التوحيد الكلي
لقد حضرت هذه المادة لخطابي في المؤتمر وسألت مديرنا الفني ما هي السمة الرئيسية لـ Kubernetes لمنظمتنا. فأجاب:
لا يفهم المطورون أنفسهم مقدار العمل الإضافي الذي قاموا به.
يبدو أنه استلهم من كتاب "الحقيقة" الذي تمت قراءته مؤخرًا - من الصعب ملاحظة التغييرات الطفيفة والمستمرة للأفضل ، ونفقد باستمرار تقدمنا.
لكن التحول إلى Kubernetes ليس بالتأكيد غير مهم.

ما يقرب من 30 من فرقنا تقوم بتشغيل كل أو بعض أعباء العمل على المجموعات. يتم إنشاء حوالي 70٪ من حركة مرور HTTP الخاصة بنا بواسطة التطبيقات الموجودة على مجموعات Kubernetes. من المحتمل أن يكون هذا أكبر تقارب بين التقنيات منذ أن انضممت إلى الشركة بعد أن اشترت Forward uSwitch في عام 2010 ، عندما انتقلنا من .NET والخوادم المادية إلى AWS ومن نظام مترابط إلى خدمات متناهية الصغر .
وكل ذلك حدث بسرعة كبيرة. في نهاية عام 2017 ، استخدمت جميع الفرق البنية التحتية AWS الخاصة بهم. قاموا بإعداد موازنات الحمل ومثيلات EC2 وتحديثات مجموعة ECS وأشياء من هذا القبيل. مر أكثر من عام بقليل ، وتغير كل شيء.
لقد أمضينا الحد الأدنى من الوقت في التقارب ، ونتيجة لذلك ، ساعدتنا Kubernetes في حل المشكلات الملحة - كانت سحبتنا تنمو ، وأصبحت المنظمة أكثر تعقيدًا ، وكنا نكافح من أجل استيعاب أشخاص جدد في فرق. لم نغير المنظمة لاستخدام Kubernetes. على العكس من ذلك - استخدمنا Kubernetes لتغيير المنظمة.
ربما لم يلاحظ المطورون تغييرات كبيرة ، لكن البيانات تتحدث عن نفسها. المزيد عن هذا في وقت لاحق.
منذ سنوات عديدة كنت في مؤتمر كلوجور واستمعت إلى محاضرة لمايكل نيجارد عن الهندسة المعمارية والتي لا يمكن الوصول بها إلى حالتها النهائية . فتح عيني. يبدو النظام الأنيق والمنظم كاريكاتيرًا عندما يقارن متاجر التلفزيون بمنتجات المطبخ وبنية البرمجيات واسعة النطاق - يبدو النظام الحالي مثل سكين غبي ، ويخرج نوع من العصيدة بدلاً من شرائح. بدون سكين جديدة ، لا يوجد شيء للتفكير في السلطة.
هذا عن كيفية عشق المنظمات لمشاريع مدتها ثلاث سنوات: السنة الأولى هي التطوير والإعداد ، السنة الثانية هي التنفيذ ، والثالثة هي العودة. في محاضرة ، يقول إن مثل هذه المشاريع يتم تنفيذها بشكل مستمر ونادرًا ما تصل إلى نهاية العام الثاني (غالبًا بسبب الاستحواذ من قبل شركة أخرى وتغيير في الاتجاه والاستراتيجية) ، لذلك فإن البنية المعتادة هي
التقسيم الطبقي للتغيير في بعض مظاهر الاستقرار.
و uSwitch مثال رائع.
لقد تحولنا إلى AWS لأسباب عديدة - لم يتمكن نظامنا من التعامل مع ذروة الأحمال ، وأعيقت المنظمة بسبب نظام صارم للغاية وفرق ذات صلة وثيقة تم تشكيلها لمشاريع محددة وتم تقسيمها حسب التخصص.
