الجزء الأول R مقتطفات ويوجه
بالطبع ، تم إنشاء PostgreSQL منذ البداية كنظام DBMS عالمي ، وليس كنظام OLAP متخصص. لكن إحدى المزايا العظيمة لـ Postgres هي دعمها للغات البرمجة ، والتي يمكنك من خلالها صنع أي شيء منها. وبالنظر إلى وفرة اللغات الإجرائية المضمنة ، فإنه ببساطة لا مثيل لها. PL / R - تنفيذ الخادم لـ
R - اللغة المفضلة للمحللين - أحدهم. لكن المزيد عن ذلك لاحقًا.
R هي لغة مذهلة مع أنواع بيانات غريبة -
list ، على سبيل المثال ، يمكن أن تتضمن ليس فقط البيانات من أنواع مختلفة ، ولكن أيضًا الوظائف (بشكل عام ، اللغة انتقائية ، ولن نتحدث عن انتمائها لعائلة معينة ، حتى لا تتسبب في مناقشات تشتت الانتباه). يحتوي على نوع بيانات
data.frame جميل يحاكي جدول RDBMS - إنه مصفوفة تحتوي فيها الأعمدة على أنواع بيانات مختلفة شائعة على مستوى العمود. لذلك (ولأسباب أخرى) العمل مع قواعد البيانات في R هو مريح للغاية.
سنعمل على سطر الأوامر في بيئة
RStudio ونتصل بـ PostgreSQL من خلال
برنامج تشغيل ODBC RpostgreSQL . فهي سهلة التركيب.
نظرًا لأنه تم إنشاء R كنوع من أشكال اللغة
S لأولئك الذين يشاركون في الإحصائيات ، سنقدم أيضًا أمثلة من إحصائيات بسيطة برسومات بسيطة. ليس لدينا هدف لإدخال اللغة ، ولكن هناك هدف لإظهار تفاعل
R و PostgreSQL .
هناك ثلاث طرق لمعالجة البيانات المخزنة في PostgreSQL.
أولاً ، يمكنك ضخ البيانات من قاعدة البيانات بأي وسيلة مناسبة ، وحزمها ، على سبيل المثال ، في JSON - R يفهمها - ومعالجتها بشكل أكبر في R. هذه ليست الطريقة الأكثر فاعلية وبالتأكيد ليست الأكثر إثارة للاهتمام ، ولن نعتبرها هنا.
ثانيًا ، يمكنك التواصل مع قاعدة البيانات - القراءة منها وتفريغ البيانات فيها - من بيئة R كعميل ، باستخدام برنامج تشغيل ODBC / DBI ، ومعالجة البيانات في R. سنوضح كيف يتم ذلك.
وأخيرًا ، يمكنك إجراء المعالجة باستخدام أدوات R الموجودة بالفعل على خادم قاعدة البيانات ، باستخدام PL / R كلغة إجرائية متكاملة. هذا منطقي في عدد من الحالات ، لأنه في R هناك ، على سبيل المثال ، وسائل ملائمة لتجميع البيانات التي ليست في
pl/pgsql . سنظهر هذا أيضا.
من الطرق الشائعة استخدام الخيارين الثاني والثالث في مراحل مختلفة من المشروع: أولاً تصحيح الكود كبرنامج خارجي ، ثم نقله إلى القاعدة.
دعنا نبدأ. ترجمة لغة R. لذلك ، يمكنك اتباع الخطوات ، أو يمكنك تفريغ الرمز في برنامج نصي. مسألة ذوق: الأمثلة في هذه المقالة قصيرة.
أولاً ، بالطبع ، تحتاج إلى توصيل برنامج التشغيل المناسب:
# install.packages("RPostgreSQL") require("RPostgreSQL") drv <- dbDriver("PostgreSQL")
تبدو عملية التعيين في R ، كما ترى ، غريبة. بشكل عام ، في R a <- b يعني ذلك نفس b -> a ، ولكن الطريقة الأولى للكتابة أكثر شيوعًا.
