جربت تحسينات
لنموذج التنبؤ
Guess.js ، بدأت أنظر عن كثب إلى التعلم العميق: الشبكات العصبية المتكررة (RNNs) ، ولا سيما LSTMs ، بسبب
"فعاليتها غير المعقولة" في المنطقة التي يعمل فيها Guess.js. في الوقت نفسه ، بدأت أتلاعب بالشبكات العصبية التلافيفية (CNN) ، والتي غالبًا ما تستخدم أيضًا في السلاسل الزمنية. تُستخدم شبكات CNN بشكل شائع لتصنيف الصور والتعرف عليها واكتشافها.
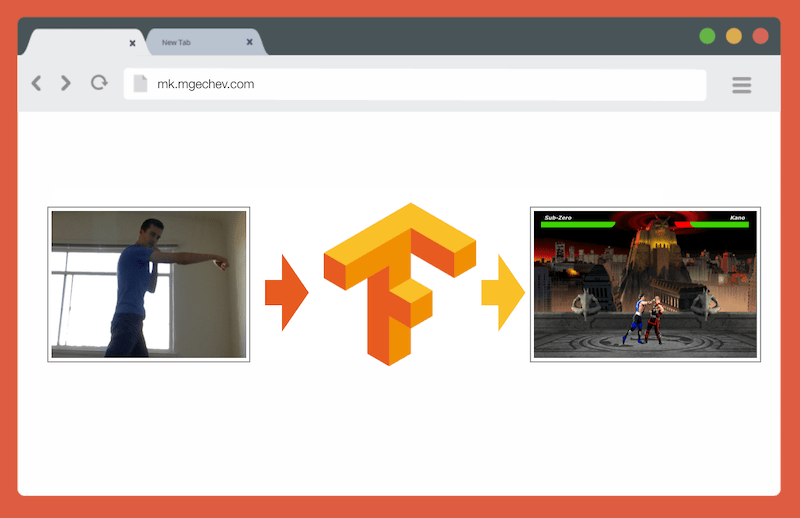 إدارة MK.js باستخدام TensorFlow.js
إدارة MK.js باستخدام TensorFlow.jsشفرة المصدر لهذه المقالة و MK.js موجودة على GitHub . لم أنشر مجموعة بيانات تدريبية ، ولكن يمكنك إنشاء النموذج الخاص بك وتدريب النموذج كما هو موضح أدناه!
بعد اللعب مع CNN ، تذكرت
تجربة أجريتها منذ عدة سنوات عندما أطلق مطورو المتصفح واجهة برمجة تطبيقات
getUserMedia . في ذلك ، عملت كاميرا المستخدم كجهاز تحكم لتشغيل استنساخ JavaScript الصغير لـ Mortal Kombat 3. يمكنك العثور على هذه اللعبة في
مستودع GitHub . كجزء من التجربة ، قمت بتطبيق خوارزمية تحديد المواقع الأساسية التي تصنف الصورة إلى الفئات التالية:
- لكمة يسار أو يمين
- ركلة اليسار أو اليمين
- خطوات اليسار واليمين
- القرفصاء
- لا شيء مما سبق
الخوارزمية بسيطة لدرجة أنني أستطيع شرحها في بضع جمل:
الخوارزمية تصور الخلفية. بمجرد ظهور المستخدم في الإطار ، تحسب الخوارزمية الفرق بين الخلفية والإطار الحالي مع المستخدم. لذا فهي تحدد موضع شخصية المستخدم. الخطوة التالية هي عرض جسم المستخدم باللون الأبيض على الأسود. بعد ذلك ، يتم إنشاء الرسوم البيانية الرأسية والأفقية ، ويلخص القيم لكل بكسل. بناءً على هذا الحساب ، تحدد الخوارزمية الوضع الحالي للجسم.
يظهر الفيديو كيف يعمل البرنامج. كود مصدر
جيثب .
على الرغم من نجاح استنساخ MK الصغير ، إلا أن الخوارزمية أبعد ما تكون عن الكمال. مطلوب إطار بخلفية. للتشغيل السليم ، يجب أن تكون الخلفية من نفس اللون طوال تنفيذ البرنامج. مثل هذا القيد يعني أن التغييرات في الضوء والظل وغيرها من الأشياء ستتداخل وتعطي نتيجة غير دقيقة. وأخيرًا ، لا تتعرف الخوارزمية على الإجراء ؛ يصنف فقط الإطار الجديد على أنه موضع الجسم من مجموعة محددة مسبقًا.
الآن ، بفضل التقدم في واجهة برمجة تطبيقات الويب ، وبالتحديد WebGL ، قررت العودة إلى هذه المهمة من خلال تطبيق TensorFlow.js.
