
في مؤتمر منظمة العفو الدولية ، سوف يتحدث
فلاديمير إيفانوف vivanov879 ، الأب عن استخدام التعلم المعزز
مهندس التعلم العميق في نفيديا . يشارك الخبير في التعلم الآلي في قسم الاختبار: "أحلل البيانات التي نجمعها أثناء اختبار ألعاب الفيديو والأجهزة. لهذا أستخدم التعلم الآلي ورؤية الكمبيوتر. الجزء الرئيسي من العمل هو تحليل الصور وتنظيف البيانات قبل التدريب وترميز البيانات وتصور الحلول التي تم الحصول عليها ".
في مقال اليوم ، يشرح فلاديمير سبب استخدام التعلم المعزز في السيارات المستقلة ويتحدث عن كيفية تدريب الوكيل على التصرف في بيئة متغيرة - باستخدام أمثلة ألعاب الفيديو.
في السنوات القليلة الماضية ، جمعت البشرية كمية هائلة من البيانات. تتم مشاركة بعض مجموعات البيانات ووضعها يدويًا. على سبيل المثال ، مجموعة بيانات CIFAR ، حيث يتم توقيع كل صورة ، إلى أي فئة تنتمي إليها.
هناك مجموعات بيانات تحتاج فيها إلى تعيين فئة ليس فقط للصورة ككل ، ولكن لكل بكسل في الصورة. كما ، على سبيل المثال ، في CityScapes.

ما يوحد هذه المهام هو أن الشبكة العصبية التعليمية تحتاج فقط إلى تذكر الأنماط في البيانات. لذلك ، مع وجود كميات كبيرة بما فيه الكفاية من البيانات ، وفي حالة CIFAR يبلغ 80 مليون صورة ، تتعلم الشبكة العصبية التعميم. ونتيجة لذلك ، تتواءم جيدًا مع تصنيف الصور التي لم ترها من قبل.
لكن العمل في إطار تقنية التدريس مع المعلم ، الذي يعمل على تمييز الصور ، من المستحيل حل المشكلات حيث لا نريد التنبؤ بالعلامة ، ولكن اتخاذ القرارات. كما هو الحال ، على سبيل المثال ، في حالة القيادة الذاتية ، حيث تكون المهمة هي الوصول بشكل آمن وموثوق إلى نقطة نهاية المسار.
في مشاكل التصنيف ، استخدمنا تقنية التدريس مع المعلم - عندما يتم تعيين فئة معينة لكل صورة. ولكن ماذا لو لم يكن لدينا مثل هذا الترميز ، ولكن هناك وكيل وبيئة يمكنه من خلالها تنفيذ إجراءات معينة؟ على سبيل المثال ، دعها تكون لعبة فيديو ، ويمكننا النقر على أسهم التحكم.

يجب حل هذا النوع من المشاكل عن طريق التدريب التعزيزي. في البيان العام للمشكلة ، نريد معرفة كيفية تنفيذ التسلسل الصحيح للإجراءات. من المهم بشكل أساسي أن يكون للوكيل القدرة على تنفيذ الإجراءات مرارًا وتكرارًا ، وبالتالي استكشاف البيئة التي يكون فيها. وبدلاً من الإجابة الصحيحة ، ماذا يفعل في حالة معينة ، يتلقى مكافأة لمهمة مكتملة بشكل صحيح. على سبيل المثال ، في حالة سيارة أجرة مستقلة ، سيحصل السائق على مكافأة لكل رحلة يتم إجراؤها.
دعنا نعود إلى مثال بسيط - لعبة فيديو. خذ شيئًا بسيطًا ، مثل لعبة تنس الطاولة أتاري.
سنتحكم في الجهاز اللوحي على اليسار. سنلعب ضد مشغل الكمبيوتر المبرمج على القواعد على اليمين. نظرًا لأننا نعمل مع صورة ، والشبكات العصبية هي الأكثر نجاحًا في استخراج المعلومات من الصور ، فلنطبق صورة على إدخال شبكة عصبية ثلاثية الطبقات بحجم 3x3 kernel. عند الخروج ، سيتعين عليها اختيار أحد الإجراءين: تحريك اللوحة لأعلى أو لأسفل.
