في الخدمات الكبيرة ، فإن حل مشكلة باستخدام التعلم الآلي يعني القيام بجزء فقط من العمل. إن تضمين نماذج ML ليس بهذه السهولة ، كما أن بناء عمليات CI / CD من حولهم أكثر صعوبة. في مؤتمر Yandex
"البيانات والعلوم: برنامج التطبيق" ، تحدث آدم إلداروف
، رئيس علم البيانات في YouDo ، عن كيفية إدارة دورة حياة النماذج ، وإعداد عمليات إعادة التدريب وإعادة التدريب ، وتطوير خدمات دقيقة قابلة للتوسيع ، والمزيد.
- لنبدأ بالمقدمة. هناك عالم بيانات ، يكتب بعض التعليمات البرمجية في Jupyter Notebook ، ويقوم بهندسة الميزات ، والتحقق المتبادل ، ويدرب نماذج النماذج. السرعة تنمو.

لكنه يفهم في مرحلة ما: من أجل تحقيق قيمة تجارية للشركة ، يجب عليه إرفاق الحل في مكان ما في الإنتاج ، إلى بعض الإنتاج الأسطوري ، مما يسبب لنا الكثير من المشاكل. لا يمكن إرسال الكمبيوتر المحمول الذي رأيناه في الإنتاج في معظم الحالات. ويطرح السؤال: كيفية شحن هذا الرمز داخل الكمبيوتر المحمول إلى خدمة معينة. في معظم الحالات ، تحتاج إلى كتابة خدمة لها واجهة برمجة تطبيقات. أو يتواصلون من خلال PubSub ، من خلال قوائم الانتظار.

عندما نقدم توصيات ، نحتاج غالبًا إلى تدريب النماذج وإعادة تدريبها. يجب مراقبة هذه العملية. في هذه الحالة ، يجب على المرء دائمًا التحقق من الاختبارات لكل من الكود نفسه والنماذج ، بحيث لا يجن نموذجنا في لحظة واحدة ولا يبدأ دائمًا في التنبؤ بالصفر. يجب أيضًا التحقق من المستخدمين الحقيقيين من خلال اختبارات AB - ما فعلناه بشكل أفضل أو على الأقل ليس أسوأ.
كيف نقترب من الكود؟ لدينا GitLab. تنقسم جميع التعليمات البرمجية الخاصة بنا إلى العديد من المكتبات الصغيرة التي تحل مشكلة مجال معينة. في الوقت نفسه ، هو مشروع GitLab منفصل ، والتحكم في إصدار Git ونموذج GitFlow المتفرع. نحن نستخدم أشياء مثل الخطافات السابقة للالتزام حتى لا تتمكن من تنفيذ التعليمات البرمجية التي لا تفي بفحوصات الاختبار الأساسي لدينا. والاختبارات نفسها ، اختبارات الوحدة. نحن نستخدم نهج الاختبار القائم على الملكية لهم.

عادة ، عندما تكتب الاختبارات ، فإنك تعني أن لديك وظيفة اختبار والحجج التي تنشئها بيديك ، وبعض الأمثلة ، والقيم التي ترجعها وظيفة الاختبار. هذا غير مريح. تم تضخيم الرمز ، والكثير منهن كسالى جدًا في الكتابة. نتيجة لذلك ، لدينا مجموعة من التعليمات البرمجية التي تم الكشف عنها بواسطة الاختبارات. يشير الاختبار القائم على الملكية إلى أن جميع حججك لها توزيع معين. دعنا نقوم بالتدريج ، وفي كثير من الأحيان نقوم بتجربة جميع حججنا من هذه التوزيعات ، واستدعاء الوظيفة قيد الاختبار باستخدام هذه الحجج ، والتحقق من خصائص معينة نتيجة هذه الدالة. نتيجة لذلك ، لدينا كود أقل بكثير ، وفي الوقت نفسه ، هناك العديد من الاختبارات.
