قاتلة 43 ثانية ، مما تسبب في التدهور اليومي للخدمةوقع
حادث على جيثب الأسبوع الماضي أدى إلى تدهور الخدمة لمدة 24 ساعة و 11 دقيقة. لم يؤثر الحادث على النظام الأساسي بأكمله ، ولكن فقط عدد قليل من الأنظمة الداخلية ، مما أدى إلى عرض معلومات قديمة وغير متناسقة. في النهاية ، لم يتم فقدان بيانات المستخدم ، ولكن التسوية اليدوية لعدة ثوان من الكتابة إلى قاعدة البيانات لا تزال جارية. في معظم فترات التعطل ، لم يتمكن GitHub أيضًا من التعامل مع رسائل الويب ، وإنشاء ونشر صفحات GitHub.
نود جميعًا في GitHub أن نعتذر بصدق عن المشاكل التي واجهتها جميعًا. نحن نعرف عن ثقتك في GitHub ونفخر بإنشاء أنظمة مستدامة تدعم التوفر العالي لمنصتنا. لقد خذلناك مع هذا الحادث ونأسف بشدة عليه. على الرغم من أنه لا يمكننا إلغاء المشاكل بسبب تدهور منصة GitHub لفترة طويلة ، يمكننا شرح أسباب ما حدث ، والتحدث عن الدروس المستفادة والتدابير التي ستسمح للشركة بحماية نفسها بشكل أفضل من مثل هذه الإخفاقات في المستقبل.
الخلفية
تعمل معظم خدمات مستخدمي GitHub في
مراكز البيانات الخاصة بنا. تم تصميم طوبولوجيا مركز البيانات لتوفير شبكة حدودية موثوقة وقابلة للتوسيع أمام العديد من مراكز البيانات الإقليمية التي توفر عمل أنظمة الحوسبة وتخزين البيانات. على الرغم من مستويات التكرار المضمنة في المكونات المادية والمنطقية للمشروع ، لا يزال من الممكن ألا تتمكن المواقع من التفاعل مع بعضها البعض لبعض الوقت.
في 21 أكتوبر ، الساعة 10:52 مساءً بالتوقيت العالمي المنسق ، أدت أعمال الإصلاح المجدولة لاستبدال المعدات الضوئية 100G الخاطئة إلى فقدان الاتصال بين عقدة الشبكة على الساحل الشرقي (الساحل الشرقي للولايات المتحدة) ومركز البيانات الرئيسي على الساحل الشرقي. تم استعادة الاتصال بينهما بعد 43 ثانية ، لكن هذا الانفصال القصير تسبب في سلسلة من الأحداث التي أدت إلى 24 ساعة و 11 دقيقة من تدهور الخدمة.