ندرب الشبكة العصبية لأداء الأعمال التي تؤدي إلى النصر. تقنية التدريب على النحو التالي. تركنا الشبكة العصبية تلعب بضع جولات من تنس الطاولة. ثم نبدأ في فرز الألعاب التي لعبت. في تلك المباريات التي فازت فيها ، قمنا بتمييز الصور التي تحمل اسم "أعلى" حيث رفعت المضرب ، و "أسفل" حيث قامت بخفضها. في الألعاب الضائعة ، نقوم بالعكس. نضع علامة على تلك الصور حيث قامت بخفض اللوحة بعلامة "لأعلى" وحيث رفعتها "لأسفل". وبالتالي ، فإننا نقصر المشكلة على النهج الذي نعرفه بالفعل - التدريب مع المعلم. لدينا مجموعة من الصور مع العلامات.
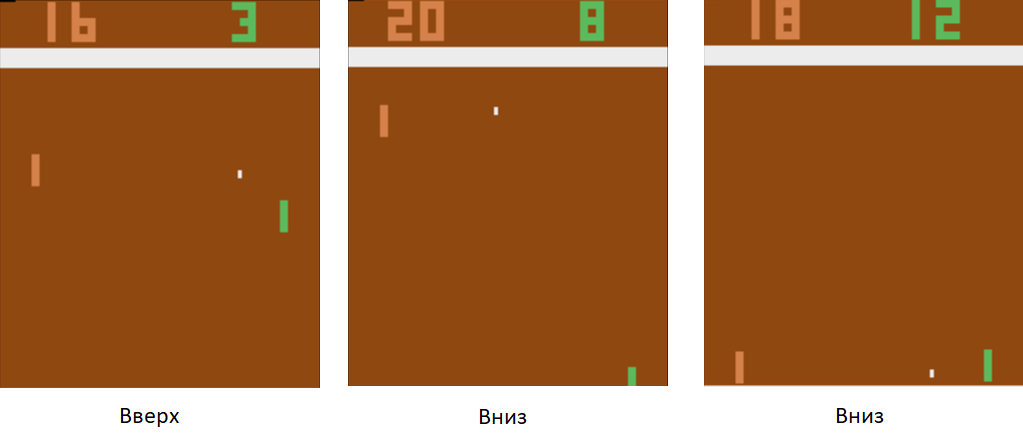
باستخدام تقنية التدريب هذه ، في غضون ساعتين ، سيتعلم وكيلنا التغلب على مشغل كمبيوتر مبرمج وفقًا للقواعد.
ماذا تفعل مع القيادة الذاتية؟ الحقيقة هي أن تنس الطاولة لعبة بسيطة للغاية. ويمكن أن تنتج آلاف الإطارات في الثانية. في شبكتنا الآن هناك 3 طبقات فقط. لذلك ، عملية التعلم بسرعة البرق. تولد اللعبة كمية هائلة من البيانات ، ونعالجها على الفور. في حالة القيادة الذاتية ، يكون جمع البيانات أطول بكثير وأكثر تكلفة. السيارات باهظة الثمن ، ومع سيارة واحدة ، لن نتلقى سوى 60 إطارًا في الثانية. بالإضافة إلى ذلك ، يزيد سعر الخطأ. في لعبة فيديو ، يمكننا أن نلعب لعبة تلو الأخرى في بداية التدريب. لكن لا يمكننا تحمل إفساد السيارة.
في هذه الحالة ، دعنا نساعد الشبكة العصبية في بداية التدريب. نقوم بإصلاح الكاميرا على السيارة ، ونضع سائقًا متمرسًا فيها وسنسجل الصور من الكاميرا. لكل صورة ، نشترك في زاوية توجيه السيارة. سنقوم بتدريب الشبكة العصبية لنسخ سلوك السائق من ذوي الخبرة. وهكذا ، قمنا بتقليص المهمة مرة أخرى إلى التدريس المعروف بالفعل مع المعلم.
