التعرف البصري على الحروف (OCR) هو عملية الحصول على النصوص المطبوعة بتنسيق رقمي. إذا قرأت رواية كلاسيكية على جهاز رقمي أو طلبت من الطبيب التقاط السجلات الطبية القديمة من خلال نظام الكمبيوتر في المستشفى ، فمن المحتمل أنك استخدمت OCR.
يجعل OCR المحتوى الثابت السابق قابلاً للتحرير وقابلًا للبحث والمشاركة. لكن العديد من المستندات التي تحتاج إلى رقمنة تحتوي على بقع القهوة ، وصفحات ذات زوايا مجعدة ، والعديد من التجاعيد التي تجعل بعض المستندات المطبوعة غير رقمية.
لقد عرف الجميع منذ فترة طويلة أن هناك ملايين الكتب القديمة المخزنة في التخزين. يحظر استخدام هذه الكتب بسبب خرابها وعدم احترامها ، وبالتالي فإن رقمنة هذه الكتب مهمة للغاية.
تتناول الورقة مهمة مسح النص من التشويش والتعرف على النص في صورة وتحويله إلى تنسيق نص.

للتدريب ، تم استخدام 144 صورة. قد يكون الحجم مختلفًا ، ولكن يفضل أن يكون في حدود المعقول. يجب أن تكون الصور بتنسيق PNG. بعد قراءة الصورة ، يتم استخدام الترميز الثنائي - عملية تحويل صورة ملونة إلى أبيض وأسود ، أي يتم تطبيع كل بكسل إلى نطاق من 0 إلى 255 ، حيث يكون 0 أسود ، و 255 أبيض.
لتدريب شبكة تلافيفية ، تحتاج إلى صور أكثر مما هو موجود. تقرر تقسيم الصور إلى أجزاء. نظرًا لأن عينة التدريب تتكون من صور بأحجام مختلفة ، تم ضغط كل صورة إلى 448x448 بكسل. وكانت النتيجة 144 صورة بدقة 448x448 بكسل. ثم تم تقطيعها جميعًا إلى نوافذ غير متداخلة بحجم 112 × 112 بكسل.

وهكذا ، من أصل 144 صورة أولية ، تم الحصول على حوالي 2304 صورة في مجموعة التدريب. لكن هذا لم يكن كافيا. هناك حاجة إلى مزيد من التدريب لتدريب شبكة تلافيفية جيدة. ونتيجة لذلك ، كان الخيار الأفضل هو تدوير الصور 90 درجة ، ثم 180 و 270 درجة. ونتيجة لذلك ، يتم توفير صفيف بحجم [16،112،112،1] لمدخلات الشبكة. حيث 16 هو عدد الصور ، 112 هو عرض وارتفاع كل صورة ، 1 هو قنوات الألوان. اتضح 9216 أمثلة للتدريب. هذا يكفي لتدريب شبكة تلافيفية.
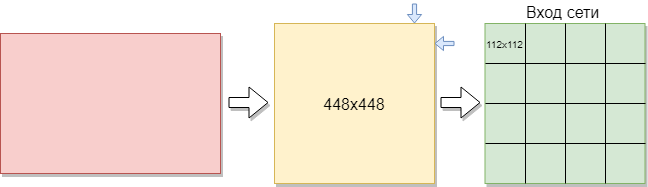
يبلغ حجم كل صورة 112x112 بكسل. إذا كان الحجم كبيرًا جدًا ، فسيزداد التعقيد الحسابي ، على التوالي ، وسيتم انتهاك القيود على سرعة الاستجابة ، ويتم تحديد تحديد الحجم في هذه المشكلة عن طريق طريقة الاختيار. إذا حددت حجمًا صغيرًا جدًا ، فلن تتمكن الشبكة من تحديد العلامات الرئيسية. تحتوي كل صورة على تنسيق أبيض وأسود ، لذلك يتم تقسيمها إلى قناة واحدة. تنقسم الصور الملونة إلى 3 قنوات: الأحمر والأزرق والأخضر. نظرًا لأن لدينا صورًا بالأبيض والأسود ، فإن حجم كل صورة هو 112x122x1 بكسل.
بادئ ذي بدء ، من الضروري تدريب شبكة عصبية تلافيفية على الصور المعدة والمعالجة. لهذه المهمة ، تم اختيار بنية U-Net.
تم اختيار نسخة مخفضة من العمارة ، تتكون من كتلتين فقط (النسخة الأصلية من أربعة). كان أحد الاعتبارات المهمة هو حقيقة أن فئة كبيرة من خوارزميات الترميز المعروفة يتم التعبير عنها بشكل صريح في مثل هذه البنية أو هندسة مماثلة (كمثال ، يمكننا تعديل خوارزمية Niblack باستبدال الانحراف المعياري بمتوسط الانحراف ، وفي هذه الحالة يتم إنشاء الشبكة بشكل خاص ببساطة).
