أول شيء نواجهه عندما نتحدث عن التحسين الاستباقي هو أنه من غير المعروف ما يجب تحسينه. "افعل ذلك ، لا أعرف ماذا."
- لا توجد خوارزمية كلاسيكية.
- لم تظهر المشكلة بعد (غير معروفة) ، ولا يمكن للمرء إلا أن يخمن مكانها.
- نحتاج إلى إيجاد بعض نقاط الضعف المحتملة في النظام.
- حاول تحسين أداء الاستعلام في هذه الأماكن.
الأهداف الرئيسية للتحسين الاستباقي
تختلف المهام الرئيسية للتحسين الاستباقي عن مهام التحسين التفاعلي وهي كما يلي:
- التخلص من الاختناقات في قاعدة البيانات ؛
- انخفاض في استهلاك موارد قاعدة البيانات.
اللحظة الأخيرة هي الأكثر أساسية. في حالة التحسين التفاعلي ، ليس لدينا مهمة تقليل استهلاك الموارد ككل ، ولكن فقط مهمة جعل وقت استجابة الوظيفة ضمن الحدود المقبولة.
إذا كنت تعمل مع خوادم المعارك ، فلديك فكرة جيدة عما تعنيه حوادث الأداء. تحتاج إلى إنهاء كل شيء وحل المشكلة بسرعة. يعمل RNKO Payment Center LLC مع العديد من الوكلاء ، ومن المهم جدًا أن يواجهوا أقل عدد ممكن من المشاكل. أخبر ألكسندر ماكاروف من HighLoad ++ Siberia ما تم فعله لتقليل عدد حوادث الأداء بشكل ملحوظ. جاء التحسين الاستباقي للإنقاذ. ولماذا وكيف يتم إنتاجه على خادم قتالي ، اقرأ أدناه.
 حول المتحدث:
حول المتحدث: ألكسندر ماكاروف (
AL_IG_Makarov ) ، المدير الرائد لقاعدة بيانات أوراكل ، مركز الدفع RNCO LLC. على الرغم من الموقف ، هناك القليل جدًا من الإدارة على هذا النحو ، والمهام الرئيسية تتعلق بالحفاظ على المجمع وتطويره ، على وجه الخصوص ، حل مشاكل الأداء.
هل التحسين على قاعدة بيانات قتالية استباقية؟
أولاً ، سنتعامل مع المصطلحات التي يشير إليها هذا التقرير باسم "تحسين الأداء الاستباقي". في بعض الأحيان يمكنك تلبية وجهة النظر القائلة بأن التحسين الاستباقي هو عندما يتم تحليل مناطق المشكلة حتى قبل بدء تشغيل التطبيق. على سبيل المثال ، اكتشفنا أن بعض الاستعلامات لا تعمل على النحو الأمثل ، نظرًا لعدم وجود فهرس كافٍ أو أن الاستعلام يستخدم خوارزمية غير فعالة ، ويتم هذا العمل على خوادم الاختبار.
ومع ذلك ، قمنا في RNCO بهذا المشروع
على خوادم المعارك . سمعت عدة مرات: "كيف ذلك؟ أنت تفعل ذلك على خادم قتالي - وهذا يعني أنه ليس تحسينًا استباقيًا للأداء! " هنا نحتاج إلى التذكير بالنهج الذي يزرع في ITIL. من وجهة نظر ITIL ، لدينا:
- حوادث الأداء هي ما حدث بالفعل ؛
- الإجراءات التي نتخذها لمنع وقوع حوادث الأداء.
بهذا المعنى ، فإن أفعالنا استباقية. على الرغم من حقيقة أننا نحل المشكلة على خادم قتالي ، فإن المشكلة نفسها لم تظهر بعد: لم يقع الحادث ، ولم نركض ولم نحاول حل هذه المشكلة في وقت قصير.
لذا ، في هذا التقرير ، يُفهم
الاستباقية على أنها
استباقية بمعنى ITIL ، فنحن نحل المشكلة قبل وقوع حادث الأداء.
النقطة المرجعية
يخدم "مركز الدفع" في RNKO نظامين كبيرين:
- بنك التجزئة RBS ؛
- بنك CFT.
طبيعة الحمل على هذه الأنظمة مختلطة (DSS + OLTP): هناك شيء يعمل بسرعة كبيرة ، وهناك تقارير ، وهناك حمولات متوسطة.
نواجه حقيقة أنه ليس في كثير من الأحيان ، ولكن بتردد معين ، وقعت حوادث الأداء. يتخيل أولئك الذين يعملون مع خوادم المعركة ما هو. هذا يعني أنك بحاجة إلى إنهاء كل شيء وحل المشكلة بسرعة ، لأنه في الوقت الحالي لا يمكن للعميل تلقي الخدمة ، أو أن شيئًا ما لا يعمل على الإطلاق ، أو أنه يعمل ببطء شديد.
نظرًا لأن الكثير من الوكلاء والعملاء مرتبطون بمنظمتنا ، فهذا مهم جدًا بالنسبة لنا. إذا لم نتمكن من حل حوادث الأداء بسرعة ، فسوف يعاني عملائنا بطريقة أو بأخرى. على سبيل المثال ، لن يتمكنوا من تجديد البطاقة أو إجراء تحويل. لذلك ، تساءلنا عما يمكن فعله للتخلص حتى من حوادث الأداء النادرة هذه. للعمل في وضع عندما تحتاج إلى إسقاط كل شيء وحل مشكلة - هذا ليس صحيحًا تمامًا. نستخدم العدو ونرسم خطة عمل العدو. وجود حوادث الأداء هو أيضا انحراف عن خطة العمل.
شيء يجب القيام به مع هذا!
مناهج التحسين
فكرنا وفهمنا تكنولوجيا التحسين الاستباقي. ولكن قبل أن أتحدث عن التحسين الاستباقي ، يجب أن أقول بضع كلمات حول التحسين التفاعلي الكلاسيكي.
