
كما تعلم ، فإن HTTP 1.1 هو بروتوكول لنقل البيانات يستند إلى نص. يتم ترميز رسائل HTTP باستخدام ISO-8859-1 (والذي يمكن اعتباره مشروطًا نسخة موسعة من ASCII تحتوي على علامات تشكيل ، وعلامات التشكيل ، وشخصيات أخرى مستخدمة في لغات أوروبا الغربية). في الوقت نفسه ، يمكن استخدام ترميز آخر في نص الرسالة ، والذي يجب الإشارة إليه في عنوان "نوع المحتوى". ولكن ماذا لو احتجنا إلى تحديد أحرف غير ASCII ليس في نص الرسالة ، ولكن في الرؤوس نفسها؟ ربما الحالة الأكثر شيوعًا هي وضع اسم ملف في رأس "ترتيب المحتوى". قد تبدو هذه مهمة شائعة إلى حد ما ، ولكن تنفيذها ليس واضحًا.
TL؛ DR: استخدم الترميز الموضح في
RFC 6266 من أجل "Content-Disposition" وتحويل النص إلى اللاتينية (تحويل صوتي) في حالات أخرى.
مقدمة صغيرة للترميزات
يذكر المقال ويستخدم US-ASCII (غالبًا ما يشار إليه ببساطة باسم ASCII) و ISO-8859-1 وترميزات UTF-8. هذه مقدمة صغيرة لهذه الترميزات. القسم مخصص للمطورين الذين نادراً أو كلياً لا يعملون مع الترميزات وتمكنوا من نسيانها. إذا كنت لا تنتمي إليهم ، فلا تتردد في تخطي القسم.
