واحدة من أهم المهام في مجال علم البيانات ليست فقط بناء نموذج قادر على عمل تنبؤات عالية الجودة ، ولكن أيضًا القدرة على تفسير مثل هذه التنبؤات.
إذا لم نكن نعلم فقط أن العميل يميل إلى شراء منتج ، ولكن أيضًا نفهم ما الذي يؤثر على شرائه ، فسنكون قادرين على بناء استراتيجية للشركة في المستقبل تهدف إلى تحسين كفاءة المبيعات.
أو توقع النموذج أن يصاب المريض بالمرض قريبًا. دقة مثل هذه التنبؤات ليست عالية جدا ، لأنه هناك العديد من العوامل المخفية عن النموذج ، لكن شرح أسباب قيام النموذج بهذا التنبؤ يمكن أن يساعد الطبيب في الانتباه إلى الأعراض الجديدة. وبالتالي ، من الممكن توسيع حدود تطبيق النموذج إذا لم تكن دقته في حد ذاتها عالية جدًا.
في هذا
المنشور ، أود أن أتحدث عن تقنية
SHAP ، التي تسمح لك بالنظر تحت غطاء مجموعة متنوعة من النماذج.
إذا كانت النماذج الخطية أقل وضوحا ، كلما زادت القيمة المطلقة للمعامل تحت المتنبئ ، كلما كان هذا التنبّؤ أكثر أهمية ، فإن شرح أهمية ميزات تعزيز التدرج نفسه أكثر صعوبة.
لماذا كانت هناك حاجة لمثل هذه المكتبة

في مكدس sklearn ، في حزم xgboost ، lightGBM ، كانت هناك طرق مدمجة لتقييم أهمية الميزات (أهمية الميزة) لـ "النماذج الخشبية":
- ربح
يوضح هذا المقياس المساهمة النسبية لكل ميزة في النموذج. للحساب ، نذهب من خلال كل شجرة ، وننظر في كل عقدة شجرة والتي تؤدي إلى تقسيم العقدة ومقدار عدم اليقين للنموذج وفقًا للمقياس (شوائب جيني ، اكتساب المعلومات).
لكل ميزة ، يتم تلخيص مساهمتها على جميع الأشجار.
- تغطية
يعرض عدد المشاهدات لكل ميزة. على سبيل المثال ، لديك 4 ميزات ، 3 أشجار. افترض أن الميزة 1 في عُقد الشجرة تحتوي على 10 و 5 و 2 ملاحظة في الأشجار 1 و 2 و 3 على التوالي ، ثم بالنسبة لهذه الميزة ، ستكون الأهمية 17 (10 + 5 + 2).
- التردد
يوضح عدد المرات التي تحدث فيها هذه الميزة في عقد الشجرة ، أي أن العدد الإجمالي لتقسيم الشجرة إلى عقد لكل عنصر في كل شجرة يعتبر.
المشكلة الرئيسية في كل هذه الأساليب هي أنه ليس من الواضح كيف تؤثر هذه الميزة بالضبط على التنبؤ بالنموذج. على سبيل المثال ، علمنا أن مستوى الدخل مهم لتقييم ملاءة عميل البنك لسداد القرض. لكن كيف بالضبط؟ ما مقدار توقعات نموذج التحيز في الإيرادات الأعلى؟
بالطبع ، يمكننا عمل العديد من التنبؤات عن طريق تغيير مستوى الدخل. ولكن ماذا تفعل مع الميزات الأخرى؟ بعد كل شيء ، نجد أنفسنا في موقف نحتاجه لفهم تأثير الدخل
بشكل مستقل عن الميزات الأخرى ، مع متوسط قيمتها.
هناك نوع من عملاء البنك العاديين "في فراغ". كيف ستتغير التنبؤات النموذجية مع التغيرات في الدخل؟
هنا تأتي مكتبة
SHAP للإنقاذ.
نحسب أهمية الميزات باستخدام SHAP
في مكتبة
SHAP ، لتقييم أهمية
الميزات ، يتم حساب قيم Shapley (باسم عالم رياضيات أمريكي وتسمى المكتبة).