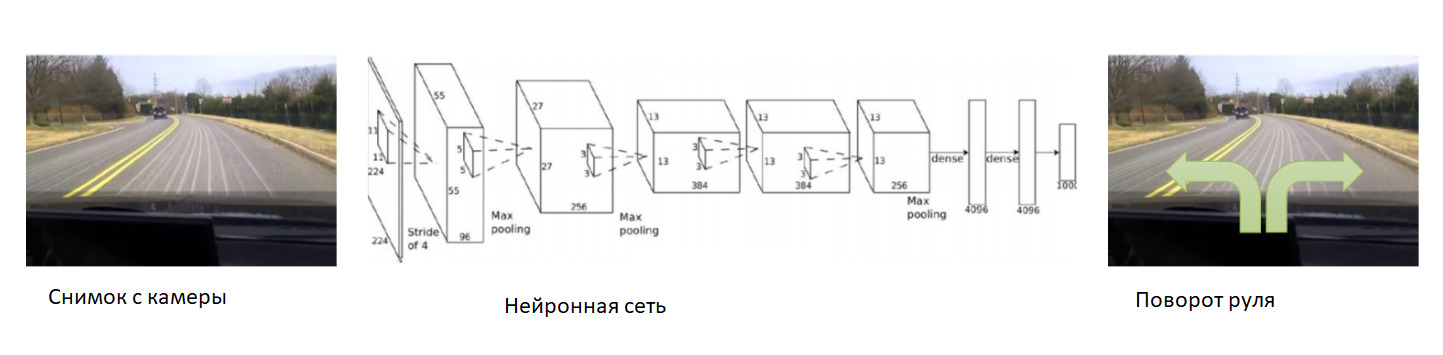
مع مجموعة بيانات كبيرة ومتنوعة بما فيه الكفاية ، والتي ستشمل مناظر طبيعية مختلفة ومواسم وظروف الطقس ، ستتعلم الشبكة العصبية كيفية التحكم بدقة في السيارة.
ومع ذلك ، كانت هناك مشكلة في البيانات. فهي طويلة ومكلفة للغاية لجمعها. دعونا نستخدم جهاز محاكاة يتم فيه تطبيق جميع فيزياء حركة السيارة - على سبيل المثال ، DeepDrive. يمكننا أن نتعلمها دون خوف من فقدان السيارة.

في هذه المحاكاة ، لدينا إمكانية الوصول إلى جميع مؤشرات السيارة والعالم. بالإضافة إلى ذلك ، يتم تمييز جميع الأشخاص والسيارات وسرعاتها ومسافاتها بها.

من وجهة نظر المهندس ، في مثل هذا المحاكي ، يمكنك تجربة تقنيات تدريب جديدة بأمان. ماذا يجب أن يفعل الباحث؟ على سبيل المثال ، دراسة الخيارات المختلفة لأصل التدرج في مشاكل التعلم مع التعزيز. لاختبار فرضية بسيطة ، لا أريد تصوير عصافير من مدفع وتشغيل وكيل في عالم افتراضي معقد ، ثم الانتظار لأيام في كل مرة للحصول على نتائج المحاكاة. في هذه الحالة ، دعنا نستخدم قوتنا الحاسوبية بشكل أكثر كفاءة. دع الوكلاء يكونون أبسط. خذ ، على سبيل المثال ، نموذج عنكبوت رباعي الأرجل. في محاكي Mujoco ، يبدو هذا:
وضعنا له مهمة الجري بأقصى سرعة ممكنة في اتجاه معين - على سبيل المثال ، إلى اليمين. عدد المعلمات التي تمت ملاحظتها للعنكبوت هو ناقل ذو أبعاد 39 ، يسجل موضع وسرعة جميع أطرافه. على عكس الشبكة العصبية لتنس الطاولة ، حيث لم يكن هناك سوى عصبون واحد عند الإخراج ، هناك ثمانية عند الإخراج (حيث يحتوي العنكبوت في هذا النموذج على 8 مفاصل).