مقدمة
في هذه المقالة ، سأشارك تجربتي في إنشاء خوارزمية لتصنيف أوضاع الجسم باستخدام TensorFlow.js و MobileNet. خذ بعين الاعتبار المواضيع التالية:
- جمع بيانات التدريب لتصنيف الصور
- زيادة البيانات باستخدام imgaug
- نقل التعلم باستخدام MobileNet
- التصنيف الثنائي والتصنيف الأساسي N
- تدريب نموذج تصنيف الصور TensorFlow.js في Node.js واستخدامه في المتصفح
- بضع كلمات حول تصنيف الإجراءات باستخدام LSTM
في هذه المقالة ، سنقوم بتقليل المشكلة لتحديد موضع الجسم على أساس إطار واحد ، على النقيض من التعرف على الإجراءات من خلال سلسلة من الإطارات. سنقوم بتطوير نموذج للتعلم العميق مع مدرس ، والذي ، بناءً على الصورة من كاميرا الويب الخاصة بالمستخدم ، يحدد حركات الشخص: ركلة ، ساق ، أو لا شيء من هذا.
في نهاية المقال سنكون قادرين على بناء نموذج للعب
MK.js :

من أجل فهم أفضل للمقال ، يجب أن يكون القارئ على دراية بالمفاهيم الأساسية للبرمجة وجافا سكريبت. إن الفهم الأساسي للتعلم العميق مفيد أيضًا ، ولكنه ليس ضروريًا.
جمع البيانات
تعتمد دقة نموذج التعلم العميق بشكل كبير على جودة البيانات. نحن بحاجة إلى السعي لجمع مجموعة بيانات واسعة النطاق ، كما هو الحال في الإنتاج.
يجب أن يكون نموذجنا قادرًا على التعرف على اللكمات والركلات. هذا يعني أنه يجب علينا جمع صور من ثلاث فئات:
في هذه التجربة ،
ساعدني متطوعان (
lili_vs و
gsamokovarov ) في جمع الصور. سجلنا 5 مقاطع فيديو QuickTime على جهاز MacBook Pro ، يحتوي كل منها على 2-4 ركلات و 2-4 ركلات.
ثم نستخدم ffmpeg لاستخراج الإطارات الفردية من مقاطع الفيديو وحفظها كصور
jpg :
ffmpeg -i video.mov $filename%03d.jpgلتنفيذ الأمر أعلاه ، تحتاج أولاً إلى
تثبيت ffmpeg على جهاز الكمبيوتر.
إذا أردنا تدريب النموذج ، فيجب علينا توفير بيانات الإدخال وبيانات الإخراج المقابلة ، ولكن في هذه المرحلة لدينا مجموعة من الصور لثلاثة أشخاص فقط في أوضاع مختلفة. لتنظيم البيانات ، تحتاج إلى تصنيف الإطارات في ثلاث فئات: اللكمات والركلات وغيرها. لكل فئة ، يتم إنشاء دليل منفصل حيث يتم نقل جميع الصور المقابلة.
وبالتالي ، في كل دليل يجب أن يكون هناك حوالي 200 صورة مشابهة لتلك الموجودة أدناه:

يرجى ملاحظة أنه سيكون هناك المزيد من الصور في دليل الآخرين ، لأن الإطارات قليلة نسبيًا تحتوي على صور لللكمات والركلات ، وفي الإطارات المتبقية يتجول الناس أو يستديرون أو يتحكمون في الفيديو. إذا كان لدينا عدد كبير جدًا من الصور لفصل واحد ، فإننا نخاطر بتدريس النموذج المتحيز تجاه هذا الفصل بعينه. في هذه الحالة ، عند تصنيف صورة ذات تأثير ، يمكن للشبكة العصبية تحديد فئة "أخرى". لتقليل هذا التحيز ، يمكنك إزالة بعض الصور من دليل الآخرين وتدريب النموذج على عدد متساو من الصور من كل فئة.
من أجل الراحة ، نقوم بتعيين الأرقام في أرقام الكتالوجات من
1 إلى
190 ، لذلك ستكون الصورة الأولى
1.jpg ، والثانية
2.jpg ، إلخ.
إذا قمنا بتدريب النموذج في 600 صورة فقط تم التقاطها في نفس البيئة مع نفس الأشخاص ، فلن نحقق مستوى عالٍ جدًا من الدقة. لتحقيق أقصى استفادة من بياناتنا ، من الأفضل إنشاء بعض العينات الإضافية باستخدام زيادة البيانات.
زيادة البيانات
زيادة البيانات هي تقنية تزيد من عدد نقاط البيانات عن طريق تجميع نقاط جديدة من مجموعة موجودة. عادة ، يتم استخدام زيادة لزيادة حجم وتنوع مجموعة التدريب. ننقل الصور الأصلية إلى خط الأنابيب للتحويلات التي تنشئ صورًا جديدة. لا يمكنك الاقتراب من التحولات بقوة: يجب إنشاء لكمات يدوية أخرى من لكمة.
التحولات المقبولة هي الدوران ، عكس اللون ، التمويه ، إلخ. هناك أدوات ممتازة مفتوحة المصدر لزيادة البيانات. في وقت كتابة هذا المقال في جافا سكريبت ، لم يكن هناك الكثير من الخيارات ، لذلك استخدمت المكتبة التي تم تنفيذها في Python -
imgaug . لديها مجموعة من المعززات التي يمكن تطبيقها باحتمالية.