التحسين التفاعلي
السيناريو بسيط ، هناك خادم قتالي حدث فيه شيء: أطلقوا تقريرًا ، وتلقى العملاء بيانات ، وفي هذا الوقت يوجد نشاط مستمر في قاعدة البيانات ، وفجأة قرر شخص ما تحديث نوع من الدليل الضخم. يبدأ النظام في التباطؤ. في هذه اللحظة ، يأتي العميل ويقول: "لا يمكنني أن أفعل هذا أو ذاك" - نحتاج إلى إيجاد سبب يمنعه من القيام بذلك.
خوارزمية الإجراء الكلاسيكي:- أعد إظهار المشكلة.
- حدد مكان المشكلة.
- تحسين مكان المشكلة.
في إطار النهج التفاعلي ، فإن المهمة الرئيسية ليست مجرد العثور على السبب الجذري نفسه والقضاء عليه ، ولكن جعل النظام يعمل بشكل طبيعي. يمكن التعامل مع القضاء على السبب الجذري في وقت لاحق. الشيء الرئيسي هو استعادة الخادم بسرعة حتى يتمكن العميل من تلقي الخدمة.
الأهداف الرئيسية للتحسين التفاعلي
في التحسين التفاعلي ، يمكن تمييز هدفين رئيسيين:
1.
تقليل وقت الاستجابة .
يجب تنفيذ إجراء ، على سبيل المثال ، تلقي تقرير أو بيان أو معاملة لبعض الوقت المجدول. من الضروري التأكد من أن وقت تلقي الخدمة يعود إلى الحدود المقبولة للعميل. ربما تعمل الخدمة بشكل أبطأ قليلاً من المعتاد ، ولكن بالنسبة للعميل هذا مقبول. ثم نعتقد أنه تم القضاء على حادث الأداء ، ونبدأ في العمل على السبب الجذري.
2.
زيادة في عدد الكائنات المعالجة لكل وحدة زمنية أثناء المعالجة المجمعة .
عندما تكون المعالجة المجمعة للمعاملات قيد التقدم ، من الضروري تقليل وقت معالجة كائن واحد من الحزمة.
إيجابيات النهج التفاعلي:●
مجموعة متنوعة من الأدوات والتقنيات هي الميزة الرئيسية في النهج التفاعلي.
يمكننا استخدام أدوات المراقبة لفهم المشكلة مباشرة: لا يوجد ما يكفي من وحدة المعالجة المركزية ، أو مؤشرات الترابط ، أو الذاكرة ، أو انزلاق نظام القرص ، أو تتم معالجة السجلات ببطء. هناك الكثير من الأدوات والتقنيات لدراسة مشكلة الأداء الحالية في قاعدة بيانات أوراكل.
●
وقت الاستجابة المطلوب هو إضافة أخرى.
في عملية مثل هذا العمل ، نصل بالوضع إلى وقت استجابة مقبول ، أي أننا لا نحاول تقليله إلى الحد الأدنى للقيمة ، ولكننا نصل إلى قيمة معينة وبعد هذا الإجراء ننتهي ، لأننا نعتقد أننا وصلنا إلى حدود مقبولة.
سلبيات النهج التفاعلي:- تبقى حوادث الأداء - هذا هو أكبر ناقص للنهج التفاعلي ، لأننا لا نستطيع دائمًا الوصول إلى السبب الجذري. يمكنها البقاء في مكان ما بعيدًا عن الطريق والاستلقاء في مكان أعمق ، على الرغم من حقيقة أننا حققنا أداءً مقبولًا.
وكيف تتعامل مع حوادث الأداء إذا لم تحدث بعد؟ دعونا نحاول صياغة كيفية تنفيذ التحسين الاستباقي من أجل منع مثل هذه المواقف.
التحسين الاستباقي
أول شيء نواجهه هو أنه من غير المعروف ما يجب تحسينه. "افعل ذلك ، لا أعرف ماذا."
- لا توجد خوارزمية كلاسيكية.
- لم تظهر المشكلة بعد (غير معروفة) ، ولا يمكن للمرء إلا أن يخمن مكانها.
- نحتاج إلى إيجاد بعض نقاط الضعف المحتملة في النظام.
- حاول تحسين أداء الاستعلام في هذه الأماكن.
الأهداف الرئيسية للتحسين الاستباقي
تختلف المهام الرئيسية للتحسين الاستباقي عن مهام التحسين التفاعلي وهي كما يلي:
- التخلص من الاختناقات في قاعدة البيانات ؛
- انخفاض في استهلاك موارد قاعدة البيانات.
اللحظة الأخيرة هي الأكثر أساسية. في حالة التحسين التفاعلي ، ليس لدينا مهمة تقليل استهلاك الموارد ككل ، ولكن فقط مهمة جعل وقت استجابة الوظيفة ضمن الحدود المقبولة.
كيف تجد الاختناقات في قاعدة البيانات؟
عندما نبدأ في التفكير في هذه المشكلة ، تنشأ العديد من المهام الفرعية على الفور. من الضروري القيام بما يلي:
- اختبار وحدة المعالجة المركزية
- اختبار الحمل على القراءات / السجلات ؛
- اختبار الإجهاد بعدد الجلسات النشطة ؛
- اختبار الحمل على ... إلخ.
إذا حاولنا محاكاة هذه المشاكل في مجمع اختبار ، فقد نواجه حقيقة أن المشكلة التي نشأت على خادم الاختبار لا علاقة لها بالمشكلة القتالية. هناك العديد من الأسباب لذلك ، بدءًا من حقيقة أن خوادم الاختبار عادة ما تكون أضعف. حسنًا ، إذا كان من الممكن جعل خادم الاختبار نسخة طبق الأصل من النسخة القتالية ، ولكن هذا لا يضمن إعادة إنتاج الحمل بالطريقة نفسها ، لأنك تحتاج إلى إعادة إنتاج نشاط المستخدم بدقة والعديد من العوامل المختلفة التي تؤثر على الحمل النهائي. إذا حاولت محاكاة هذا الموقف ، فعندئذ بشكل عام ، لا أحد يضمن أن نفس الشيء سيحدث تمامًا والذي سيحدث على خادم المعركة.
