يعد التعلم المعزز (RL) أحد أكثر تقنيات التعلم الآلي الواعدة التي يتم تطويرها بنشاط. هنا ، يتلقى وكيل منظمة العفو الدولية مكافأة إيجابية عن الإجراءات الصحيحة ، ومكافأة سلبية عن الإجراءات الخاطئة. طريقة
الجزرة والعصا بسيطة وعالمية. مع ذلك ، قام DeepMind بتدريس خوارزمية
DQN لتشغيل ألعاب الفيديو Atari القديمة ، و
AlphaGoZero للعب لعبة Go القديمة. لذا قامت OpenAI بتدريس خوارزمية
OpenAI-Five لتشغيل لعبة فيديو Dota الحديثة ، وعلمت Google الأيدي الروبوتية
لالتقاط أشياء جديدة . على الرغم من نجاح RL ، لا تزال هناك العديد من المشاكل التي تقلل من فعالية هذه التقنية.
تجد خوارزميات RL
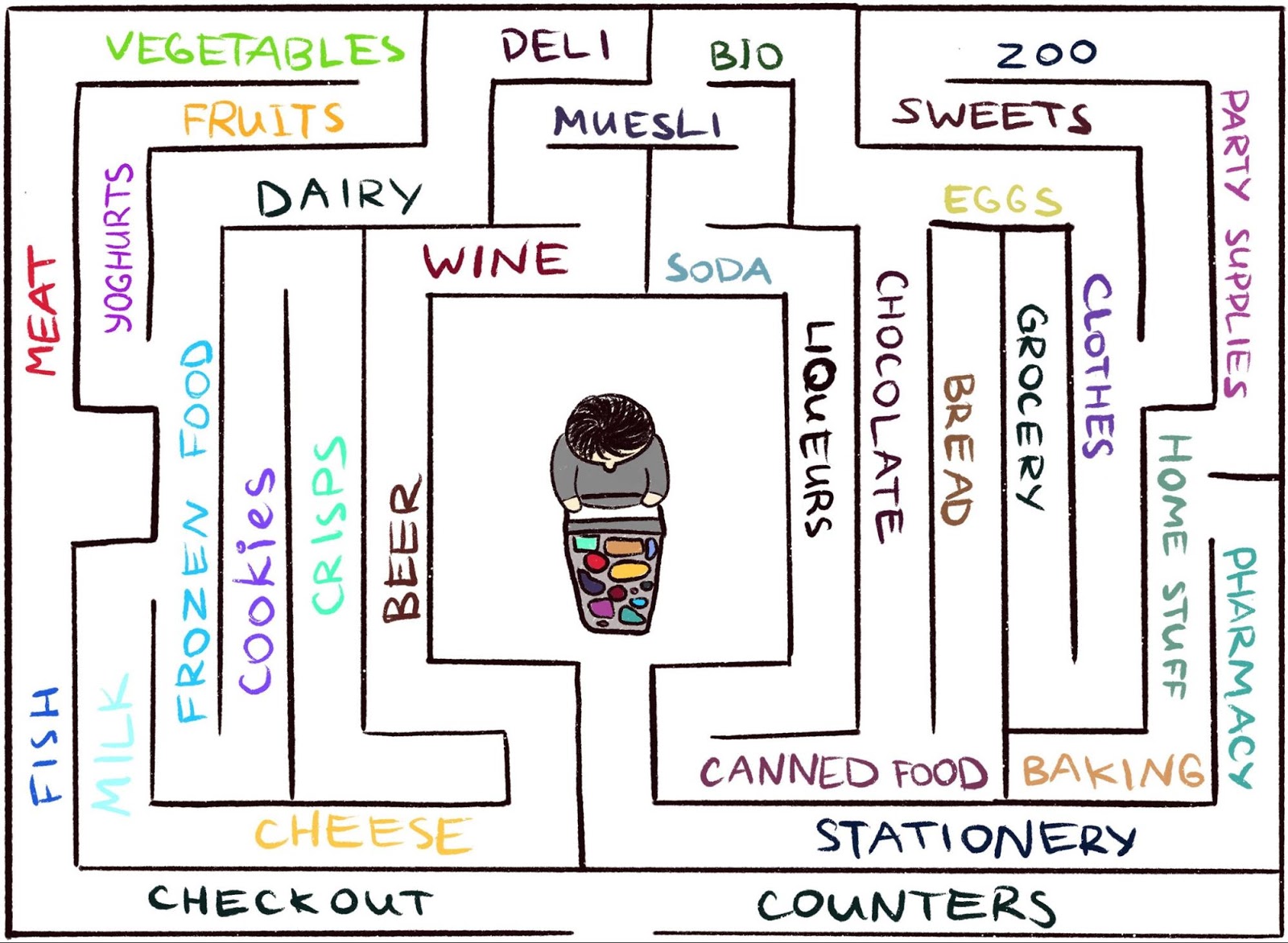
صعوبة في العمل في بيئة نادرًا ما يتلقى فيها الوكيل ملاحظات. ولكن هذا هو نموذجي للعالم الحقيقي. كمثال ، تخيل البحث عن الجبن المفضل لديك في متاهة كبيرة ، مثل السوبر ماركت. أنت تبحث وتبحث عن قسم بالجبن ، ولكن لا يمكنك العثور عليه. إذا لم تحصل في كل خطوة على "عصا" أو "جزرة" ، فمن المستحيل تحديد ما إذا كنت تتحرك في الاتجاه الصحيح. في حالة عدم وجود مكافأة ، ما الذي يمنعك من التجول إلى الأبد؟ لا شيء سوى فضولك. إنه يحفز الانتقال إلى قسم البقالة ، والذي يبدو غير مألوف.
إن العمل العلمي ،
"الفضول العرضي من خلال إمكانية الوصول" ، هو نتيجة تعاون بين
فريق Google Brain و