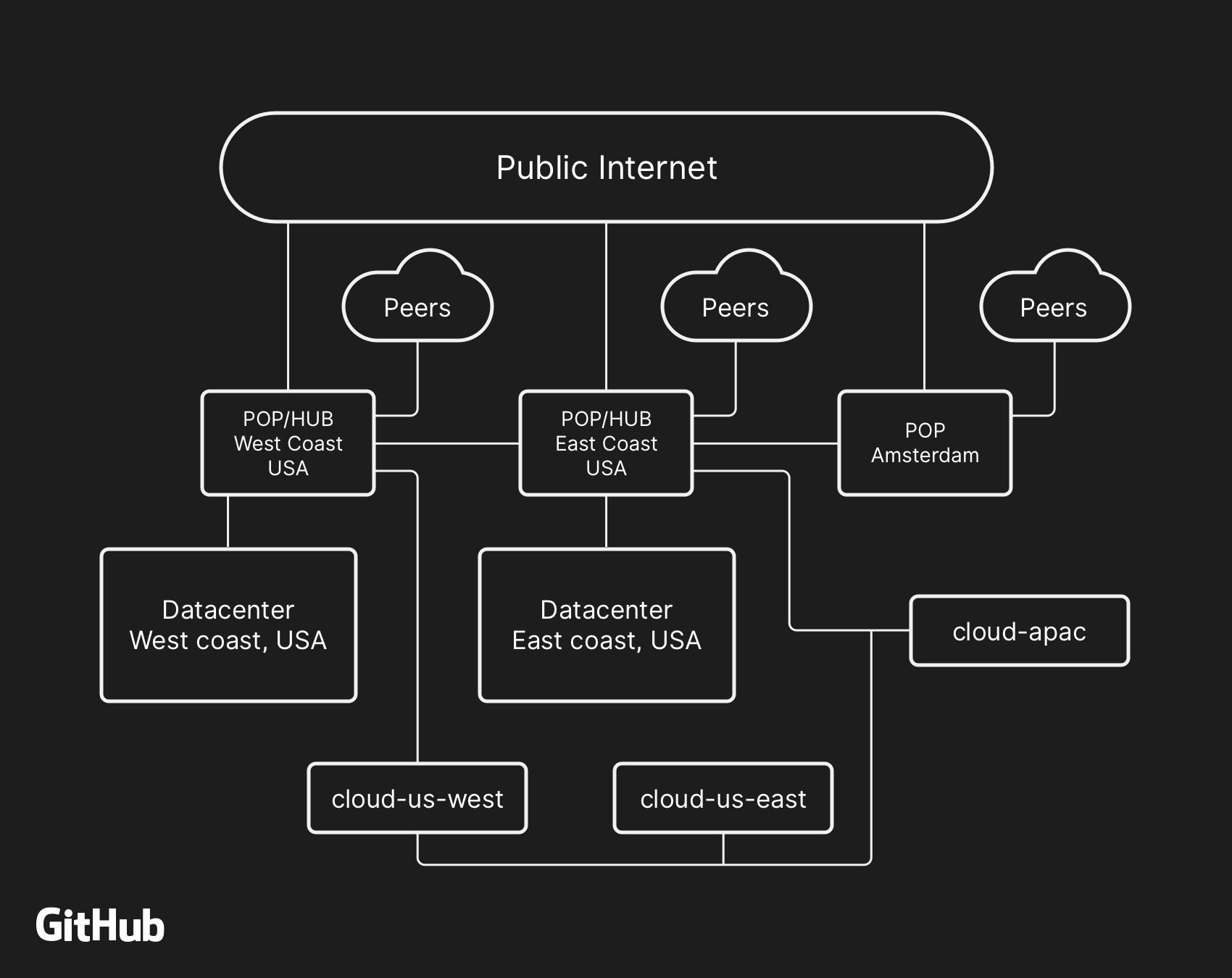 بنية شبكة GitHub رفيعة المستوى ، بما في ذلك مركزين للبيانات المادية ، و 3 POPs ، والتخزين السحابي في عدة مناطق ، متصلة عبر الأقران
بنية شبكة GitHub رفيعة المستوى ، بما في ذلك مركزين للبيانات المادية ، و 3 POPs ، والتخزين السحابي في عدة مناطق ، متصلة عبر الأقرانفي الماضي ، ناقشنا كيف نستخدم
MySQL لتخزين البيانات الوصفية لـ GitHub ، بالإضافة إلى أسلوبنا في توفير إمكانية توفر
عالية لـ MySQL . يدير GitHub عدة مجموعات MySQL تتراوح في الحجم من مئات غيغابايت إلى ما يقرب من خمسة تيرابايت. تحتوي كل مجموعة على العشرات من النسخ المتماثلة للقراءة لتخزين البيانات الوصفية بخلاف Git ، لذلك توفر تطبيقاتنا طلبات التجمع والمشكلات والمصادقة ومعالجة الخلفية وميزات إضافية خارج مستودع كائن Git. يتم تخزين البيانات المختلفة في أجزاء مختلفة من التطبيق في مجموعات مختلفة باستخدام التجزئة الوظيفية.
لتحسين الأداء على نطاق واسع ، تكتب التطبيقات مباشرة إلى الخادم الأساسي المناسب لكل مجموعة ، ولكن في الغالبية العظمى من الحالات تفوض طلبات القراءة إلى مجموعة فرعية من خوادم النسخ المتماثلة. نستخدم
Orchestrator لإدارة طوبولوجيا كتلة MySQL ونفشل تلقائيًا. خلال هذه العملية ، تأخذ Orchestrator في الاعتبار عددًا من المتغيرات ويتم تجميعها فوق
الطوافة من أجل الاتساق. يمكن أن يقوم Orchestrator بتنفيذ طبولوجيا لا تدعمها التطبيقات ، لذلك تحتاج إلى التأكد من أن تكوين Orchestrator الخاص بك يلبي التوقعات على مستوى التطبيق.