إذا نشأت المشكلة في إحدى الحالات بسبب وصول سجل جديد ، فقد تنشأ في الحالة الأخرى لأن المستخدم أطلق تقريرًا ضخمًا يقوم بفرز كبير ، ونتيجة لذلك تمتلئ مساحة الجدول المؤقتة ، وكما ونتيجة لذلك ، بدأ النظام في التباطؤ. أي أن الأسباب يمكن أن تكون مختلفة ، وليس من الممكن دائمًا التنبؤ بها. لذلك ،
تخلينا عن محاولات البحث عن الاختناقات على خوادم الاختبار منذ البداية تقريبًا. اعتمدنا فقط على الخادم القتالي وما كان يحدث عليه.
ماذا تفعل في هذه الحالة؟ دعونا نحاول فهم الموارد التي من المرجح أن تفتقر إليها في المقام الأول.
تقليل استهلاك موارد قاعدة البيانات
استنادًا إلى المجمعات الصناعية المتوفرة لدينا ،
لوحظ نقص الموارد الأكثر شيوعًا في قراءات القرص ووحدات المعالجة المركزية . لذلك ، في المقام الأول ، سوف نبحث عن نقاط الضعف في هذه المجالات على وجه التحديد.
السؤال الثاني المهم: كيف تبحث عن شيء؟
السؤال غير تافه للغاية. نستخدم Oracle Enterprise Edition مع خيار حزمة التشخيص ووجدنا هذه الأداة لأنفسنا -
تقارير AWR (في إصدارات أخرى من Oracle يمكنك استخدام
تقارير STATSPACK ). في PostgreSQL يوجد تناظري - pgstatspack ، يوجد
pg_profile لأندري زوبكوف. المنتج الأخير ، كما أفهمه ، ظهر وبدأ في التطور في العام الماضي فقط. بالنسبة لـ MySQL ، لم أجد أدوات مماثلة ، لكني لست خبيرًا في MySQL.
لا يرتبط النهج نفسه بأي نوع معين من قواعد البيانات. إذا كان من الممكن الحصول على معلومات حول حمل النظام من بعض التقارير ، فعندئذٍ ، باستخدام التقنية التي سأتحدث عنها الآن ، يمكنك تنفيذ العمل على التحسين الاستباقي
على أي أساس .
تحسين أفضل 5 عمليات
تتكون تقنية التحسين الاستباقية التي طورناها ونستخدمها في مركز الدفع RNCO من أربع مراحل.
المرحلة 1. نتلقى تقرير AWR لأكبر فترة ممكنة.هناك حاجة لأطول فترة زمنية ممكنة لمتوسط الحمل في أيام مختلفة من الأسبوع ، لأنه في بعض الأحيان يكون مختلفًا جدًا. على سبيل المثال ، تصل سجلات الأسبوع الماضي إلى RBS-Retail Bank يوم الثلاثاء ، وتبدأ معالجتها ، واليوم كله لدينا حمولة أعلى من المتوسط بحوالي 2-3 مرات. في أيام أخرى ، يكون الحمل أقل.
إذا كان من المعروف أن النظام لديه بعض التفاصيل - في بعض الأيام يكون الحمل أكبر ، في بعض الأيام - أقل ، فأنت بحاجة إلى تلقي تقارير لهذه الفترات بشكل منفصل والعمل معها بشكل منفصل إذا أردنا تحسين فترات زمنية محددة . إذا كنت بحاجة إلى تحسين الوضع العام على الخادم ، يمكنك الحصول على تقرير كبير للشهر ، ومعرفة ما تستهلكه موارد الخادم فعليًا.
في بعض الأحيان تأتي المواقف غير المتوقعة للغاية. على سبيل المثال ، في حالة CFT Bank ، قد يكون الطلب الذي يتحقق من قائمة انتظار خادم التقارير في أعلى 10. علاوة على ذلك ، هذا الطلب رسمي ولا ينفذ أي منطق تجاري ، ولكنه يتحقق فقط مما إذا كان هناك تقرير عن التنفيذ أم لا.
المرحلة 2. ننظر الأقسام:- SQL مرتبة حسب الوقت المنقضي - استعلامات SQL مرتبة حسب وقت التشغيل ؛
- SQL مرتبة حسب CPU Time - لاستخدام CPU ؛
- SQL مرتبة بواسطة Gets - عن طريق القراءات المنطقية ؛
- SQL مرتبة حسب قراءات - للقراءات المادية.
تتم دراسة الأقسام المتبقية من SQL مرتبة حسب الحاجة.
المرحلة 3. نحدد العمليات الأم والطلبات التي تعتمد عليها.يحتوي تقرير AWR على أقسام منفصلة حيث ، بناءً على إصدار Oracle ، يتم عرض 15 أو أكثر من الاستعلامات في كل قسم من هذه الأقسام. لكن هذه الاستفسارات أوراكل في تقرير AWR يظهر فوضى.
على سبيل المثال ، هناك عملية أصل ، يمكن أن يوجد بداخلها 3 طلبات بحث رئيسية. ستعرض Oracle في تقرير AWR كلاً من العملية الرئيسية وجميع الاستعلامات الثلاثة هذه. لذلك ، تحتاج إلى إجراء تحليل لهذه القائمة ومعرفة العمليات التي تشير إليها الطلبات المحددة وتجميعها.
المرحلة 4. نقوم بتحسين أفضل 5 عمليات.بعد هذا التجميع ، يكون الإخراج عبارة عن قائمة بالعمليات التي يمكنك من خلالها تحديد الأكثر صعوبة. نحن مقيدون بـ 5 عمليات (ليس الطلبات ، أي العمليات). إذا كان النظام أكثر تعقيدًا ، فيمكنك أخذ المزيد.
أخطاء تصميم الاستعلام الشائعة
أثناء تطبيق هذه التقنية ، قمنا بتجميع قائمة صغيرة من أخطاء التصميم النموذجية. بعض الأخطاء بسيطة للغاية لدرجة أنها لا تبدو كذلك.
