أريد أن أتحدث عن تجربتنا في تطوير التطبيقات على أساس منصة بحث النص الكامل Apache Solr.
كانت مهمتنا هي تطوير نظام تحليل الكلام لمراكز الاتصال. يعتمد النظام على تقنيتين أساسيتين: التعرف على الكلام والبحث المفهرس. للتعرف على ذلك ، استخدمنا محركاتنا ، وللفهرسة والبحث ، اخترنا Solr.
لماذا سولر؟ لم نجري بحثنا المقارن لمحركات البحث المفهرسة ، ولكننا فحصنا بعناية
آراء زملائنا . بالطبع ، يمكن إجراء الاختيار لصالح Elasticsearch أو Sphinx ، ولكن ، على ما يبدو ، شكلت النجوم في مشروعنا لصالح Solr ، "رأينا" ذلك. بالفعل خلال فترة المشروع ، قررنا أن الإعدادات المتاحة في Solr كافية لتكوين مهامنا.
ميزات مشروعنا
تم تطوير النظام لتحليل مكالمات العملاء ، والتي يتم تسجيلها في مركز الاتصال لمراقبة جودة الخدمة. لا يحلل الصوت ، ولكن النص الذي تم الحصول عليه نتيجة التعرف التلقائي على الحوار. تختلف نصوص الكلام المعترف بها اختلافًا جوهريًا عن النصوص التي نواجهها بانتظام على مواقع الويب أو البريد الإلكتروني. حتى مع دقة التعرف بنسبة 100 ٪ ، قد يبدو أن نصوص الكلام التلقائي المعترف بها ليس لها معنى.
هذا يرجع إلى عاملين رئيسيين. أولاً ، في الكلام الشفهي ، يتم استخدام تعبيرات غير اللفظية والوجه في كثير من الأحيان ، والتي لم يتم التعرف عليها في النص ، ولكنها مهمة لفهم ما قيل. ثانيًا ، يتم استخدام الاختصارات والسهو في الهياكل اللغوية باستمرار في الكلام ، والتي يمكن استعادتها من سياق حالة التواصل. تسمى هذه الظاهرة في اللغويات القطع الناقص.
لترى بأم عينيك نص الخطاب الذي تم التعرف عليه بكل ميزاته ، انظر إلى الترجمات التلقائية للفيديو على يوتيوب مع إيقاف تشغيل الصوت. حول هذا المحتوى ، تذهب المادة إلى إدخال نظام تحليلات الكلام.
استعلامات معقدة
على الرغم من أن Solr يدعم
البيانات والتجمعات الشرطية القياسية ، إلا أن هذه القدرات غالبًا ما تكون غير كافية لتنفيذ جميع السيناريوهات للمحللين.
غالبًا ما يحتاج المحلل إلى إنشاء استعلام باستخدام معلمات غير مضمنة في فهرس Solr. على سبيل المثال ، ابحث عن جميع الكلمات "شكرًا لك" التي تم نطقها في آخر 30 ثانية من المحادثة. يتم فهرسة الكلمات بواسطة Solr ، ولكن لا توجد مواقف كلمات مؤقتة. نحن نسمي مثل هذه الاستعلامات "المعقدة" - الاستعلامات التي تتضمن معلمات مؤشر Solr وأي معلمات اختيار بيانات أخرى غير مضمنة في فهرس Solr.
كيف يقوم المحلل بتكوين الاستفسارات؟
ليس لدى المحلل فكرة عن تكوين مؤشر Solr ، فمن المهم بالنسبة له أن يبحث ويقطع جميع سمات التسجيلات الصوتية للمكالمات ونسخها النصية. لذلك ، فإن مفهوم "الاستعلام المعقد" للمحلل هو عملي بحتة: الاستعلامات التي يوجد بها العديد من معلمات التحديد ، أو الاستعلامات مرتبة في التسلسل الهرمي.
في وصف تصرفات المحلل في لغة نظرية المجموعات ، يمكن القول أنه بمساعدة الاستفسارات ، يستكشف المحلل العلاقات بين مجموعات فرعية مختلفة: التقاطعات والاختلافات والإضافات. باستخدام الاستفسارات الهرمية ، يقوم المحلل بتحليل مجموعة البيانات إلى المستوى المطلوب من التفاصيل من هيكلها.
