تحليل منشورات Lenta.ru على مدى 18 عامًا (من سبتمبر 1999 إلى ديسمبر 2017) باستخدام python و sklearn و scipy و XGBoost و pymorphy2 و nltk و gensim و MongoDB و Keras و TensorFlow.

استخدمت الدراسة بيانات من منشور " تحليل هذا - Lenta.ru " بواسطة ildarchegg . يرجى من المؤلف تقديم 3 غيغابايت من المقالات بتنسيق مناسب ، وقررت أن هذه كانت فرصة رائعة لاختبار بعض طرق معالجة النصوص. في نفس الوقت ، إذا كنت محظوظًا ، فتعلم شيئًا جديدًا عن الصحافة الروسية والمجتمع بشكل عام.
المحتوى:
MongoDB لاستيراد جيسون في بيثون
لسوء الحظ ، تبين أن json مع النصوص مكسورة قليلاً ، وهذا ليس بالغ الأهمية بالنسبة لي ، لكن بيثون رفضت العمل مع الملف. لذلك ، قمت أولاً باستيراده إلى MongoDB ، وعندئذ فقط ، من خلال MongoClient من مكتبة pymongo ، قمت بتحميل الصفيف وإعادة تخزينه في ملف csv على شكل قطع.
من التعليقات: 1. كان علي أن أبدأ قاعدة البيانات باستخدام الأمر sudo service mongod start - هناك خيارات أخرى ، لكنها لم تنجح ؛ 2. mongoimport - تطبيق منفصل ، لا يبدأ من وحدة تحكم mongo ، فقط من المحطة.
يتم توزيع فجوات البيانات بالتساوي عبر السنوات. لا أخطط لاستخدام فترة أقل من عام ، آمل ألا يؤثر ذلك على صحة الاستنتاجات.
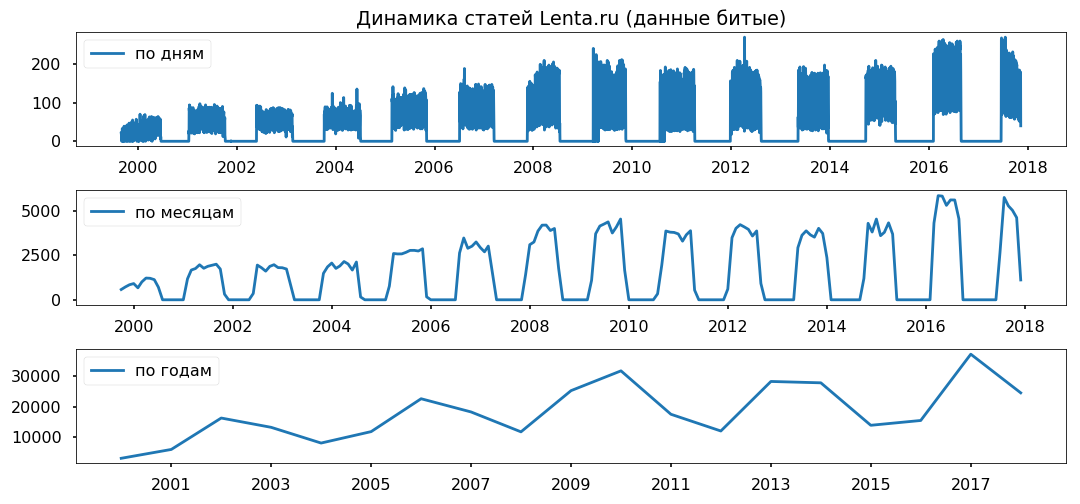
تنظيف وتطبيع النص
قبل تحليل الصفيف مباشرة ، تحتاج إلى إحضاره إلى النموذج القياسي: إزالة الأحرف الخاصة ، وتحويل النص إلى أحرف صغيرة (قامت أساليب سلسلة الباندا بعمل رائع) ، وإزالة كلمات التوقف (stopwords.words ("الروسية") من nltk.corpus) ، وإعادة الكلمات إلى شكلها الطبيعي باستخدام lemmatization (pymorphy2.MorphAnalyzer).
كانت هناك بعض العيوب ، على سبيل المثال ، تحول ديمتري بيسكوف إلى "ديمتري" و "رمل" ، ولكن بشكل عام كنت سعيدًا بالنتيجة.