DeepMind والمدرسة الفنية السويسرية العليا في زيوريخ . نحن نقدم نموذج مكافأة RL عرضي جديد قائم على الذاكرة. تبدو مثل الفضول الذي يسمح لك باستكشاف البيئة. نظرًا لأن الوكيل يجب ألا يدرس البيئة فحسب ، بل يحل أيضًا المشكلة الأولية ، يضيف نموذجنا مكافأة إلى المكافأة المتفرقة في البداية. لم تعد المكافأة مجتمعة متناثرة ، مما يسمح لخوارزميات RL القياسية بالتعلم منها. وبالتالي ، فإن طريقة الفضول لدينا توسع نطاق المهام التي يمكن حلها باستخدام RL.
 فضول عرضي من خلال إمكانية الوصول: يتم إضافة بيانات المراقبة إلى الذاكرة ، يتم حساب المكافأة بناءً على مدى المراقبة الحالية من الملاحظات المماثلة في الذاكرة. يتلقى الوكيل مكافأة أكبر للملاحظات التي لم يتم عرضها بعد في الذاكرة.
فضول عرضي من خلال إمكانية الوصول: يتم إضافة بيانات المراقبة إلى الذاكرة ، يتم حساب المكافأة بناءً على مدى المراقبة الحالية من الملاحظات المماثلة في الذاكرة. يتلقى الوكيل مكافأة أكبر للملاحظات التي لم يتم عرضها بعد في الذاكرة.الفكرة الرئيسية للطريقة هي تخزين ملاحظات الوكيل للبيئة في الذاكرة العرضية ، وكذلك مكافأة الوكيل على عرض الملاحظات التي لم يتم تقديمها في الذاكرة. "نقص الذاكرة" هو تعريف الحداثة في أسلوبنا. البحث عن مثل هذه الملاحظات يعني البحث عن شخص غريب. مثل هذه الرغبة في البحث عن شخص غريب ستقود وكيل الذكاء الاصطناعي إلى مواقع جديدة ، وبالتالي يمنع التجول في دائرة ، ويساعده في النهاية على التعثر على الهدف. كما نناقش لاحقًا ، فإن صياغتنا قد تردع الوكيل عن السلوك غير المرغوب فيه الذي تخضع له بعض الكلمات الأخرى. ولدهشتنا العظيمة ، فإن هذا السلوك له بعض أوجه التشابه مع ما يمكن أن يسميه المواطن العادي "التسويف".
