لقد أخبرناك بالفعل عن
الإحصائيات المثيرة للاهتمام
للنصوص ، وقمنا
بمراجعة المقالات حول استخدام أجهزة التشفير الآلي في تحليل النصوص ، وفاجأنا بخوارزميات
البحث الجديدة
الخاصة بنا للاقتراضات القابلة للتحويل وإعادة
الصياغة . قررت مواصلة تقاليد الشركة ، أولاً ، ابدأ المقالة بـ "T" ، وثانيًا ، أخبر:
- كيفية العثور بسرعة على فقرة من النص بين مئات الملايين من المقالات ؛
- ما الذي تتحول إليه الوثيقة بعد تحميلها في نظام مكافحة الانتحال ، وماذا تفعل بعد ذلك ؛
- كيف يتم تشكيل تقرير لا ينظر إليه أحد تقريبًا ، ولكنه يستحق ذلك ؛
- كيفية فهرسة ليس كل شيء ، ولكن يكفي.

كيف بدأ كل شيء
في عام 2005 ، أتى إلينا عميد إحدى أكبر جامعات موسكو في
Forecsys لحل مشكلة خطيرة للغاية - في المؤسسات التعليمية ، اجتاز الطلاب الدبلومات المشطوبة بالكامل والأوراق الدراسية. أخذنا عدة مئات من الأعمال للطلاب المتفوقين وبحثنا عنها في الشبكة باستفسارات بسيطة. تبين أن أكثر من نصف
"الطلاب المتفوقين" هم محتالون قاموا بتنزيل دبلوم من الإنترنت واستبدلوا صفحة العنوان فقط. أكثر من نصف الطلاب المتفوقين ، كارل! ما حدث للطلاب العاديين يصعب تخيله. إن أسهل طريقة للبحث عن وظيفة هي الاستعلام الذي يحتوي على كلمات تحتوي على "ثقوب سوداء". لقد أدركنا حجم الكارثة. كان من الملح حل شيء ما. بحلول ذلك الوقت ، كانت الجامعات الأجنبية الناطقة باللغة الإنجليزية تستخدم بالفعل حلول استعارة البحث ، ولكن لسبب ما لم يقم أحد بفحص العمل باللغة الروسية.
لم يرغب اللاعبون الأجانب في تكييف حلولهم مع اللغة الروسية في ذلك الوقت. ونتيجة لذلك ، في 17 مارس 2005 ، بدأ تطوير أول نظام بحث عن الاقتراض المحلي. تم ابتكار كلمة "مكافحة الانتحال" بعد ذلك بقليل ، وتم تسجيل المجال antiplagiat.ru في 28 أبريل 2005. خططنا لإطلاق الموقع بحلول 1 سبتمبر 2005 ، ولكن ، كما هو الحال غالبًا مع المبرمجين ، لم يكن لدينا الوقت. عيد الميلاد الرسمي لشركتنا هو اليوم الذي تلقى فيه antiplagiat.ru المستخدمين الأوائل ، أي 4 سبتمبر. كما تعلم ، أنا سعيد بذلك ، لأنه خلال حفلة الشركة بمناسبة عيد ميلاد الشركة ، يمكن للجميع الاحتفال بهدوء وعدم القلق بشأن أول يوم دراسي لأطفالهم.
لكن شيئًا كان مشتتًا. في عام 2005 ، أنشأنا نوعًا من محركات البحث ، حيث ، على عكس ياندكس وجوجل ، فإن الاستعلام ليس كلمتين أو ثلاث كلمات ، ولكنه نص كامل يتكون من عدة جمل. لذلك ، من المعقول استخدام "مكافحة الانتحال" إذا كان لديك نص من 1000 حرف (هذا حوالي نصف صفحة).
أثناء تطوير الخدمة ، تم عمل نموذج أولي على php (جزء الويب) و Microsoft SQL Server (محرك البحث). أصبح من الواضح على الفور أن هذا لن ينطلق وسيعمل ببطء على عدة ملايين من الوثائق. لذلك ، كان علي قطع محرك البحث الخاص بي. الآن تمت كتابة النظام في C # و python ، ويستخدم PostgreSQL و MongoDB (في الواقع ، الكثير ، ولكن المزيد عن ذلك في المقالة التالية). لا يزال محرك البحث مطورًا بالكامل من قبلنا.
