يتيح لك التعلم الآلي جعل الخدمة أكثر ملاءمة للمستخدمين. ليس من الصعب البدء في تنفيذ التوصيات ، حيث يمكن الحصول على النتائج الأولى حتى بدون وجود بنية أساسية راسخة ، الشيء الرئيسي هو البدء. وعندها فقط لبناء نظام واسع النطاق. هكذا بدأ كل شيء على Booking.com. وقال فيكتور بيليك لـ HighLoad ++ Siberia ، وما أسفر عنه ، وما هي الأساليب المستخدمة حاليًا ، وكيف يتم إدخال النماذج في الإنتاج ، وتلك التي يجب مراقبتها. لم يتم ترك الأخطاء والمشكلات المحتملة وراء التقرير ، وسوف يساعد شخصًا ما على الالتفاف حول الضحلة ، وسيخرج شخص آخر بأفكار جديدة.
 نبذة عن المتحدث: يقدم
نبذة عن المتحدث: يقدم فيكتور بيليك منتجات التعلم الآلي في العمليات التجارية على Booking.com.
أولاً ، دعنا نرى أين تستخدم Booking.com التعلم الآلي في أي المنتجات.
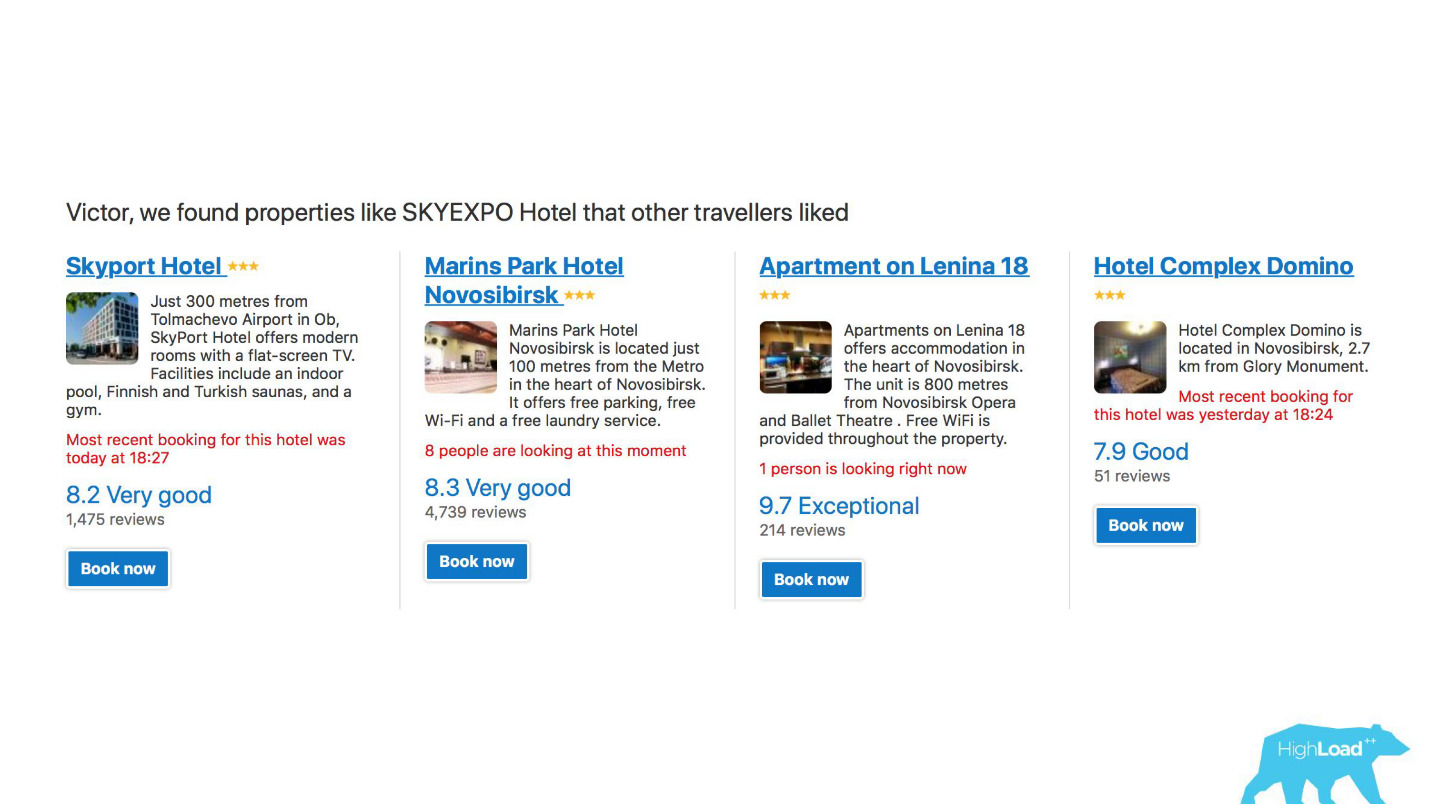
أولاً ، هذا عدد كبير من أنظمة التوصيات للفنادق والوجهات والتواريخ وفي نقاط مختلفة في مسار المبيعات وفي سياقات مختلفة. على سبيل المثال ، نحن نحاول تخمين المكان الذي ستذهب إليه عندما لا تدخل أي شيء في سطر البحث على الإطلاق.

هذه لقطة شاشة في حسابي ، وسأزور بالتأكيد اثنين من هذه المجالات هذا العام.
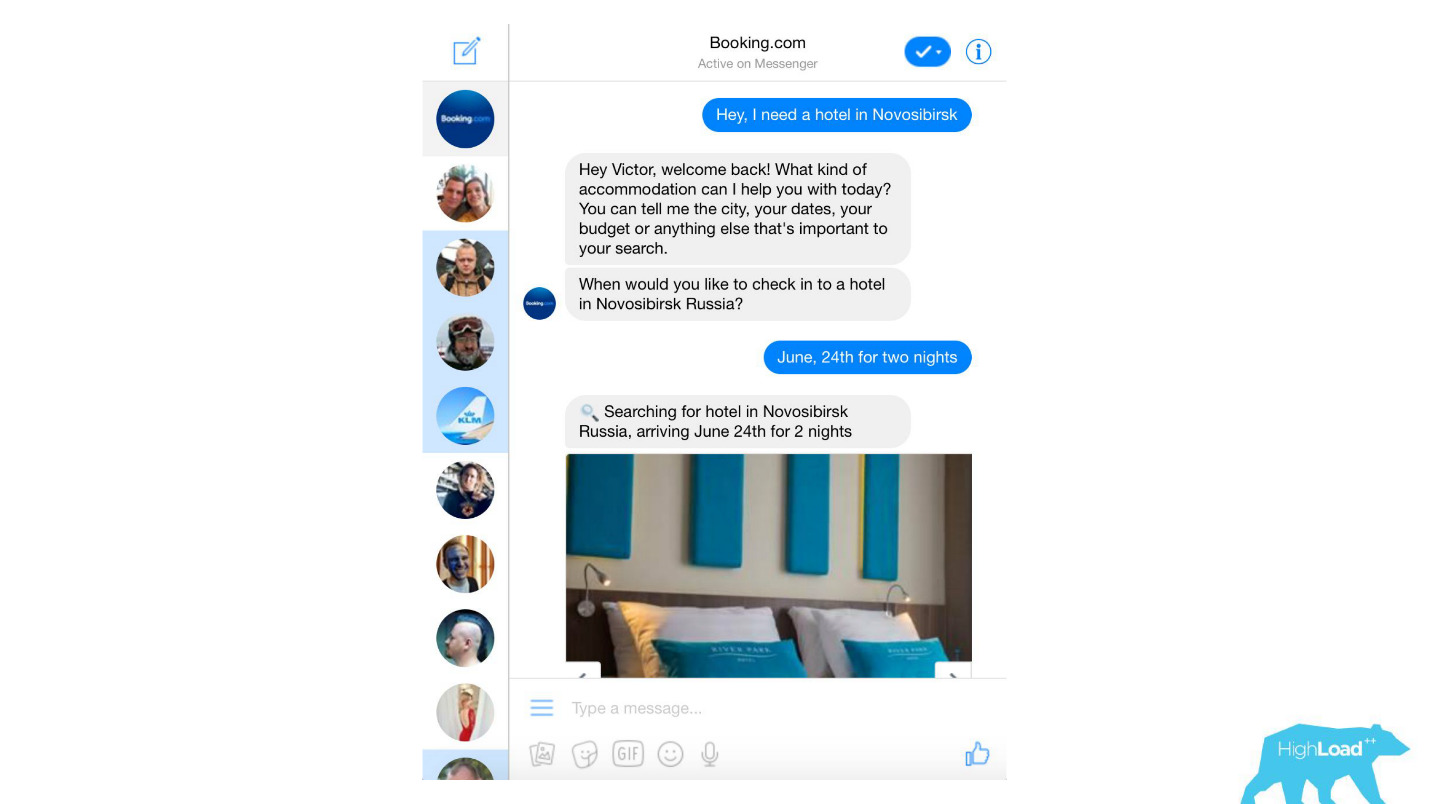
نعالج تقريبًا أي رسالة نصية من العملاء ، بدءًا من فلاتر الرسائل غير المرغوب فيها العادية إلى المنتجات المتطورة مثل Assistant و ChatToBook ، والتي تستخدم النماذج لتحديد النوايا والتعرف على الكيانات. بالإضافة إلى ذلك ، هناك نماذج غير ملحوظة ، على سبيل المثال ، كشف الاحتيال.
نقوم بتحليل المراجعات. تخبرنا النماذج لماذا يذهب الناس ، على سبيل المثال ، إلى برلين.
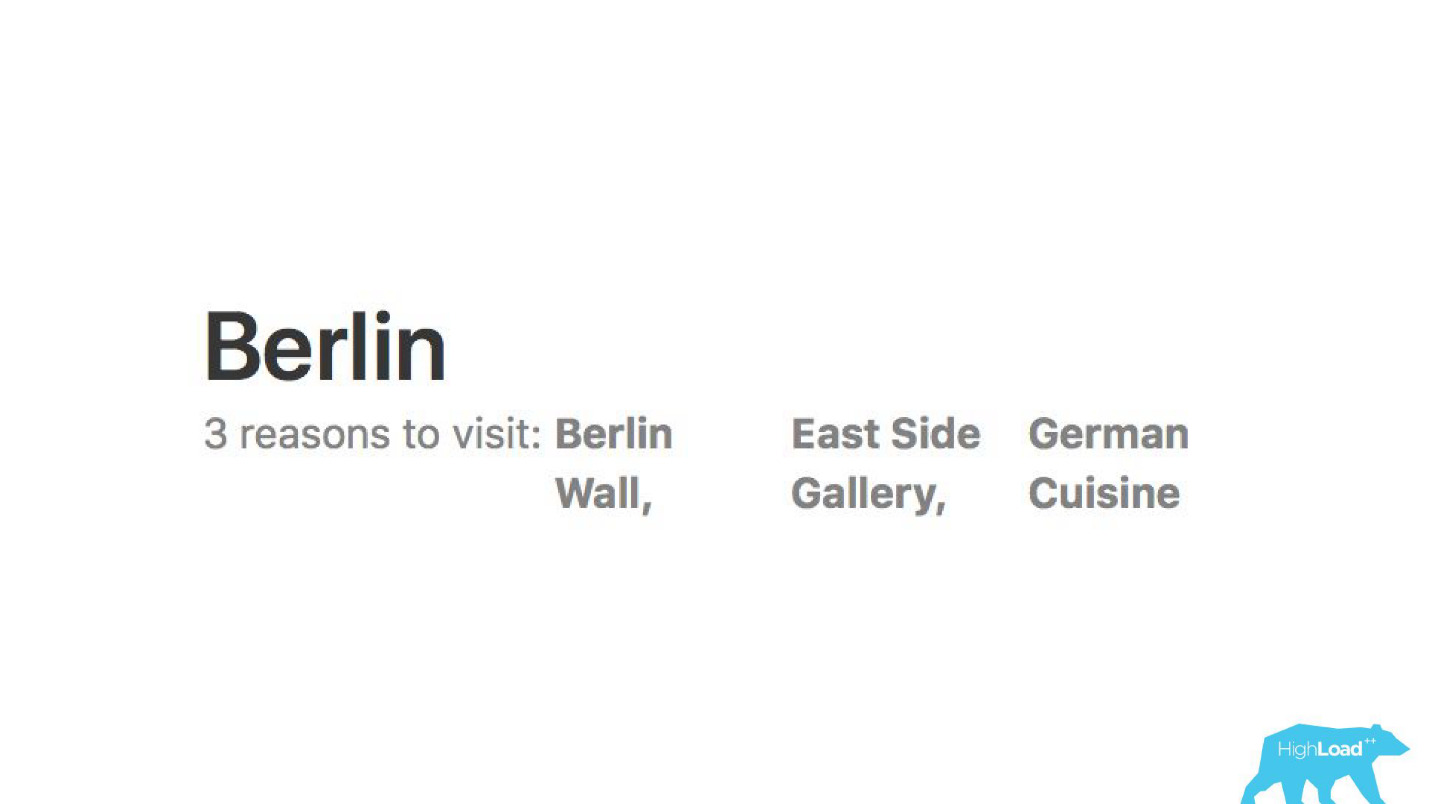
بمساعدة نماذج التعلم الآلي ، يتم تحليل سبب الإشادة بالفندق بحيث لا تضطر إلى قراءة آلاف المراجعات بنفسك.