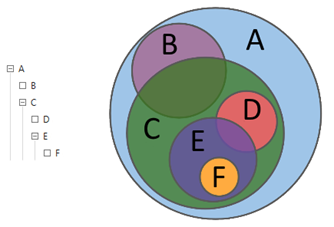 الشكل 1. الشكل 1. الاستفسارات الهرمية
الشكل 1. الشكل 1. الاستفسارات الهرميةيوضح الشكل 2 مثالاً كلاسيكياً لاستعلام معقد يحتوي على معايير اختيار نصية ورقمية.
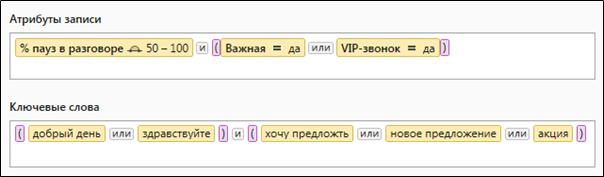 الشكل 2. استعلام معقد يحتوي على معلمات اختيار البيانات الكمية والمعجمية
الشكل 2. استعلام معقد يحتوي على معلمات اختيار البيانات الكمية والمعجميةكيف تبدو الاستعلامات لـ Solr؟
خذ بعين الاعتبار الآلية العامة لتنفيذ استعلام في Solr باستخدام مثال الاستعلام
B في الشكل 1. كما نرى ، يحتوي الاستعلام
B على استعلام
أصل A ، وبعبارة أخرى
B⊆A . في تحليلات الكلام ، لا يمكن تلبية الطلب في حين أن واحدًا على الأقل من "والديه" لم يتم الوفاء به. وبالتالي ، يتم تنفيذ الاستعلام
أ أولاً ، وعندها فقط
ب. من الواضح أن
B يجب أن يحتوي على شروط الاستعلام
A.أول شيء يتبادر إلى الذهن هو دمج شروط كل من الاستعلامات من خلال
AND ولصقها في
query :
q=key:A AND key:Bومع ذلك ، إذا قمنا ببساطة بدمج جميع الاستعلامات المتتالية في
query واحد ، فسيكون كبيرًا ، وسيكون مختلفًا لكل استعلام وسيتم حسابه بالكامل. كما أن الشروط
A ستؤثر على صلة نتائج الاستعلام
B ، وهو أمر غير مرغوب فيه.
دعنا نحاول إضافة استعلامات
FilterQuery مثل
FilterQuery . في هذه الحالة ، لن يتأثر الاستعلام
أ بعدم الصلة بالموضوع ويمكننا أن نتوقع أن يكون قد اكتمل بالفعل وأن نتائجه موجودة في ذاكرة التخزين المؤقت. وبالتالي ، سيتعين على Solr حساب الاستعلام
B فقط ، بينما يقوم Solr بفرز التحديد الناتج بالطريقة التي نحتاجها:
q=keyword:B &fq=keyword:Aإذا أخذنا في الاعتبار تنسيق الطلب إلى Solr بشكل تخطيطي ، يمكننا تمييز كيانين رئيسيين:
MainQuery - الاستعلام الرئيسي مع مجموعة من المعلمات التي يجب أن تفي بها الوثيقة. على سبيل المثال ، قد يبدو طلب البحث عن عوامل تشغيل مهذبة بالشكل التالي: text_operator: ” ” .