الفضول السابق
على الرغم من وجود العديد من المحاولات لصياغة الفضول في الماضي
[1] [2] [3] [4] ، إلا أننا سنركز في هذا المقال على نهج واحد وشائع جدًا: الفضول من خلال المفاجأة بناءً على التنبؤ. تم وصف هذه التقنية في مقال حديث بعنوان
"التحقيق في بيئة باستخدام الفضول من خلال التنبؤ تحت سيطرتها الخاصة" (يشار إليه عادةً باسم ICM). لتوضيح العلاقة بين المفاجأة والفضول ، نستخدم مرة أخرى تشبيه إيجاد الجبن في السوبر ماركت.
 رسم توضيحي من إنديرا باسكو ، مرخص بموجب CC BY-NC-ND 4.0
رسم توضيحي من إنديرا باسكو ، مرخص بموجب CC BY-NC-ND 4.0تتجول في المتجر ، تحاول التنبؤ بالمستقبل (
"الآن أنا في قسم اللحوم ، لذلك أعتقد أن القسم القريب هو قسم الأسماك ، وعادة ما يكون في مكان قريب في سلسلة السوبر ماركت هذه" ). إذا كانت التوقعات غير صحيحة ، فستفاجأ (
"في الواقع ، هناك قسم من الخضروات. لم أتوقع هذا!" ) - وبهذه الطريقة تحصل على مكافأة. هذا يزيد من الدافع في المستقبل للنظر حول الزاوية مرة أخرى ، واستكشاف أماكن جديدة فقط للتحقق من صحة توقعاتك (وربما تتعثر على الجبن).
وبالمثل ، فإن طريقة ICM تبني نموذجًا تنبئيًا لديناميكيات العالم وتعطي الوكيل مكافأة إذا فشل النموذج في تقديم تنبؤات جيدة - علامة على المفاجأة أو الحداثة. يرجى ملاحظة أن استكشاف الأماكن الجديدة لا يتم التعبير عنه بشكل مباشر في فضول ICM. بالنسبة إلى طريقة ICM ، فإن حضورهم هو مجرد طريقة للحصول على المزيد من "المفاجآت" وبالتالي زيادة المكافأة الإجمالية الخاصة بك. كما اتضح ، في بعض البيئات قد تكون هناك طرق أخرى لمفاجأة نفسه ، مما يؤدي إلى نتائج غير متوقعة.
يتجمد وكيل لديه نظام فضول قائم على مفاجأة مفاجئة عند مقابلة جهاز تلفزيون. الرسوم المتحركة من فيديو Deepak Patak المرخص بموجب CC BY 2.0خطر التسويف
في مقال
"دراسة واسعة النطاق للتعلم القائم على الفضول" ، أظهر مؤلفو أسلوب ICM ، إلى جانب باحثين OpenAI ، خطرًا خفيًا من تعظيم المفاجأة: يمكن للعملاء تعلم الانغماس في التسويف بدلاً من القيام بشيء مفيد لهذه المهمة. لفهم سبب حدوث ذلك ، ضع في اعتبارك تجربة فكرية يسميها المؤلفون "مشكلة الضوضاء التليفزيونية". يتم وضع الوكيل هنا في متاهة مع مهمة العثور على عنصر مفيد للغاية (مثل "الجبن" في مثالنا). البيئة بها تلفاز ، والوكيل به جهاز تحكم عن بعد. يوجد عدد محدود من القنوات (كل قناة لديها إرسال منفصل) ، وكل ضغطة على جهاز التحكم عن بعد تحول التلفزيون إلى قناة عشوائية. كيف سيتصرف الوكيل في مثل هذه البيئة؟
إذا تم تشكيل الفضول على أساس المفاجأة ، فإن تغيير القنوات سيعطي المزيد من المكافآت ، حيث أن كل تغيير غير متوقع وغير متوقع. من المهم أن نلاحظ أنه حتى بعد إجراء مسح دوري لجميع القنوات المتاحة ، فإن الاختيار العشوائي للقناة يضمن أن كل تغيير جديد سيظل غير متوقع - يتنبأ الوكيل بأنه سيعرض التلفزيون بعد تبديل القناة ، وعلى الأرجح ستتحول التوقعات إلى أن تكون غير صحيحة ، مما سيؤدي إلى مفاجأة. من المهم ملاحظة أنه حتى إذا كان الوكيل قد شاهد بالفعل كل إرسال على كل قناة ، فإن التغيير لا يزال غير متوقع. وبسبب هذا ، فإن الوكيل ، بدلاً من البحث عن عنصر مفيد للغاية ، سيبقى في نهاية المطاف أمام التلفزيون - على غرار التسويف. كيفية تغيير صياغة الفضول لمنع هذا السلوك؟