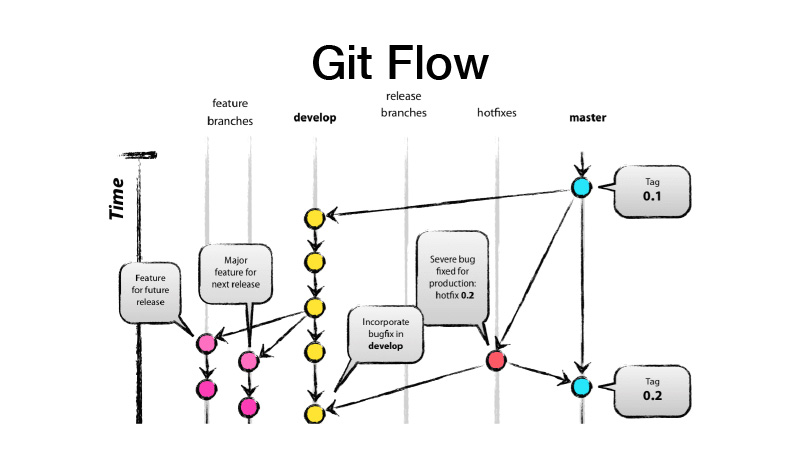
ما هو GitFlow؟ هذا نموذج متفرع ، مما يعني أن لديك فرعين رئيسيين - التطوير والماجستير ، حيث يوجد الرمز الجاهز للإنتاج ، ويتم تنفيذ جميع عمليات التطوير في فرع التطوير ، حيث تحصل جميع الميزات الجديدة من غداء الميزات. أي أن كل ميزة هي ميزة جديدة في وجبة الإفطار ، في حين يجب أن تكون ميزة الميزة لفترة قصيرة ، وللأبد - يتم تغطيتها أيضًا من خلال تبديل الميزة. نقوم بعد ذلك بإصدار إصدار من dev من خلال التغييرات لإتقان ووضع علامة الإصدار الخاصة بمكتبتنا أو خدمتنا عليها.
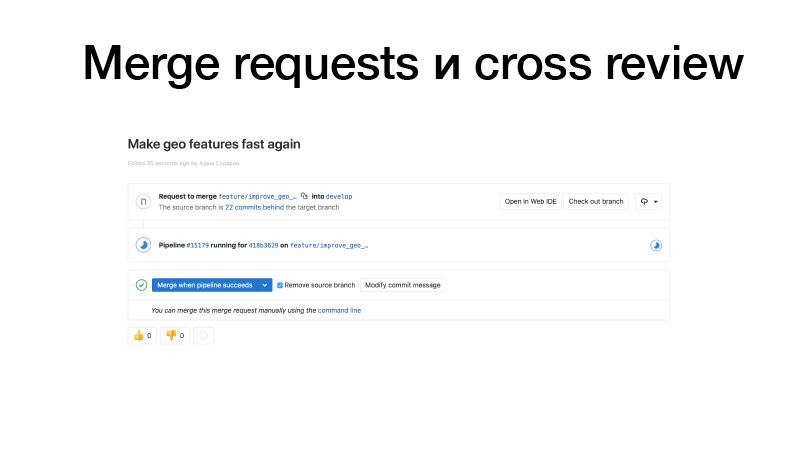
نحن نقوم بالتطوير ، ونشهد بعض الميزات ، ونقوم بدفعها إلى GitLab ، وإنشاء طلب دمج من غداء الميزة إلى عوانس. تعمل المشغلات ، وتجري الاختبارات ، إذا كان كل شيء على ما يرام ، يمكننا تجميده. لكن ليس نحن من نحملها ، بل شخص من الفريق. يقوم بمراجعة الرمز ، وبالتالي يزيد من عامل الناقل. قسم الرمز هذا معروف بالفعل لشخصين. ونتيجة لذلك ، إذا أصيب أحدهم بالحافلة ، فإن شخصًا ما يعرف بالفعل ما يفعله.

عادةً ما يبدو التكامل المستمر للمكتبات بمثابة اختبارات لأية تغييرات. وإذا قمنا بإصداره ، فسيتم نشره أيضًا على خادم PyPI الخاص لحزمتنا.
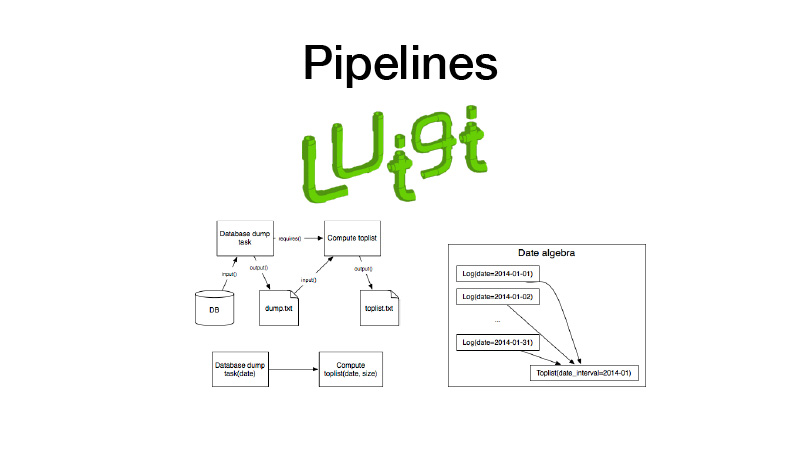
علاوة على ذلك يمكننا جمعها في خطوط الأنابيب. لهذا نستخدم مكتبة لويجي. يعمل مع كيان مثل المهمة ، التي لها مخرجات ، حيث يتم حفظ الأداة التي تم إنشاؤها أثناء تنفيذ المهمة. هناك معلمة مهمة تحدد معلمة منطق الأعمال التي تقوم بتنفيذها ، وتحدد المهمة ونواتجها. في الوقت نفسه ، تتضمن المهام دائمًا متطلبات تفرضها المهام الأخرى. عندما ندير نوعًا من المهام ، يتم فحص جميع تبعياتها من خلال التحقق من مخرجاتها. إذا كان الناتج موجودًا ، فلن يبدأ اعتمادنا. إذا كانت القطعة غير موجودة في بعض وحدات التخزين ، فستبدأ. هذا يشكل خط أنابيب ، رسم بياني دوري موجه.