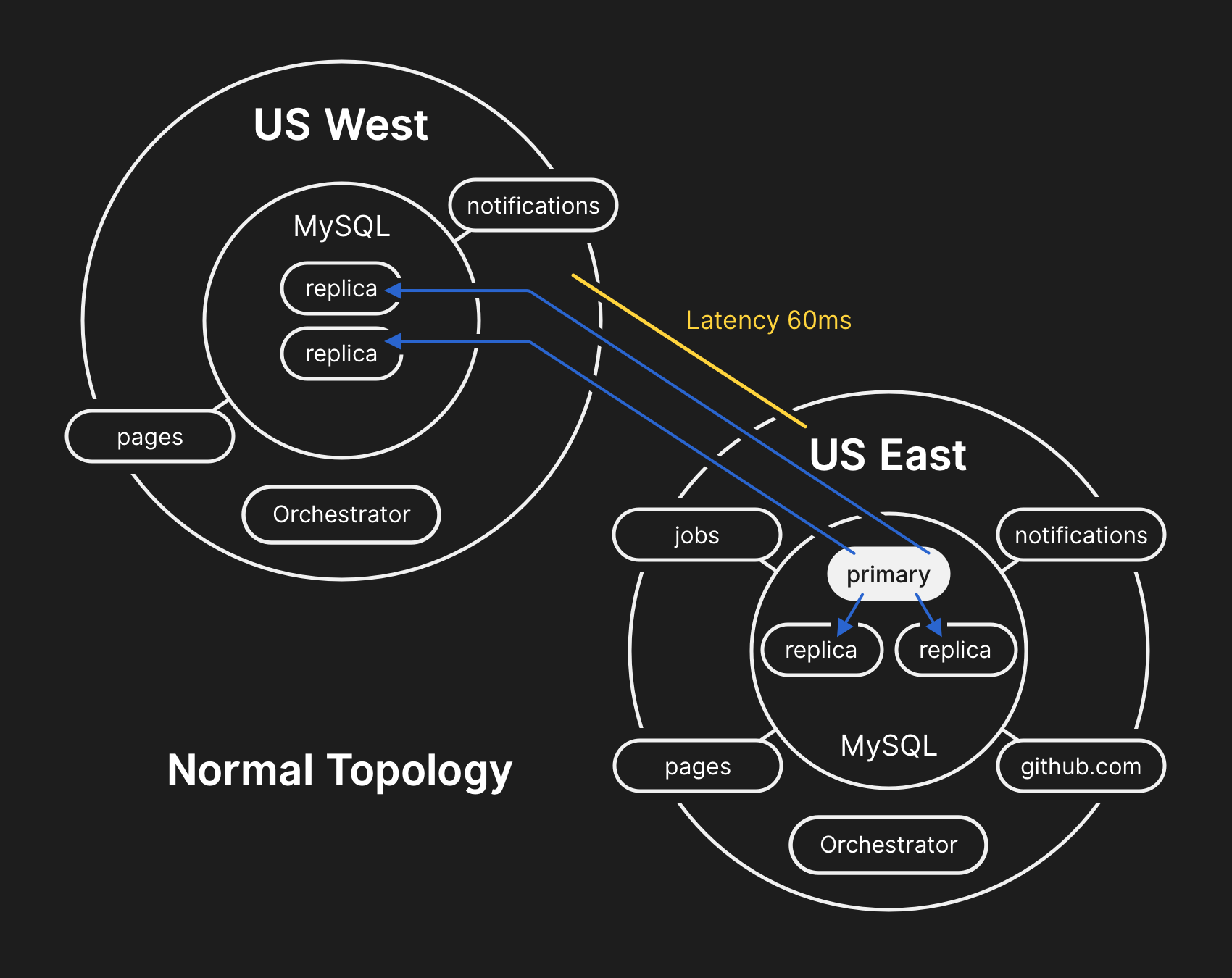 في الطوبولوجيا النموذجية ، تتم قراءة جميع التطبيقات محليًا بوقت استجابة منخفض.
في الطوبولوجيا النموذجية ، تتم قراءة جميع التطبيقات محليًا بوقت استجابة منخفض.وقائع الحادث
10.21.2018 ، 22:52 UTC
خلال فصل الشبكة المذكور ، بدأ Orchestrator في مركز البيانات الرئيسي عملية إلغاء اختيار القيادة وفقًا لخوارزمية توافق Raft. تمكن مركز بيانات الساحل الغربي وعقد السحابة العامة Orchestrator على الساحل الشرقي من التوصل إلى توافق في الآراء - وبدأت في حل فشل المجموعات لإعادة توجيه السجلات إلى مركز البيانات الغربي. بدأ Orchestrator في إنشاء طوبولوجيا كتلة قاعدة بيانات في الغرب. بعد إعادة الاتصال ، أرسلت التطبيقات على الفور حركة مرور الكتابة إلى الخوادم الأساسية الجديدة في غرب الولايات المتحدة.
على خوادم قواعد البيانات في مركز البيانات الشرقي ، كانت هناك سجلات لفترة قصيرة لم يتم نسخها إلى مركز البيانات الغربي. نظرًا لأن مجموعات قواعد البيانات في كلا مركزي البيانات تحتوي الآن على سجلات لم تكن موجودة في مركز البيانات الآخر ، لم نتمكن من إعادة الخادم الأساسي بأمان إلى مركز البيانات الشرقي.
10.21.2018 ، 22:54 UTC
بدأت أنظمة المراقبة الداخلية لدينا في إصدار تنبيهات تشير إلى العديد من أعطال النظام. في هذا الوقت ، استجاب العديد من المهندسين وعملوا على فرز الإشعارات الواردة. بحلول 23:02 ، حدد مهندسو مجموعة الاستجابة الأولى أن طبولوجيا العديد من مجموعات قواعد البيانات كانت في حالة غير متوقعة. عند الاستعلام عن Orchestrator API ، تم عرض طبولوجيا النسخ المتماثل لقاعدة البيانات ، التي تحتوي فقط على خوادم من مركز البيانات الغربي.