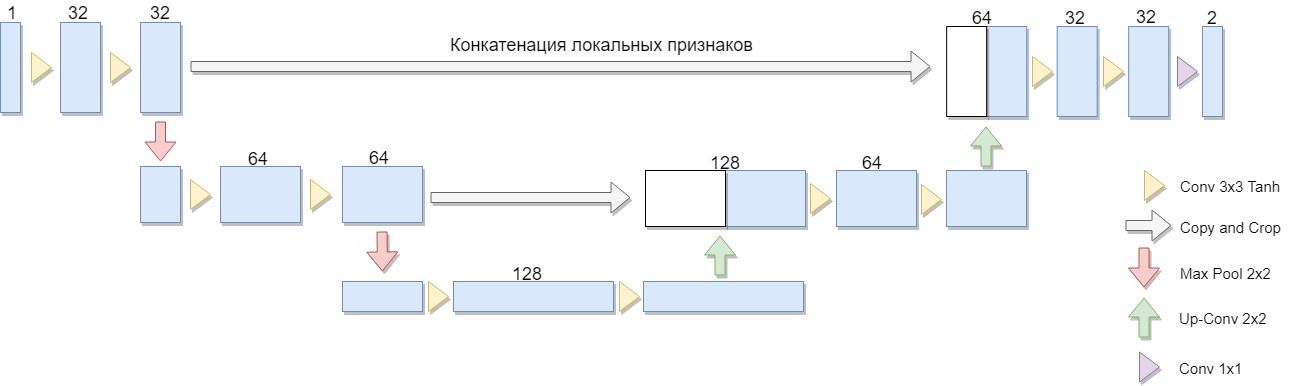
ميزة هذه البنية هي أنه لتدريب الشبكة ، يمكنك إنشاء كمية كافية من بيانات التدريب من عدد قليل من الصور المصدر. علاوة على ذلك ، تمتلك الشبكة عددًا صغيرًا نسبيًا من الأوزان بسبب بنيتها التلافيفية. ولكن هناك بعض الفروق الدقيقة. على وجه الخصوص ، الشبكة العصبية الاصطناعية المستخدمة ، بشكل دقيق ، لا تحل مشكلة التثبيط: لكل بكسل من صورة المصدر ، تربط رقمًا من 0 إلى 1 ، والذي يميز الدرجة التي تنتمي بها هذه البكسل إلى إحدى الفئات (تعبئة أو خلفية ذات معنى) وهو ضروري لا يزال يتحول إلى إجابة ثنائية نهائية. [1]
يتكون U-Net من مسار الضغط وإلغاء الضغط و "الأمام" بينهما. يتكون مسار الضغط ، في هذه البنية ، من كتلتين (في النسخة الأصلية المكونة من أربعة). تحتوي كل كتلة على تلافيتين مع مرشح 3x3 (باستخدام وظيفة التنشيط Tanh بعد الالتفاف) وتجمع بحجم مرشح 2x2 في خطوات من 2. يتضاعف عدد القنوات في كل خطوة.
يتكون مسار الضغط أيضًا من كتلتين. يتكون كل منها من "مسح" بحجم مرشح 2x2 ، وخفض عدد القنوات إلى النصف ، وسلسلة مع خريطة معالم مقطوعة مقابلة من مسار الضغط ("إعادة التوجيه") ولفائف مع مرشح 3x3 (باستخدام وظيفة التنشيط Tanh بعد الالتفاف). بعد ذلك ، في الطبقة الأخيرة ، يلتف 1x1 (باستخدام وظيفة التنشيط السيني) للحصول على إخراج ، صورة مسطحة. لاحظ أن اقتطاع خريطة المعالم أثناء التسلسل ضروري بسبب فقدان وحدات البكسل الحدية لكل التفاف. تم اختيار آدم كطريقة لتحسين الاستوكاستك.
بشكل عام ، العمارة عبارة عن سلسلة من طبقات الالتفاف + التجميع التي تقلل من الدقة المكانية للصورة ، ثم تزيدها عن طريق دمجها مع بيانات الصورة مقدمًا والمرور عبر طبقات الالتفاف الأخرى. وبالتالي ، تعمل الشبكة كنوع من المرشحات. [2]
تكونت عينة الاختبار من صور مماثلة ، وكانت الاختلافات فقط في نسيج الضجيج وفي النص. تم اختبار الشبكة على هذه الصورة.