سنأخذ قاعدة البيانات النهائية:
demobase النقل الجوي ، والتي تستخدمها
مواد تدريب Postgres Professional . في
هذه الصفحة يمكنك تحديد خيار قاعدة البيانات لتذوق (أي الحجم) وقراءة الوصف. نقوم بإعادة إنتاج مخطط البيانات من أجل الراحة:
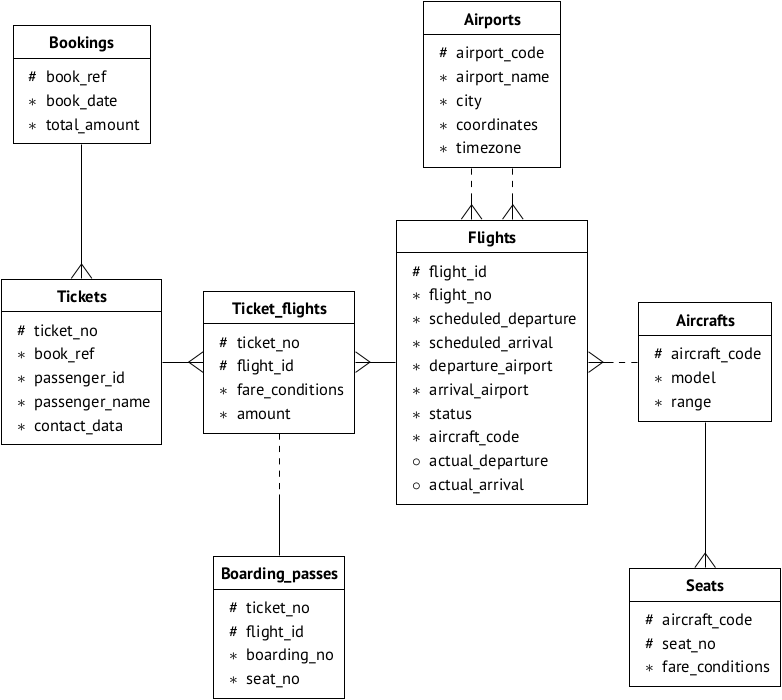
افترض أن القاعدة مثبتة على الخادم 192.168.1.100 وتسمى
demo . ربط:
con <- dbConnect(drv, dbname = "demo", host = "192.168.1.100", port = 5434, user = "u_r")
نواصل. دعونا نرى مع هذا الطلب الذي تتأخر رحلات طيران المدن إليه في الغالب:
SELECT ap.city, avg(extract(EPOCH FROM f.actual_arrival) - extract(EPOCH FROM f.scheduled_arrival))/60.0 t FROM airports ap, flights f WHERE ap.airport_code = f.departure_airport AND f.scheduled_arrival < f.actual_arrival AND f.departure_airport = ap.airport_code GROUP BY ap.city ORDER BY t DESC LIMIT 10;
للحصول على الدقائق المتأخرة ، استخدمنا
extract(EPOCH FROM ...) postgres
extract(EPOCH FROM ...) لاستخراج الثواني "المطلقة" من حقل
timestamp مقسومًا على 60.0 ، بدلاً من 60 ، لتجنب تجاهل الباقي عند القسمة ، على أنه صحيح. لا يمكن استخدام
EXTRACT MINUTE ، لأن هناك تأخيرات لأكثر من ساعة. نحن نحسب متوسط زمن التأخير بواسطة عامل
avg .
نقوم بتمرير النص إلى المتغير وإرسال الطلب إلى الخادم:
sql1 <- "SELECT ... ;" res1 <- dbGetQuery(con, sql1)
الآن سنكتشف الشكل الذي جاء به الطلب. للقيام بذلك ، فإن لغة R لها وظيفة
class() class (res1)
سيظهر أن النتيجة كانت معبأة في نوع
data.frame ، أي ، كما نتذكر ، تناظرية للجدول الأساسي: في الواقع ، إنها مصفوفة مع أعمدة من أنواع عشوائية. بالمناسبة ، إنها تعرف أسماء الأعمدة ، والأعمدة ، إن وجدت ، يمكن الوصول إليها ، على سبيل المثال ، مثل:
print (res1$city)
حان الوقت للتفكير في كيفية تصور النتائج. للقيام بذلك ، يمكنك أن ترى ما لدينا. على سبيل المثال ، حدد الجدول المناسب من
هذه القائمة :
- مخططات R-Bar (شريط)
- R-Boxplots (المخزون)
- R-Histograms
- الرسوم البيانية R- الخط (الرسوم البيانية)
- R-Scatterplots (نقطة)
يجب أن يوضع في الاعتبار أنه لكل نوع من أنواع المدخلات ، يتم توفير نوع بيانات مناسب للصورة. اختر مخططًا شريطيًا (الأشرطة المستلقيّة). يتطلب متجهين للقيم المحورية. النوع "متجه" في R هو ببساطة مجموعة من القيم من نفس النوع.
c() منشئ ناقل.