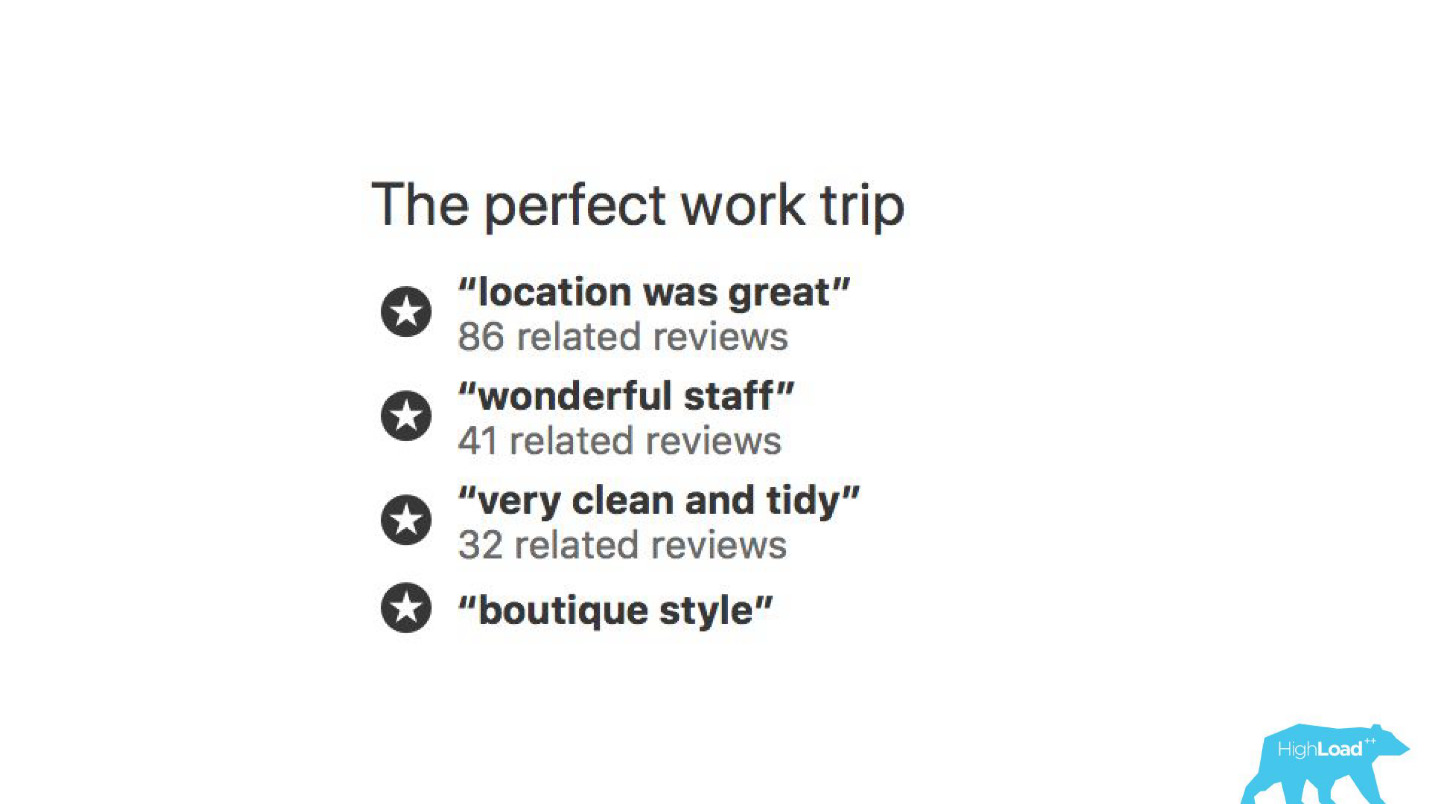
في بعض الأماكن في واجهتنا ، ترتبط كل قطعة تقريبًا بتنبؤات بعض النماذج. على سبيل المثال ، نحاول هنا التنبؤ بموعد بيع الفندق.
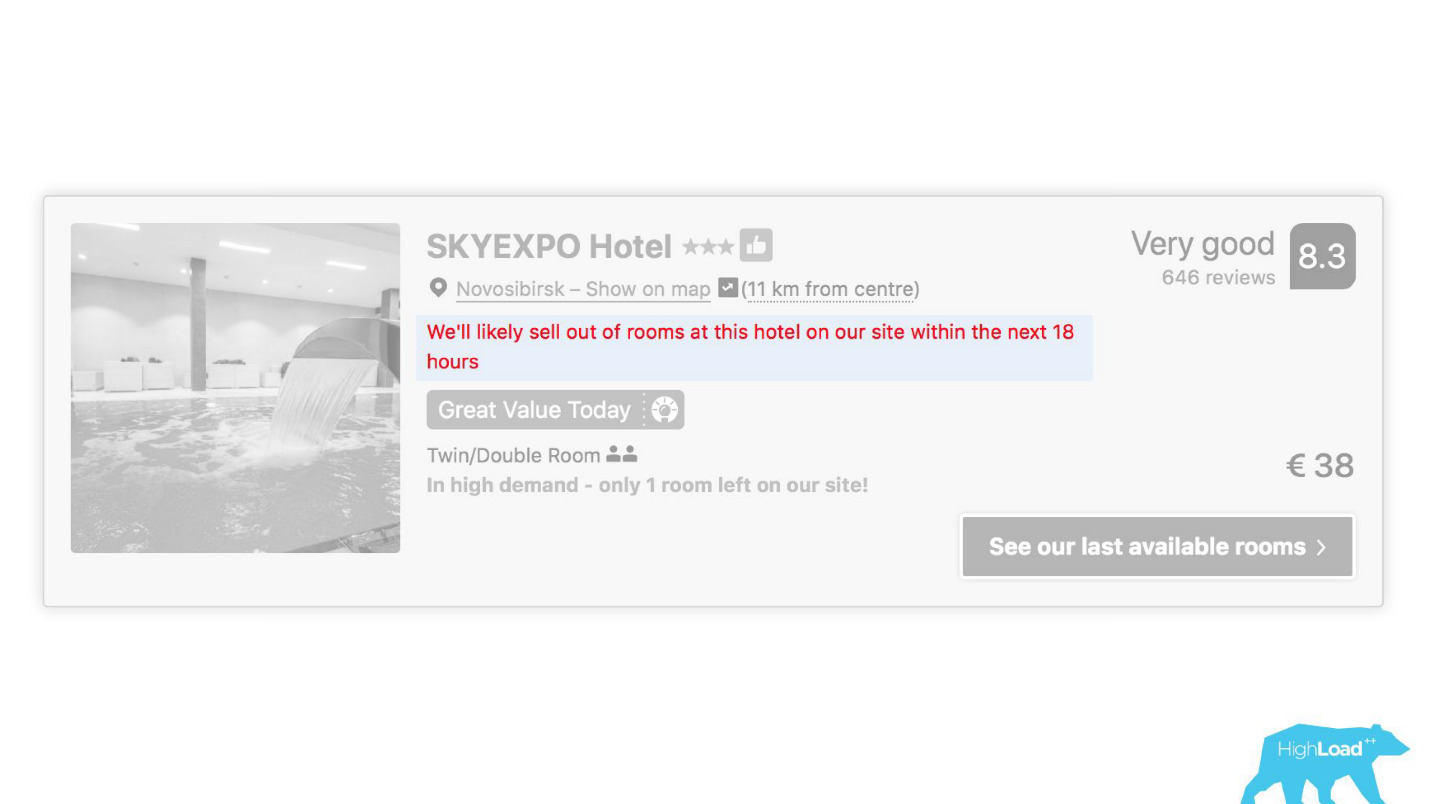
غالبًا ما نجد أنفسنا على حق - بعد 19 ساعة تم حجز الغرفة الأخيرة بالفعل.
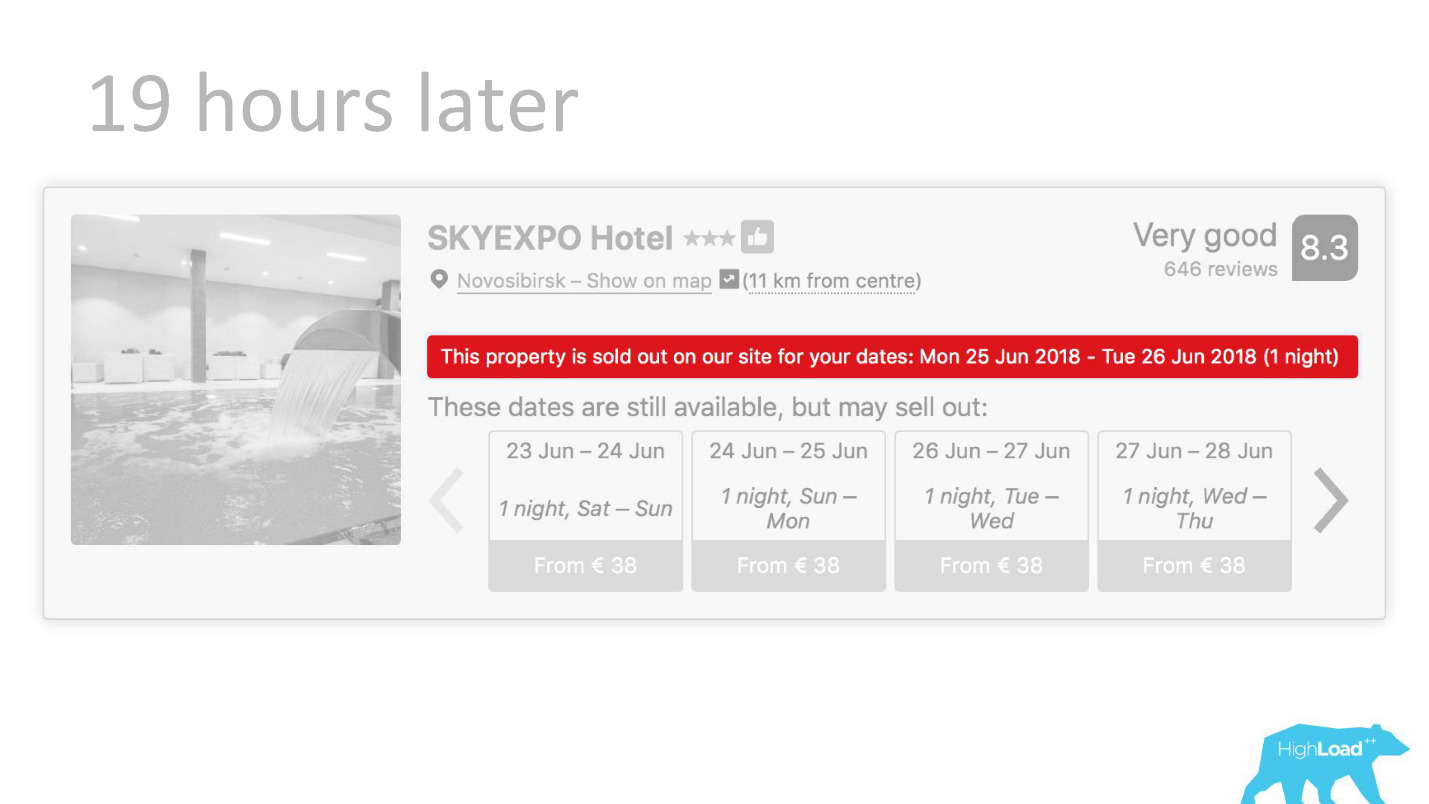
أو ، على سبيل المثال ، - شارة "العرض المفضل". نحن هنا نحاول إضفاء الطابع الرسمي على الذات: ما هو مثل هذا العرض المفيد. كيف نفهم أن الأسعار التي حددها الفندق لهذه التواريخ جيدة؟ بعد كل شيء ، هذا بالإضافة إلى السعر ، يعتمد على العديد من العوامل ، مثل الخدمات الإضافية ، وغالبًا حتى لأسباب خارجية ، على سبيل المثال ، إذا تم عقد كأس العالم أو مؤتمر تقني كبير في هذه المدينة الآن.
بدء التنفيذ
دعونا نعود قبل بضع سنوات ، في عام 2015. بعض المنتجات التي تحدثت عنها موجودة بالفعل. علاوة على ذلك ، فإن النظام الذي سأتحدث عنه اليوم ليس بعد. كيف تم التنفيذ في ذلك الوقت؟ كانت الأمور ، بصراحة تامة ، ليست شديدة. والحقيقة أن لدينا مشكلة كبيرة ، جزء منها تقني ، وجزء تنظيمي.
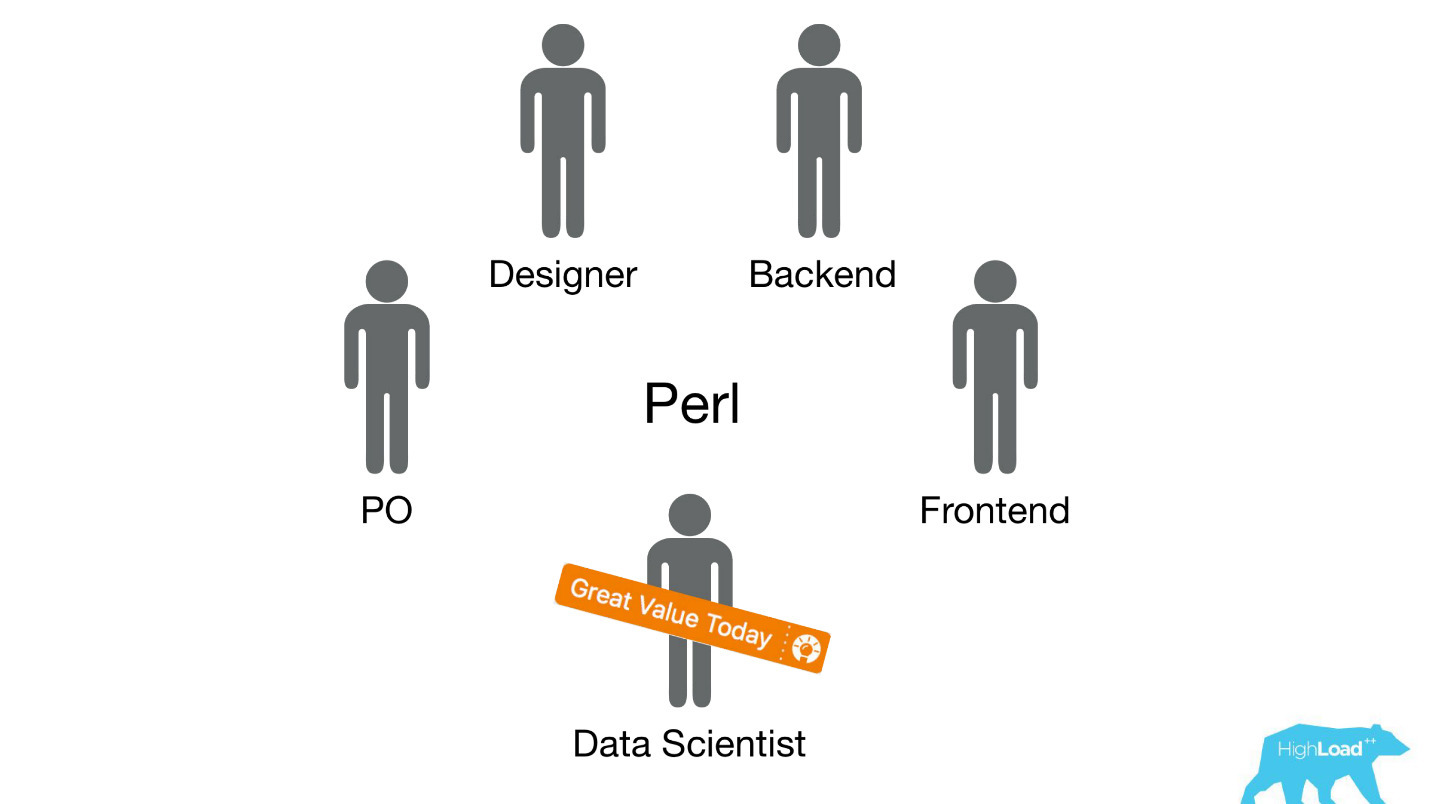
لقد أرسلنا علماء البيانات إلى الفرق الحالية متعددة الوظائف التي تعمل على مشكلة مستخدم محددة وتوقعت منهم تحسين المنتج بطريقة أو بأخرى.