فضول عرضي
في مقالة
"الفضول العرضي من خلال قابلية الوصول" ، ندرس نموذج الفضول القائم على الذاكرة العرضية الأقل عرضة للمتعة الفورية. لماذا ذلك إذا أخذنا المثال أعلاه ، فبعد مرور بعض الوقت على تبديل القنوات ، ستنتهي جميع عمليات الإرسال في الذاكرة. وبالتالي ، سيفقد التلفزيون جاذبيته: حتى لو كان الترتيب الذي تظهر به البرامج على الشاشة عشوائيًا ولا يمكن التنبؤ به ، فهي كلها في الذاكرة! هذا هو الفرق الرئيسي عن الطريقة القائمة على المفاجأة: طريقتنا لا تحاول حتى التنبؤ بالمستقبل ، من الصعب التكهن (أو حتى المستحيل). بدلاً من ذلك ، يفحص الوكيل الماضي ويتحقق لمعرفة ما إذا كانت هناك أي ملاحظات في الذاكرة
مثل الحالية. وبالتالي ، فإن وكيلنا ليس عرضة للمتعة الفورية ، مما يعطي "ضوضاء تلفزيونية". سيتعين على الوكيل الذهاب واستكشاف العالم خارج التلفزيون للحصول على المزيد من المكافآت.
ولكن كيف نقرر ما إذا كان الوكيل يرى نفس الشيء المخزن في الذاكرة؟ التحقق الدقيق من المطابقة لا معنى له: في بيئة حقيقية ، نادرًا ما يرى الوكيل نفس الشيء مرتين. على سبيل المثال ، حتى إذا عاد الوكيل إلى نفس الغرفة ، فسيظل يرى هذه الغرفة من زاوية مختلفة.
بدلاً من التحقق من المطابقات الدقيقة ، نستخدم
شبكة عصبية عميقة مدربة لقياس مدى تشابه تجربتين. لتدريب هذه الشبكة ، يجب علينا تخمين مدى قرب حدوث الملاحظات في الوقت المناسب. القرب في الوقت هو مؤشر جيد لما إذا كان ينبغي اعتبار ملاحظتين جزءًا من نفس الشيء. يؤدي هذا التعلم إلى مفهوم عام للحداثة من خلال إمكانية الوصول ، وهو موضح أدناه.
 يحدد الرسم البياني قابلية الوصول الجدة. من الناحية العملية ، هذا الرسم البياني غير متاح - لذلك ، نقوم بتدريب مُقارب الشبكة العصبية لتقدير عدد الخطوات بين الملاحظات
يحدد الرسم البياني قابلية الوصول الجدة. من الناحية العملية ، هذا الرسم البياني غير متاح - لذلك ، نقوم بتدريب مُقارب الشبكة العصبية لتقدير عدد الخطوات بين الملاحظاتنتائج تجريبية
لمقارنة أداء المناهج المختلفة لوصف الفضول ، قمنا باختبارها في
بيئتين ثلاثيتي الأبعاد
غنيتين بصريًا:
ViZDoom و
DMLab . في ظل هذه الظروف ، تم تكليف الوكيل بمهام مختلفة ، مثل العثور على هدف في المتاهة ، وجمع الأشياء الجيدة وتجنب الأشياء السيئة. في بيئة DMLab ، تم تجهيز الوكيل افتراضيًا بأداة رائعة مثل الليزر ، ولكن إذا لم تكن هناك حاجة إلى الأداة لمهمة معينة ، لا يمكن للوكيل استخدامها بحرية. ومن المثير للاهتمام ، استنادًا إلى المفاجأة ، أن وكيل ICM كان يستخدم الليزر في كثير من الأحيان ، حتى لو كان من غير المجدي إكمال المهمة! كما هو الحال في التلفزيون ، بدلاً من البحث عن عنصر قيم في المتاهة ، فضل قضاء بعض الوقت في إطلاق النار على الجدران ، لأنه أعطى الكثير من المكافآت في شكل مفاجأة. من الناحية النظرية ، يجب أن تكون نتيجة اللقطة الجدارية قابلة للتنبؤ بها ، ولكن من الناحية العملية يصعب التنبؤ بها. ربما يتطلب هذا معرفة أعمق بالفيزياء مما هو متاح لعامل الذكاء الاصطناعي القياسي.