في ما يلي منطق زيادة البيانات لهذه التجربة:
np.random.seed(44) ia.seed(44) def main(): for i in range(1, 191): draw_single_sequential_images(str(i), "others", "others-aug") for i in range(1, 191): draw_single_sequential_images(str(i), "hits", "hits-aug") for i in range(1, 191): draw_single_sequential_images(str(i), "kicks", "kicks-aug") def draw_single_sequential_images(filename, path, aug_path): image = misc.imresize(ndimage.imread(path + "/" + filename + ".jpg"), (56, 100)) sometimes = lambda aug: iaa.Sometimes(0.5, aug) seq = iaa.Sequential( [ iaa.Fliplr(0.5),
يستخدم هذا البرنامج النصي الطريقة
main مع ثلاث حلقات - واحدة لكل فئة صورة. في كل تكرار ، في كل حلقة ، نسمي طريقة
draw_single_sequential_images : الوسيطة الأولى هي اسم الملف ، والثاني هو المسار ، والثالث هو الدليل حيث يتم حفظ النتيجة.
بعد ذلك ، نقرأ الصورة من القرص ونطبق عليها سلسلة من التحولات. لقد وثقت معظم التحويلات في مقتطف الشفرة أعلاه ، لذلك لن نكررها.
لكل صورة ، يتم إنشاء 16 صورة أخرى. فيما يلي مثال لكيفية ظهورها:

يرجى ملاحظة أنه في البرنامج النصي أعلاه نقوم
100x56 الصور إلى
100x56 بكسل. نقوم بذلك لتقليل كمية البيانات ، وبالتالي عدد الحسابات التي يقوم بها نموذجنا أثناء التدريب والتقييم.
بناء نموذجي
الآن قم ببناء نموذج للتصنيف!
نظرًا لأننا نتعامل مع الصور ، فإننا نستخدم شبكة عصبية تلافيفية (CNN). من المعروف أن بنية الشبكة هذه مناسبة للتعرف على الصور واكتشاف الكائنات والتصنيف.
نقل التعلم
تُظهر الصورة أدناه CNN VGG-16 ، المستخدم لتصنيف الصور.
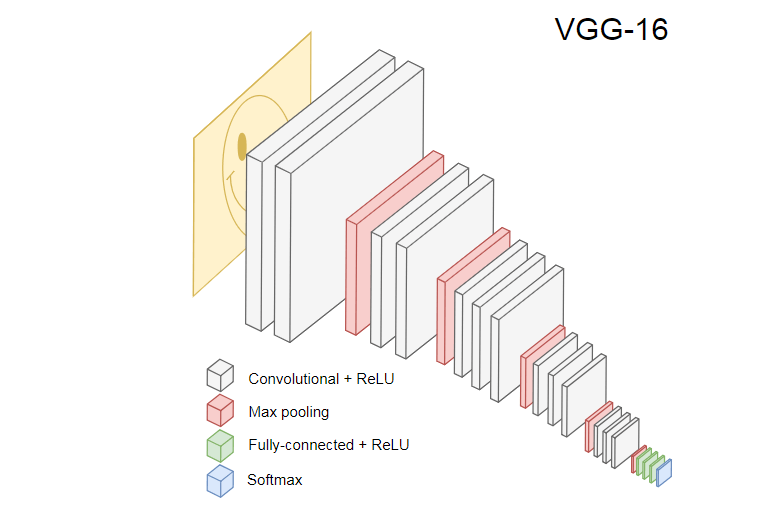
تتعرف الشبكة العصبية VGG-16 على 1000 فئة للصور. لديها 16 طبقة (لا تحسب طبقات التجميع والإخراج). من الصعب تدريب مثل هذه الشبكة متعددة الطبقات من الناحية العملية. سيتطلب ذلك مجموعة بيانات كبيرة وساعات تدريب طويلة.
تتعرف الطبقات المخفية من CNN على عناصر مختلفة من الصور من مجموعة التدريب ، بدءًا من الحواف ، والانتقال إلى العناصر الأكثر تعقيدًا ، مثل الأشكال والأشياء الفردية ، وما إلى ذلك. يجب أن يكون للشبكة CNN المدربة بأسلوب VGG-16 للتعرف على مجموعة كبيرة من الصور طبقات مخفية تعلمت الكثير من الميزات من مجموعة التدريب. ستكون هذه الميزات شائعة في معظم الصور ، وبالتالي يتم إعادة استخدامها في مهام مختلفة.
يسمح لك نقل التعلم بإعادة استخدام شبكة حالية ومدربة. يمكننا أخذ الإخراج من أي من طبقات الشبكة الحالية ونقله كمدخل إلى الشبكة العصبية الجديدة. وهكذا ، من خلال تعليم الشبكة العصبية التي تم إنشاؤها حديثًا ، يمكن بمرور الوقت تعلم كيفية التعرف على الميزات الجديدة لمستوى أعلى وتصنيف الصور بشكل صحيح من الفصول التي لم يسبق أن شهدها النموذج الأصلي من قبل.
لأغراضنا ، خذ الشبكة العصبية MobileNet من
حزمة @ tensorflow-models / mobilenet . إن MobileNet قوية مثل VGG-16 ، ولكنها أصغر بكثير ، مما يسرع التوزيع المباشر ، أي انتشار الشبكة (الانتشار الأمامي) ، ويقلل وقت التنزيل في المتصفح. تم تدريب MobileNet على
مجموعة بيانات تصنيف الصور
ILSVRC-2012-CLS .
