
لقد صادفت مادة مثيرة للاهتمام حول الذكاء الاصطناعي في الألعاب. مع شرح الأشياء الأساسية حول الذكاء الاصطناعي باستخدام أمثلة بسيطة ، وداخله هناك العديد من الأدوات والأساليب المفيدة لتطويره وتصميمه المريح. كيف وأين ومتى لاستخدامها - هناك أيضا.
معظم الأمثلة مكتوبة في كود زائف ، لذا فإن معرفة البرمجة المتعمقة غير مطلوبة. تحت 35 ورقة نص مقطوعة مع صور وصور متحركة ، فاستعد.
UPD أنا
آسف ، لكن
PatientZero قام بالفعل بترجمة هذا المقال عن حبري. يمكنك قراءة نسخته
هنا ، ولكن لسبب ما اجتازني المقال (استخدمت البحث ، ولكن حدث خطأ ما). وبما أنني أكتب مدونة تطوير لعبة ، قررت ترك خيار الترجمة الخاص بي للمشتركين (بعض اللحظات مختلفة بالنسبة لي ، وبعضها مفقود عن عمد بناء على نصيحة المطورين).
ما هو الذكاء الاصطناعي؟
تركز لعبة AI على الإجراءات التي يجب أن يقوم بها الكائن بناءً على الظروف التي يوجد فيها. يُسمى هذا عادةً بإدارة "الوكلاء الأذكياء" ، حيث يكون الوكيل شخصية لعبة ، مركبة ، روبوت ، وأحيانًا شيء أكثر تجريدًا: مجموعة كاملة من الكيانات أو حتى الحضارة. في كل حالة ، إنه شيء يجب أن يرى محيطه ، واتخاذ القرارات على أساسه والتصرف وفقًا له. وهذا ما يسمى دورة Sense / Think / Act:
- المعنى: يجد الوكيل أو يتلقى معلومات حول أشياء في بيئته قد تؤثر على سلوكه (التهديدات القريبة ، العناصر التي يجب جمعها ، الأماكن المثيرة للاهتمام للبحث).
- فكر: يقرر الوكيل كيفية الرد (ضع في الاعتبار ما إذا كان من الآمن جمع العناصر أو ما إذا كان يجب عليه القتال / الإخفاء أولاً).
- الفعل: يقوم الوكيل بإجراءات لتنفيذ القرار السابق (يبدأ بالتحرك نحو الخصم أو الشيء).
- ... الآن تغير الوضع بسبب تصرفات الشخصيات ، لذلك تتكرر الدورة مع البيانات الجديدة.
يميل الذكاء الاصطناعي إلى التركيز على الجزء الحسي من الحلقة. على سبيل المثال ، تقوم السيارات ذاتية القيادة بالتقاط صور للطريق ودمجها مع بيانات الرادار والليدار وتفسيرها. عادة يتم ذلك عن طريق التعلم الآلي ، الذي يعالج البيانات الواردة ويعطيها معنى ، واستخراج المعلومات الدلالية مثل "هناك سيارة أخرى أمامك على بعد 20 ياردة". هذه هي مشاكل التصنيف.
لا تحتاج الألعاب إلى نظام معقد لاستخراج المعلومات ، لأن معظم البيانات جزء لا يتجزأ منها بالفعل. ليست هناك حاجة لتشغيل خوارزميات التعرف على الصور لتحديد ما إذا كان هناك عدو أمامك - فاللعبة تعرف بالفعل وتنقل المعلومات مباشرة في عملية صنع القرار. لذلك ، غالبًا ما يكون جزء من دورة Sense أبسط بكثير من Think and Act.
قيود لعبة الذكاء الاصطناعي
لدى منظمة العفو الدولية عدد من القيود التي يجب مراعاتها:
- لا يحتاج الذكاء الاصطناعي إلى التدريب مقدمًا ، كما لو كان خوارزمية للتعلم الآلي. من غير المجدي كتابة شبكة عصبية أثناء التطوير لمشاهدة عشرات الآلاف من اللاعبين وتعلم أفضل طريقة للعب ضدهم. لماذا؟ لأنه لم يتم إصدار اللعبة ، ولكن لا يوجد لاعبون.
- يجب على اللعبة التسلية والتحدي ، لذلك لا يجب على العملاء العثور على أفضل نهج ضد الناس.
- يحتاج الوكلاء إلى أن يبدووا واقعيين حتى يشعر اللاعبون أنهم يلعبون ضد أناس حقيقيين. قام AlphaGo بتفوق البشر ، لكن الخطوات التي تم اتخاذها كانت بعيدة عن الفهم التقليدي للعبة. إذا كانت اللعبة تقلد خصمًا بشريًا ، فلا ينبغي أن يكون هناك مثل هذا الشعور. يجب تغيير الخوارزمية بحيث تتخذ قرارات معقولة ، وليست قرارات مثالية.
- يجب أن يعمل الذكاء الاصطناعي في الوقت الفعلي. وهذا يعني أن الخوارزمية لا يمكنها احتكار استخدام المعالج لفترة طويلة لاتخاذ القرار. حتى 10 مللي ثانية لهذا طويل جدًا ، لأن معظم الألعاب لديها 16 إلى 33 مللي ثانية فقط لإكمال جميع المعالجة والانتقال إلى الإطار التالي للرسم.
- من الناحية المثالية ، يعتمد جزء على الأقل من النظام على البيانات بحيث يمكن لغير المبرمجين إجراء التغييرات والتعديلات بشكل أسرع.
ضع في اعتبارك مناهج الذكاء الاصطناعي التي تمتد عبر دورة الإحساس / التفكير / الفعل.
صنع القرار الأساسي
لنبدأ مع أبسط لعبة - بونغ. الهدف: تحريك المنصة (مجداف) بحيث ترتد الكرة منها ، بدلاً من الطيران في الماضي. إنه مثل التنس ، حيث تخسر إذا لم تضرب الكرة. هنا ، لدى الذكاء الاصطناعي مهمة سهلة نسبيًا - أن تقرر في أي اتجاه لتحريك المنصة.

عبارات شرطية
بالنسبة للذكاء الاصطناعي ، لدى Pong الحل الأكثر وضوحًا - حاول دائمًا وضع المنصة تحت الكرة.
خوارزمية بسيطة لهذا مكتوبة في pseudocode:
كل إطار / تحديث أثناء تشغيل اللعبة:
إذا كانت الكرة على يسار المجذاف:
تحرك مجداف اليسار
إذا كانت الكرة على يمين المجذاف:
نقل مجداف لليمينإذا كانت المنصة تتحرك بسرعة الكرة ، فهذه هي الخوارزمية المثالية للذكاء الاصطناعي في Pong. ليست هناك حاجة لتعقيد أي شيء إذا لم يكن هناك الكثير من البيانات والإجراءات الممكنة للوكيل.
هذا النهج بسيط للغاية لدرجة أن دورة Sense / Think / Act بأكملها بالكاد يمكن ملاحظتها. لكنه:
- ينقسم جزء Sense إلى عبوتين إذا. تعرف اللعبة مكان الكرة وأين توجد المنصة ، لذلك يتحول الذكاء الاصطناعي إليها للحصول على هذه المعلومات.
- يأتي جزء التفكير أيضًا في جملتين إذا. إنها تجسد حلين ، وهما في هذه الحالة حصريان بشكل متبادل. ونتيجة لذلك ، تم تحديد أحد الإجراءات الثلاثة - انقل النظام الأساسي إلى اليسار ، أو انتقل إلى اليمين ، أو لا تفعل شيئًا إذا تم وضعه بالفعل بشكل صحيح.
- الجزء Act موجود في عبارتي Move Paddle Left و Move Paddle Right. اعتمادًا على تصميم اللعبة ، يمكنهم تحريك النظام الأساسي على الفور أو بسرعة معينة.
تسمى هذه الأساليب رد الفعل - هناك مجموعة بسيطة من القواعد (في هذه الحالة ، إذا كانت البيانات في التعليمات البرمجية) التي تستجيب للحالة الراهنة للعالم وتتصرف.
شجرة القرار
مثال Pong يساوي في الواقع مفهوم منظمة العفو الدولية الرسمي المسمى شجرة القرار. تمررها الخوارزمية من أجل الوصول إلى "ورقة" - قرار حول الإجراء الذي يجب اتخاذه.
لنقم بعمل رسم تخطيطي لشجرة القرار لخوارزمية منصتنا:
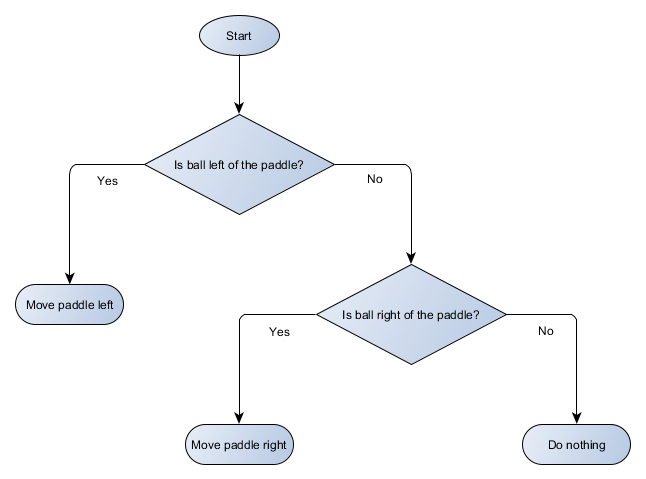
يسمى كل جزء من الشجرة عقدة - يستخدم الذكاء الاصطناعي نظرية الرسم البياني لوصف مثل هذه الهياكل. هناك نوعان من العقد:
- عُقد القرار: الاختيار بين بديلين بناءً على التحقق من حالة معينة حيث يتم تقديم كل بديل كعقدة منفصلة.
- عقد النهاية: إجراء يتم تنفيذه يمثل القرار النهائي.
تبدأ الخوارزمية بالعقدة الأولى ("جذر" الشجرة). تقرر إما العقدة الفرعية التي يجب أن تذهب إليها ، أو تقوم بإجراء مخزن في العقدة وتكتمل.
ما الفائدة إذا قامت شجرة القرار بنفس الوظيفة مثل عبارات if في القسم السابق؟ هنا يوجد نظام مشترك حيث لكل حل شرط واحد فقط ونتائج محتملة. هذا يسمح للمطور بإنشاء الذكاء الاصطناعي من البيانات التي تمثل القرارات في الشجرة ، وتجنب ترميزها. تخيل على شكل جدول:
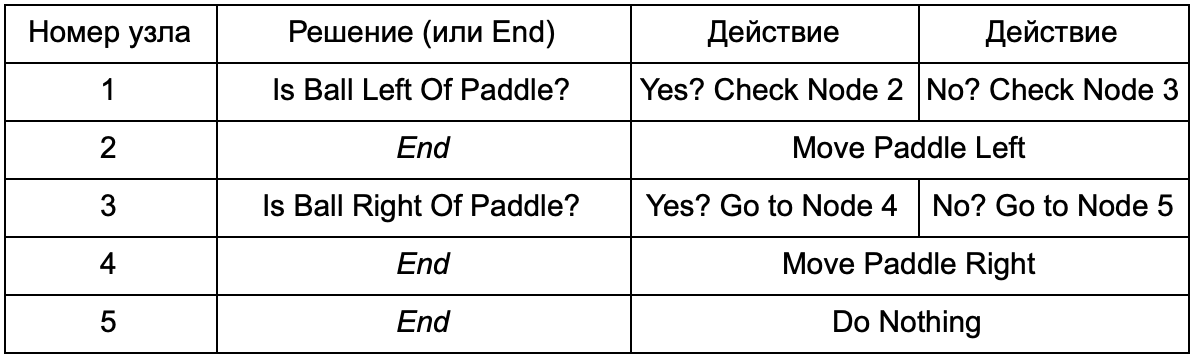
على جانب الكود ، تحصل على نظام لقراءة السلاسل. قم بإنشاء عقدة لكل منها ، وقم بتوصيل منطق القرار بناءً على العمود الثاني والعقد الفرعية بناءً على العمودين الثالث والرابع. ما زلت بحاجة إلى برمجة الشروط والإجراءات ، ولكن الآن سيكون هيكل اللعبة أكثر تعقيدًا. في ذلك ، يمكنك إضافة قرارات وإجراءات إضافية ، ثم تكوين الذكاء الاصطناعي بالكامل بمجرد تحرير ملف نصي مع تعريف شجرة. بعد ذلك ، انقل الملف إلى مصمم اللعبة الذي يمكنه تغيير السلوك دون إعادة تجميع اللعبة وتغيير الرمز.
تكون أشجار القرار مفيدة للغاية عندما يتم بناؤها تلقائيًا استنادًا إلى مجموعة كبيرة من الأمثلة (على سبيل المثال ، باستخدام خوارزمية ID3). وهذا يجعلها أداة فعالة وعالية الأداء لتصنيف المواقف بناءً على البيانات المستلمة. ومع ذلك ، فإننا نتجاوز نظامًا بسيطًا يمكن للوكلاء تحديد الإجراءات.
السيناريوهات
قمنا بتفكيك نظام شجرة القرار الذي استخدم الشروط والإجراءات التي تم إنشاؤها مسبقًا. يمكن لمصمم الذكاء الاصطناعي ترتيب الشجرة بالطريقة التي يريدها ، ولكن لا يزال عليه الاعتماد على برنامج التشفير الذي برمجها بالكامل. ماذا لو استطعنا إعطاء المصمم أدوات لخلق ظروفنا أو إجراءاتنا الخاصة؟
لمنع المبرمج من كتابة تعليمات برمجية لظروف Is Ball Left Of Paddle و Is Ball Right Of Paddle ، يمكنه إنشاء نظام يسجل فيه المصمم شروط التحقق من هذه القيم. ثم ستبدو بيانات شجرة القرار كما يلي:
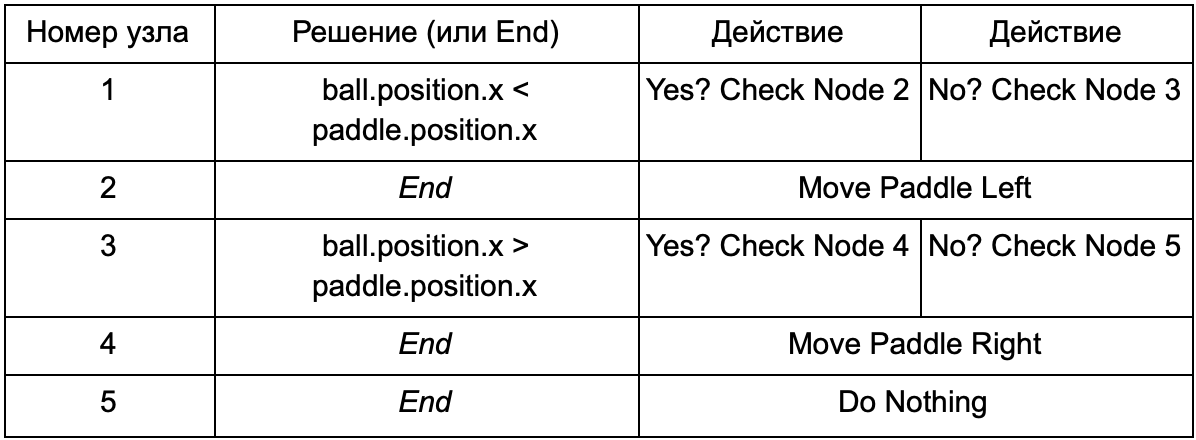
في الجوهر ، هذا هو نفسه كما هو الحال في الجدول الأول ، ولكن الحلول الموجودة في داخلها لها رمزها الخاص ، يشبه إلى حد ما الجزء الشرطي من جملة if-statement. على جانب الشفرة ، سيتم قراءة هذا في العمود الثاني لعقد القرار ، ولكن بدلاً من البحث عن شرط معين لاستيفائه (Is Ball Left Of Paddle) ، فإنه يقيم التعبير الشرطي ويعيد true أو false ، على التوالي. يتم ذلك باستخدام لغة البرمجة النصية Lua أو Angelscript. باستخدامها ، يمكن للمطور أخذ الأشياء في لعبته (الكرة والمجذاف) وإنشاء المتغيرات التي ستكون متاحة في البرنامج النصي (ball.position). بالإضافة إلى ذلك ، لغة البرمجة النصية أبسط من C ++. لا يتطلب مرحلة تجميع كاملة ، وبالتالي فهو مناسب تمامًا للتعديل السريع لمنطق اللعبة ويسمح لـ "غير المبرمجين" بإنشاء الوظائف اللازمة بأنفسهم.
في المثال أعلاه ، يتم استخدام لغة البرمجة النصية فقط لتقييم تعبير شرطي ، ولكن يمكن أيضًا استخدامها في الإجراءات. على سبيل المثال ، يمكن أن تصبح بيانات Move Paddle Right عبارة نصية (ball.position.x + = 10). بحيث يتم تعريف الإجراء أيضًا في البرنامج النصي ، دون الحاجة إلى برمجة Move Paddle Right.
يمكنك الذهاب إلى أبعد من ذلك وكتابة شجرة قرار كاملة بلغة البرمجة النصية. سيكون هذا رمزًا في شكل عبارات شرطية مضمنة ، ولكن سيتم وضعها في ملفات نصية خارجية ، أي أنه يمكن تغييرها دون إعادة تجميع البرنامج بأكمله. غالبًا ، يمكنك تغيير ملف البرنامج النصي مباشرة أثناء اللعبة لاختبار تفاعلات الذكاء الاصطناعي المختلفة بسرعة.
استجابة الحدث
الأمثلة أعلاه مثالية لبونغ. إنهم يديرون بشكل مستمر دورة Sense / Think / Act ويتصرفون على أساس أحدث حالة في العالم. ولكن في الألعاب الأكثر تعقيدًا ، تحتاج إلى الاستجابة للأحداث الفردية ، وليس تقييم كل شيء في وقت واحد. بونغ هو بالفعل مثال غير ناجح. اختر واحدة أخرى.
تخيل مطلق النار حيث يكون الأعداء بلا حراك حتى يعثروا على اللاعب ، وبعد ذلك يتصرفون اعتمادًا على "تخصصهم": سيركض أحدهم إلى "يسحق" ، ويهاجم شخص ما من بعيد. لا يزال هذا هو النظام الأساسي المستجيب - "إذا تم ملاحظة اللاعب ، فقم بعمل شيء ما" - ولكن يمكن تقسيمه منطقياً إلى حدث Player Seen (لاحظ اللاعب) ورد الفعل (حدد الإجابة وقم بتنفيذها).
هذا يعيدنا إلى دورة الإحساس / التفكير / الفعل. يمكننا ترميز جزء Sense ، والذي سيتحقق منه كل إطار لمعرفة ما إذا كان AI للاعب مرئيًا أم لا. إذا لم يكن الأمر كذلك ، فلن يحدث شيء ، ولكن إذا رأيت ، فسيتم رفع حدث Player Seen. سيحتوي الكود على قسم منفصل يقول: "عند حدوث حدث Player Seen ، افعل ذلك" ، حيث هو الجواب الذي تحتاجه للإشارة إلى أجزاء Think and Act. وبالتالي ، ستقوم بإعداد ردود الفعل على حدث Player Seen: ChargeAndAttack للشخصية "المتنامية" ، و HideAndSnipe للقناص. يمكن إنشاء هذه العلاقات في ملف البيانات للتحرير السريع دون الحاجة إلى إعادة الترجمة. وهنا يمكنك أيضًا استخدام لغة البرمجة النصية.
اتخاذ قرارات صعبة
على الرغم من أن أنظمة التفاعل البسيطة فعالة للغاية ، إلا أن هناك العديد من المواقف عندما لا تكون كافية. في بعض الأحيان يكون من الضروري اتخاذ قرارات مختلفة بناءً على ما يقوم به الوكيل في الوقت الحالي ، ولكن من الصعب تخيل ذلك كشرط. في بعض الأحيان يكون هناك الكثير من الشروط لتمثيلها بشكل فعال في شجرة القرار أو البرنامج النصي. تحتاج في بعض الأحيان إلى إجراء تقييم مسبق لكيفية تغير الموقف قبل اتخاذ قرار بشأن الخطوة التالية. يتطلب حل هذه المشكلات أساليب أكثر تعقيدًا.
آلة الحالة المحدودة
آلة الحالة المحدودة أو FSM (آلة الحالة) هي طريقة للقول أن وكيلنا موجود حاليًا في واحدة من العديد من الحالات المحتملة ، وأنه يمكنه الانتقال من حالة إلى أخرى. هناك عدد معين من هذه الحالات - ومن هنا جاء الاسم. أفضل مثال على الحياة هو إشارة المرور. في أماكن مختلفة تسلسلات مختلفة من الأضواء ، ولكن المبدأ هو نفسه - كل حالة تمثل شيئًا (الوقوف ، الذهاب ، إلخ). يكون إشارة المرور في حالة واحدة فقط في أي وقت معين ، وينتقل من واحد إلى آخر بناءً على قواعد بسيطة.
مع الشخصيات في الألعاب ، قصة مماثلة. على سبيل المثال ، خذ حارسًا بالشروط التالية:
وهذه الشروط لتغيير حالته:
- إذا رأى الحارس العدو يهاجم.
- إذا هاجم الحارس ، لكنه لم يعد يرى العدو ، يعود إلى الدوريات.
- إذا هاجم الحارس ولكنه أصيب بجروح بالغة ، فإنه يهرب.
يمكنك أيضًا كتابة عبارات if بمتغير حالة حارس وفحوصات مختلفة: هل يوجد عدو قريب ، وما هو المستوى الصحي لمجلس الشعب ، وما إلى ذلك. دعنا نضيف بعض الحالات الأخرى:
- التقاعس عن العمل - بين الدوريات.
- البحث (البحث) - عندما اختفى العدو الملاحظ.
- اطلب المساعدة (Finding Help) - عندما يُرى العدو ، لكنه قوي للغاية للقتال معه وحده.
الخيار لكل منهم محدود - على سبيل المثال ، لن يذهب الحارس للبحث عن عدو مختبئ إذا كان في حالة صحية سيئة.
في النهاية ، قد تصبح القائمة الضخمة من "if <x and y، not not z>، <p>" مرهقة للغاية ، لذلك يجب علينا إضفاء الطابع الرسمي على طريقة تتيح لنا أن نضع في الاعتبار الحالات والانتقالات بين الحالات. للقيام بذلك ، نأخذ في الاعتبار جميع الولايات ، وتحت كل ولاية ، نقوم بإدراج جميع التحولات إلى دول أخرى ، مع الشروط اللازمة لها.
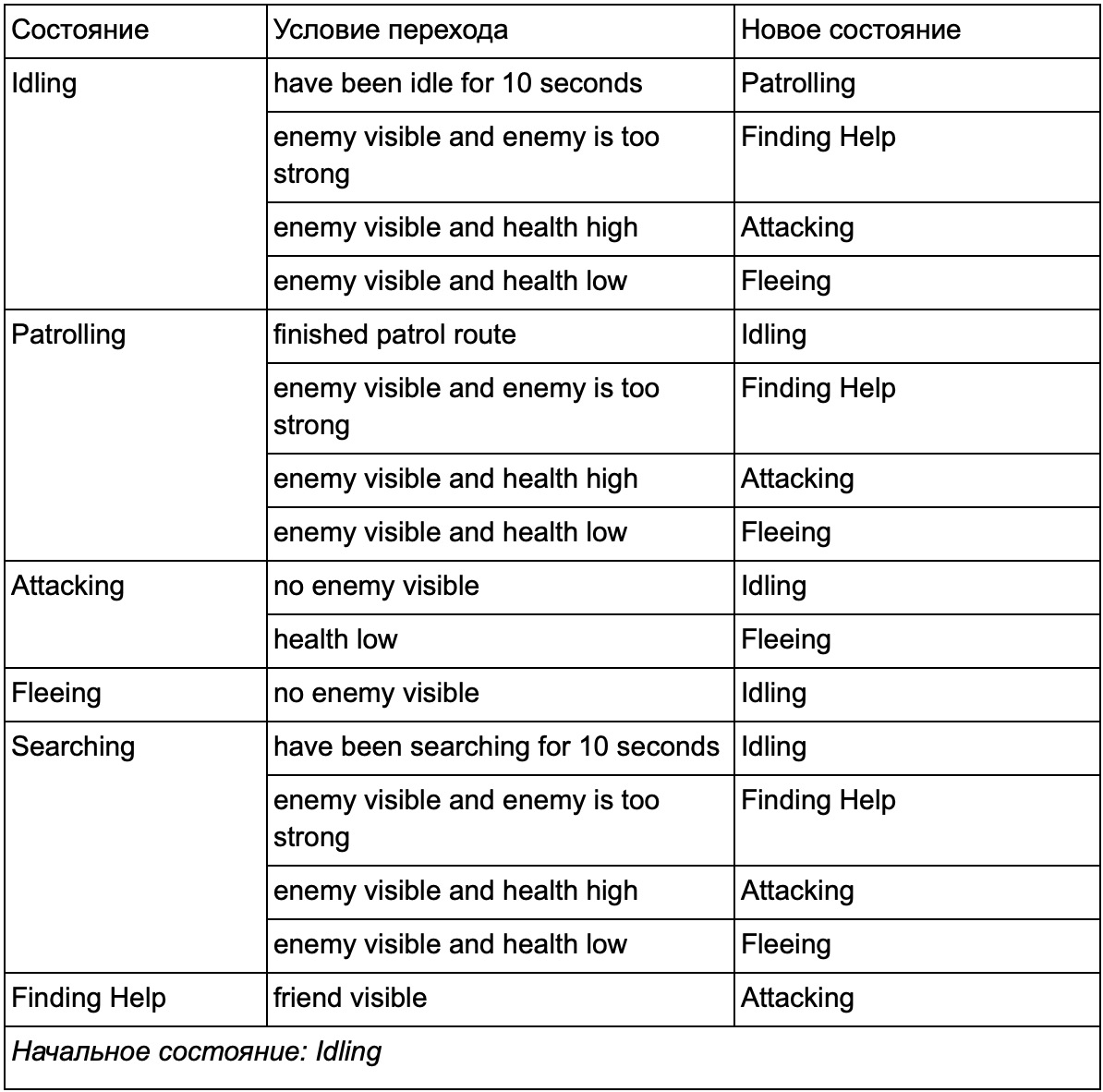
جدول انتقال الحالة هذا هو طريقة شاملة لتمثيل FSM. دعنا نرسم مخططًا ونحصل على نظرة عامة كاملة عن كيفية تغير سلوك الشخصيات غير القابلة للعب.
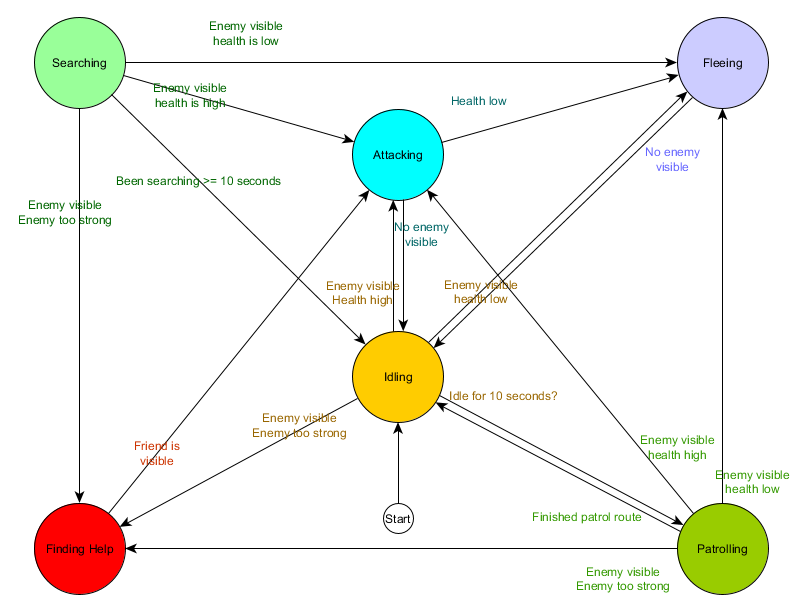
يعكس الرسم البياني جوهر اتخاذ القرار لهذا الوكيل بناءً على الوضع الحالي. علاوة على ذلك ، يظهر كل سهم انتقالًا بين الحالات إذا كان الشرط المجاور له صحيحًا.
في كل تحديث ، نتحقق من الحالة الحالية للوكيل ، ونلقي نظرة على قائمة الانتقالات ، وإذا تم استيفاء شروط الانتقال ، فإنها تأخذ حالة جديدة. على سبيل المثال ، يتحقق كل إطار لمعرفة ما إذا كان جهاز ضبط الوقت الذي تبلغ مدته 10 ثوانٍ قد انتهت صلاحيته ، وإذا كان الأمر كذلك ، فإن الحرس يتحول من وضع الخمول إلى الدورية. بنفس الطريقة ، تتحقق الدولة المهاجمة من صحة الوكيل - إذا كانت منخفضة ، فإنها تذهب إلى حالة الفرار.
هذا يتعامل مع انتقالات الدولة ، ولكن ماذا عن السلوك المرتبط بالدول نفسها؟ فيما يتعلق بتنفيذ السلوك الفعلي لدولة معينة ، عادة ما يكون هناك نوعان من "السنانير" حيث نقوم بتعيين إجراءات ل FSM:
- الإجراءات التي نقوم بها بشكل دوري للحالة الحالية.
- الإجراءات التي نتخذها عند الانتقال من دولة إلى أخرى.
أمثلة للنوع الأول. حالة الدوريات يتحرك كل إطار العامل على طول مسار الدورية. حالة الهجوم سيحاول كل إطار بدء هجوم أو الدخول في حالة متى أمكن.
بالنسبة للنوع الثاني ، ضع في اعتبارك الانتقال "إذا كان العدو مرئيًا وكان العدو قويًا جدًا ، فانتقل إلى حالة العثور على المساعدة. يجب على الوكيل اختيار المكان الذي يذهب إليه للحصول على المساعدة وحفظ هذه المعلومات حتى تعرف حالة البحث عن تعليمات إلى أين تذهب. بمجرد العثور على المساعدة ، يعود الوكيل إلى حالة الهجوم. عند هذه النقطة ، سيرغب في إخبار الحليف بشأن التهديد ، لذلك قد يحدث إجراء NotifyFriendOfThreat.
ومرة أخرى ، يمكننا أن ننظر إلى هذا النظام من خلال منظور دورة الإحساس / التفكير / الفعل. يترجم العقل إلى البيانات التي يستخدمها منطق الانتقال. فكر - التحولات المتوفرة في كل دولة. ويتم الفعل من خلال الإجراءات التي تتم بشكل دوري داخل الدولة أو في عمليات الانتقال بين الدول.
قد يكون الاستقصاء المستمر لظروف الانتقال مكلفًا في بعض الأحيان. على سبيل المثال ، إذا قام كل وكيل بإجراء حسابات معقدة على كل إطار لتحديد ما إذا كان يرى الأعداء وفهم ما إذا كان من الممكن التبديل من حالة الدورية إلى الهجوم ، فسيستغرق ذلك الكثير من وقت المعالج.
يمكن اعتبار التغييرات الهامة في حالة العالم كأحداث ستتم معالجتها عند حدوثها. بدلاً من التحقق من FSM لشرط النقل "هل يستطيع وكيل أعمالي رؤية المشغل؟" في كل إطار ، يمكنك تكوين نظام منفصل لإجراء عمليات فحص أقل (على سبيل المثال ، 5 مرات في الثانية). والنتيجة هي إعطاء اللاعب Seen عند مرور الشيك.
يتم تمرير هذا إلى FSM ، والتي يجب أن تذهب الآن إلى حالة استقبال حدث Player Seen وتتفاعل وفقًا لذلك. السلوك الناتج هو نفسه باستثناء تأخير غير محسوس قبل الإجابة. لكن الإنتاجية أصبحت أفضل نتيجة فصل جزء Sense إلى جزء منفصل من البرنامج.
آلة الحالة المحدودة الهرمية
ومع ذلك ، فإن العمل مع FSMs الكبيرة ليس مناسبًا دائمًا. إذا أردنا توسيع حالة الهجوم ، واستبداله بـ MeleeAttacking (المشاجرة) و RangedAttacking (المتراوحة) ، فسيتعين علينا تغيير التحولات من جميع الحالات الأخرى التي تؤدي إلى حالة الهجوم (الحالية والمستقبلية).
بالتأكيد لاحظت أنه في مثالنا هناك الكثير من التحولات المكررة. معظم التحولات في حالة التباطؤ مماثلة للتحولات في حالة الدوريات. سيكون من الجيد عدم التكرار ، خاصة إذا أضفنا المزيد من الحالات المتشابهة. من المنطقي تجميع التباطؤ والدوريات تحت التسمية المشتركة "غير قتالية" ، حيث لا توجد سوى مجموعة واحدة مشتركة من التحولات إلى الدول القتالية. إذا قدمنا هذا التصنيف كدولة ، فعندئذ سيصبح التباطؤ والدوريات فرعية. مثال على استخدام جدول تحويل منفصل لدولة فرعية غير قتالية جديدة:
الشروط الرئيسية: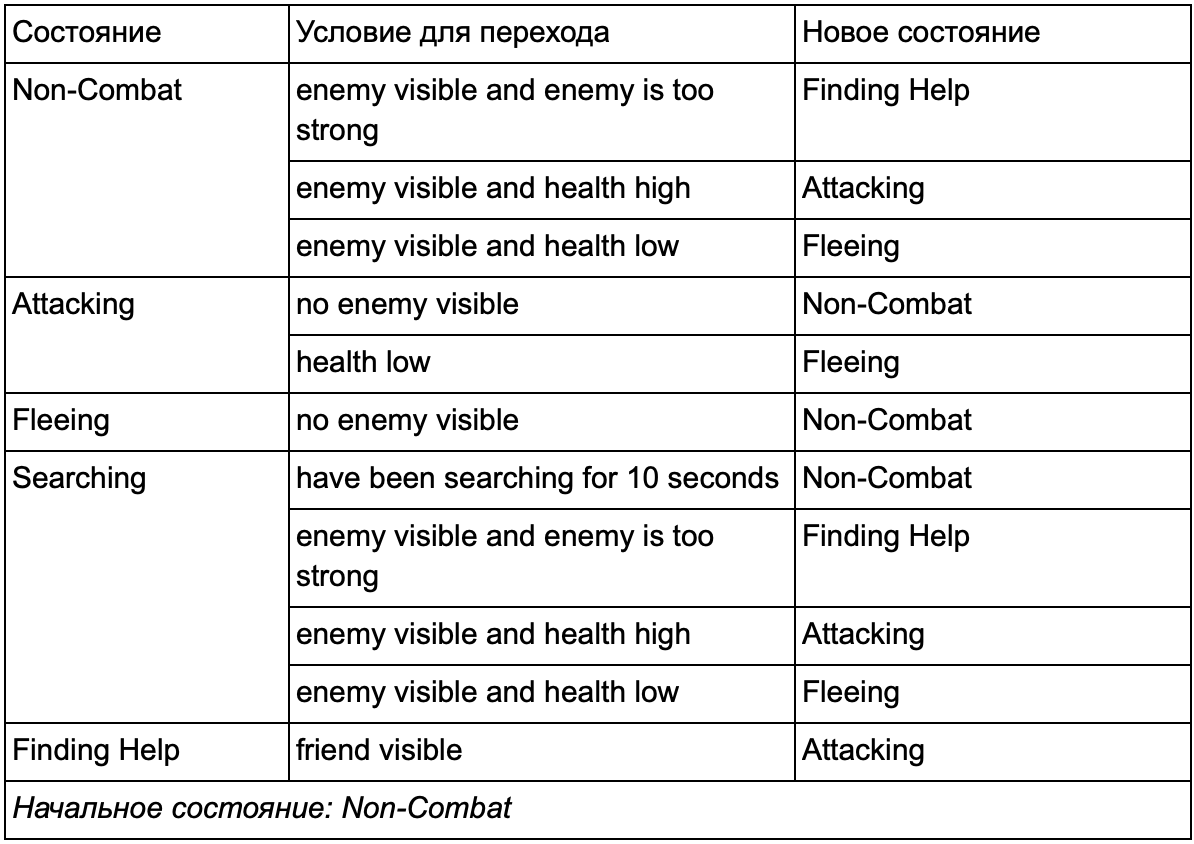 خارج حالة القتال:
خارج حالة القتال:
وفي شكل مخطط:
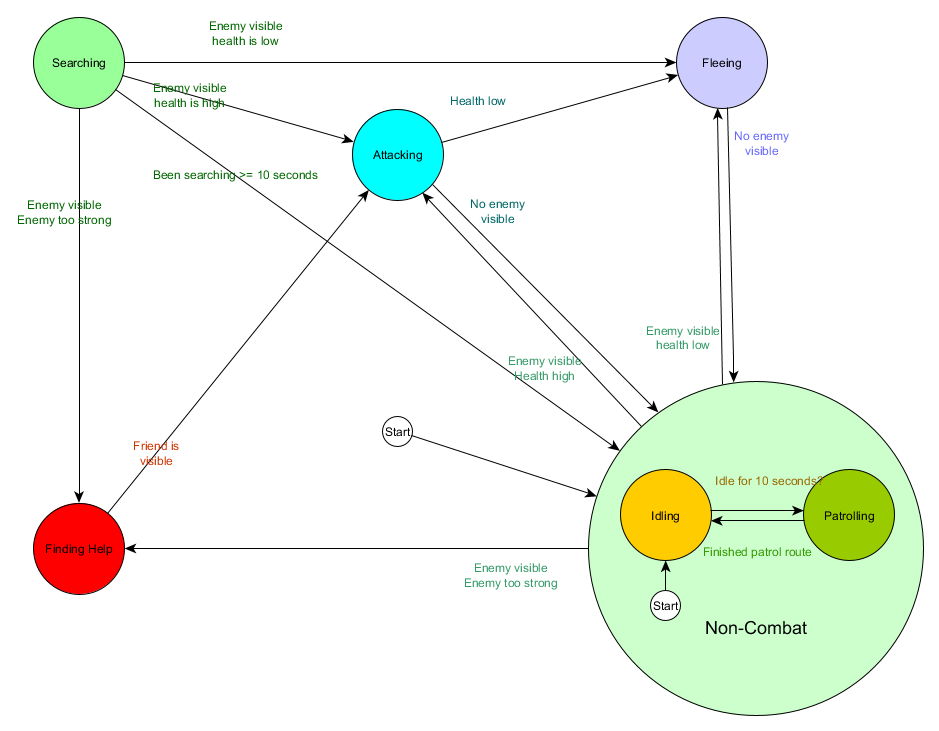
هذا هو نفس النظام ، ولكن مع دولة جديدة غير قتالية ، والتي تشمل التباطؤ والدوريات. مع كل حالة تحتوي على FSMs مع الحالات الفرعية (وهذه الحالات الفرعية ، بدورها ، تحتوي على FSMs الخاصة بهم - وهكذا ، بقدر ما تحتاج) ، نحصل على آلة الحالة المحدودة الهرمية أو HFSM (آلة الحالة الهرمية). بعد أن جمعت دولة غير قتالية ، قطعنا مجموعة من التحولات الزائدة عن الحاجة. يمكننا أن نفعل الشيء نفسه مع أي دول جديدة ذات انتقالات مشتركة. على سبيل المثال ، إذا قمنا في المستقبل بتوسيع حالة الهجوم إلى دولتي MeleeAttacking و MissileAttacking ، فسوف تكون حالات فرعية تعبر بعضها البعض بناءً على المسافة إلى العدو ووجود الذخيرة. ونتيجة لذلك ، يمكن تمثيل النماذج المعقدة للسلوك والنماذج الفرعية للسلوك بحد أدنى من التحولات المكررة.
HFSM . , , . , . . , , . , 25%, , , , — . 25% 10%, .
, « », , . .
, : «» , , , . :
- : Succeeded ( ), Failed ( ) Running ( ).
- . Decorator, . Succeed, .
- , , Running .
. HFSM :
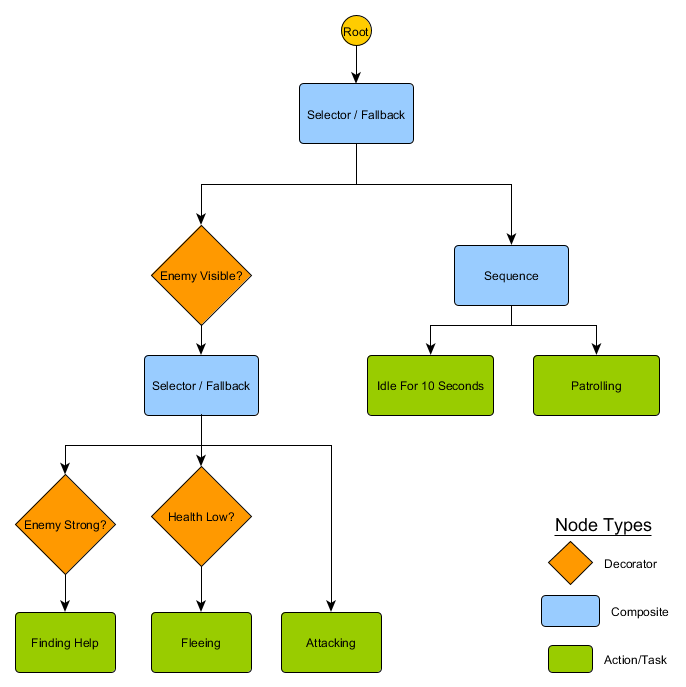
Idling/Patrolling Attacking . , , Fleeing, , — Patrolling, Idling, Attacking .
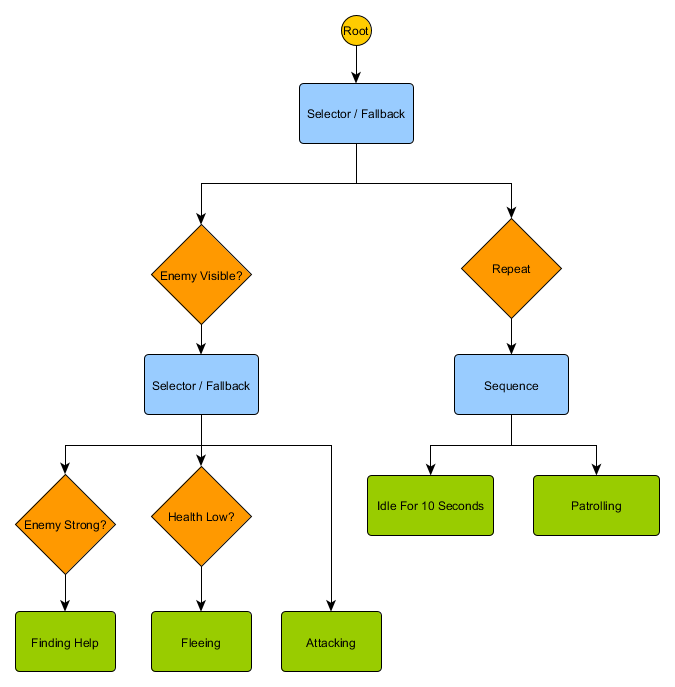
— , . , — , ? , — , Idling 10 , , ?
. , . , .
Utility-based system
. , , . , , .
Utility-based system (, ) . , , , . — , .
, . FSM, , , . , ( , ). , .
— , 0 ( ) 100 ( ). , . :

— . . , , , Fleeing, FindingHelp . FindingHelp . , 50, . .
, . . , Fleeing , , Attacking , . - Fleeing Attacking , , . , , FSM.
. . The Sims, , — «», . , , EatFood , , , EatFood .
, Utility-based system , . . , Utility , , .
, , , . ? , , , , ? .
الإدارة
, , , . , , . . Sense/Think/Act, , Think , Act . , , . — , . , , . :
desired_travel = destination_position – agent_position2D-. (-2,-2), - - (30, 20), , — (32, 22). , — 5 , (4.12, 2.83). 8 .
. , , 5 / ( ), . , .
— , , , . . steering behaviours, : Seek (), Flee (), Arrival () . . , , , .
. Seek Arrival — . Obstacle Avoidance ( ) Separation () , . Alignment () Cohesion () . steering behaviours . , Arrival, Separation Obstacle Avoidance, . .
, — , - Arrival Obstacle Avoidance. , , . : , .
, , - .
Steering behaviours ( ), — . pathfinding ( ), .
— . - , , . . , ( , ). , Breadth-First Search BFS ( ). ( breadth, «»). , , — , , .
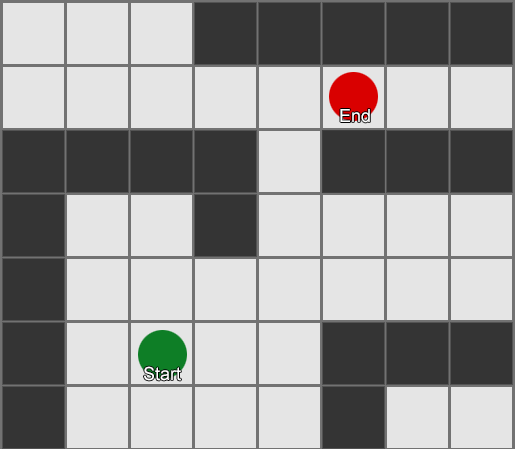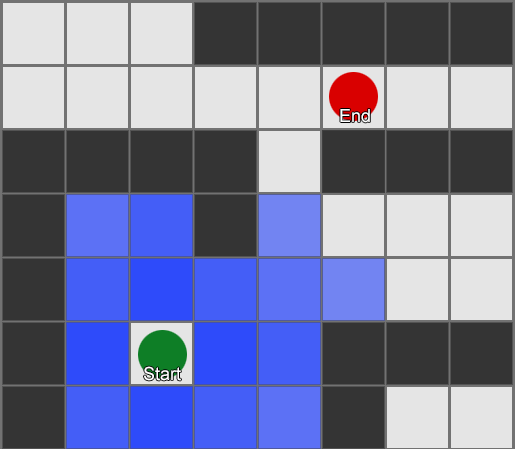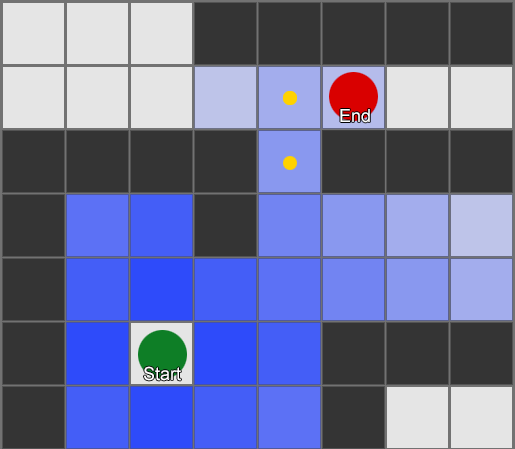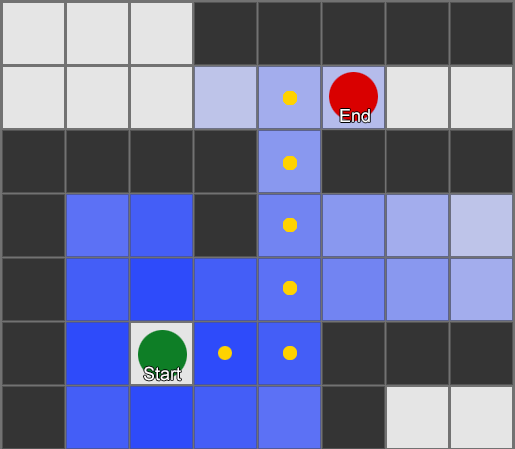
, . (, pathfinding) — , , .
, , steering behaviours, — 1 2, 2 3 . — , — . - .
BFS — «» , «». A* (A star). , - ( , ), , , . , — «» ( ) , ( ).
, , , . , BFS, — .
لكن معظم الألعاب لا يتم وضعها على الشبكة ، وغالبًا لا يمكن القيام بذلك دون المساس بالواقعية. التسويات مطلوبة. ما هو حجم المربعات؟ كبير جدًا - ولن يتمكنوا من تخيل الممرات أو المنعطفات الصغيرة بشكل صحيح ، صغيرة جدًا - سيكون هناك الكثير من المربعات للبحث عنها ، والتي ستستغرق في النهاية الكثير من الوقت.
أول شيء يجب فهمه هو أن الشبكة تعطينا رسمًا بيانيًا للعقد المتصلة. تعمل خوارزميات A * و BFS فعليًا على الرسوم البيانية ولا تهتم بشبكتنا على الإطلاق. يمكننا وضع العقد في أي مكان في عالم اللعبة: إذا كان هناك اتصال بين أي عقدتين متصلتين ، وكذلك بين نقطتي البداية والنهاية وواحدة على الأقل من العقد ، فستعمل الخوارزمية تمامًا كما كانت من قبل. غالبًا ما يسمى هذا نظام نقطة الطريق ، حيث تمثل كل عقدة موقعًا مهمًا في العالم ، والذي يمكن أن يكون جزءًا من أي عدد من المسارات الافتراضية.
 مثال 1: عقدة في كل مربع. يبدأ البحث من العقدة التي يوجد فيها الوكيل ، وينتهي عند عقدة المربع المطلوب.
مثال 1: عقدة في كل مربع. يبدأ البحث من العقدة التي يوجد فيها الوكيل ، وينتهي عند عقدة المربع المطلوب.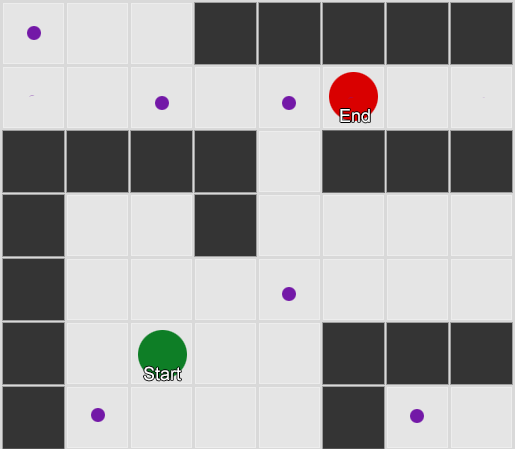 مثال 2: مجموعة أصغر من العقد (نقاط الطريق). يبدأ البحث مربعاً مع الوكيل ، ويمر عبر العدد المطلوب من العقد ، ثم يستمر إلى الوجهة.
مثال 2: مجموعة أصغر من العقد (نقاط الطريق). يبدأ البحث مربعاً مع الوكيل ، ويمر عبر العدد المطلوب من العقد ، ثم يستمر إلى الوجهة.هذا نظام مرن وقوي تمامًا. ولكنك تحتاج إلى بعض الحذر في تحديد مكان وكيفية وضع نقطة الطريق ، وإلا فقد لا يرى العملاء أقرب نقطة ولن يتمكنوا من بدء المسار. سيكون من الأسهل إذا تمكنا تلقائيًا من تعيين نقاط الطريق استنادًا إلى هندسة العالم.
ثم تظهر شبكة التنقل أو navmesh. عادة ما تكون هذه شبكة ثنائية الأبعاد من المثلثات التي تغطي هندسة العالم - أينما سمح للعامل بالسير. يصبح كل من المثلثات في الشبكة عقدة في الرسم البياني ولديه ما يصل إلى ثلاثة مثلثات متجاورة تصبح عُقدًا متجاورة في الرسم البياني.
هذه الصورة هي مثال من محرك الوحدة - لقد حلل الهندسة في العالم وأنشأ نافميش (أزرق فاتح في لقطة الشاشة). كل مضلع في navmesh عبارة عن منطقة يمكن للعامل فيها الوقوف أو الانتقال من مضلع إلى مضلع آخر. في هذا المثال ، تكون المضلعات أصغر من الطوابق التي تقع عليها - مصنوعة من أجل مراعاة أبعاد العامل ، والتي ستتجاوز وضعها الاسمي.

يمكننا البحث في المسار من خلال هذه الشبكة ، مرة أخرى باستخدام خوارزمية A *. سيعطينا هذا مسارًا مثاليًا تقريبًا في العالم يأخذ في الاعتبار جميع الأشكال الهندسية ولا يتطلب نقاطًا ونقاطًا إضافية.
Pathfinding هو موضوع واسع للغاية حول أي قسم من المقالة لا يكفي. إذا كنت ترغب في دراسته بمزيد من التفاصيل ، فإن
موقع Amit Patel سيساعد في ذلك.
التخطيط
لقد تأكدنا من خلال البحث عن المسار أنه في بعض الأحيان لا يكفي فقط اختيار الاتجاه والتحرك - يجب علينا اختيار الطريق وإجراء عدة دورات للوصول إلى الوجهة المطلوبة. يمكننا تلخيص هذه الفكرة: تحقيق الهدف ليس فقط الخطوة التالية ، ولكن تسلسل كامل ، حيث تحتاج في بعض الأحيان إلى النظر إلى الأمام بضع خطوات لمعرفة ما يجب أن يكون الأول. وهذا ما يسمى التخطيط. يمكن اعتبار البحث عن المسار أحد الإضافات التخطيطية العديدة. من منظور دورة الإحساس / التفكير / الفعل ، هذا هو المكان الذي يخطط فيه جزء Think للعديد من أجزاء القانون للمستقبل.
دعونا نلقي نظرة على مثال لعبة الطاولة Magic: The Gathering. نبدأ أولاً بمجموعة من البطاقات في متناول اليد:
- مستنقع - يعطي 1 مانا سوداء (خريطة الأرض).
- غابة - تعطي 1 مانا خضراء (خريطة الأرض).
- معالج الهارب - يتطلب مانا زرقاء واحدة للاستدعاء.
- Elvish Mystic - يتطلب مانا خضراء واحدة للاستدعاء.
نتجاهل البطاقات الثلاث المتبقية لتسهيل الأمر. وفقًا للقواعد ، يُسمح للاعب بلعب بطاقة واحدة من الأرض لكل دور ، ويمكنه "النقر" على هذه البطاقة لاستخراج المانا منها ، ثم استخدام التعويذات (بما في ذلك استدعاء المخلوقات) وفقًا لكمية المانا. في هذه الحالة ، يعرف اللاعب البشري أنك بحاجة إلى لعب لعبة Forest ، "اضغط" على مانا خضراء ، ثم اتصل بـ Elvish Mystic. ولكن كيف يمكنك تخمين لعبة الذكاء الاصطناعي؟
تخطيط سهل
النهج التافه هو محاولة كل عمل بدوره حتى تكون هناك إجراءات مناسبة. بالنظر إلى البطاقات ، ترى منظمة العفو الدولية ما يمكن أن يلعبه Swamp. ويلعبها. هل هناك أي إجراءات أخرى تركت هذا المنعطف؟ لا يمكنه استدعاء Elvish Mystic أو Fugitive Wizard ، حيث تتطلب استدعاءاتهم مانا خضراء وزرقاء على التوالي ، ويعطي Swamp مانا سوداء فقط. ولن يتمكن من لعب الغابة ، لأنه لعب Swamp بالفعل. وهكذا ، خضعت لعبة الذكاء الاصطناعي للقواعد ، لكنها فعلت ذلك بشكل سيئ. يمكن تحسينه.
يمكن أن يجد التخطيط قائمة بالإجراءات التي تجعل اللعبة في حالتها المرغوبة. تمامًا كما كان لكل مربع على المسار جيران (في تحديد المسار) ، فإن كل إجراء في الخطة له جيران أو خلفاء. يمكننا البحث عن هذه الإجراءات والإجراءات اللاحقة حتى نصل إلى الحالة المطلوبة.
في مثالنا ، النتيجة المرجوة هي "استدعاء مخلوق إن أمكن". في بداية الحركة ، نرى فقط إجراءين محتملين يسمح بهما قواعد اللعبة:
1. لعب Swamp (النتيجة: Swamp in the game)
2. لعب الغابة (النتيجة: غابة في اللعبة)يمكن أن يؤدي كل إجراء يتم اتخاذه إلى مزيد من الإجراءات وإغلاق الإجراءات الأخرى ، مرة أخرى ، وفقًا لقواعد اللعبة. تخيل أننا لعبنا Swamp - سيؤدي ذلك إلى إزالة Swamp كخطوة تالية (لعبناها بالفعل) ، سيؤدي أيضًا إلى حذف Forest (لأنه وفقًا للقواعد ، يمكنك تشغيل خريطة واحدة للأرض في كل دور). بعد ذلك ، يضيف AI كخطوة تالية - الحصول على مانا سوداء واحدة ، لأنه لا توجد خيارات أخرى. إذا ذهب أبعد واختار Tap the Swamp ، فسوف يتلقى وحدة واحدة من mana الأسود ولا يمكنه فعل أي شيء بها.
1. لعب Swamp (النتيجة: Swamp in the game)
1.1 مستنقع "Tap" (النتيجة: Swamp "tap" ، +1 وحدة من المانا السوداء)
لا توجد إجراءات متاحة - END
2. لعب الغابة (النتيجة: غابة في اللعبة)كانت قائمة الإجراءات قصيرة ، نحن في طريق مسدود. كرر العملية للخطوة التالية. نلعب Forest ، نفتح الإجراء "احصل على مانا خضراء واحدة" ، والتي بدورها ستفتح الإجراء الثالث - دعوة Elvish Mystic.
1. لعب Swamp (النتيجة: Swamp in the game)
1.1 مستنقع "Tap" (النتيجة: Swamp "tap" ، +1 وحدة من المانا السوداء)
لا توجد إجراءات متاحة - END
2. لعب الغابة (النتيجة: غابة في اللعبة)
2.1 غابة "Tap" (النتيجة: Forest "tap" ، +1 وحدة مانا خضراء)
2.1.1 استدعاء Elvish Mystic (النتيجة: Elvish Mystic في اللعبة ، -1 وحدة من مانا الخضراء)
لا توجد إجراءات متاحة - ENDأخيرًا ، فحصنا جميع الإجراءات الممكنة ووجدنا خطة تدعو المخلوق.
هذا مثال مبسط للغاية. من المستحسن اختيار أفضل خطة ممكنة ، وليس أي خطة تلبي بعض المعايير. كقاعدة ، يمكنك تقييم الخطط المحتملة بناءً على النتيجة النهائية أو الفوائد الإجمالية لتنفيذها. يمكنك إضافة نقطة واحدة للعب خريطة الأرض و 3 نقاط لتحدي مخلوق. لعب Swamp سيكون خطة تعطي نقطة واحدة. ولعب الغابة → اضغط على الغابة → اتصل على Elvish Mystic - سيعطي فورًا 4 نقاط.
هذه هي الطريقة التي يعمل بها التخطيط في Magic: The Gathering ، ولكن من نفس المنطق ينطبق على المواقف الأخرى. على سبيل المثال ، حرك البيدق لإفساح المجال أمام الأسقف للتحرك في الشطرنج. أو احتموا خلف حائط لإطلاق النار بأمان على XCOM من هذا القبيل. بشكل عام ، تحصل على النقطة.
تحسين التخطيط
في بعض الأحيان يكون هناك الكثير من الإجراءات المحتملة للنظر في كل خيار ممكن. بالعودة إلى المثال مع Magic: The Gathering: لنفترض أنه في اللعبة وعلى يديك هناك العديد من بطاقات الأرض والمخلوقات - يمكن أن يكون عدد المجموعات المحتملة من الحركات في العشرات. هناك العديد من الحلول للمشكلة.
الطريقة الأولى هي التسلسل إلى الوراء. بدلاً من فرز جميع المجموعات ، من الأفضل البدء بالنتيجة النهائية ومحاولة العثور على طريق مباشر. بدلاً من المسار من جذر الشجرة إلى ورقة معينة ، نتحرك في الاتجاه المعاكس - من الورقة إلى الجذر. هذه الطريقة أبسط وأسرع.
إذا كان لدى الخصم وحدة صحية واحدة ، يمكنك العثور على خطة "لإلحاق وحدة أو أكثر من الضرر". لتحقيق ذلك ، يجب استيفاء عدد من الشروط:
1. يمكن أن يكون الضرر ناتجًا عن التعويذة - يجب أن يكون في اليد.
2. لإلقاء تعويذة ، تحتاج مانا.
3. للحصول على المانا ، تحتاج إلى لعب بطاقة الأرض.
4. للعب بطاقة الأرض - تحتاج إلى أن تكون في يدك.
طريقة أخرى هي البحث الأفضل أولاً. بدلاً من المرور عبر جميع المسارات ، نختار أنسبها. في معظم الأحيان ، تعطي هذه الطريقة خطة مثالية دون تكاليف بحث غير ضرورية. A * هو شكل البحث الأول الأفضل - من خلال استكشاف المسارات الواعدة منذ البداية ، يمكنه بالفعل العثور على أفضل طريقة دون الحاجة إلى التحقق من الخيارات الأخرى.
يعد Monte Carlo Tree Search خيارًا مثيرًا للاهتمام وشائعًا بشكل متزايد للبحث الأفضل أولاً. بدلاً من تخمين الخطط الأفضل من غيرها عند اختيار كل إجراء لاحق ، تختار الخوارزمية خلفاء عشوائيين في كل خطوة حتى تصل إلى النهاية (عندما تؤدي الخطة إلى النصر أو الهزيمة). ثم يتم استخدام النتيجة النهائية لزيادة أو إنقاص وزن الوزن للخيارات السابقة. بتكرار هذه العملية عدة مرات متتالية ، تعطي الخوارزمية تقديرًا جيدًا للخطوة التالية الأفضل ، حتى إذا تغير الموقف (إذا اتخذ الخصم تدابير لمنع اللاعب).
لن تدور قصة التخطيط في الألعاب بدون التخطيط للعمل الموجه نحو الهدف أو GOAP (تخطيط العمل الموجه نحو الهدف). هذه طريقة مستخدمة ومناقشة على نطاق واسع ، ولكن إلى جانب بعض التفاصيل المميزة ، فهي في الأساس طريقة التسلسل العكسي التي تحدثنا عنها سابقًا. إذا كانت المهمة هي "تدمير اللاعب" ، وكان اللاعب خلف الغطاء ، فقد تكون الخطة هي: التدمير بقنبلة يدوية → الحصول عليها → إسقاطها.
عادة ما يكون هناك العديد من الأهداف ، لكل منها أولوياته الخاصة. إذا تعذر إكمال الهدف ذو الأولوية القصوى (لا توجد مجموعة من الإجراءات تنشئ خطة "لتدمير اللاعب" لأن اللاعب غير مرئي) ، سيعود الذكاء الاصطناعي إلى الأهداف ذات الأولوية الأقل.
التدريب والتكيف
قلنا بالفعل أن الذكاء الاصطناعي للألعاب لا يستخدم عادةً التعلم الآلي لأنه غير مناسب لإدارة الوكلاء في الوقت الفعلي. لكن هذا لا يعني أنه لا يمكنك استعارة أي شيء من هذه المنطقة. نريد مثل هذا الخصم في مطلق النار يمكننا من خلاله تعلم شيء ما. على سبيل المثال ، تعرف على أفضل المواضع على الخريطة. أو خصم في لعبة قتال من شأنها أن تمنع الحيل السرد المستخدمة بشكل متكرر من قبل اللاعب ، وتحفيز الآخرين على استخدامها. لذا يمكن أن يكون التعلم الآلي في مثل هذه المواقف مفيدًا جدًا.
الإحصائيات والاحتمالات
قبل أن ننتقل إلى الأمثلة المعقدة ، سوف نقدر إلى أي مدى يمكننا أن نذهب من خلال أخذ بعض القياسات البسيطة واستخدامها لاتخاذ القرارات. على سبيل المثال ، إستراتيجية في الوقت الفعلي - كيف يمكننا تحديد ما إذا كان يمكن للاعب شن هجوم في الدقائق القليلة الأولى من اللعبة وما هو الدفاع الذي يجب الاستعداد له ضد هذا؟ يمكننا دراسة تجربة اللاعب السابقة لفهم رد الفعل المستقبلي. بادئ ذي بدء ، ليس لدينا مثل هذه البيانات الأولية ، ولكن يمكننا جمعها - في كل مرة يلعب فيها الذكاء الاصطناعي ضد شخص ما ، يمكنه تسجيل وقت الهجوم الأول. بعد عدة جلسات ، سنحصل على متوسط الوقت الذي سيهاجم فيه اللاعب في المستقبل.
متوسط القيم لديه مشكلة: إذا "قرر" اللاعب 20 مرة ولعب ببطء 20 مرة ، فإن القيم الضرورية ستكون في مكان ما في الوسط ، وهذا لن يعطينا أي شيء مفيد. حل واحد هو الحد من المدخلات - يمكنك التفكير في آخر 20 قطعة.
يتم استخدام نهج مماثل لتقييم احتمالية بعض الإجراءات ، على افتراض أن تفضيلات اللاعب السابقة ستكون هي نفسها في المستقبل. إذا هاجمنا اللاعب خمس مرات بكرة نارية ، ومرتين بالبرق ومرة بالقتال باليد ، فمن الواضح أنه يفضل كرة نارية. نستنبط ونرى احتمال استخدام أسلحة مختلفة: كرة نارية = 62.5٪ ، برق = 25٪ ومشاجرة = 12.5٪. تحتاج لعبتنا AI للتحضير للحماية من الحرائق.
طريقة أخرى مثيرة للاهتمام هي استخدام Naive Bayes Classifier (مصنف بايزي ساذج) لدراسة كميات كبيرة من بيانات الإدخال وتصنيف الموقف بحيث يستجيب الذكاء الاصطناعي بالطريقة الصحيحة. تشتهر مصنّفات بايزي باستخدام مرشحات البريد الإلكتروني العشوائي. هناك ، يبحثون عن الكلمات ويقارنونها بالمكان الذي ظهرت فيه هذه الكلمات في وقت سابق (في البريد العشوائي أم لا) ، ويستخلصون استنتاجات حول الحروف الواردة. يمكننا أن نفعل الشيء نفسه حتى مع إدخال أقل. استنادًا إلى جميع المعلومات المفيدة التي يراها الذكاء الاصطناعي (على سبيل المثال ، ما هي وحدات العدو التي يتم إنشاؤها ، أو التعويذات التي يستخدمونها ، أو ما هي التقنيات التي اكتشفوها) ، والنتيجة النهائية (الحرب أو السلام ، "سحق" أو الدفاع ، إلخ.) - سنختار سلوك الذكاء الاصطناعي المطلوب.
جميع طرق التدريب هذه كافية ، ولكن يُنصح باستخدامها بناءً على بيانات من الاختبار. سيتعلم الذكاء الاصطناعي كيفية التكيف مع الاستراتيجيات المختلفة التي استخدمها مختبرو اللعب. الذكاء الاصطناعي الذي يتكيف مع اللاعب بعد الإصدار يمكن أن يصبح متوقعًا للغاية ، أو العكس ، معقد للغاية بحيث لا يمكن الفوز به.
التكيف القائم على القيمة
نظرًا لمحتوى عالم اللعبة والقواعد ، يمكننا تغيير مجموعة القيم التي تؤثر على عملية صنع القرار ، وليس فقط استخدام بيانات الإدخال. نقوم بذلك:
- اسمح للذكاء الاصطناعي بجمع بيانات عن حالة العالم والأحداث الرئيسية أثناء اللعبة (كما هو موضح أعلاه).
- دعنا نغير بعض القيم المهمة بناءً على هذه البيانات.
- ندرك قراراتنا بناء على معالجة أو تقييم هذه القيم.
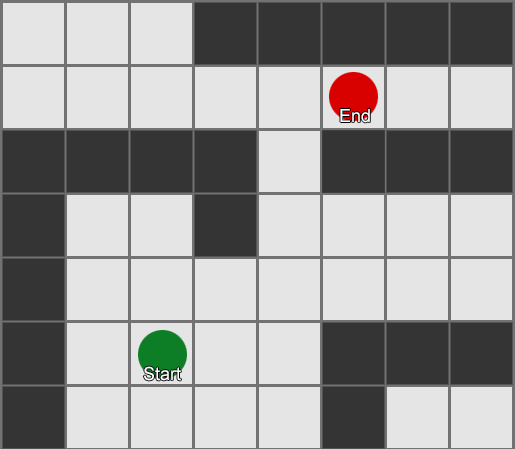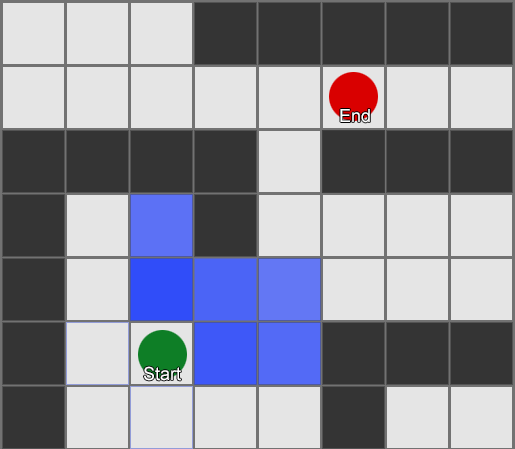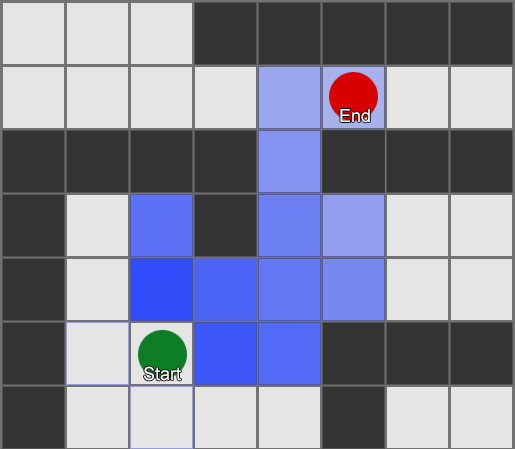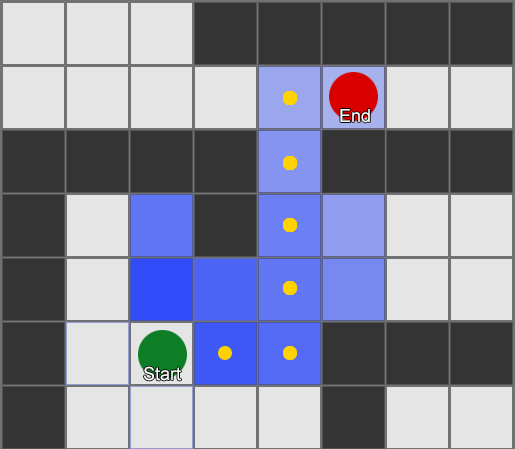
على سبيل المثال ، لدى الوكيل عدة غرف لاختيار مطلق النار من منظور الشخص الأول على الخريطة. كل غرفة لها قيمتها الخاصة ، والتي تحدد مدى الرغبة في زيارتها. يختار الذكاء الاصطناعي بشكل عشوائي أي غرفة يجب أن يذهب إليها بناءً على قيمة القيمة. ثم يتذكر الوكيل الغرفة التي قتل فيها ، ويقلل من قيمتها (احتمال عودته إلى هناك). وبالمثل بالنسبة للحالة العكسية - إذا دمر الوكيل العديد من المعارضين ، فإن قيمة الغرفة تزداد.
نموذج ماركوف
ماذا لو استخدمنا البيانات المجمعة للتنبؤ؟ إذا تذكرنا كل غرفة نرى فيها اللاعب لفترة معينة من الزمن ، فسوف نتنبأ بالغرفة التي يمكن أن يدخل فيها اللاعب. من خلال تتبع وتسجيل حركة اللاعب في الغرف (القيم) ، يمكننا التنبؤ بها.
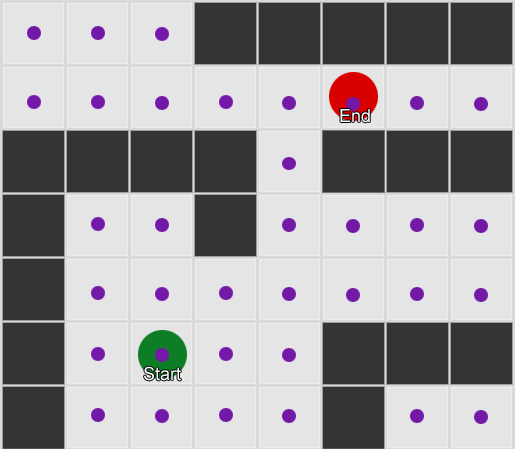
لنأخذ ثلاث غرف: الأحمر والأخضر والأزرق. بالإضافة إلى الملاحظات التي سجلناها عند مشاهدة جلسة اللعب:
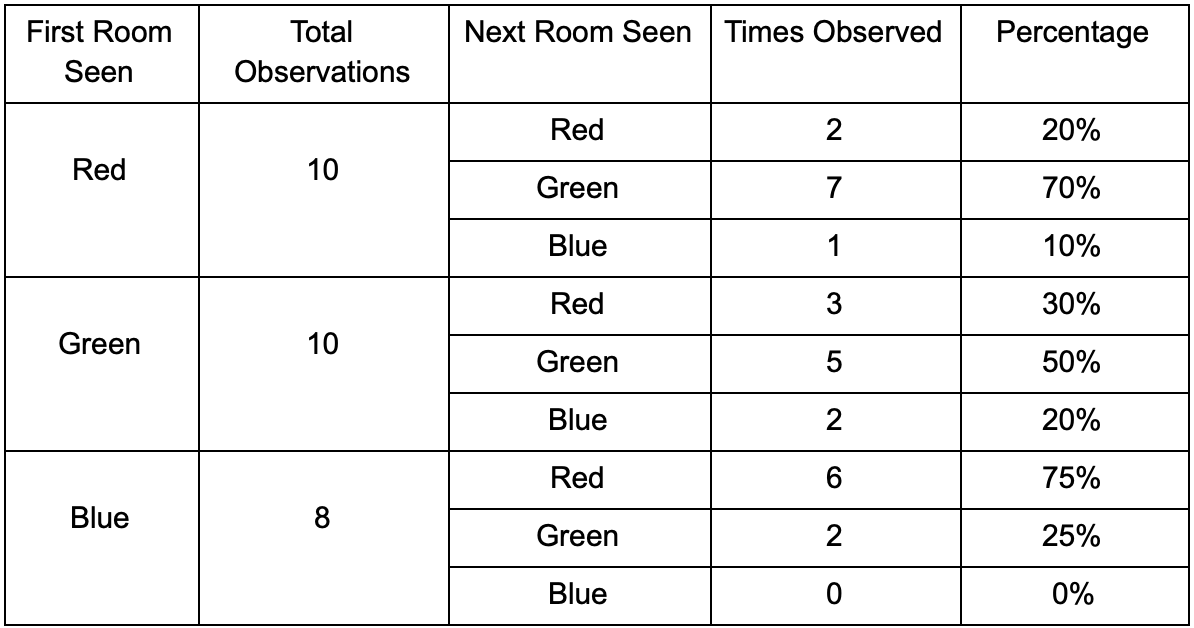
عدد المشاهدات لكل غرفة متساوٍ تقريبًا - ما زلنا لا نعرف أين نوفر مكانًا جيدًا للكمائن. كما أن جمع الإحصاءات معقد بسبب إعادة ظهور اللاعبين الذين يظهرون بالتساوي في جميع أنحاء الخريطة. لكن البيانات الموجودة في الغرفة التالية ، والتي يدخلونها بعد ظهورها على الخريطة ، مفيدة بالفعل.