عميل ICM المفاجئ يطلق النار باستمرار على الحائط بدلاً من استكشاف المتاهةعلى عكسه ، أتقن وكيلنا السلوك المعقول لدراسة البيئة. حدث هذا لأنه لا يحاول التنبؤ بنتيجة أفعاله ، بل يبحث عن ملاحظات "أبعد" من تلك الموجودة في الذاكرة العرضية. بعبارة أخرى ، يسعى الوكيل ضمنياً إلى تحقيق أهداف تتطلب مجهوداً أكبر من مجرد لقطة بسيطة على الحائط.
توضح طريقتنا سلوك الاستكشاف البيئي الذكي.من المثير للاهتمام ملاحظة كيف يعاقب نهجنا للمكافأة وكيل يعمل في دائرة ، لأنه بعد الانتهاء من الدائرة الأولى ، لا يواجه الوكيل ملاحظات جديدة ، وبالتالي ، لا يحصل على أي مكافأة:
تصور المكافأة: الأحمر يقابل المكافأة السلبية ، الأخضر إلى الإيجابي. من اليسار إلى اليمين: بطاقة المكافأة ، الخريطة مع المواقع في الذاكرة ، عرض الشخص الأولفي الوقت نفسه ، تساهم طريقتنا في دراسة جيدة للبيئة:
تصور المكافأة: الأحمر يقابل المكافأة السلبية ، الأخضر إلى الإيجابي. من اليسار إلى اليمين: بطاقة المكافأة ، الخريطة مع المواقع في الذاكرة ، عرض الشخص الأولنأمل أن يساهم عملنا في موجة جديدة من البحث تتجاوز نطاق تقنية المفاجأة من أجل تثقيف العملاء حول السلوك الأكثر ذكاءً. للحصول على تحليل متعمق لطريقتنا ، يرجى إلقاء نظرة على
الطباعة الأولية للعمل العلمي .
شكر وتقدير:
هذا المشروع هو نتيجة للتعاون بين فريق Google Brain و DeepMind والمدرسة التقنية العليا السويسرية في زيوريخ. المجموعة البحثية الرئيسية: نيكولاي سافينوف ، أنطون رايشوك ، رافائيل مارينير ، داميان فنسنت ، مارك بوليفيس ، تيموثي ليليراب وسيلفان زيلي. نود أن نشكر أوليفييه بيتكين وكارلوس ريكيلمي وتشارلز بلونديل وسيرجي ليفين على مناقشة هذه الوثيقة. نحن ممتنون لأنديرا باسكو للمساعدة في الرسوم التوضيحية.
مراجع الأدب:
[1]
"دراسة البيئة على أساس العد مع نماذج الكثافة العصبية" ، جورج أوستروفسكي ، مارك ج. بيلمار ، آرون فان دن أورد ، ريمي مونوز
[2]
"بيئات التعلم القائمة على العد
للتعلم العميق مع التعزيز" ، خوران تان ، رين هوثوفت ، ديفيس فوت ، آدم نوك ، شي تشين ، يان دوان ، جون شولمان ، فيليب دي ترك ، بيتر أبيل
[3]
"التعلم بدون معلم لتحديد أهداف البحوث ذات الدوافع الداخلية" ألكسندر بيري ، سيباستيان فورستيير ، أوليفييه سيجوت ، بيير إيف أوديي
[4]
"فايم: الاستخبارات لزيادة التغيرات في المعلومات إلى أقصى حد" ، رين هوثفت ، شي تشين ، يان دوان ، جون شولمان ، فيليب دي ترك ، بيتر أبيل