لن ننهي كل شيء وننقل جميع الأنظمة ونبدأ من جديد. لقد أنشأنا خدمات جديدة مع التوكيل من خلال موازن التحميل الحالي وخنقنا التطبيق القديم تدريجيًا . أردنا إظهار العائد على الفور ، وفي الأسبوع الأول أجرينا اختبار أ / ب للنسخة الأولى من الخدمة الجديدة في الإنتاج. ونتيجة لذلك ، أخذنا منتجات طويلة الأجل وبدأنا في تشكيل فرق لهم من المطورين والمصممين والمحللين ، وما إلى ذلك ، ورأينا النتيجة على الفور. في عام 2010 ، بدت هذه ثورة حقيقية.
عامًا بعد عام ، أضفنا فرقًا وخدمات وتطبيقات جديدة و "خنق" النظام المترابط تدريجيًا. تقدمت الفرق بسرعة - الآن عملوا بشكل مستقل عن بعضهم البعض وتألفوا من متخصصين في جميع المجالات الضرورية. قمنا بتقليل تفاعلات الفريق لإصدارات المنتج. لقد خصصنا عدة أوامر فقط لتكوين موازن التحميل.
اختارت الفرق نفسها طرق التطوير والأدوات واللغات. لقد حددنا لهم مهمة ، ووجدوا أنفسهم هم الحل ، لأنهم كانوا أفضل ضليعين في هذا الأمر. مع AWS ، أصبحت هذه التغييرات أسهل.
لقد اتبعت مبادئ البرمجة بشكل حدسي - فالفرق التي ترتبط ارتباطًا وثيقًا ببعضها البعض ستكون أقل احتمالية للتواصل ، ولن نضطر إلى إنفاق موارد ثمينة على تنسيق عملها. تم وصف كل هذا بشكل رائع في الكتاب الذي تم نشره مؤخرًا.
ونتيجة لذلك ، كما وصف مايكل Nygard ، حصلنا على نظام من طبقات عديدة من التغييرات - تم تشغيل بعض الأنظمة باستخدام Puppet ، وبعضها باستخدام Terraform ، وفي مكان ما استخدمنا فيه ECS ، وفي مكان ما EC2.
في عام 2012 ، كنا فخورين بهندستنا المعمارية ، والتي يمكن تغييرها بسهولة للتجربة ، وإيجاد حلول ناجحة وتطويرها.
لكن في عام 2017 ، أدركنا أن الكثير قد تغير.
AWS الآن أكثر تعقيدًا بكثير مما كانت عليه في عام 2010. وهي تقدم الكثير من الخيارات والميزات - ولكن ليس بدون عواقب. واليوم ، يتعين على أي فريق يعمل مع EC2 أن يختار VPC وتكوين الشبكة والمزيد.
لقد اختبرنا ذلك بمفردنا - بدأت الفرق تشكو من أنهم كانوا يقضون المزيد والمزيد من الوقت في الحفاظ على البنية التحتية ، على سبيل المثال ، تحديث الحالات في مجموعات AWS ECS ، وآلات EC2 ، والتحول من موازنات ELB إلى ALB ، إلخ.
في منتصف عام 2017 ، في حدث للشركات ، حثت الجميع على توحيد عملهم من أجل تحسين الجودة الإجمالية للأنظمة. لقد استخدمت استعارة جبل الجليد المخترقة لإظهار كيفية إنشاء البرامج وصيانتها:

قلت أنه يجب على معظم الفرق في شركتنا إنشاء خدمات أو منتجات والتركيز على حل المشكلات ، ورمز التطبيق ، والأنظمة الأساسية والمكتبات ، وما إلى ذلك. لا يزال هناك الكثير من العمل تحت الماء - دمج السجلات ، وزيادة المراقبة ، وإدارة الأسرار ، وما إلى ذلك.
في ذلك الوقت ، تعامل كل فريق من مطوري التطبيقات مع جبل الجليد بالكامل تقريبًا واتخذ جميع القرارات بمفرده - باختيار اللغة وبيئة التطوير والمكتبة وأداة المقاييس ونظام التشغيل ونوع المثيل والتخزين.