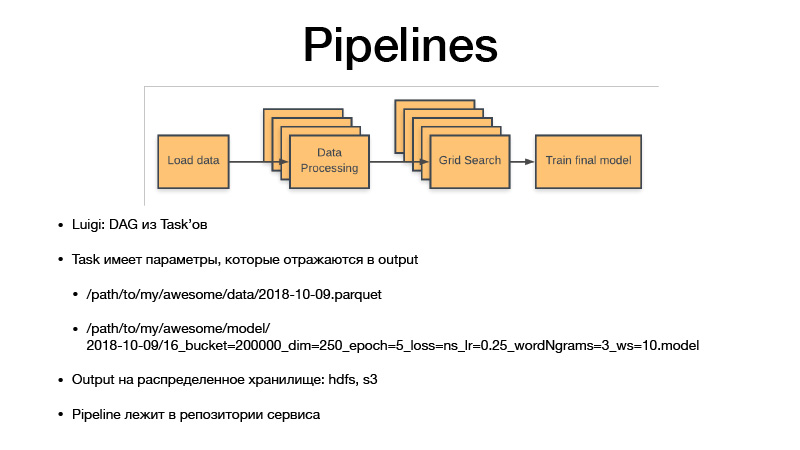
تحدد جميع المعلمات منطق الأعمال. من خلال القيام بذلك ، يحددون القطع الأثرية. إنه دائمًا موعد مع بعض الدقة أو الحساسية أو أسبوع أو يوم أو ساعة أو ثلاث ساعات. إذا قمنا بتدريب بعض النماذج ، فإن Luigi taska دائمًا ما تحتوي على معلمات مفرطة لهذه المهمة ، فهي تتسرب إلى الأداة التي ننتجها ، وتنعكس المعلمات المفرطة في اسم الأداة. وبالتالي ، فإننا نصدر بشكل أساسي جميع مجموعات البيانات الوسيطة والقطع الأثرية النهائية ، ولا يتم استبدالها أبدًا ، دائمًا ما يتم قلبها فقط إلى التخزين ، والتخزين هو HDFS و S3 خاص ، والذي يرى القطع الأثرية النهائية لبعض المخللات أو النماذج أو أي شيء آخر . وكل رمز خط الأنابيب يكمن في مشروع الخدمة في المستودع الذي يتعلق به.

يجب إصلاحه بطريقة أو بأخرى. يأتي مكدس HashiCorp إلى الإنقاذ ، ونحن نستخدم Terraform للإعلان عن البنية التحتية في شكل رمز ، Vault لإدارة الأسرار ، وهناك جميع كلمات المرور ، والمظاهر لقاعدة البيانات. القنصل هو خدمة اكتشاف موزعة بواسطة تخزين قيمة المفتاح الذي يمكنك استخدامه لتكوين. وكذلك يقوم القنصل بإجراء فحوصات صحية لعقدك وخدماتك ، والتحقق من توفرها.
و - البدوي. إنه نظام من التنسيق ، والتخلص من خدماتك ونوع من الوظائف المجمعة.
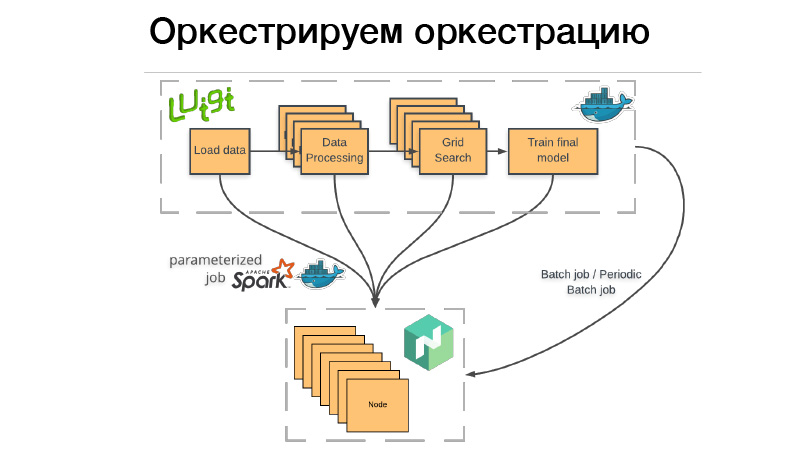
كيف نستخدم هذا؟ هناك خط أنابيب Luigi ، سنقوم بتعبئته في حاوية Docker ، أو إسقاط الخفاش أو مهمة الدفعة الدورية في Nomad. مهمة دفعية - هذا شيء مكتمل ، وإذا انتهى كل شيء - كل شيء على ما يرام ، يمكننا بدء تشغيله يدويًا مرة أخرى. ولكن إذا حدث خطأ ما ، يعيده البدوي حتى يستنفد المحاولة ، أو لا ينتهي بنجاح.