ضع الإعجابات اكتب في التعليقات إذا كنت تريد التعرف على تاريخ تطور النظام ، والتغيير في عمليات الشركة والأجهزة التي عملت عليها Antiplagiarism في أوقات مختلفة من حياتها ، وهي تعمل الآن.
أصبحت الكلمة التي أعطت اسم الشركة كلمة منزلية. في كثير من الأحيان في محرك البحث ، يمكن للمرء أن يجد عبارات مثل "التحقق من مكافحة الانتحال" ، "زيادة مكافحة الانتحال". كل من يرتبط بطريقة ما بمجال استعارة البحث في روسيا والدول المجاورة يحاول استخدام كلمة "مكافحة الانتحال" لرفعها في نتائج البحث. غالبًا ما يُسأل عن "مناهضة الانتحال" الأخرى. لذا ، فإن "مكافحة الانتحال" واحدة ، وهي علامة تجارية واسم لشركتنا.
في بداية تنفيذ خدمة البحث عن القرض ، قررنا أن نعمل مع النص كتسلسل من الأحرف. تم رفض الإنشاءات الدلالية المختلفة من النصوص ، والبحث عن المعاني ، وتحليل الجمل ، وما إلى ذلك. يوفر الحل الذي اخترناه ميزتين كبيرتين - سرعة بحث عالية وحجم صغير نسبيًا لفهارس البحث.
يوجد حاليا ثلاثة منتجات في تشكيلتنا. وتتميز بالوظائف ، ولكنها تحتوي بشكل أساسي على نفس مبدأ استعارة البحث. في هذه المقالة ، سأتحدث عن كيفية بحثنا الكلاسيكي عن أعمال الاقتراض - الوظيفة التي أصبحت أساس الخدمة منذ البداية ولم تتغير بعد من حيث المفهوم. نظام البحث عن الاقتراض ، كما ترى في الصورة ، بسيط ومباشر ، مثل رسم بومة. أولاً ، نحصل على المستند من المستخدم ، ثم نستخرج النص منه. ثم نبحث عن الاقتراضات في هذا النص ، ونحصل على "المراجعات" (كما نسميها التقرير لوحدة بحث واحدة) ، وأخيرًا ، نجمع المراجعات في تقرير واحد كبير ، والذي نعرضه كنتيجة للمستخدم.
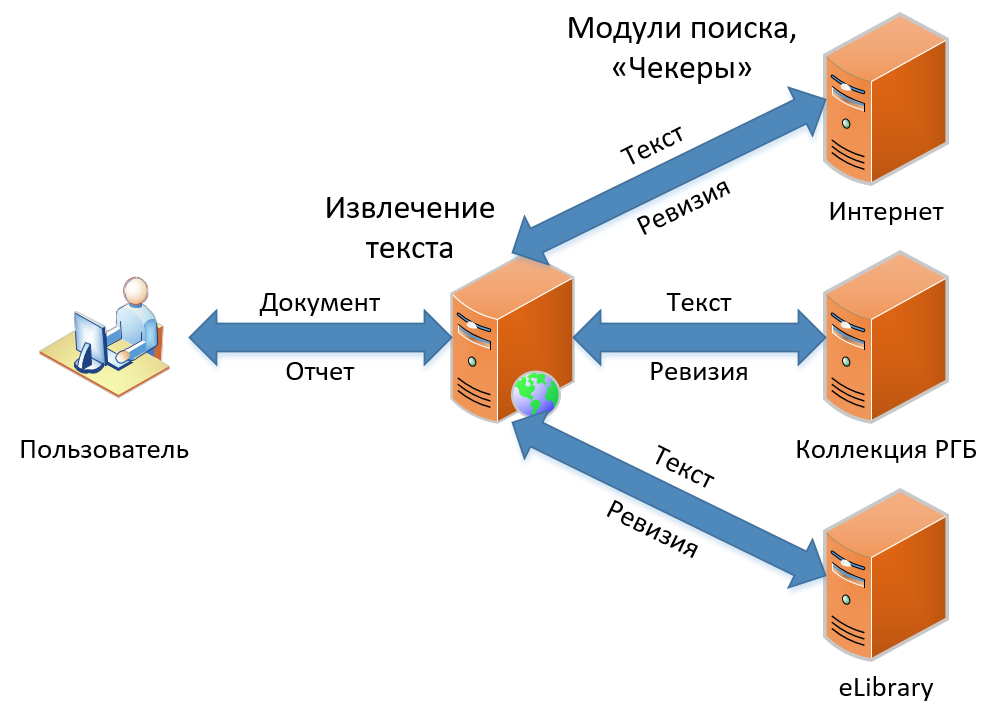
دعونا نرى كيف يحدث كل هذا بالتفصيل.
