مرحبا حب.
في أحد المشاريع حيث كان من الضروري تخزين ومعالجة قائمة ديناميكية كبيرة إلى حد ما ، بدأ المختبرون في الشكوى من نقص الذاكرة. يوصف أدناه طريقة بسيطة لإصلاح المشكلة مع "القليل من الدم" عن طريق إضافة سطر واحد فقط من التعليمات البرمجية. النتيجة في الصورة:
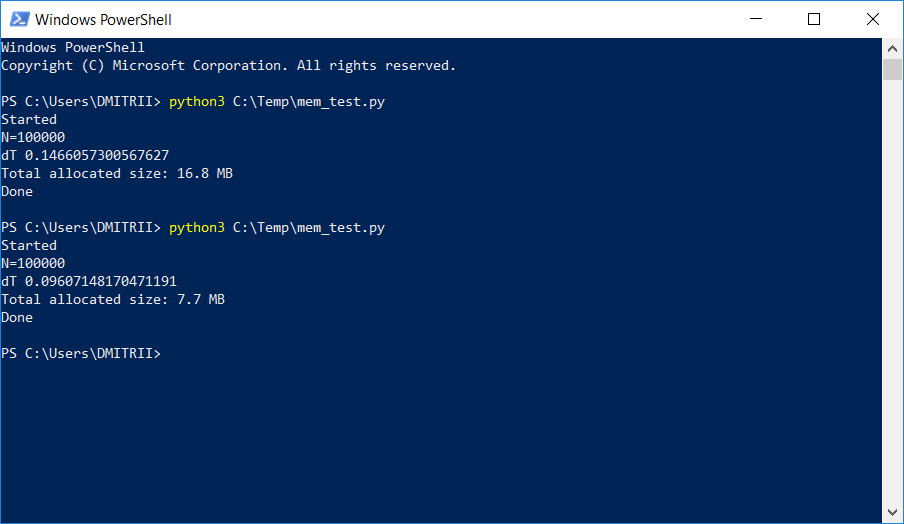
كيف يعمل ، استمر تحت القطع.
لنأخذ مثالاً بسيطًا على "التدريب" - قم بإنشاء فصل DataItem يحتوي على بيانات
شخصية عن شخص ، على سبيل المثال ، الاسم والعمر والعنوان.
class DataItem(object): def __init__(self, name, age, address): self.name = name self.age = age self.address = address
سؤال "الأطفال" هو كم يأخذ هذا الشيء في الذاكرة؟
لنجرب الحل في الجبين:
d1 = DataItem("Alex", 42, "-") print ("sys.getsizeof(d1):", sys.getsizeof(d1))
نحصل على استجابة 56 بايت. يبدو قليلا ، راضيا تماما.
ومع ذلك ، فإننا نتحقق من كائن آخر فيه المزيد من البيانات:
d2 = DataItem("Boris", 24, "In the middle of nowhere") print ("sys.getsizeof(d2):", sys.getsizeof(d2))
الجواب مرة أخرى 56. في هذه المرحلة ، نفهم أن شيئًا ما ليس هنا ، وليس كل شيء بسيطًا كما يبدو للوهلة الأولى.
لا يفشلنا الحدس ، وكل شيء ليس بهذه البساطة. Python هي لغة مرنة للغاية مع كتابة ديناميكية ، ولعملها ، تقوم بتخزين الكثير من البيانات الإضافية. والتي في حد ذاتها تستهلك الكثير. على سبيل المثال ، ستعيد sys.getsizeof ("") 33 - نعم ، ما يصل إلى 33 بايت لكل سطر فارغ! وستعيد sys.getsizeof (1) 24 - 24 بايت لعدد صحيح (أطلب من المبرمجين C الابتعاد عن الشاشة وعدم قراءة المزيد ، حتى لا يفقدوا الثقة في الجميل). بالنسبة للعناصر الأكثر تعقيدًا ، مثل القاموس ، ستعيد sys.getsizeof (dict ()) 272 بايت - وهذا لقاموس
فارغ . لن أكمل المزيد ، آمل أن يكون المبدأ واضحًا ،
وأن مصنعي ذاكرة الوصول العشوائي يحتاجون أيضًا إلى بيع رقائقهم .
