
مرحبا بالجميع!
من خلال مواصلة دراسة موضوع
التعلم العميق ، أردنا مرة التحدث معك عن
سبب ظهور الأغنام في كل مكان في الشبكات العصبية .
تمت مناقشة هذا الموضوع في الفصل التاسع من كتاب فرانسوا شول.
وهكذا ، ذهبنا إلى الدراسات الرائعة للتكنولوجيا الإيجابية ،
المقدمة في حبري ، وكذلك إلى العمل الممتاز الذي قام به اثنان من موظفي معهد ماساتشوستس للتكنولوجيا الذين يعتبرون أن "التعلم الآلي الخبيث" ليس مجرد عائق ومشكلة ، ولكنه أيضًا أداة تشخيصية رائعة.
التالي - تحت الخفض.
على مدى السنوات القليلة الماضية ، جذبت حالات التدخل الخبيث اهتمامًا جادًا في مجتمع التعلم العميق. في هذه المقالة ، نود أن نلخص هذه الظاهرة بعبارات عامة ونناقش كيف تتناسب مع السياق الأوسع لموثوقية التعلم الآلي.
التدخلات الخبيثة: ظاهرة مثيرة للاهتماملتحديد نطاق مناقشتنا ، نقدم بعض الأمثلة على مثل هذا التدخل الضار. نعتقد أن معظم الباحثين المشاركين في منطقة موسكو قد صادفوا صورًا مشابهة:
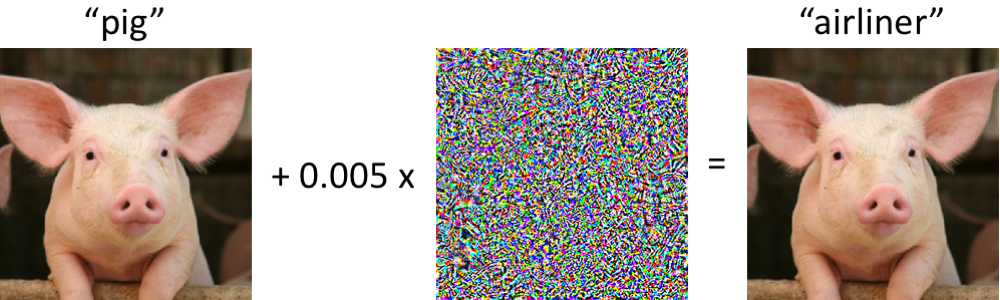
على اليسار خنزير ، يصنف بشكل صحيح على أنه خنزير صغير من قبل الشبكة العصبية التلافيفية الحديثة. بمجرد إجراء تغييرات طفيفة على الصورة (جميع وحدات البكسل في النطاق [0 ، 1] ، وكل تغيير بما لا يزيد عن 0.005) - والآن تقوم الشبكة بإرجاع فئة "الطائرة" بموثوقية عالية. هذه الهجمات على المصنفات المدربة معروفة منذ عام 2004 (
link ) على الأقل ، وتعود الأعمال الأولى على التداخل الضار مع مصنفات الصور إلى عام 2006 (
link ). ثم بدأت هذه الظاهرة تجذب المزيد من الاهتمام بشكل كبير منذ حوالي عام 2013 ، عندما اتضح أن الشبكات العصبية عرضة لهجمات من هذا النوع (انظر
هنا وهنا ). منذ ذلك الحين ، اقترح العديد من الباحثين خيارات لبناء أمثلة خبيثة ، بالإضافة إلى طرق لزيادة مقاومة المصنفات لهذه الاضطرابات المرضية.
ومع ذلك ، من المهم أن نتذكر أنه ليس من الضروري الخوض في الشبكات العصبية من أجل ملاحظة مثل هذه الأمثلة الخبيثة.
ما مدى قوة أمثلة البرامج الضارة؟ربما يكون الوضع الذي يخلط فيه الكمبيوتر بين الخنزير والطائرة قد يكون مقلقًا في البداية. ومع ذلك ، تجدر الإشارة إلى أن المصنف المستخدم في هذه الحالة (
شبكة Inception-v3 ) ليس هشًا كما قد يبدو للوهلة الأولى. على الرغم من أن الشبكة ربما تكون مخطئة عند محاولة تصنيف خنزير صغير مشوه ، يحدث هذا فقط في حالة الانتهاكات المحددة بشكل خاص.
الشبكة أكثر مقاومة للاضطرابات العشوائية ذات الحجم المماثل. لذلك ، فإن السؤال الرئيسي هو ما إذا كانت الاضطرابات الخبيثة هي التي تسبب هشاشة الشبكات. إذا كان الخبث في حد ذاته يعتمد بشكل كبير على التحكم في كل بكسل إدخال ، فعند تصنيف الصور في ظروف واقعية ، لا يبدو أن هذه العينات الخبيثة مشكلة خطيرة.