استخراج النص
بادئ ذي بدء ، "مكافحة الانتحال" هي خدمة للبحث عن الاقتراضات
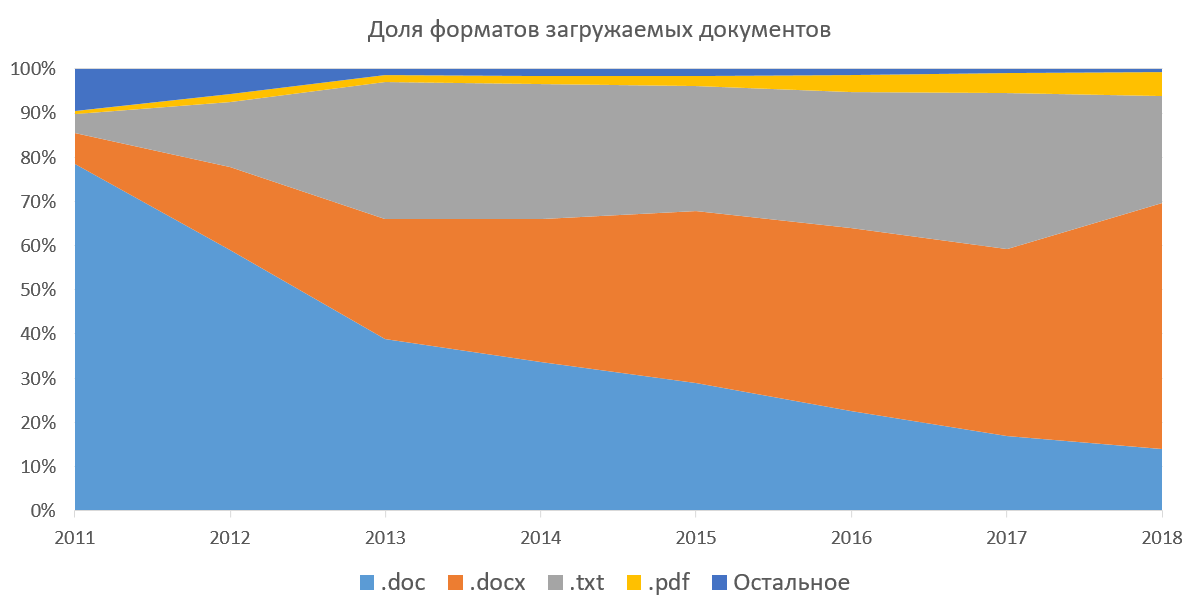
النصية فقط ، مما يعني أننا بحاجة إلى استخراج النص من جميع الوثائق من أجل مواصلة العمل معها. يدعم النظام القدرة على تنزيل المستندات بتنسيق docx و doc و txt و pdf و rtf و odt و html و pptx والعديد من التنسيقات الأخرى (التي لم يتم استخدامها مطلقًا). يمكنك أيضًا تنزيل جميع هذه المستندات في الأرشيفات (7z ، zip ، rar). كانت هذه الطريقة شائعة عندما لم نتمكن من تحميل عدة مستندات مرة واحدة من خلال واجهة الويب. فيما يلي رسم بياني لشعبية تنسيقات المستندات القابلة للتنزيل في جزء الشركة من نظامنا. يوضح كيف تم استبدال docx بواسطة doc على مدى عدة سنوات ، ونسبة pdf تنمو تدريجياً. إذا كنت لا تفكر في txt (استخراج النص له تافه) ، فإن الأكثر متعة بالنسبة لنا هو pdf. PDF في الخارج هو المعيار الواقعي ، فهو ينشر المقالات ، ويجهز عمل الطلاب. وفقًا لإحصاءاتنا ، يكتسب pdf تدريجيًا شعبية في روسيا ودول رابطة الدول المستقلة. نحن أنفسنا نقوم بترويج هذا التنسيق للجماهير ، ونوصي بتنزيل المستندات فيه.