في معظم الأحيان ، تم بناء هذه القطع من المنتج على مكدس Perl. هناك مشكلة واضحة مع Perl - لم يتم تصميمها للحوسبة المكثفة ، وقد تم تحميل الواجهة الخلفية بالفعل بأشياء أخرى. علاوة على ذلك ، لا يمكن تحديد أولويات تطوير أنظمة جادة من شأنها حل هذه المشكلة ضمن الفريق ، لأن تركيز الفريق ينصب على حل مشكلة مستخدم ، وليس على حل مشكلة مستخدم باستخدام التعلم الآلي. لذلك ، سيعارض مالك المنتج (PO) ذلك بشدة.
دعونا نرى كيف حدث ذلك الحين.
لم يكن هناك سوى خيارين - أعرف هذا بالتأكيد ، لأنه في ذلك الوقت كنت أعمل للتو في مثل هذا الفريق وساعد علماء البيانات على إدخال نماذجهم الأولى في المعركة.
كان الخيار الأول
تجسيد التنبؤات . لنفترض أن هناك نموذجًا بسيطًا للغاية به ميزتان فقط:
- البلد الذي يوجد فيه الزائر ؛
- المدينة التي يبحث فيها عن فندق.
نحن بحاجة إلى توقع احتمالية وقوع حدث ما. نحن نفجر جميع ناقلات المدخلات: لنقل 100.000 مدينة و 200 دولة - ما مجموعه 20 مليون خط في MySQL. يبدو وكأنه خيار وظيفي بالكامل لإخراج بعض أنظمة التصنيف الصغيرة أو نماذج بسيطة أخرى للإنتاج.

خيار آخر هو
تضمين التنبؤات مباشرة في كود الواجهة الخلفية . هناك قيود كبيرة - مئات ، ربما الآلاف من المعاملات - هذا كل ما يمكننا تحمله.

من الواضح أنه لا أحد ولا الطريقة الأخرى تسمح لك بإخراج نوع من النموذج المعقد على الأقل في الإنتاج. وقد حد هذا من مركز البيانات والنجاحات التي يمكن أن يحققوها من خلال تحسين المنتجات. من الواضح أنه كان لا بد من حل هذه المشكلة بطريقة أو بأخرى.
خدمة التنبؤ
أول شيء فعلناه هو خدمة التنبؤ. من المحتمل أن تكون أبسط معمارية تظهر على الإطلاق على Habré و HighLoad ++ أقل.
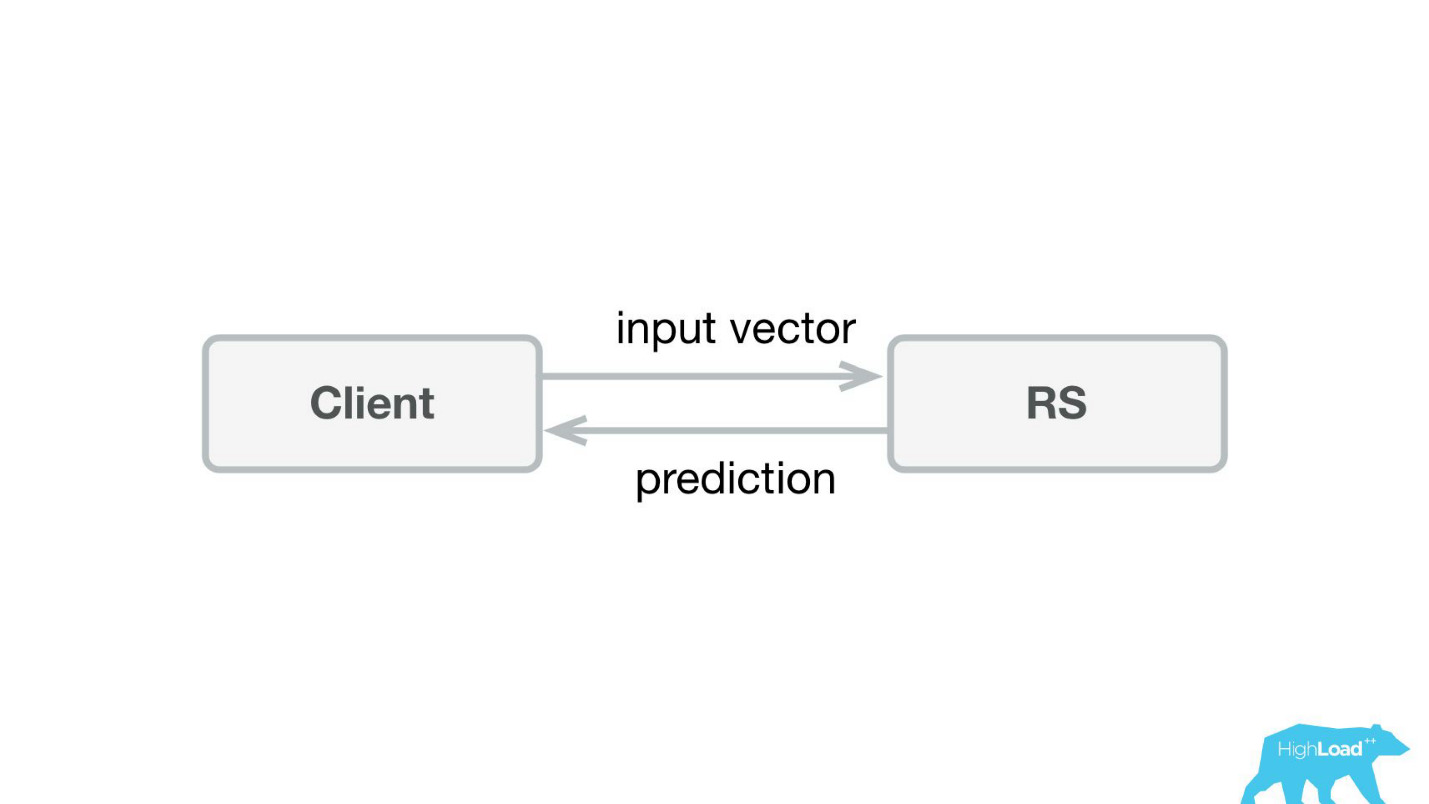
كتبنا تطبيقًا صغيرًا في Scala + Akka + Spray والذي أخذ ببساطة المتجهات الواردة وأعاد التنبؤ. في الواقع ، أنا ماكرة قليلاً - كان النظام أكثر تعقيدًا بعض الشيء ، لأننا كنا بحاجة إلى مراقبته ونشره بطريقة أو بأخرى. في الواقع ، بدا كل شيء مثل هذا:
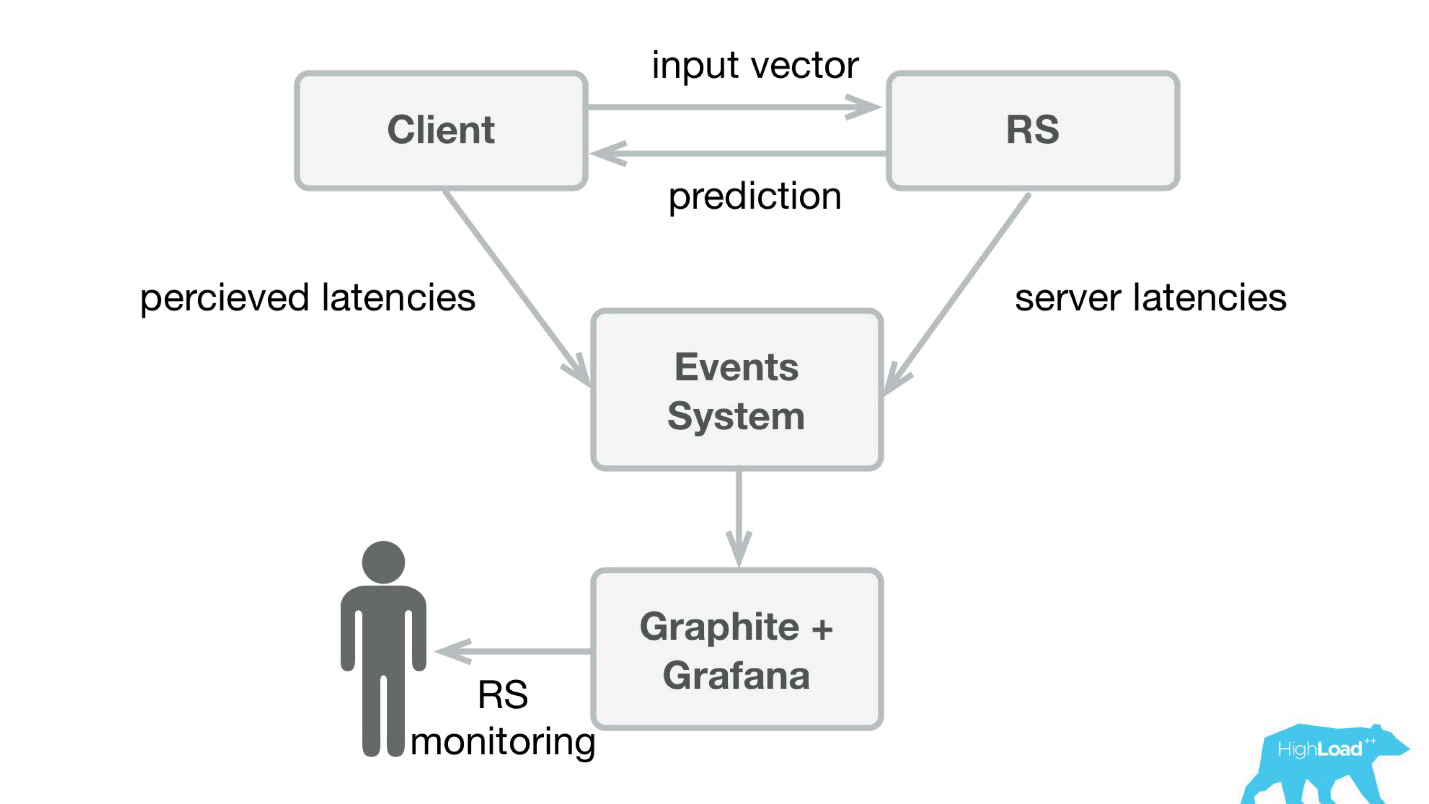
Booking.com لديها نظام أحداث - شيء مثل مجلة لجميع الأنظمة. من السهل جدًا الكتابة هناك ، ومن السهل جدًا إعادة توجيه هذا الدفق. في البداية ، كنا بحاجة إلى إرسال القياس عن بعد للعميل إلى الجرافيت وجرافانا مع فترات انتظار ملحوظة ومعلومات تفصيلية من جانب الخادم.

لقد أنشأنا مكتبات عملاء بسيطة لـ Perl - أخفيت RPC بالكامل في مكالمة محلية ، ووضعنا عدة نماذج هناك ، وبدأت الخدمة في الإقلاع. كان بيع هذا المنتج أمرًا بسيطًا للغاية ، لأننا حصلنا على فرصة
لتقديم نماذج أكثر تعقيدًا وقضاء وقت أقل بكثير .
بدأ علماء البيانات في العمل مع قيود أقل بكثير ، وفي بعض الحالات تقلص عمل الأخصائيين الخلفيين إلى خط واحد.
توقعات المنتج
ولكن دعنا نعود لفترة وجيزة إلى كيفية استخدامنا لهذه التوقعات في المنتج.
هناك نموذج يجعل التنبؤات مبنية على حقائق معروفة. بناءً على هذا التوقع ، نقوم بتغيير واجهة المستخدم بطريقة أو بأخرى. هذا بالطبع ليس السيناريو الوحيد لاستخدام التعلم الآلي في شركتنا ، ولكنه شائع جدًا.
ما هي مشكلة إطلاق مثل هذه الميزات؟ الشيء هو أن هذين شيئين في زجاجة واحدة: نموذج وتغيير في واجهة المستخدم. من الصعب للغاية فصل التأثيرات عن كليهما.
تخيل إطلاق شارة "العرض المفضل" كجزء من تجربة AB. إذا لم تقلع - لا يوجد تغيير ذي دلالة إحصائية في المقاييس المستهدفة - فمن غير المعروف ما هي المشكلة: شارة غير مفهومة ، صغيرة ، غير واضحة أو نموذج سيئ.
بالإضافة إلى ذلك ، يمكن أن تتدهور النماذج ، ويمكن أن يكون هناك العديد من الأسباب لذلك. ما عمل بالأمس لا يعمل بالضرورة اليوم. بالإضافة إلى ذلك ، نحن دائمًا في وضع البدء البارد ، ونربط باستمرار المدن والفنادق الجديدة ، ويأتي إلينا أشخاص من مدن جديدة. نحن بحاجة إلى أن نفهم بطريقة أو بأخرى أن النموذج لا يزال يعمم جيدًا في هذه الأجزاء من المساحة الواردة.

ربما كانت آخر حالة معروفة لتدهور النموذج هي القصة مع أليكس. على الأرجح ، نتيجة لإعادة التدريب ، بدأت في فهم الضوضاء العشوائية ، كطلب للضحك ، وبدأت في الضحك في الليل ، مما أخاف أصحابها.
مراقبة التنبؤ
من أجل مراقبة التوقعات ، قمنا بتعديل نظامنا بشكل طفيف (الرسم البياني أدناه). بنفس الطريقة ، من نظام الأحداث ، قمنا بإعادة توجيه الدفق إلى Hadoop وبدأنا في الحفظ ، بالإضافة إلى كل ما تم حفظه من قبل ، أيضًا جميع ناقلات المدخلات وجميع التوقعات التي وضعها نظامنا. ثم ، باستخدام Oozie ، قمنا بتجميعها في MySQL وأظهرناها من خلال تطبيق ويب صغير لأولئك المهتمين بنوع من الخصائص النوعية للنماذج.