●
عدم وجود فهرس → مسح كاملهناك حالات عرضية للغاية ، على سبيل المثال ، مع عدم وجود فهرس على مخطط القتال. كان لدينا مثال ملموس حيث يعمل الاستعلام لفترة طويلة بسرعة بدون فهرس. ولكن كان هناك مسح كامل ، ومع نمو حجم الجدول تدريجيًا ، بدأ الاستعلام في العمل بشكل أبطأ ، ومن ربع إلى ربع استغرق الأمر وقتًا أطول قليلاً. في النهاية اهتمنا به واتضح أن الفهرس غير موجود.
●
اختيار كبير → مسح كاملالخطأ الشائع الثاني هو عينة بيانات كبيرة - الحالة الكلاسيكية للمسح الكامل. يعلم الجميع أنه يجب استخدام الفحص الكامل فقط عندما يكون مبررًا حقًا. في بعض الأحيان توجد حالات عندما يتم العثور على مسح كامل حيث يمكن الاستغناء عنه ، على سبيل المثال ، إذا قمت بنقل شروط التصفية من كود pl / sql إلى الاستعلام.
●
مؤشر غير فعال ← فحص نطاق مؤشر طويلربما يكون هذا هو الخطأ الأكثر شيوعًا ، والذي لسبب ما يقولون القليل جدًا - ما يسمى المؤشر غير الفعال (مسح الفهرس الطويل ، طويل المدى INDEX RANGE SCAN). على سبيل المثال ، لدينا جدول للسجلات. في الطلب ، نحاول العثور على جميع سجلات هذا الوكيل ، ونضيف في نهاية المطاف نوعًا من حالة التصفية ، على سبيل المثال ، لفترة معينة ، أو مع رقم معين ، أو عميل معين. في مثل هذه الحالات ، يتم بناء المؤشر عادة فقط على حقل "الوكيل" لأسباب عالمية الاستخدام. والنتيجة هي الصورة التالية: في السنة الأولى من العمل ، على سبيل المثال ، كان لدى الوكيل 100 إدخال في هذا الجدول ، في العام المقبل بالفعل 1000 ، في عام آخر قد يكون هناك 10000 إدخال. مع مرور الوقت ، تصبح هذه السجلات 100000. من الواضح أن الطلب يبدأ في العمل ببطء ، لأنه في الطلب تحتاج إلى إضافة ليس فقط معرف الوكيل نفسه ، ولكن أيضًا بعض المرشحات الإضافية ، في هذه الحالة حسب التاريخ. خلاف ذلك ، اتضح أن حجم العينة سيزداد من سنة إلى أخرى ، حيث يتزايد عدد السجلات لهذا الوكيل. يجب معالجة هذه المشكلة على مستوى الفهرس. إذا كان هناك الكثير من البيانات ، فيجب أن نفكر بالفعل في اتجاه التقسيم.
●
فروع رمز التوزيع غير الضروريةهذه أيضًا حالة غريبة ، لكنها مع ذلك تحدث. ننظر إلى أهم الاستعلامات ونرى بعض الاستفسارات الغريبة هناك. نأتي إلى المطورين ونقول: "وجدنا بعض الطلبات ، فلنكتشفها ونرى ما يمكن القيام به حيال ذلك". يفكر المطور ، ثم يأتي بعد فترة ويقول: "لا يجب أن يكون هذا الفرع من التعليمات البرمجية على نظامك. لا تستخدم هذه الوظيفة. " ثم يوصي المطور بتشغيل بعض الإعدادات الخاصة من أجل العمل حول هذا القسم من التعليمات البرمجية.
دراسات حالة
أود الآن أن أعتبر مثالين من ممارستنا الحقيقية. عندما نتعامل مع أهم الاستفسارات ، فإننا بالطبع نفكر أولاً في حقيقة أنه يجب أن يكون هناك شيء ضخم وغير تافه ، مع عمليات معقدة. في الواقع ، ليس هذا هو الحال دائمًا. في بعض الأحيان توجد حالات عندما تقع الاستعلامات البسيطة جدًا في العمليات العليا.
مثال 1
select * from (select o.* from rnko_dep_reestr_in_oper o where o.type_oper = 'proc' and o.ean_rnko in (select l.ean_rnko from rnko_dep_link l where l.s_rnko = :1) order by o.date_oper_bnk desc, o.date_reg desc) where ROWNUM = 1
في هذا المثال ، يتكون الاستعلام من جدولين فقط ، وهذه ليست جداول ثقيلة - فقط بضعة ملايين من السجلات. قد يبدو أسهل؟ ومع ذلك ، ضرب الطلب القمة.
دعونا نحاول معرفة ما هو الخطأ معه.
فيما يلي صورة من التحكم في سحابة Enterprise Manager - بيانات عن إحصائيات هذا الطلب (تمتلك Oracle مثل هذه الأداة). يمكن ملاحظة وجود حمولة منتظمة على هذا الطلب (الرسم البياني العلوي). يشير الرقم 1 على الجانب إلى أنه لا يوجد في المتوسط أكثر من جلسة واحدة قيد التشغيل. يوضح الرسم البياني الأخضر أن
الطلب يستخدم وحدة المعالجة المركزية فقط ، وهو أمر مثير للاهتمام على نحو مضاعف.