ASCII هو ترميز بسيط يحتوي على 128 حرفًا ويتضمن الأبجدية الإنجليزية بالكامل والأرقام وعلامات الترقيم وأحرف الخدمة.
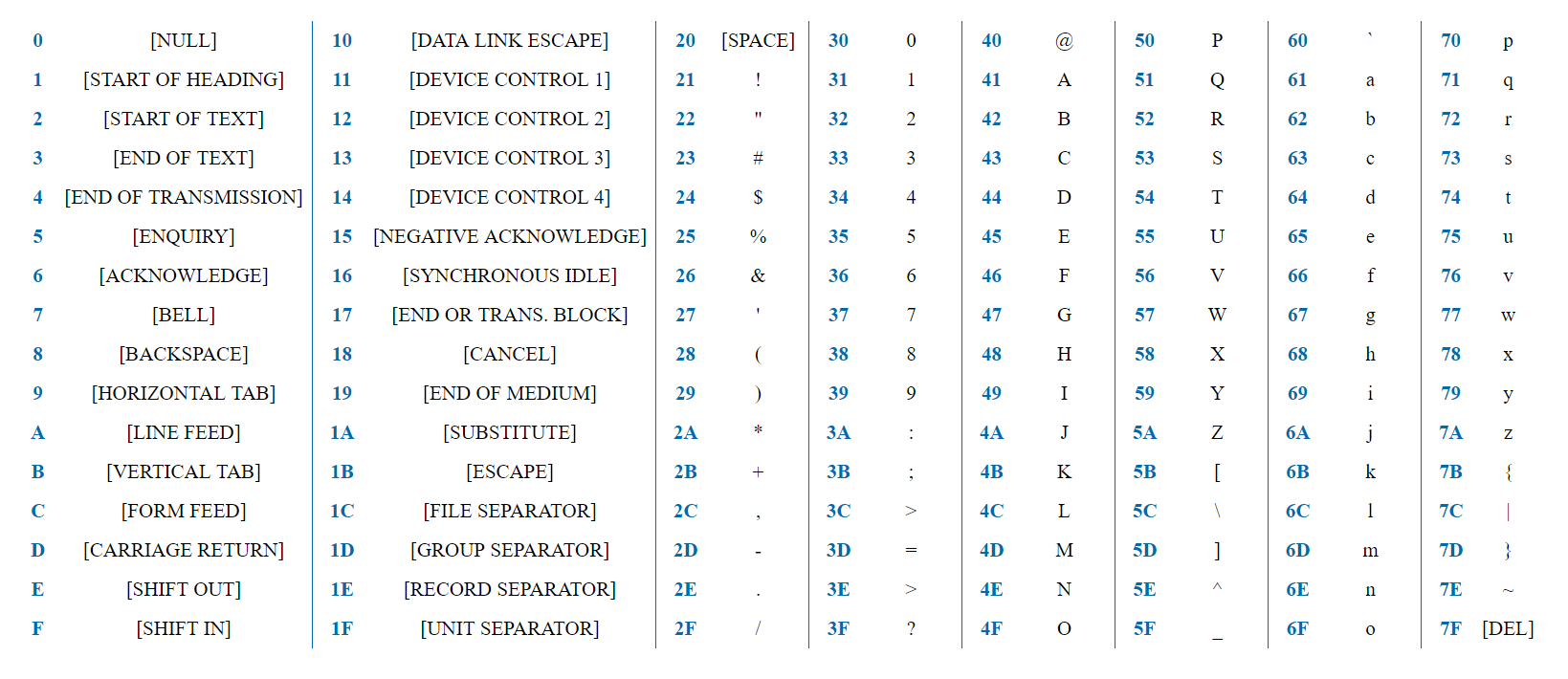
7 بتات كافية لتمثيل أي حرف ASCII. سيتم تمثيل كلمة "اختبار" في تمثيل HEX كـ 0x74 0x65 0x73 0x74. دائمًا ما يكون البت الأول لجميع الأحرف هو 0 ، لأن الأحرف يتم ترميزها في 128 ، ويوفر البايت 2 ^ 8 = 256 خيارًا.
ISO-8859-1 هو ترميز مخصص للغات أوروبا الغربية. يحتوي على علامات تشكيل فرنسية ، ونقاط ألمانية ، وما إلى ذلك.
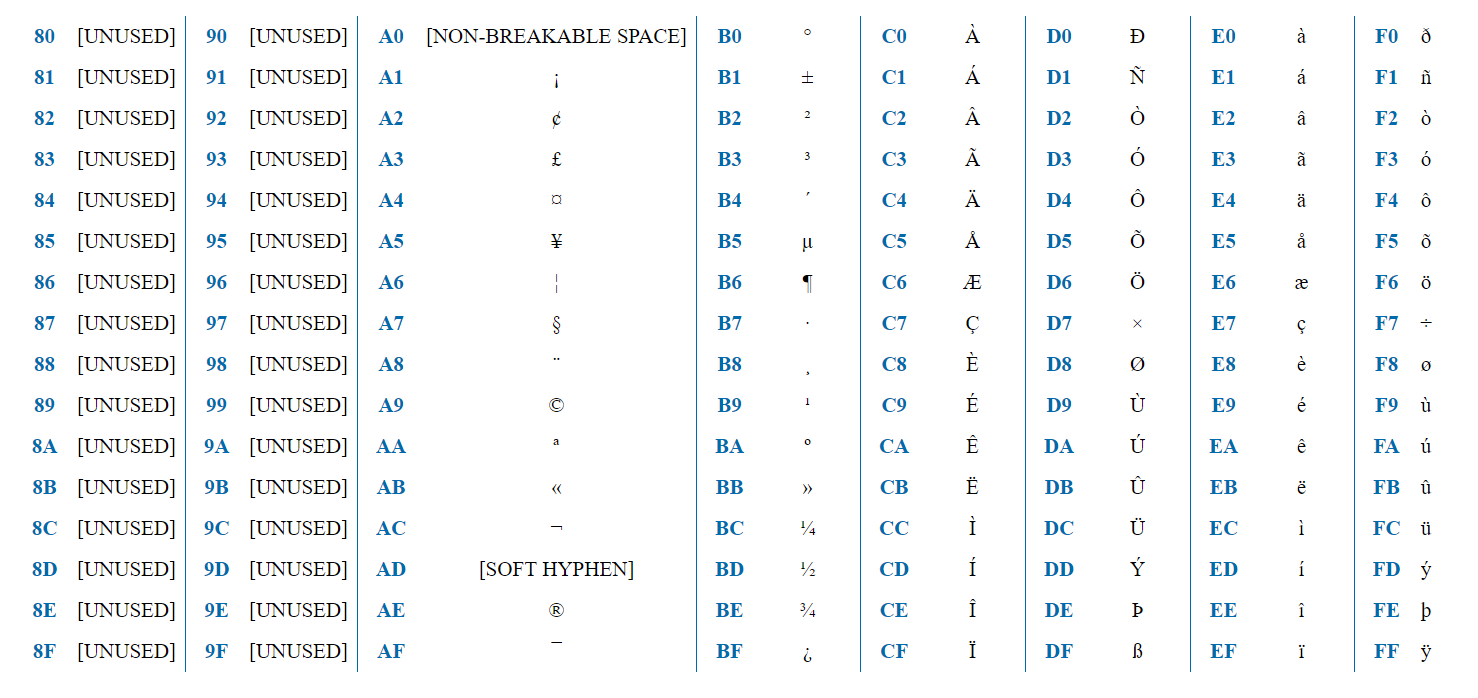
يحتوي الترميز على 256 حرفًا ، وبالتالي يمكن تمثيله ببايت واحد. النصف الأول (128 حرفًا) هو تمامًا مثل ASCII. وبالتالي ، إذا كانت البتة الأولى = 0 ، فهذا حرف ASCII عادي. إذا كانت 1 ، فهذا حرف خاص بـ ISO-8859-1.
UTF-8 هو واحد من أشهر الترميزات مع ASCII. قادرة على ترميز 1.112.064 حرفا.
يختلف حجم كل حرف من 1 إلى 4 بايت (تم السماح حتى 6 بايت سابقًا).

يحدد البرنامج الذي يعمل مع هذا التشفير بالبتات الأولى عدد البايتات المضمنة في الحرف. إذا بدأت الثماني في 0 ، فسيتم تمثيل الحرف ببايت واحد. 110 - 2 بايت 1110 - 3 بايت 11110 - 4 بايت.