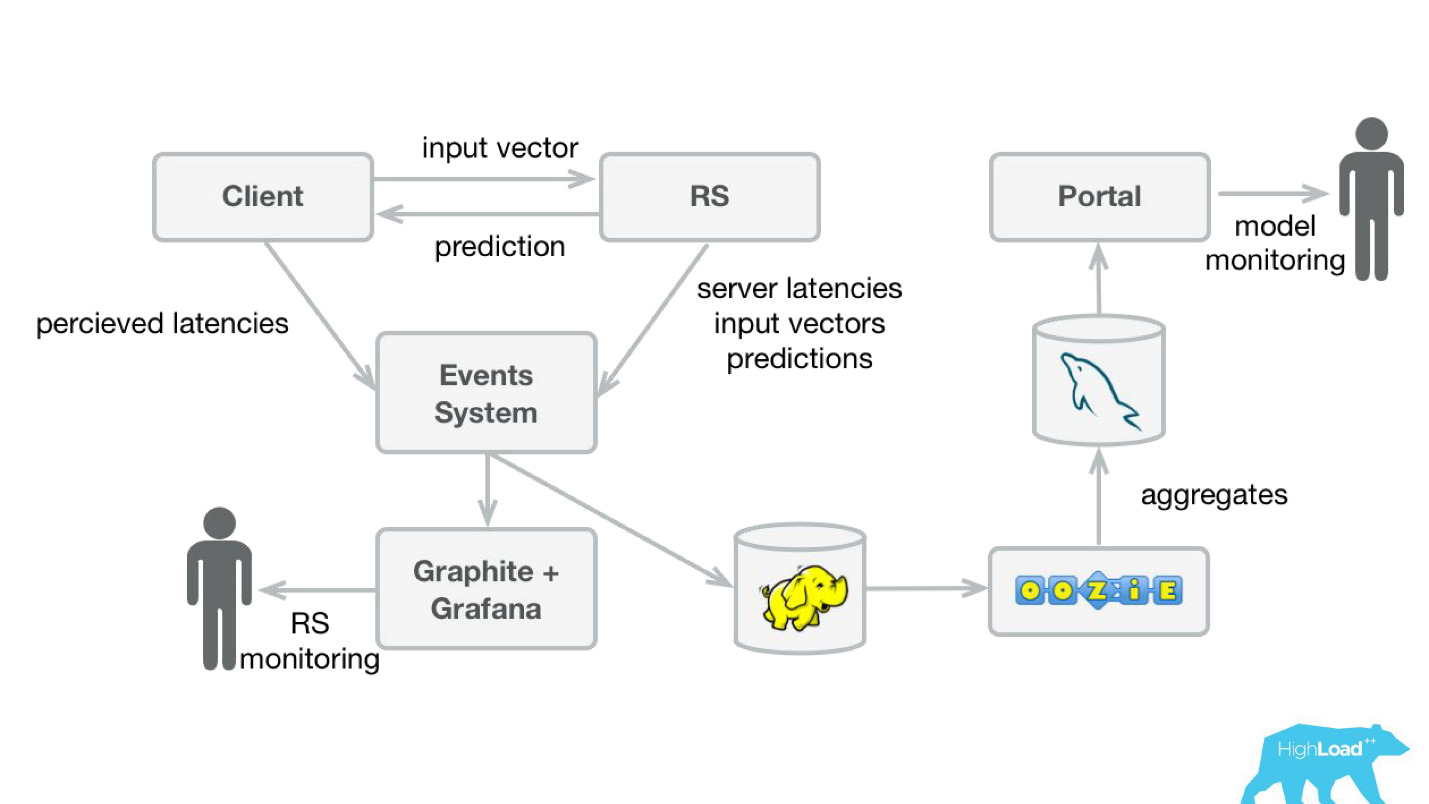
ومع ذلك ، من المهم معرفة ما يجب إظهاره هناك. الشيء هو أنه في حالتنا ، من الصعب جدًا حساب المقاييس المعتادة المستخدمة في تدريب النموذج ، لأنه غالبًا ما يكون لدينا تأخير كبير في التسميات.
اعتبر هذا كمثال. نريد أن نتنبأ إذا كان المستخدم في إجازة بمفرده أو مع العائلة. نحتاج إلى هذا التنبؤ عندما يختار الشخص فندقًا ، ولكن لا يمكننا معرفة الحقيقة إلا في عام واحد. بعد أن ذهب في إجازة ، سيتلقى المستخدم دعوة لترك مراجعة ، حيث سيكون هناك سؤال من بين أمور أخرى سواء كان هناك بمفرده أو مع عائلته.
أي أنك تحتاج إلى تخزين كل التوقعات التي تم إجراؤها على مدار العام في مكان ما ، وحتى يمكنك العثور بسرعة على التطابقات مع التصنيفات الواردة. بدا الأمر وكأنه استثمار خطير للغاية ، وربما حتى استثمار ثقيل. لذلك ، حتى تعاملنا مع هذه المشكلة ، قررنا القيام بشيء أبسط.
تحول هذا "الأبسط" إلى مجرد رسم
بياني للتنبؤات التي وضعها النموذج.
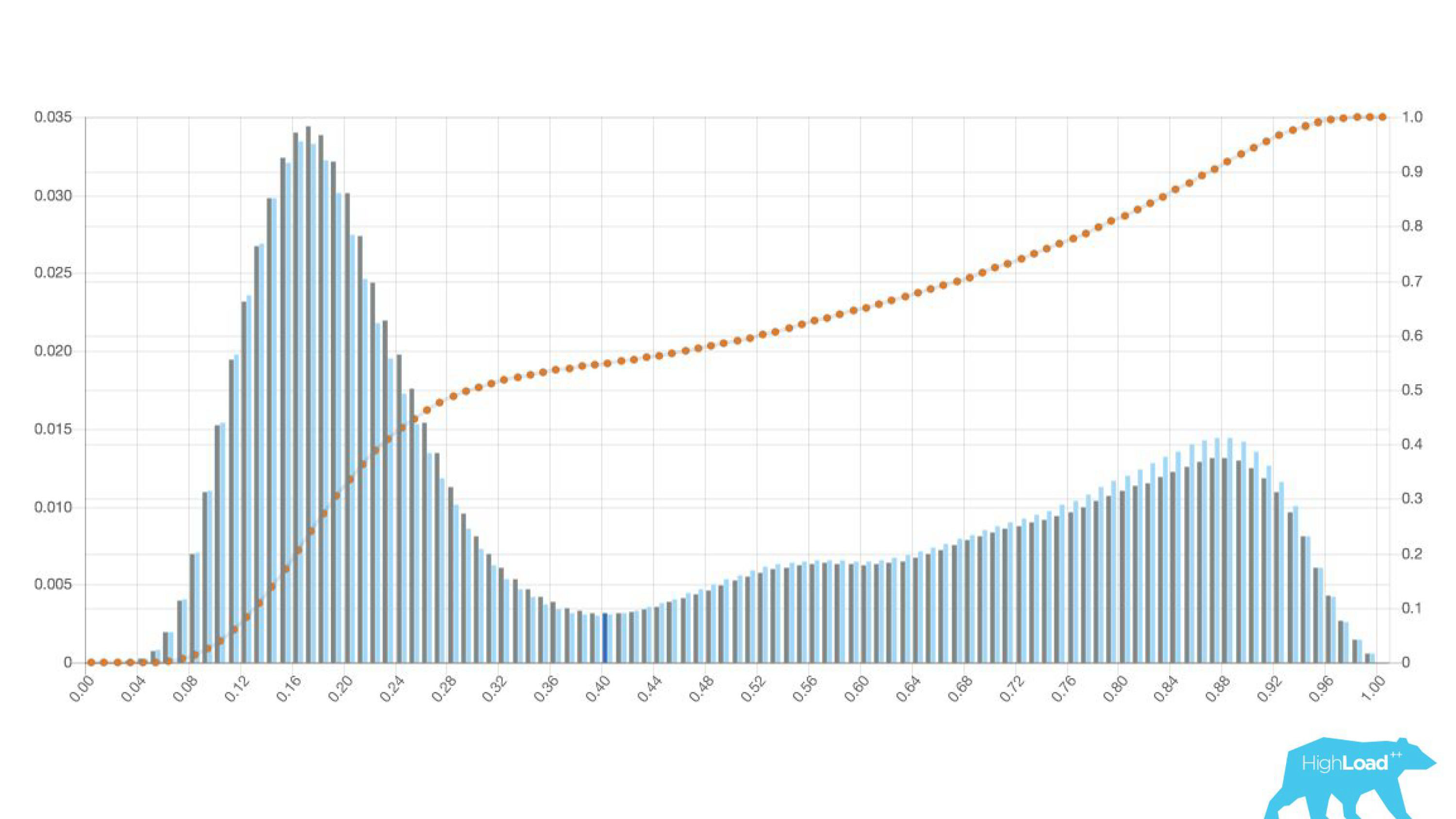
يظهر على الرسم البياني انحدار لوجستي يتنبأ بما إذا كان المستخدم سيغير تاريخ رحلته أم لا. يمكن ملاحظة أنه يقسم المستخدمين جيدًا إلى فئتين: على اليسار ، التل هو أولئك الذين لن يفعلوا ذلك ؛ التل إلى اليمين هو أولئك الذين يفعلون ذلك.
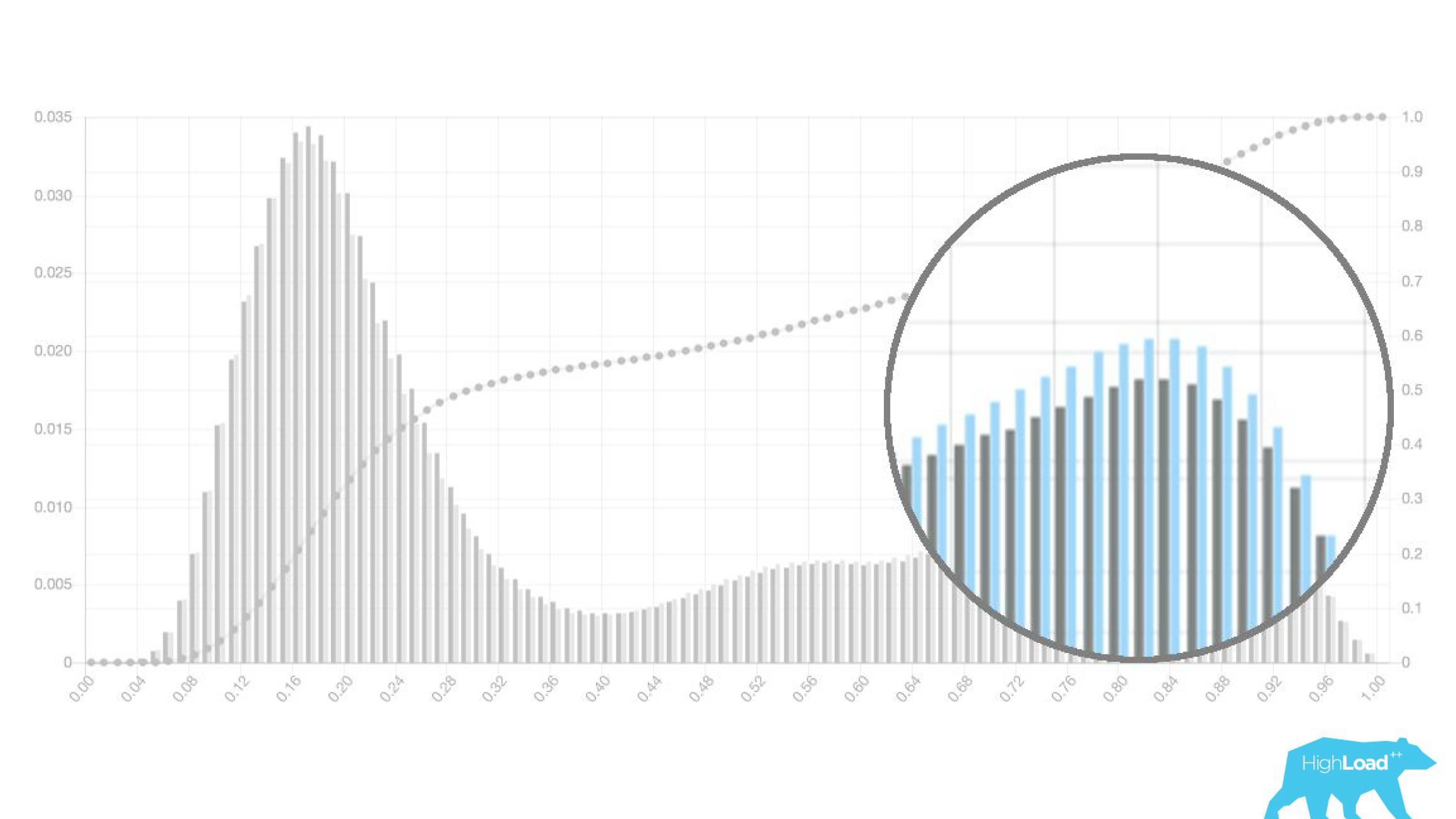
في الواقع ، نحن نعرض رسمين بيانيين: أحدهما للفترة الحالية ، والآخر للفترة السابقة. من الواضح أن هذا الأسبوع (هذا مخطط أسبوعي) يتنبأ النموذج بتغيير التواريخ أكثر قليلاً. من الصعب القول على وجه اليقين ما إذا كانت موسمية ، أو نفس التدهور مع مرور الوقت.
أدى هذا إلى تغيير في عمل مرضى البيانات ، الذين توقفوا عن إشراك الآخرين وبدأوا في تكرار نماذجهم بشكل أسرع. أرسلوا نماذج للإنتاج في التشغيل الجاف مع مهندسي الخلفية. أي أنه تم جمع المتجهات ، وقدم النموذج تنبؤًا ، ولكن لم يتم استخدام هذه التنبؤات بأي شكل من الأشكال.
في حالة الشارة ، لم نعرض أي شيء ، كما كان من قبل ، ولكننا جمعنا الإحصائيات. سمح لنا هذا بعدم إضاعة الوقت مسبقًا في المشاريع الفاشلة. وفرنا الوقت للواجهة الأمامية والمصممين للتجارب الأخرى.
طالما أن مركز البيانات غير متأكد من أن النموذج يعمل بالطريقة التي يريدها ، فهو ببساطة لا يشرك الآخرين في هذه العملية.من المثير للاهتمام أن نرى كيف تتغير الرسوم البيانية في أقسام مختلفة.