عند إخراج الشبكة العصبية التلافيفية ، يتم الحصول على مجموعة من الأرقام بحجم [16،112،112،1]. كل رقم هو وحدة بكسل منفصلة تعالجها الشبكة. الصور بتنسيق 112 × 112 بكسل ، كما كان من قبل ، تم تقطيعها إلى قطع. إنها بحاجة إلى خيانة المظهر الأصلي. نقوم بدمج الصور التي تم الحصول عليها في جزء واحد ، ونتيجة لذلك تكون الصورة بتنسيق 448x448. بعد ذلك ، نضرب كل رقم في المصفوفة في 255 للحصول على نطاق من 0 إلى 255 ، حيث 0 أسود ، 255 أبيض. نعيد الصورة إلى حجمها الأصلي ، كما كان من قبل ، تم ضغطها. والنتيجة هي الصورة أدناه في الشكل.

في هذا المثال ، يُلاحظ أن الشبكة التلافيفية تعاملت مع معظم الضوضاء وأثبتت فعاليتها. ولكن من الواضح أن الصورة أصبحت أكثر قتامة والضوضاء الضائعة مرئية. في المستقبل ، قد يؤثر هذا على دقة التعرف على النص.
وبناءً على هذه الحقيقة ، تقرر استخدام شبكة عصبية أخرى - تصور متعدد الطبقات. في النتيجة المتوقعة ، يجب أن تجعل الشبكة النص في الصورة أكثر وضوحًا وتزيل الضجيج المفقود من الشبكة العصبية التلافيفية.
يتم إرسال صورة تمت معالجتها بالفعل من قبل شبكة الالتفاف إلى مدخلات المنظور متعدد الطبقات. في هذه الحالة ، ستكون عينة التدريب لهذه الشبكة مختلفة عن العينة للشبكة التلافيفية ، حيث إن الشبكات تعالج الصورة بشكل مختلف. تعتبر الشبكة التلافيفية الشبكة الرئيسية وتزيل معظم الضوضاء في الصورة ، بينما يعالج النظام متعدد الطبقات ما فشل التلافيفي في القيام به.
فيما يلي بعض الأمثلة من مجموعة التدريب لفهم متعدد الطبقات.

تم الحصول على بيانات الصورة من خلال معالجة عينة التدريب للشبكة التلافيفية مع منظور متعدد الطبقات. في نفس الوقت ، تم تدريب الإكسبترون على نفس العينة ، ولكن على عدد قليل من الأمثلة وعدد صغير من العصور.
لتدريب ندبترون ، تمت معالجة 36 صورة. يتم تدريب الشبكة بكسل تلو الآخر ، أي يتم إرسال بكسل واحد من الصورة إلى إدخال الشبكة. عند إخراج الشبكة ، نحصل أيضًا على عصبون ناتج واحد - بكسل واحد ، أي استجابة الشبكة. لزيادة دقة المعالجة ، تم عمل 29 خلية عصبية. وعلى الصورة التي تم الحصول عليها بعد المعالجة بواسطة شبكة الالتواء ، يتم فرض 28 مرشحًا. والنتيجة هي 29 صورة بفلاتر مختلفة. نرسل بكسل واحد من كل 29 صورة إلى إدخال الشبكة ويتم استقبال بكسل واحد فقط عند إخراج الشبكة ، أي استجابة الشبكة.
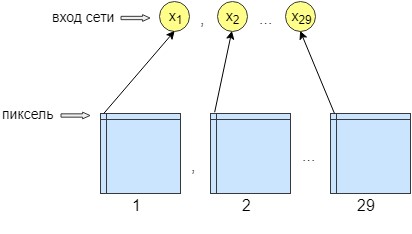
تم ذلك لتحسين التدريب والتواصل. بعد ذلك ، بدأت الشبكة في زيادة دقة وتباين الصورة. كما ينظف الأخطاء الطفيفة التي لا يمكن مسح الشبكة التلافيفية.
ونتيجة لذلك ، تحتوي الشبكة العصبية على 29 خلية عصبية إدخال ، بكسل واحد من كل صورة. بعد التجارب ، تبين أن هناك حاجة لطبقة خفية واحدة فقط ، فيها 500 خلية عصبية. هناك طريقة واحدة فقط للخروج من الشبكة. منذ أن تم التدريب بكسل بعد بكسل ، تم الوصول إلى الشبكة n * m مرات ، حيث n هو عرض الصورة و m هو الارتفاع ، على التوالي.

بعد معالجة الصورة بالتسلسل بواسطة شبكتين عصبيتين ، فإن الشيء الرئيسي المتبقي هو التعرف على النص. لهذا ، تم اتخاذ حل جاهز ، وهو مكتبة Python Pytesseract. لا يوفر Pytesseract روابط Python حقيقية. بدلا من ذلك ، هو غلاف بسيط للثنائي tesseract. في هذه الحالة ، يتم تثبيت tesseract بشكل منفصل على الكمبيوتر. يحفظ Pytesseract الصورة إلى ملف مؤقت على القرص ، ثم يستدعي الملف الثنائي tesseract ويكتب النتيجة إلى ملف.