في مثل هذه النماذج البسيطة ، يمكن اختبار الفرضيات المختلفة حول تقنية التدريس. على سبيل المثال ، دعنا نقارن سرعة التعلم للتشغيل ، اعتمادًا على نوع الشبكة العصبية. فليكن شبكة عصبية أحادية الطبقة ، وشبكة عصبية ثلاثية الطبقات ، وشبكة تلافيفية وشبكة متكررة:
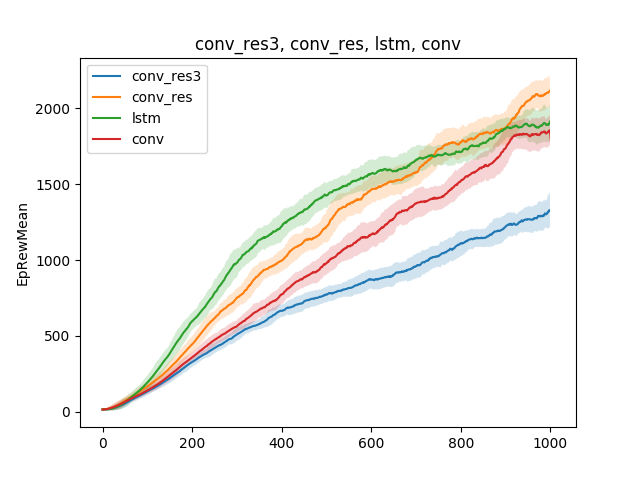
يمكن استخلاص النتيجة على النحو التالي: نظرًا لأن نموذج العنكبوت والمهمة بسيطان للغاية ، فإن نتائج التدريب هي نفسها تقريبًا بالنسبة للنماذج المختلفة. شبكة من ثلاث طبقات معقدة للغاية ، وبالتالي فهي تتعلم بشكل أسوأ.
على الرغم من حقيقة أن المحاكي يعمل مع نموذج عنكبوت بسيط ، اعتمادًا على المهمة الموكلة إلى العنكبوت ، يمكن أن يستمر التدريب لعدة أيام. في هذه الحالة ، دعنا ننقل عدة مئات من العناكب على سطح واحد في نفس الوقت بدلاً من واحد ونتعلم من البيانات التي سنتلقاها من الجميع. لذلك سوف نقوم بتسريع التدريب عدة مئات المرات. هنا مثال لمحرك فليكس.
الشيء الوحيد الذي تغير من حيث تحسين الشبكة العصبية هو جمع البيانات. عندما قمنا بتشغيل عنكبوت واحد فقط ، تلقينا البيانات بشكل تسلسلي. واحدة تلو الأخرى.

الآن قد يحدث أن بعض العناكب بدأت للتو السباق ، في حين أن البعض الآخر يركض منذ فترة طويلة.
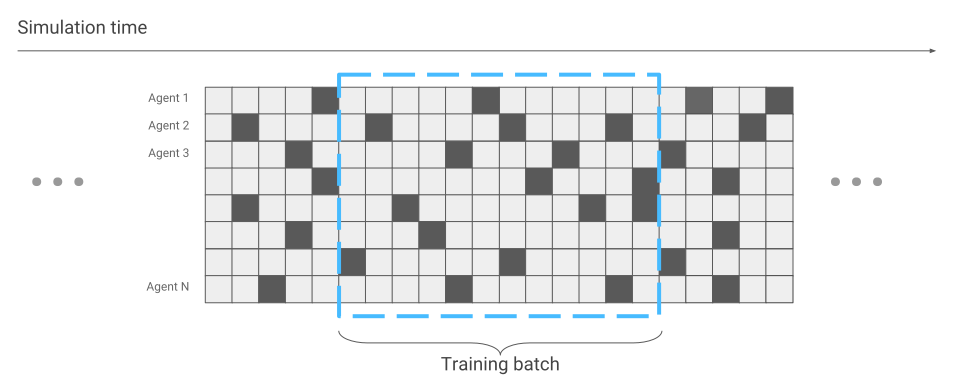
سنأخذ هذا في الاعتبار أثناء تحسين الشبكة العصبية. خلاف ذلك ، يبقى كل شيء على حاله. ونتيجة لذلك ، نحصل على تسارع في التدريب مئات المرات ، وفقًا لعدد العناكب التي تظهر على الشاشة في وقت واحد.
