بناء توجيه العميل / البحث الدلالي وتجميع المجموعات الخارجية التعسفية في Profi.ru
TLDR
هذا ملخص تنفيذي قصير جدًا (أو دعابة) حول ما تمكنا من القيام به في شهرين تقريبًا في قسم Profi.ru DS (لقد كنت هناك لفترة أطول قليلاً ، ولكن كنت أركب نفسي وفريقي شيء منفصل القيام به في البداية).
الأهداف المتوقعة
- فهم مدخلات العميل / نية العملاء وتوجيه العملاء وفقًا لذلك (اخترنا المصنف الملحد لجودة المدخلات في النهاية ، على الرغم من أننا قد أخذنا في الاعتبار نماذج مستوى الحروف ونماذج اللغة المستقبلية أيضًا. قواعد البساطة) ؛
- البحث عن خدمات ومرادفات جديدة تمامًا للخدمات الموجودة ؛
- كهدف فرعي لـ (2) - تعلم بناء مجموعات مناسبة على الجثث الخارجية التعسفية ؛
الأهداف المحققة
من الواضح أن بعض هذه النتائج لم يتم تحقيقها من قبل فريقنا فحسب ، ولكن من خلال العديد من الفرق (أي من الواضح أننا لم نقم بجزء الاستغناء عن مجموعات المجال والتعليق التوضيحي اليدوي ، على الرغم من أنني أعتقد أنه يمكن أيضًا حل الكشط بواسطة فريقنا - ما عليك سوى ما يكفي من وكلاء + ربما بعض الخبرة مع السيلينيوم).
أهداف العمل:
- ~
88+% (مقابل ~ 60% مع بحث مرن) الدقة في تصنيف توجيه العميل / نية العميل (فئات 5k ) ؛ - البحث غير ملائم لجودة المدخلات (الأخطاء المطبعية / الإدخال الجزئي) ؛
- يصنف المصنف ، يتم استغلال البنية الصرفية للغة ؛
- المصنف يتفوق بشدة على البحث المرن على مختلف المعايير (انظر أدناه) ؛
- لتكون في الجانب الآمن - تم العثور على
1,000 خدمة جديدة على الأقل + 15,000 مرادف على الأقل (مقابل الحالة الحالية 5,000 + ~ 30,000 ). أتوقع أن يتضاعف هذا الرقم إلى ثلاثة أضعاف ؛
الرصاصة الأخيرة هي تقدير ملاعب ، لكنها محافظة.
كما ستتبع اختبارات AB. لكني واثق في هذه النتائج.
الأهداف "العلمية":
- قارنا بدقة العديد من تقنيات تضمين الجمل الحديثة باستخدام مهمة تصنيف المصب + KNN مع قاعدة بيانات من مرادفات الخدمة ؛
- تمكنا من التغلب على ضعف الإشراف (بشكل أساسي مصنفهم هو كيس من ngrams) بحث مرن على هذا المعيار (انظر التفاصيل أدناه) باستخدام طرق UNSUPERVISED ؛
- لقد طورنا طريقة جديدة لبناء نماذج البرمجة اللغوية العصبية التطبيقية (حقيبة الفانيلا العادية ثنائية LSTM + من التضمين ، يلتقي النص السريع بشكل أساسي مع RNN) - وهذا يأخذ شكل اللغة الروسية في الاعتبار ويعمم بشكل جيد ؛
- أثبتنا أن تقنية التضمين النهائية (طبقة عنق الزجاجة من أفضل المصنف) مقترنة بخوارزميات غير خاضعة للرقابة (UMAP + HDBSCAN) يمكن أن تنتج مجموعات نجمي ؛
- لقد أثبتنا في الممارسة إمكانية وجدوى وسهولة الاستخدام:
- تقطير المعرفة
- زيادة البيانات النصية (كذا!) ؛
- خفض تدريب المصنفات القائمة على النص مع التعزيزات الديناميكية وقت التقارب بشكل كبير (10x) مقارنة بتوليد مجموعات بيانات ثابتة أكبر (أي أن CNN تتعلم تعميم الخطأ الذي يتم عرضه جملًا أقل زيادة بشكل كبير) ؛
الهيكل العام للمشروع
هذا لا يشمل المصنف النهائي.