سحابة الوسم
كبذرة ، دعنا نرى ما هي المنشورات في الشكل العام. سنعرض 50 الكلمات الأكثر شيوعًا التي استخدمها صحفيو Lenta من 1999 إلى 2017 في شكل سحابة الوسم.

ريا نوفوستي (المصدر الأكثر شعبية) ، مليار دولار ومليون دولار (موضوعات مالية) ، حاضر (تداول الكلام شائع في جميع المواقع الإخبارية) ، وكالة تطبيق القانون وقضية جنائية (أخبار إجرامية) ) ، "رئيس الوزراء" و "فلاديمير بوتين" (السياسة) - النمط والمواضيع المتوقعة لبوابة الأخبار.
نمذجة LDA
نحن نحسب المواضيع الأكثر شعبية لكل عام باستخدام LDA من gensim. يحدد LDA (النمذجة المواضيعية باستخدام طريقة Dirichlet للوضع الكامن) تلقائيًا الموضوعات المخفية (مجموعة من الكلمات التي تحدث معًا وفي أغلب الأحيان) من خلال ترددات الكلمات المرصودة في المقالات.
كان حجر الزاوية في الصحافة المحلية هو روسيا ، بوتين ، الولايات المتحدة.
في بعض السنوات ، تم تخفيف هذا الموضوع مع الحرب الشيشانية (من 1999 إلى 2000) ، 11 سبتمبر - في 2001 ، والعراق (من 2002 إلى 2004). من عام 2008 إلى عام 2009 ، جاء الاقتصاد في المرتبة الأولى: الفائدة ، الشركة ، الدولار ، الروبل ، مليار ، مليون. في عام 2011 ، غالبًا ما كتبوا عن القذافي.
من 2014 إلى 2017 بدأت سنوات أوكرانيا وتستمر في روسيا. حدثت الذروة في عام 2015 ، ثم بدأ الاتجاه في الانخفاض ، ولكن لا يزال مستمراً في البقاء على مستوى عال.