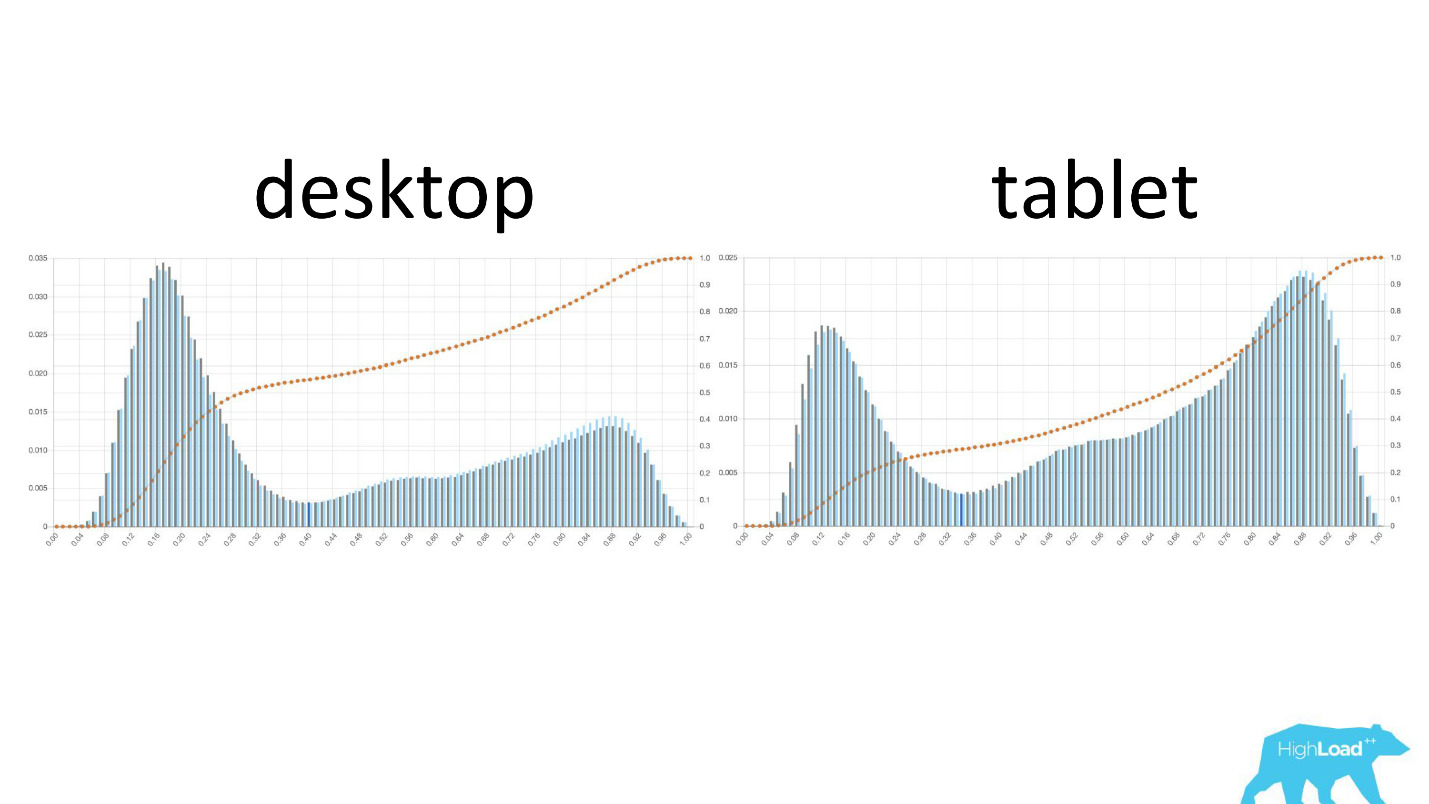
على اليسار هو احتمال تغيير التواريخ على سطح المكتب ، على اليمين على الأجهزة اللوحية. من الواضح أنه على الأجهزة اللوحية يتنبأ النموذج بتغيير أكثر احتمالية للتواريخ. هذا على الأرجح يرجع إلى حقيقة أن الجهاز اللوحي غالبًا ما يستخدم لتخطيط السفر وأقل في كثير من الأحيان للحجوزات.
من المثير للاهتمام أيضًا معرفة كيف تتغير هذه الرسوم البيانية أثناء انتقال المستخدمين خلال مسار المبيعات.
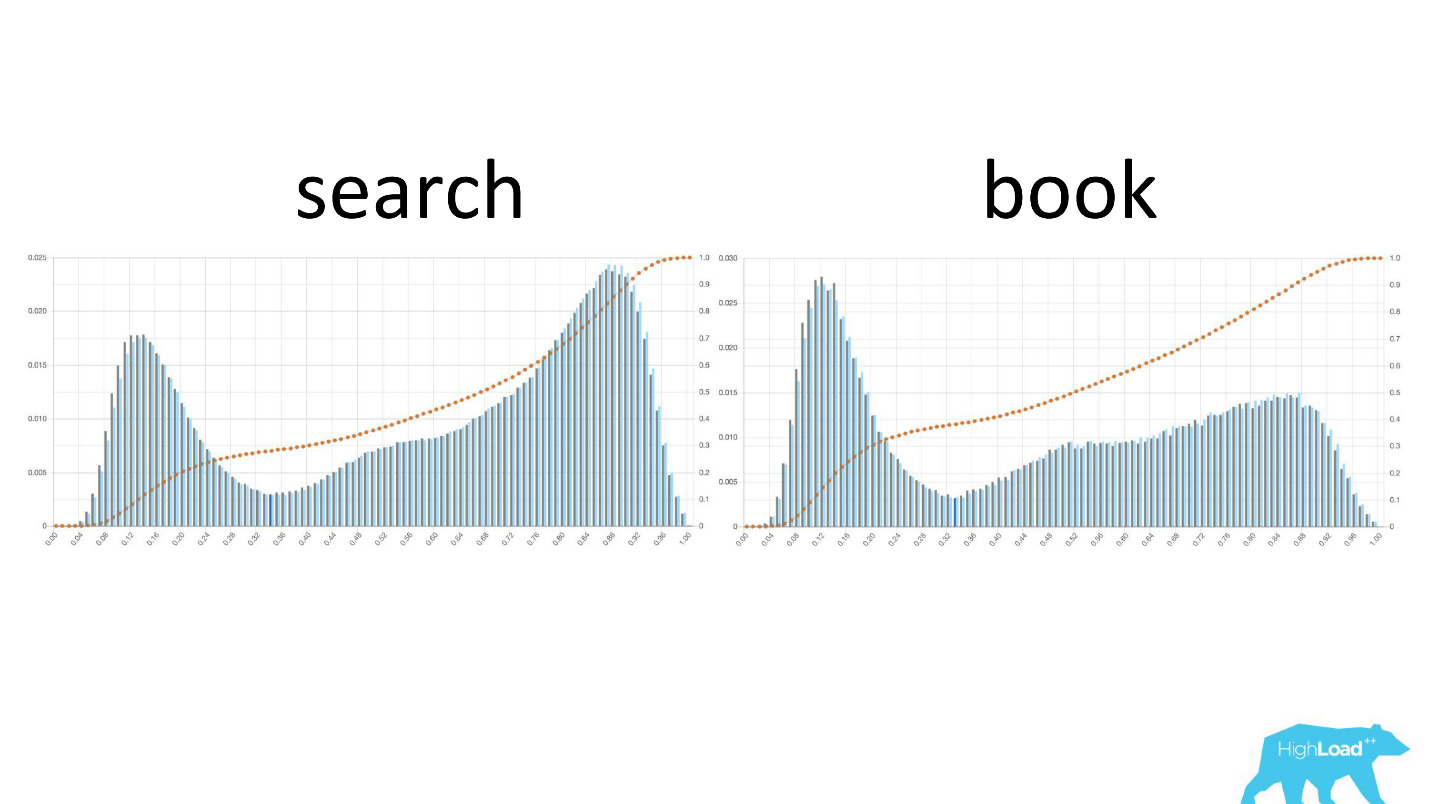
على اليسار يوجد احتمال لتغيير التواريخ في صفحة البحث ، على اليمين في صفحة الحجز الأولى. يمكن ملاحظة أن عددًا أكبر بكثير من الأشخاص الذين قرروا بالفعل في مواعيدهم يصلون إلى صفحة الحجز.
لكن هذه كانت رسومات جيدة. كيف تبدو السيئة؟ بطرق مختلفة للغاية. في بعض الأحيان يكون الأمر مجرد ضجيج ، وأحيانًا يكون تلة ضخمة ، مما يعني أن النموذج لا يمكنه فصل أي فئتين من التنبؤات بشكل فعال.

في بعض الأحيان تكون هذه قمم ضخمة.
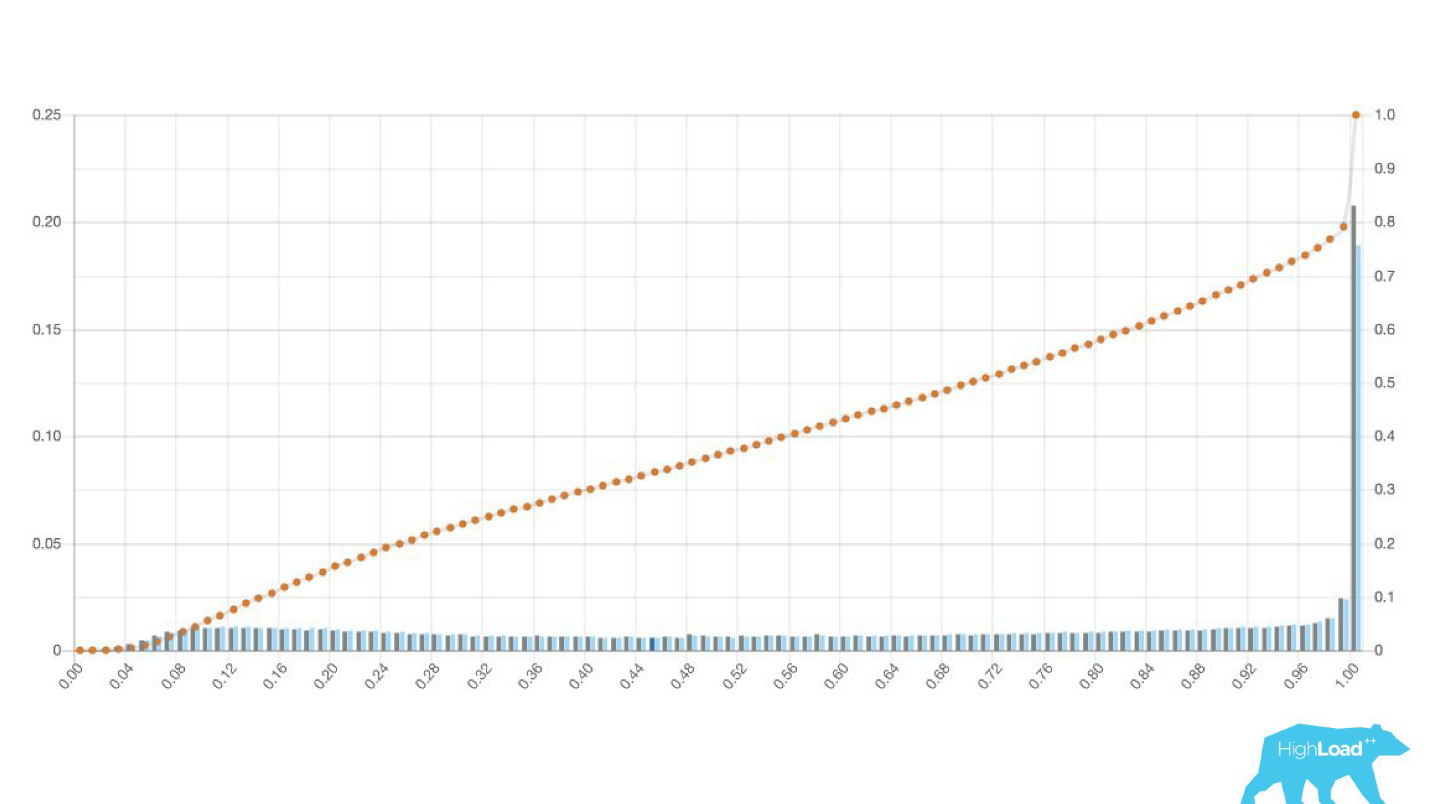
هذا أيضًا انحدار لوجستي ، وحتى مرحلة ما أظهر صورة جميلة مع تلالين ، لكن في صباح أحد الأيام أصبح الأمر كذلك.
من أجل فهم ما حدث في الداخل ، تحتاج إلى فهم كيفية حساب الانحدار اللوجستي.
مرجع سريع
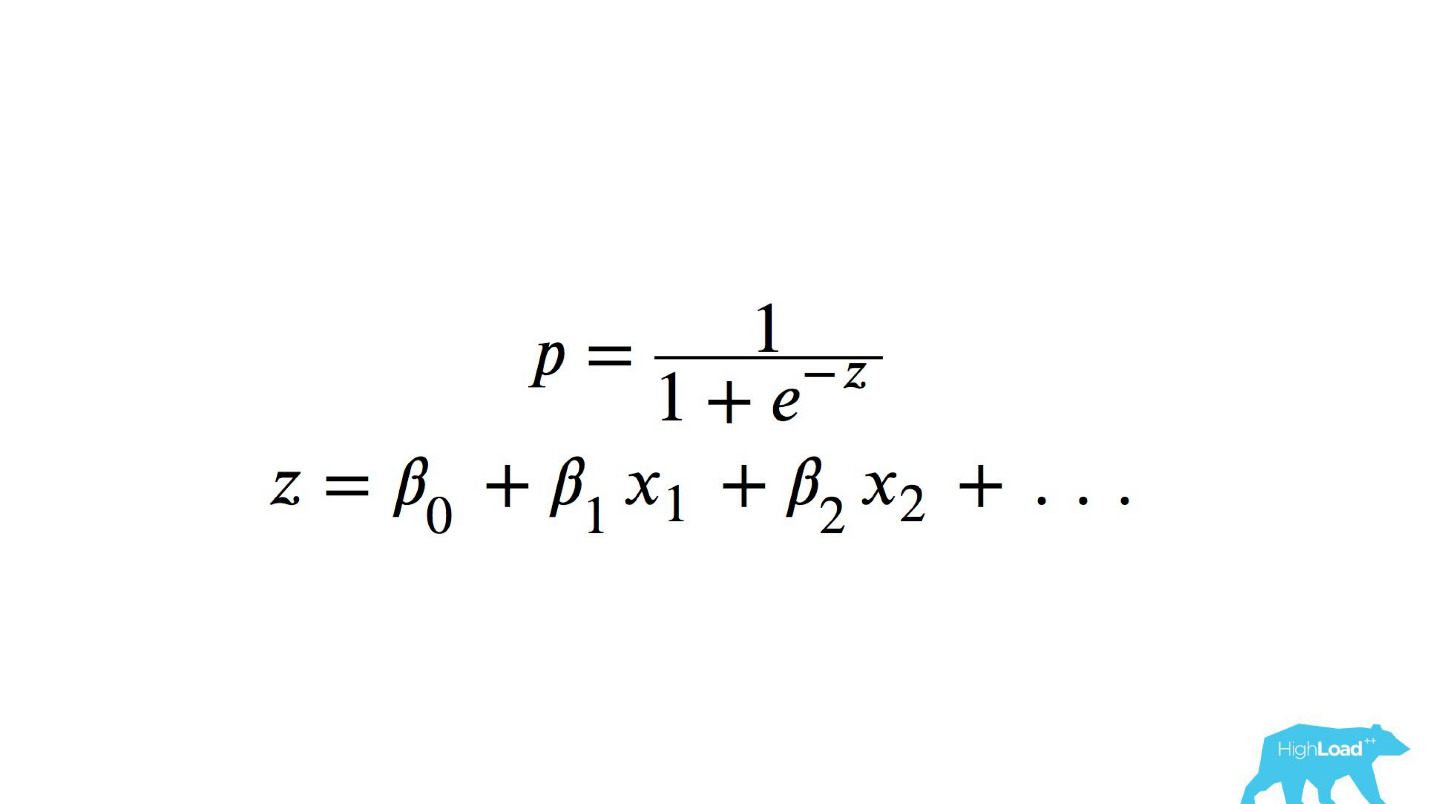
هذه هي وظيفة لوجستية للمنتج العادي ، حيث x
n هي بعض الميزات. واحدة من هذه الميزات كانت سعر ليلة في فندق (باليورو).
