
في صميم محركات البحث Meltwater و
Fairhair.ai ، تقع شركة Elasticsearch ، وهي مجموعة من المجموعات التي تضم مليارات وسائل الإعلام ومقالات وسائل الإعلام الاجتماعية.
تختلف أجزاء الفهرس في المجموعات بشكل كبير في هيكل الوصول ، وعبء العمل ، والحجم ، مما يثير بعض المشاكل المثيرة للاهتمام.
في هذه المقالة ، سنصف كيف استخدمنا البرمجة الخطية (التحسين الخطي) لتوزيع عبء عمل البحث والفهرسة بالتساوي قدر الإمكان عبر جميع العقد في المجموعات. يقلل هذا الحل من احتمال أن تصبح عقدة واحدة عنق الزجاجة في النظام. ونتيجة لذلك ، قمنا بزيادة سرعة البحث وحفظنا في البنية التحتية.
الخلفية
تحتوي محركات البحث Fairhair.ai على حوالي 40 مليار منشور من وسائل التواصل الاجتماعي والافتتاحيات ، وتعالج ملايين الاستفسارات يوميًا. توفر المنصة للعملاء نتائج البحث والرسوم البيانية والتحليلات وتصدير البيانات لتحليل أكثر تقدمًا.
تتواجد مجموعات البيانات الضخمة هذه في عدة مجموعات من 750 عقدة من نوع Elasticsearch مع آلاف الفهارس في أكثر من 50000 جزء.
لمزيد من المعلومات حول مجموعتنا ، راجع المقالات السابقة حول
هيكلها وموازنة تحميل التعلم الآلي .
توزيع غير متكافئ لعبء العمل
عادةً ما تكون بياناتنا واستفسارات المستخدم مرتبطةً بالتاريخ. تقع معظم الطلبات في فترة زمنية معينة ، على سبيل المثال ، الأسبوع الماضي أو الشهر الماضي أو الربع الأخير أو نطاق تعسفي. لتبسيط الفهرسة والاستعلامات ، نستخدم
فهرسة الوقت ، على غرار
مكدس ELK .
تقدم هندسة الفهرس العديد من المزايا. على سبيل المثال ، يمكنك إجراء فهرسة كتلة فعالة ، وكذلك حذف فهارس كاملة عندما تكون البيانات قديمة. وهذا يعني أيضًا أن عبء العمل لمؤشر معين يختلف اختلافًا كبيرًا بمرور الوقت.
يتم طرح المزيد من الاستفسارات بشكل كبير إلى أحدث الفهارس ، مقارنة بالفهارس القديمة.
 التين. 1. مخطط الوصول إلى مؤشرات الوقت. يمثل المحور الرأسي عدد الاستعلامات المكتملة ، ويمثل المحور الأفقي عمر الفهرس. يمكن رؤية الهضاب الأسبوعية والشهرية والسنوية بوضوح ، يليها ذيل طويل من عبء العمل المنخفض على المؤشرات القديمة
التين. 1. مخطط الوصول إلى مؤشرات الوقت. يمثل المحور الرأسي عدد الاستعلامات المكتملة ، ويمثل المحور الأفقي عمر الفهرس. يمكن رؤية الهضاب الأسبوعية والشهرية والسنوية بوضوح ، يليها ذيل طويل من عبء العمل المنخفض على المؤشرات القديمةالأنماط في الشكل. 1 كان متوقعًا تمامًا ، لأن عملائنا أكثر اهتمامًا بالمعلومات الجديدة ويقارنون الشهر الحالي بانتظام بالماضي و / أو هذا العام بالعام الماضي. تكمن المشكلة في أن Elasticsearch لا يعرف عن هذا النمط ولا يقوم تلقائيًا بتحسين حجم العمل الملاحظ!
تأخذ خوارزمية التخصيص الجزئي المضمنة في Elasticearch في الاعتبار عاملين فقط:
- عدد الأجزاء في كل عقدة. تحاول الخوارزمية موازنة عدد الأجزاء لكل عقدة في المجموعة بالتساوي.
- تسميات مساحة القرص الحرة. تدرس شركة Elasticsearch مساحة القرص المتوفرة على العقدة قبل أن تقرر ما إذا كانت ستقوم بتخصيص أجزاء جديدة لهذه العقدة أو نقل الأجزاء من هذه العقدة للآخرين. مع استخدام 80٪ من القرص ، يُمنع وضع شظايا جديدة على عقدة ، وسيبدأ 90٪ من النظام في نقل الشظايا من هذه العقدة.
الافتراض الأساسي للخوارزمية هو أن كل جزء في المجموعة يتلقى نفس حجم عبء العمل تقريبًا وأن كل شخص له نفس الحجم. في حالتنا ، هذا بعيد جدا عن الحقيقة.
تؤدي موازنة التحميل القياسية بسرعة إلى نقاط ساخنة في المجموعة. تظهر وتختفي بشكل عشوائي ، مع تغير عبء العمل بمرور الوقت.