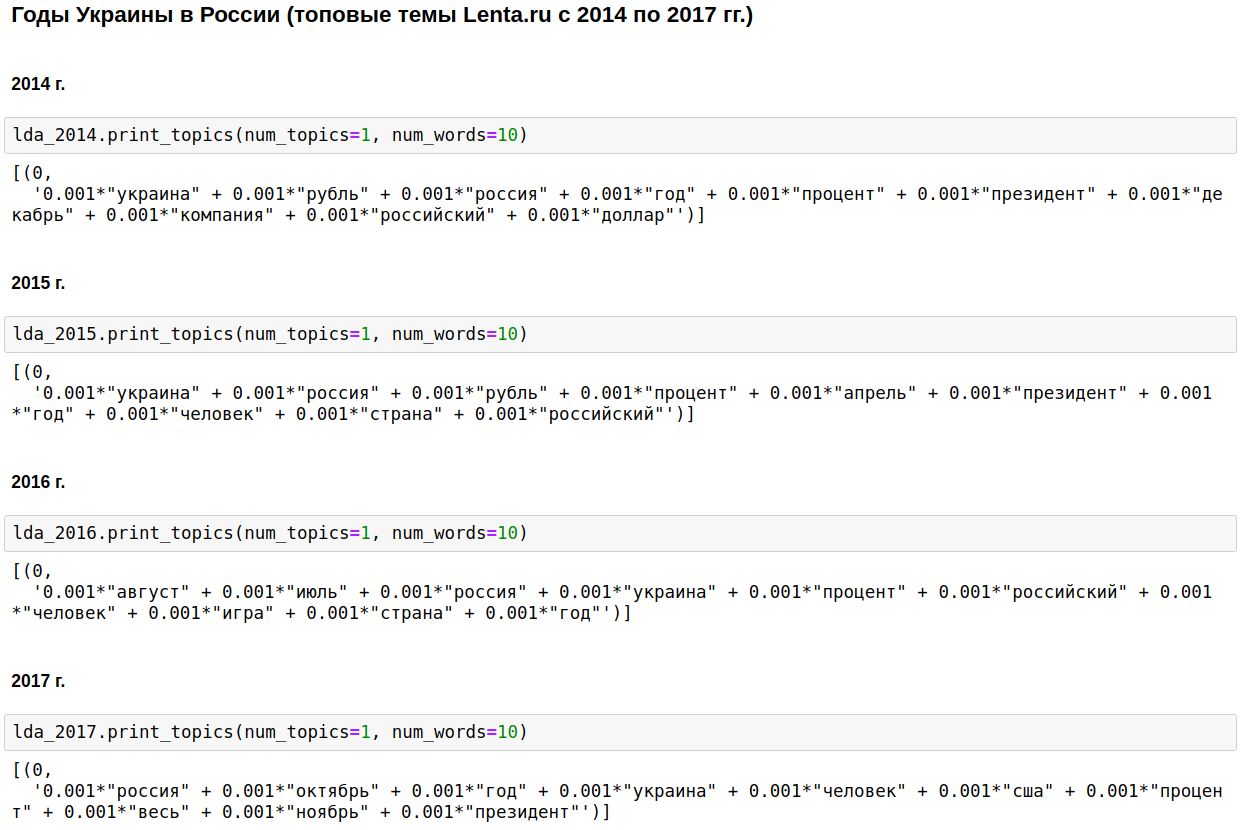
إنه أمر مثير للاهتمام بالطبع ، ولكن لا يوجد شيء لا أعرفه أو أخمنه.
دعنا نغير النهج قليلاً - حدد أهم الموضوعات طوال الوقت ونرى كيف تغيرت نسبتهم من سنة إلى أخرى ، أي أننا سوف ندرس تطور الموضوعات.
كان الخيار الأكثر تفسيرًا هو Top 5:
- الجريمة (ذكر ، شرطة ، تحدث ، محتجز ، شرطي) ؛
- السياسة (روسيا ، أوكرانيا ، الرئيس ، الولايات المتحدة الأمريكية ، رئيس) ؛
- الثقافة (سبينر ، قيحي ، انستغرام ، متعرج - نعم ، هذه هي ثقافتنا ، على الرغم من أن هذا الموضوع على وجه التحديد تبين أنه مختلط إلى حد ما) ؛
- الرياضة (المباراة ، الفريق ، اللعبة ، النادي ، الرياضي ، البطولة) ؛
- العلم (عالم ، فضاء ، قمر صناعي ، كوكب ، خلية).
بعد ذلك ، نأخذ كل مقالة ونرى كيف ترتبط بموضوع معين ، ونتيجة لذلك ، سيتم تقسيم جميع المواد إلى خمس مجموعات.
تحولت السياسة إلى أن تكون الأكثر شعبية - أقل من 80 ٪ من جميع المنشورات. ومع ذلك ، تم تمرير ذروة شعبية المواد السياسية في عام 2014 ، والآن تقل حصتها ، وتتزايد المساهمة في أجندة المعلومات الخاصة بالجريمة والرياضة.
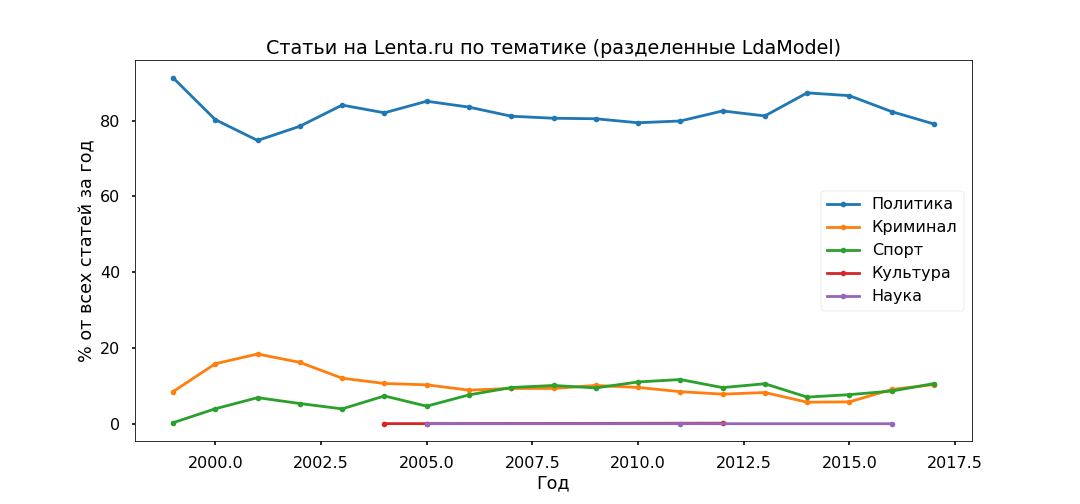
سوف نتحقق من كفاية النماذج المواضيعية باستخدام العناوين الفرعية التي أشار إليها المحررون. تم تحديد الفئات الفرعية الأعلى بشكل صحيح تقريبًا منذ عام 2013.