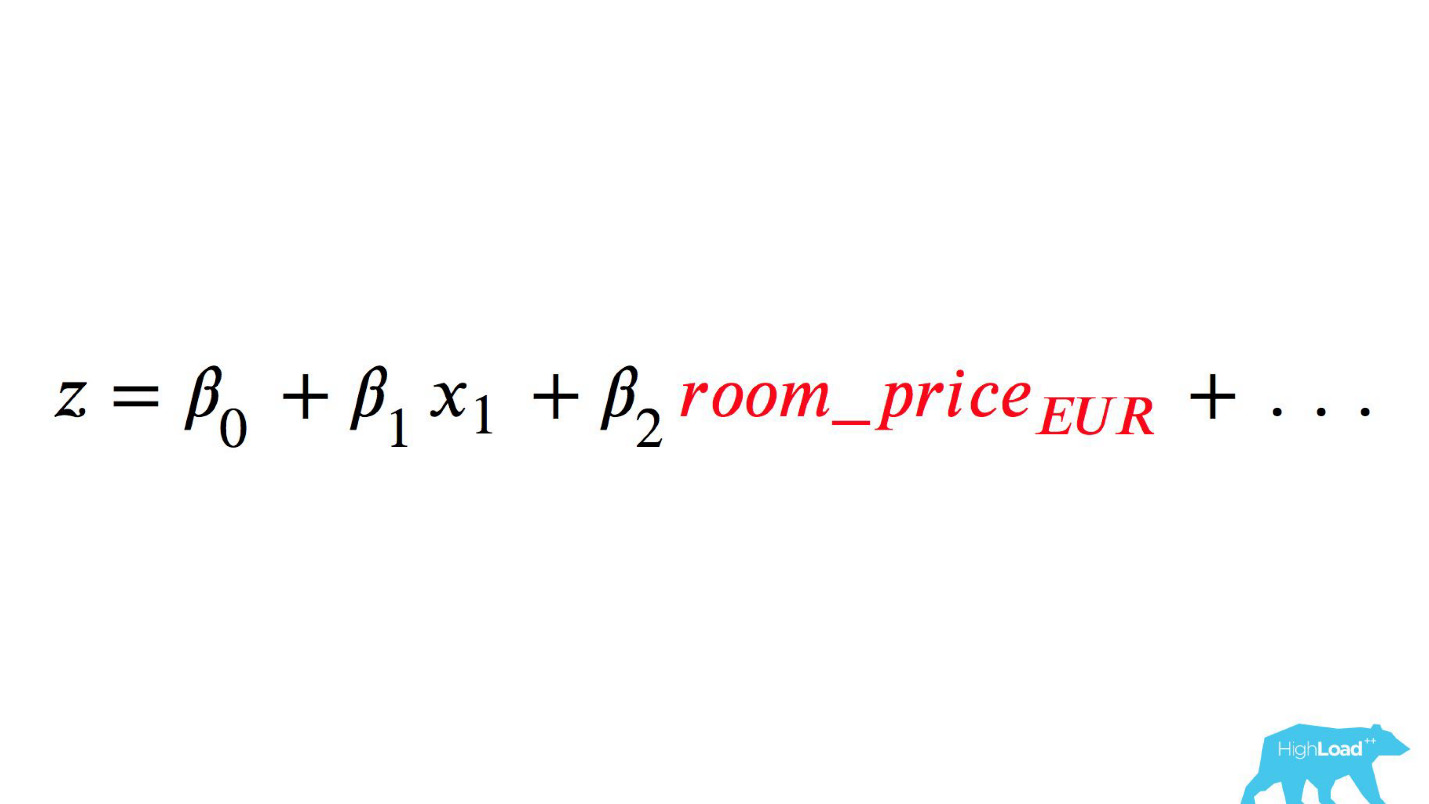
سيكون استدعاء هذا النموذج شيئًا مثل هذا:
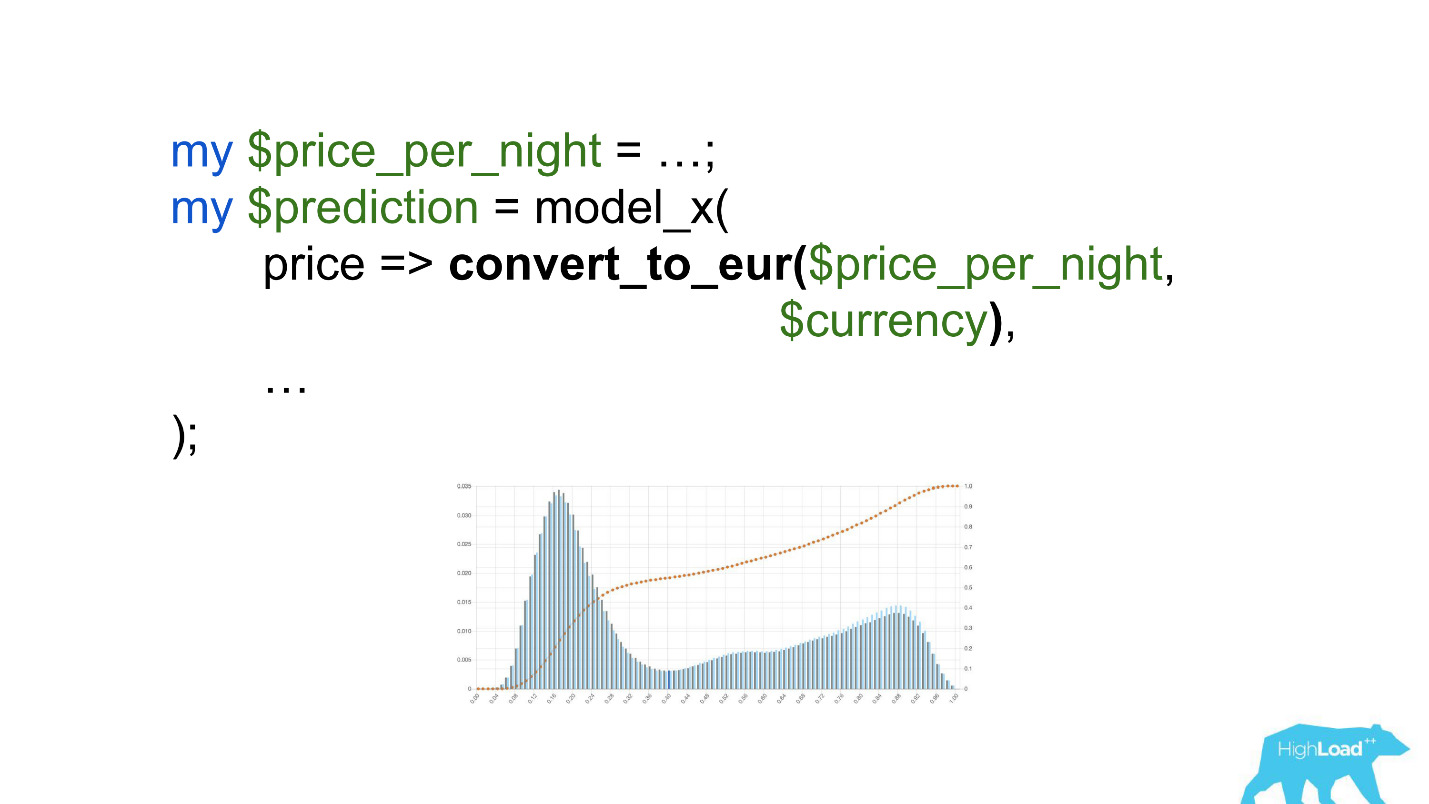
انتبه إلى الاختيار. كان من الضروري تحويل السعر إلى اليورو ، لكن المطور نسي ذلك.
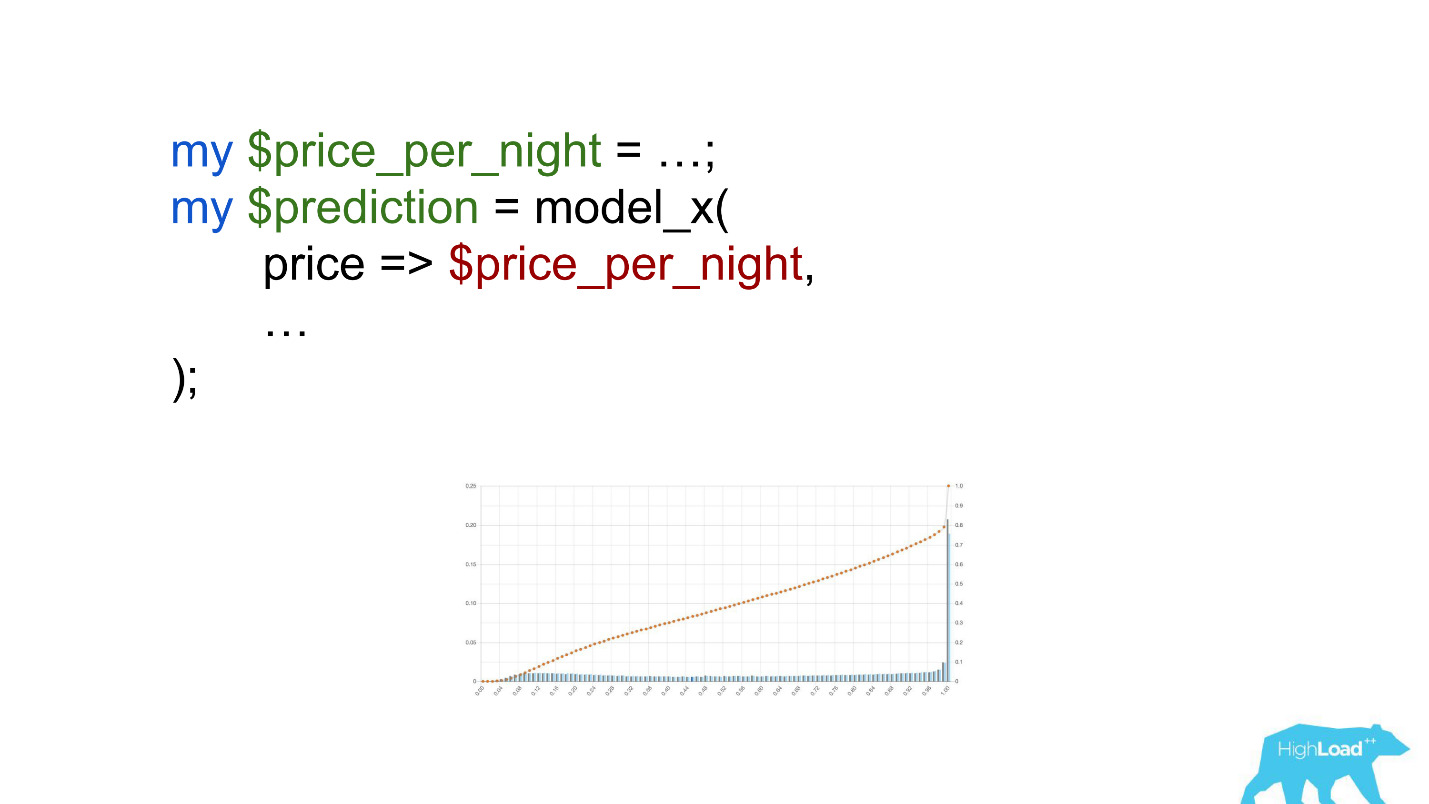
عملت العملات مثل الروبيات أو الروبل على زيادة المنتج العددي مرات عديدة ، وبالتالي ، أجبر هذا النموذج على إنتاج قيمة قريبة من الوحدة ، في كثير من الأحيان ، والتي نراها على الرسم البياني.
قيم العتبة
ميزة أخرى مفيدة لهذه الرسوم البيانية هي إمكانية الاختيار الواعي والأمثل لقيم العتبة.