دعونا نحاول معرفة ما يحدث هنا؟

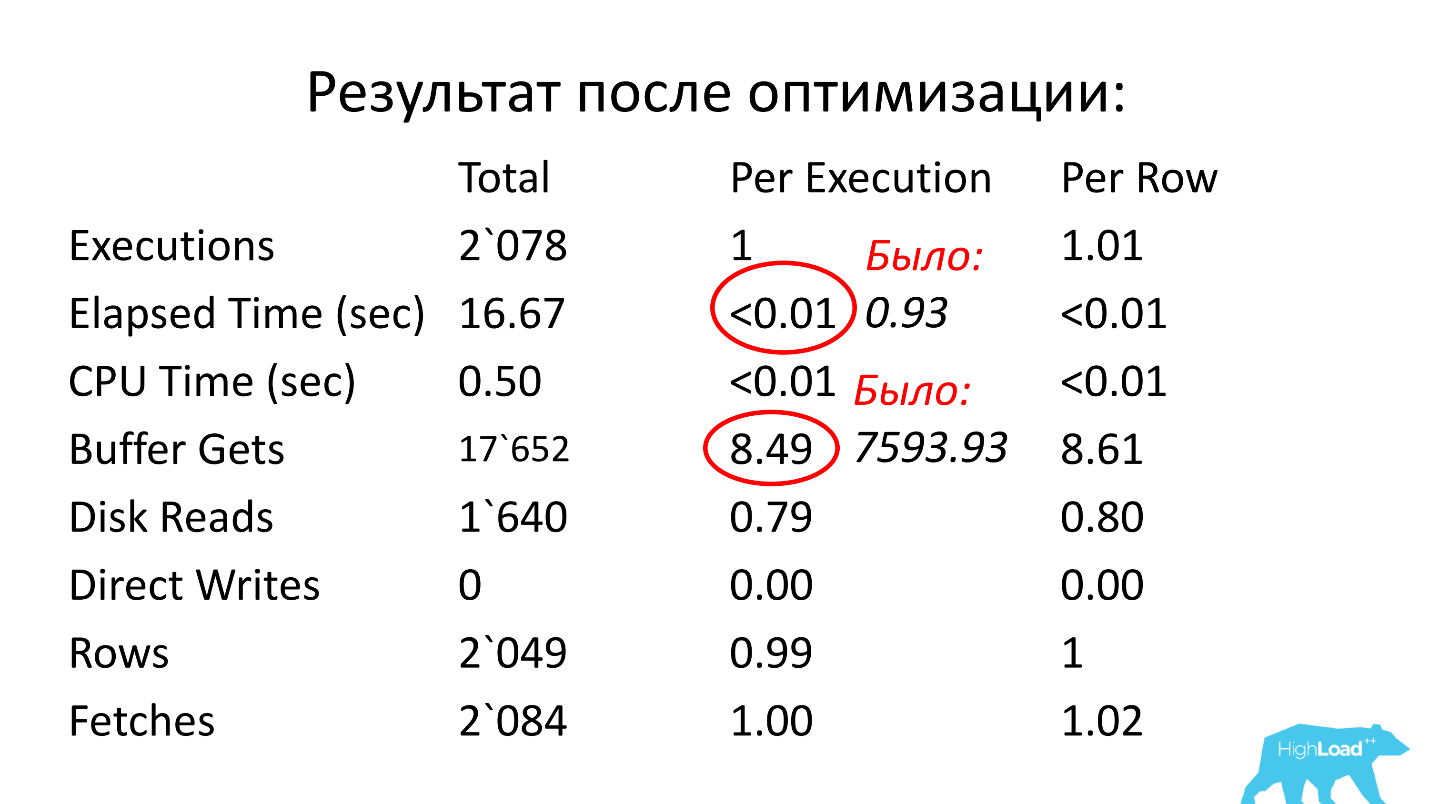
أعلاه جدول بإحصائيات عند الطلب. ما يقرب من 700 ألف عملية إطلاق - وهذا لن يفاجئ أي شخص. لكن الفاصل الزمني من وقت التحميل الأول في 15 ديسمبر إلى وقت التحميل الأخير في 22 ديسمبر (انظر الصورة السابقة) هو أسبوع واحد. إذا قمت بحساب عدد مرات البدء في الثانية ، فقد اتضح أن
الاستعلام يتم تنفيذه في المتوسط كل ثانية .
نحن ننظر إلى أبعد من ذلك. وقت تنفيذ الاستعلام 0.93 ثانية ، أي أقل من ثانية ، هذا رائع. يمكننا أن نفرح - الطلب ليس ثقيلاً. ومع ذلك ، وصل إلى القمة ، مما يعني أنه يستهلك الكثير من الموارد. أين تستهلك الكثير من الموارد؟
يحتوي الجدول على خط للقراءات المنطقية. نرى أنه بالنسبة لعملية إطلاق واحدة ، يحتاج الأمر إلى ما يقرب من 8 آلاف كتلة (عادةً يكون كتلة واحدة 8 كيلوبايت). اتضح أن الطلب ، الذي يعمل مرة واحدة في الثانية ، يحمل حوالي 64 ميغابايت من البيانات من الذاكرة. هناك خطأ ما هنا ، علينا أن نفهم.
دعونا نرى الخطة: هناك مسح كامل. حسنًا ، دعنا ننتقل.
Plan hash value: 634977963
في الجدول rnko_dep_reestr_in_oper ، هناك 5 ملايين صف فقط ومتوسط طول الصف 150 بايت. ولكن اتضح أنه لا يوجد فهرس كافٍ للحقل الذي يتم الاتصال به - حيث يرتبط الاستعلام الفرعي بالطلب من خلال حقل ean_rnko ، الذي لا يوجد فهرس له!
علاوة على ذلك ، حتى لو ظهر ، في الواقع لن يكون الوضع جيدًا جدًا. سيحدث هذا المسح الضوئي للفهرس الطويل (فحص نطاق INDEX RANGE الطويل). ean_rnko هو المعرف الداخلي للوكيل. سوف تتراكم سجلات الوكيل ، وستزداد كمية البيانات التي سيختارها هذا الطلب كل عام ، وسيتباطأ الطلب.
الحل: قم بإنشاء فهرس لحقول ean_rnko و date_reg ، اطلب من المطورين تحديد عمق المسح حسب التاريخ في هذا الطلب. ثم يمكنك على الأقل ضمان أن أداء الاستعلام سيظل تقريبًا عند نفس الحدود ، نظرًا لأن حجم العينة سيقتصر على فاصل زمني ثابت ، ولن يحتاج الجدول بأكمله إلى القراءة. هذه نقطة مهمة جدا ، انظر ماذا حدث.
بعد التحسين ، أصبح وقت التشغيل أقل من مائة من الثانية (كان 0.93) ، وأصبح عدد الكتل في المتوسط 8.5 - 1000 مرة أقل من ذي قبل.
مثال 2
select count(1) from loy$barcodes t where t.id_processing = :b1 and t.id_rec_out is null and not t.barcode is null and t.status = 'u' and not t.id_card is null
لقد بدأت القصة بالقول أنه عادة ما يتوقع شيء معقد في أعلى الاستعلام. أعلاه هو مثال على استعلام "معقد" ينتقل إلى جدول واحد (!) ، كما تم إدخاله في أهم الاستعلامات :) يوجد فهرس في حقل ID_PROCESSING!