كما هو الحال مع ISO-8859-1 ، فإن أول 128 حرفًا متوافقة تمامًا مع ASCII. لذلك ، فإن النصوص التي تستخدم أحرف ASCII فقط ستكون متطابقة تمامًا في التمثيل الثنائي ، بغض النظر عما إذا تم استخدام US-ASCII أو ISO-8859-1 أو UTF-8 للترميز.
استخدام UTF-8 في نص الرسالة
قبل الانتقال إلى الرؤوس ، دعنا نلقي نظرة سريعة على كيفية استخدام UTF-8 في نص الرسائل. للقيام بذلك ، استخدم رأس
"نوع المحتوى" .

إذا لم يتم تحديد "نوع المحتوى" ، فيجب على المتصفح معالجة الرسائل كما لو كانت مكتوبة في ISO-8859-1.
يجب ألا يحاول
المتصفح تخمين الترميز ، علاوة على ذلك ، يتجاهل "نوع المحتوى". ولكن ما يظهر حقًا في حالة لا يتم فيها إرسال "نوع المحتوى" يعتمد على تنفيذ المتصفح. على سبيل المثال ، سيفعل Firefox وفقًا للمواصفات ويقرأ الرسالة كما لو كانت مشفرة في ISO-8859-1. في المقابل ، سيستخدم Google Chrome ترميز نظام التشغيل ، والذي يساوي بالنسبة إلى العديد من المستخدمين الروس نظام Windows-1251. على أي حال ، إذا كانت الرسالة بتنسيق UTF-8 ، فلن يتم عرضها بشكل صحيح.