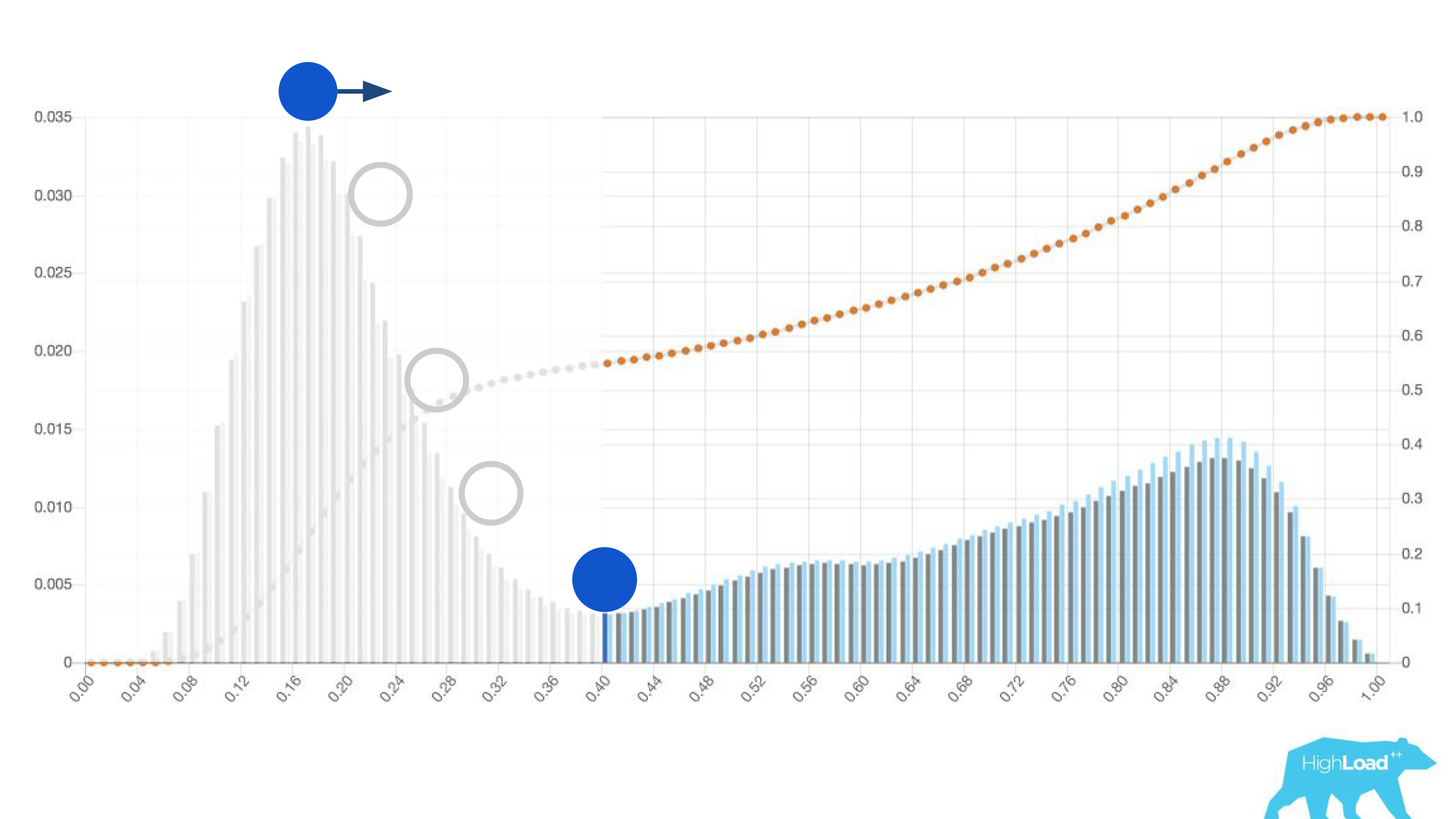
إذا وضعت الكرة على أعلى تل في هذا الرسم البياني ، فقم بدفعها وتخيل أين ستتوقف ، ستكون هذه هي النقطة المثلى لفصل الفصل. كل شيء على اليمين فئة واحدة ، وكل شيء على اليسار هو فئة أخرى.
ومع ذلك ، إذا بدأت في تحريك هذه النقطة ، يمكنك تحقيق تأثيرات مثيرة للاهتمام. لنفترض أننا نريد تشغيل تجربة ، إذا قال النموذج نعم ، فإنها تغير واجهة المستخدم بطريقة أو بأخرى. إذا قمت بنقل هذه النقطة إلى اليمين ، فسيتم تقليل جمهور تجربتنا. بعد كل شيء ، فإن عدد الأشخاص الذين حصلوا على هذا التنبؤ هو المنطقة تحت المنحنى. ومع ذلك ، في الممارسة العملية ، دقة التنبؤات أعلى بكثير. وبالمثل ، إذا لم تكن هناك قوة ثابتة كافية ، فيمكنك زيادة جمهور تجربتك ، ولكن تقليل دقة التوقعات.
بالإضافة إلى التوقعات نفسها ، بدأنا في مراقبة قيم الإدخال في المتجهات.
ترميز واحد ساخن
معظم الميزات في أبسط نماذجنا هي تصنيفية. وهذا يعني أن هذه ليست أرقامًا ، بل فئات معينة: المدينة التي ينتمي إليها المستخدم ، أو المدينة التي يبحث فيها عن فندق. نستخدم ترميزًا ساخنًا واحدًا ونحول كل قيمة ممكنة إلى وحدة في ناقل ثنائي. نظرًا لأننا في البداية استخدمنا جوهر الحوسبة الخاص بنا فقط ، كان من السهل تحديد المواقف التي لا يوجد فيها مكان للفئة الواردة في الناقل الوارد ، أي أن النموذج لم يشاهد هذه البيانات أثناء التدريب.
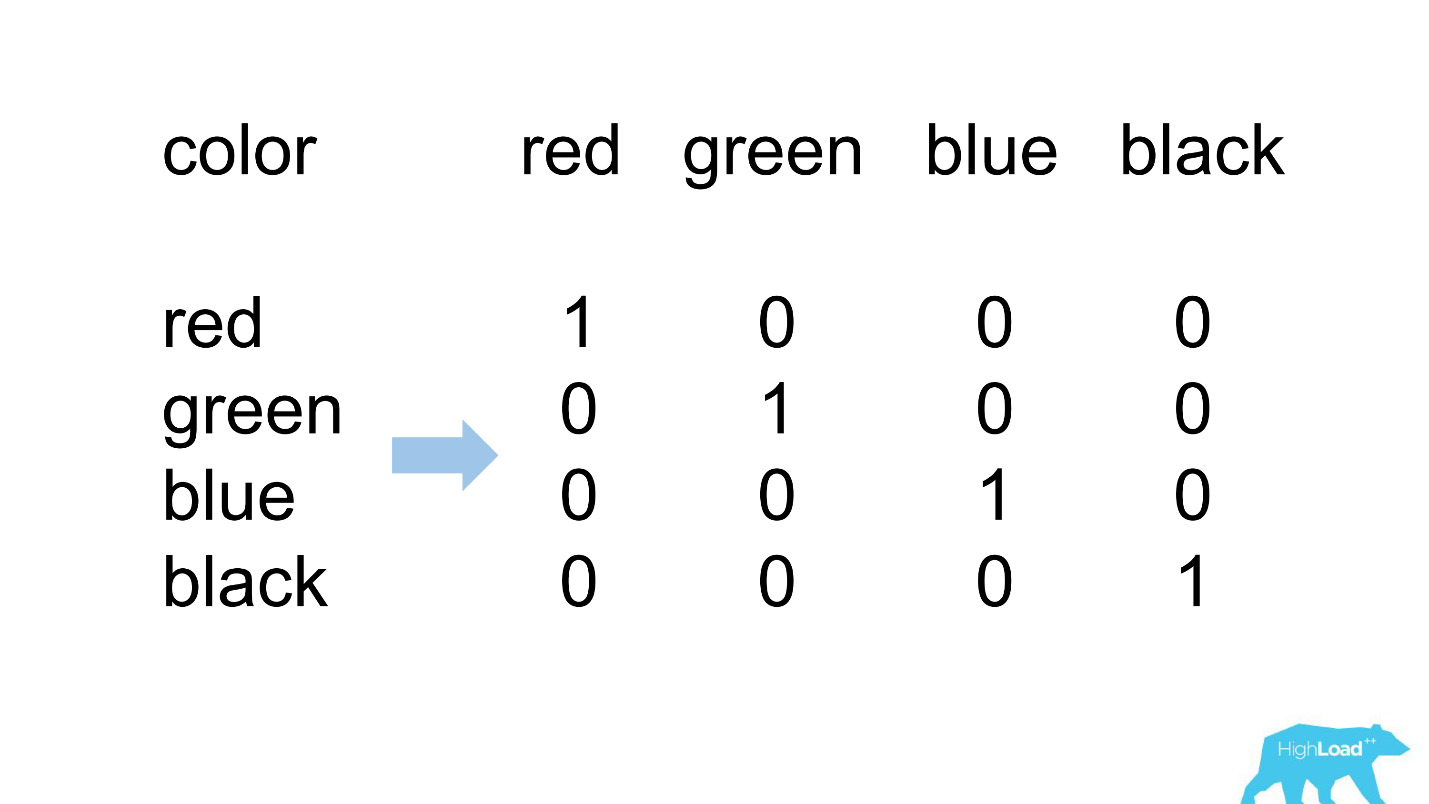
هذا ما يبدو عليه عادة.

destination_id - المدينة التي يبحث فيها المستخدم عن فندق. بطبيعة الحال ، لم يشاهد النموذج حوالي 5 ٪ من القيم ، لأننا نربط باستمرار المدن الجديدة. Visitor_cty_id = 23.32٪ ، لأن علماء البيانات يغفلون أحيانًا بوعي المدن الأقل شيوعًا.
في حالة سيئة ، قد يبدو مثل هذا:

على الفور 3 خصائص ، 100٪ من القيم التي لم يشاهدها النموذج من قبل. غالبًا ما يحدث هذا بسبب استخدام تنسيقات أخرى غير تلك المستخدمة في التدريب ، أو ببساطة أخطاء كتابية عادية.
الآن بمساعدة لوحات العدادات ، نكتشف ونصحح مثل هذه المواقف بسرعة كبيرة.
معرض التعلم الآلي
لنتحدث عن قضايا أخرى قمنا بحلها. بعد أن قمنا بإنشاء مكتبات العملاء والمراقبة ، بدأت الخدمة تكتسب الزخم بسرعة كبيرة. لقد غمرنا حرفياً التطبيقات من أجزاء مختلفة من الشركة: "دعنا نربط هذا النموذج أيضًا! دعونا نقوم بتحديث القديم! " لقد خيطنا للتو ، في الواقع ، توقف أي تطور جديد.
لقد خرجنا من الموقف عن طريق
إنشاء كشك خدمة ذاتية لعلماء البيانات . يمكنك الآن الانتقال إلى بوابتنا ، وهي نفس البوابة التي استخدمناها في البداية فقط للمراقبة ، وبشكل حرفي بالنقر فوق الزر تحميل النموذج في الإنتاج. في غضون دقائق قليلة ستعمل وتقدم توقعات.
كان هناك مشكلة أخرى.
Booking.com لديها ما يقرب من 200 فريق تكنولوجيا المعلومات. كيف يمكن إخبار الفريق في جزء مختلف تمامًا من الشركة بوجود نموذج يمكن أن يساعدهم؟ قد لا تعرف ببساطة وجود مثل هذا الفريق. كيف تعرف ما هي النماذج الموجودة وكيف تستخدمها؟ تقليديا ، تعمل الاتصالات الخارجية في فرقنا في PO (مالك المنتج). هذا لا يعني أنه ليس لدينا أي اتصالات أفقية أخرى ، فقط PO يفعل ذلك أكثر من الآخرين. ولكن من الواضح أنه في مثل هذا النطاق ، لا يتم توسيع نطاق الاتصالات الفردية. عليك أن تفعل شيئا حيال ذلك.
كيف يمكن تسهيل التواصل؟أدركنا فجأة أن البوابة ، التي أنشأناها حصريًا للمراقبة ، بدأت تتحول تدريجياً إلى عرض للتعلم الآلي داخل شركتنا.
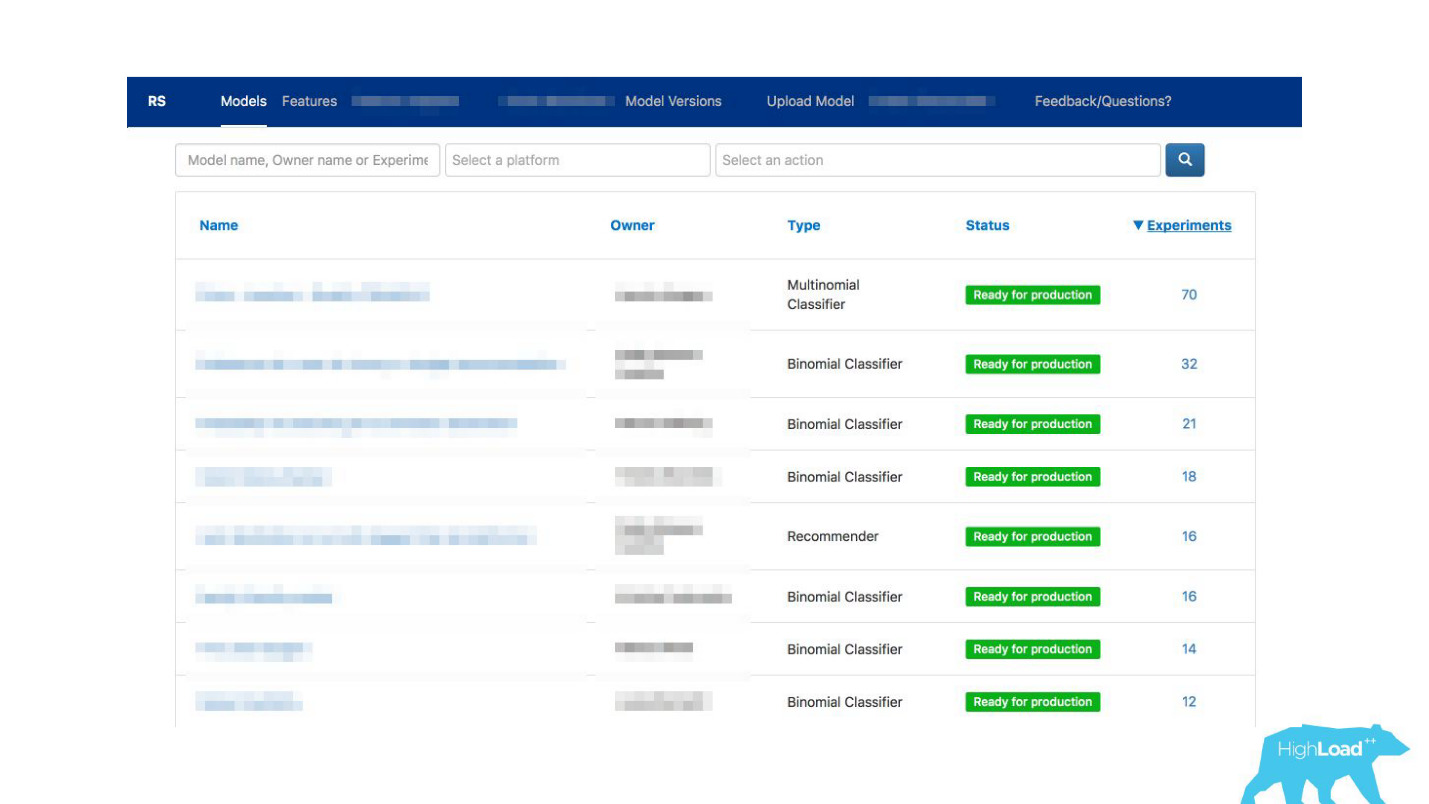
لقد مكننا أطباء البيانات من وصف نماذجهم بالتفصيل. عندما كان هناك الكثير من النماذج ، أضفنا تسميات الموضوعات والمساحات لتجميع ملائم.