في قاعدة الهرم ، كان لدينا بنية تحتية لخدمات Amazon Web Services. ولكن ليست كل خدمات AWS متشابهة. لديهم Backend-as-a-Service (BaaS) ، على سبيل المثال للمصادقة وتخزين البيانات. وهناك خدمات أخرى منخفضة المستوى نسبيًا ، مثل EC2. كنت أرغب في دراسة البيانات وفهم أن الفرق لديها سبب للشكوى وأنهم يقضون حقًا المزيد من الوقت في العمل مع خدمات منخفضة المستوى واتخاذ العديد من القرارات ليست الأكثر أهمية.
لقد قسمت الخدمات إلى فئات ، باستخدام CloudTrail ، جمعت جميع الإحصاءات المتاحة ، ثم استخدمت BigQuery و Athena و ggplot2 لمعرفة كيف تغير وضع المطورين مؤخرًا. نمو خدمات مثل RDS و Redshift وما إلى ذلك ، نعتبره مرغوبًا (ومتوقعًا) ونموًا لـ EC2 و CloudFormation وما إلى ذلك - والعكس صحيح.

توضح كل نقطة في الرسم البياني النسب المئوية 90 (الحمراء) و 80 (الخضراء) و 50 (الزرقاء) لعدد الخدمات ذات المستوى المنخفض التي يستخدمها موظفونا كل أسبوع لفترة معينة. أضفت خطوط تنعيم لإظهار الاتجاه.
على الرغم من أننا استهدفنا عمليات تجريد على مستوى أعلى عند نشر البرامج ، على سبيل المثال ، باستخدام حاويات و Amazon ECS ، استخدم مطورونا بانتظام المزيد والمزيد من خدمات AWS ولم يتجاهلوا بشكل كافٍ صعوبات إدارة الأنظمة. في غضون عامين ، تضاعف عدد الخدمات لـ 50٪ من الموظفين وزاد ثلاث مرات تقريبًا لـ 20٪.
هذا حد من نمو شركتنا. سعت الفرق إلى الاستقلال الذاتي ، ولكن كيف يمكن توظيف أشخاص جدد؟ كنا بحاجة إلى مطوري تطبيقات ومنتجات قوية ومعرفة بنظام AWS المتطور بشكل متزايد.
أردنا توسيع فرقنا وفي الوقت نفسه الحفاظ على المبادئ التي نجحنا بها: الاستقلالية والحد الأدنى من التنسيق والبنية التحتية للخدمة الذاتية.
مع Kubernetes ، أنجزنا ذلك باستخدام الملخصات التي تركز على التطبيق والقدرة على الحفاظ على المجموعات وتكوينها مع الحد الأدنى من التنسيق الجماعي.
التجريد يركز على التطبيق
من السهل مطابقة مفاهيم Kubernetes مع اللغة التي يستخدمها مطور التطبيق. افترض أنك تدير إصدارات التطبيق كنشر . يمكنك تشغيل عدة نسخ متماثلة خلف الخدمة وتعيينها إلى HTTP من خلال Ingress . ومن خلال موارد المستخدم ، يمكنك توسيع وتخصيص هذه اللغة اعتمادًا على ما تحتاجه.
تعمل الفرق بشكل أكثر كفاءة مع هذه التجريدات. بشكل أساسي ، يحتوي هذا المثال على كل ما تحتاجه لنشر تطبيق ويب وتشغيله. والباقي Kubernetes.
في الصورة مع جبل الجليد ، تكون هذه المفاهيم على مستوى المياه وتجمع بين مهام المطور من الأعلى والمنصة أدناه. يمكن لفريق إدارة المجموعة اتخاذ قرارات منخفضة المستوى وغير ذات أهمية (حول إدارة المقاييس ، وتسجيل الدخول ، وما إلى ذلك) وفي نفس الوقت يتحدثون نفس اللغة مع المطورين فوق سطح الماء.
في عام 2010 ، كان لدى uSwitch فرق تقليدية لخدمة نظام متآلف ، وكان لدينا مؤخرًا قسم تكنولوجيا المعلومات الذي كان يدير حساب AWS الخاص بنا جزئيًا. يبدو لي أن نقص المفاهيم المشتركة أعاق عمل هذا الفريق بشكل خطير.