أيضا في النهاية تخلينا عن نماذج RNN المزيفة وخسارة ثلاثية لصالح اختناق المصنف.

ما الذي يعمل في البرمجة اللغوية العصبية الآن؟
نظرة عين الطيور:

قد تعلم أيضًا أن البرمجة اللغوية العصبية قد تواجه لحظة Imagenet الآن .
اختراق UMAP واسع النطاق
عند إنشاء مجموعات ، تعثرنا على طريقة / اختراق لتطبيق UMAP بشكل أساسي على مجموعات بيانات بحجم 100 م + نقطة (أو حتى 1 مليار). بشكل أساسي ، قم بإنشاء رسم بياني لـ KNN باستخدام FAISS ، ثم أعد كتابة حلقة UMAP الرئيسية في PyTorch باستخدام GPU. لم نكن بحاجة إلى ذلك وتخلوا عن المفهوم (كان لدينا 10-15 مليون نقطة فقط بعد كل شيء) ، ولكن يرجى اتباع هذا الموضوع للحصول على التفاصيل.
ما يعمل بشكل أفضل
- بالنسبة للتصنيف الخاضع للإشراف ، يلبي النص السريع RNN (bi-LSTM) + مجموعة مختارة من n-grams بعناية ؛
- التنفيذ - الثعبان العادي ل n-grams + طبقة حقيبة تضمين PyTorch ؛
- للتجميع - طبقة عنق الزجاجة لهذا النموذج + UMAP + HDBSCAN ؛
أفضل معايير التصنيف
مجموعة مطور تعليقات يدوية يدويًا
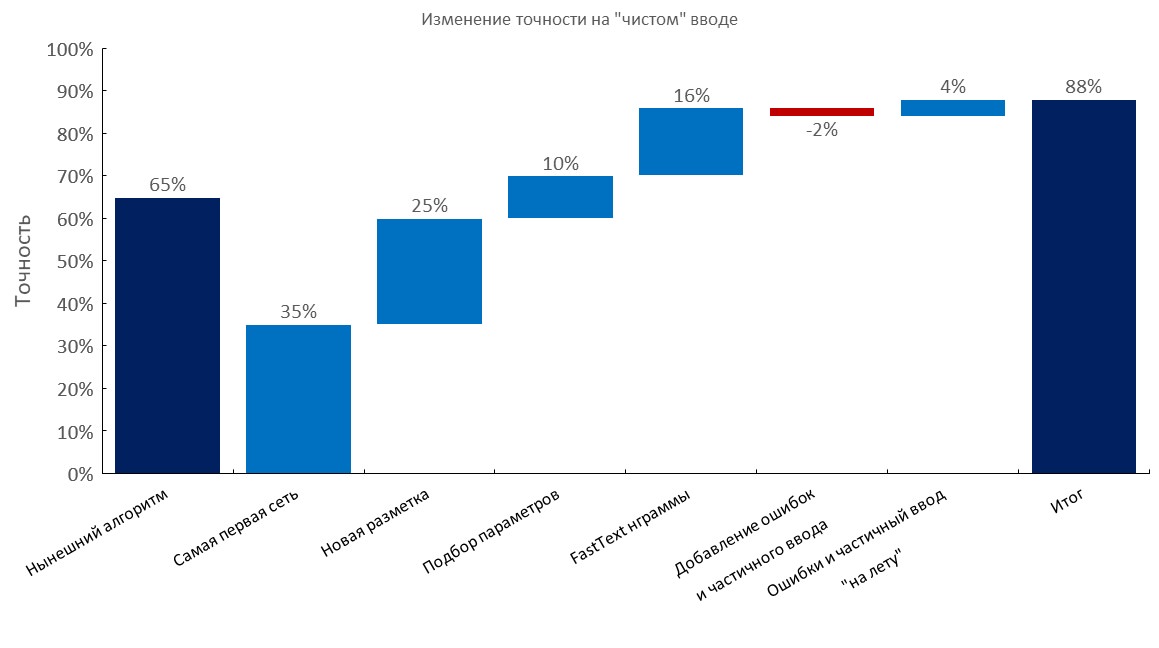
من اليسار لليمين:
(دقة Top1)
- الخوارزمية الحالية (بحث مرن) ؛
- أول RNN ؛
- تعليق توضيحي جديد ؛
- الضبط
- طبقة حقيبة تضمين النص السريع ؛
- إضافة أخطاء إملائية وإدخال جزئي ؛
- التوليد الديناميكي للأخطاء والمدخلات الجزئية (تم تقليل وقت التدريب 10x ) ؛
- النتيجة النهائية ؛
مجموعة مطور عليها تعليقات توضيحية يدويًا + 1-3 أخطاء لكل طلب بحث

من اليسار لليمين:
(دقة Top1)
- الخوارزمية الحالية (بحث مرن) ؛
- طبقة حقيبة تضمين النص السريع ؛