تشير الدراسات الحديثة إلى خلاف ذلك: من الممكن ضمان استقرار الاضطرابات لتأثيرات القنوات المختلفة في سيناريوهات مادية محددة. على سبيل المثال ، يمكن طباعة عينات ضارة على طابعة مكتبية عادية ، لذلك
لا تزال الصور التي تم تصويرها عليها بواسطة كاميرا الهاتف الذكي
غير مصنفة بشكل صحيح . يمكنك أيضًا إنشاء ملصقات ، بسبب الشبكات العصبية التي تصنف المشاهد الحقيقية المختلفة بشكل غير صحيح (انظر ، على سبيل المثال ،
link1 و
link2 و
link3 ). أخيرًا ، قام الباحثون مؤخرًا بطباعة سلحفاة ثلاثية الأبعاد على طابعة ثلاثية الأبعاد ، والتي
تعتبرها شبكة Inception القياسية عن طريق الخطأ
بندقية في أي زاوية عرض تقريبًا.
التحضير لهجوم التصنيف الخاطئكيفية خلق مثل هذه الاضطرابات الخبيثة؟ هناك العديد من المقاربات ، لكن التحسين يتيح لنا اختزال كل هذه الأساليب المختلفة إلى تمثيل معمم. كما تعلم ، غالبًا ما يتم صياغة تدريب المصنف كإيجاد معلمات نموذجية
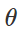
لتقليل دالة الخسارة التجريبية لمجموعة معينة من الأمثلة

:
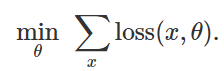
لذلك ، من أجل إثارة تصنيف خاطئ لنموذج ثابت
ومدخلات "غير ضارة"
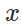
حاول بشكل طبيعي أن تجد اضطرابًا محدودًا

مثل هذه الخسائر في

تبين أن الحد الأقصى:
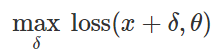
استنادًا إلى هذه الصيغة ، يمكن اعتبار العديد من الطرق لإنشاء إدخال ضار خوارزميات تحسين مختلفة (خطوات التدرج الفردية ، نزول التدرج المتوقع ، إلخ) لمجموعات مختلفة من القيود (صغيرة
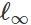
- اضطراب عادي ، تغييرات صغيرة في البكسل ، إلخ.). يتم تقديم عدد من الأمثلة في المقالات التالية:
link1 و
link2 و
link3 و
link4 و
link5 .
كما هو موضح أعلاه ، تعمل العديد من الطرق الناجحة لتوليد عينات ضارة مع مصنف هدف ثابت. لذلك فإن السؤال المهم هو: ألا تؤثر هذه الاضطرابات على نموذج مستهدف محدد فقط؟ من المثير للاهتمام ، لا. عند استخدام العديد من طرق الاضطراب ، يتم نقل العينات الخبيثة الناتجة من المصنف إلى المصنف المدرب بمجموعة مختلفة من القيم العشوائية الأولية (البذور العشوائية) أو بنيات نموذجية مختلفة. علاوة على ذلك ، يمكنك إنشاء عينات ضارة لديها وصول محدود فقط إلى النموذج المستهدف (أحيانًا في هذه الحالة يتحدثون عن "هجمات الصندوق الأسود"). انظر ، على سبيل المثال ، المقالات الخمس التالية:
link1 و
link2 و
link3 و
link4 و
link5 .
ليس مجرد صورتم العثور على عينات ضارة ليس فقط في تصنيف الصور. تُعرف ظواهر مماثلة في
التعرف على الكلام وفي
أنظمة الإجابة على الأسئلة وفي
التعلم المعزز وفي حل المشكلات الأخرى. كما تعلم ، فإن دراسة العينات الخبيثة مستمرة منذ أكثر من عشر سنوات:
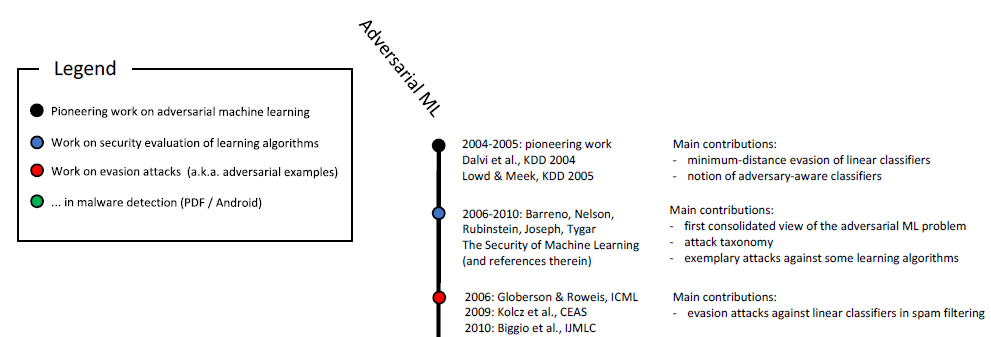
المقياس الزمني للتعلم الآلي الضار (البداية). يظهر المقياس الكامل في الشكل. 6 في
هذه الدراسة .