لم يلاحظ أي تناقض محدد: الركود السياسي في عام 2017 ، كرة القدم والحوادث في تزايد ، أوكرانيا لا تزال في الاتجاه ، مع ذروة في عام 2015.
التنبؤ بالشعبية: XGBClassifier ، LogisticRegression ، Embedding & LSTM
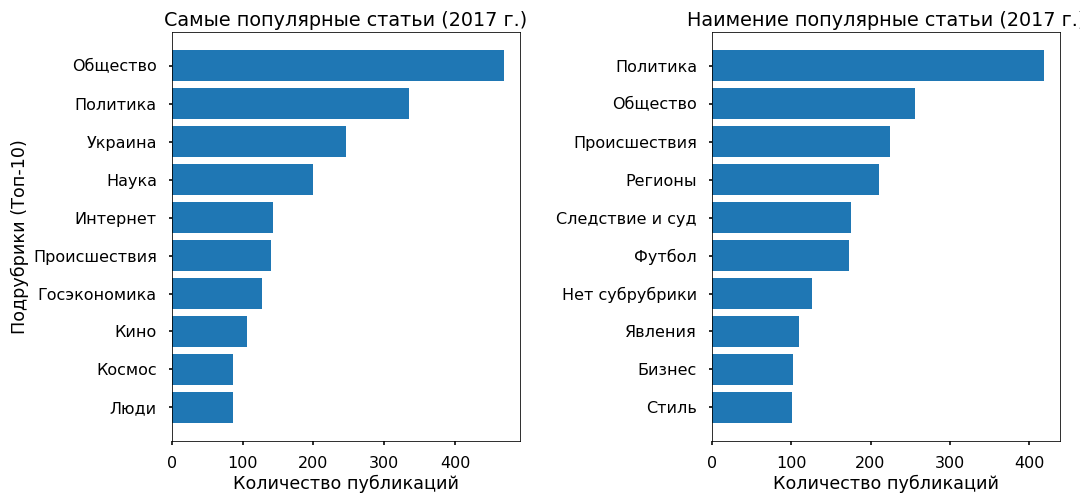
دعونا نحاول أن نفهم ما إذا كان من الممكن التنبؤ بشعبية مقال على الشريط من النص ، وماذا تعتمد هذه الشعبية بشكل عام. كمتغير مستهدف ، أخذت عدد عمليات إعادة النشر على Facebook لعام 2017.
لم تحتوي 3 آلاف مقالة لعام 2017 على إعادة نشر على Fb - تم تعيين فئة "غير شعبية" لها ، حيث تلقت 3 آلاف مادة بها أكبر عدد من عمليات إعادة النشر التسمية "الأكثر شيوعًا".
تم تقسيم النص (6 آلاف منشور لعام 2017) إلى unograms و bigrams (كلمات رمزية ، عبارات مفردة وكلمتين) وتم إنشاء مصفوفة حيث تكون الأعمدة رموزًا ، والصفوف عبارة عن مقالات ، وعند التقاطع نسبي تواتر حدوث الكلمات في المقالات. الوظائف المستخدمة من sklearn - CountVectorizer و TfidfTransformer.
تم إدخال البيانات المعدة إلى XGBClassifier (مصنف يعتمد على تعزيز التدرج من مكتبة xgboost) ، والتي أعطت بعد 13 دقيقة من تعداد المعلمات المفرطة (GridSearchCV مع cv = 3) دقة بنسبة 76٪ في الاختبار.

ثم استخدمت الانحدار اللوجستي المعتاد (sklearn.linear_model.LogisticRegression) وبعد 17 ثانية حصلت على دقة 81٪.
