أعمل كمطور في
hh.ru ، وأريد الذهاب إلى قواعد البيانات ، ولكن حتى الآن لا توجد مهارات كافية. لذلك ، في وقت فراغي ، أدرس التعلم الآلي وأحاول حل المشكلات العملية من هذا المجال. في الآونة الأخيرة ، ألقوا بي مهمة تجميع السير الذاتية لدينا. سيكون المنشور حول كيفية حلها باستخدام التجميع الهرمي التراكمي. إذا كنت لا تريد القراءة ، ولكن النتيجة مثيرة للاهتمام ، فيمكنك مشاهدة
العرض التوضيحي على الفور.

الخلفية
سوق العمل في ديناميكيات مستمرة ، وظهور مهن جديدة ، وأخرى تختفي ، وأريد أن أحصل على تصنيف مناسب للسير الذاتية. إن قائمة المجالات والتخصصات المهنية على hh.ru قديمة منذ فترة طويلة: يرتبط الكثير بها ، لذلك لم يتم إجراء أي تغييرات لفترة طويلة. قد يكون من المفيد معرفة كيفية تحرير هذه الفئات دون ألم. أحاول تحديد هذه الفئات تلقائيًا. آمل أن يساعد ذلك في المستقبل على حل المشكلة.
حول النهج المختار وحول التكتل
من خلال التجميع ، سوف أفهم مجموعة الكائنات ذات الميزات الأكثر تشابهًا في مجموعة واحدة. في حالتي ، تحت الكائن يعتبر سيرة ذاتية ، وتحت علامات الكائن هي البيانات الموجزة: على سبيل المثال ، تكرار كلمة "مدير" في السيرة الذاتية أو حجم الراتب. يتم تحديد تشابه الكائنات بواسطة مقياس تم تحديده مسبقًا. في الوقت الحالي ، يمكنك التفكير في الأمر على أنه مربع أسود يتلقى كائنين عند الإدخال ، وينتج الناتج رقمًا يعكس ، على سبيل المثال ، المسافة بين الكائنات في فضاء المتجهات: كلما كانت المسافة أصغر ، كلما كانت الكائنات أكثر تشابهًا.
يمكن أن يسمى النهج الذي استخدمته التجميع الهرمي التراكمي التصاعدي. نتيجة التجميع هي شجرة ثنائية ، حيث توجد في الأوراق عناصر فردية ، وجذر الشجرة هو مجموعة من جميع العناصر. يطلق عليه الصعود لأن التجميع يبدأ عند أدنى مستوى من الشجرة ، بأوراق ، حيث يعتبر كل عنصر فردي مجموعة.

ثم تحتاج إلى العثور على أقرب عناقيد ودمجها في كتلة جديدة. يجب تكرار هذا الإجراء حتى يكون هناك كتلة واحدة فقط مع جميع الكائنات في الداخل. عند دمج العناقيد ، يتم تسجيل المسافة بينها. في المستقبل ، يمكن استخدام هذه المسافات لتحديد المكان الذي تكون فيه هذه المسافات كبيرة بما يكفي لاعتبار المجموعات المحددة منفصلة.
تفترض معظم طرق التجميع أن عدد المجموعات معروف مسبقًا ، أو يحاول عزل المجموعات بشكل مستقل ، اعتمادًا على الخوارزمية ومعلمات هذه الخوارزمية. تتمثل ميزة التجميع الهرمي في أنه يمكنك محاولة تحديد العدد المطلوب من المجموعات عن طريق فحص خصائص الشجرة الناتجة ، على سبيل المثال ، تحديد الأشجار الفرعية في مجموعات مختلفة تكون مسافاتها كبيرة جدًا. من السهل العمل مع الهيكل الناتج للبحث عن العناقيد فيه. بشكل ملائم ، تم بناء مثل هذا الهيكل مرة واحدة ولا يحتاج إلى إعادة بناء عند البحث عن العدد المطلوب من العناقيد.
من بين أوجه القصور ، أود أن أذكر أن الخوارزمية تتطلب تمامًا الذاكرة المستهلكة. وبدلاً من تعيين فئة معينة ، أود أن أحصل على احتمال أن تنتمي السيرة الذاتية للفصل لكي لا ننظر إلى أقرب تخصص ، ولكن إلى الإجمالي.
