توليف وتحرير الصور المتحكم فيه باستخدام TL-GAN الجديد مثال على التوليف المتحكم فيه في نموذج TL-GAN الخاص بي (GAN الشفاف في الفضاء الكامن ، شبكة المحتوى التوليدي مع الفضاء الخفي الشفاف)
مثال على التوليف المتحكم فيه في نموذج TL-GAN الخاص بي (GAN الشفاف في الفضاء الكامن ، شبكة المحتوى التوليدي مع الفضاء الخفي الشفاف)تتوفر جميع التعليمات البرمجية والعروض التوضيحية عبر الإنترنت على
صفحة المشروع .
ندرب الكمبيوتر على التقاط الصور كما هو موضح
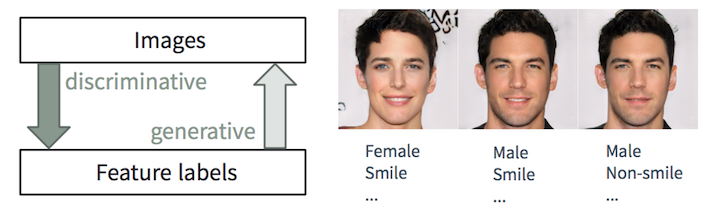 المهام التمييزية والتوليدية
المهام التمييزية والتوليديةمن السهل على الشخص أن
يصف صورة ، نتعلم القيام بها منذ صغره. في التعلم الآلي ، هذه هي مهمة التصنيف / الانحدار
التمييزي ، أي التنبؤ بالميزات من الصور المدخلة. تبدأ التطورات الحديثة في أساليب ML / AI ، خاصة في نماذج التعلم العميق ، في التفوق في هذه المهام ، حيث تصل أحيانًا إلى القدرات البشرية أو تتجاوزها ، كما هو موضح في مهام مثل التعرف البصري على الأشياء (على سبيل المثال ، من AlexNet إلى ResNet وفقًا لتصنيف ImageNet) والكشف / التقسيم الأشياء (على سبيل المثال ، من RCNN إلى YOLO في مجموعة بيانات COCO) ، إلخ.
ومع ذلك ، فإن المهمة العكسية
لإنشاء صور واقعية من الوصف أكثر تعقيدًا وتتطلب سنوات عديدة من التدريب في التصميم الجرافيكي. في التعلم الآلي ، هذه مهمة
توليدية ، وهي أكثر تعقيدًا بكثير من المهام التمييزية ، حيث يجب أن يولد النموذج التوليدي المزيد من المعلومات (على سبيل المثال ، صورة كاملة عند مستوى معين من التفاصيل والتباين) بناءً على بيانات أولية أصغر.
على الرغم من تعقيد إنشاء مثل هذه التطبيقات ، فإن
النماذج التوليدية (مع بعض التحكم) مفيدة للغاية في العديد من الحالات:
- إنشاء المحتوى : تخيل أن شركة إعلانية تقوم تلقائيًا بإنشاء صور جذابة تتوافق مع محتوى وأسلوب صفحة الويب التي يتم إدراج هذه الصور فيها. يسعى المصمم إلى الإلهام من خلال طلب الخوارزمية لإنشاء 20 نمطًا من الأحذية مرتبطة بعلامات "الراحة" و "الصيف" و "العاطفي". تتيح لك اللعبة الجديدة إنشاء صور رمزية واقعية من وصف بسيط.
- تحرير ذكي يعتمد على المحتوى : يغير المصور تعبيرات الوجه ، وعدد التجاعيد وتصفيف الشعر في الصورة ببضع نقرات. يقوم فنان في استوديو هوليوود بتحويل اللقطات التي تم التقاطها في أمسية غائمة ، كما لو تم التقاطها في صباح مشرق ، مع وجود ضوء الشمس على الجانب الأيسر من الشاشة.
- زيادة البيانات : يمكن لمطور الطائرات بدون طيار تجميع مقاطع فيديو واقعية لسيناريو حادث معين من أجل زيادة مجموعة بيانات التدريب. يمكن للبنك تجميع أنواع معينة من بيانات الاحتيال المقدمة بشكل سيئ في مجموعة البيانات الحالية من أجل تحسين نظام مكافحة الاحتيال.