ولكن نعود إلى صف DataItem وسؤال "الطفل". كم تستغرق هذه الفئة في الذاكرة؟ بادئ ذي بدء ، نقوم بعرض محتويات الفصل بالكامل عند مستوى أقل:
def dump(obj): for attr in dir(obj): print(" obj.%s = %r" % (attr, getattr(obj, attr)))
ستُظهر هذه الوظيفة ما هو مخفي "تحت الغطاء" بحيث تعمل جميع وظائف Python (الكتابة ، والميراث ، وغيرها من الأشياء الجيدة).
النتيجة مذهلة:
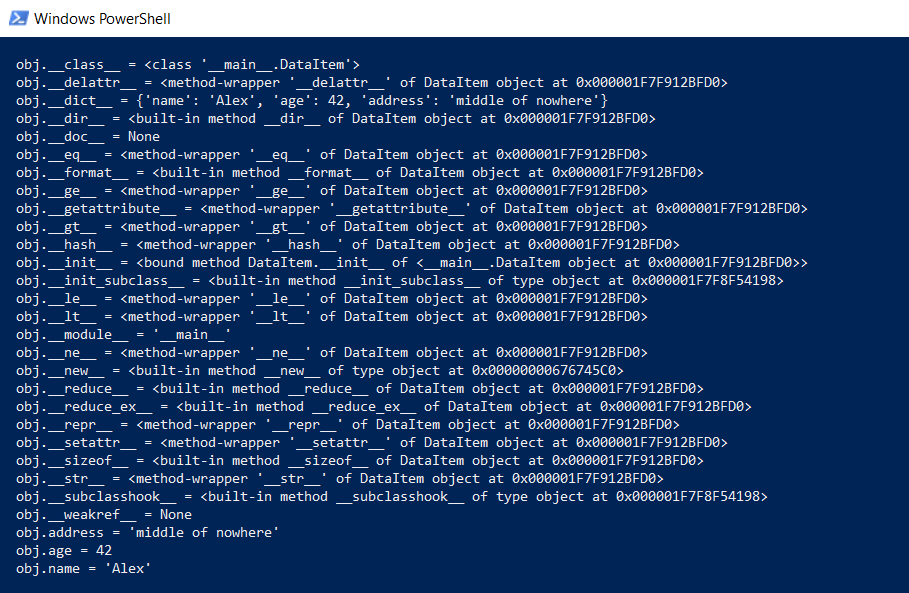
كم يأخذ كل هذا؟ في github كانت هناك وظيفة تحسب المقدار الفعلي للبيانات ، وتستدعي بشكل متكرر getizeof لجميع الكائنات.
def get_size(obj, seen=None):
نحاول:
d1 = DataItem("Alex", 42, "-") print ("get_size(d1):", get_size(d1)) d2 = DataItem("Boris", 24, "In the middle of nowhere") print ("get_size(d2):", get_size(d2))
نحصل على 460 و 484 بايت على التوالي ، وهو ما يشبه الحقيقة.
باستخدام هذه الوظيفة ، يمكن إجراء عدد من التجارب. على سبيل المثال ، أتساءل كم من البيانات ستستهلك إذا قمت بوضع هياكل DataItem في القائمة. تُرجع الدالة get_size ([d1]) 532 بايت - يبدو أن هذا هو "نفس" 460 + بعض الحمل. لكن get_size ([d1، d2]) سيعرض 863 بايت - أقل من 460 + 484 بشكل منفصل. والأكثر إثارة للاهتمام هو نتيجة get_size ([d1، d2، d1]) - نحصل على 871 بايت ، فقط أكثر بقليل ، أي Python ذكية بما يكفي لعدم تخصيص ذاكرة لنفس الكائن مرة ثانية.