مرة أخرى أنا مقتنع بأن الطرق الخطية هي الأنسب لتصنيف النصوص ، شريطة أن يتم إعداد البيانات بعناية.
كتقدير للأزياء ، اختبرت الشبكات العصبية قليلاً. قام بترجمة الكلمات إلى أرقام باستخدام one_hot من keras ، وأحضر جميع المقالات إلى نفس الطول (دالة pad_sequences من keras) وطبّق LSTM (الشبكة العصبية التلافيفية ، باستخدام TensorFlow backend) من خلال طبقة التضمين (لتقليل البعد وتسريع وقت المعالجة).
عملت الشبكة في دقيقتين وأظهرت الدقة في اختبار 70٪. لا يقتصر الأمر على الإطلاق ، ولكن في هذه الحالة ليس من المنطقي أن تزعج نفسك كثيرًا.
بشكل عام ، أنتجت جميع الطرق دقة منخفضة نسبيًا. كما تظهر التجربة ، تعمل خوارزميات التصنيف بشكل جيد مع مجموعة متنوعة من الأساليب - على مواد حقوق الطبع والنشر ، بعبارة أخرى. هناك مثل هذه المواد على Lenta.ru ، ولكن هناك القليل جدًا منها - أقل من 2 ٪.

الصفيف الرئيسي مكتوب باستخدام مفردات الأخبار المحايدة. ولا يتم تحديد شعبية الأخبار من خلال النص نفسه ولا حتى الموضوع على هذا النحو ، ولكن انتمائهم لاتجاه المعلومات التصاعدي.
على سبيل المثال ، هناك عدد غير قليل من المقالات الشائعة التي تغطي الأحداث في أوكرانيا ، وأقلها شيوعًا لا تتعلق بهذا الموضوع.
استكشاف الكائنات باستخدام Word2Vec
في الختام ، كنت أرغب في إجراء تحليل عاطفي - لفهم كيفية ارتباط الصحفيين بالأشياء الأكثر شيوعًا التي يذكرونها في مقالاتهم ، سواء تغيرت مواقفهم بمرور الوقت.
لكن ليس لدي البيانات المميزة ، ومن غير المحتمل أن يعمل البحث في المعجم الدلالي بشكل صحيح ، حيث أن مفردات الأخبار محايدة جدًا ، وخيلة بالمشاعر. لذلك ، قررت التركيز على السياق الذي يتم فيه ذكر الأشياء.
أخذت أوكرانيا (2015 مقابل 2017) وبوتين (2000 مقابل 2017) كاختبار. لقد اخترت المقالات التي ذكرت فيها ، وترجمت النص إلى مساحة متجهية متعددة الأبعاد (Word2Vec من gensim.models) ، وعرضت على ثنائي الأبعاد باستخدام طريقة المكونات الرئيسية.
بعد عرض الصور ، اتضح أنها ملحمة ، لا تقل عن حجم نسيج من بايو. لقد قطعت المجموعات الضرورية لتبسيط الإدراك ، كما يمكنني ، آسف على "ابن آوى".


ما لاحظت.
لطالما ظهر بوتين من نموذج 2000 في سياق روسيا وتناول بشكل شخصي. في عام 2017 ، تحول رئيس الاتحاد الروسي إلى زعيم (مهما كان ذلك) ونأى بنفسه عن البلاد ، الآن ، إذا حكمنا من خلال السياق ، فهو ممثل الكرملين الذي يتواصل مع العالم من خلال سكرتيره الصحفي.
أوكرانيا 2015 في وسائل الإعلام الروسية - الحرب والمعارك والانفجارات. هو ذكر نزع الطابع الشخصي (ذكرت كييف ، بدأت كييف). تظهر أوكرانيا 2017 بشكل رئيسي في سياق المفاوضات بين المسؤولين ، ول هؤلاء الأشخاص أسماء محددة.
...
يمكنك تفسير المعلومات التي تم تلقيها لبعض الوقت ، ولكن ، كما أعتقد ، هذا مورد خارجى عن هذا المورد. أولئك الذين يرغبون يمكنهم أن يروا بنفسك. أرفق الرمز والبيانات.
ارتباط البرنامج النصي
ارتباط البيانات