10.21.2018 ، 23:07 UTC
في هذه المرحلة ، قرر فريق الاستجابة حظر أدوات النشر الداخلي يدويًا لمنع التغييرات الإضافية. في الساعة 23:09 ، قامت المجموعة بضبط الموقع على
اللون الأصفر . يقوم هذا الإجراء تلقائيًا بتعيين الحالة لحادث نشط وإرسال تحذير إلى منسق الحادث. في الساعة 23:11 ، انضم المنسق إلى العمل وقرر بعد دقيقتين
تغيير الحالة إلى اللون الأحمر .
10.21.2018 ، 23:13 UTC
في ذلك الوقت ، كان من الواضح أن المشكلة تؤثر على العديد من مجموعات قواعد البيانات. وشارك مطورون آخرون من المجموعة الهندسية لقاعدة البيانات في العمل. بدأوا في فحص الحالة الحالية لتحديد الإجراءات التي يلزم اتخاذها لتكوين قاعدة بيانات الساحل الشرقي للولايات المتحدة يدويًا كأساس لكل عنقود وإعادة بناء طبولوجيا النسخ المتماثل. لم يكن ذلك سهلاً ، لأنه في هذه المرحلة كانت مجموعة قاعدة البيانات الغربية تتلقى سجلات من مستوى التطبيق لمدة 40 دقيقة تقريبًا. بالإضافة إلى ذلك ، في المجموعة الشرقية ، كانت هناك عدة ثوان من السجلات التي لم يتم تكرارها في الغرب ولم تسمح بتكرار السجلات الجديدة مرة أخرى إلى الشرق.
حماية خصوصية بيانات المستخدم وسلامتها هي الأولوية القصوى لـ GitHub. لذلك ، قررنا أن أكثر من 30 دقيقة من البيانات المسجلة في مركز البيانات الغربي تترك لنا حلًا واحدًا فقط للوضع من أجل حفظ هذه البيانات: النقل إلى الأمام (الفشل إلى الأمام). ومع ذلك ، فإن التطبيقات في الشرق ، التي تعتمد على كتابة المعلومات إلى مجموعة MySQL الغربية ، غير قادرة حاليًا على التعامل مع التأخير الإضافي بسبب نقل معظم مكالمات قاعدة البيانات ذهابًا وإيابًا. سيؤدي هذا القرار إلى حقيقة أن خدمتنا ستصبح غير مناسبة للعديد من المستخدمين. نعتقد أن التدهور طويل الأمد لجودة الخدمة كان يستحق ضمان اتساق بيانات المستخدمين.