وظيفة الدفعة الدورية - هذا هو نفسه تمامًا ، يعمل فقط وفقًا لجدول زمني.
هناك مشكلة. عندما ننشر حاوية إلى أي نظام تنسيق ، نحتاج إلى الإشارة إلى مقدار الذاكرة التي تحتاجها هذه الحاوية أو وحدة المعالجة المركزية أو الذاكرة. إذا كان لدينا خط أنابيب يعمل لمدة ثلاث ساعات ، فإن ساعتين من هذا تستهلك 10 غيغابايت من ذاكرة الوصول العشوائي ، ساعة واحدة - 70 غيغابايت. إذا تجاوزنا الحد الذي حددناه له ، يأتي Docker daemon ويقتل Dockers و (nrzb.) [02:26:13] نحن لا نريد أن نحصل على الذاكرة باستمرار ، لذلك نحتاج إلى تحديد 70 غيغابايت ، ذروة تحميل الذاكرة. ولكن هنا تكمن المشكلة ، سيتم تخصيص 70 غيغابايت لمدة ثلاث ساعات ولا يمكن الوصول إليها لأي وظيفة أخرى.
لذلك ، ذهبنا في الاتجاه الآخر. لا يبدأ خط أنابيب Luigi بالكامل أي نوع من منطق الأعمال ، ولكنه يطلق مجموعة من الزهر في Nomad ، ما يسمى بالوظيفة المعلمة. في الواقع ، هذا هو التناظرية لوظائف الخادم (NRZB.) [02:26:39] ، AVS Lambda ، الذي يعرف. عندما نقوم بإنشاء مكتبة ، ننشر من خلال CI جميع التعليمات البرمجية الخاصة بنا في شكل وظائف ذات معلمات ، أي حاوية مع بعض المعلمات. لنفترض ، Lite JBM Classifier ، أنه يحتوي على معلمة لمسار بيانات الإدخال للتدريب ، والمعلمات الفائقة للموديلات والمسار إلى المخرجات. كل هذا مسجل في Nomad ، وبعد ذلك من خط أنابيب Luigi يمكننا سحب كل وظائف Nomad هذه من خلال واجهة برمجة التطبيقات ، بينما يتأكد Luigi من عدم تشغيل نفس المهمة عدة مرات.
لنفترض أن لدينا نفس معالجة النصوص. هناك 10 نماذج شرطية ، ولا نريد إعادة تشغيل معالجة النصوص في كل مرة. سيبدأ مرة واحدة فقط ، وفي نفس الوقت ستكون هناك نتيجة نهائية في كل مرة يتم إعادة استخدامها. وفي الوقت نفسه ، كل هذا يعمل بطريقة موزعة ، يمكننا إجراء بحث شبكي عملاق على كتلة كبيرة ، ليس لدينا سوى الوقت لإلقاء الحديد.
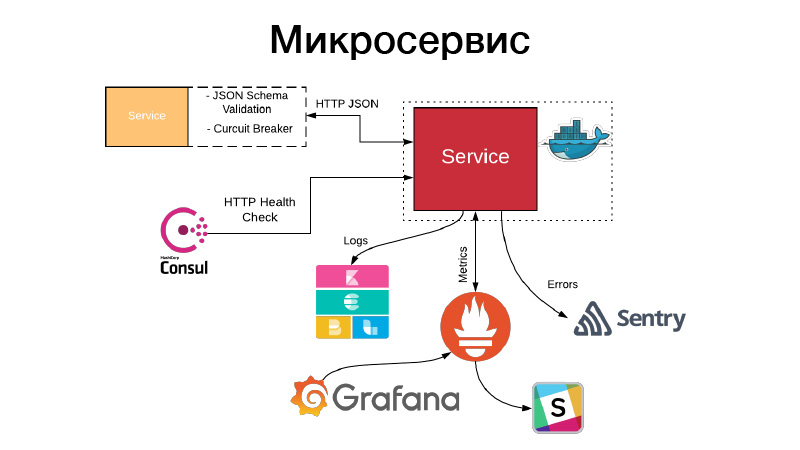
لدينا قطعة أثرية ، ونحن بحاجة إلى ترتيب هذا بطريقة أو بأخرى في شكل خدمة. تكشف الخدمات إما HTTP API أو التواصل من خلال قوائم الانتظار. في هذا المثال ، هذا هو HTTP API ، أبسط مثال. في نفس الوقت ، فإن التواصل مع الخدمة ، أو أن خدمتنا تتواصل مع خدمات أخرى من خلال HTTP JSON API ، يثبت صحة مخطط JSON. تصف الخدمة نفسها دائمًا كائن JSON في وثائق واجهة برمجة التطبيقات الخاصة بها ومخطط هذا الكائن. ولكن ليست هناك حاجة دائمًا إلى جميع مجالات كائن JSON ، وبالتالي يتم التحقق من صحة العقود التي يقودها المستهلك ، ويتم التحقق من هذا المخطط ، ويتم الاتصال عبر قاطع دارات النمط لمنع نظامنا الموزع من الفشل بسبب فشل المتتالية.