نضع رسالة UTF-8 في قيمة الرأس
مع نص الرسالة ، كل شيء بسيط للغاية. يتبع نص الرسالة دائمًا الرؤوس ، لذلك لا توجد مشاكل فنية. ولكن ماذا عن العناوين الرئيسية؟ تنص المواصفات
صراحة على أن ترتيب الرؤوس في الرسالة لا يهم. على سبيل المثال لا يمكن تحديد الترميز في رأس واحد من خلال رأس آخر.
ماذا يحدث إذا أخذت للتو وكتبت قيمة UTF-8 إلى قيمة الرأس؟ لقد رأينا أن مثل هذه الخدعة مع نص الرسالة ستؤدي إلى قراءة القيمة ببساطة في ISO-8859-1. سيكون من المنطقي افتراض أن الشيء نفسه سيحدث مع العنوان. لكن الأمر ليس كذلك. في الواقع ، في العديد من الحالات ، إن لم يكن معظمها ، سيعمل هذا الحل. وهذا يشمل أجهزة iPhone القديمة و IE11 و Firefox و Google Chrome. المتصفح الوحيد بين يدي عندما كتبت هذه المقالة التي لم ترغب في العمل مع هذا العنوان كان Edge.

لم يتم تسجيل هذا السلوك في المواصفات. ربما قرر مطورو المتصفح جعل الحياة أسهل للمطورين واكتشاف تلقائيًا أن رؤوس الرسائل تم ترميزها في UTF-8. بشكل عام ، هذه ليست مهمة صعبة. ننظر إلى البتة الأولى: إذا 0 ، ثم ASCII ، إذا 1 - ثم ، ربما ، UTF-8.
هل هناك تقاطع مع ISO-8859-1 في هذه الحالة؟ في الواقع ، لا شيء تقريبًا. خذ على سبيل المثال UTF-8 حرف 2 ثماني (يتم تمثيل الحروف الروسية بثمانيتين). سيبدو الرمز الموجود في الملف الثنائي كما يلي:
110xxxxx 10xxxxxx . في تمثيل HEX:
[0xC0-0x6F] [0x80-0xBF] . في ISO-8859-1 ، بالكاد تستطيع هذه الأحرف ترميز شيء يحمل حملًا دلاليًا. لذلك ، فإن خطر قيام المستعرض بفك تشفير الرسالة بشكل غير صحيح ضئيل جدًا.
ومع ذلك ، عند محاولة استخدام هذه الطريقة ، قد تواجه مشاكل فنية: قد لا يسمح خادم الويب أو إطار العمل بكتابة أحرف UTF-8 إلى قيمة الرأس. على سبيل المثال ، يضع Apache Tomcat 0x3F (علامة استفهام) بدلاً من جميع أحرف UTF-8. بالطبع ، يمكن التحايل على هذا التقييد ، ولكن إذا كان التطبيق نفسه يتصافح ولا يسمح لك بفعل شيء ، فربما لا تحتاج إلى القيام بذلك.
ولكن ، بغض النظر عما إذا كان الإطار أو الخادم الخاص بك يسمح لك بكتابة رسائل UTF-8 إلى الرأس أم لا ، لا أوصي بذلك. هذا ليس حلاً موثقًا قد يتوقف عن العمل في المتصفحات في أي وقت.
ترجمة
أعتقد أن الترجمة تستخدم - eto bolee horoshee reshenie. لا تستهين العديد من الموارد الروسية الشعبية الكبيرة باستخدام الترجمة الصوتية في أسماء الملفات. هذا حل مضمون لن ينقطع عن إصدار المتصفحات الجديدة ولا يحتاج إلى اختباره بشكل منفصل على كل نظام أساسي. على الرغم من أنك بالطبع تحتاج إلى التفكير في كيفية تحويل مجموعة كاملة من الشخصيات المحتملة ، والتي قد لا تكون تافهة تمامًا. على سبيل المثال ، إذا تم تصميم التطبيق لجمهور روسي ، فقد يظهر الحرفان التتاران ң و in في اسم الملف ، والذي يجب معالجته بطريقة أو بأخرى ، وليس فقط استبداله بـ "؟".