حاول أن تقول شيئًا مفيدًا إذا كان لديك مثيلات EC2 فقط في مفرداتك وموازنات الحمل والشبكات الفرعية. كان من الصعب أو حتى المستحيل وصف جوهر التطبيق. يمكن أن تكون حزمة دبيان ، تنتشر عبر كابيسترانو ، وما إلى ذلك. لم نتمكن من وصف التطبيق بلغة مشتركة للجميع.
في أوائل العقد الأول من القرن الحادي والعشرين ، عملت في ThoughtWorks في لندن. في المقابلة ، نصحني بقراءة التصميم الموجه للمشكلة من إريك إيفانز. اشتريت كتابًا في طريق العودة إلى المنزل وبدأت القراءة في القطار. منذ ذلك الحين ، أتذكرها في كل مشروع ونظام تقريبًا.
إحدى المفاهيم الرئيسية للكتاب هي لغة واحدة تتواصل فيها فرق مختلفة. توفر Kubernetes فقط مثل هذه اللغة الموحدة للمطورين وفرق صيانة البنية التحتية ، وهذه واحدة من مزاياها الرئيسية. بالإضافة إلى أنه يمكن توسيعه واستكماله بمجالات مواضيع وخطوط أعمال أخرى.
يعد التواصل بلغة مشتركة أكثر إنتاجية ، ولكن ما زلنا بحاجة إلى الحد من التفاعل بين الفرق قدر الإمكان.
الحد الأدنى من التفاعل الضروري
يسلط مؤلفو Accelerate الضوء على خصائص البنية المقترنة بشكل فضفاض والتي تعمل معها فرق تقنية المعلومات بكفاءة أكبر:
في عام 2017 ، اعتمد نجاح التسليم المستمر على ما إذا كان بإمكان الفريق:
تغيير هيكل النظام الخاص بك بجدية دون إذن من الإدارة.
قم بتغيير هيكل النظام الخاص بك بجدية ، دون انتظار تغيير الفرق الأخرى لهيكلها ، ودون إنشاء الكثير من العمل غير الضروري للفرق الأخرى.
أداء مهامهم دون التواصل أو تنسيق عملهم مع الفرق الأخرى.
نشر وإصدار منتج أو خدمة عند الطلب ، بغض النظر عن الخدمات الأخرى المرتبطة بها.
قم بإجراء معظم الاختبارات حسب الطلب بدون بيئة اختبار متكاملة.
لقد احتجنا إلى مجموعات مركزية متعددة المستأجرين للبرامج المركزية لجميع الفرق ، ولكن في الوقت نفسه أردنا الحفاظ على هذه الخصائص. لم نصل بعد إلى المثالية ، لكننا نحاول قدر الإمكان ما يلي:
- لدينا عدة مجموعات عاملة ، وتختار الفرق نفسها مكان تشغيل التطبيق. نحن لا نستخدم الاتحاد بعد (نحن في انتظار دعم AWS) ، ولكن لدينا Envoy لموازنة الحمل على موازنات Ingress في مجموعات مختلفة. نقوم بأتمتة معظم هذه المهام باستخدام خط أنابيب التوصيل المستمر (لدينا طائرة بدون طيار ) وخدمات AWS الأخرى.
- كافة الكتل لها نفس مساحة الاسم . عن واحد لكل فريق.
- نتحكم في الوصول إلى مساحات الأسماء من خلال RBAC (التحكم في الوصول المستند إلى الدور). للمصادقة والتفويض ، نستخدم هوية الشركة في Active Directory.
- تتوسع المجموعات تلقائيًا ، ونحن نبذل قصارى جهدنا لتحسين وقت بدء العقدة. لا يزال الأمر يستغرق بضع دقائق ، ولكن ، بشكل عام ، حتى مع أعباء العمل الكبيرة ، نقوم بذلك بدون تنسيق.
- يتم قياس التطبيقات تلقائيًا بناءً على مقاييس مستوى التطبيق من Prometheus. تتحكم فرق التطوير في التحجيم التلقائي لتطبيقها من خلال مقاييس الاستعلام في الثانية ، والعمليات في الثانية ، وما إلى ذلك. وبفضل التحجيم التلقائي للكتلة ، يقوم النظام بإعداد العقد عندما يتجاوز الطلب إمكانات الكتلة الحالية.