جمع البيانات وإعدادها
أهم جزء في العمل مع البيانات هو تحضيرها واختيارها واسترجاع السمات. على أساس العلامات التي ستؤدي في النهاية ، سيعتمد على ما إذا كانت هناك أنماط فيها ، وما إذا كانت هذه الأنماط تتوافق مع النتيجة المتوقعة وما إذا كانت هذه "النتيجة المتوقعة" ممكنة على الإطلاق. قبل تغذية البيانات إلى نوع ما من خوارزمية التعلم الآلي ، تحتاج إلى الحصول على فكرة عن كل علامة ، وما إذا كانت هناك فجوات ، ونوع العلامة التي تنتمي إليها ، وما هي خصائص هذا النوع من العلامات ، وما هو توزيع القيم في هذه العلامة. من المهم أيضًا اختيار الخوارزمية الصحيحة التي ستتم بها معالجة البيانات المتاحة.
أخذت السير الذاتية التي تم تحديثها على مدى الأشهر الستة الماضية. لقد اتضح أن 2.7 مليون. من البيانات الموجودة في السيرة الذاتية ، اخترت أبسط العلامات ، والتي ، كما بدا لي ، يجب أن تعتمد عضوية السيرة الذاتية على مجموعة أو أخرى. بالنظر إلى المستقبل ، سأقول أن نتيجة تجميع كل السير الذاتية مرة واحدة لم ترضيني. لذلك ، كان علينا أولاً أن نقسم السيرة الذاتية على المجالات المهنية الـ 28 الموجودة.
لكل خاصية ، قمت برسم التوزيع للحصول على فكرة عن كيفية ظهور البيانات. ربما يجب تحويلها بطريقة أو بأخرى أو التخلي عنها تمامًا.
المنطقة حتى يمكن مقارنة قيم هذه الميزة مع بعضها البعض ، قمت بتعيين العدد الإجمالي للسيرة الذاتية التي تنتمي إلى هذه المنطقة لكل منطقة وأخذت اللوغاريتم من هذا الرقم لتسوية الفرق بين المدن الكبيرة والصغيرة جدًا.
بول تحويل إلى علامة ثنائية.
تاريخ الميلاد . تحسب في عدد الأشهر. ليس لدى الجميع عيد ميلاد. لقد ملأت الفجوات بمتوسط قيم العمر من التخصص الذي تنتمي إليه هذه السيرة الذاتية.
مستوى التعليم . هذه علامة قاطعة. لقد قمت
بترميزها باستخدام
LabelBinarizer .
اسم العنصر . قدت سيارتي عبر
TfidfVectorizer باستخدام ngram_range = (1،2) ، استخدمت
ساقًا .
الراتب . ترجم جميع القيم في روبل. لقد ملأت الفجوات بنفس الطريقة كما في عمري. أخذ اللوغاريتم من القيمة.
جدول العمل . LabelBinarizer المشفر.
معدل العمالة . لقد جعلتها ثنائية ، وتقسمها إلى قسمين: بدوام كامل وبقية العالم.
إتقان اللغة . لقد اخترت الأكثر استخدامًا. يتم تعيين كل لغة كميزة منفصلة. تتم مطابقة مستويات الملكية بالأرقام من 0 إلى 5.
المهارات الأساسية . قدت سيارتي عبر TfidfVectorizer. وككلمة توقف ، جمعت قاموسًا صغيرًا للمهارات العامة والكلمات ، كما يبدو لي ، لا تؤثر على التخصص. يتم تمرير جميع الكلمات من خلال الجذع. يمكن أن تتكون كل مهارة رئيسية ليس فقط من كلمة واحدة ، ولكن أيضًا من عدة كلمات. في حالة عدة كلمات في المهارة الرئيسية ، قمت بفرز الكلمات ، واستخدمت أيضًا كل كلمة كسمة منفصلة. كانت هذه الميزة تسير بشكل جيد في المجال المهني "تقنيات المعلومات والإنترنت والاتصالات" ، لأن الأشخاص غالبًا ما يشيرون إلى المهارات ذات الصلة بتخصصهم. في المجالات المهنية الأخرى ، لم أستخدمها بسبب وفرة مهارات الكلمات العامة.
تخصصات لقد قمت بتعيين كل من التخصصات المحددة من قبل المستخدم كسمة ثنائية.
الخبرة العملية . تولى لوغاريتم عدد الأشهر + 1 ، لأن هناك أشخاص ليس لديهم خبرة في العمل.
التقييس
ونتيجة لذلك ، بدأت كل سيرة ذاتية في كونها ناقلًا لإشارات الأرقام. تعتمد خوارزمية التجميع المحددة على حساب المسافة بين الكائنات. كيفية تحديد كيفية مساهمة كل ميزة في هذه المسافة؟ على سبيل المثال ، هناك علامة ثنائية - 0 و 1 ، ويمكن أن تأخذ علامة أخرى الكثير من القيم من 0 إلى 1000.