لتقييم أهمية الميزة ، يتم تقييم تنبؤات النموذج
باستخدام هذه الميزة أو
بدونها .
قليلا من عصور ما قبل التاريخ

معاني شابلي تأتي من نظرية اللعبة.
تأمل السيناريو: مجموعة من الناس يلعبون الورق. كيف توزع جائزة الجائزة بينهما حسب مساهمتها؟
يتم إجراء عدد من الافتراضات:
- مبلغ المكافأة لكل لاعب يساوي مجموع الجوائز
- إذا قدم لاعبان مساهمة متساوية في اللعبة ، فسيحصلان على مكافأة متساوية.
- إذا لم يقدم اللاعب أي مساهمة ، فلن يحصل على مكافأة.
- إذا قضى اللاعب مباراتين ، فإن مكافأته الإجمالية تتكون من مقدار المكافآت لكل لعبة
نقدم ميزات النموذج كلاعبين ، ومجموعة الجوائز كتوقع نهائي للنموذج.
دعونا نلقي نظرة على مثال.
صيغة حساب قيمة Shapley لميزة i-th:
$$ display $$ \ تبدأ {المعادلة *} \ phi_ {i} (p) = \ sum_ {S \ subseteq N / \ {i \}} \ frac {| S |! (n - | S | -1) !} {n!} (p (S \ cup \ {i \}) - p (S)) \ النهاية {المعادلة *} $$ display $$
هنا:
p (S \ cup \ {i \}) هو توقع نموذج بميزة i-th ،
- هذا توقع للنموذج بدون ميزة i-th ،
- عدد الميزات ،
- مجموعة من الميزات العشوائية بدون ميزة i-th
يتم حساب قيمة Shapley لميزة i-th لكل عينة بيانات (على سبيل المثال ، لكل عميل في العينة) على جميع المجموعات الممكنة من الميزات (بما في ذلك غياب جميع الميزات) ، ثم يتم جمع القيم التي تم الحصول عليها ويتم الحصول على الأهمية النهائية لميزة i-th.
هذه الحسابات مكلفة للغاية ، لذلك ، تحت غطاء المحرك ، يتم استخدام خوارزميات مختلفة لتحسين الحسابات ، لمزيد من التفاصيل ، راجع الرابط أعلاه على github.
خذ مثال الفانيليا من
وثائق xgboost .
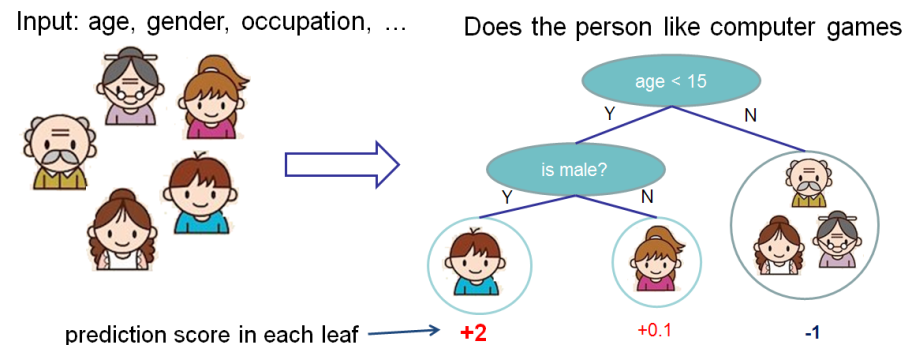
نريد تقييم أهمية الميزات للتنبؤ بما إذا كان الشخص يحب ألعاب الكمبيوتر.
في هذا المثال ، من أجل البساطة ، لدينا ميزتان: العمر (العمر) والجنس (الجنس). يأخذ الجنس (الجنس) القيمتين 0 و 1.
خذ بوبي (الولد الصغير في أقصى عقدة الشجرة اليسرى) واحسب قيمة شابلي للعمر المميز (العمر).