نظرًا لأن لدينا محاكيًا فعالًا ، فلنحاول حل المشكلات الأكثر تعقيدًا. على سبيل المثال ، الركض فوق التضاريس الوعرة.

نظرًا لأن البيئة في هذه الحالة أصبحت أكثر عدوانية ، فلنغير ونعقد المهام أثناء التدريب. من الصعب التعلم ، ولكن من السهل في المعركة. على سبيل المثال ، كل بضع دقائق لتغيير التضاريس. بالإضافة إلى ذلك ، دعنا نوجه وكلاء خارجيين إلى الوكيل. على سبيل المثال ، دعنا نرمي الكرات عليه ونحول الرياح ونغلقها. ثم يتعلم الوكيل الركض حتى على الأسطح التي لم يلتق بها قط. على سبيل المثال ، تسلق السلالم.

نظرًا لأننا تعلمنا بشكل فعال الركض في المحاكاة ، فلنراجع تقنيات التدريب التعزيزي في التخصصات التنافسية. على سبيل المثال ، في ألعاب الرماية. تقدم منصة VizDoom عالماً يمكنك فيه إطلاق النار وجمع الأسلحة وتجديد صحتك. في هذه اللعبة سنستخدم أيضًا شبكة عصبية. الآن فقط سيكون لديها خمسة مخارج: أربعة للحركة وواحدة لإطلاق النار.
لكي يكون التدريب فعالاً ، لنأخذه تدريجيًا. من البسيط إلى المعقد. عند المدخلات ، تتلقى الشبكة العصبية صورة ، وقبل البدء في القيام بشيء واعي ، يجب أن تتعلم فهم ما يتكون منه العالم. من خلال الدراسة في سيناريوهات بسيطة ، ستتعلم كيفية فهم الأشياء التي تسكن العالم وكيفية التفاعل معها. لنبدأ بالشرطة:
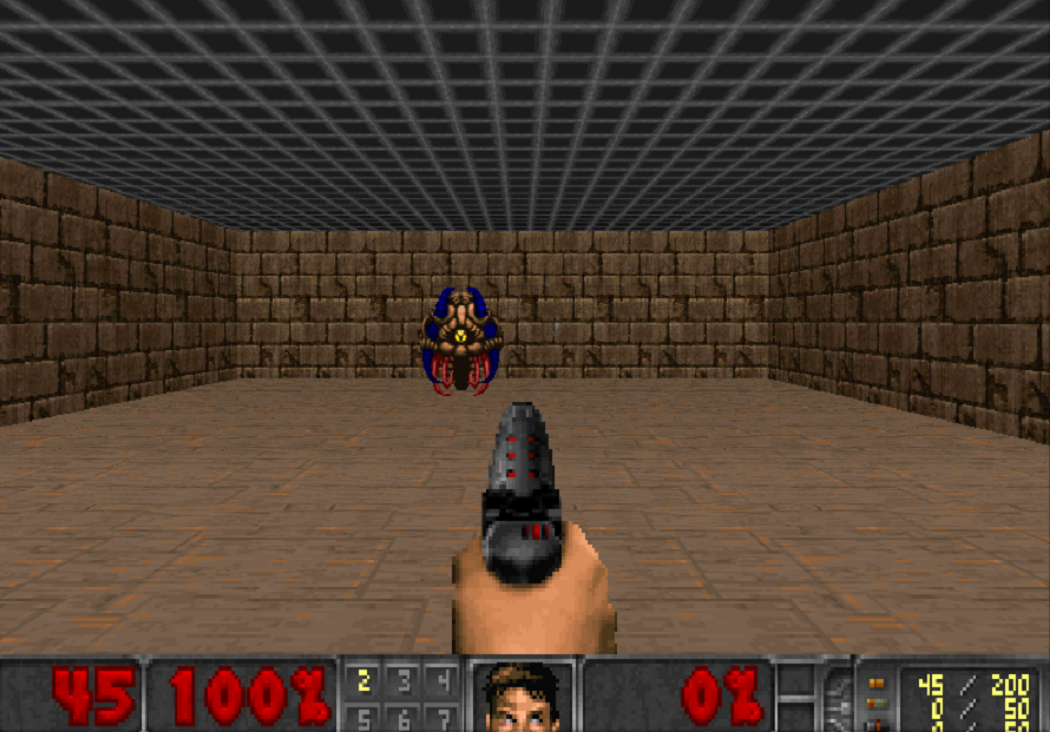
بعد إتقان هذا السيناريو ، سيفهم الوكيل أن هناك أعداء ، ويجب إطلاق النار عليهم ، لأنك تحصل على نقاط لهم. ثم سنقوم بتدريبه على سيناريو تتدهور فيه الصحة باستمرار ، وتحتاج إلى تجديده.

