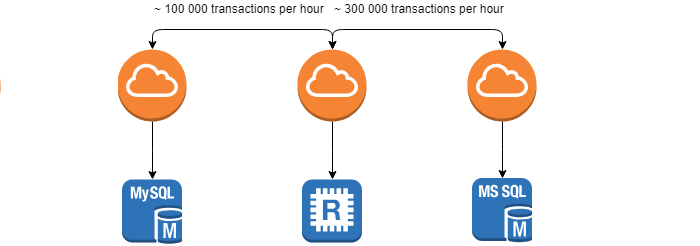
عند تطوير واستخدام النظم الموزعة ، نواجه مهمة مراقبة سلامة وهوية البيانات بين الأنظمة - مهمة المصالحة .
المتطلبات التي يحددها العميل هي الحد الأدنى من الوقت لهذه العملية ، نظرًا لأنه في أقرب وقت يتم العثور على التناقض ، سيكون من الأسهل إزالة عواقبه. المهمة معقدة بشكل كبير من حقيقة أن الأنظمة في حركة مستمرة (~ 100000 معاملة في الساعة) ولا يمكن تحقيق 0 ٪ من التناقضات.
الفكرة الرئيسية
يمكن وصف الفكرة الرئيسية للحل في الرسم البياني التالي.
نحن نعتبر كل عنصر على حدة.
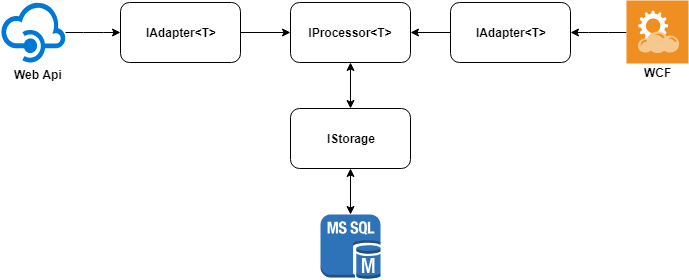
محولات البيانات
تم تصميم كل نظام لمنطقة الموضوع الخاصة به ، ونتيجة لذلك ، يمكن أن تختلف أوصاف الكائنات بشكل كبير. نحتاج إلى مقارنة مجموعة معينة فقط من الحقول من هذه الكائنات.
لتبسيط إجراء المقارنة ، نقوم بإحضار الكائنات إلى تنسيق واحد عن طريق كتابة محول لكل مصدر بيانات. يمكن أن يؤدي إحضار الكائنات إلى تنسيق واحد إلى تقليل حجم الذاكرة المستخدمة بشكل كبير ، حيث أننا سنقوم فقط بتخزين الحقول التي تتم مقارنتها.
تحت غطاء المحرك ، يمكن أن يكون للمحول أي مصدر بيانات: HttpClient ، SqlClient ، DynamoDbClient ، إلخ.
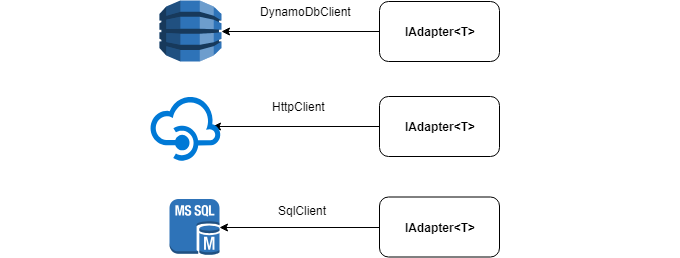
ما يلي هو واجهة IAdapter التي تريد تنفيذها:
public interface IAdapter<T> where T : IModel { int Id { get; } Task<IEnumerable<T>> GetItemsAsync(ISearchModel searchModel); } public interface IModel { Guid Id { get; } int GetHash(); }
التخزين
لا يمكن أن تبدأ تسوية البيانات إلا بعد قراءة جميع البيانات ، حيث يمكن أن تقوم المحولات بإعادتها بترتيب عشوائي.
في هذه الحالة ، قد لا تكون كمية ذاكرة الوصول العشوائي (RAM) كافية ، خاصة إذا قمت بإجراء العديد من التسويات في نفس الوقت ، مما يشير إلى فترات زمنية كبيرة.
خذ بعين الاعتبار واجهة IStorage
public interface IStorage { int SourceAdapterId { get; } int TargetAdapterId { get; } int MaxWriteCapacity { get; } Task InitializeAsync(); Task<int> WriteItemsAsync(IEnumerable<IModel> items, int adapterId); Task<IEnumerable<IResultModel>> GetDifferenceAsync(ISearchDifferenceModel model); } public interface ISearchDifferenceModel { int Offset { get; } int Limit { get; } }
المستودع. تطبيق MS SQL
قمنا بتطبيق IStorage باستخدام MS SQL ، مما سمح لنا بإجراء المقارنة بالكامل من جانب خادم Db.