في الوقت نفسه ، يجب أن تقوم الخدمة بتعيين فحص صحة HTTP حتى يتمكن القنصل من القدوم والتحقق من توفر هذه الخدمة. في الوقت نفسه ، يمكن لـ Nomad إجراؤها بحيث تكون هناك خدمة لثلاث عمليات فحص مرحبًا على التوالي ، ويمكنها إعادة تشغيل الخدمة لمساعدتها. تكتب الخدمة جميع سجلاتها بتنسيق JSON. نستخدم برنامج تشغيل تسجيل JSON ومكدس Elastic ، في كل نقطة يأخذ FileBit ببساطة كل سجلات JSON ، ويلقيها في ذاكرة التخزين المؤقت للسجلات ، ومن هناك يصل إلى المرونة ، يمكننا تحليل KBan. في الوقت نفسه ، لا نستخدم السجلات لجمع المقاييس ولوحة بيانات البناء ، وهي غير فعالة ، ونستخدم نظام Prometheus الجذاب لهذا ، ولدينا عملية لإنشاء قوالب لكل خدمة لوحة تحكم ، ويمكننا تحليل المقاييس التقنية التي تنتجها الخدمة.
علاوة على ذلك ، إذا حدث خطأ ما ، تأتي التنبيهات ، ولكن في معظم الحالات لا يكون ذلك كافيًا. الحراسة تأتي لمساعدتنا ، وهذا شيء لتحليل الحوادث. في الواقع ، نلتقط جميع سجلات مستوى الخطأ بواسطة معالج Sentry وندفعهم إلى Sentry. ثم هناك تتبع تفصيلي ، هناك كل المعلومات حول البيئة التي كانت الخدمة فيها ، أي إصدار ، والوظائف التي تم استدعاءها من خلال أي وسيطات ، والمتغيرات في هذا النطاق التي كانت مع أي قيم. جميع التكوينات ، كل هذا مرئي ، ويساعد كثيرًا على فهم ما حدث بسرعة وإصلاح الخطأ.
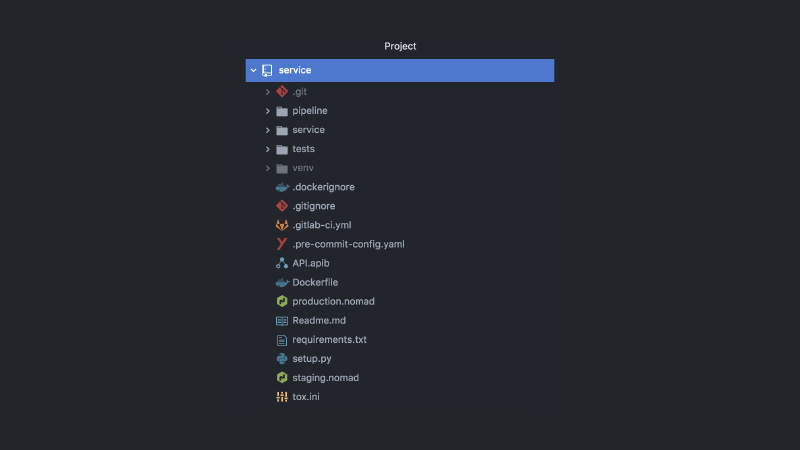
ونتيجة لذلك ، تبدو الخدمة مثل هذا. مشروع GitLab منفصل ، رمز خط الأنابيب ، رمز الاختبار ، رمز الخدمة نفسه ، مجموعة من التكوينات المختلفة ، Nomad ، CI-configs ، وثائق API ، ربط الخطافات والمزيد.