هنا سوف يتعلم أن لديه صحة ويحتاج إلى تجديد ، لأنه في حالة الوفاة يحصل الوكيل على مكافأة سلبية. بالإضافة إلى ذلك ، سيتعلم أنه إذا تحركت نحو الموضوع ، فيمكنك جمعه. في السيناريو الأول ، لم يستطع الوكيل التحرك.
وفي السيناريو الثالث والثالث ، دعنا نتركه يطلق النار باستخدام الروبوتات المبرمجة على القواعد من اللعبة حتى يتمكن من صقل مهاراته.

أثناء التدريب في هذا السيناريو ، فإن الاختيار الصحيح للمكافآت التي يتلقاها الوكيل مهم جدًا. على سبيل المثال ، إذا منحت مكافأة فقط للمنافسين المهزومين ، فستكون الإشارة نادرة جدًا: إذا كان هناك عدد قليل من اللاعبين ، فسوف نتلقى نقاطًا كل بضع دقائق. لذلك ، دعنا نستخدم مجموعة المكافآت التي كانت من قبل. سيحصل الوكيل على مكافأة لكل إجراء مفيد ، سواء كان ذلك لتحسين الصحة أو اختيار الخراطيش أو ضرب الخصم.
ونتيجة لذلك ، فإن الوكيل المدرب بمكافآت منتقاة جيدًا أقوى من خصومه الأكثر تطلبًا حسابيًا. في عام 2016 ، فاز مثل هذا النظام في مسابقة VizDoom بهامش أكثر من نصف النقاط التي تم تسجيلها من المركز الثاني. استخدم فريق الوصيف أيضًا شبكة عصبية ، فقط مع عدد كبير من الطبقات ومعلومات إضافية من محرك اللعبة أثناء التدريب. على سبيل المثال ، معلومات حول ما إذا كان هناك أعداء في مجال رؤية الوكيل.
لقد درسنا أساليب حل المشكلات ، حيث من المهم اتخاذ القرارات. لكن العديد من المهام مع هذا النهج ستبقى دون حل. على سبيل المثال ، لعبة السعي Montezuma Revenge.
هنا تحتاج إلى البحث عن مفاتيح لفتح الأبواب للغرف المجاورة. نادرًا ما نحصل على المفاتيح ، ونفتح الغرف بشكل أقل. من المهم أيضًا ألا تشتت انتباهك الأجسام الغريبة. إذا قمت بتدريب النظام كما فعلنا في المهام السابقة ، ومنحت مكافآت للأعداء الذين تعرضوا للضرب ، فإنه ببساطة سيطرد الجمجمة المتدرجة مرة تلو الأخرى ولن يفحص الخريطة. إذا كنت مهتمًا ، يمكنني التحدث عن حل هذه المشاكل في مقالة منفصلة.
يمكنك الاستماع إلى خطاب فلاديمير إيفانوف في مؤتمر منظمة العفو الدولية يوم 22 نوفمبر . يتوفر برنامج مفصل وتذاكر على
الموقع الرسمي للحدث.
اقرأ المقابلة مع فلاديمير
هنا .