- إضافة أخطاء إملائية وإدخال جزئي ؛
- التوليد الديناميكي للأخطاء والمدخلات الجزئية ؛
- النتيجة النهائية ؛
مجموعة مطور تعليقات يدويًا + إدخال جزئي
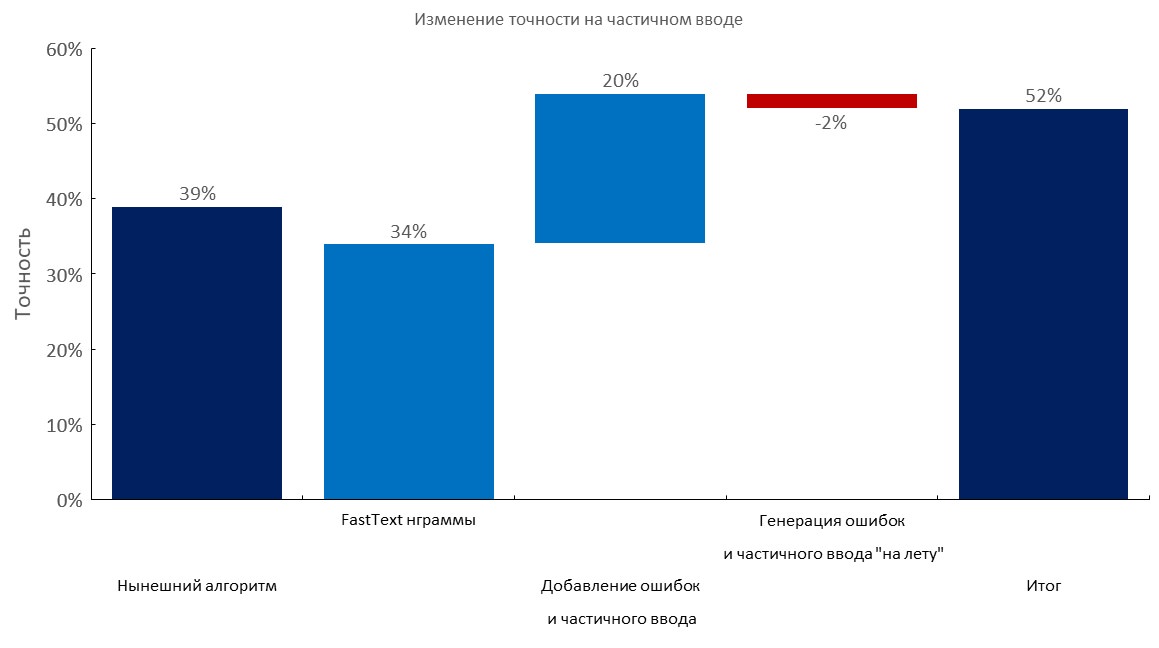
من اليسار لليمين:
(دقة Top1)
- الخوارزمية الحالية (بحث مرن) ؛
- طبقة حقيبة تضمين النص السريع ؛
- إضافة أخطاء إملائية وإدخال جزئي ؛
- التوليد الديناميكي للأخطاء والمدخلات الجزئية ؛
- النتيجة النهائية ؛
اختيار الجثث على نطاق واسع / ن غرام
- جمعنا أكبر الجثث للغة الروسية:
- قمنا بتجميع قاموس الكلمات
100m باستخدام زحف 1TB ؛ - استخدم أيضًا هذا الاختراق لتنزيل هذه الملفات بشكل أسرع (بين عشية وضحاها) ؛
- لقد اخترنا مجموعة مثالية من
1m n-grams 500k لتعميم الأفضل ( 500k n-grams الأكثر شيوعًا من النص السريع المدربين على Wikipedia الروسية + 500k n-grams الأكثر شيوعًا على بيانات المجال) ؛
اختبار الإجهاد لمليون غرام في المفردات 100 مليون:

تكبير النص
باختصار:
- خذ قاموسًا كبيرًا به أخطاء (مثل 10-100 متر من الكلمات الفريدة) ؛
- إنشاء خطأ (إسقاط حرف ، تبديل حرف باستخدام الاحتمالات المحسوبة ، إدراج حرف عشوائي ، ربما استخدام تخطيط لوحة المفاتيح ، إلخ) ؛
- تحقق من وجود كلمة جديدة في القاموس ؛
لقد أجبرنا الكثير من الاستفسارات على خدمات مثل هذه (في محاولة لإجراء هندسة عكسية لمجموعة البيانات الخاصة بهم) ، ولديهم قاموس صغير جدًا في الداخل (كما أن هذه الخدمة مدعومة بمصنف شجرة بميزات n-gram). كان من المضحك نوعًا ما أن نرى أنها غطت 30-50٪ فقط من الكلمات التي لدينا في بعض الجثث .