يأتي التقييس لإنقاذ. لقد استخدمت
StandardScaler . يقوم بتحويل كل سمة بطريقة تجعل متوسط قيمتها صفرًا والانحراف المعياري عن المتوسط واحد. وبالتالي ، نحن نحاول إحضار جميع البيانات إلى نفس التوزيع - المعيار العادي. بالطبع ، ليس من الحقيقة أن البيانات نفسها لها طبيعة التوزيع الطبيعي. هذا مجرد أحد أسباب إنشاء الرسوم البيانية لتوزيع معلماتهم ويسعدهم أنها تبدو وكأنها غوسية.
لذا ، على سبيل المثال ، بدا مخطط توزيع الرواتب.

يمكن ملاحظة أن لديه ذيل ثقيل للغاية. لجعل التوزيع أكثر طبيعية ، يمكنك أخذ اللوغاريتم من هذه البيانات. في الوقت نفسه ، لن تكون الانبعاثات قوية جدًا.
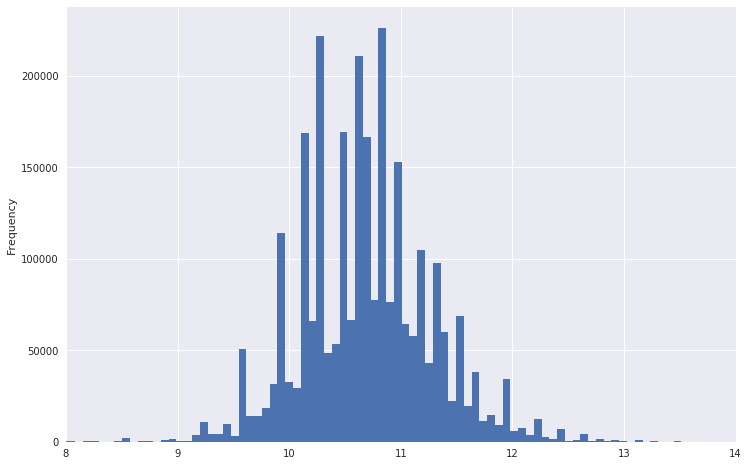
الرجوع إلى إصدار أقدم
من المنطقي الآن نقل البيانات إلى مساحة ذات أبعاد أصغر ، بحيث تتمكن خوارزمية التجميع في المستقبل من هضمها في وقت وذاكرة مقبولين. لقد استخدمت
TruncatedSVD ،
لأنها تعرف كيفية العمل مع المصفوفات المتناثرة وعند المخرج ، فإنها تعطي المصفوفة الكثيفة المعتادة ، والتي سنحتاجها لمزيد من العمل. بالمناسبة ، يحتاج TruncatedSVD أيضًا إلى إرسال بيانات قياسية.
في نفس المرحلة ، يجدر محاولة تصور مجموعة البيانات الناتجة ، وترجمتها إلى مساحة ثنائية الأبعاد باستخدام
t-SNE . هذه خطوة مهمة للغاية. إذا لم يكن هناك هيكل مرئي في الصورة الناتجة ، أو على العكس من ذلك ، فإن هذه البنية تبدو غريبة للغاية ، فإما أن بياناتك لا تحتوي على الانتظام اللازم ، أو حدث خطأ في مكان ما.
حصلت على الكثير من الصور المريبة للغاية قبل أن يسير كل شيء على ما يرام. على سبيل المثال ، بمجرد ظهور مثل هذه الصورة الجميلة:

كان سبب الديدان الناتجة هو الحصول على معرفات السيرة الذاتية في مجموعة البيانات. وهنا شيء أكثر تشابهًا مع الحقيقة:

التكتل
إذا كان كل شيء يبدو مرتبًا مع البيانات ، فيمكنك البدء في التجميع. لقد استخدمت حزمة
التجميع الهرمي من SciPy. يسمح التجميع باستخدام
طريقة الربط . لقد حاولت جميع مقاييس مسافة الكتلة المقترحة في الخوارزمية. أفضل نتيجة أعطتها
طريقة وارد .