عند تطوير نموذج مع نقل التعلم ، لدينا خياران:
- الناتج الذي يتم استخدام طبقة النموذج المصدر منه كمدخل للنموذج الهدف.
- كم عدد الطبقات من النموذج المستهدف الذي سنتدربه ، إن وجد.
النقطة الأولى مهمة للغاية. اعتمادًا على الطبقة المحددة ، سنحصل على ميزات بمستوى أقل أو أعلى من التجريد كمدخل إلى شبكتنا العصبية.
لن نقوم بتدريب أي طبقات من MobileNet.
global_average_pooling2d_1 الإخراج من
global_average_pooling2d_1 الصغير. لماذا اخترت هذه الطبقة بالذات؟ تجريبيا. لقد أجريت بعض الاختبارات ، وهذه الطبقة تعمل بشكل جيد.
تعريف النموذج
كانت المهمة الأولية هي تصنيف الصورة إلى ثلاث فئات: اليد والقدم والحركات الأخرى. أولاً ، دعنا نحل المشكلة الأصغر: سنحدد ما إذا كان هناك ضربة يدوية في الإطار أم لا. هذه مشكلة تصنيف ثنائية نموذجية. لهذا الغرض ، يمكننا تحديد النموذج التالي:
import * as tf from '@tensorflow/tfjs'; const model = tf.sequential(); model.add(tf.layers.inputLayer({ inputShape: [1024] })); model.add(tf.layers.dense({ units: 1024, activation: 'relu' })); model.add(tf.layers.dense({ units: 1, activation: 'sigmoid' })); model.compile({ optimizer: tf.train.adam(1e-6), loss: tf.losses.sigmoidCrossEntropy, metrics: ['accuracy'] });
تحدد هذه الشفرة نموذجًا بسيطًا ، وطبقة ذات
1024 وحدة وتنشيط
ReLU ، بالإضافة إلى وحدة إخراج واحدة تمر عبر
sigmoid التنشيط
sigmoid . يعطي الأخير رقمًا من
0 إلى
1 ، اعتمادًا على احتمالية إصابة اليد في هذا الإطار.
لماذا اخترت
1024 وحدة للمستوى الثاني وسرعة تدريب
1e-6 ؟ حسنًا ، لقد جربت العديد من الخيارات المختلفة ورأيت أن هذه الخيارات تعمل بشكل أفضل. لا يبدو أن طريقة الرمح هي أفضل نهج ، ولكن إلى حد كبير هذه هي الطريقة التي تعمل بها إعدادات المعلمات المفرطة في عمل التعلم العميق - بناءً على فهمنا للنموذج ، فإننا نستخدم الحدس لتحديث المعلمات المتعامدة والتحقق تجريبيًا من كيفية عمل النموذج.
compile طريقة
compile الطبقات معًا ، وتعد النموذج للتدريب والتقييم. نعلن هنا أننا نريد استخدام خوارزمية تحسين
adam . نعلن أيضًا أننا سنحسب الخسارة (الخسارة) من الكون المتقاطع ، ونشير إلى أننا نريد تقييم دقة النموذج. ثم يحسب TensorFlow.js الدقة باستخدام الصيغة:
Accuracy = (True Positives + True Negatives) / (Positives + Negatives)إذا قمت بنقل التدريب من طراز MobileNet الأصلي ، يجب عليك تنزيله أولاً. نظرًا لأنه ليس من العملي تدريب نموذجنا على أكثر من 3000 صورة في متصفح ، فسوف نستخدم Node.js ونحمل الشبكة العصبية من الملف.
قم بتنزيل MobileNet
هنا . يحتوي الكتالوج على ملف
model.json ، الذي يحتوي على بنية النموذج - الطبقات ، التنشيط ، إلخ. تحتوي الملفات المتبقية على معلمات النموذج. يمكنك تحميل النموذج من ملف باستخدام هذا الرمز:
export const loadModel = async () => { const mn = new mobilenet.MobileNet(1, 1); mn.path = `file://PATH/TO/model.json`; await mn.load(); return (input): tf.Tensor1D => mn.infer(input, 'global_average_pooling2d_1') .reshape([1024]); };
لاحظ أنه في طريقة
loadModel نقوم بإرجاع دالة تقبل موتر أحادي البعد كمدخل وإرجاع
mn.infer(input, Layer) . تأخذ طريقة
infer الموتر والطبقة كوسيطة. تحدد الطبقة الطبقة المخفية التي نريد الإخراج منها. إذا فتحت
model.json global_average_pooling2d_1 ، فستجد مثل هذا الاسم في إحدى الطبقات.