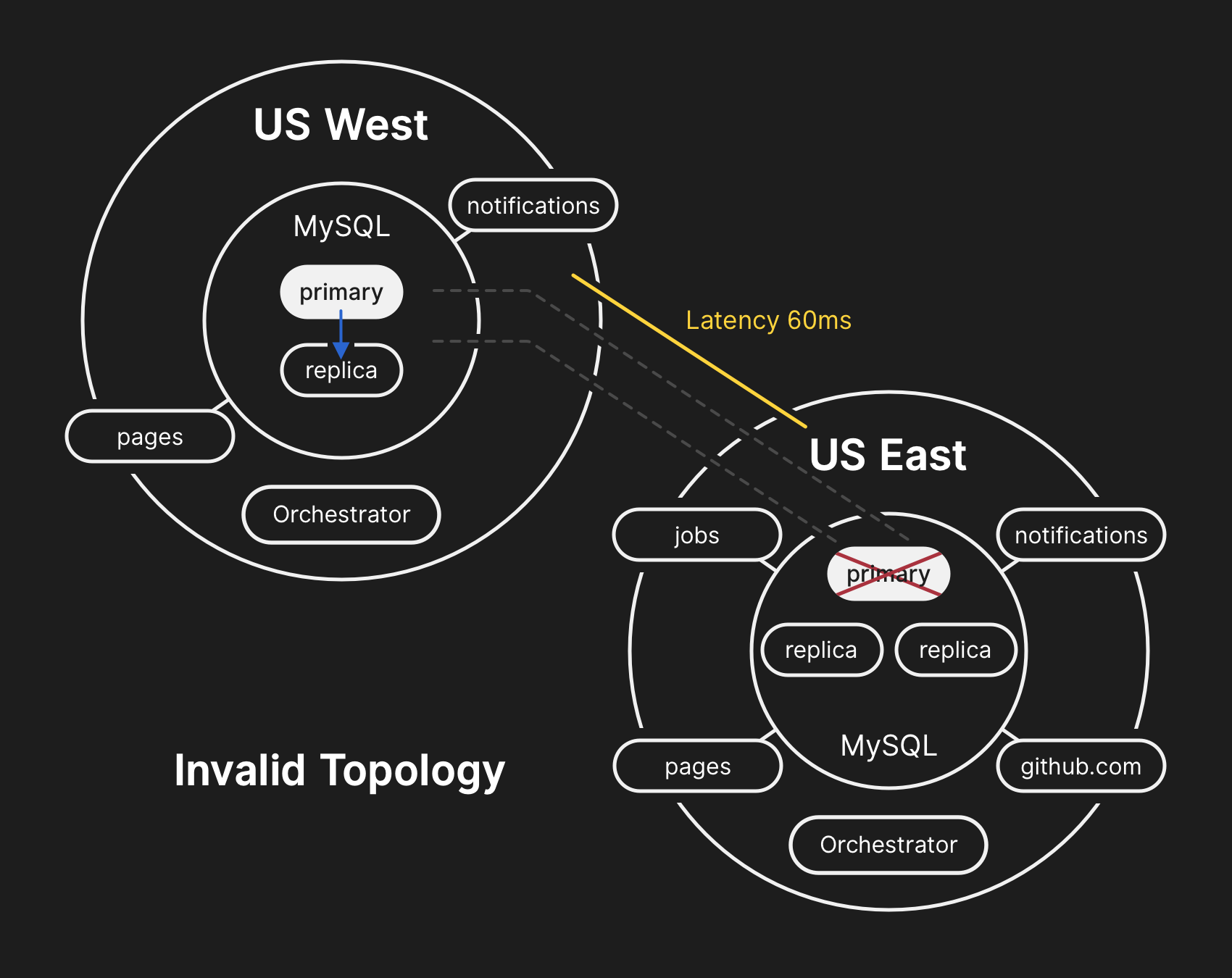 في الهيكل الخاطئ ، ينتهك النسخ المتماثل من الغرب إلى الشرق ، ولا يمكن للتطبيقات قراءة البيانات من النسخ المتماثلة الحالية ، لأنها تعتمد على الكمون المنخفض للحفاظ على أداء المعاملات
في الهيكل الخاطئ ، ينتهك النسخ المتماثل من الغرب إلى الشرق ، ولا يمكن للتطبيقات قراءة البيانات من النسخ المتماثلة الحالية ، لأنها تعتمد على الكمون المنخفض للحفاظ على أداء المعاملات10.21.2018 ، 23:19 UTC
أظهرت الاستفسارات حول حالة مجموعات قواعد البيانات أنه من الضروري إيقاف تنفيذ المهام التي تكتب بيانات التعريف مثل طلبات الدفع. لقد اخترنا وذهبنا عمدًا إلى تدهور جزئي في الخدمة ، وتعليق الخطافات على الويب وتجميع صفحات GitHub ، حتى لا يتم اختراق البيانات التي تلقيناها بالفعل من المستخدمين. وبعبارة أخرى ، كانت الاستراتيجية هي إعطاء الأولوية: سلامة البيانات بدلاً من سهولة الاستخدام في الموقع والاسترداد السريع.
10/22/2018 ، 00:05 UTC
بدأ مهندسو فريق الاستجابة في تطوير خطة لحل تناقضات البيانات وأطلقوا إجراءات تجاوز الفشل لـ MySQL. كانت الخطة هي استعادة الملفات من النسخ الاحتياطي ، ومزامنة النسخ المتماثلة على كلا الموقعين ، والعودة إلى طوبولوجيا خدمة مستقرة ، ثم استئناف مهام المعالجة في قائمة الانتظار. قمنا بتحديث الحالة لإبلاغ المستخدمين بأننا سنقوم بإجراء تجاوز فشل مُدار لنظام التخزين الداخلي.
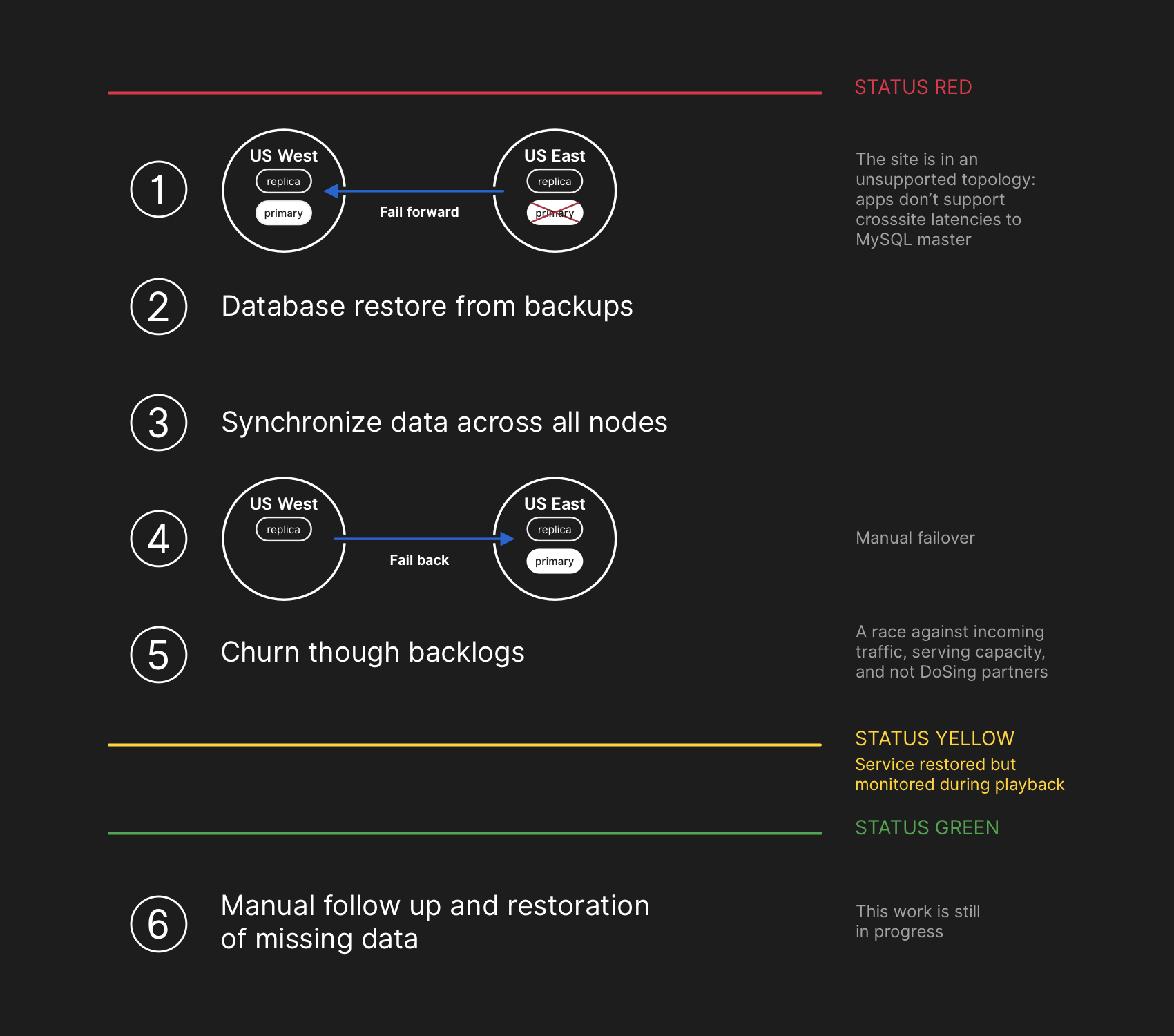 تضمنت خطة الاسترداد المضي قدمًا ، والاستعادة من النسخ الاحتياطية ، والمزامنة ، والتراجع ، والتخلص من التأخير قبل العودة إلى الحالة الخضراء