المشكلة الرئيسية التي واجهتها هي خوارزمية التجميع وتحسب مصفوفة المسافة بين جميع العناصر ، مما يعني اعتمادًا على الذاكرة التربيعية لعدد العناصر. مقابل 2.7 مليون سيرة ذاتية ، لم أنجح ، لأن مقدار الذاكرة المطلوبة هو تيرابايت. تم تنفيذ جميع الحسابات على جهاز كمبيوتر عادي. ليس لدي الكثير من ذاكرة الوصول العشوائي. لذلك ، بدا لي من المعقول أنه يمكنك أولاً الجمع بين السير الذاتية القريبة ، واتخاذ مراكز المجموعات الناتجة ، وتجميعها بالفعل مع الخوارزمية المطلوبة. أخذت
MiniBatchKMeans ، وشكلت 30.000 مجموعة وأرسلتها إلى مجموعات هرمية. نجحت ، ولكن النتيجة كانت كذلك. برزت العديد من مجموعات السيرة الذاتية الأكثر بروزًا ، لكن التفاصيل ليست كافية للعثور على تخصصات بمستوى جيد.
لتحسين جودة التخصصات التي تم الحصول عليها ، قمت بتقسيم البيانات إلى مجالات مهنية. اتضح أن مجموعات البيانات من 400000 سيرة ذاتية وأقل. في تلك اللحظة ، بدا لي أن تجميع عينة بيانات أفضل من استخدام خوارزميتين متتاليتين. لذلك تخليت عن MiniBatchKMeans وأخذت ما يصل إلى 100000 سيرة ذاتية لكل تخصص حتى تتمكن طريقة الربط من هضمها. 32 غيغابايت من ذاكرة الوصول العشوائي لم تكن كافية ، لذلك خصصت 100 غيغابايت إضافية للتبديل. ونتيجة لذلك ، يوفر الربط مصفوفة مع المسافات بين العناقيد مجتمعة في كل خطوة وعدد العناصر في المجموعة الناتجة.
كمقياس لمراقبة الجودة لمقارنة الإصدارات المختلفة من مجموعات البيانات والطرق المختلفة لحساب المسافة بين المجموعات ، استخدمت الخوارزمية معامل الارتباط الخلقي الذي تم الحصول عليه من
cophenet . يوضح هذا المعامل كيف يعكس المخطط الشكلي الناتج اختلاف الأشياء مع بعضها البعض. كلما كانت القيمة أقرب إلى الوحدة ، كان ذلك أفضل.
التصور
أفضل طريقة للتحقق من جودة التكتل هي التصور.
ترسم طريقة
dendrogram مخططات dendrograms الناتجة التي يمكنك من خلالها تحديد الكتل حسب المسافة أو المستوى في الشجرة:

يوضح الرسم البياني التالي اعتماد المسافة بين العناقيد على رقم خطوة التكرار ، حيث يتم الجمع بين أقرب العناقيدتين في واحدة جديدة. يوضح الخط الأخضر كيف يتغير التسارع - سرعة المسافة بين العناقيد التي يتم ضمها.
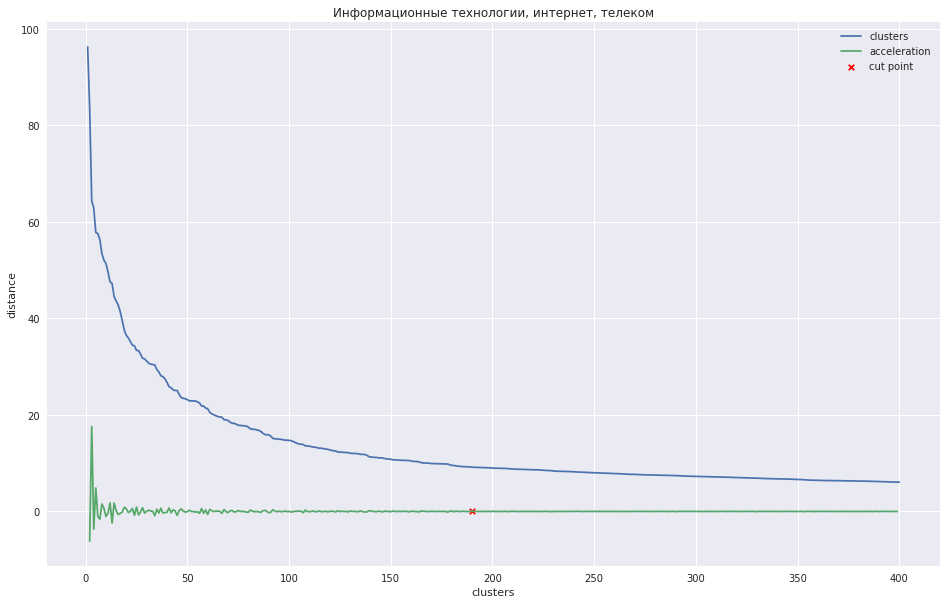
في حالة وجود عدد قليل من العناقيد ، يمكن للمرء أن يحاول تقليم الشجرة عند النقطة التي يكون فيها الحد الأقصى للتسارع ، أي أن المسافة في تلك اللحظة التي تم فيها دمج المجموعتين كانت أكبر ، وكانت أصغر بالفعل في الخطوة التالية. في حالتي ، كل شيء مختلف - لدي العديد من المجموعات ، واقترحت أنه من الأفضل قطع مخطط الشريان عند النقطة التي يبدأ فيها التسارع في الانخفاض بشكل أكثر رتابة ، أي أن المسافات بين المجموعات في هذا المستوى لم تعد تشير إلى مجموعة منفصلة. على الرسم البياني ، يكون هذا المكان تقريبًا عند النقطة التي يتوقف فيها الخط الأخضر عن الرقص.