نهجنا هو أعلى بكثير ، إذا كان لديك حق الوصول إلى مفردات نطاق كبير .
أفضل النتائج غير الخاضعة للرقابة / شبه الخاضعة للإشراف
يستخدم KNN كمعيار لمقارنة طرق التضمين المختلفة.
(حجم المتجه) قائمة النماذج المختبرة:
- (512) تم تدريب كاشف الجمل المزيفة على نطاق واسع على 200 غيغابايت من بيانات الزحف الشائعة ؛
- (300) كاشف جملة مزيف تم تدريبه على إخبار جملة عشوائية من ويكيبيديا من خدمة ؛
- (300) نص سريع تم الحصول عليه من هنا ، تم تدريبه مسبقًا على جسد أرنيوم ؛
- (200) تم تدريب النص السريع على بيانات المجال الخاصة بنا ؛
- (300) تم تدريب النص السريع على 200 جيجابايت من بيانات الزحف الشائعة ؛
- (300) شبكة سيامية مع فقدان ثلاثي مدربة بالخدمات / المرادفات / جمل عشوائية من ويكيبيديا ؛
- (200) التكرار الأول لطبقة التضمين لحقيبة التضمين RNN ، يتم تشفير الجملة كحقيبة كاملة من التضمين ؛
- (200) نفس الشيء ، ولكن يتم أولاً تقسيم الجملة إلى كلمات ، ثم يتم تضمين كل كلمة ، ثم يتم أخذ المتوسط ؛
- (300) نفس ما ورد أعلاه ولكن للنموذج النهائي ؛
- (300) نفس ما ورد أعلاه ولكن للنموذج النهائي ؛
- (250) طبقة عنق الزجاجة للنموذج النهائي (250 خلية عصبية) ؛
- خط أساس للبحث المرن ضعيف الإشراف ؛
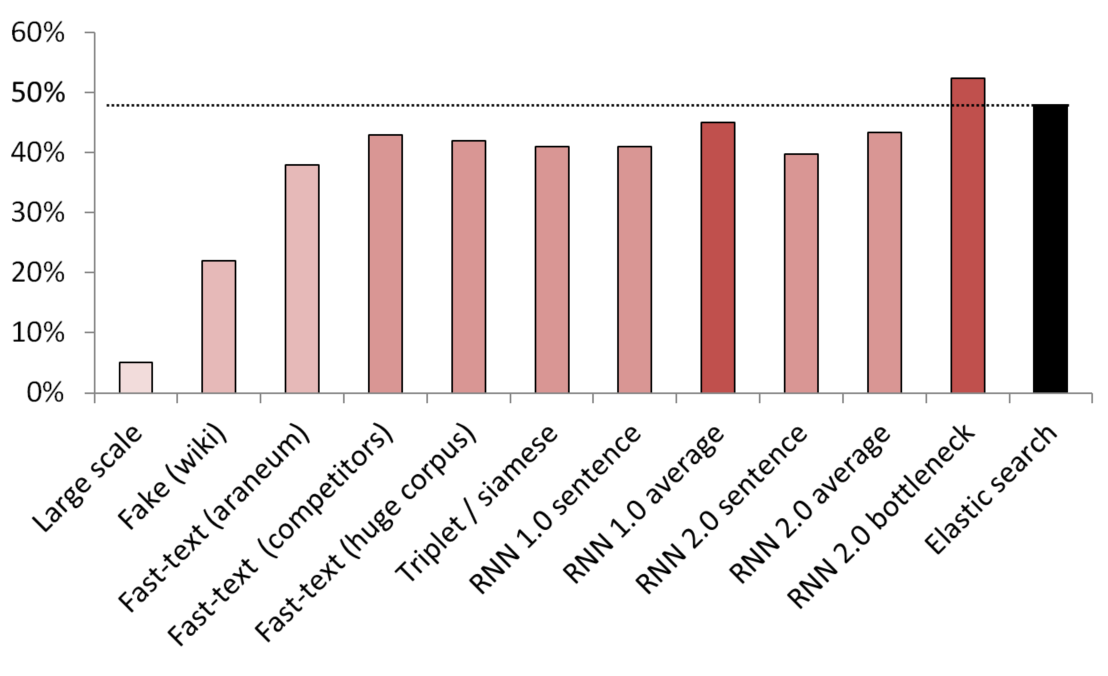
لتجنب التسريبات ، تم أخذ جميع الجمل العشوائية بشكل عشوائي. كان طولهم في الكلمات هو نفس طول الخدمات / المرادفات التي تمت مقارنتها معهم. كما تم اتخاذ تدابير للتأكد من أن النماذج لم تتعلم فقط عن طريق فصل المفردات (تم تجميد التضمين ، تم وضع Wikipedia في شكل غير دقيق للتأكد من وجود كلمة مجال واحدة على الأقل في كل جملة Wikipedia).
التصور العنقودي
ثلاثي الأبعاد