هناك 3 شروط IS NULL في هذا الاستعلام ، وكما نعلم ، فإن هذه الشروط غير مفهرسة (لا يمكنك استخدام الفهرس في هذه الحالة). بالإضافة إلى ذلك ، هناك شرطان فقط لنوع المساواة (عن طريق ID_PROCESSING و STATUS).
على الأرجح ، المطور الذي سيطلع على هذا الاستعلام ، أولاً سيقترح إنشاء فهرس على ID_PROCESSING و STATUS. ولكن بالنظر إلى كمية البيانات التي سيتم اختيارها (سيكون هناك الكثير منها) ، فإن هذا الحل لا يعمل.
ومع ذلك ، يستهلك الطلب الكثير من الموارد ، مما يعني أنه يجب القيام بشيء ما لجعله يعمل بشكل أسرع. دعونا نحاول معرفة الأسباب.

الإحصائيات المذكورة أعلاه هي ليوم واحد ، يمكن من خلالها ملاحظة أن الطلب يتم إطلاقه كل 5 دقائق. استهلاك الموارد الرئيسي هو قراءة وحدة المعالجة المركزية والقرص. أدناه على الرسم البياني مع إحصائيات عدد بدايات الاستعلام ، يمكن ملاحظة أن كل شيء على ما يرام - لا يتغير عدد مرات البدء تقريبًا بمرور الوقت - وهو وضع مستقر إلى حد ما.

وإذا نظرت إلى أبعد من ذلك ، يمكنك أن ترى أن وقت الاستعلام يختلف أحيانًا كثيرًا - عدة مرات ، وهو أمر مهم بالفعل.
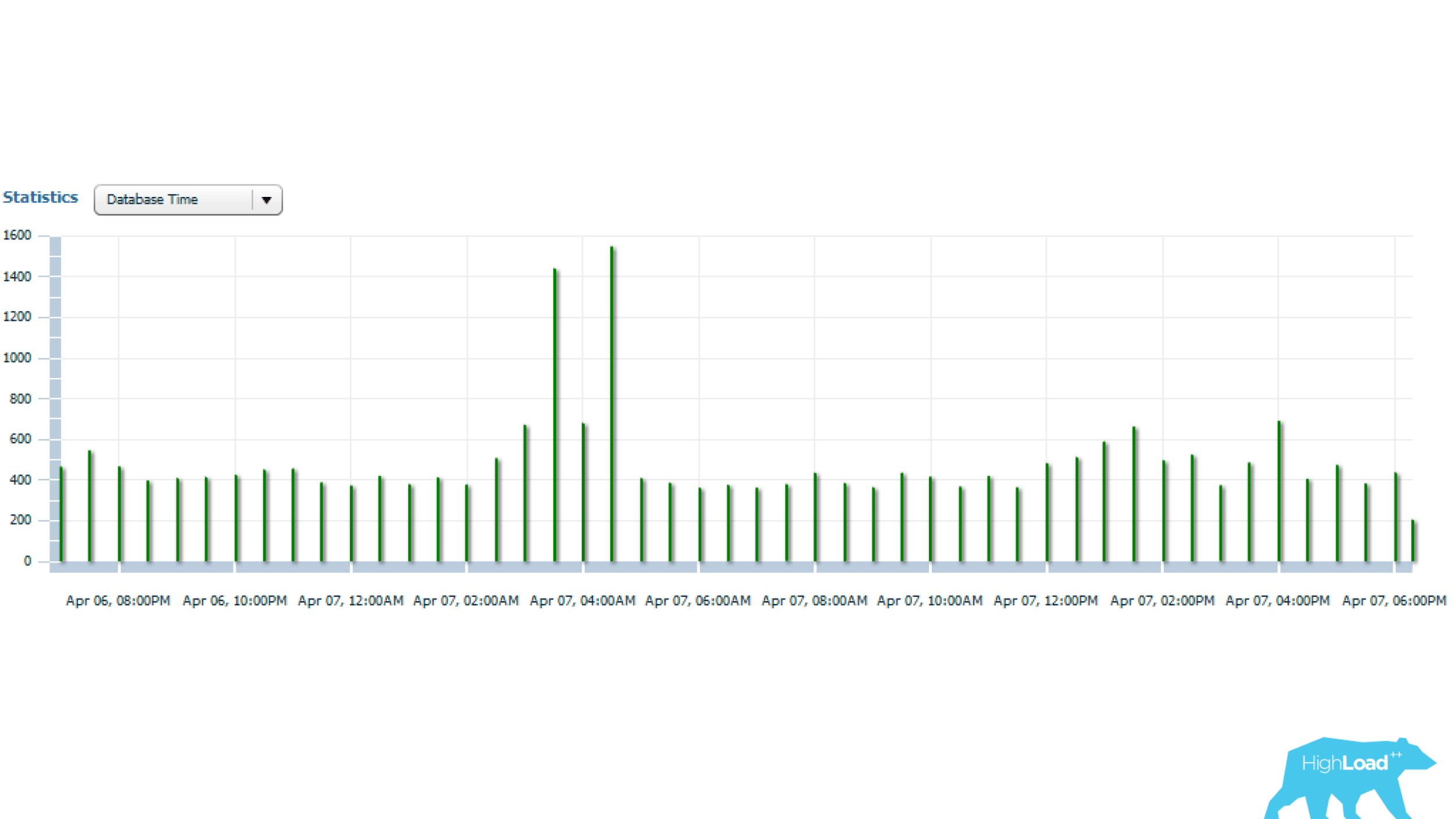
دعونا نكتشف ذلك بعد ذلك.
يحتوي Oracle Enterprise Manager على أداة مساعدة لمراقبة SQL. مع هذه الأداة يمكنك أن ترى في الوقت الحقيقي استهلاك الموارد حسب الطلب.