تحتاج الآن إلى إنشاء مجموعة بيانات لتدريب النموذج. للقيام بذلك ، يجب علينا تمرير جميع الصور من خلال طريقة
infer في MobileNet وتعيين تسميات لهم:
1 للصور ذات الخطوط و
0 للصور بدون حدود:
const punches = require('fs') .readdirSync(Punches) .filter(f => f.endsWith('.jpg')) .map(f => `${Punches}/${f}`); const others = require('fs') .readdirSync(Others) .filter(f => f.endsWith('.jpg')) .map(f => `${Others}/${f}`); const ys = tf.tensor1d( new Array(punches.length).fill(1) .concat(new Array(others.length).fill(0))); const xs: tf.Tensor2D = tf.stack( punches .map((path: string) => mobileNet(readInput(path))) .concat(others.map((path: string) => mobileNet(readInput(path)))) ) as tf.Tensor2D;
في الكود أعلاه ، قرأنا أولاً الملفات في الدلائل مع أو بدون نتائج. ثم نحدد الموتر أحادي البعد الذي يحتوي على تسميات الإخراج. إذا كان لدينا
n صور مع حدود وصور
m أخرى ، فسيحتوي الموتر على عناصر
n بقيمة 1 وعناصر
m بقيمة 0.
في
xs infer نتائج استدعاء طريقة
infer للصور الفردية. لاحظ أنه لكل صورة ، نسمي طريقة
readInput . هنا هو تنفيذه:
export const readInput = img => imageToInput(readImage(img), TotalChannels); const readImage = path => jpeg.decode(fs.readFileSync(path), true); const imageToInput = image => { const values = serializeImage(image); return tf.tensor3d(values, [image.height, image.width, 3], 'int32'); }; const serializeImage = image => { const totalPixels = image.width * image.height; const result = new Int32Array(totalPixels * 3); for (let i = 0; i < totalPixels; i++) { result[i * 3 + 0] = image.data[i * 4 + 0]; result[i * 3 + 1] = image.data[i * 4 + 1]; result[i * 3 + 2] = image.data[i * 4 + 2]; } return result; };
يستدعي
readInput أولاً وظيفة
readImage ، وبعد ذلك يفوض استدعائها إلى
imageToInput . تقرأ وظيفة
readImage صورة من القرص ثم تقوم بفك تشفير jpg من المخزن المؤقت باستخدام حزمة
jpeg-js . في
imageToInput نقوم بتحويل الصورة إلى موتر ثلاثي الأبعاد.
ونتيجة لذلك ، يجب أن يكون لكل
i من
0 إلى
TotalImages ys[i] تساوي
1 إذا كانت
xs[i] تتوافق مع الصورة مع ضرب ، و
0 خلاف ذلك.
تدريب نموذجي
الآن النموذج جاهز للتدريب! استدعاء الأسلوب
fit :
await model.fit(xs, ys, { epochs: Epochs, batchSize: parseInt(((punches.length + others.length) * BatchSize).toFixed(0)), callbacks: { onBatchEnd: async (_, logs) => { console.log('Cost: %s, accuracy: %s', logs.loss.toFixed(5), logs.acc.toFixed(5)); await tf.nextFrame(); } } });
fit مكالمات الرمز أعلاه مع ثلاث وسيطات:
xs و ys وكائن التكوين. في كائن التكوين ، قمنا بتعيين عدد العصور التي سيولدها النموذج ، وحجم الحزمة ، ورد الاتصال TensorFlow.js بعد معالجة كل حزمة سيتم تدريبها.
يحدد حجم الحزمة
xs و
ys لتدريب النموذج في عصر واحد. لكل عصر ، سيختار TensorFlow.js مجموعة فرعية من
xs والعناصر المقابلة من
ys ، ويقوم بتوزيع مباشر ، ويتلقى إخراج الطبقة مع التنشيط
sigmoid ، ثم ، بناءً على الخسارة ، قم بإجراء التحسين باستخدام خوارزمية
adam .
بعد بدء البرنامج النصي للتدريب ، سترى نتيجة مشابهة للنتائج أدناه:
التكلفة: 0.84212 ، الدقة: 1.00000
eta = 0.3> ---------- acc = 1.00 خسارة = 0.84 التكلفة: 0.79740 ، الدقة: 1.00000
eta = 0.2 => --------- acc = 1.00 خسارة = 0.80 التكلفة: 0.81533 ، الدقة: 1.00000
eta = 0.2 ==> -------- acc = 1.00 خسارة = 0.82 التكلفة: 0.64303 ، الدقة: 0.50000
eta = 0.2 ===> ------- acc = 0.50 خسارة = 0.64 التكلفة: 0.51377 ، الدقة: 0.00000
eta = 0.2 ====> ------ acc = 0.00 خسارة = 0.51 التكلفة: 0.46473 ، الدقة: 0.50000
eta = 0.1 =====> ----- acc = 0.50 خسارة = 0.46 التكلفة: 0.50872 ، الدقة: 0.00000
eta = 0.1 ======> ---- acc = 0.00 خسارة = 0.51 التكلفة: 0.62556 ، الدقة: 1.00000
eta = 0.1 =======> --- acc = 1.00 خسارة = 0.63 التكلفة: 0.65133 ، الدقة: 0.50000
eta = 0.1 ========> - acc = 0.50 خسارة = 0.65 التكلفة: 0.63824 ، الدقة: 0.50000
eta = 0.0 ===========>
293ms 14675us / step - acc = 0.60 خسارة = 0.65
العصر 3/50
التكلفة: 0.44661 ، الدقة: 1.00000
eta = 0.3> ---------- acc = 1.00 خسارة = 0.45 التكلفة: 0.78060 ، الدقة: 1.00000
eta = 0.3 => --------- acc = 1.00 خسارة = 0.78 التكلفة: 0.79208 ، الدقة: 1.00000
eta = 0.3 ==> -------- acc = 1.00 خسارة = 0.79 التكلفة: 0.49072 ، الدقة: 0.50000
eta = 0.2 ===> ------- acc = 0.50 خسارة = 0.49 التكلفة: 0.62232 ، الدقة: 1.00000
eta = 0.2 ====> ------ acc = 1.00 خسارة = 0.62 التكلفة: 0.82899 ، الدقة: 1.00000
eta = 0.2 =====> ----- acc = 1.00 خسارة = 0.83 التكلفة: 0.67629 ، الدقة: 0.50000
eta = 0.1 ======> ---- acc = 0.50 خسارة = 0.68 التكلفة: 0.62621 ، الدقة: 0.50000
eta = 0.1 =======> --- acc = 0.50 خسارة = 0.63 التكلفة: 0.46077 ، الدقة: 1.00000
eta = 0.1 ========> - acc = 1.00 خسارة = 0.46 التكلفة: 0.62076 ، الدقة: 1.00000
eta = 0.0 ===========>
304ms 15221us / step - acc = 0.85 خسارة = 0.63
لاحظ كيف تزداد الدقة بمرور الوقت وتقل الخسارة.