في هذه المقالة ، سنتحدث عن عملنا الأخير المسمى
GAN Transparent Latent-space GAN (TL-GAN) ، والذي يوسع وظائف أحدث الموديلات ، مما يوفر واجهة جديدة. نحن نعمل حاليًا على مستند يحتوي على مزيد من التفاصيل الفنية.
نظرة عامة على النماذج التوليدية
يعمل مجتمع التعلم العميق على تحسين النماذج التوليدية بسرعة. يمكن تمييز ثلاثة أنواع واعدة بينها:
نماذج الانحدار الذاتي ،
وأجهزة الترميز التلقائي المتغيرة (VAE) وشبكات الخصومة التوليدية (GAN) ، كما هو موضح في الشكل أدناه. إذا كنت مهتمًا بالتفاصيل ، فالرجاء قراءة
مقالة مدونة OpenAI الممتازة.
 مقارنة الشبكات التوليدية. صورة من دورة STAT946F17 في جامعة واترلو
مقارنة الشبكات التوليدية. صورة من دورة STAT946F17 في جامعة واترلوفي الوقت الحالي ، يتم إنشاء الصور
عالية الجودة من خلال شبكات GAN (الواقعية والمتنوعة ، مع تفاصيل مقنعة بدقة عالية). ألق نظرة على شبكة pg-GAN المذهلة (
GAN المتنامية تدريجيًا ) من Nvidia. لذلك ، سنركز في هذه المقالة على نماذج GAN.
 الاصطناعية pg-GAN التي تم إنشاؤها بواسطة نفيديا. لا شيء من الصور مرتبطة بالواقع.
الاصطناعية pg-GAN التي تم إنشاؤها بواسطة نفيديا. لا شيء من الصور مرتبطة بالواقع.إدارة مشكلات نموذج GAN
 توليد الصور العشوائية والتحكم فيهاتعد النسخة الأصلية من GAN
توليد الصور العشوائية والتحكم فيهاتعد النسخة الأصلية من GAN والعديد من النماذج الشائعة المستندة إليها (مثل
DC-GAN و
pg-GAN ) نماذج تعليمية
بدون معلم . بعد التدريب ، تأخذ الشبكة العصبية التوليدية ضوضاء عشوائية كمدخلات وتخلق صورة واقعية لا يمكن تمييزها بالكاد عن مجموعة بيانات التدريب. ومع ذلك ، لا يمكننا أيضًا التحكم في ميزات الصور التي تم إنشاؤها. في معظم التطبيقات (على سبيل المثال ، في السيناريوهات الموضحة في القسم الأول) ، يرغب المستخدمون في إنشاء أنماط ذات
سمات عشوائية (على سبيل المثال ، العمر ولون الشعر وتعبير الوجه ، وما إلى ذلك) من الناحية المثالية ، قم بتهيئة كل وظيفة بسلاسة.
تم إنشاء العديد من متغيرات GAN لمثل هذا التوليف الخاضع للرقابة. يمكن تقسيمها بشكل مشروط إلى نوعين: شبكات نقل النمط والمولدات الشرطية.
شبكات نقل النمط
يتم تدريب
شبكات نقل نمط
CycleGAN و
pix2pix على نقل صورة من منطقة (مجال) إلى أخرى: على سبيل المثال ، من حصان إلى حمار وحشي ، من رسم إلى صور ملونة. ونتيجة لذلك ، لا يمكننا تغيير علامة محددة بسلاسة بين حالتين منفصلتين (على سبيل المثال ، إضافة لحية صغيرة على الوجه). بالإضافة إلى ذلك ، تم تصميم شبكة واحدة لنوع واحد من الإرسال ، لذلك ستكون هناك حاجة إلى عشر شبكات عصبية مختلفة لتكوين عشر وظائف.