يمكن للمرء أن يبتكر نوعًا من الأسلوب البرمجي ، ولكن اتضح أنه أسرع لتحديد هذه الأماكن بـ 28 يدًا لـ 28
مجالًا احترافيًا وتمرير العدد المطلوب من العناقيد إلى طريقة
fcluster ، والتي ستقطع الشجرة في المكان الصحيح.
قمت بحفظ البيانات التي تم الحصول عليها سابقًا من t-SNE ، ولاحظت المجموعات الناتجة عليها. تبدو جيدة:

ونتيجة لذلك ، قمت بإنشاء واجهة ويب حيث يمكنك مشاهدة الملخص من كل مجموعة ، وموقعها على الرسم البياني وإعطاء اسم ذي معنى. من أجل الراحة ، استنتجت العنوان الأكثر شيوعًا للسيرة الذاتية - غالبًا ما يميز اسم المجموعة جيدًا.
يمكنك إلقاء نظرة على نتيجة التجميع
هنا .
خلصت لنفسي إلى أن النظام تبين أنه يعمل. على الرغم من أن التقسيم إلى مجموعات غير كامل وبعض المجموعات متشابهة جدًا مع بعضها البعض ، ولكن يمكن تقسيم بعضها ، على العكس من ذلك ، إلى أجزاء ، ولكن الاتجاهات الرئيسية لسوق التخصص واضحة بشكل واضح. يمكنك أيضًا الاطلاع على كيفية تكوين المجموعات الجديدة. تم تفريغ السيرة الذاتية في الصيف ، لذلك برز
السائقون الذين أرادوا العمل في كأس العالم ، على سبيل المثال. إذا تعلمت مطابقة المجموعات بين بعضها البعض من الإطلاق إلى الإطلاق ، يمكنك ملاحظة كيف تتغير مجالات التخصص الرئيسية بمرور الوقت. في الواقع ، لا تزال أفكار تحسين الجودة والتطوير ممتلئة. إذا تمكنت من إيجاد الدافع الصحيح في نفسي ، فسوف أتطور أكثر.
مواد إضافية
فيديو حول التكتل الهرمي التكتل من الدورة حول البحث عن بنية في البيانات
حول تحجيم العلامات وتطبيعهابرنامج تعليمي حول المجموعات الهرمية من مكتبة SciPy ، والتي أخذتها كأساس لمهمتي
مقارنة بين أنواع المجموعات المختلفة باستخدام مكتبات sklearn كمثال
مكافأة صغيرة. اعتقدت أنه من المثير للاهتمام كيف يعمل شخص ما في مهمة ما. أريد أن أقول أنه في بعض القضايا قمت بالضخ بشكل جيد بينما كنت أقوم بهذا المشروع. جربت خيارات مختلفة ، درست ، فكرت في كيفية عمل هذا الشيء أو ذاك. في العديد من الأماكن ، تم تعويض الافتقار إلى قاعدة رياضية جيدة من خلال الحيلة وعدد كبير من المحاولات. وأود أن أشارك صحيفة
إيفرنوت التي عانيت منها أثناء العمل في المهمة. كانت التأملات فيه مخصصة لي فقط ، فهناك العديد من البدع وعدم الفهم ، ولكن أعتقد أن هذا أمر طبيعي.
UPD: لقد نشرت أجهزة الكمبيوتر المحمولة مع
إعداد البيانات ورمز
التجميع . لم أخطط لتحميل الرمز ، لذا فأنا آسف للجودة.