- كتبنا Go باستخدام أداة سطر الأوامر تسمى u التي توحد مصادقة الأوامر في Kubernetes ، وتستخدم Vault ، وطلبات أوراق اعتماد AWS المؤقتة ، وما إلى ذلك.
لست متأكدا من أنه مع Kubernetes لدينا المزيد من الاستقلالية ، لكنها ظلت بالتأكيد على مستوى عال ، وفي الوقت نفسه تخلصنا من بعض المشاكل.
كان التحول إلى Kubernetes سريعًا. يعرض الرسم البياني إجمالي عدد مساحات الأسماء (يساوي تقريبًا عدد الأوامر) في مجموعات عملنا. ظهر الأول في فبراير 2017.
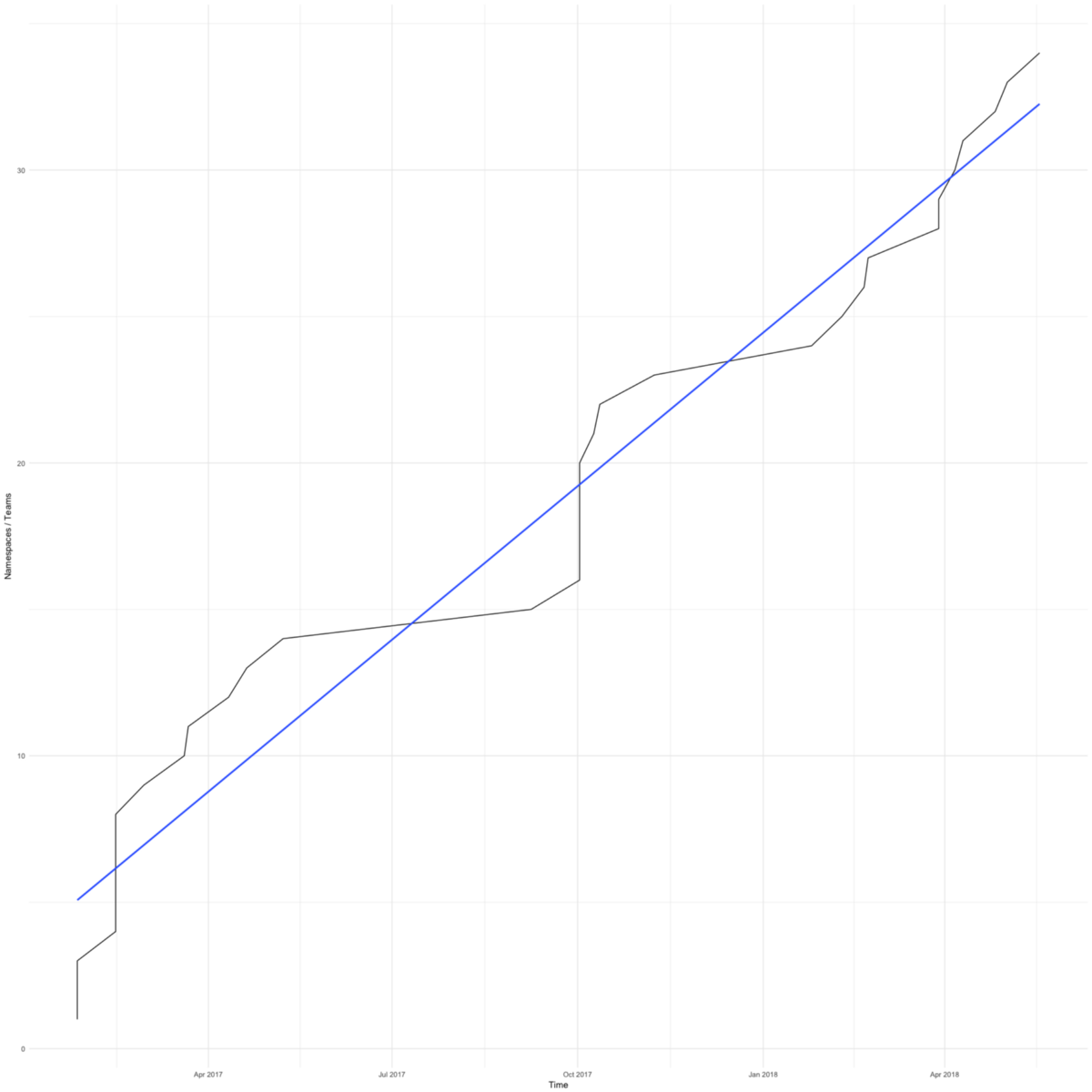
كان لدينا أسباب للتسرع - أردنا إنقاذ الفرق الصغيرة التي تركز على منتجاتها من المخاوف بشأن البنية التحتية.