مولدات حالة
المولدات
الشرطية -
GAN الشرطي و
AC-GAN و Stack-GAN - في عملية التدريب ، تدرس في وقت واحد الصور وتسميات الأشياء ، مما يسمح لك بإنشاء صور مع تحديد السمات. عندما تريد إضافة ميزات جديدة إلى عملية التوليد ، فأنت بحاجة إلى إعادة تدريب نموذج GAN بالكامل ، والذي يتطلب موارد ووقتًا حسابيًا ضخمًا (على سبيل المثال ، من عدة أيام إلى أسابيع على وحدة معالجة الرسومات K80 نفسها مع مجموعة مثالية من المعلمات الفائقة). بالإضافة إلى ذلك ، لإكمال التدريب ، من الضروري الاعتماد على مجموعة بيانات واحدة تحتوي على جميع تسميات الكائنات المعرفة من قبل المستخدم ، وعدم استخدام تسميات مختلفة من عدة مجموعات بيانات.
تستخدم شبكتنا التنافسية التنافسية مع المساحة المخفية
الشفافة (
GAN الشفاف في المساحة الكامنة ، TL-GAN) نهجًا مختلفًا للجيل الخاضع للرقابة - وتحل هذه المشاكل. يوفر القدرة على
تكوين ميزة واحدة أو أكثر باستخدام شبكة واحدة بسلاسة . بالإضافة إلى ذلك ، يمكنك إضافة ميزات مخصصة جديدة بشكل فعال في أقل من ساعة واحدة.
TL-GAN: نهج جديد وفعال للتوليف والتحرير المحكم
جعل هذا الفضاء الخفي الغامض الشفاف
خذ نموذج pvGAN من Nvidia ، الذي يولد صورًا واقعية عالية الدقة للوجوه ، كما هو موضح في القسم السابق. يتم تحديد جميع ميزات الصورة التي تم إنشاؤها بدقة 1024 × 1024 بكسل بشكل حصري من خلال ناقل الضوضاء ذي الأبعاد 512 في المساحة المخفية (كتمثيل منخفض الأبعاد لمحتوى الصورة). لذلك ،
إذا فهمنا ما يشكل مساحة مخفية (أي جعلها شفافة) ، فيمكننا التحكم تمامًا في عملية التوليد .
 دافع TL-GAN: فهم المساحة المخفية لإدارة عملية التوليد
دافع TL-GAN: فهم المساحة المخفية لإدارة عملية التوليدأثناء تجربة شبكة pg-GAN المدربة مسبقًا ، اكتشفت أن المساحة المخفية لها بالفعل خاصيتان جيدتان:
- إنه مليء جيدًا ، بمعنى أن معظم النقاط في الفضاء تولد صورًا معقولة.
- إنه مستمر تمامًا ، أي أن الاستيفاء بين نقطتين في مساحة مخفية يؤدي عادةً إلى انتقال سلس للصور المقابلة.
يقول الحدس أنه في الفضاء الخفي هناك اتجاهات تتنبأ بالسمات التي نحتاجها (على سبيل المثال ، رجل / امرأة). إذا كان الأمر كذلك ، فستصبح ناقلات هذه الاتجاهات محاور للتحكم في عملية التوليد (وجه أكثر ذكورية أو أنثوية).
النهج: توسيع محور الميزة
للعثور على محور السمات هذا في مساحة مخفية ،
نقوم ببناء اتصال بين المتجه المخفي ض والعلامات ذ باستخدام تدريب المعلمين في أزواج
( ض ، ص ) . تكمن المشكلة الآن في كيفية الحصول على هذه الأزواج ، لأن مجموعات البيانات الموجودة تحتوي على صور فقط
س وتسميات الكائن المقابلة
ذ .