ثنائي الأبعاد

استكشاف الواجهة "الواجهة"
الأخضر - كلمة / مرادف جديدة.
خلفية رمادية - كلمة جديدة محتملة.
نص رمادي - مرادف موجود.

اختبارات الاجتثاث وما يصلح وما جربناه وما لم نجربه
- انظر الرسوم البيانية أعلاه ؛
- المتوسط البسيط / المتوسط tf-idf لتضمين النص السريع - خط أساس هائل جدًا ؛
- Fast-text> Word2Vec للروسية ؛
- تضمين الجملة من خلال نوع من أعمال الكشف عن الجمل المزيفة ، ولكنها تتضاءل بالمقارنة مع الطرق الأخرى ؛
- أظهر BPE (جملة) أي تحسن في مجالنا.
- كافحت نماذج مستوى شار للتعميم ، على الرغم من الورقة الأخيرة من جوجل.
- لقد جربنا المحولات متعددة الرؤوس (مع رؤوس المصنف ونمذجة اللغة) ، ولكن في التعليق التوضيحي المتوفر في متناول اليد ، كان أداؤه تقريبًا مثل الموديلات المستندة إلى الفانيليا العادية. عندما انتقلنا إلى تضمين مناهج سيئة ، تخلينا عن هذا الخط من البحث بسبب انخفاض التطبيق العملي وعدم قابلية وجود رأس LM جنبًا إلى جنب مع طبقة حقيبة التضمين ؛
- BERT - يبدو أنه مبالغة ، كما يدعي بعض الأشخاص أن المحولات تتدرب حرفياً لأسابيع ؛
- ELMO - يبدو أن استخدام مكتبة مثل AllenNLP غير مثمر في رأيي في بيئات البحث / الإنتاج والتعليم لأسباب لن أقوم بتقديمها هنا ؛
انشر
تم باستخدام:
- حاوية Docker مع خدمة ويب بسيطة ؛
- وحدة المعالجة المركزية فقط للاستدلال كافية ؛
- ~
2.5 ms لكل استعلام على وحدة المعالجة المركزية ، الدفعة ليست ضرورية حقًا ؛ - ~ ذاكرة RAM
1GB ؛ - لا توجد تبعيات تقريبًا ، باستثناء
PyTorch و numpy و numpy (وخادم الويب الخاص بـ c). - قم بتقليد توليد n-gram سريع النص مثل هذا ؛
- تضمين طبقة حقيبة + فهارس كما تم تخزينها للتو في القاموس ؛