ننتقل الآن إلى الجزء الثاني من السؤال - هل من الممكن تقليل استهلاك الذاكرة؟ نعم يمكنك ذلك. Python مترجم ، ويمكننا توسيع صفنا في أي وقت ، على سبيل المثال ، إضافة حقل جديد:
d1 = DataItem("Alex", 42, "-") print ("get_size(d1):", get_size(d1)) d1.weight = 66 print ("get_size(d1):", get_size(d1))
هذا أمر رائع ، ولكن إذا
لم نكن بحاجة إلى هذه الوظيفة ، فيمكننا إجبار المترجم على سرد كائنات الفئة باستخدام التوجيه __slots__:
class DataItem(object): __slots__ = ['name', 'age', 'address'] def __init__(self, name, age, address): self.name = name self.age = age self.address = address
يمكنك قراءة المزيد في الوثائق (
RTFM ) ، التي تنص على أن "__slots__ تسمح لنا بالإعلان صراحةً عن أعضاء البيانات (مثل الخصائص) ورفض إنشاء __dict__ و __weakref__.
يمكن أن تكون المساحة المحفوظة باستخدام __dict__
كبيرة ".
تحقق: نعم ، مهم حقًا ، ترجع get_size (d1) ... 64 بايت بدلاً من 460 ، أي 7 مرات أقل. كمكافأة ، يتم إنشاء الكائنات بشكل أسرع بنسبة 20٪ تقريبًا (انظر أول لقطة شاشة للمقالة).
للأسف ، مع الاستخدام الحقيقي ، لن تكون هذه الزيادة الكبيرة في الذاكرة بسبب النفقات العامة الأخرى. لنقم بإنشاء مصفوفة لـ 100000 ببساطة عن طريق إضافة عناصر ، ونرى استهلاك الذاكرة:
data = [] for p in range(100000): data.append(DataItem("Alex", 42, "middle of nowhere")) snapshot = tracemalloc.take_snapshot() top_stats = snapshot.statistics('lineno') total = sum(stat.size for stat in top_stats) print("Total allocated size: %.1f MB" % (total / (1024*1024)))
لدينا 16.8 ميجا بايت بدون __slots__ و 6.9 ميجا بايت معها. ليس 7 مرات بالطبع ، ولكن حتى بشكل جيد جدًا ، نظرًا لأن تغيير الرمز كان ضئيلاً.
الآن عن أوجه القصور. تنشيط __slots__ يمنع إنشاء جميع العناصر ، بما في ذلك __dict__ ، مما يعني ، على سبيل المثال ، أن مثل هذا الرمز لترجمة هيكل إلى json لن يعمل:
def toJSON(self): return json.dumps(self.__dict__)
ولكن من السهل إصلاحه ، ما عليك سوى إنشاء الإملاء برمجيًا ، والفرز عبر جميع العناصر في الحلقة:
def toJSON(self): data = dict() for var in self.__slots__: data[var] = getattr(self, var) return json.dumps(data)
سيكون من المستحيل أيضًا إضافة متغيرات جديدة إلى الفصل ديناميكيًا ، ولكن في حالتي لم يكن ذلك مطلوبًا.
والاختبار الأخير لهذا اليوم. من المثير للاهتمام أن نرى مقدار الذاكرة التي يستغرقها البرنامج بأكمله. أضف حلقة لا نهاية لها في نهاية البرنامج حتى لا تغلق ، وانظر استهلاك الذاكرة في إدارة مهام Windows.
بدون __ فتحات__:
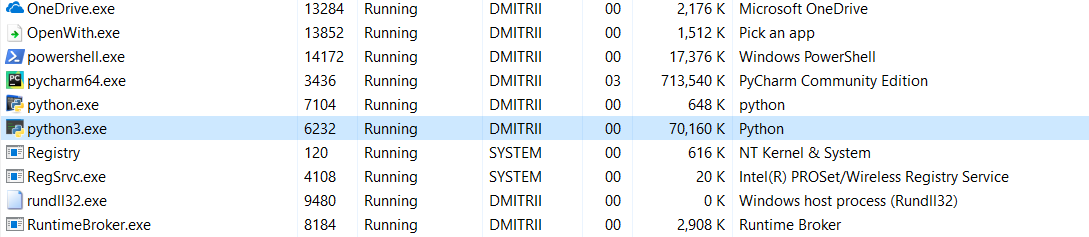
16.8 ميغابايت تحولت بطريقة ما بأعجوبة (التحرير - شرح المعجزة أدناه) إلى 70 ميغابايت (آمل أن المبرمجين سي لم يعودوا إلى الشاشة بعد؟).