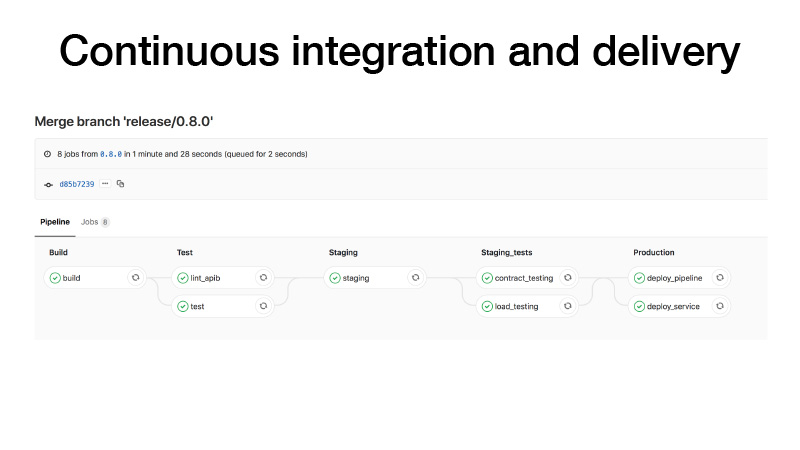
CI ، عندما نقوم بإصدار ، نقوم بذلك على هذا النحو: بناء حاوية ، وإجراء الاختبارات ، ورمي كتلة على خشبة المسرح ، وتشغيل عقد اختبار لخدمتنا هناك ، وإجراء اختبار الضغط للتأكد من أن توقعاتنا ليست بطيئة للغاية والحفاظ على الحمل الذي نعتقد . إذا كان كل شيء على ما يرام ، فسننشر هذه الخدمة للإنتاج. وهناك طريقتان: يمكننا نشر خط الأنابيب ، إذا كانت وظيفة الدفعة الدورية ، تعمل في مكان ما في الخلفية وتنتج قطعًا ، أو باستخدام الأقلام التي نشغل بعض خطوط الأنابيب ، فإنها تدرب بعض النماذج ، بعد ذلك نفهم أن كل شيء على ما يرام ونشر الخدمة.

ماذا يحدث في هذه الحالة؟ قلت أنه في تطوير وجبات الإفطار المتأخر ، يوجد نموذج مثل تبديل الميزات. بطريقة جيدة ، تحتاج إلى تغطية الميزات ببعض التبديل ، فقط لقطع ميزة في المعركة إذا حدث خطأ ما. يمكننا بعد ذلك جمع كل الميزات في قطارات الإصدار ، وحتى إذا لم تكتمل الميزات ، يمكننا نشرها. سيتم إيقاف تشغيل تبديل الميزة فقط. نظرًا لأننا جميعًا علماء بيانات ، فإننا نرغب أيضًا في إجراء اختبارات AV. لنفترض أننا استبدلنا LightGBM بـ CatBoost. نريد التحقق من ذلك ، ولكن في نفس الوقت ، يُدار اختبار AV بالإشارة إلى بعض معرف المستخدم. مفتاح تبديل الميزة مرتبط بمعرف المستخدم ، وبالتالي اجتياز اختبار AV. نحتاج إلى التحقق من هذه المقاييس هنا.
يتم نشر جميع الخدمات إلى البدوي. لدينا مجموعتا إنتاج Nomad - إحداهما للدفعة والأخرى للخدمات.
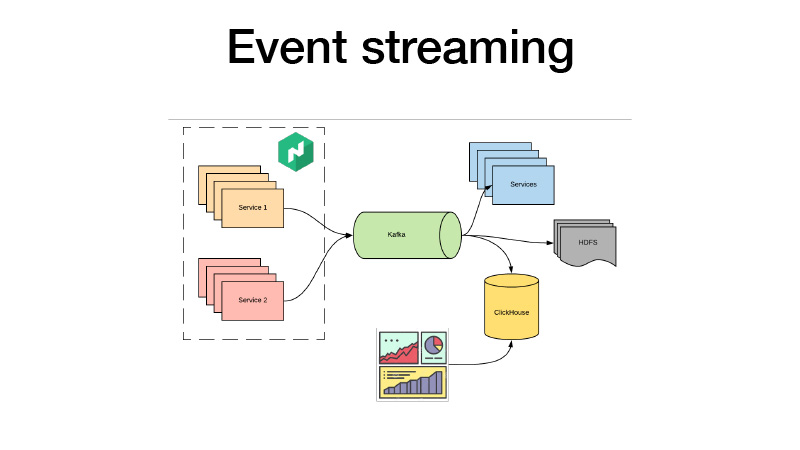
يدفعون كل أحداثهم التجارية إلى كافكا. من هناك يمكننا التقاطهم. في جوهرها ، إنها هندسة الضأن. يمكننا الاشتراك في HDFS مع بعض الخدمات ، وإجراء بعض التحليلات في الوقت الحقيقي ، وفي الوقت نفسه ، نقوم جميعًا بجمع المحتوى في ClickHouse وإنشاء لوحات تحكم لتحليل جميع أحداث الأعمال لخدماتنا. يمكننا تحليل اختبارات AV ، أيا كان.