في مجموعة البيانات الخاصة بي ، أظهر النموذج بعد التدريب دقة 92٪. ضع في اعتبارك أن الدقة قد لا تكون عالية جدًا بسبب مجموعة صغيرة من بيانات التدريب.
تشغيل النموذج في المتصفح
في القسم السابق ، قمنا بتدريب نموذج التصنيف الثنائي. الآن قم بتشغيله في متصفح
واتصل بـ
MK.js !
const video = document.getElementById('cam'); const Layer = 'global_average_pooling2d_1'; const mobilenetInfer = m => (p): tf.Tensor<tf.Rank> => m.infer(p, Layer); const canvas = document.getElementById('canvas'); const scale = document.getElementById('crop'); const ImageSize = { Width: 100, Height: 56 }; navigator.mediaDevices .getUserMedia({ video: true, audio: false }) .then(stream => { video.srcObject = stream; });
هناك العديد من الإعلانات في الكود أعلاه:
video HTML5 videoLayer MobileNet,mobilenetInfer — , MobileNet . MobileNetcanvas HTML5 canvas ,scale — canvas ,
بعد ذلك ، نحصل على دفق الفيديو من كاميرا المستخدم ونعينه كمصدر للعنصر video.الخطوة التالية هي تنفيذ مرشح تدرج الرمادي يقبل canvasمحتوياته ويحولها: const grayscale = (canvas: HTMLCanvasElement) => { const imageData = canvas.getContext('2d').getImageData(0, 0, canvas.width, canvas.height); const data = imageData.data; for (let i = 0; i < data.length; i += 4) { const avg = (data[i] + data[i + 1] + data[i + 2]) / 3; data[i] = avg; data[i + 1] = avg; data[i + 2] = avg; } canvas.getContext('2d').putImageData(imageData, 0, 0); };
كخطوة تالية ، سنقوم بربط النموذج بـ MK.js: let mobilenet: (p: any) => tf.Tensor<tf.Rank>; tf.loadModel('http://localhost:5000/model.json').then(model => { mobileNet .load() .then((mn: any) => mobilenet = mobilenetInfer(mn)) .then(startInterval(mobilenet, model)); });
في الكود أعلاه ، نقوم أولاً بتحميل النموذج الذي دربناه أعلاه ، ثم نزل MobileNet. نقوم بتمرير MobileNet في الطريقة mobilenetInferللحصول على طريقة لحساب الإخراج من طبقة الشبكة المخفية. بعد ذلك ، نسمي الطريقة startIntervalبشبكتين كوسيطة. const startInterval = (mobilenet, model) => () => { setInterval(() => { canvas.getContext('2d').drawImage(video, 0, 0); grayscale(scale .getContext('2d') .drawImage( canvas, 0, 0, canvas.width, canvas.width / (ImageSize.Width / ImageSize.Height), 0, 0, ImageSize.Width, ImageSize.Height )); const [punching] = Array.from(( model.predict(mobilenet(tf.fromPixels(scale))) as tf.Tensor1D) .dataSync() as Float32Array); const detect = (window as any).Detect; if (punching >= 0.4) detect && detect.onPunch(); }, 100); };
يبدأ الجزء الأكثر إثارة للاهتمام في الطريقة startInterval! أولاً ، نقوم بتشغيل فاصل زمني حيث 100msيدعو الجميع وظيفة مجهولة. في ذلك ، يتم تقديم canvasالفيديو بالإطار الحالي أولاً فوقه . ثم نقوم بتقليل حجم الإطار إلى 100x56وتطبيق مرشح تدرج الرمادي عليه.الخطوة التالية هي نقل الإطار إلى MobileNet ، والحصول على الإخراج من الطبقة المخفية المطلوبة ونقله كمدخل لطريقة predictنموذجنا. هذا يعيد موتر بعنصر واحد. باستخدام ، dataSyncنحصل على القيمة من الموتر ونعينها إلى ثابت punching.أخيرًا ، نتحقق: إذا تجاوز احتمال ضربة اليد 0.4، فإننا نسمي طريقة onPunchالكائن العام Detect. يوفر MK.js كائنًا عالميًا بثلاث طرق:onKick، onPunchو onStandأننا يمكن أن تستخدم للسيطرة على واحدة من الشخصيات.انتهى!