وافق الفريق الأول على التحول إلى Kubernetes عندما نفدت مساحة خادم التطبيق الخاص بهم بسبب إعدادات تسجيل الدخول غير الصحيحة. استغرق الانتقال بضعة أيام فقط ، وبدأوا مرة أخرى في العمل.
في الآونة الأخيرة ، تحولت الفرق إلى Kubetnetes للحصول على أدوات محسنة. تعمل مجموعات Kubernetes على تبسيط التكامل مع Hashicorp Vault و Google Cloud Trace والأدوات المشابهة. تحصل جميع فرقنا على ميزات أكثر فعالية.
لقد عرضت بالفعل مخططًا يحتوي على نسب مئوية من عدد الخدمات التي يستخدمها موظفونا كل أسبوع من نهاية 2014 إلى 2017. وهنا استمرار لهذا الرسم البياني حتى يومنا هذا.
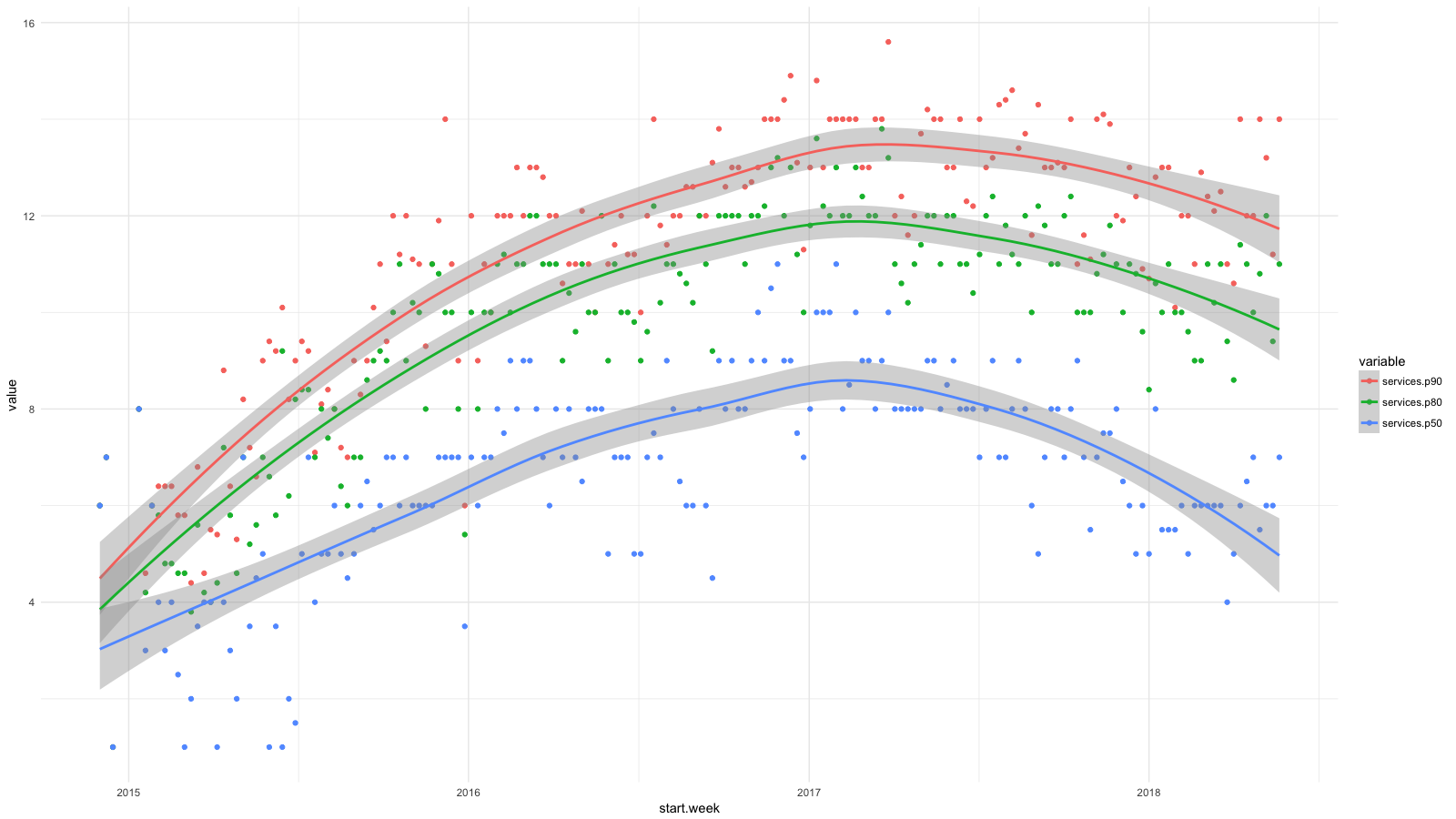
لقد حققنا تقدمًا في إدارة إطار AWS المعقد. يسعدني أن نصف الموظفين الآن يفعلون نفس الشيء كما في بداية عام 2015. لدينا 4-6 موظفين في فريق الحوسبة السحابية ، حوالي 10٪ من العدد الإجمالي - ليس من المستغرب أن النسبة المئوية 90 لم تتزحزح تقريبًا. ولكن آمل أن يكون هناك تقدم هنا أيضًا.