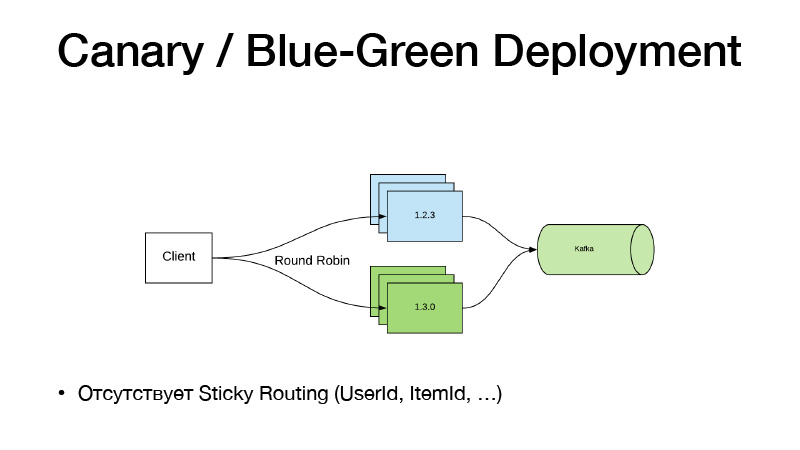
وإذا لم نغير الرمز ، فلا تستخدم تبديل الميزة. لقد بدأنا للتو العمل مع بعض الأقلام على بعض خطوط الأنابيب ، علمنا نموذجًا جديدًا. لدينا طريق جديد لذلك. نحن فقط نغير مسار Nomad إلى النموذج في التكوين ، ونقوم بإصدار خدمة جديدة ، وهنا يأتي نموذج نشر Canary إلى مساعدتنا ، وهو متاح في Nomad من الصندوق.
لدينا الإصدار الحالي من الخدمة في ثلاث حالات. نقول أننا نريد ثلاث طيور الكناري - ثلاث نسخ متماثلة أخرى من الإصدارات الجديدة يتم نشرها دون قطع القديمة. ونتيجة لذلك ، تبدأ حركة المرور في الانقسام إلى جزأين. يقع جزء من حركة المرور على إصدارات جديدة من الخدمات. جميع الخدمات تدفع جميع فعاليات أعمالها إلى كافكا. نتيجة لذلك ، يمكننا تحليل المقاييس في الوقت الفعلي.
إذا كان كل شيء على ما يرام ، فيمكننا القول أن كل شيء على ما يرام. نشر ، سوف يمر Nomad ، ويوقف بلطف جميع الإصدارات القديمة ويوسع نطاق الإصدارات الجديدة.
هذا النموذج سيء لأنه إذا احتجنا إلى ربط توجيه الإصدار من قبل كيان ما ، عنصر المستخدم. لا يعمل مثل هذا المخطط ، لأن الحركة متوازنة من خلال Round-robin. لذلك ، ذهبنا بالطريقة التالية ورأينا الخدمة إلى قسمين.
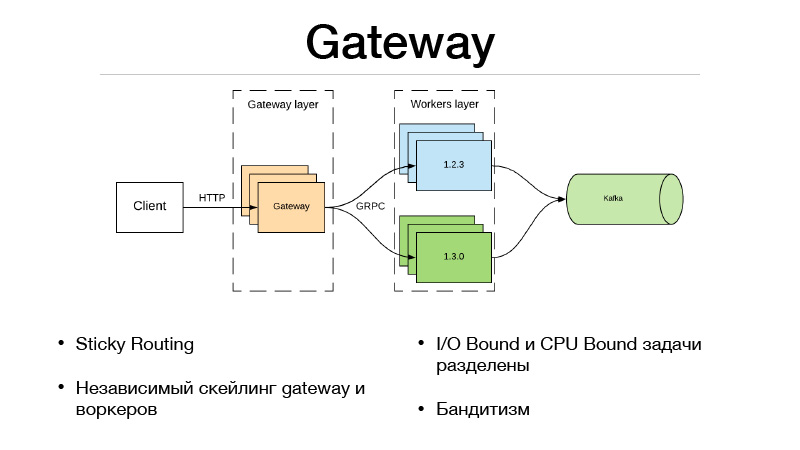
هذه هي طبقة البوابة وطبقة العمال. يتواصل العميل عبر HTTP مع طبقة البوابة ، كل منطق اختيار الإصدار وموازنة الحركة موجود في البوابة. في الوقت نفسه ، توجد أيضًا جميع مهام I / O Bound المطلوبة لإكمال المسند في البوابة. افترض أننا حصلنا على معرف مستخدم في المسند في الطلب ، والذي نحتاج إلى إثرائه ببعض المعلومات. يجب علينا سحب الخدمات الصغيرة الأخرى والتقاط جميع المعلومات أو الميزات أو القواعد. ونتيجة لذلك ، يحدث كل هذا في البوابة. يتواصل مع العمال الذين هم فقط في النموذج ، ويفعل شيئًا واحدًا - وهو توقع. المدخلات والمخرجات.