لقد حددنا تنسيقات تنزيل المستندات للعملاء من القطاع الخاص إلى pdf و txt ، ولهذا السبب قللنا من استهلاك الموارد وقللنا من تكلفة دعم خدمة مجانية. بعد كل شيء ، تحتاج إلى التحقق من النص ، وليس اختبار النظام؟ إذن ما الفرق في أي تنسيق لتحميله؟
الطريقة التالية الأسهل لاستخراج النص هي docx ، لأنه في الواقع ، إنه أرشيف مضغوط مع xml بداخله ، ومن السهل جدًا معالجته ، ويمكن القيام بالكثير على مستوى منخفض.
أصعب شيء بالنسبة لنا هو المستند. تم إغلاق هذا التنسيق لفترة طويلة ، والآن هناك مجموعة من تطبيقاته. تم إصدار Microsoft Word الأخير ، الذي لا يدعم .docx (على الرغم من خلال حزمة التوافق لـ Microsoft Office) قبل 20 عامًا وتم تضمينه في Microsoft Office 97. يستخدم التنسيق OLE ، الذي نما لاحقًا إلى COM و ActiveX ، كل شيء ثنائي ، وأحيانًا غير متوافق بين الإصدارات. بشكل عام ، الحلم الرهيب لمبرمج حديث. من الجيد أن تنسيق doc. يغادر المشهد تدريجيًا. أعتقد أن الوقت قد حان لمساعدته على التقاعد. سرعان ما سنحذر المستخدمين عن عمد من أن هذا التنسيق قديم.
لذا ، عد إلى التقرير. حصلنا على الملف وبدأنا في استخراج النص. بالإضافة إلى النص ، يستخلص النظام أيضًا مواضع الكلمات على الصفحات بحيث يمكن في المستقبل أن يُظهر لمستخدمينا ترميز تقرير الاقتراض على المستند نفسه. بالإضافة إلى ذلك ، في نفس المرحلة ، نحن نبحث عن حلول فنية لمكافحة الانتحال.
بمجرد ظهور "مكافحة الانتحال" ، والتي تظهر النسبة المئوية للأصالة ، كان هناك أشخاص يريدون تمرير شيك للاقتراض بأقل جهد ، بالإضافة إلى أشخاص يقدمون مثل هذه الخدمة مقابل المال. المشكلة هي أن المعلمة العددية تطلب أن تصبح تقديرًا. بعد كل شيء ، الأمر بسيط للغاية - بدلاً من قراءة عمل باستخدام النظام كأداة ، لا تقرأه ، ولكن قيمه بنسبة الأصالة! كانت هذه المصيبة هي التي أدت إلى اتجاه مثل ضبط الأعمال (تغيير في النص من أجل زيادة نسبة أصالة العمل). اقرأ المزيد عن مشاكل العمليات الجامعية في مقالة
"حول ممارسة الكشف عن الاقتراض في الجامعات الروسية" .
في أنظمة البحث الأجنبية ، لا تكفي مشاكل اكتشاف الحلول التقنية ومكافحتها. والحقيقة هي أن "الخدعة مع الأذنين" المكتشفة سيتبعها عقوبة قاسية للغاية - الطرد ، وصمة لا تُمحى على السمعة العلمية ، تتعارض مع المزيد من الوظائف. في حالتنا ، الوضع بسيط للغاية: "أوه ، هذا النظام أفسد شيئًا ما!" ، "أوه ، ليس أنا ، إنه بحد ذاته!" من المرجح أن يتم إرسال الطالب لإعادة. الحقيقة هي أن الشطب ، للأسف ، ليس بالشيء المخزي.
ولكن مرة أخرى مشتت. طريقة أخرى لاستخراج النص هي OCR. نطبع المستند على طابعة افتراضية ، ثم نتعرف عليه. اقرأ المزيد عن هذا في مقال
"التعرف على الصور في خدمة مكافحة الانتحال" .