لدينا مجموعتان من ميزات S:
\ {\} - لا يوجد ميزات
\ {النوع \} - لا يوجد سوى جنس سمة.
الحالة عندما لا توجد قيم الميزة
تعمل النماذج المختلفة بشكل مختلف مع المواقف التي لا توجد فيها ميزات لعينة البيانات ، أي أن جميع القيم هي قيم فارغة لجميع الميزات.
في هذه الحالة ، سيعتبر أن النموذج يحسب متوسط التوقعات على أغصان الشجرة ، أي أن التنبؤ بدون ميزات سيكون
.
إذا أضفنا معرفة العمر ، فسيكون التنبؤ بالنموذج
.
ونتيجة لذلك ، فإن قيمة شابلي في حالة عدم وجود ميزات:
\ frac {| S |! (n - | S | -1)!} {n!} (p (S \ cup \ {i \}) - p (S)) = \ frac {1 (2-0 -1)!} {2!} (1.025) = 0.5125
الوضع عندما نعرف الجنس
لبوبي
التنبؤ بدون ميزات العمر ، فقط مع ميزات الجنس متساوية
. إذا كنا نعرف العمر ، فإن التوقع هو الشجرة أقصى اليسار ، أي 2.
ونتيجة لذلك ، فإن قيمة شابلي لهذه الحالة:
$$ display $$ \ تبدأ {المعادلة *} \ frac {| S |! (n - | S | -1)!} {n!} (p (S \ cup \ {i \}) - p (S) ) = \ frac {1 (2-1-1)!} {2!} (1.975) = 0.9875 \ end {المعادلة *} $$ display $$
تلخيص
القيمة الإجمالية لشابلي لميزات العمر (العمر):
$$ display $$ \ تبدأ {المعادلة *} \ phi_ {Age Bobby} = 0.9875 + 0.5125 = 1.5 \ end {المعادلة *} $$ display $$
مثال حقيقي للأعمال
تحتوي مكتبة SHAP على وظيفة تصوير غنية تساعد على شرح النموذج للأعمال والمحلل بسهولة وببساطة ، من أجل تقييم كفاية النموذج.
في أحد المشاريع ، قمت بتحليل تدفق الموظفين من الشركة. كنموذج ، تم استخدام xgboost.
الرمز في بيثون:
import shap shap_test = shap.TreeExplainer(best_model).shap_values(df) shap.summary_plot(shap_test, df, max_display=25, auto_size_plot=True)
الرسم البياني الناتج عن أهمية الميزات:
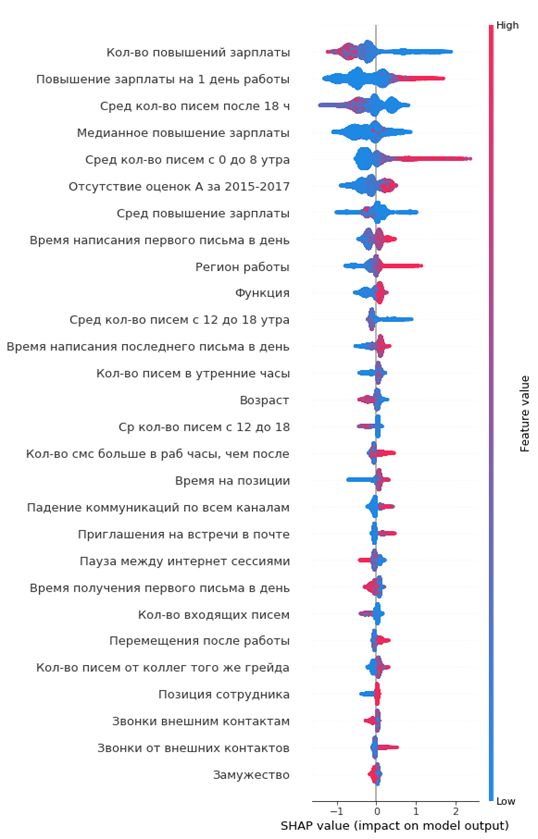
كيف تقرأه:
- القيم على يسار الخط العمودي الأوسط هي الفئة السالبة (0) ، إلى اليمين - موجبة (1)
- كلما كان الخط على الرسم البياني أكثر سمكًا ، كلما زادت نقاط المراقبة
- كلما زاد عدد النقاط على الرسم البياني ، زادت قيمة الميزات الموجودة فيه
من الرسم البياني ، يمكنك استخلاص استنتاجات مثيرة للاهتمام والتحقق من كفاءتها:
- كلما قلت الزيادة في راتب الموظف ، زادت احتمالية رحيله
- هناك مناطق من المكاتب حيث يكون التدفق أعلى
- كلما كان الموظف أصغر ، كلما زاد احتمال رحيله
- ...