هذا يعني أن حقل text_operator لوثيقة البحث يجب أن يحتوي على عبارة “ ”
FilterQuery - مجموعة من المرشحات الإضافية التي تحد من التحديد الناتج. FilterQuery تنسيق MainQuery مع MainQuery
يتيح لك تقسيم الطلب إلى
Main Filter ما يلي:
- الإشارة صراحةً إلى معلمات الاستعلام التي يجب أن تؤثر على رتبة المستند في التحديد ، والتي تخدم فقط التحديد في التحديد الناتج. يتم حساب مدى الصلة ببناء ترتيب المستندات عند تنفيذ جزء من استعلام MainQuery ، وعند تنفيذ جزء من استعلام
FilterQuery يتم FilterQuery المستندات التي لا تستوفي شروط الاستعلام - تقليل الحمل بشكل كبير على محرك البحث ، نظرًا لأن العينة الناتجة التي تم الحصول عليها بعد
FilterQuery حسابات FilterQuery يتم تخزينها مؤقتًا ، في حين يتم تخزين نتائج حساب MainQuery في ذاكرة التخزين المؤقت فقط MainQuery في رتبة 50 قيمة
MainQuery و
FiletrQuery تأثيرات مختلفة على وظائف
FiletrQuery . على سبيل المثال ،
MainQuery ، الوظيفة المسؤولة عن تمييز أجزاء الوثيقة ذات الصلة ، فقط
MainQuery ، ولا تؤثر معلمات
FilterQuery على
highlighting . يعد هذا
MainQuery منطقيًا ، لأنه يتم حساب الملاءمة تمامًا في جزء استعلام
MainQuery . هذا ما يبدو عليه
highlighting النتائج في البحث الحقيقي عن النصوص التي تحتوي على الكلمتين "hello" و "services".
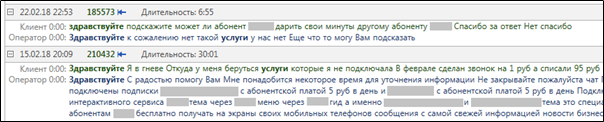 الشكل 3. تسليط الضوء على الكلمات ذات الصلة بعد إكمال استعلام
الشكل 3. تسليط الضوء على الكلمات ذات الصلة بعد إكمال استعلام MainQuery .
استعلامات معقدة في Solr
دعنا نعود إلى مثال عامل مهذب. في هذا المثال ، حددنا المكالمات المناسبة من خلال وجود عبارة "مساء الخير" في كلام المشغل ، ولكننا لم نشير إلى الفاصل الزمني للبحث عن الكلمات الرئيسية المتعلقة ببداية أو نهاية المحادثة.
يبدو أن هناك كل ما هو ضروري لذلك - يحتوي النص النصي للمحادثة الهاتفية على الطابع الزمني لكل كلمة ، بالإضافة إلى معلومات حول أي من المشاركين في الحوار الذي تنتمي إليه. يمكن استخدام هذه البيانات أيضًا في البحث.
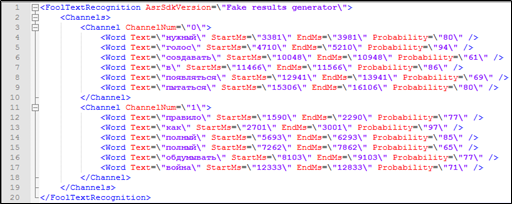 الشكل 4. جزء من فك التشفير النصي مع ترميز غير مضمن في فهرس Solr: انتماء المتحدث ، الطوابع الزمنية.
الشكل 4. جزء من فك التشفير النصي مع ترميز غير مضمن في فهرس Solr: انتماء المتحدث ، الطوابع الزمنية.ولكن كيف تتم معالجة استعلام البحث إلى Solr ، إذا كانت المعلمات غير القابلة للفهرسة متضمنة في الاستعلام - وقت نطق الكلمة؟
تنشأ طريقتان واضحتان لحل هذه المشكلة:
- إضافة معلمات غير مفهرسة إلى فهرس Solr. في الوقت نفسه ، سيزداد استهلاك الذاكرة قليلاً ، لكن المؤشر سيكون أثقل بشكل ملحوظ
- يجب أن يتم اختيار البيانات بواسطة معلمات غير قابلة للفهرسة باستخدام خدمتها ، وفي جمع الوثائق التي تم الحصول عليها بعد هذا الاختيار ، ابحث باستخدام فهرس Solr. في الوقت نفسه ، سيكون استهلاك الذاكرة أكبر بكثير مما كان عليه في الحالة الأولى ، ولكن سيكون الأداء متوقعًا
لقد اخترنا الخيار الثاني. للقيام بذلك ، قمنا بتطوير خدمة تحسب المجموعات عن طريق الطلبات التي تحتوي على أي معلمات منطقية ورقمية غير مدرجة في فهرس Solr. نتيجة لعمل هذه الخدمة ، تم تمييز الجزء من المجموعة الذي لم يستوف الطلب بعلامة خاصة ("هرب") ثم لم يشارك في حساب نتائج الاستعلام.