الآن القليل من قصتنا حول استخراج النصوص. أولاً ، استخرجنا النصوص باستخدام IFilters. فهي بطيئة ، فقط ضمن Windows ، ولا تُرجع معلومات التنسيق (ليس من الواضح مكان النص الأبيض على الخلفية البيضاء ، فلا يمكنك وضع علامة على كتل الاقتراض مباشرة في مستند المستخدم). اعتقدنا أنه سيتم حل هذه المشاكل إذا بدأنا في استخدام المكتبات المدفوعة ، ولكننا وجدنا أيضًا قيودًا: كما كان الحال من قبل في نظام التشغيل Windows ، لا يرون الصيغ ، وأحيانًا تقع في وثائق معدة خصيصًا (مكتبات مختلفة في مكتبات مختلفة!). كانت الفكرة التالية هي التعرف الضوئي على الحروف على جميع المستندات الواردة ، ولكن هذا النهج يتطلب الكثير من الموارد (معالجة 10 صفحات فقط في الدقيقة على قلب واحد) ، وفي بعض الأماكن لا يتم استخراج النص بدقة.
لم نعثر على رصاصة فضية ، على الرغم من أننا اعتقدنا عدة مرات أنها السعادة. ومع ذلك ، بعد أن عاشوا قليلاً مع هذا ، أدركوا أنه مرة أخرى كانت تجربة. أرصدة استخراج النص على خط رفيع بين الأداء (تحتاج إلى استخراج النص من مئات المستندات في الدقيقة) ، والموثوقية (تحتاج إلى استخراج النص من كل شيء) ، والوظيفة (التنسيق ، الحلول ، هذا كل شيء). الآن كل ما سبق والمزيد من العمل لنا. نحن نجرب باستمرار في هذا المجال ونواصل البحث عن سعادتنا.
يتم استخراج النص ، تم العثور على الجولات وإزالتها جزئيًا ، انطلقنا للبحث عن الاقتراضات!
البحث عن الاقتراض
تم اقتراح الفكرة التي تم تنفيذها في إجراء البحث بواسطة Ilya Segalovich و Yuri Zelenkov (يمكنك قراءة ، على سبيل المثال ، في المقالة:
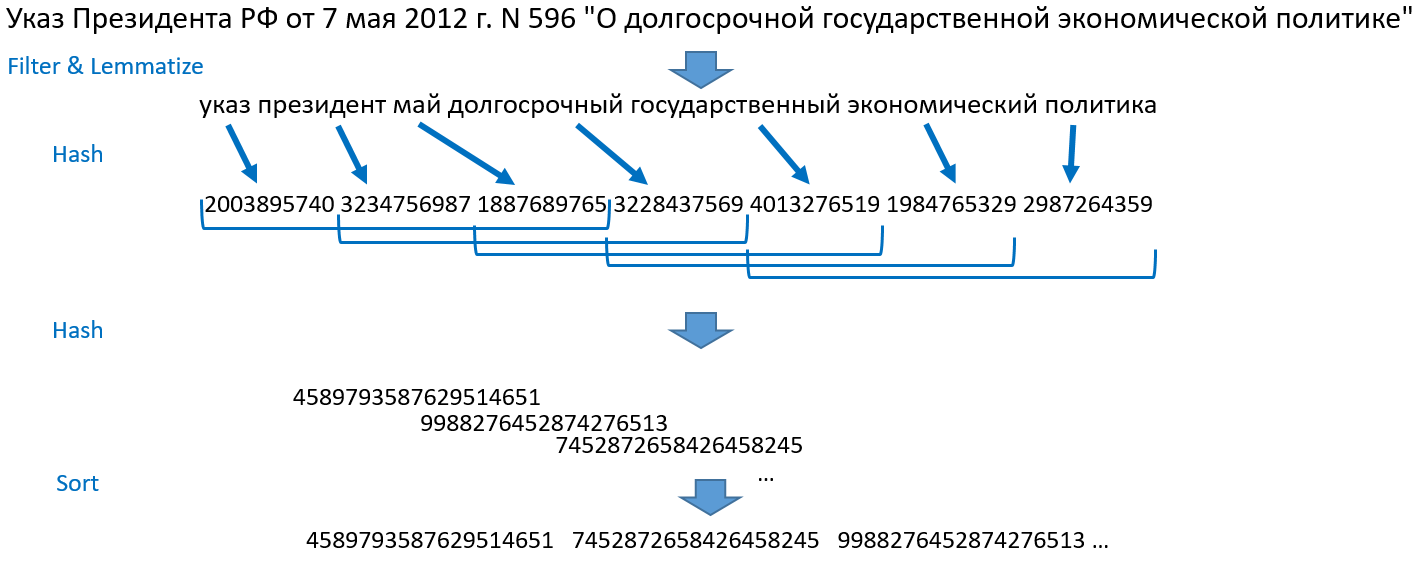
تحليل مقارن لطرق تحديد التكرارات الغامضة لوثائق الويب ). سأخبرك كيف يعمل بالنسبة لنا. خذ على سبيل المثال الجملة: "مرسوم رئيس الاتحاد الروسي في 7 مايو 2012 N 596" على السياسة الاقتصادية للدولة طويلة الأجل "."