يمكنك على الفور تكوين صورة للموظفة المنتهية ولايتها: لم ترفع راتبه ، لقد كانت صغيرة بما يكفي ، عزباء ، لفترة طويلة في منصب واحد ، لم تكن هناك زيادات في الرتبة ، لم تكن هناك تقييمات سنوية عالية ، بدأ في التواصل قليلاً مع الزملاء.
بسيطة ومريحة!
يمكنك شرح التنبؤ لموظف معين:

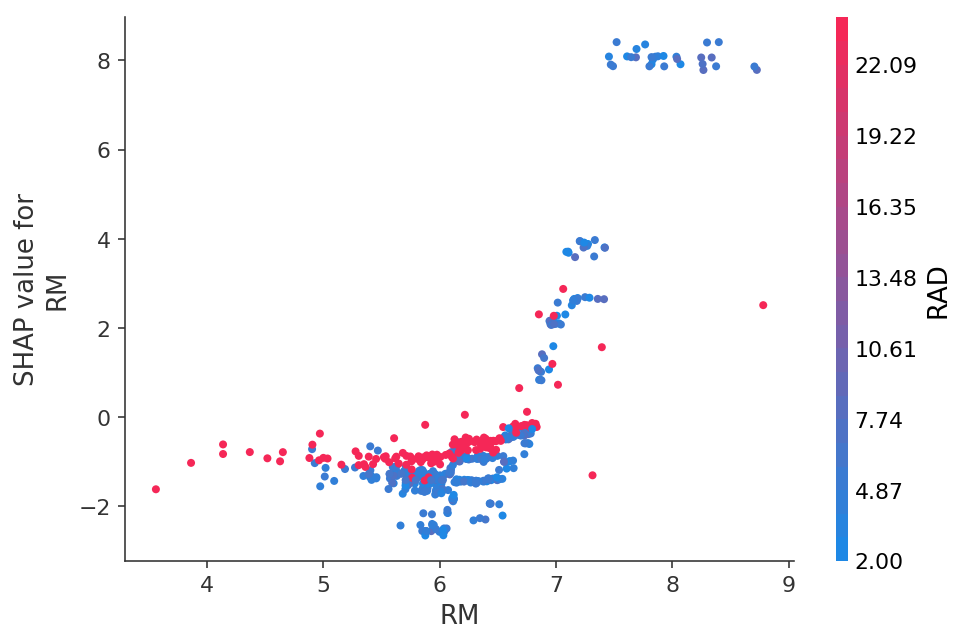
أو انظر اعتماد الاعتماد على ميزة معينة في شكل رسم بياني ثنائي الأبعاد:
يمكنك حتى تصور توقعات الشبكات العصبية في الصور:

الخلاصة
لقد عرفت بنفسي عن قيم SHAP منذ حوالي ستة أشهر ، واستبدل هذا تمامًا طرقًا أخرى لتقييم أهمية الميزات.
المزايا الرئيسية:
- تصور وتفسير ملائم
- حساب صادق لأهمية الميزات
- القدرة على تقييم الميزات لعينة فرعية معينة من البيانات (على سبيل المثال ، كيف يختلف عملاؤنا عن العملاء الآخرين في العينة) عن طريق مرشح بسيط لمجموعة البيانات في الباندا وتحليلها في شكل ، حرفيا سطرين من التعليمات البرمجية