أعلاه تقرير لطلب إشكالية. بادئ ذي بدء ، يجب أن نهتم بحقيقة أن INDEX RANGE SCAN (الخط السفلي) في العمود Actual Rows يعرض 17 مليون سطر. ربما يستحق النظر.
إذا نظرنا إلى خطة التنفيذ أكثر ، اتضح أنه بعد البند التالي في الخطة ، من أصل 17 مليون خط ، يبقى 1705 فقط. والسؤال هو ، لماذا تم اختيار 17 مليون؟ بقي حوالي 0.01 ٪ في العينة النهائية ، أي أنه من
الواضح أنه غير فعال ، تم إنجاز عمل غير ضروري . علاوة على ذلك ، يتم هذا العمل كل 5 دقائق. هنا تكمن المشكلة! لذلك ، وصل هذا الطلب إلى أهم الاستعلامات.
دعونا نحاول حل هذه المشكلة غير التافهة. المؤشر الذي يطرح نفسه في المقام الأول غير فعال ، لذلك تحتاج إلى التوصل إلى شيء صعب وهزيمة شروط IS NULL.
فهرس جديد
لقد تشاورنا مع المطورين ، وفكرنا ، وتوصلنا إلى هذا القرار: قمنا بعمل فهرس وظيفي يوجد فيه عمود ID_PROCESSING ، والذي كان مع حالة المساواة في الطلب ، وأدرجنا جميع الحقول الأخرى كحجج لهذه الوظيفة:
create index gc.loy$barcod_unload_i on gc.loy$barcodes (gc.loy_barcodes_ic_unload(id_rec_out, barcode, id_card, status), id_processing); function loy_barcodes_ic_unload( pIdRecOut in loy$barcodes.id_rec_out%type, pBarcode in loy$barcodes.barcode%type, pIdCard in loy$barcodes.id_card%type, pStatus in loy$barcodes.status%type) return varchar2 deterministic is vRes varchar2(1) := ''; begin if pIdRecOut is null and pBarcode is not null and pIdCard is not null and pStatus = 'U' then vRes := pStatus; end if; return vRes; end loy_barcodes_ic_unload;
هذه الوظيفة حتمية من النوع ، أي أنها ، على نفس مجموعة المعلمات ، تعطي دائمًا نفس الإجابة. تأكدنا من أن هذه الوظيفة دائمًا ما تُرجع قيمة واحدة - في هذه الحالة "U". عندما يتم استيفاء جميع هذه الشروط ، يتم إصدار "U" ، عندما لا يتم استيفائها - NULL. مثل هذا المؤشر الوظيفي يجعل من الممكن تصفية البيانات بشكل فعال.
أدى تطبيق هذا المؤشر إلى النتيجة التالية:
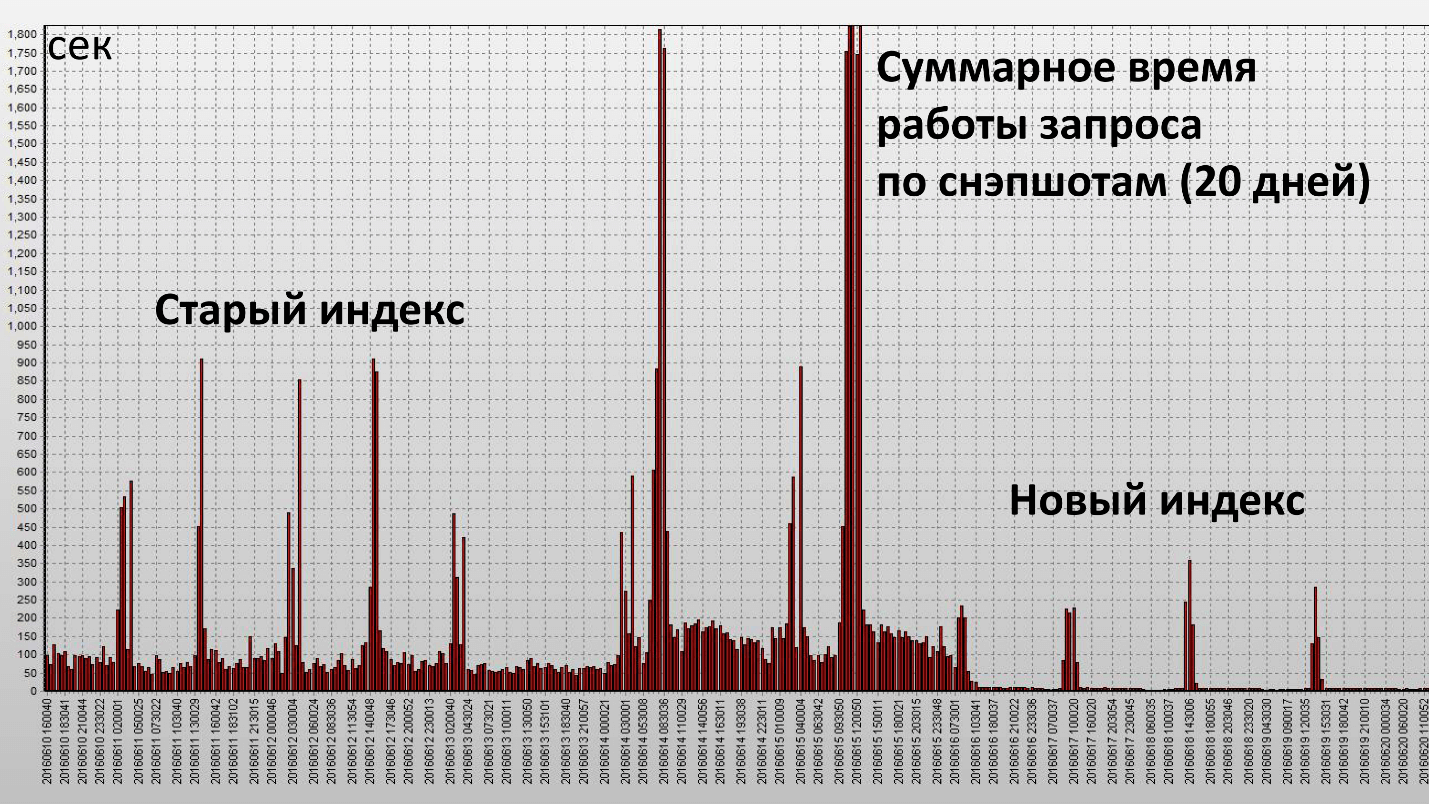
هنا ، عمود واحد هو لقطة واحدة ، ويتم كل نصف ساعة من قاعدة البيانات. لقد حققنا هدفنا وكان هذا المؤشر فعالاً حقًا. دعونا نرى الخصائص الكمية:
متوسط إحصائيات الطلب
|
| من قبل
| بعد
|
الوقت المنقضي ، ثانية
| 143.21
| 60.7
|
وقت وحدة المعالجة المركزية ، ثانية
| 33.23
| 45.38
|
العازلة يحصل على كتلة
| 62888`237.67
| 1`589`836
|
قرص يقرأ كتلة
| 266`600.33
| 2`680
|
انخفض وقت التشغيل بمقدار 2.5 مرة ، واستهلاك الموارد (Buffer Gets) - بحوالي 4. انخفض عدد كتل البيانات التي تم قراءتها من القرص بشكل ملحوظ.