مع تمكين __slots__:

6.9 ميغابايت تحولت إلى 27 ميغابايت ... حسنًا ، بعد كل شيء ، حفظنا الذاكرة ، 27 ميغابايت بدلاً من 70 ليست سيئة جدًا نتيجة لإضافة سطر واحد من التعليمات البرمجية.
تحرير : في التعليقات (بفضل robert_ayrapetyan للاختبار) ، اقترحوا أن مكتبة تصحيح أخطاء tracemalloc تستهلك الكثير من الذاكرة الإضافية. على ما يبدو ، فإنه يضيف عناصر إضافية
لكل كائن تم إنشاؤه. إذا قمت بتعطيله ، فسيكون إجمالي استهلاك الذاكرة أقل بكثير ، وستظهر لقطة الشاشة خيارين:
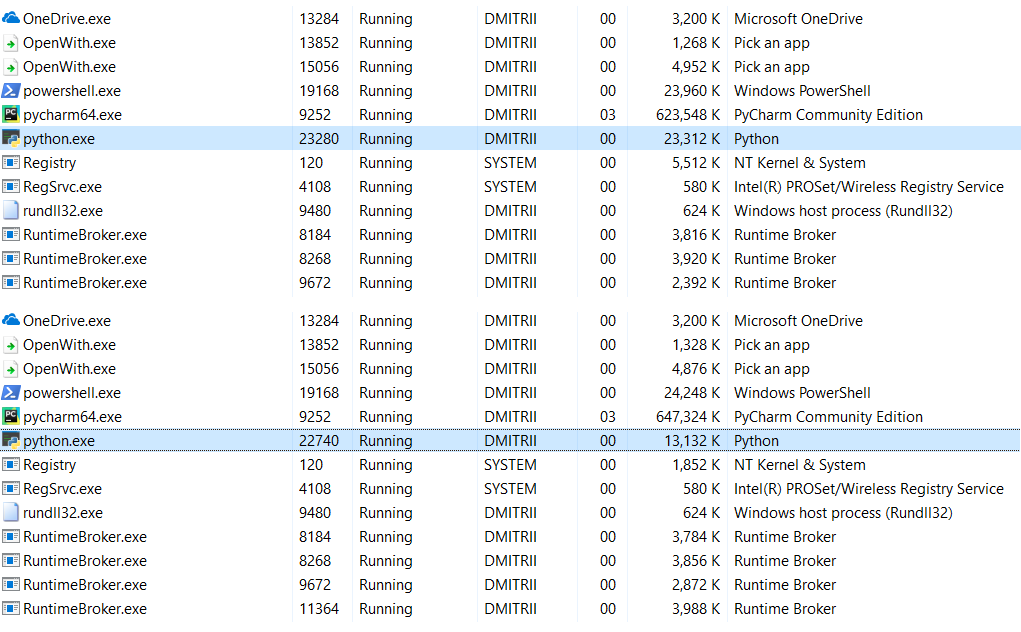
ماذا تفعل إذا كنت بحاجة إلى توفير المزيد من الذاكرة؟ هذا ممكن باستخدام مكتبة
numpy ، والتي تسمح لك بإنشاء هياكل على غرار C ، ولكن في حالتي ، سيتطلب الأمر تحسينًا أعمق للرمز ، وتبين أن الطريقة الأولى كافية تمامًا.
من الغريب أن استخدام __slots__ لم يتم فحصه بالتفصيل على حبري ، آمل أن تملأ هذه المقالة هذه الفجوة قليلاً.
بدلا من الاستنتاج.
قد تبدو هذه المقالة وكأنها مكافحة للإعلان في Python ، ولكنها ليست على الإطلاق. Python موثوق به للغاية (يجب أن تحاول جاهدًا
للغاية لإسقاط برنامج Python) ، وهي لغة يمكن قراءتها بسهولة وسهلة لكتابة التعليمات البرمجية. هذه المزايا تفوق السلبيات في كثير من الحالات ، ولكن إذا كنت بحاجة إلى أقصى قدر من الأداء والكفاءة ، فيمكنك استخدام مكتبات مثل مكتوبة بلغة C ++ تعمل مع البيانات بسرعة وكفاءة.
شكرا لكم جميعا على اهتمامكم ، وكود جيد :)