لتخزين القيم المطلوبة ، ما عليك سوى إنشاء الجدول التالي:
CREATE TABLE [dbo].[Storage_1540747667] ( [id] UNIQUEIDENTIFIER NOT NULL, [adapterid] INT NOT NULL, [qty] INT NOT NULL, [price] INT NOT NULL, CONSTRAINT [PK_Storage_1540747667] PRIMARY KEY ([id], [adapterid]) )
يحتوي كل سجل على حقول النظام ( [id] و [adapterId] ) وحقول المقارنة ( [qty] و [price] ). بضع كلمات حول حقول النظام:
[id] - معرف فريد للدخول ، وهو نفس الشيء في كلا النظامين
[adapterId] - كود تعريف الموفق الذي تم استلام السجل من خلاله
نظرًا لأن عمليات التسوية يمكن أن تبدأ بالتوازي ولها فواصل زمنية متقاطعة ، فإننا ننشئ جدولًا باسم فريد لكل منها. في حالة نجاح التسوية ، يتم حذف هذا الجدول ، وإلا يتم إرسال تقرير يحتوي على قائمة من السجلات التي توجد بها اختلافات.
المستودع. مقارنة القيمة
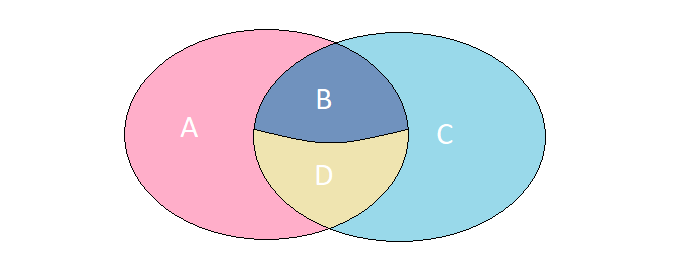
تخيل أن لدينا مجموعتان تحتوي عناصرهما على مجموعة متطابقة تمامًا من الحقول. فكر في 4 حالات محتملة لتقاطعها:
أ. العناصر موجودة فقط في المجموعة اليسرى.
ب. العناصر موجودة في كلا المجموعتين ، ولكن لها معاني مختلفة.
ق العناصر موجودة فقط في المجموعة الصحيحة.
د العناصر موجودة في كلا المجموعتين ولها نفس المعنى.
في مشكلة معينة ، نحتاج إلى العثور على العناصر الموضحة في الحالات أ ، ب ، ج. يمكنك الحصول على النتيجة المطلوبة في استعلام واحد إلى MS SQL عبر FULL OUTER JOIN :
select [s1].[id], [s1].[adapterid] from [dbo].[Storage_1540758006] as [s1] full outer join [dbo].[Storage_1540758006] as [s2] on [s2].[id] = [s1].[id] and [s2].[adapterid] != [s1].[adapterid] and [s2].[qty] = [s1].[qty] and [s2].[price] = [s1].[price] where [s2].[id] is nul
قد يحتوي ناتج هذا الطلب على 4 أنواع من السجلات التي تلبي المتطلبات الأولية
| # | معرف | محوّل | التعليق |
|---|
| 1 | Guid1 | ADP1 | السجل موجود فقط في المجموعة اليسرى. الحالة أ |
| 2 | دليل 2 | ADP2 | السجل موجود فقط في المجموعة الصحيحة. الحالة ج |
| 3 | دليل 3 | ADP1 | السجلات موجودة في كلتا المجموعتين ، ولكن لها معان مختلفة. الحالة ب |
| 4 | دليل 3 | ADP2 | السجلات موجودة في كلتا المجموعتين ، ولكن لها معان مختلفة. الحالة ب |
المستودع. التجزئة
باستخدام التجزئة على الأشياء المقارنة ، يمكنك تقليل تكلفة الكتابة ومقارنة العمليات بشكل كبير. خاصة عندما يتعلق الأمر بمقارنة عشرات الحقول.
تبين أن الطريقة الأكثر شمولية لتجزئة تمثيل متسلسل لكائن ما.
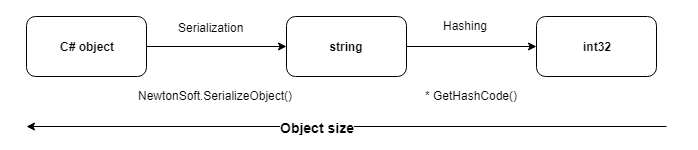
1. بالنسبة للتجزئة ، نستخدم طريقة GetHashCode () القياسية ، التي تُرجع int32 ويتم تجاوزها لجميع الأنواع البدائية.