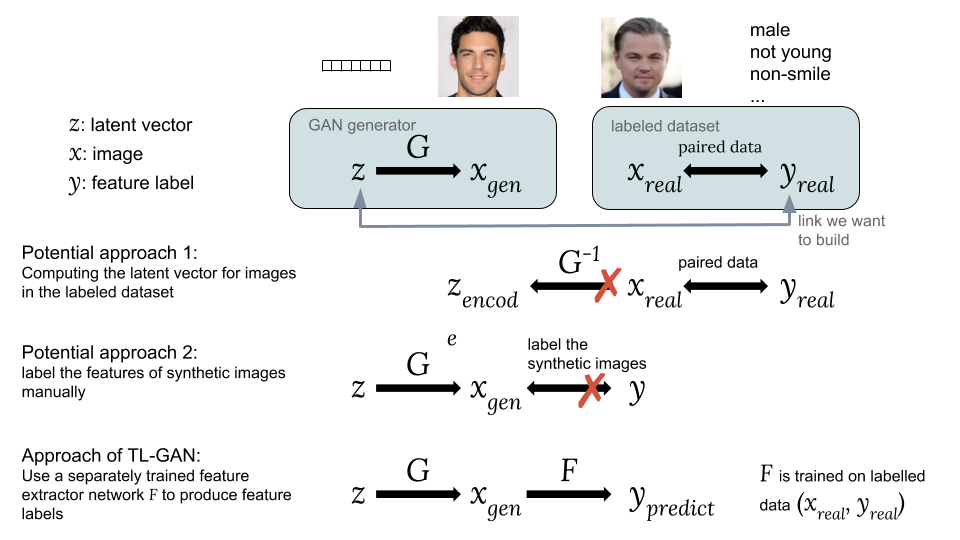 طرق ربط المتجه الخفي z مع بطاقة الوسم yالنهج الممكنة:أحد الخيارات هو حساب المتجهات المخفية المقابلة ض الصور x r e a l من مجموعة بيانات حالية ذات علامات تهمنا y r e a l . ومع ذلك ، لا توفر GAN طريقة سهلة للحساب z e n c o d e = G - 1 x r e a l مما يجعل من الصعب تنفيذ هذه الفكرة.
طرق ربط المتجه الخفي z مع بطاقة الوسم yالنهج الممكنة:أحد الخيارات هو حساب المتجهات المخفية المقابلة ض الصور x r e a l من مجموعة بيانات حالية ذات علامات تهمنا y r e a l . ومع ذلك ، لا توفر GAN طريقة سهلة للحساب z e n c o d e = G - 1 x r e a l مما يجعل من الصعب تنفيذ هذه الفكرة.
الخيار الثاني هو إنشاء صور اصطناعية س ز ه ن باستخدام GAN من متجه مخفي عشوائي ض كيف x g e n = G ( z ) . تكمن المشكلة في أن الصور الاصطناعية لا يتم وضع علامات عليها ، لذلك من الصعب استخدام مجموعة يمكن الوصول إليها من البيانات التي تم وضع علامة عليها.يتمثل الابتكار الرئيسي لنموذج TL-GAN الخاص بنا في
تدريب مستخرج منفصل (مصنف للملصقات المنفصلة أو الارتداد المستمر) مع النموذج
ص = و ( خ ) باستخدام مجموعة موجودة من البيانات ذات العلامات (
x r e a l ،
y r e a l ) ، ثم انطلق في مجموعة من مولدات GAN المدربة
ز مع شبكة استخراج الميزة
و . يتيح لك هذا توقع تصنيفات الميزات.
ص ص ص ه د صور اصطناعية
س ز ه ن باستخدام شبكة استخراج ميزة مدربة (مستخرج). وهكذا ، من خلال الصور الاصطناعية ، يتم إنشاء اتصال بين
ض و
ذ كيف
x g e n = G ( z ) و
y p r e d = F ( x g e n ) .
الآن لدينا ناقل وميزات مخفية مقترنة. يمكنك تدريب نموذج الانحدار
ذ = أ ( ض ) لفتح كل محور الميزات للتحكم في عملية توليد الصورة.
