2.55 جيجابايت. يمكن أن تعمل العقدة في وقت واحد مع ذاكرة 1.5 جيجا بايت ، لا أكثر.
لذلك ، لم يأت أي من قراراتي. استغرق الأمر واحدًا جديدًا يمكن أن يعمل حتى مع مثل هذه الملفات الضخمة.
حل جديد
كما اتضح ، كان من الضروري استخدام وحدة EventStream المشهورة NPM.
بعد دراسة الوثائق ، تمكنت من فهم ما يجب القيام به. هنا الإصدار الثالث من كود البرنامج.

أشارت وثائق الوحدة إلى أنه يجب تقسيم دفق البيانات إلى عناصر منفصلة باستخدام \ n الحرف في نهاية كل سطر من ملف txt.
في الأساس ، كان الشيء الوحيد الذي كان علي تغييره هو استجابة الأسماء. لم أستطع وضع 130 مليون اسم في المصفوفة - ظهر خطأ نقص الذاكرة مرة أخرى. لقد قمت بحل المشكلة عن طريق حساب الأسماء 432 و 43243 وإضافتها إلى صفيف الخاص بي. ليس قليلاً ما سُئل في الشروط ، ولكن من قال أنه لا يمكنك أن تكون مبدعًا؟
الجولة 2. نحاول البرنامج في العمل
نعم ، كل نفس الملف بحجم 2.55 جيجا بايت ، نتقاطع أصابعنا ونتابع النتيجة.
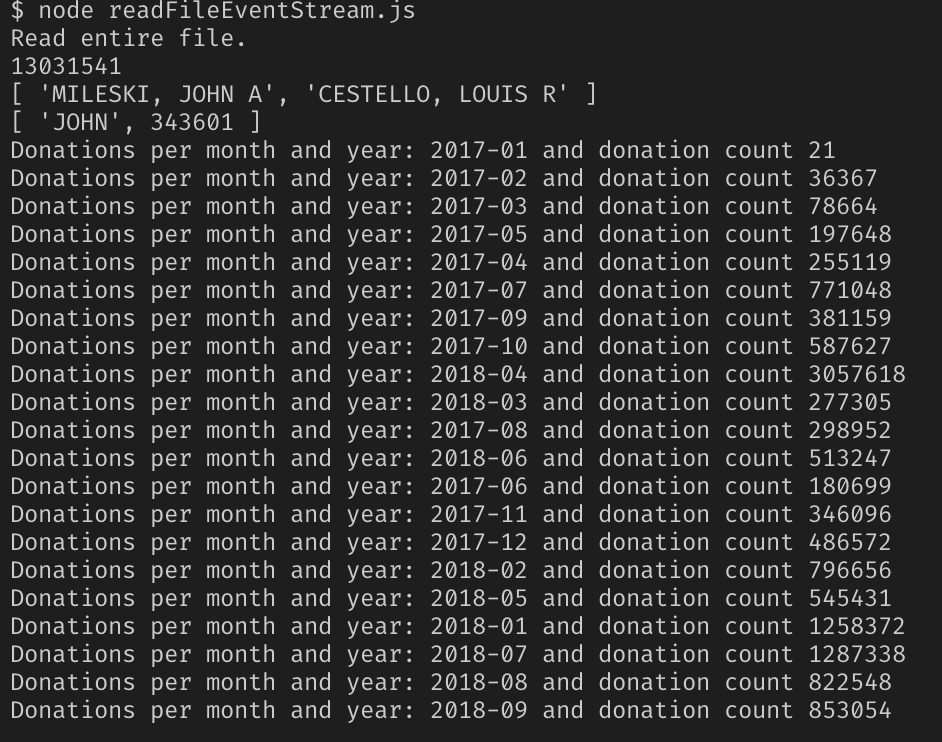
نجاح!
كما اتضح ، فإن Node.js فقط غير مناسب لحل مثل هذه المشاكل ، وقدراته محدودة إلى حد ما. ولكن توسيعها باستخدام الوحدات النمطية ، يمكنك العمل مع مثل هذه الملفات الكبيرة.
توصي Skillbox بما يلي: