ملاحظة perev. ج: تمت كتابة المقالة الأصلية بواسطة BlueData ، وهي شركة أسسها أشخاص من VMware. وهي متخصصة في تسهيل نشر الحلول لتحليلات البيانات الضخمة وتعلم الآلة في بيئات مختلفة (أسهل وأسرع وأرخص). إن المبادرة الأخيرة للشركة المسماة BlueK8s ، والتي يريد المؤلفون فيها تجميع مجموعة من أدوات المصادر المفتوحة "لنشر التطبيقات ذات الحالة وإدارتها في Kubernetes" ، مدعوة أيضًا للمساهمة في ذلك. تم تخصيص المقالة لأولهم - KubeDirector ، والذي ، وفقًا للمؤلفين ، يساعد المتحمسين في مجال Big Data ، الذين ليس لديهم تدريب خاص في Kubernetes ، ينشرون تطبيقات مثل Spark ، Cassandra أو Hadoop في K8s. يتم توفير تعليمات موجزة حول كيفية القيام بذلك في المقالة. ومع ذلك ، ضع في اعتبارك أن المشروع لديه حالة استعداد مبكر - ما قبل ألفا.
KubeDirector هو مشروع مفتوح المصدر مصمم لتبسيط إطلاق المجموعات من التطبيقات المعقدة القابلة للتطوير في Kubernetes. يتم تنفيذ KubeDirector باستخدام إطار عمل
تعريف الموارد المخصصة (CRD) ، ويستخدم إمكانات امتداد Kubernetes API الأصلية ويعتمد على فلسفتهم. يوفر هذا النهج تكاملاً شفافًا مع إدارة المستخدمين والموارد في Kubernetes ، وكذلك مع العملاء الحاليين والمرافق.
يعد مشروع KubeDirector الذي
تم الإعلان عنه مؤخرًا جزءًا من مبادرة مفتوحة المصدر أكبر لـ Kubernetes تسمى BlueK8s. يسرني الآن أن أعلن عن توفر رمز
KubeDirector المبكر (قبل ألفا). هذا المنشور سيظهر كيف يعمل
يقدم KubeDirector الميزات التالية:
- لا حاجة لتعديل التعليمات البرمجية لتشغيل تطبيقات أخرى بخلاف السحابة الأصلية من Kubernetes. وبعبارة أخرى ، ليست هناك حاجة لتحليل التطبيقات الحالية لتتناسب مع نمط بنية الخدمات المصغرة.
- دعم أصلي لتخزين التكوين والحالة الخاصة بالتطبيق.
- نمط نشر مستقل عن التطبيق يقلل من وقت بدء تشغيل التطبيقات ذات الحالة الجديدة في Kubernetes.
يسمح KubeDirector لعلماء البيانات ، الذين اعتادوا على التطبيقات الموزعة بمعالجة البيانات المكثفة ، مثل Hadoop و Spark و Cassandra و TensorFlow و Caffe2 وما إلى ذلك ، بتشغيلها في Kubernetes بأقل منحنى تعليمي ودون الحاجة إلى كتابة التعليمات البرمجية على Go. عندما يتم التحكم في هذه التطبيقات بواسطة KubeDirector ، يتم تعريفها بواسطة بيانات تعريف بسيطة ومجموعة التكوينات المرتبطة بها. يتم تعريف بيانات تعريف
KubeDirectorApp كمورد
KubeDirectorApp .
لفهم مكونات KubeDirector ، قم باستنساخ المستودع على
GitHub باستخدام أمر مثل ما يلي:
git clone http://<userid>@github.com/bluek8s/kubedirector.
KubeDirectorApp تعريف
KubeDirectorApp لتطبيق Spark 2.2.1 في ملف
kubedirector/deploy/example_catalog/cr-app-spark221e2.json :
~> cat kubedirector/deploy/example_catalog/cr-app-spark221e2.json
{ "apiVersion": "kubedirector.bluedata.io/v1alpha1", "kind": "KubeDirectorApp", "metadata": { "name" : "spark221e2" }, "spec" : { "systemctlMounts": true, "config": { "node_services": [ { "service_ids": [ "ssh", "spark", "spark_master", "spark_worker" ], …
يتم تعريف تكوين كتلة التطبيق كمورد
KubeDirectorCluster .
KubeDirectorCluster تعريف
KubeDirectorCluster الكتلة Spark 2.2.1 على
kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml :
~> cat kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml
apiVersion: "kubedirector.bluedata.io/v1alpha1" kind: "KubeDirectorCluster" metadata: name: "spark221e2" spec: app: spark221e2 roles: - name: controller replicas: 1 resources: requests: memory: "4Gi" cpu: "2" limits: memory: "4Gi" cpu: "2" - name: worker replicas: 2 resources: requests: memory: "4Gi" cpu: "2" limits: memory: "4Gi" cpu: "2" - name: jupyter …
قم بتشغيل Spark على Kubernetes مع KubeDirector
من السهل بدء مجموعات Spark في Kubernetes باستخدام KubeDirector.
أولاً ، تأكد من تشغيل Kubernetes (الإصدار 1.9 أو أعلى) باستخدام الأمر
kubectl version :
~> kubectl version Client Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T18:02:47Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"} Server Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T17:53:03Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}
انشر خدمة KubeDirector وعينة
KubeDirectorApp موارد
KubeDirectorApp باستخدام الأوامر التالية:
cd kubedirector make deploy
ونتيجة لذلك ، سيبدأ تحت KubeDirector:
~> kubectl get pods NAME READY STATUS RESTARTS AGE kubedirector-58cf59869-qd9hb 1/1 Running 0 1m
عرض قائمة التطبيقات المثبتة في KubeDirector بتشغيل
kubectl get KubeDirectorApp :
~> kubectl get KubeDirectorApp NAME AGE cassandra311 30m spark211up 30m spark221e2 30m
يمكنك الآن بدء تشغيل مجموعة Spark 2.2.1 باستخدام ملف عينة لـ
KubeDirectorCluster kubectl create -f deploy/example_clusters/cr-cluster-spark211up.yaml . تحقق من أنها بدأت:
~> kubectl get pods NAME READY STATUS RESTARTS AGE kubedirector-58cf59869-djdwl 1/1 Running 0 19m spark221e2-controller-zbg4d-0 1/1 Running 0 23m spark221e2-jupyter-2km7q-0 1/1 Running 0 23m spark221e2-worker-4gzbz-0 1/1 Running 0 23m spark221e2-worker-4gzbz-1 1/1 Running 0 23m
ظهر Spark أيضًا في قائمة الخدمات قيد التشغيل:
~> kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 21s svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 20s svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 20s svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 20s svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 20s
إذا وصلت إلى المنفذ 31533 في متصفحك ، يمكنك مشاهدة واجهة مستخدم Spark Master:
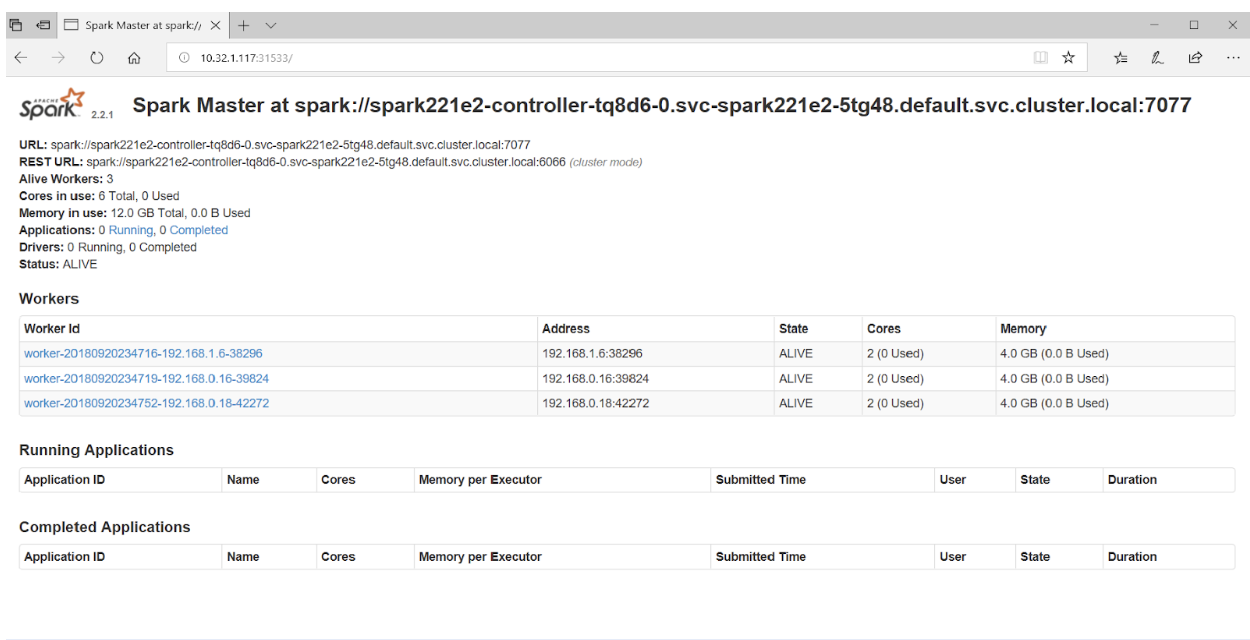
هذا كل شيء! في المثال أعلاه ، بالإضافة إلى مجموعة Spark ، قمنا أيضًا بنشر
Jupyter Notebook .
لبدء تطبيق آخر (على سبيل المثال ، كاساندرا) ما
KubeDirectorApp سوى تحديد ملف آخر باستخدام
KubeDirectorApp :
kubectl create -f deploy/example_clusters/cr-cluster-cassandra311.yaml
تحقق من أن مجموعة كاساندرا قد بدأت:
~> kubectl get pods NAME READY STATUS RESTARTS AGE cassandra311-seed-v24r6-0 1/1 Running 0 1m cassandra311-seed-v24r6-1 1/1 Running 0 1m cassandra311-worker-rqrhl-0 1/1 Running 0 1m cassandra311-worker-rqrhl-1 1/1 Running 0 1m kubedirector-58cf59869-djdwl 1/1 Running 0 1d spark221e2-controller-tq8d6-0 1/1 Running 0 22m spark221e2-jupyter-6989v-0 1/1 Running 0 22m spark221e2-worker-d9892-0 1/1 Running 0 22m spark221e2-worker-d9892-1 1/1 Running 0 22m
تدير Kubernetes الآن مجموعة Spark (مع Jupyter Notebook) وكتلة Cassandra. يمكن رؤية قائمة الخدمات باستخدام الأمر
kubectl get service :
~> kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d svc-cassandra311-seed-v24r6-0 NodePort 10.96.94.204 <none> 22:31131/TCP,9042:30739/TCP 3m svc-cassandra311-seed-v24r6-1 NodePort 10.106.144.52 <none> 22:30373/TCP,9042:32662/TCP 3m svc-cassandra311-vhh29 ClusterIP None <none> 8888/TCP 3m svc-cassandra311-worker-rqrhl-0 NodePort 10.109.61.194 <none> 22:31832/TCP,9042:31962/TCP 3m svc-cassandra311-worker-rqrhl-1 NodePort 10.97.147.131 <none> 22:31454/TCP,9042:31170/TCP 3m svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 24m svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 24m svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 24m svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 24m svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 24m
ملاحظة من المترجم
إذا كنت مهتمًا بمشروع KubeDirector ، يجب عليك أيضًا الانتباه إلى موقع
wiki الخاص به . لسوء الحظ ، لم يكن من الممكن العثور على خريطة طريق عامة ، ومع ذلك ، فإن
القضايا على GitHub تلقي الضوء على تطوير المشروع ووجهات نظر مطوريه الرئيسيين. بالإضافة إلى ذلك ، بالنسبة للمهتمين بـ KubeDirector ، يوفر المؤلفون روابط إلى
Slack chat و
Twitter .
اقرأ أيضا في مدونتنا: