مرحبا بالجميع!
لقد فتحنا تدفقًا جديدًا لدورة
التعلم الآلي ، لذا انتظر في المستقبل القريب المقالات المتعلقة بهذا ، إذا جاز التعبير ، الانضباط. حسنا ، بالطبع ، ندوات مفتوحة. الآن دعونا نلقي نظرة على ما هو التعلم المعزز.
التعلم المعزز هو شكل مهم من أشكال التعلم الآلي ، حيث يتعلم الوكيل التصرف في بيئة من خلال تنفيذ الإجراءات ورؤية النتائج.
في السنوات الأخيرة ، شهدنا العديد من النجاحات في هذا المجال الرائع للبحث. على سبيل المثال ،
DeepMind و Deep Q Learning Architecture في 2014 ،
هزيمة بطل Go مع AlphaGo في 2016 ،
OpenAI و PPO في 2017 ، من بين آخرين.
 DeepMind DQN
DeepMind DQNفي هذه السلسلة من المقالات ، سنركز على دراسة الهياكل المختلفة المستخدمة اليوم لحل مشكلة التعلم المعزز. وتشمل هذه التعلم Q ، والتعلم العميق Q ، والتدرج السياسات ، والنقد الفاعل ، و PPO.
في هذه المقالة سوف تتعلم:
- ما هو التعلم المعزز ولماذا تعتبر المكافآت فكرة مركزية
- ثلاثة مناهج التعلم التعزيزي
- ماذا يعني "العميق" في التعلم المعزز العميق
من المهم جدًا إتقان هذه الجوانب قبل الانغماس في تنفيذ عوامل التعلم المعزز.
إن فكرة التدريب التعزيزي هي أن الوكيل سوف يتعلم من البيئة من خلال التفاعل معه والحصول على مكافآت لأداء الإجراءات.

التعلم من خلال التفاعل مع البيئة يأتي من تجربتنا الطبيعية. تخيل أنك طفل في غرفة المعيشة. ترى الموقد وتذهب إليه.
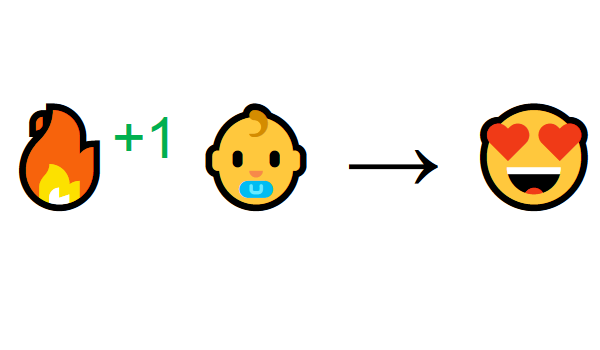
بالقرب من الحارة ، تشعر بالارتياح (مكافأة إيجابية +1). أنت تفهم أن النار شيء إيجابي.
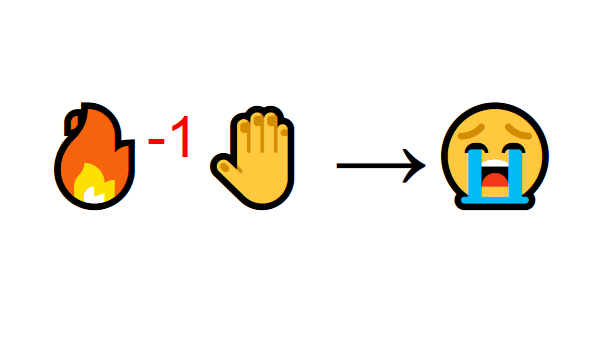
ولكن بعد ذلك تحاول لمس النار. عذرًا! أحرق يده (مكافأة سلبية -1). لقد أدركت للتو أن الحريق إيجابي عندما تكون على مسافة كافية لأنه ينتج حرارة. ولكن إذا اقتربت منه ، فسوف تحترق.
هكذا يتعلم الناس من خلال التفاعل. التعلم المعزز هو ببساطة طريقة حسابية للتعلم من خلال العمل.
عملية التعلم التعزيز

كمثال ، تخيل وكيل يتعلم لعب سوبر ماريو بروس. يمكن نمذجة عملية التعلم التعزيزي (RL) كدورة تعمل على النحو التالي:
- يتلقى الوكيل الحالة S0 من البيئة (في حالتنا ، نحصل على الإطار الأول للعبة (الحالة) من Super Mario Bros (بيئة))
- بناءً على هذه الحالة S0 ، يتخذ الوكيل الإجراء A0 (سينتقل الوكيل إلى اليمين)
- تنتقل البيئة إلى حالة جديدة S1 (إطار جديد)
- البيئة تمنح بعض المكافآت لعامل R1 (لم يمت: +1)
تنتج دورة RL هذه سلسلة من
الحالات والإجراءات والمكافآت.هدف الوكيل هو تعظيم المكافآت المتراكمة المتوقعة.
فرضيات مكافأة الفكرة المركزيةلماذا هدف الوكيل بتعظيم المكافآت المتراكمة المتوقعة؟ حسنًا ، يعتمد التعلم المعزز على فكرة فرضية المكافأة. يمكن وصف جميع الأهداف من خلال زيادة المكافآت المتراكمة المتوقعة.
لذلك ، في التدريب التعزيزي ، من أجل تحقيق أفضل السلوك ، نحتاج إلى زيادة المكافآت المتراكمة المتوقعة.يمكن كتابة المكافأة المتراكمة في كل خطوة زمنية على النحو التالي:

وهذا يعادل:
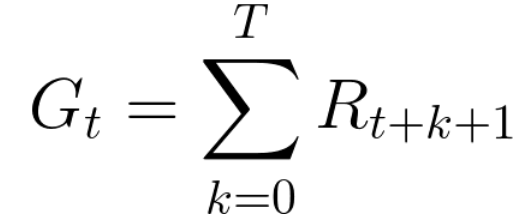
ومع ذلك ، في الواقع ، لا يمكننا ببساطة إضافة هذه المكافآت. المكافآت التي تصل مبكرًا (في بداية اللعبة) أكثر احتمالًا ، حيث يمكن توقعها أكثر من المكافآت في المستقبل.

افترض أن وكيلك هو فأر صغير وأن خصمك قطة. هدفك هو تناول أكبر قدر ممكن من الجبن قبل أن يأكلك القط. كما نرى في الرسم البياني ، من المرجح أن يأكل الفأر الجبن بجانبه أكثر من الجبن بالقرب من القط (كلما اقتربنا منه ، كلما كان أكثر خطورة).
ونتيجة لذلك ، سيتم تخفيض مكافأة القط ، حتى إذا كانت أكبر (المزيد من الجبن). لسنا متأكدين من أنه يمكننا أكله. لتقليل الأجر ، نقوم بما يلي:
- نحدد معدل الخصم يسمى جاما. يجب أن تكون بين 0 و 1.
- كلما كبر حجم جاما ، انخفض الخصم. وهذا يعني أن الوكيل التعليمي أكثر اهتمامًا بالمكافآت طويلة المدى.
- من ناحية أخرى ، كلما كان جاما أصغر ، كلما زاد الخصم. هذا يعني أن الأولوية تعطى للمكافآت قصيرة المدى (أقرب الجبن).
إن المقابل المتوقع المتراكم ، مع مراعاة الخصم ، هو كما يلي:
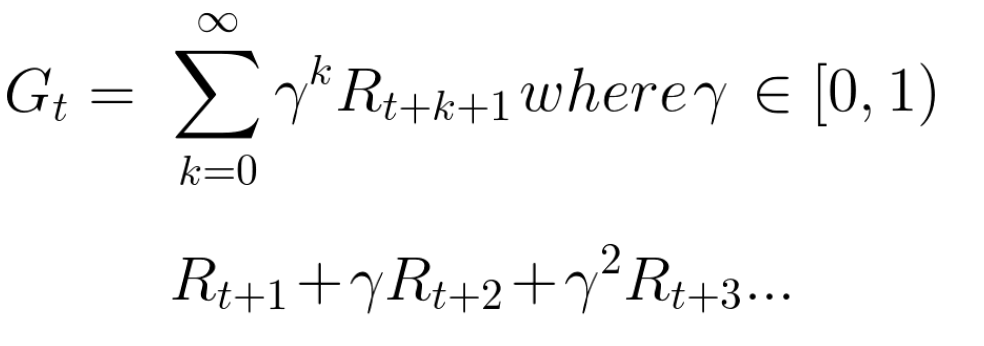
تحدث تقريبًا ، سيتم تخفيض كل مكافأة باستخدام غاما لمؤشر الوقت. كلما زادت الخطوة الزمنية ، أصبحت القطة أقرب إلينا ، لذا أصبحت المكافأة المستقبلية أقل وأقل احتمالية.
المهام العرضية أو المستمرةالمهمة هي مثال على مشكلة التعلم مع التعزيز. يمكن أن يكون لدينا نوعان من المهام: عرضية ومتواصلة.
مهمة عرضيةفي هذه الحالة ، لدينا نقطة بداية ونقطة نهاية
(حالة نهائية). يؤدي هذا إلى إنشاء حلقة : قائمة بالدول والإجراءات والمكافآت والولايات الجديدة.
خذ Super Mario Bros على سبيل المثال: تبدأ الحلقة بإطلاق Mario الجديد وتنتهي عندما تقتل أو تصل إلى نهاية المستوى.
 بداية حلقة جديدةالمهام المستمرةهذه مهام تستمر إلى الأبد (بدون حالة نهائية)
بداية حلقة جديدةالمهام المستمرةهذه مهام تستمر إلى الأبد (بدون حالة نهائية) . في هذه الحالة ، يجب أن يتعلم الوكيل كيفية اختيار أفضل الإجراءات وأن يتفاعل في نفس الوقت مع البيئة.
على سبيل المثال ، وكيل يقوم بتداول الأسهم الآلي. لا توجد نقطة بداية وحالة نهائية لهذه المهمة.
يستمر الوكيل في العمل حتى نقرر إيقافه. مونتي كارلو مقابل طريقة اختلاف الوقت
مونتي كارلو مقابل طريقة اختلاف الوقتهناك طريقتان للتعلم:
- جمع المكافآت في نهاية الحلقة ثم حساب الحد الأقصى للمكافآت المستقبلية المتوقعة - منهج مونت كارلو
- تقييم المكافآت في كل خطوة - فرق مؤقت
مونتي كارلوعندما تنتهي الحلقة (يصل الوكيل إلى "حالة نهائية") ، ينظر الوكيل في إجمالي المكافأة المتراكمة لمعرفة مدى أدائه. في نهج مونتي كارلو ، يتم تلقي المكافآت فقط في نهاية اللعبة.
ثم نبدأ لعبة جديدة مع زيادة المعرفة.
يقوم الوكيل باتخاذ أفضل القرارات مع كل تكرار.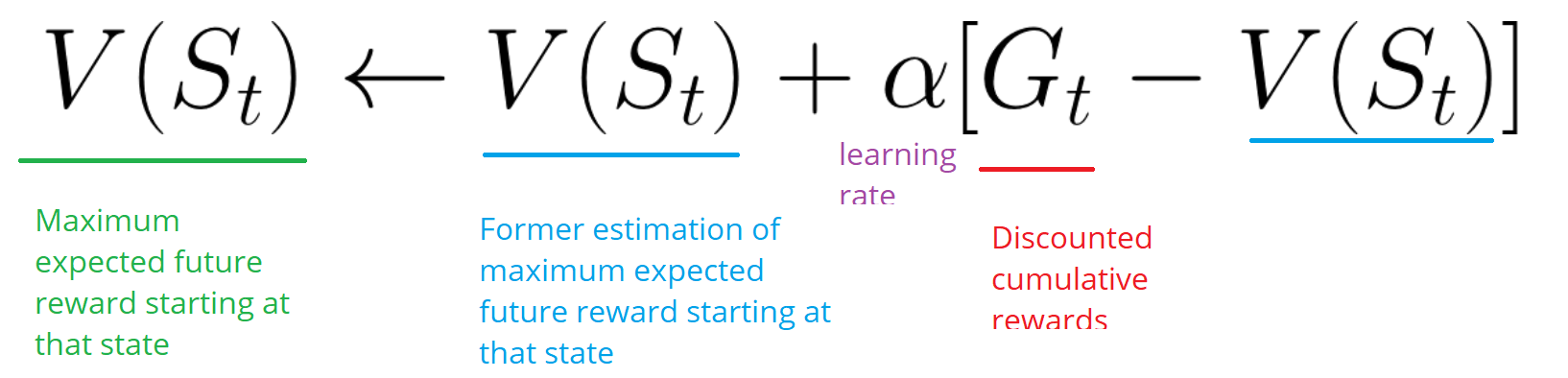
هنا مثال:
إذا أخذنا المتاهة كبيئة:
- نبدأ دائمًا من نفس نقطة البداية.
- نوقف الحلقة إذا أكلت القطة لنا أو تحركنا> 20 خطوة.
- في نهاية الحلقة ، لدينا قائمة بالدول والأفعال والمكافآت والولايات الجديدة.
- يلخص الوكيل مكافأة Gt الإجمالية (لمعرفة مدى أدائه).
- ثم يقوم بتحديث V (st) وفقًا للصيغة أعلاه.
- ثم تبدأ لعبة جديدة بمعرفة جديدة.
عند تشغيل المزيد والمزيد من الحلقات ،
سيتعلم الوكيل اللعب بشكل أفضل وأفضل.الاختلافات الزمنية: التعلم في كل خطوة زمنيةلن تنتظر طريقة التعلم الفارق الزمني (TD) حتى نهاية الحلقة لتحديث أعلى مكافأة ممكنة. سيقوم بتحديث V اعتمادًا على الخبرة المكتسبة.
تسمى هذه الطريقة TD (0) أو
TD التدريجي (تحديث وظيفة الأداة المساعدة بعد أي خطوة واحدة).
تتوقع طرق TD فقط
الخطوة الزمنية التالية
لتحديث القيم. في الوقت t + 1
، يتم تشكيل هدف TD باستخدام المكافأة Rt + 1 والتصنيف الحالي V (St + 1).هدف TD هو تقدير لما هو متوقع: في الواقع ، تقوم بتحديث تصنيف V (St) السابق إلى الهدف خلال خطوة واحدة.
الاستكشاف / التشغيلقبل النظر في استراتيجيات مختلفة لحل مشاكل التدريب التعزيزي ، يجب علينا النظر في موضوع آخر مهم للغاية: المفاضلة بين الاستكشاف والاستغلال.
- المخابرات تجد المزيد من المعلومات حول البيئة.
- يستخدم الاستغلال المعلومات المعروفة لزيادة المكافآت.
تذكر أن هدف وكيل RL الخاص بنا هو زيادة المكافآت المتراكمة المتوقعة. ومع ذلك ، يمكن أن نقع في فخ مشترك.
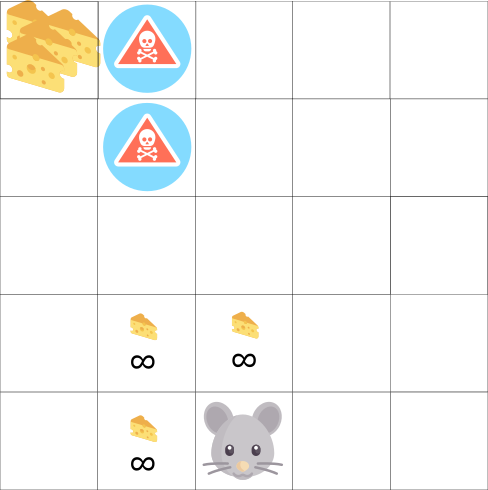
في هذه اللعبة ، يمكن أن يحتوي الماوس على عدد لا نهائي من قطع الجبن الصغيرة (+1 لكل قطعة). ولكن في الجزء العلوي من المتاهة توجد قطعة جبن عملاقة (+1000). ومع ذلك ، إذا ركزنا فقط على المكافآت ، فلن يصل وكيلنا أبدًا إلى قطعة ضخمة. بدلاً من ذلك ، سيستخدم فقط أقرب مصدر للمكافآت ، حتى لو كان هذا المصدر صغيرًا (استغلال). ولكن إذا استدعى وكيلنا قليلاً ، فسيتمكن من العثور على مكافأة كبيرة.
هذا ما نسميه تسوية بين الاستكشاف والاستغلال. يجب أن نحدد قاعدة ستساعد في التعامل مع هذه التسوية. في المقالات المستقبلية ستتعلم طرقًا مختلفة للقيام بذلك.
ثلاثة مناهج التعلم المعززالآن بعد أن حددنا العناصر الرئيسية للتعلم المعزز ، دعنا ننتقل إلى ثلاثة مناهج لحل التعلم المعزز: على أساس التكلفة ، وعلى أساس السياسات ، وعلى أساس النموذج.
على أساس التكلفةفي RL على أساس التكلفة ، الهدف هو تحسين وظيفة المنفعة V (s).
وظيفة الأداة المساعدة هي وظيفة تبلغنا بالحد الأقصى للمكافأة المتوقعة التي سيحصل عليها الوكيل في كل ولاية.
قيمة كل ولاية هي المبلغ الإجمالي للمكافأة التي يمكن للوكيل توقع تكديسها في المستقبل ، بدءًا من هذه الحالة.
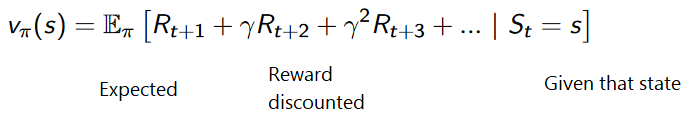
سيستخدم الوكيل وظيفة الأداة المساعدة هذه لتحديد الحالة التي يجب اختيارها في كل خطوة. يختار الوكيل الحالة ذات القيمة الأعلى.
في المثال المتاهة ، سنأخذ أعلى قيمة في كل خطوة: -7 ، ثم -6 ، ثم -5 (إلخ) لتحقيق الهدف.
على أساس السياسةفي RL المستندة إلى السياسة ، نريد تحسين وظيفة سياسة π (s) بشكل مباشر دون استخدام وظيفة الأداة المساعدة. السياسة هي التي تحدد سلوك الوكيل في وقت معين.
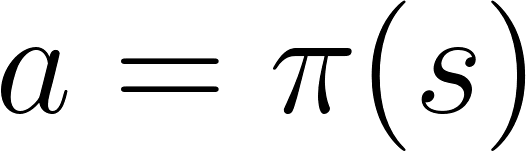 العمل = السياسة (الدولة)
العمل = السياسة (الدولة)ندرس وظيفة السياسة. هذا يسمح لنا بربط كل دولة بأفضل إجراء مناسب.
هناك نوعان من السياسات:
- الحتمية: السياسة في دولة ما ستعيد نفس الفعل دائما.
- مؤشر ستوكاستيك Stochastic: يعرض احتمالية التوزيع عن طريق الفعل.

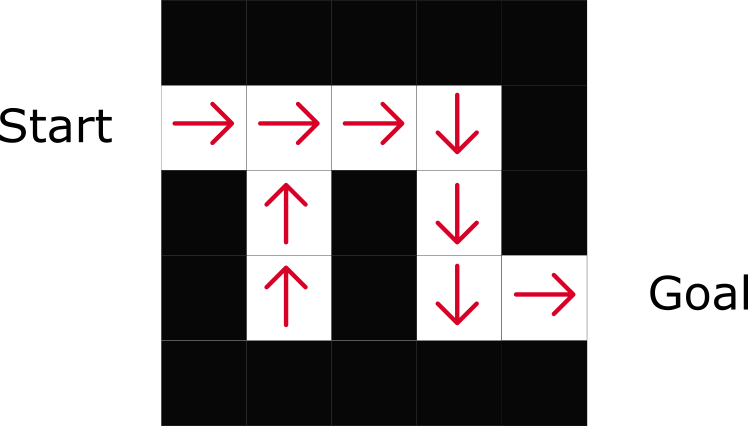
كما ترى ، تشير السياسة بشكل مباشر إلى أفضل إجراء لكل خطوة.