RFC 2047
كما ذكرت من قبل ، لم تسمح لي tomkat بوضع UTF-8 في رأس الرسالة. هل تنعكس ميزة السلوك هذه في مستندات Java for servlets؟ نعم ، ينعكس:
المذكورة
RFC 2047 . حاولت ترميز الرسائل باستخدام هذا التنسيق - لم يفهمني المتصفح. لا يعمل أسلوب الترميز هذا في HTTP. على الرغم من أنه كان يعمل من قبل. على سبيل المثال ،
تذكرة لإزالة دعم هذا الترميز من Firefox.
RFC 6266
في التذكرة ، الرابط الذي يوجد في القسم السابق ،
هناك إشارات إلى أنه حتى بعد انتهاء دعم RFC 2047 ، لا تزال هناك طريقة لنقل قيم UTF-8 باسم الملفات التي تم تنزيلها:
RFC 6266 . في رأيي ، هذا هو القرار الأكثر صحة حتى الآن. تستخدمه العديد من الموارد الشعبية على الإنترنت. نحن في
CUBA Platform نستخدم أيضًا RFC المحدد هذا لإنشاء "ترتيب المحتوى".
RFC 6266 عبارة عن مواصفات تصف استخدام رأس "ترتيب المحتوى". يتم وصف طريقة الترميز نفسها بالتفصيل في مواصفات أخرى ،
RFC 8187 .

تحتوي المعلمة "اسم الملف" على اسم الملف في ASCII ، "اسم الملف *" - في أي ترميز ضروري. مع كلتا السمتين ، يتم تجاهل "اسم الملف" في جميع المتصفحات الحديثة (بما في ذلك IE11 والإصدارات الأقدم من Safari). في المقابل ، تتجاهل معظم المتصفحات القديمة "اسم الملف *".
عند استخدام طريقة التشفير هذه ، تشير المعلمة أولاً إلى التشفير ، متبوعة بالقيمة المشفرة. لا تتطلب الأحرف المرئية من ترميز ASCII. يتم كتابة الأحرف المتبقية ببساطة في شكل سداسي عشري ، مع "٪" قبل كل ثماني بتات.
ماذا تفعل مع رؤوس أخرى؟
الترميز الموضح في RFC 8187 ليس عالميًا. نعم ، يمكنك وضع معلمة ببادئة * في الرأس ، وقد يعمل هذا حتى مع بعض المتصفحات ، ولكن
المواصفات تنص على عدم القيام بذلك.
في كل حالة يكون فيها UTF-8 مدعومًا في الرؤوس ، يوجد حاليًا ذكر صريح لهذا في RFC ذي الصلة. بالإضافة إلى Content-Disposition ، يتم استخدام هذا الترميز ، على سبيل المثال ، في
Web Linking و
Digest Access Authentication .
وتجدر الإشارة إلى أن المعايير في هذا المجال تتغير باستمرار. تم
اقتراح استخدام الترميز الموضح أعلاه في HTTP
فقط في عام 2010 . تم
إصلاح استخدام هذا الترميز في "ترتيب المحتوى"
في المعيار في عام 2011 . على الرغم من حقيقة أن هذه المعايير هي فقط
في مرحلة "المعيار المقترح" ، إلا أنها مدعومة في كل مكان. لا يُستبعد الخيار الذي نتوقعه في المستقبل معايير جديدة تسمح بعمل أكثر انتظامًا مع ترميزات مختلفة في الرؤوس. لذلك ، يبقى فقط متابعة الأخبار في عالم معايير HTTP ومستوى دعمهم على جانب المتصفحات.