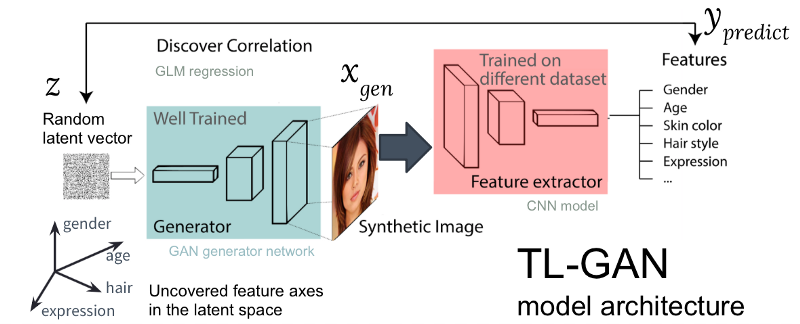 الشكل: بنية نموذج TL-GAN
الشكل: بنية نموذج TL-GANيوضح الشكل أعلاه بنية نموذج TL-GAN ، الذي يحتوي على خمس خطوات:
- دراسة التوزيع . نختار نموذج GAN مدرب جيدًا وشبكة إنتاجية. لقد حصلت على pg-GAN المدربة جيدًا (من نفيديا) ، والتي توفر أفضل جيل للوجه.
- التصنيف . نختار نموذجًا مدربًا مسبقًا لاستخراج الصفات (يمكن أن يكون المستخرج شبكة عصبية تلافيفية أو نماذج أخرى لرؤية الكمبيوتر) أو ندرب مستخرجنا الخاص باستخدام مجموعة من البيانات المميزة. لقد قمت بتدريب شبكة عصبية تلافيفية بسيطة باستخدام مجموعة CelebA (أكثر من 30.000 وجه مع 40 علامة).
- جيل . نقوم بإنشاء العديد من المتجهات المخفية العشوائية ، ونمر عبر مولد GAN المدرب لإنشاء صور اصطناعية ، ثم نستخدم مستخرج الميزات المدربة لإنشاء ميزات على كل صورة.
- الارتباط . نستخدم النموذج الخطي المعمم (GLM) لتنفيذ الانحدار بين المتجهات والميزات المخفية. يصبح منحدر خط الانحدار محور الصفات .
- البحث . نبدأ بمتجه واحد مخفي ، وننقله على طول محور واحد أو أكثر من العلامات ، وندرس كيف يؤثر ذلك على توليد الصور.
لقد قمت بتحسين العملية إلى حد كبير: في نموذج GAN المدرب مسبقًا ،
لا يستغرق تحديد محاور الميزات
سوى ساعة واحدة على الجهاز باستخدام وحدة معالجة رسومات واحدة. يتم تحقيق ذلك من خلال العديد من الحيل الهندسية ، بما في ذلك نقل التدريب ، وتقليل حجم الصور ، والتخزين المؤقت الأولي للصور الاصطناعية ، وما إلى ذلك.
النتائج
دعونا نرى كيف تعمل هذه الفكرة البسيطة.
تحريك متجه مخفي على طول محاور الكائنات
أولاً ، تحققت مما إذا كان يمكن استخدام محاور المعالم المكتشفة للتحكم في الميزة المقابلة للصورة التي تم إنشاؤها. للقيام بذلك ، قم بإنشاء ناقل عشوائي
ض 0 في المساحة الخفية لـ GAN وإنشاء صورة اصطناعية
× 0 تمريرها عبر شبكة مولدة
x 0 = G ( z 0 ) . ثم نقوم بنقل المتجه الخفي على طول محور واحد من الميزات
ش (ناقل وحدة في الفضاء الخفي ، على سبيل المثال ، يتوافق مع جنس الوجه) على مسافة
λ إلى موقع جديد
س 1 = س 0 + λ ش وإنشاء صورة جديدة
x 1 = G ( z 1 ) . من الناحية المثالية ، يجب أن تتغير الميزة المقابلة للصورة الجديدة في الاتجاه المتوقع.
يتم عرض نتائج تحريك ناقل على طول محور السمات (الجنس والعمر وما إلى ذلك) أدناه. يعمل بشكل جيد بشكل مدهش! يمكنك
تحويل الصورة
بسلاسة بين رجل / امرأة ، شاب / رجل عجوز ، إلخ.