بالإضافة إلى ذلك ، تعد التطبيقات المتعلقة بالأمان وسيلة طبيعية لدراسة الجوانب الخبيثة للتعلم الآلي. إذا تمكن المهاجم من خداع المصنف وتمرير المدخلات الضارة (مثل البريد العشوائي أو الفيروسات) على أنه غير ضار ، فإن كاشف البريد العشوائي أو الماسح الضوئي لمكافحة الفيروسات بناءً على التعلم الآلي لن يكون
فعالاً . يجب التأكيد على أن هذه الاعتبارات ليست أكاديمية بحتة. على سبيل المثال ، نشر فريق Google Safebrowsing في عام 2011 دراسة
متعددة السنوات حول كيفية محاولة المهاجمين التحايل على أنظمة الكشف عن البرامج الضارة. راجع أيضًا هذه
المقالة حول العينات الضارة في سياق تصفية البريد العشوائي في بريد Gmail.
ليس فقط السلامةيتم الحفاظ على جميع الأعمال الأخيرة في دراسة العينات الخبيثة بشكل واضح للغاية في مفتاح ضمان الأمن. هذه وجهة نظر معقولة ، لكننا نعتقد أنه يجب النظر في مثل هذه العينات في سياق أوسع.
الموثوقيةبادئ ذي بدء ، تثير العينات الخبيثة مسألة موثوقية النظام بأكمله. قبل أن نتمكن من مناقشة خصائص المصنف بشكل معقول من وجهة نظر السلامة ، يجب أن نتأكد من أن الآلية توفر دقة تصنيف عالية. في النهاية ، إذا كنا سننشر نماذجنا المدربة في سيناريوهات العالم الحقيقي ، فمن الضروري أن تظهر درجة عالية من الموثوقية عند تغيير توزيع البيانات الأساسية - بغض النظر عما إذا كانت هذه التغييرات ناتجة عن تداخل ضار أو مجرد تقلبات طبيعية.
في هذا السياق ، تعد نماذج البرامج الضارة أداة تشخيصية مفيدة لتقييم موثوقية أنظمة التعلم الآلي. على وجه الخصوص ، يسمح لك النهج القائم على البرامج الضارة بتجاوز بروتوكول التقييم القياسي ، حيث يتم تشغيل المصنف المدرب على مجموعة اختبار مختارة بعناية (وعادة ثابتة).
حتى تتمكن من الوصول إلى استنتاجات مذهلة. على سبيل المثال ، اتضح أنه يمكن للمرء بسهولة إنشاء عينات ضارة دون اللجوء إلى أساليب التحسين المعقدة. في
ورقة بحث حديثة ، نظهر أن مصنفات الصور المتطورة معرضة بشكل مدهش للتحولات أو المنعطفات المرضية الصغيرة. (انظر
هنا وهنا لمزيد من الأعمال حول هذا الموضوع.)

لذلك ، حتى لو لم نعلق أهمية ، على سبيل المثال ، على الاضطرابات الناتجة عن التفريغ، ، غالبًا ما تنشأ مشاكل في الموثوقية بسبب الدوران والتحولات. بالمعنى الأوسع ، من الضروري فهم مؤشرات الموثوقية لمصنفاتنا قبل أن يتم دمجها في أنظمة أكبر كمكونات موثوقة حقًا.
مفهوم المصنفاتلفهم كيفية عمل المصنف المدرب ، تحتاج إلى العثور على أمثلة لعملياته الناجحة أو الفاشلة بشكل واضح. في هذه الحالة ، توضح العينات الخبيثة أن الشبكات العصبية المدربة غالبًا لا تتوافق مع فهمنا الحدسي لما يعنيه "تعلم" مفهوم معين. هذا مهم بشكل خاص في التعلم العميق ، حيث غالبًا ما يتم المطالبة بالخوارزميات والشبكات المعقولة بيولوجيًا والتي لا يكون نجاحها أدنى من النجاح البشري (انظر ، على سبيل المثال ،
هنا ،
هنا أو
هنا ). من الواضح أن العينات الخبيثة تجعل المرء يشك في ذلك في سياقات عديدة:
- عند تصنيف الصور ، إذا تم تغيير مجموعة وحدات البكسل إلى الحد الأدنى أو تم تدوير الصورة قليلاً ، فهذا بالكاد يمنع الشخص من تعيينها للفئة الصحيحة. ومع ذلك ، يتم قطع هذه التغييرات تمامًا من قبل المصنفين الأكثر حداثة. إذا وضعت أشياء في مكان غير عادي (على سبيل المثال ، الأغنام على شجرة ) ، فمن السهل أيضًا التأكد من أن الشبكة العصبية تفسر المشهد بشكل مختلف تمامًا عن الإنسان.