- نقسم الجمل إلى كلمات ، ونرمي الأرقام ، وعلامات الترقيم ، ونوقف الكلمات. Lemmatize (إحضار إلى الشكل العادي) جميع الكلمات.
- نحول الكلمات إلى أعداد صحيحة من خلال التجزئة ، نحصل على مجموعة من الأرقام.
- نأخذ التجزئة الثلاثة الأولى ، ثم التجزئة الثانية والثالثة والرابعة ، ثم الثالثة والرابعة والخامسة وهكذا إلى نهاية مجموعة التجزئة. هذا قرميدة مبلطة. حصلت هذه الطريقة على اسمها بسبب مجموعات التداخل المتجانبة. نقوم بدمج كل بلاطة في كائن واحد وتجزئة مرة أخرى.
- نقوم بفرز الأرقام الناتجة ، نحصل على مجموعة مرتبة من الأعداد الصحيحة. هذا هو أساس البحث.
الآن للبحث ، نحتاج إلى وظيفة سحرية ، وفقًا لقائمة التجزئات هذه ، تحول المستندات ، مرتبة ترتيبًا تنازليًا لعدد التجزئات المطابقة ، إلى مستند مصدر. هذه الوظيفة يجب أن تعمل بسرعة بسبب نريد البحث في مليارات الوثائق. من أجل العثور بسرعة على مثل هذه المجموعة ، نحتاج إلى فهرس عكسي ، والذي من خلال التجزئة يقوم بإرجاع قائمة من المستندات التي يكون فيها هذا التجزئة. قمنا بتطبيق مثل هذه المائدة العملاقة. على عكس إخواننا الكبار في البحث ، نقوم بتخزين هذا الجدول على SSD ، وليس في الذاكرة. نحن أقل من هذا الأداء. يأخذ البحث في الفهرس جزءًا صغيرًا من دورة معالجة المستند بالكامل. انظر كيف يتم البحث:
المرحلة 1. البحث في الفهرس
لكل تجزئة من نص الطلب ، نحصل على قائمة بمعرفات المستندات المصدر التي تحدث فيها. بعد ذلك ، نقوم بترتيب قائمة معرفات المستندات المصدر حسب عدد التجزئة التي تمت مواجهتها من نص الطلب. نحصل على قائمة مرتبة من الوثائق المرشحة لمصدر الاقتراض.
المرحلة 2. بناء المراجعة
بالنسبة لطلب نص كبير للمرشحين ، قد يكون هناك حوالي 10 آلاف. ولا يزال هذا كثيرًا لمقارنة كل مستند بنص الطلب. نتصرف بجشع ، ولكن بشكل حاسم. نأخذ المستند المصدر الأول ، ونجري مقارنة مع نص الطلب ونستبعد من جميع المرشحين الآخرين تلك التجزئة التي كانت موجودة بالفعل في هذا المستند الأول. نزيل من قائمة المرشحين أولئك الذين ليس لديهم تجزئات ، ونعيد تصنيف المرشحين وفقًا لعدد التجزئة الجديد. نأخذ الوثيقة الأولى من القائمة الجديدة ، ونقارنها بالنص المصدر ، ونحذف التجزئة ، ونحذف الصفات المرشحة ، ونعيد فرز المرشحين. نقوم بذلك 10-20 مرة ، وعادة ما يكون هذا كافيًا لتشغيل القائمة أو تبقى فقط المستندات التي تتطابق مع العديد من التجزئة.
يتيح لنا استخدام تجزئات الكلمات إجراء عمليات مقارنة بشكل أسرع ، وتوفير الذاكرة وتخزين ليس نصوص المستندات المصدر ، ولكن تم الحصول على قوالبها الرقمية (TextSpirit ، كما نسميها بمودة) أثناء الفهرسة ، وبالتالي انتهاك حقوق النشر. يتم اختيار أجزاء الاقتراض المحددة باستخدام شجرة اللاحقة.