نتائج التحسين الاستباقي
لقد تلقينا:
- تقليل الحمل على قاعدة البيانات ؛
- تحسين استقرار قاعدة البيانات ؛
- انخفاض كبير في عدد حوادث أداء البرمجيات.
انخفضت حوادث الأداء بنسبة 10 مرات . هذا مبلغ ذاتي ، قبل وقوع الأحداث في مجمع RBS-Retail Bank 1-2 مرات في الشهر ، لكننا الآن نسيناهم عمليًا.
هذا يثير السؤال - ماذا عن حوادث أداء البرنامج؟ لم نتعامل معهم بشكل مباشر؟
العودة إلى الجدول الأخير. إذا كنت تتذكر ، كان هناك مسح كامل ، كان مطلوبًا تخزين عدد كبير من الكتل في الذاكرة. منذ تنفيذ الطلب بانتظام ، تم تخزين جميع هذه الكتل في ذاكرة التخزين المؤقت لـ Oracle. اتضح أنه إذا حدث في هذا الوقت حمولة عالية في قاعدة البيانات ، على سبيل المثال ، بدأ شخص ما في استخدام الذاكرة بنشاط ، فستحتاج إلى ذاكرة تخزين مؤقت لتخزين كتل البيانات. وبالتالي ، سيتم ازدحام جزء من بيانات طلبنا ، مما يعني أنه سيتعين علينا القيام بقراءات مادية. إذا أجريت قراءات مادية ، فسيزداد وقت تشغيل الاستعلام بشكل كبير.
تعمل القراءة المنطقية مع الذاكرة ، وتحدث بسرعة ، ويكون أي وصول إلى القرص بطيئًا (إذا نظرت إلى الوقت ، بالمللي ثانية). إذا كنت محظوظًا ، وهناك هذه البيانات في ذاكرة التخزين المؤقت لنظام التشغيل أو في ذاكرة التخزين المؤقت للمصفوفة ، فستظل عشرات الميكرو ثانية. القراءة من ذاكرة التخزين المؤقت لـ Oracle أسرع بكثير.
عندما تخلصنا من الفحص الكامل ، اختفت الحاجة إلى تخزين هذا العدد الكبير من الكتل في ذاكرة التخزين المؤقت (ذاكرة التخزين المؤقت العازلة). عندما يكون هناك نقص في هذه الموارد ، يكون الطلب أكثر أو أقل استقرارًا. لم تعد هناك مثل هذه المسامير الكبيرة التي كانت مع المؤشر القديم.
ملخص التحسين الاستباقي:- يجب إجراء تحسين الاستعلام الأولي على خوادم الاختبار ، لمعرفة كيفية عمل الاستعلامات ومنطق عملهم ، حتى لا تفعل أي شيء غير ضروري. هذه الأعمال باقية.
- ولكن بشكل دوري ، مرة كل بضعة أشهر ، من المنطقي إزالة التقارير عن التحميل الكامل من الخادم ، وإجراء بحث عن أهم الاستعلامات والعمليات في قاعدة البيانات وتحسينها.
هناك العديد من الأدوات للحصول على الإحصائيات في قاعدة بيانات أوراكل:- تقرير AWR (DBMS_WORKLOAD_REPOSITORY.awr_report_html) ؛
- Enterprise Manager Cloud Control 12c (تفاصيل SQL) ؛
- التقرير النشط لتفاصيل SQL (DBMS_PERF.report_sql) ؛
- مراقبة SQL (علامة التبويب في EMCC) ؛
- تقرير مراقبة SQL (DBMS_SQLTUNE.report_sql_monitor *).
تعمل بعض هذه الأدوات في وحدة التحكم ، أي أنها غير مرتبطة بـ Enterprise Manager.
أمثلة على أدوات أوراكل لجمع الإحصائيات المكافأة: تم إعداد المتخصصين في RNCO "مركز الدفع" و CFT بشكل جيد للمؤتمر في نوفوسيبيرسك ، وقدموا بعض التقارير المفيدة ، ونظموا أيضًا راديو خروج حقيقي. لمدة يومين ، تمكن الخبراء والمتحدثون والمنظمون من زيارة راديو CFT. يمكنك العودة إلى الصيف في سيبيريا من خلال تضمين الإدخالات ، وهنا الروابط إلى الكتل:
Kubernetes: إيجابيات وسلبيات ؛
علوم البيانات وتعلم الآلة ؛
DevOps .
في HighLoad ++ في موسكو ، وهو بالفعل 8 و 9 نوفمبر ، سيكون هناك أشياء أكثر إثارة للاهتمام. يتضمن البرنامج تقارير عن جميع جوانب العمل في المشاريع المحملة بشكل كبير ، والفصول الرئيسية ، والاجتماعات والأحداث من الشركاء الذين سيتبادلون نصائح الخبراء ويجدون شيئًا مفاجئًا. تأكد من الكتابة عن الأكثر إثارة للاهتمام وإخطار في النشرة الإخبارية ، تواصل!