بناء على النموذجفي RL المستندة إلى النموذج ، نقوم بنمذجة البيئة. هذا يعني أننا نقوم بإنشاء نموذج للسلوك البيئي. تكمن المشكلة في أن كل بيئة ستحتاج إلى رؤية مختلفة للنموذج. لهذا السبب لن نركز كثيرًا على هذا النوع من التدريب في المقالات التالية.
إدخال التعلم المعزز العميقيقدم التعلم المعزز العميق شبكات عصبية عميقة لحل مشكلات التعلم المعزز - ومن هنا جاء اسم "عميق".
على سبيل المثال ، في المقالة التالية ، سنعمل على Q-Learning (التعلم المعزز الكلاسيكي) و Q-Learning العميق.
سترى الفرق في حقيقة أنه في النهج الأول نستخدم الخوارزمية التقليدية لإنشاء جدول Q ، مما يساعدنا في العثور على الإجراء المطلوب اتخاذه لكل حالة.
في الطريقة الثانية ، سنستخدم شبكة عصبية (لتقريب المكافآت القائمة على الحالة: قيمة q).
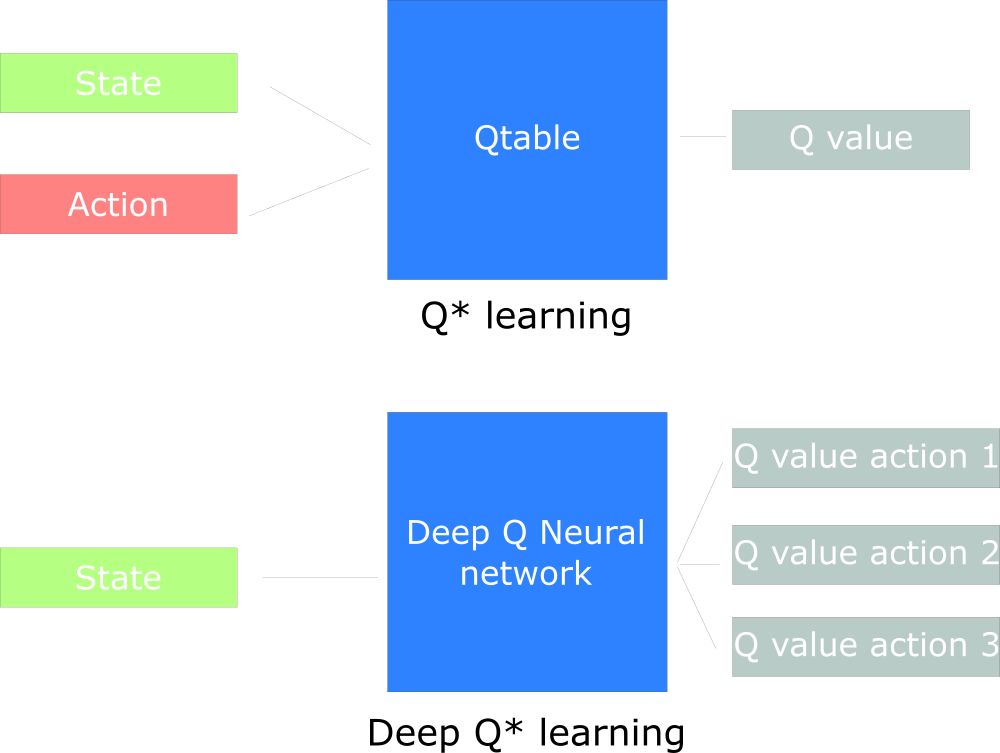 مخطط تصميم Q مستوحى من Udacity
مخطط تصميم Q مستوحى من Udacity
هذا كل شيء. كما هو الحال دائمًا ، نحن في انتظار تعليقاتك أو أسئلتك هنا ، أو يمكنك طرحها على مدرس الدورة
آرثر كادورين في
درسه المفتوح حول التواصل.