 النتائج الأولى لتحريك ناقل مخفي على طول محاور المعالم المتشابكة
النتائج الأولى لتحريك ناقل مخفي على طول محاور المعالم المتشابكةكشف محاور المعالم المترابطة
في الأمثلة أعلاه ، فإن عيوب الطريقة الأصلية مرئية ، وهي المحور المربك للسمات. على سبيل المثال ، عندما تحتاج إلى تقليل شعر الوجه ، تصبح الوجوه الناتجة أكثر أنوثة ، وهي ليست النتيجة المتوقعة. المشكلة هي أن الجنس واللحية مرتبطان بطبيعتهما. يؤدي التغيير في إحدى السمات إلى تغيير في سمة أخرى. حدثت أشياء مشابهة مع ميزات أخرى ، مثل الشعر والشعر المجعد. كما هو موضح في الشكل أدناه ، فإن المحور الأصلي للسمة "اللحية" في الفضاء الخفي ليس متعامدًا مع المحور "الأرضي".
لحل المشكلة ، استخدمت تقنيات الجبر الخطي البسيط. على وجه الخصوص ، قام بإسقاط محور اللحية في اتجاه جديد ، متعامد على محور الأرضية ، مما يلغي بشكل فعال ارتباطها ، وبالتالي ، يمكن أن يكشف هاتين العلامتين على الوجوه المتولدة.
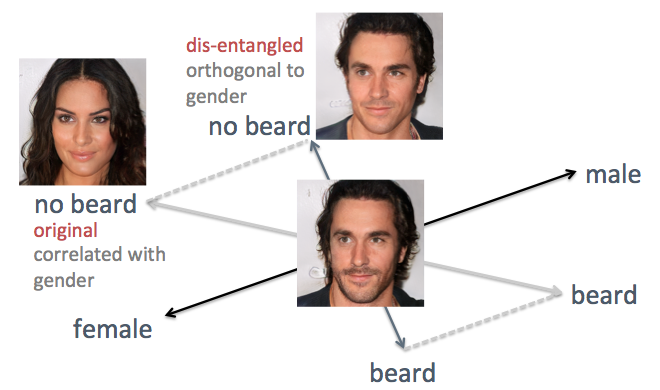 كشف محاور المعالم المترابطة بتقنيات الجبر الخطي
كشف محاور المعالم المترابطة بتقنيات الجبر الخطيلقد طبقت هذه الطريقة على نفس الشخص. هذه المرة ، يتم اختيار محاور الجنس والعمر كمحور مساعد ، بحيث يتم عرض جميع المحاور الأخرى بحيث تصبح متعامدة مع الجنس والعمر. يتم إنشاء الوجوه عن طريق تحريك المتجه المخفي على طول محاور المعالم التي تم إنشاؤها حديثًا (كما هو موضح في الشكل أدناه). كما هو متوقع ، الآن لا تؤثر الإشارات مثل تسريحات الشعر واللحى على الأرض.
 نتيجة محسنة لتحريك ناقل مخفي على طول محاور المعالم غير المتشابكة
نتيجة محسنة لتحريك ناقل مخفي على طول محاور المعالم غير المتشابكةتحرير تفاعلي مرن
لمعرفة مدى مرونة نموذج TL-GAN الخاص بنا في التحكم في عملية إنشاء الصور ، قمت بإنشاء واجهة رسومية تفاعلية مع تغيير سلس في قيم الكائنات على محاور مختلفة ، كما هو موضح أدناه.
التحرير التفاعلي مع TL-GANومرة أخرى ، يعمل النموذج بشكل جيد بشكل مدهش إذا قمت بتغيير الصورة على طول محور العلامات!
الملخص
يوضح هذا المشروع طريقة جديدة لإدارة النموذج التوليدي بدون معلم ، مثل GAN (شبكة الخصومة التوليدية). باستخدام مولد GAN تم تدريبه مسبقًا (pg-GAN من Nvidia) ، جعلت مساحته المخفية شفافة من خلال إظهار محاور الميزات المهمة. عندما يتحرك ناقل على طول مثل هذا المحور في مساحة مخفية ، يتم تحويل الصورة المقابلة على طول هذه الميزة ، مما يوفر توليفًا وتحريرًا محكمًا.
هذه الطريقة لها مزايا واضحة:
- الكفاءة: من أجل إضافة موالف علامات جديد للمولد ، لا تحتاج إلى إعادة تدريب نموذج GAN ، لذا فإن إضافة موالفات لـ 40 علامة تستغرق أقل من ساعة.