النقطة الفعالة هي في الأساس مضيف يعمل بالقرب من حده لمورد نظام واحد أو أكثر ، مثل وحدة المعالجة المركزية أو إدخال / إخراج القرص أو النطاق الترددي للشبكة. عند حدوث ذلك ، تقوم العقدة أولاً بوضع الطلبات في قائمة الانتظار لفترة ، مما يزيد من وقت الاستجابة للطلب. ولكن إذا استمر الحمل الزائد لفترة طويلة ، فسيتم رفض الطلبات في نهاية المطاف ، ويتلقى المستخدمون أخطاء.
من النتائج الأخرى الشائعة للازدحام الضغط غير المستقر لقمامة JVM بسبب الاستفسارات وعمليات الفهرسة ، مما يؤدي إلى ظاهرة "الجحيم المخيف" لمجمع القمامة JVM. في مثل هذه الحالة ، إما أن JVM لا يمكنها الحصول على الذاكرة بسرعة كافية وتعطلها ، أو تتعثر في دورة جمع القمامة التي لا نهاية لها ، وتتجمد وتتوقف عن الاستجابة لطلبات الكتلة والأصوات.
تفاقمت المشكلة عندما قمنا
بإعادة هيكلة بنيتنا تحت AWS . في السابق ، "تم إنقاذنا" من خلال حقيقة أننا قمنا بتشغيل ما يصل إلى أربع عُقد Elasticsearch على خوادمنا القوية (24 مركزًا) في مركز البيانات الخاص بنا. هذا أخفى تأثير التوزيع غير المتماثل للقطع: تم تخفيف الحمل إلى حد كبير من خلال عدد كبير نسبيًا من النوى على الجهاز.
بعد إعادة الهيكلة ، وضعنا عقدة واحدة فقط في كل مرة على آلات أقل قوة (8 نوى) - وكشفت الاختبارات الأولى على الفور عن مشكلات كبيرة في "النقاط الساخنة".
تقوم شركة Elasticsearch بتخصيص شظايا بترتيب عشوائي ، ومع وجود أكثر من 500 عقدة في مجموعة ، فقد زاد احتمال وجود الكثير من القطع "الساخنة" على عقدة واحدة بشكل كبير - وقد تجاوزت هذه العقد بسرعة.
بالنسبة للمستخدمين ، قد يعني هذا تدهورًا خطيرًا في العمل ، حيث تستجيب العقد المكتظة ببطء ، وأحيانًا ترفض تمامًا الطلبات أو تتعطل. إذا أدخلت مثل هذا النظام في الإنتاج ، فسوف يرى المستخدمون بشكل متكرر ، على ما يبدو ، تباطؤ عشوائي لواجهة المستخدم ومهلات عشوائية.
في الوقت نفسه ، لا يزال هناك عدد كبير من العقد مع شظايا دون الكثير من الحمل ، والتي تكون غير نشطة في الواقع. هذا يؤدي إلى الاستخدام غير الفعال لموارد المجموعة لدينا.
يمكن تجنب كلتا المشكلتين إذا قام Elasticsearch بتوزيع الأجزاء بشكل أكثر ذكاء ، نظرًا لأن متوسط استخدام موارد النظام في جميع العقد عند مستوى صحي يبلغ 40٪.
التغيير المستمر للكتلة
عند العمل على أكثر من 500 عقدة ، لاحظنا شيئًا آخر: تغيير مستمر في حالة العقد. تتحرك الشظايا باستمرار ذهابًا وإيابًا في العقد تحت تأثير العوامل التالية:
- يتم إنشاء فهارس جديدة ، ويتم تجاهل الفهارس القديمة.
- يتم تشغيل ملصقات القرص بسبب الفهرسة والتغيرات الأخرى في الجزء.
- يقرر Elasticearch بشكل عشوائي أن هناك أجزاء قليلة جدًا أو كثيرة جدًا على العقدة مقارنةً بمتوسط قيمة الكتلة.
- تتسبب أعطال الأجهزة وتعطلها على مستوى نظام التشغيل في تشغيل مثيلات AWS جديدة وضمها إلى المجموعة. مع 500 عقدة ، يحدث هذا في المتوسط عدة مرات في الأسبوع.
- تتم إضافة مواقع جديدة كل أسبوع تقريبًا بسبب النمو الطبيعي للبيانات.
مع أخذ كل هذا في الاعتبار ، توصلنا إلى استنتاج مفاده أن الحل المعقد والمستمر لجميع المشاكل يتطلب خوارزمية إعادة تحسين مستمرة وديناميكية.
الحل: شاردونيه
بعد دراسة طويلة للخيارات المتاحة ، توصلنا إلى استنتاج أننا نريد:
- قم ببناء الحل الخاص بك. لم نجد أي مقالات أو تعليمات برمجية جيدة أو أفكار أخرى موجودة من شأنها أن تعمل بشكل جيد على نطاقنا ومهامنا.