نتيجة للتدقيق باستخدام وحدة بحث واحدة ، نحصل على مراجعة تحتوي على قائمة بالمصادر والبيانات الوصفية الخاصة بها وإحداثيات وحدات الاقتراض نسبة إلى نص الطلب.
تقرير التجميع
بالمناسبة ، ماذا لو لم تستجب إحدى الوحدات 10-15 في الوقت المحدد؟ نبحث في مجموعات RSL والمكتبة الإلكترونية والضامن. تقع وحدات البحث هذه على أراضي مؤسسات تابعة لجهات خارجية ، ولا يمكن نقلها إلى موقعنا لأسباب تتعلق بحقوق الطبع والنشر. يمكن أن تكون نقطة الفشل هنا دائمًا قناة اتصال وقوة قاهرة مختلفة في مراكز البيانات التي لا نتحكم فيها. من ناحية ، يمكن العثور على الاقتراض في أي وحدة بحث ، من ناحية أخرى ، إذا كان أحد مكونات النظام غير متوفر ، يمكنك تدهور جودة البحث ، ولكن إعطاء معظم النتيجة ، بينما تحذير المستخدم من أن النتيجة لبعض وحدات البحث ليست جاهزة بعد. أي خيار ستطبق؟ نطبق كلا هذين الخيارين حسب الاقتضاء.

وأخيرًا ، يتم تلقي جميع المراجعات ، ونبدأ في تجميع التقرير. يستخدم نهج مماثل لإعداد مراجعة واحدة. يبدو أنه لا يوجد شيء معقد ، ولكن هناك أيضًا مهام مثيرة للاهتمام. لدينا نوعان من الاقتراض. يشار إلى "الاقتباسات" باللون الأخضر - اقتباسات مقتبسة بشكل صحيح (وفقًا لـ GOST) من وحدة "الاقتباس" ، وتعبيرات من النوع "كما هو مطلوب" من وحدة "التعبيرات الشائعة" ، والوثائق التنظيمية من قواعد بيانات الضامن و Lexpro. يتم تمييز جميع القروض الأخرى باللون البرتقالي. يحظى الخضر بالأسبقية على البرتقال ، ما لم يدخلوا الكتلة البرتقالية بالكامل.
ونتيجة لذلك ، يمكن مقارنة التقرير بالنص المطبوع على ورق ملقى على الطاولة ، حيث يتم كتابة خطوط ملونة (كتل من الاقتباسات وعروض الأسعار) عليها ، متداخلة بشكل خيالي مع بعضها البعض. ما نراه أعلاه هو تقرير. لدينا مؤشرين لكل مصدر:
الحصة في التقرير هي نسبة حجم القروض ، التي تؤخذ في الاعتبار من هذا المصدر ، إلى الحجم الإجمالي للوثيقة. إذا تم العثور على نفس النص في عدة مصادر ، فسيتم أخذه بعين الاعتبار في أحدها فقط. عند تغيير تكوين التقرير (تمكين أو تعطيل المصادر) ، قد يتغير مؤشر المصدر هذا. في المجموع ، فإنه يعطي النسبة المئوية للاقتراضات والاستشهادات (اعتمادًا على لون المصدر).
المشاركة في النص - نسبة الحجم المقترض من مصدر النص إلى الحجم الإجمالي للوثيقة. ليس من المنطقي تلخيص الأسهم في النص حسب المصادر ، وسوف يتحول بسهولة إلى 146 ٪ أو حتى أكثر. لا يتغير هذا المؤشر عندما يتغير التقرير.
بطبيعة الحال ، يمكن تحرير التقرير. هذه وظيفة خاصة للخبير الذي يتحقق من العمل لإيقاف الاقتراضات من أعمال المؤلف الخاصة (قد يبدو أن هذا الجزء ليس فقط في عمل المؤلف نفسه ، ولكن أيضًا في مكان آخر) وكتل استعارة منفصلة ، قم بتغيير نوع المصدر من الاقتراض للاقتباس. نتيجة لتحرير التقرير ، يتلقى الخبير القيمة الحقيقية للاقتراض. يجب قراءة أي عمل للتحقق. من الملائم القيام بذلك من خلال النظر إلى الشكل الأصلي للمستند ، حيث يتم وضع علامة على كتل الاقتراض ، وعلى الفور ، كما تقرأ ، قم بتحرير التقرير. لسوء الحظ ، هذا ليس إجراءً منطقيًا من قبل الجميع ، فالعديد راضون عن نسبة الأصالة ، حتى دون النظر إلى التقرير.