تخيل أننا نريد فرض قيود على البحث على الاستعلام
B الذي نعرفه بالفعل ، فقط في أول 30 ثانية من مربع الحوار. في المرحلة الأولى ، نقوم بتنفيذ
B كاستعلام بسيط ، ثم "شاشة" الكلمات التي تتجاوز النطاق المحدد بحيث لا تقع في فهرس Solr ، ولكن في نفس الوقت ، يمكننا استعادة المستند الأصلي منها. يتم وضع المستندات الناتجة في مجموعة Solr منفصلة ويتم إعادة البحث عن الاستعلام
B عليها.
هنا يجب أن أقول إن القيود المفروضة على بداية أو نهاية المحادثة هي الزهور ، والتوت قيود على نتائج طلب الوالدين. النظر في تنفيذ مثل هذا الطلب.
تخيل أن وثائقنا تتكون من كرات بأرقام. لنحاول العثور على جميع الكرات "6" الموجودة في ما لا يزيد عن كرتين على يمين "5".
لقد أدركت بالفعل أن أرقام الكرة مضمنة في مؤشر Solr ، ولا توجد مسافة بين الكرات.
|  |
البحث عن جميع المستندات التي تحتوي على الكرات "6" و "5". بصفتنا MainQuery نستخدم استعلامًا عن الكرات "5" ، واستعلامًا عن "6" سنرسل إلى FilterQuery . نتيجة لذلك ، سوف يسلط Solr الضوء على الكرات "5" في نتائج البحث ، والتي ستبسط حياتنا بشكل كبير في الخطوة التالية. | 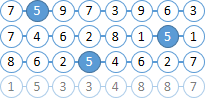 |
| نقوم بفحص جميع الكرات باستثناء تلك الموجودة على مسافة مرغوبة من "5". سيتم وضع المستندات المستلمة (المستندات التي تحتوي على الكرات المطلوبة) في مجموعة منفصلة. |  |
FilterQuery على الكرات "6" في المجموعة الناتجة ، والنتيجة هي المستندات التي FilterQuery عنها. |  |
من الناحية العملية ، عادة ما تخفي الكرات 5 و 6 الاستعلامات التي تشغل عدة شاشات في تمثيلها النصي. أنا سعيد لأننا نفذنا هذا البحث دون جدوى - غالبًا ما يستخدم المحللون الاستفسارات مع قيود من الوالدين.
الخلاصة
ماذا تعلمنا ، وماذا تعلمنا وماذا حققنا نتيجة للمشروع؟
نحن نعلم كيفية استخدام Solr بشكل فعال للعمل مع البيانات من أنواع مختلفة ، يمكننا "تعليم" Solr لمعالجة الاستعلامات مع المعلمات غير المدرجة في فهرس البحث الخاص بها.
لقد قمنا بتطوير نظام تحليلي صوتي صناعي يعمل تحت حمولة عالية: يتم احتساب استعلامات البحث المعقدة للمحللين لعينات تصل إلى خمسة ملايين مستند نصي. إنه ممكن وأكثر ، ولكن لم تكن هناك حاجة عملية. تصل عينة العمل المعتادة للمحلل إلى حوالي 500 ألف رسالة نصية من المكالمات الهاتفية المعروفة ، ويمكن أن يصل العدد الإجمالي للمكالمات إلى 15 مليونًا.
بالنسبة لعملائنا في مراكز الاتصال ، يوفر النظام فرصًا غير مسبوقة للتحليلات ذات الطبيعة المختلفة تمامًا: تحليل الموضوعات وأسباب الطلبات ، وتحليل رضا العملاء وغيرها الكثير.
نحن الآن بصدد ربط مصادر جديدة بتحليلاتنا - الدردشات النصية للعملاء مع المشغلين. ننفذ تطبيقًا واحدًا لتحليل مكالمات العملاء عبر جميع قنوات مركز الاتصال: الهاتف والدردشة والنماذج على المواقع وما إلى ذلك.
سنكون سعداء للإجابة على أسئلتكم.
شكرا لك
PS Solr هو شيء صعب للغاية ويتطلب ضبطًا جيدًا للحصول على نتائج جيدة. سنخبر عن تجربتنا في هذا المجال في المقالات التالية.