تضمنت خطة الاسترداد المضي قدمًا ، والاستعادة من النسخ الاحتياطية ، والمزامنة ، والتراجع ، والتخلص من التأخير قبل العودة إلى الحالة الخضراءعلى الرغم من أن النسخ الاحتياطية لـ MySQL يتم إجراؤها كل أربع ساعات ويتم تخزينها لسنوات عديدة ، إلا أنها تقع في التخزين السحابي البعيد لكائنات النقطة. استغرق استرداد عدة تيرابايت من نسخة احتياطية عدة ساعات. استغرق نقل البيانات من خدمة النسخ الاحتياطي عن بُعد وقتًا طويلاً. قضى معظم الوقت في تفريغ ، فحص المجموع الاختباري ، وإعداد وتحميل ملفات النسخ الاحتياطي الكبيرة إلى خوادم MySQL المعدة حديثًا. يتم اختبار هذا الإجراء يوميًا ، لذلك كان لدى الجميع فكرة جيدة عن المدة التي سيستغرقها التعافي. ومع ذلك ، قبل هذا الحادث ، لم يكن علينا أبدًا إعادة بناء المجموعة بالكامل من نسخة احتياطية. لقد عملت استراتيجيات أخرى دائمًا ، مثل النسخ المتماثلة المؤجلة.
10/22/2018 ، 00:41 UTC
وبحلول هذا الوقت ، كانت قد بدأت عملية النسخ الاحتياطي لجميع مجموعات MySQL المتأثرة ، وتتبع المهندسون التقدم. في الوقت نفسه ، درست عدة مجموعات من المهندسين طرق تسريع النقل والاسترداد دون مزيد من التدهور في الموقع أو خطر تلف البيانات.
10/22/2018 ، 06:51 UTC
أكملت عدة مجموعات في مركز البيانات الشرقي التعافي من النسخ الاحتياطية وبدأت في تكرار البيانات الجديدة من الساحل الغربي. أدى ذلك إلى تباطؤ في تحميل الصفحات التي قامت بعملية كتابة عبر الدولة ، ولكن قراءة الصفحات من مجموعات قواعد البيانات هذه أعادت نتائج فعلية إذا وقع طلب القراءة على نسخة متماثلة مستعادة حديثًا. استمرت مجموعات قاعدة البيانات الأكبر الأخرى في التعافي.