أخيرًا ، سأتحدث عن كيفية تغير دورة التطوير لدينا ، وأتذكر مرة أخرى كتاب Accelerate الذي تمت قراءته مؤخرًا.
يذكر الكتاب مقياسين للتطور الهزيل: المهلة الزمنية وحجم العبوة. يعتبر المهلة الزمنية من الطلب إلى تسليم الحل النهائي. حجم العبوة هو مقدار العمل. كلما كان حجم العبوة أصغر ، كان العمل أكثر كفاءة:
كلما كانت الحزمة أصغر ، كلما كانت دورة الإنتاج أقصر ، وأقل تغير في العملية ، ومخاطر أقل ، وتكاليف وتكاليف ، نحصل على تعليقات أسرع ، ونعمل بكفاءة أكبر ، ولدينا المزيد من الحافز ، ونحاول الانتهاء بشكل أسرع وتأجيل التسليم بشكل أقل.
يقترح الكتاب قياس حجم الحزم حسب تواتر النشر - فكلما زاد النشر ، كانت الحزم أصغر.
لدينا بيانات لبعض عمليات النشر. البيانات ليست دقيقة تمامًا - ترسل بعض الفرق الإصدارات مباشرة إلى الفرع الرئيسي للمستودع ، وبعضها يستخدم آليات أخرى. لا يشمل هذا جميع التطبيقات ، ولكن يمكن اعتبار البيانات لمدة 12 شهرًا إرشادية.