2. في هذه الحالة ، من غير المحتمل حدوث تصادمات ، حيث تتم مقارنة السجلات التي لها نفس المعرفات فقط.
خذ بعين الاعتبار بنية الجدول المستخدمة في هذا التحسين:
CREATE TABLE [dbo].[Storage_1540758006] ( [id] UNIQUEIDENTIFIER NOT NULL, [adapterid] INT NOT NULL, [hash] INT NOT NULL, CONSTRAINT [PK_Storage_1540758006] PRIMARY KEY ([id], [adapterid], [hash]) )
ميزة مثل هذا الهيكل هو التكلفة الثابتة لتخزين سجل واحد (24 بايت) ، والتي لن تعتمد على عدد الحقول المقارنة.
بطبيعة الحال ، يخضع إجراء المقارنة لتغييراته ويصبح أبسط بكثير.
select [s1].[id], [s1].[adapterid] from [dbo].[Storage_1540758006] as [s1] full outer join [dbo].[Storage_1540758006] as [s2] on [s2].[id] = [s1].[id] and [s2].[adapterid] != [s1].[adapterid] and [s2].[hash] = [s1].[hash] where [s2].[id] is null
وحدة المعالجة المركزية
في هذا القسم ، سنتحدث عن فصل يحتوي على كل منطق الأعمال للمصالحة ، وهي:
1. قراءة موازية للبيانات من المحولات
2. تجزئة البيانات
3. سجل مخزنة للقيم في قاعدة البيانات
4. تسليم النتائج
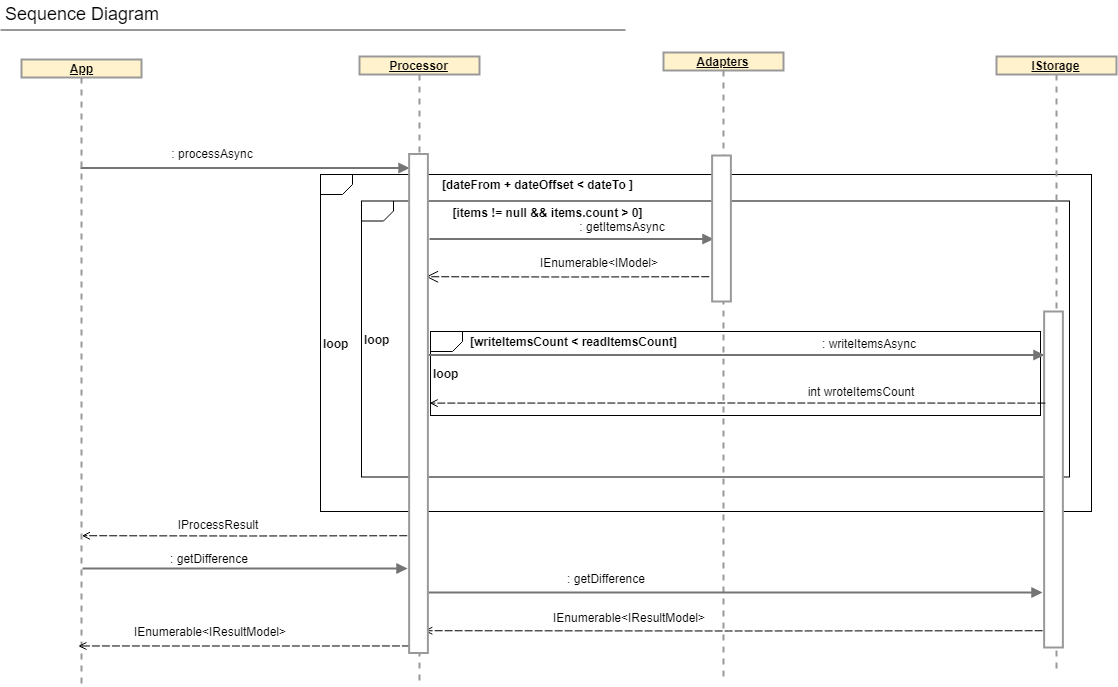
يمكن الحصول على وصف أكثر شمولاً لعملية التسوية من خلال النظر إلى مخطط التسلسل وواجهة IProcessor.
public interface IProcessor<T> where T : IModel { IAdapter<T> SourceAdapter { get; } IAdapter<T> TargetAdapter { get; } IStorage Storage { get; } Task<IProcessResult> ProcessAsync(); Task<IEnumerable<IResultModel>> GetDifferenceAsync(ISearchDifferenceModel model); }
شكر وتقدير
شكرا جزيلا لزملائي من مجموعة MySale على التعليقات: AntonStrakhov و Nesstory و Barlog_5 و Kostya Krivtsun و VeterManve - مؤلف الفكرة.