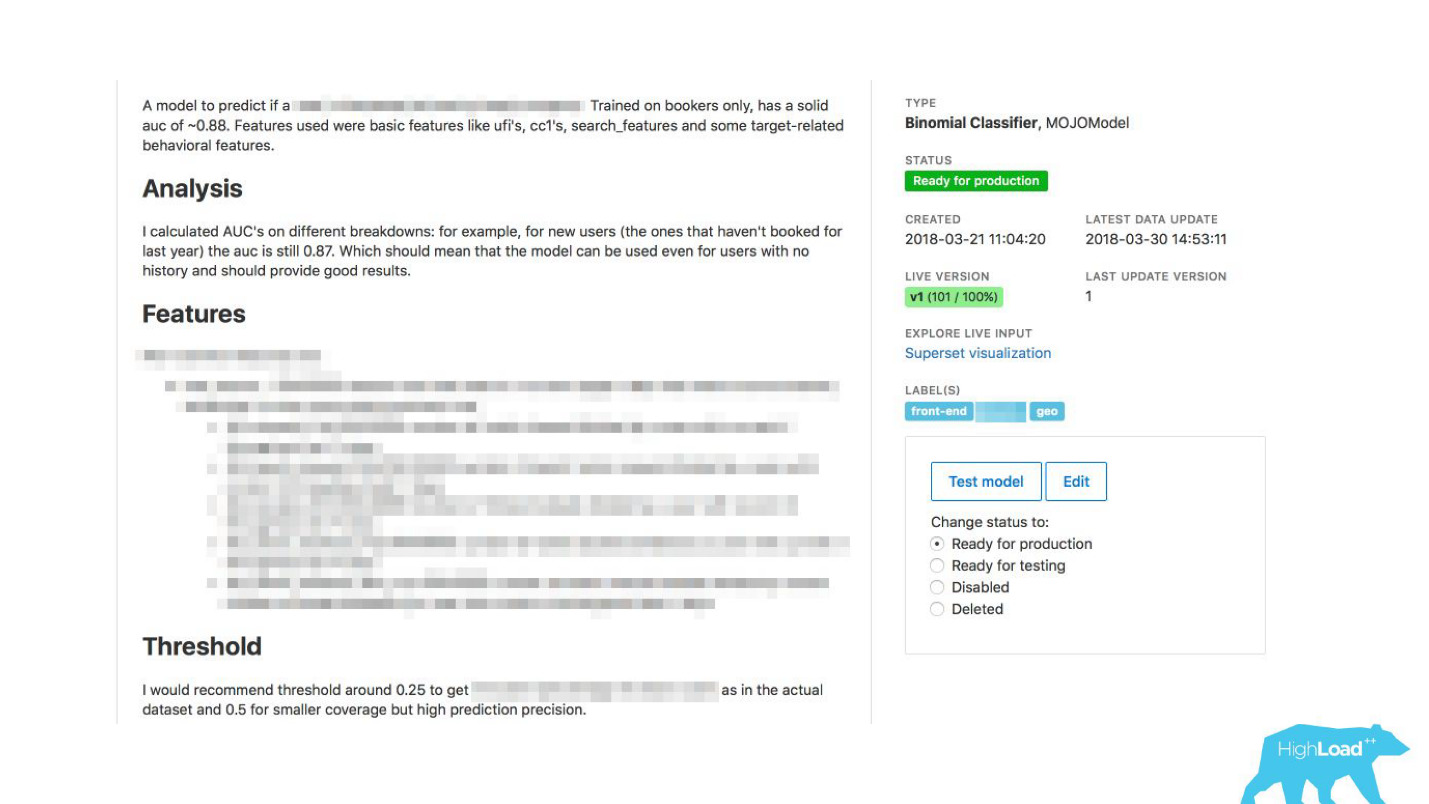
قمنا بربط أداتنا مع ExperimentTool. هذا منتج داخل شركتنا يوفر تجارب أ / ب ويخزن سجل التجارب بالكامل.

الآن ، إلى جانب وصف النموذج ، يمكنك أيضًا معرفة ما فعلته الفرق الأخرى بهذا النموذج من قبل ومدى نجاحه. لقد تغير كل شيء.
على محمل الجد ، أدى ذلك إلى تغيير طريقة عمل تكنولوجيا المعلومات ، لأنه حتى في الحالات التي لا يوجد فيها عالم بيانات في الفريق ، يمكنك استخدام التعلم الآلي.
على سبيل المثال ، تستخدم العديد من الفرق هذا أثناء جلسات العصف الذهني. عندما يخرجون ببعض أفكار المنتجات الجديدة ، فإنهم ببساطة يختارون النماذج التي تناسبهم ويستخدمونها. لا شيء معقد مطلوب لذلك.
ماذا انسكب علينا؟ في الوقت الحالي ، في الذروة ، نقدم حوالي 200 ألف توقع في الثانية ، مع وقت استجابة أقل من 20-30 مللي ثانية ، بما في ذلك رحلة ذهاب وعودة HTTP ، ووضع أكثر من 200 طراز.
قد يبدو أنه كان من السهل السير في الحديقة: قمنا بعمل رائع ، كل شيء يعمل ، الجميع سعداء!
هذا ، بالطبع ، لا يحدث. كانت هناك أخطاء. في البداية ، على سبيل المثال ، قمنا بزرع قنبلة موقوتة صغيرة. لسبب ما ، افترضنا أن معظم نماذجنا ستكون أنظمة توصية ذات نواقل إدخال ثقيلة ، وقد تم اختيار مكدس Scala + Akka على وجه التحديد لأنه من السهل جدًا تنظيم الحسابات المتوازية بمساعدتها. ولكن في الواقع ، تبين أن النفقات العامة لكل هذا التوازي ، للجمع معًا ، أعلى من الكسب المحتمل. في مرحلة ما ، قامت أجهزتنا المائة بمعالجة 100 ألف RPS فقط ، وحدث فشل مع أعراض مميزة تمامًا: استخدام وحدة المعالجة المركزية منخفض ، ولكن تم الحصول على مهلات.
ثم عدنا إلى جوهر الحوسبة الخاص بنا ، وقمنا بمراجعة المعايير ووضعها ، ونتيجة لاختبار السعة ، علمنا أنه بالنسبة لنفس حركة المرور ، نحتاج فقط إلى 4 أجهزة. , , -, , , , 100 000 RPS 4 .
- , , . - , , , .
— , . , ID , . , 0.
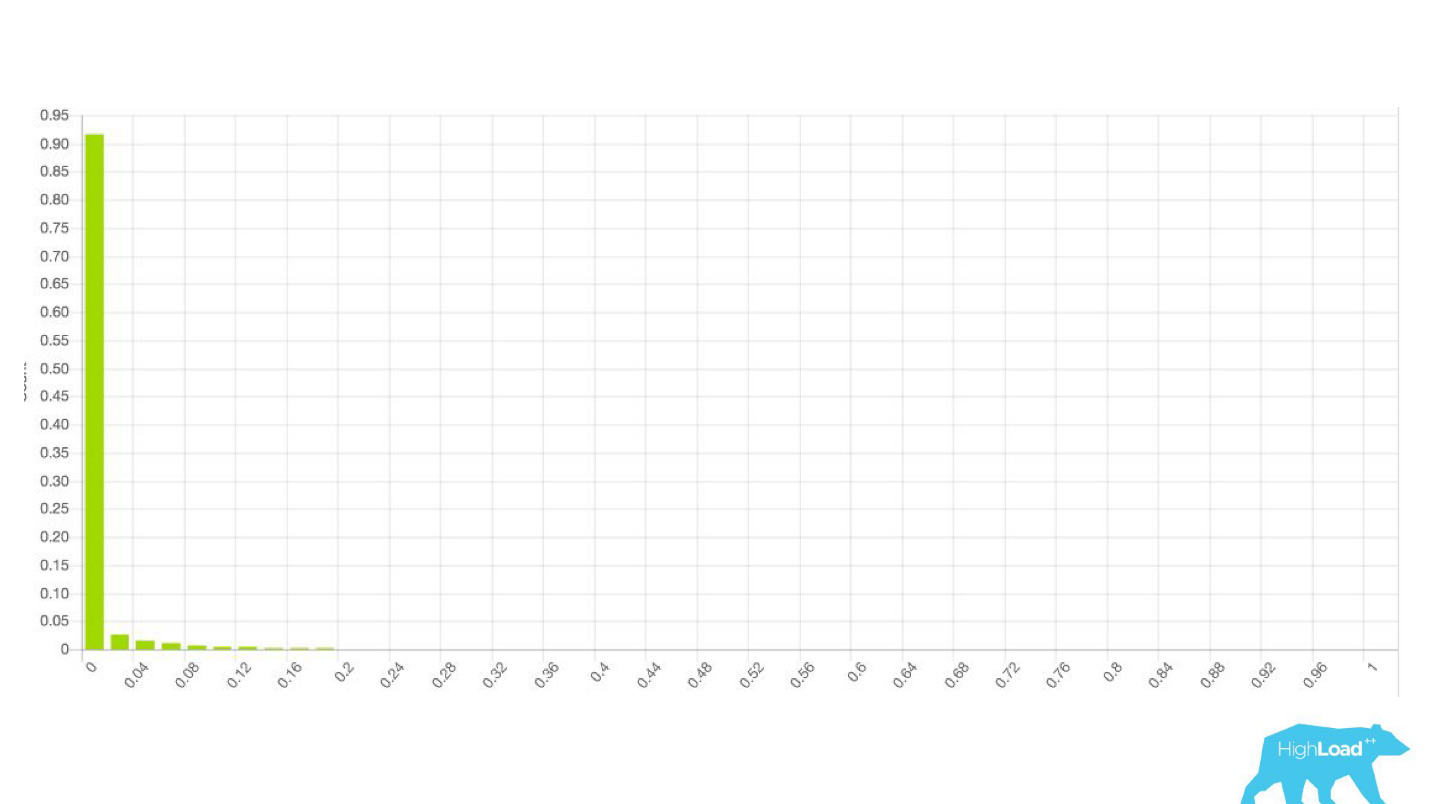
— , — .
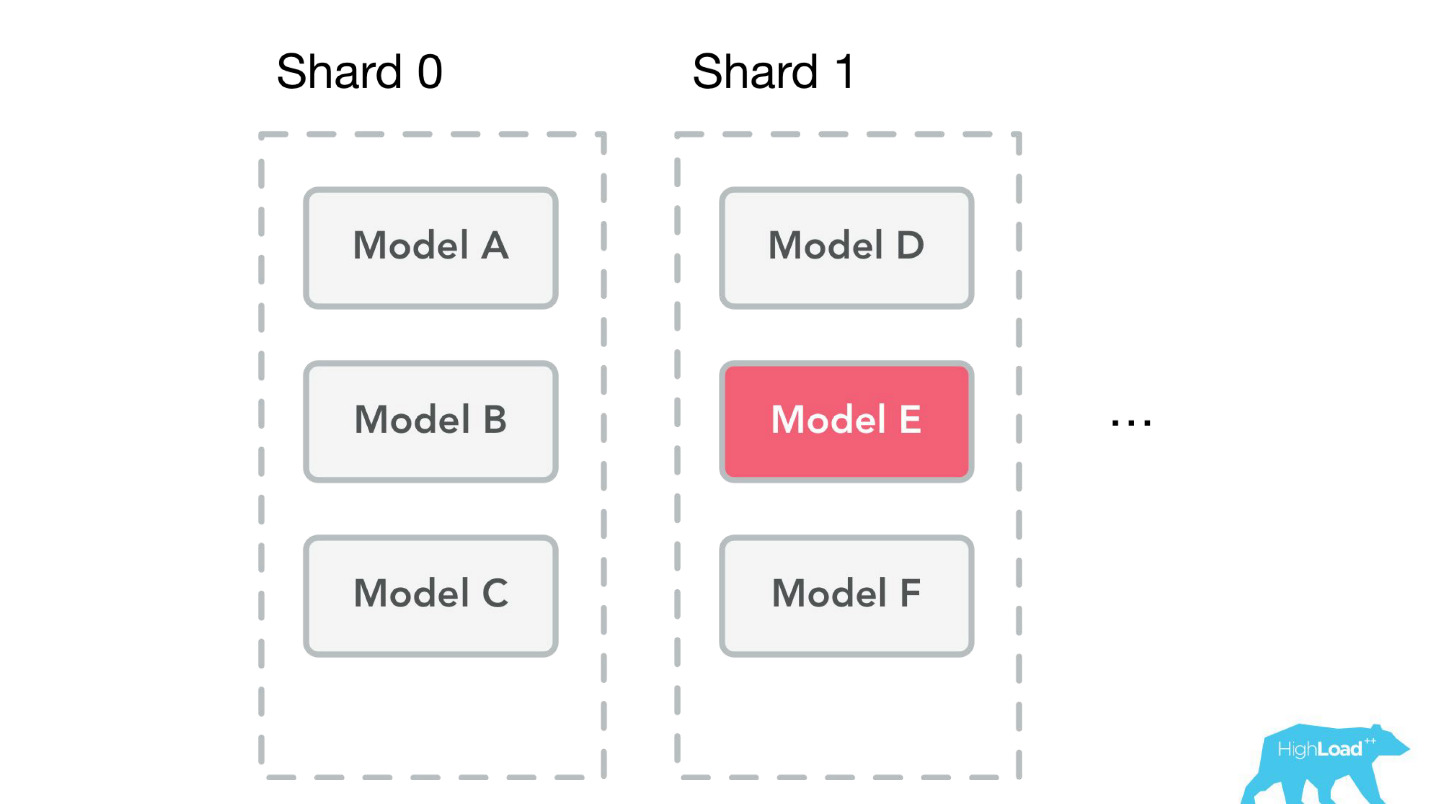
, . , . , — , . , , , - .
, — ID . — 49-51%. , . , , . , .
الخطط المستقبلية
- , . Label based metrics, precision recall .
- More tools & integrations
, . , Perl Java, , , . Spark, .
- Reusable training pipelines
.
, -. , , , , ,
steaming — - , , .
. pipeline, , . , , .
. ,
, 50 , . , . , , .
Start small
, , Booking.com, , , — !
, , MySQL. , , . - . B . , , - — .
, ?
Monitor
— , -, .
— . — , . , , , . : , . , , , — !
Organization footprint
, . , . , .
(Don't) Follow our steps
- , , , . , - , . , . — , , ? , , , ?
, , !HighLoad++ 2018, 8 9 , 135 , . 9 - . , .