- المرونة: يمكنك استخدام أي مستخرج للميزات تم تدريبه على أي مجموعة بيانات ، وإضافة المزيد من الميزات إلى شبكة GAN المدربة جيدًا.
بضع كلمات حول الأخلاق
يتيح لك هذا العمل التحكم في إنشاء الصور بالتفصيل ، ولكنه لا يزال يعتمد إلى حد كبير على خصائص مجموعة البيانات. يعني التدريب على صور نجوم هوليوود أن النموذج سيولد صورًا لأغلبهم من البيض والجذابين. سيؤدي هذا إلى حقيقة أن المستخدمين سيتمكنون من إنشاء وجوه لا تمثل سوى جزء صغير من البشرية. إذا قمت بنشر هذه الخدمة كتطبيق حقيقي ، فمن المستحسن توسيع مجموعة البيانات الأصلية لمراعاة تنوع مستخدمينا.
على الرغم من أن الأداة يمكن أن تساعد بشكل كبير في العملية الإبداعية ، إلا أنك تحتاج إلى تذكر إمكانيات استخدامها لأغراض غير مناسبة. إذا أنشأنا وجوهًا واقعية من أي نوع ، إلى أي مدى يمكننا الوثوق بالشخص الذي نراه على الشاشة؟ من المهم اليوم مناقشة قضايا من هذا النوع. كما رأينا في الأمثلة الأخيرة
لتقنية Deepfake ، فإن الذكاء الاصطناعي يتقدم بسرعة ، لذا من الضروري للبشرية أن تبدأ مناقشة حول أفضل طريقة لنشر مثل هذه التطبيقات.
العرض التوضيحي والرمز على الإنترنت
تتوفر جميع التعليمات البرمجية والعروض التوضيحية عبر الإنترنت لهذا العمل على
صفحة GitHub .
إذا كنت ترغب في اللعب بالنموذج في المتصفح
لست بحاجة إلى تنزيل رمز أو نموذج أو بيانات. ما عليك سوى اتباع التعليمات الواردة في
قسم المستند التمهيدي. يمكنك تغيير الوجوه في المتصفح كما هو موضح في الفيديو.
إذا كنت ترغب في تجربة الرمز
ما عليك سوى الانتقال إلى صفحة المستند التمهيدي لمستودع GitHub. تم تجميع الرمز على Anaconda Python 3.6 مع Tensorflow و Keras.
إذا كنت تريد المساهمة
مرحبًا لا تتردد في إرسال طلب تجمع أو الإبلاغ عن مشكلة على GitHub.
عني
حصلت مؤخرًا على درجة الدكتوراه في علم الأعصاب الحسابي والمعرفي من جامعة براون ودرجة الماجستير في علوم الكمبيوتر ، مع التخصص في تعلم الآلة. في الماضي ، درست كيف تعالج الخلايا العصبية في الدماغ المعلومات بشكل جماعي لتحقيق وظائف عالية المستوى مثل الإدراك البصري. أنا أحب النهج الخوارزمي لتحليل ومحاكاة وتنفيذ الذكاء ، وكذلك لاستخدام الذكاء الاصطناعي لحل مشاكل العالم الواقعي المعقدة. أنا أبحث بنشاط عن وظيفة كباحث ML / AI في صناعة التكنولوجيا.
شكر وتقدير
تم إنجاز هذا العمل في غضون ثلاثة أسابيع كمشروع لبرنامج
المنح الدراسية في InSight AI . أشكر مدير البرنامج
Emmanuel Amaisen و
Matt Rubashkin على القيادة العامة ، وخاصة Emmanuel على اقتراحاته وتحرير المقال. كما أشكر جميع موظفي Insight على البيئة التعليمية الممتازة والمشاركين الآخرين في برنامج Insight AI الذين تعلمت منهم الكثير.
شكر خاص لروبين شيا للعديد من النصائح والإلهام عندما قررت في أي اتجاه لتطوير المشروع ، وللمساعدة الهائلة في هيكلة وتحرير هذه المقالة.