ولكن نظرًا لأننا قسمنا خدمتنا إلى جزأين ، فقد ظهرت النفقات العامة بسبب مكالمة شبكة بعيدة. كيفية تسوية ذلك؟ يأتي إطار عمل JRPC من Google ، و RPC من Google ، والذي يتم تشغيله فوق HTTP2 إلى الإنقاذ. يمكنك استخدام مضاعفة وضغط. يستخدم JPRC البروتوبوف. هذا بروتوكول ثنائي مطبوع بقوة يحتوي على تسلسل سريع وإلغاء التسلسل.
ونتيجة لذلك ، لدينا أيضًا القدرة على توسيع البوابة والعامل بشكل مستقل. لنفترض أننا لا نستطيع الاحتفاظ بقدر معين من اتصالات HTTP المفتوحة. حسنًا ، توسيع البوابة. تنبؤنا بطيء للغاية ، ليس لدينا الوقت للحفاظ على الحمل - حسنًا ، نحن نقيس العمال. يناسب هذا النهج بشكل جيد للغاية قطاع الطرق المتعددين. في Gateway ، نظرًا لأنه يتم تنفيذ منطق موازنة حركة المرور بالكامل ، فيمكنه الانتقال إلى الخدمات الصغيرة الخارجية وأخذ جميع الإحصائيات لكل نسخة منها ، بالإضافة إلى اتخاذ قرارات حول كيفية موازنة حركة المرور. لنفترض استخدام Thompson Sampling.
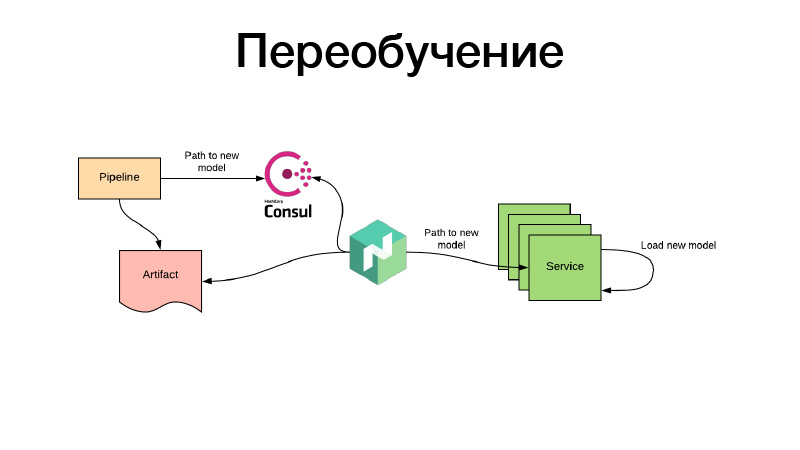
حسنًا ، تم تدريب النماذج بطريقة أو بأخرى ، وقمنا بتسجيلها في تكوين Nomad. ولكن ماذا لو كان هناك نموذج للتوصيات التي لديها الوقت بالفعل لتصبح عفا عليها الزمن أثناء التدريب ونحتاج إلى إعادة تدريبهم باستمرار؟ يتم تنفيذ كل شيء بالطريقة نفسها: من خلال وظائف المجموعة الدورية ، يتم إنتاج بعض القطع الأثرية - على سبيل المثال ، كل ثلاث ساعات. في نفس الوقت ، في نهاية عمله ، يحدد خط الأنابيب المسار للنموذج الجديد في القنصل. هذا هو تخزين القيمة الرئيسية ، والذي يستخدم للتكوين. يمكن للبدلة تكوين التكوينات. يجب ألا يكون هناك متغير بيئة بناءً على قيم Consul لتخزين القيمة الرئيسية. يراقب التغييرات ، وبمجرد ظهور مسار جديد ، يقرر أنه يمكن اتخاذ مسارين. يقوم بتنزيل الأداة نفسها عبر رابط جديد ، ويضع حاوية الخدمة في Docker باستخدام الحجم ويعيد تحميله - ويقوم بكل ذلك حتى لا يكون هناك وقت تعطل ، أي ببطء ، بشكل فردي. أو يقدم تكوينًا جديدًا ويبلغه بالخدمة. أو الخدمة نفسها تكتشفها - وداخلها يمكن أن تقوم بشكل مستقل بتحديث نموذجها. هذا كل شيء ، شكرا.