يمكن ملاحظة أن الغرفة الخضراء مناسبة للاعبين - معظم الناس من اللون الأحمر يذهبون إليها ، وتبقى 50 ٪ منهم هناك وأكثر. على العكس من ذلك ، لا تحظى الغرفة الزرقاء بشعبية ، ولا يتم زيارتها مطلقًا تقريبًا ، وإذا كانت كذلك ، فإنها لا تزال قائمة.
لكن البيانات تخبرنا بشيء أكثر أهمية - عندما يكون اللاعب في الغرفة الزرقاء ، فإن الغرفة التالية التي سنراها فيها على الأرجح ستكون حمراء ، وليست خضراء. على الرغم من حقيقة أن الغرفة الخضراء أكثر شعبية من الغرفة الحمراء ، يتغير الوضع إذا كان اللاعب باللون الأزرق. تعتمد الحالة التالية (أي الغرفة التي سيدخلها اللاعب) على الحالة السابقة (أي الغرفة التي يوجد فيها اللاعب الآن). نظرًا لدراسة التبعيات ، سنقوم بعمل التنبؤات بدقة أكثر مما لو قمنا ببساطة بحساب الملاحظات بشكل مستقل عن بعضها البعض.
يُطلق على توقع حالة مستقبلية استنادًا إلى بيانات الحالة السابقة نموذج ماركوف ، وتسمى هذه الأمثلة (مع الغرف) سلاسل ماركوف. نظرًا لأن النماذج تمثل احتمالية حدوث تغييرات بين الحالات المتتالية ، يتم عرضها بصريًا على أنها FSMs مع احتمال بالقرب من كل انتقال. في السابق ، استخدمنا FSM لتمثيل الحالة السلوكية التي يوجد فيها الوكيل ، ولكن هذا المفهوم ينطبق على أي حالة ، بغض النظر عما إذا كانت مرتبطة بالوكيل أم لا. في هذه الحالة ، تمثل الولايات الغرفة التي يشغلها الوكيل:
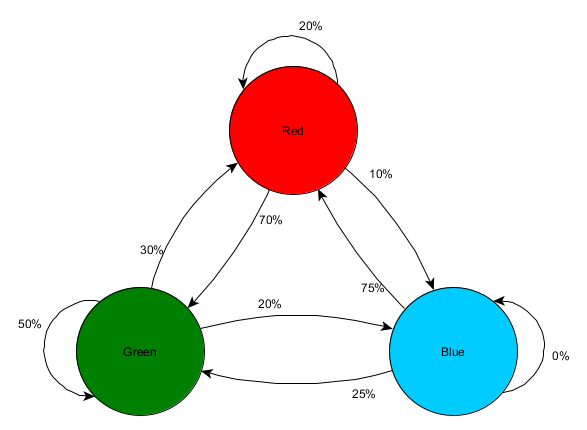
هذه نسخة بسيطة من تمثيل الاحتمال النسبي للتغييرات في الولايات ، مما يمنح الذكاء الاصطناعي بعض الفرص للتنبؤ بالحالة التالية. يمكنك التنبؤ بخطوات قليلة إلى الأمام.
إذا كان اللاعب في الغرفة الخضراء ، فهناك احتمال بنسبة 50٪ أن يبقى هناك خلال الملاحظة التالية. ولكن ما هو احتمال بقاءه هناك حتى بعد ذلك؟ لا توجد فرصة فقط لبقاء اللاعب في الغرفة الخضراء بعد ملاحظتين ، ولكن هناك أيضًا فرصة لمغادرته والعودة. فيما يلي الجدول الجديد بالبيانات الجديدة:
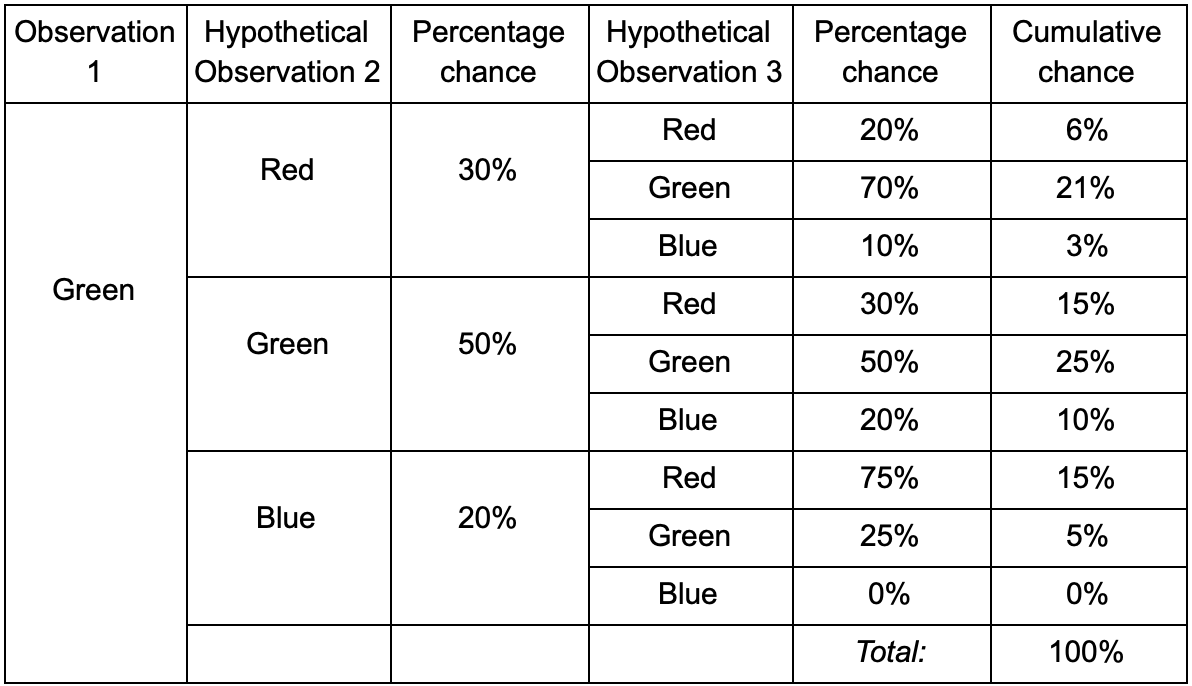
يظهر أن فرصة رؤية لاعب في الغرفة الخضراء بعد ملاحظتين ستكون 51٪ - 21٪ ، أنه سيأتي من الغرفة الحمراء ، 5٪ منهم ، أن اللاعب سيزور الغرفة الزرقاء بينهما ، و 25٪ ، أن اللاعب لا سيغادر الغرفة الخضراء.
الجدول هو مجرد أداة بصرية - يتطلب الإجراء فقط مضاعفة الاحتمالات في كل خطوة. هذا يعني أنه يمكنك النظر إلى المستقبل من خلال تعديل واحد: نفترض أن فرصة دخول غرفة تعتمد بشكل كامل على الغرفة الحالية. وهذا ما يسمى بخاصية ماركوف - فالدولة المستقبلية تعتمد فقط على الحاضر. لكن هذا ليس دقيقًا تمامًا. يمكن للاعبين اتخاذ قرارات اعتمادًا على عوامل أخرى: المستوى الصحي أو كمية الذخيرة. نظرًا لأننا لا نصلح هذه القيم ، فإن توقعاتنا ستكون أقل دقة.
ن غرامات
- ? ! , , -.
— (, Kick, Punch Block) . , Kick, Kick, Punch, SuperDeathFist, , .
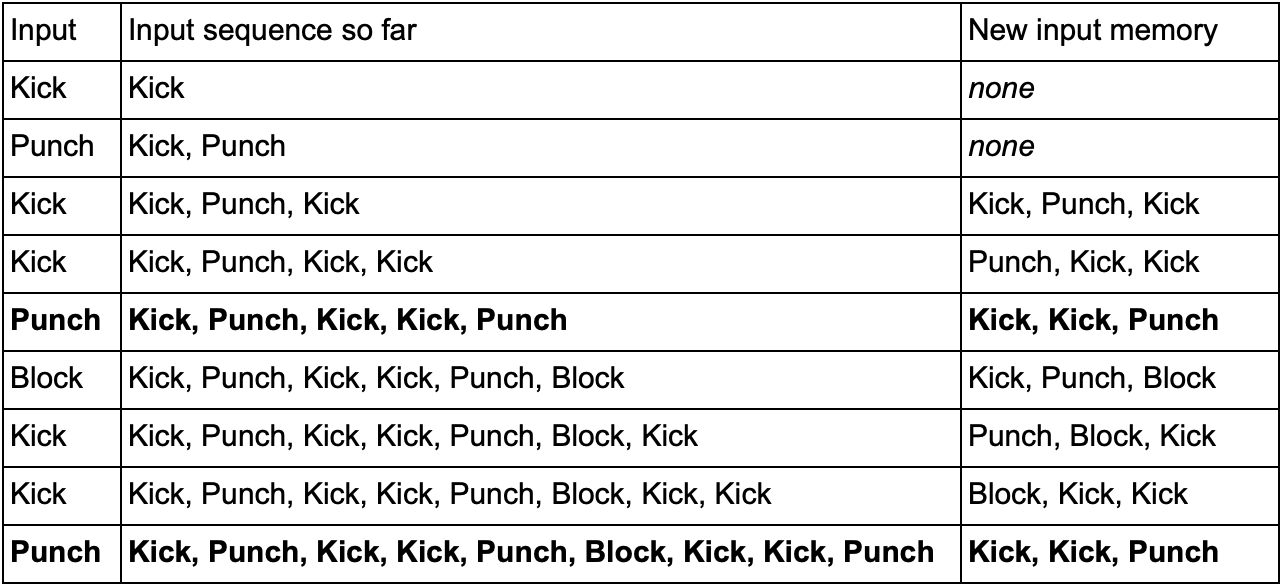
( , SuperDeathFist.)
, Kick, Kick, , Punch. - SuperDeathFist , .
N- (N-grams), N — . 3- (), : . 5- .
N-. N , . , 2- () Kick, Kick Kick, Punch, Kick, Kick, Punch, SuperDeathFist.
, , . Kick, Punch Block, 10-, 60 .
— « / » , . 3- N- , ( N-) , — . Kick Kick Kick Punch. , , , . , , - .
الخلاصة
. , .
. , , . , :
- , ,
- / (minimax alpha-beta pruning)
- (, )
- ( , )
- ( )
- ( , anytime, timeslicing)
- :
1. GameDev.net
,
.
2.
AiGameDev.com .
3.
The GDC Vault GDC AI, .
4.
AI Game Programmers Guild .
5. , , YouTube-
AI and Games .
:
1. Game AI Pro , , .
Game AI Pro: Collected Wisdom of Game AI ProfessionalsGame AI Pro 2: Collected Wisdom of Game AI ProfessionalsGame AI Pro 3: Collected Wisdom of Game AI Professionals2. AI Game Programming Wisdom — Game AI Pro. , .
AI Game Programming Wisdom 1AI Game Programming Wisdom 2AI Game Programming Wisdom 3AI Game Programming Wisdom 43.
Artificial Intelligence: A Modern Approach — . — .