تم تطوير هذا المجمع بواسطة Google وهو مجاني ومجاني للاستخدام. يمكن استخدامه لأغراضه الخاصة والتجارية. تعمل المكتبة بدون اتصال بالإنترنت ، وتدعم العديد من اللغات للتعرف عليها وتبهر بسرعتها. يمكن العثور على تطبيقه في العديد من التطبيقات الشعبية.
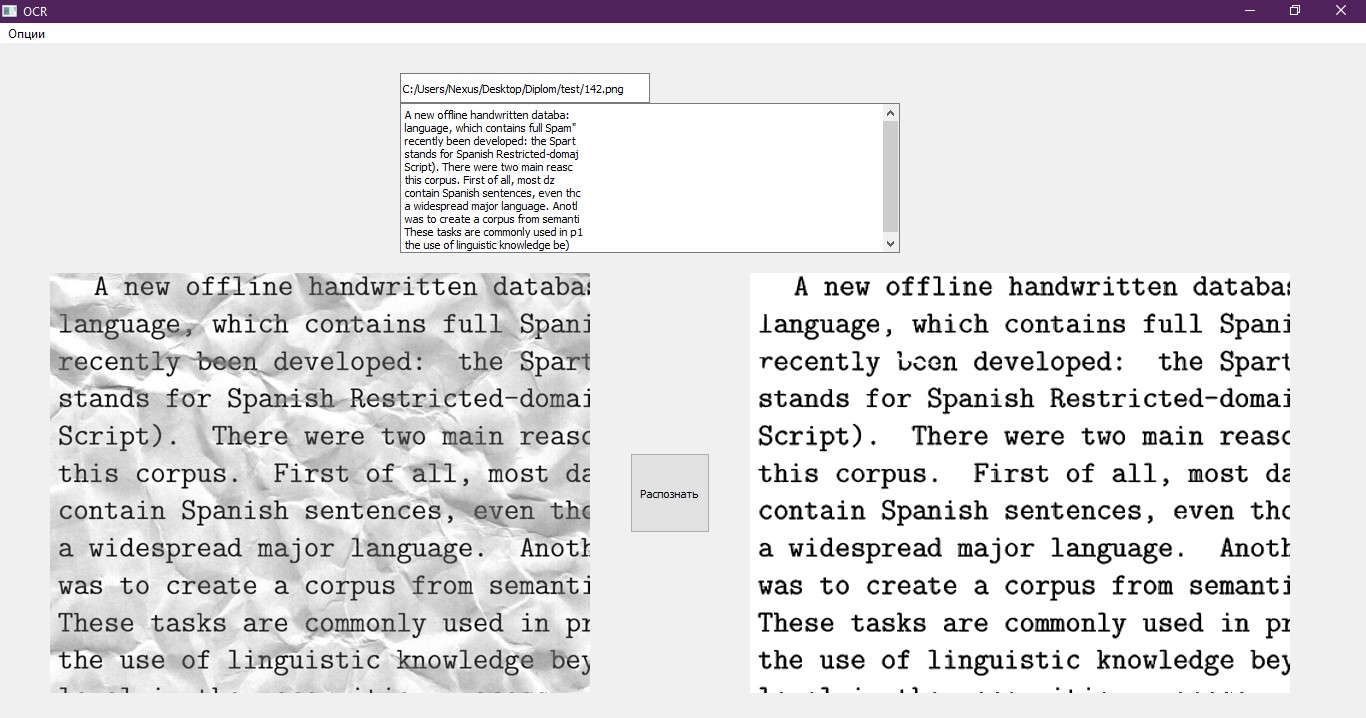
العنصر الأخير المتبقي هو كتابة النص الذي تم التعرف عليه إلى ملف بتنسيق مناسب لمعالجته. نستخدم لهذا الكمبيوتر المحمول العادي ، والذي يفتح بعد انتهاء البرنامج. أيضا ، يتم عرض النص على واجهة الاختبار. مثال جيد للواجهة.
المراجع:
- قصة النصر في مسابقة التعرف على الوثائق الدولية لفريق SmartEngines [المورد الإلكتروني]. وضع الوصول: https://habr.com/company/smartengines/blog/344550/
- تجزئة الصورة باستخدام شبكة عصبية: U-Net [مورد إلكتروني]. وضع الوصول: http://robocraft.ru/blog/machinelearning/3671.html
> مستودع جيثب