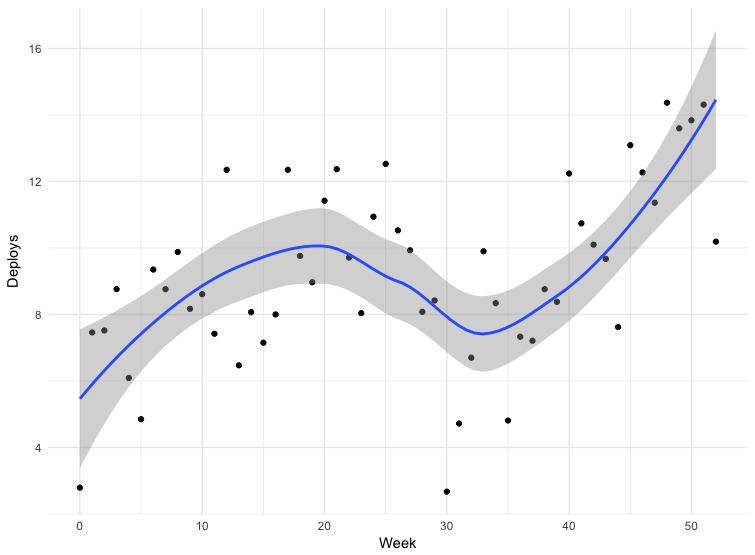
الفشل في الأسبوع الثلاثين هو عيد الميلاد. بالنسبة للبقية ، نرى أن تردد النشر يزداد ، مما يعني أن حجم الحزمة ينخفض. من مارس إلى مايو 2018 ، تضاعف تكرار الإصدارات تقريبًا ، ومؤخراً نقوم أحيانًا بإصدار أكثر من مائة إصدار يوميًا.
يعد التبديل إلى Kubernetes جزءًا فقط من استراتيجيتنا لتوحيد الأدوات وأتمتتها وتحسينها. على الأرجح ، كل هذه العوامل أثرت على تواتر الإطلاقات.
يتحدث برنامج "تسريع" أيضًا عن العلاقة بين تكرار النشر وعدد الموظفين ، ومدى السرعة التي يمكن أن تعمل بها الشركة إذا تم زيادة الموظفين. يؤكد المؤلفون على قيود العمارة والفرق ذات الصلة:
يُعتقد تقليديًا أن توسيع الفريق يزيد من الإنتاجية الإجمالية ، ولكنه يقلل من إنتاجية المطورين الفرديين.
إذا أخذنا نفس البيانات حول تواتر عمليات النشر وقمنا بعمل رسم تخطيطي للاعتماد على عدد المستخدمين ، يمكننا أن نرى أنه يمكننا زيادة تكرار الإصدارات ، حتى إذا كان لدينا المزيد من الأشخاص.

في بداية المقال ، ذكرت كتاب الحقائق (الذي ألهم CTO لدينا). أصبح الانتقال إلى Kubernetes للمطورين لدينا هو التقارب الأكثر أهمية وسرعة من التكنولوجيا. نتحرك بخطوات صغيرة ، ومن السهل عدم ملاحظة مدى تغير كل شيء نحو الأفضل. من الجيد أن لدينا بيانات ، وتظهر أنهم حققنا ما نريد - يشارك أفرادنا في منتجهم ويتخذون قرارات مهمة في مجالهم.
كانت جيدة لنا. كان لدينا خدمات متناهية الصغر ، AWS ، وفرق راسخة للمنتجات ، ومطورين مسؤولين عن خدماتهم في الإنتاج ، وفرق وهندسة مقرونة بشكل فضفاض. لقد تحدثت عن هذا في تقرير "عصر التنوير لدينا" ("عصر التنوير لدينا") في مؤتمر عام 2012. لكن ليس هناك حد للكمال.
في النهاية ، أود أن أقتبس من كتاب آخر - مقياس . لقد بدأتها مؤخرًا ، وهناك جزء مثير للاهتمام حول استهلاك الطاقة في الأنظمة المعقدة:
للحفاظ على النظام والهيكل في النظام النامي ، هناك حاجة إلى تدفق مستمر للطاقة ، ويخلق الفوضى. لذلك ، للحفاظ على الحياة ، يجب أن نأكل طوال الوقت من أجل هزيمة الكون الحتمي.
نحن نكافح الإنتروبيا من خلال توفير المزيد من الطاقة للنمو والابتكار والصيانة والإصلاح ، والتي تصبح أكثر صعوبة مع تقدم العمر ، وهذه المعركة هي أساس أي مناقشات جادة حول الشيخوخة والوفيات والاستدامة والاكتفاء الذاتي لأي نظام ، سواء كان كائنًا حيًا أو شركة أو مجتمع.
أعتقد أنه يمكنك إضافة أنظمة تكنولوجيا المعلومات هنا. آمل أن تحافظ جهودنا الأخيرة على الإنتروبيا حتى لفترة من الوقت.