- إذا قمت باستبدال الكلمات الضرورية في فقرة نصية ، يمكنك أن تخلط نظام الإجابة على الأسئلة بشكل جدي ، على الرغم من أنه من وجهة نظر الشخص ، لن يتغير معنى النص بسبب هذه الإدخالات.
- خلال هذه المقالة ، تظهر أمثلة نصية مختارة بعناية حدود الترجمة من Google.
في جميع الحالات الثلاث ، تساعد الأمثلة الخبيثة في اختبار نماذجنا الحالية للقوة والتأكيد في المواقف التي تتصرف فيها هذه النماذج بشكل مختلف تمامًا عما يفعله الشخص.
الأمانأخيرًا ، تمثل العينات الضارة خطرًا في المناطق التي يحقق فيها تعلُم الآلة بالفعل دقة معينة في المواد "غير الضارة". قبل بضع سنوات فقط ، كانت مهام مثل تصنيف الصور لا تزال تؤدي بشكل سيئ للغاية ، لذلك كانت المشكلة الأمنية في هذه الحالة تبدو ثانوية. في النهاية ، تصبح درجة أمان نظام التعلم الآلي مهمة فقط عندما يبدأ هذا النظام في معالجة المدخلات "غير الضارة" بجودة كافية. خلاف ذلك ، ما زلنا لا نثق في توقعاتها.
الآن ، في مجالات موضوعية مختلفة ، تحسنت دقة هذه المصنفات بشكل ملحوظ ، ونشرها في المواقف التي تعتبر فيها اعتبارات السلامة حاسمة مسألة وقت فقط. إذا أردنا التعامل مع هذا الأمر بمسؤولية ، فمن المهم التحقيق في خصائصهم بدقة في سياق الأمان. لكن قضية الأمن تحتاج إلى نهج شامل. إن تزوير بعض الميزات (على سبيل المثال ، مجموعة من وحدات البكسل) أسهل بكثير من ، على سبيل المثال ، الطرائق الحسية الأخرى أو الميزات الفئوية أو البيانات الوصفية. في النهاية ، عند ضمان الأمان ، من الأفضل الاعتماد على تلك العلامات التي يصعب تغييرها أو حتى شبه المستحيل.
النتائج (هل من السابق لأوانه الفشل؟)على الرغم من التقدم المثير للإعجاب في التعلم الآلي الذي شهدناه في السنوات الأخيرة ، إلا أنه من الضروري مراعاة حدود إمكانيات الأدوات التي لدينا. هناك مجموعة متنوعة من المشاكل (مثل تلك المتعلقة بالصدق أو الخصوصية أو تأثيرات التغذية المرتدة) ، والموثوقية هي مصدر قلق كبير. إن الإدراك البشري والإدراك يقاومان مجموعة متنوعة من التدخلات البيئية الخلفية. ومع ذلك ، تظهر العينات الخبيثة أن الشبكات العصبية لا تزال بعيدة جدًا عن المرونة المماثلة.
لذا ، نحن على يقين من أهمية دراسة الأمثلة الخبيثة. إن قابليتها للتطبيق في التعلم الآلي لا تقتصر على القضايا الأمنية ، ولكنها يمكن أن تكون بمثابة
معيار تشخيصي لتقييم النماذج المدربة. يقارن النهج الذي يستخدم عينات ضارة بشكل إيجابي مع إجراءات التقييم القياسية والاختبارات الثابتة من حيث أنه يحدد العيوب المحتملة غير الواضحة. إذا أردنا أن نفهم موثوقية التعلم الآلي الحديث ، فإن أهم الإنجازات مهمة للتحقيق من وجهة نظر المهاجم (اختيار عينات ضارة بشكل صحيح).
طالما أن المصنفات لدينا تفشل حتى مع الحد الأدنى من التغييرات بين التدريب وتوزيع الاختبار ، لا يمكننا تحقيق موثوقية مضمونة مرضية. في النهاية ، نسعى جاهدين لإنشاء نماذج لن تكون موثوقة فحسب ، بل ستكون متسقة مع أفكارنا البديهية حول معنى "دراسة" مشكلة ما. ثم ستكون آمنة وموثوقة وسهلة النشر في مجموعة متنوعة من البيئات.