يمكنك إنشاء
data.frame من خلال نوع
data.frame النحو التالي:
Time <- res1[,c('t')] City <- res1[,c('city')] class (Time) class (City)
تبدو التعبيرات على الجانبين الأيمن غريبة ، لكنها تقنية ملائمة. علاوة على ذلك ، يمكن كتابة التعبيرات المختلفة بشكل مضغوط للغاية في R. في الأقواس المربعة قبل الفاصلة ، فهرس السلسلة ، بعد الفاصلة - فهرس العمود. حقيقة أن الفاصلة لا تساوي شيئًا يعني فقط أنه سيتم تحديد جميع القيم من العمود المقابل.
فئة الوقت
numeric ، وفئة المدينة
character . هذه هي أنواع المتجهات.
الآن يمكنك القيام بالتخيل نفسه. يجب تحديد ملف صورة.
png(file = "/home/igor_le/R/pics/bars_horiz.png")
بعد ذلك ، يتبع الإجراء الممل: تعيين المعلمات (
par ) للمخططات. ولا يعني أن كل شيء في حزم رسومات R كان بديهيًا. على سبيل المثال ، تحدد المعلمة
las موضع التسميات ذات القيم على طول المحاور بالنسبة إلى المحاور نفسها:
- 0 وبشكل افتراضي بالتوازي مع المحاور ؛
- 1 - أفقي دائمًا ؛
- 2 - عمودي على المحاور ؛
- 3 - دائما منتصبا
لن نرسم جميع المعلمات. بشكل عام ، هناك الكثير منها: الحقول ، المقاييس ، الألوان - ابحث عن ، جرب وقت فراغك.
par(las=1) par(mai=c(1,2,1,1))
أخيرًا ، نقوم ببناء رسم بياني من الأعمدة الراقد:
barplot(Time, names.arg=City, horiz=TRUE, xlab=" ()", col="green", main=" ", border="red", cex.names=0.9)
هذا ليس كل شيء. يجب أن أقول شيئًا أخيرًا:
dev.off()

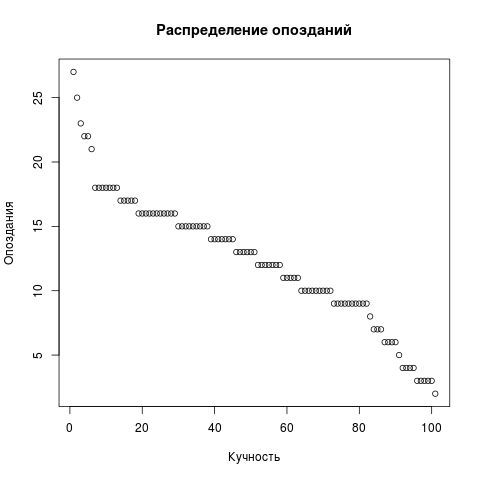
من أجل التغيير ، سنرسم الرسم البياني النقطي لوقت الاستجابة. إزالة LIMIT من الطلب ، والباقي هو نفسه. لكن المخطط المبعثر يحتاج إلى متجه واحد وليس اثنين.
Dots <- res2[,c('t')] png(file = "/home/igor_le/R/scripts/scatter.png") plot(input5, xlab="",ylab="",main=" ") dev.off()
للتصور ، استخدمنا الحزم القياسية. من الواضح أن R هي لغة شائعة وأن الحزم موجودة حول اللانهاية. يمكنك أن تسأل عن تلك المثبتة بالفعل مثل هذا:
library()
الجزء الثاني R يولد المتقاعدين
R مناسب للاستخدام ليس فقط لتحليل البيانات ، ولكن أيضًا لتوليدها. عندما تكون هناك وظائف إحصائية غنية ، لا يمكن أن يكون هناك مجموعة متنوعة من الخوارزميات لإنشاء تسلسلات عشوائية. على وجه الخصوص ، يمكنك استخدام توزيعات نموذجية (غوسية) وليست توزيعات (Zipf) نموذجية تمامًا لمحاكاة استعلامات قاعدة البيانات.
لكن المزيد عن ذلك في الجزء التالي.