حددت فرقنا طريقة استرداد مباشرة من الساحل الغربي للتغلب على قيود النطاق الترددي الناتجة عن التمهيد من وحدة التخزين الخارجية. أصبح من الواضح 100 ٪ تقريبًا أن الاسترداد سيكتمل بنجاح ، ويعتمد الوقت اللازم لإنشاء طبولوجيا النسخ المتماثل الصحي على مقدار ما يستغرقه النسخ المتماثل. تم استكمال هذا التقدير خطيًا بناءً على النسخ المتماثل للقياس عن بُعد المتاح ، وتم
تحديث صفحة الحالة لتعيين الانتظار لمدة ساعتين كوقت الاسترداد المقدر.
10/22/2018 ، 07:46 UTC
نشر GitHub
مشاركة مدونة إخبارية . نحن أنفسنا نستخدم صفحات GitHub ، وتم إيقاف جميع التجميعات مؤقتًا قبل بضع ساعات ، لذلك يتطلب المنشور جهدًا إضافيًا. نعتذر عن التأخير. نحن نعتزم إرسال هذه الرسالة في وقت أبكر بكثير وفي المستقبل سوف ننشر التحديثات في ظروف مثل هذه القيود.
10/22/2018 ، 11:12 UTC
يتم نقل جميع قواعد البيانات الأولية مرة أخرى إلى الشرق. أدى ذلك إلى جعل الموقع أكثر استجابة ، حيث تم الآن توجيه السجلات إلى خادم قاعدة بيانات موجود في نفس مركز البيانات المادية مثل طبقة التطبيق لدينا. على الرغم من أن هذا تحسن بشكل كبير في الأداء ، إلا أنه لا تزال هناك عشرات النسخ المتماثلة لقراءة قاعدة البيانات التي كانت متأخرا عن النسخة الرئيسية بضع ساعات. دفعت هذه النسخ المتماثلة المؤجلة المستخدمين إلى رؤية بيانات غير متناسقة عند التفاعل مع خدماتنا. نقوم بتوزيع حمل القراءة عبر مجموعة كبيرة من النسخ المتماثلة للقراءة ، ولكل طلب لخدماتنا فرص جيدة للوصول إلى النسخة المتماثلة للقراءة مع تأخير لعدة ساعات.
في الواقع ، يتم تقليل وقت اللحاق بالنسخة المتماثلة المتأخر بشكل كبير ، وليس بشكل خطي. عندما استيقظ المستخدمون في الولايات المتحدة وأوروبا ، نظرًا لزيادة الحمل على السجلات في مجموعات قواعد البيانات ، استغرقت عملية الاسترداد وقتًا أطول من المتوقع.
10/22/2018 ، 13:15 UTC
كنا نقترب من ذروة الحمل على GitHub.com. ناقش فريق الاستجابة الخطوات التالية. كان من الواضح أن تأخر النسخ المتماثل إلى حالة ثابتة آخذ في الازدياد ، وليس في التناقص. في وقت سابق ، بدأنا في إعداد نسخ متماثلة إضافية لقراءة MySQL في سحابة الساحل الشرقي العامة. بمجرد توفرها ، أصبح من الأسهل توزيع تدفق طلبات القراءة بين عدة خوادم. إن تقليل الحمل المتوسط على النسخ المتماثلة المقروءة يؤدي إلى تسريع اللحاق بالنسخ المتماثل.
10/22/2018 ، 16:24 UTC
بعد مزامنة النسخ المتماثلة ، عدنا إلى الهيكل الأصلي ، تخلصنا من مشاكل التأخير والتوافر. كجزء من قرار واع بشأن أولوية تكامل البيانات عبر تصحيح سريع للموقف ،
حافظنا على الحالة الحمراء للموقع عندما بدأنا في معالجة البيانات المتراكمة.
10/22/2018 ، 16:45 UTC
في مرحلة الاسترداد ، كان من الضروري موازنة الحمل الزائد المرتبط بالتأخر ، مما قد يؤدي إلى زيادة التحميل على شركائنا في النظام البيئي مع الإخطارات والعودة إلى كفاءة مائة بالمائة في أسرع وقت ممكن. بقي في قائمة الانتظار أكثر من خمسة ملايين حدث ربط و 80 ألف طلب لبناء صفحات ويب.
عندما قمنا بإعادة تمكين معالجة هذه البيانات ، قمنا بمعالجة حوالي 200000 مهمة مفيدة مع رسائل الويب التي تجاوزت TTL الداخلية وتم إسقاطها. عند التعرف على هذا الأمر ، توقفنا عن المعالجة وبدأنا في زيادة مدة البقاء (TTL).
لتجنب المزيد من الانخفاض في موثوقية تحديثات الحالة لدينا ، تركنا حالة التدهور حتى ننتهي من معالجة الكمية الكاملة من البيانات المتراكمة ونتأكد من أن الخدمات قد عادت بوضوح إلى المستوى العادي للأداء.
10/22/2018 ، 11:03 مساءً UTC
تتم معالجة جميع أحداث التجميع غير المكتمل وتجميعات الصفحات وتأكيد سلامة جميع الأنظمة والتشغيل الصحيح لها. تم
تحديث حالة الموقع
إلى اللون الأخضر .