ها هي النتيجة!
التعرف على الركل والذراع مع تصنيف N
في القسم التالي ، سنصنع نموذجًا أكثر ذكاءً: شبكة عصبية تتعرف على اللكمات والركلات والصور الأخرى. هذه المرة ، لنبدأ بإعداد مجموعة التدريب: const punches = require('fs') .readdirSync(Punches) .filter(f => f.endsWith('.jpg')) .map(f => `${Punches}/${f}`); const kicks = require('fs') .readdirSync(Kicks) .filter(f => f.endsWith('.jpg')) .map(f => `${Kicks}/${f}`); const others = require('fs') .readdirSync(Others) .filter(f => f.endsWith('.jpg')) .map(f => `${Others}/${f}`); const ys = tf.tensor2d( new Array(punches.length) .fill([1, 0, 0]) .concat(new Array(kicks.length).fill([0, 1, 0])) .concat(new Array(others.length).fill([0, 0, 1])), [punches.length + kicks.length + others.length, 3] ); const xs: tf.Tensor2D = tf.stack( punches .map((path: string) => mobileNet(readInput(path))) .concat(kicks.map((path: string) => mobileNet(readInput(path)))) .concat(others.map((path: string) => mobileNet(readInput(path)))) ) as tf.Tensor2D;
كما كان من قبل ، قرأنا أولاً الكتالوجات مع صور اللكمات باليد والقدم وغيرها من الصور. بعد ذلك ، على عكس المرة الأخيرة ، نشكل النتيجة المتوقعة في شكل موتر ثنائي الأبعاد ، وليس بعد واحد. اذا كان لدينا ن الصور مع لكمة، م الصور مع ركلة و ك صور أخرى، موتر ysستكون nعناصر القيمة [1, 0, 0]، mالعناصر مع قيمة [0, 1, 0]و kبنود ذات قيمة [0, 0, 1].متجه nللعناصر التي توجد فيها n - 1عناصر بقيمة 0وعنصر واحد بقيمة 1، فإننا نسمي متجهًا أحاديًا (متجه واحد ساخن).بعد ذلك ، نقوم بتشكيل موتر الإدخالxsتكديس إخراج كل صورة من MobileNet.هنا عليك تحديث تعريف النموذج: const model = tf.sequential(); model.add(tf.layers.inputLayer({ inputShape: [1024] })); model.add(tf.layers.dense({ units: 1024, activation: 'relu' })); model.add(tf.layers.dense({ units: 3, activation: 'softmax' })); await model.compile({ optimizer: tf.train.adam(1e-6), loss: tf.losses.sigmoidCrossEntropy, metrics: ['accuracy'] });
الاختلافان الوحيدان عن النموذج السابق هما:- عدد الوحدات في طبقة الإخراج
- التنشيط في طبقة الإخراج
هناك ثلاث وحدات في طبقة الإخراج ، لأن لدينا ثلاث فئات مختلفة من الصور:يتم تشغيل التنشيط على هذه الوحدات الثلاث softmax، والتي تحول معلماتها إلى موتر بثلاث قيم. لماذا ثلاث وحدات لطبقة الإخراج؟ كل من القيم الثلاث لثلاث فئات يمكن أن تكون ممثلة من قبل اثنين من بت: 00، 01، 10. مجموع قيم الموتر الذي تم إنشاؤه softmaxهو 1 ، أي أننا لن نحصل على 00 أبدًا ، لذلك لن نتمكن من تصنيف صور إحدى الفصول.بعد تدريب النموذج على 500مر العصور ، حققت دقة حوالي 92٪! هذا ليس سيئًا ، ولكن لا تنس أن التدريب قد تم على مجموعة بيانات صغيرة.الخطوة التالية هي تشغيل النموذج في متصفح! نظرًا لأن المنطق يشبه إلى حد كبير تشغيل النموذج للتصنيف الثنائي ، ألق نظرة على الخطوة الأخيرة ، حيث يتم تحديد الإجراء بناءً على إخراج النموذج: const [punch, kick, nothing] = Array.from((model.predict( mobilenet(tf.fromPixels(scaled)) ) as tf.Tensor1D).dataSync() as Float32Array); const detect = (window as any).Detect; if (nothing >= 0.4) return; if (kick > punch && kick >= 0.35) { detect.onKick(); return; } if (punch > kick && punch >= 0.35) detect.onPunch();