ومع ذلك ، فلنرجع خطوة إلى الوراء ونكتشف ما يدخل في فهرس وحدة البحث على الإنترنت التي أنشأتها مكافحة الانتحال.
فهرسة الإنترنت
تركز مكافحة الانتحال إلى حد كبير على عمل الطلاب والمنشورات العلمية وأعمال التأهيل النهائية والرسائل العلمية وما إلى ذلك. نقوم بفهرسة الإنترنت بطريقة اتجاهية - نحن نبحث عن مجموعات كبيرة من النصوص العلمية والملخصات والمقالات والأطروحات والمجلات العلمية ، إلخ. تحدث الفهرسة على النحو التالي:
- يأتي الروبوت الخاص بنا ، ويقدم نفسه ، وتوجيهًا بواسطة robots.txt (لدينا روبوت جيد) ، يقوم بتنزيل المستندات بحمل معقول على كل مضيف (يتم تشغيل مئات المواقع في نفس الوقت ، حتى نتمكن من الانتظار بعض الوقت بين تحميل الصفحة) ؛
- يقوم الروبوت بتمرير المستند وبياناته الوصفية إلى قائمة انتظار المعالجة ، ويتم استخراج النص من المستند ؛
- يتم تحليل النص من أجل "الجودة" - كما تتذكر من المقالة حول المكب ، يمكننا تحديد نوع المستند ، وإضافة استدلال بسيط إلى المجلد هنا وفهم ما إذا كان نص مناسب وصلنا أو بعض القمامة ؛
- يذهب النص النوعي إلى أبعد من ذلك ويتحول إلى تجزئات. يتم إرسال التجزئة والبيانات الوصفية إلى فهرس الإنترنت الرئيسي ؛
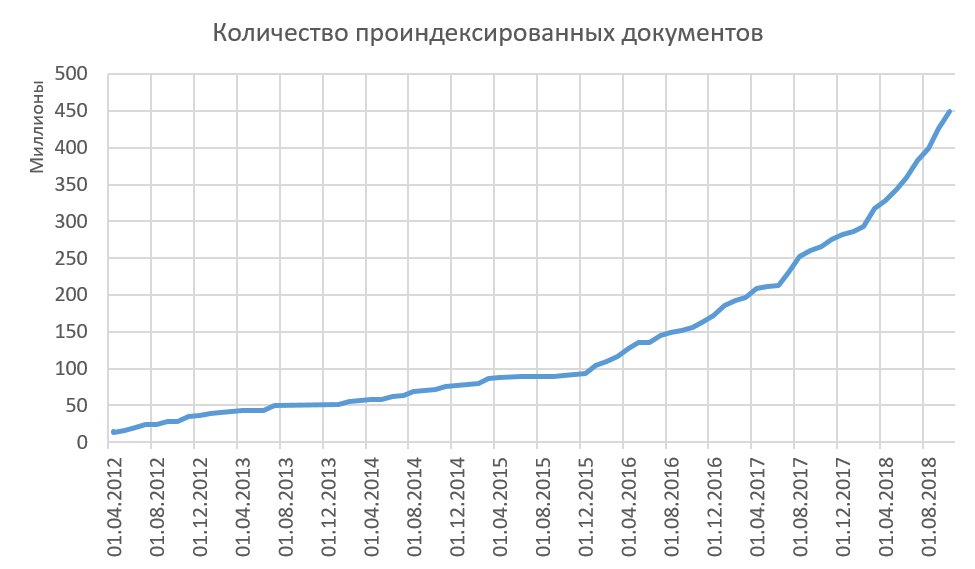
- قارنا النص المستلم مع النصوص المفهرسة من قبلنا. تتم إضافة مبتدئ فقط إذا كان جديدًا حقًا ، أي 90% - . , url .
, . . 15-20 .
, ? ! . , - , . , - , . , , « », — ! - . ?
الخلاصة
, , 10 , . 4 , , , , . — , , , , .
, ?