إجراءات أخرى
حل عدم تطابق البيانات
أثناء عملية الاسترداد ، قمنا بإصلاح سجلات MySQL الثنائية بإدخالات خاصة بمركز البيانات ، والتي لم يتم نسخها إلى السجلات الغربية. العدد الإجمالي لمثل هذه الإدخالات صغير نسبيا. على سبيل المثال ، في واحدة من أكثر المجموعات ازدحامًا ، يوجد 954 سجل فقط في هذه الثواني. نقوم حاليًا بتحليل هذه السجلات وتحديد الإدخالات التي يمكن التوفيق بينها تلقائيًا والتي تتطلب مساعدة المستخدم. تشارك عدة فرق في هذا العمل ، وقد حدد تحليلنا بالفعل فئة السجلات التي قام المستخدم بتكرارها - وتم حفظها بنجاح. كما هو مذكور في هذا التحليل ، هدفنا الأساسي هو الحفاظ على سلامة ودقة البيانات التي تقوم بتخزينها على GitHub.
التواصل
في محاولة لنقل معلومات مهمة إليك أثناء الحادث ، قمنا بعمل العديد من التقديرات العامة لوقت الاسترداد استنادًا إلى سرعة معالجة البيانات المتراكمة. إذا نظرنا إلى الوراء ، فإن تقديراتنا لم تأخذ في الاعتبار جميع المتغيرات. نعتذر عن هذا الارتباك وسنسعى جاهدين لتوفير معلومات أكثر دقة في المستقبل.
التدابير الفنية
في سياق هذا التحليل ، تم تحديد عدد من التدابير التقنية. يستمر التحليل ، يمكن استكمال القائمة.
- اضبط تكوين Orchestrator لمنع قواعد البيانات الأساسية من التحرك خارج المنطقة. عمل Orchestrator وفقًا للإعدادات ، على الرغم من أن طبقة التطبيق لا تدعم مثل هذا التغيير في الهيكل. عادةً ما يكون اختيار قائد داخل منطقة ما آمنًا ، ولكن ظهور التأخير المفاجئ بسبب تدفق حركة المرور عبر القارة أصبح السبب الرئيسي لهذا الحادث. هذا سلوك ناشئ وجديد للنظام ، لأنه قبل أن نواجه القسم الداخلي للشبكة بهذا الحجم.
- لقد قمنا بتسريع الترحيل إلى نظام الإبلاغ عن الحالة الجديد ، والذي سيوفر منصة أكثر ملاءمة لمناقشة الحوادث النشطة مع صيغ أكثر دقة ووضوحًا. على الرغم من أن العديد من أجزاء GitHub كانت متاحة طوال الحادث ، إلا أنه كان بإمكاننا فقط اختيار حالات خضراء وصفراء وحمراء للموقع بالكامل. نعترف بأن هذا لا يعطي صورة دقيقة: ما يصلح وما لا يصلح. سيعرض النظام الجديد مختلف مكونات النظام الأساسي حتى تعرف حالة كل خدمة.
- قبل بضعة أسابيع من هذا الحادث ، أطلقنا مبادرة هندسية على مستوى الشركة لدعم خدمة حركة مرور GitHub من مراكز بيانات متعددة باستخدام البنية النشطة / النشطة / النشطة. الهدف من هذا المشروع هو دعم التكرار N + 1 على مستوى مركز البيانات من أجل تحمل فشل مركز بيانات واحد دون تدخل خارجي. هذا كثير من العمل وسيستغرق بعض الوقت ، لكننا نعتقد أن العديد من مراكز البيانات الجيدة الاتصال في مناطق مختلفة ستوفر تسوية جيدة. دفع الحادث الأخير هذه المبادرة إلى أبعد من ذلك.
- سنتخذ موقفا أكثر نشاطا في التحقق من افتراضاتنا. ينمو GitHub بسرعة وقد تراكم قدر كبير من التعقيد على مدى العقد الماضي. لقد أصبح من الصعب على نحو متزايد التقاط وتمرير الجيل الجديد من الموظفين السياق التاريخي للتسويات والقرارات المتخذة.
الإجراءات التنظيمية
أثر هذا الحادث بشكل كبير على فهمنا لموثوقية الموقع. علمنا أن تشديد الرقابة التشغيلية أو تحسين أوقات الاستجابة ليست ضمانات كافية للموثوقية في مثل هذا النظام المعقد من الخدمات مثل خدماتنا. لدعم هذه الجهود ، سنبدأ أيضًا ممارسة منهجية لاختبار سيناريوهات الخطأ قبل حدوثها بالفعل. يتضمن هذا العمل استكشاف الأخطاء وإصلاحها بشكل متعمد واستخدام أدوات هندسة الفوضى.
الخلاصة
نحن نعرف كيف تعتمد على GitHub في مشاريعك وأعمالك. نحن نهتم أكثر من أي شخص بتوافر خدمتنا وسلامة بياناتك.
سيستمر تحليل هذا الحادث في إيجاد فرصة لخدمتك بشكل أفضل وتبرير ثقتك.