أولاً نسمي MobileNet بإطار مخفّض بظلال رمادية ، ثم ننقل نتيجة نموذجنا المدرّب. يقوم النموذج بإرجاع موتر أحادي البعد ، والذي نقوم بتحويله إلى Float32Arrayc dataSync. نستخدم Array.fromفي الخطوة التالية لإرسال مصفوفة مكتوبة إلى مصفوفة JavaScript. ثم نستخرج احتمالات وجود لقطة بيد أو ركلة أو لا شيء على الإطار.إذا تجاوز احتمال النتيجة الثالثة 0.4، نعود. خلاف ذلك ، إذا كان احتمال الركلة أعلى 0.32، نرسل أمر ركلة إلى MK.js. إذا كان احتمال الركلة أعلى 0.32وأعلى من احتمال الركلة ، فإننا نرسل حركة الركلة.بشكل عام ، هذا كل شيء! النتيجة موضحة أدناه:
التعرف على العمل
إذا جمعت مجموعة كبيرة ومتنوعة من البيانات حول الأشخاص الذين يضربون بأيديهم وأقدامهم ، فيمكنك بناء نموذج يعمل بشكل رائع على الإطارات الفردية. ولكن هل هذا يكفي؟ ماذا لو أردنا الذهاب إلى أبعد من ذلك وتمييز نوعين مختلفين من الركلات: من الدوران ومن الخلف (الركلة الخلفية).كما يمكن رؤيته في الإطارات أدناه ، في وقت معين من زاوية معينة ، تبدو كلتا الجلستين متشابهتين:
 ولكن إذا نظرت إلى الأداء ، فإن الحركات مختلفة تمامًا:
ولكن إذا نظرت إلى الأداء ، فإن الحركات مختلفة تمامًا: كيف يمكنك تدريب شبكة عصبية لتحليل تسلسل الإطارات ، وليس فقط إطار واحد؟لهذا الغرض ، يمكننا استكشاف فئة أخرى من الشبكات العصبية ، تسمى الشبكات العصبية المتكررة (RNNs). على سبيل المثال ، RNNs رائعة للعمل مع السلاسل الزمنية:
كيف يمكنك تدريب شبكة عصبية لتحليل تسلسل الإطارات ، وليس فقط إطار واحد؟لهذا الغرض ، يمكننا استكشاف فئة أخرى من الشبكات العصبية ، تسمى الشبكات العصبية المتكررة (RNNs). على سبيل المثال ، RNNs رائعة للعمل مع السلاسل الزمنية:- معالجة اللغات الطبيعية (NLP) ، حيث تعتمد كل كلمة على السابقة واللاحقة
- توقع الصفحة التالية بناءً على سجل التصفح الخاص بك
- التعرف على الإطار
تطبيق مثل هذا النموذج هو خارج نطاق هذه المقالة ، ولكن دعونا نلقي نظرة على مثال الهندسة المعمارية للحصول على فكرة عن كيفية عمل كل هذا معًا.قوة RNN
يوضح الرسم البياني أدناه نموذج التعرف على الإجراءات: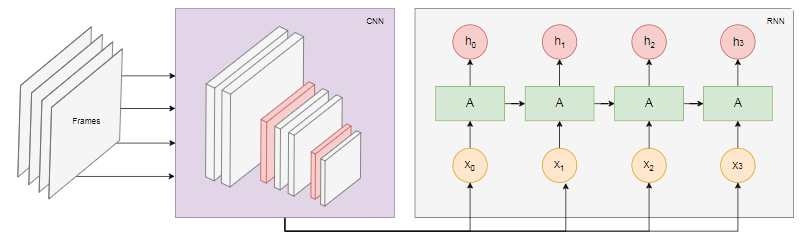 نأخذ
نأخذ nالإطارات الأخيرة من الفيديو وننقلها إلى CNN. يُرسل خرج CNN لكل رتل كمدخل RNN. ستحدد الشبكة العصبية المتكررة العلاقات بين الإطارات الفردية وتتعرف على الإجراء الذي تتوافق معه.الخلاصة
في هذه المقالة ، قمنا بتطوير نموذج تصنيف الصور. لهذا الغرض ، جمعنا مجموعة بيانات: استخرجنا إطارات الفيديو وقسمناها يدويًا إلى ثلاث فئات. ثم تم زيادة البيانات بإضافة الصور باستخدام imgaug .بعد ذلك ، شرحنا ما هو نقل التعلم واستخدمنا نموذج MobileNet المدرّب من حزمة @ tensorflow-models / mobilenet لأغراضنا . قمنا بتحميل MobileNet من ملف في عملية Node.js ودربنا طبقة كثيفة إضافية حيث تم تغذية البيانات من طبقة MobileNet المخفية. بعد التدريب حققنا دقة تزيد عن 90٪!لاستخدام هذا النموذج في متصفح ، قمنا بتنزيله مع MobileNet وبدأنا في تصنيف الإطارات من كاميرا الويب الخاصة بالمستخدم كل 100 مللي ثانية. قمنا بتوصيل النموذج باللعبةMK.js واستخدمت إخراج النموذج للتحكم في أحد الأحرف.أخيرًا ، نظرنا في كيفية تحسين النموذج من خلال دمجه مع شبكة عصبية متكررة للتعرف على الإجراءات.آمل أن تكون قد استمتعت بهذا المشروع الصغير على الأقل كما فعلت!