- ابدأ عملية إعادة التوازن خارج Elasticsearch واستخدم واجهات برمجة التطبيقات لإعادة التوجيه المجمعة بدلاً من محاولة إنشاء مكون إضافي . أردنا حلقة ردود فعل سريعة ، وقد يستغرق نشر مكون إضافي على مجموعة من هذا المقياس عدة أسابيع.
- استخدم البرمجة الخطية لحساب حركات القطع المثلى في أي وقت.
- قم بإجراء التحسين باستمرار حتى تصل حالة الكتلة تدريجيًا إلى المستوى الأمثل.
- لا تتحرك الكثير من القطع في وقت واحد.
لقد لاحظنا شيئًا مثيرًا للاهتمام: إذا قمت بنقل عدد كبير جدًا من الشظايا في نفس الوقت ، فمن السهل جدًا إطلاق
عاصفة متتالية من حركة الشظية . بعد ظهور مثل هذه العاصفة ، يمكن أن تستمر لساعات ، عندما تتحرك الشظايا بشكل لا يمكن السيطرة عليه ذهابًا وإيابًا ، مما يتسبب في ظهور علامات حول المستوى الحرج لمساحة القرص في أماكن مختلفة. وهذا بدوره يؤدي إلى حركة شظية جديدة وما إلى ذلك.
لفهم ما يحدث ، من المهم أن تعرف أنه عند نقل مقطع مفهرس بنشاط ، فإنه يبدأ بالفعل في استخدام مساحة أكبر بكثير على القرص الذي ينتقل منه. ويرجع ذلك إلى كيفية قيام Elasticsearch بتخزين
سجلات المعاملات . لقد رأينا حالات حيث عند تحريك عقدة ، تضاعف المؤشر. وهذا يعني أن العقدة التي بدأت حركة الشظية بسبب ارتفاع استخدام مساحة القرص ستستخدم
مساحة أكبر على القرص لفترة من الوقت حتى تنتقل شظايا كافية إلى العقد الأخرى.
لحل هذه المشكلة ، قمنا بتطوير خدمة
Shardonnay تكريما لمجموعة متنوعة من عنب Chardonnay الشهير.
التحسين الخطي
التحسين الخطي (أو
البرمجة الخطية ، LP) هو طريقة لتحقيق أفضل نتيجة ، مثل أقصى ربح أو أقل تكلفة ، في نموذج رياضي تمثل متطلباته علاقات خطية.
تعتمد طريقة التحسين على نظام المتغيرات الخطية ، وبعض القيود التي يجب الوفاء بها ، ووظيفة موضوعية تحدد كيف يبدو الحل الناجح. الهدف من التحسين الخطي هو إيجاد قيم المتغيرات التي تقلل من وظيفة الهدف ، مع مراعاة القيود.
توزيع شارد كمشكلة تحسين خطية
يجب أن تعمل Shardonnay بشكل مستمر ، وفي كل تكرار تقوم الخوارزمية التالية:
- باستخدام واجهة برمجة التطبيقات ، يسترد Elasticsearch المعلومات حول الأجزاء والفهارس والعقد الموجودة في المجموعة ، بالإضافة إلى موقعها الحالي.
- يعدل حالة الكتلة كمجموعة من متغيرات LP الثنائية. كل تركيبة (عقدة ، فهرس ، جزء ، نسخة) تحصل على متغيرها الخاص. في نموذج LP ، هناك عدد من الاستدلال والقيود والوظيفة الموضوعية المصممة بعناية ، المزيد عن هذا أدناه.
- يرسل نموذج LP إلى حلال الخط ، والذي يعطي الحل الأمثل مع مراعاة القيود ووظيفة الهدف. الحل هو إعادة تعيين الأجزاء إلى العقد.
- يفسر حل LP ويحوله إلى سلسلة من حركات القطع.
- يرشد Elasticsearch لنقل الأجزاء من خلال واجهة برمجة تطبيقات إعادة توجيه نظام المجموعة.
- ينتظر الكتلة لتحريك الشظايا.
- يعود إلى الخطوة 1.
الشيء الرئيسي هو تطوير القيود الصحيحة والوظيفة الموضوعية. وسيتم تنفيذ الباقي من قبل Solver LP و Elasticsearch.
ليس من المستغرب أن المهمة كانت صعبة للغاية بالنسبة لمجموعة من هذا الحجم والتعقيد!
القيود
نحن نبني بعض القيود على النموذج بناءً على القواعد التي يمليها Elasticsearch نفسه. على سبيل المثال ، التزم دائمًا بتسميات القرص أو حظر وضع نسخة متماثلة على نفس العقدة مثل نسخة متماثلة أخرى من نفس الجزء.
يتم إضافة الآخرين بناءً على الخبرة المكتسبة على مدى سنوات من العمل مع مجموعات كبيرة. فيما يلي بعض الأمثلة عن القيود الخاصة بنا:
- لا تقم بتحريك فهارس اليوم ، لأنها الأكثر سخونة وتحصل على حمل ثابت تقريبًا على القراءة والكتابة.
- أعط الأفضلية لتحريك القطع الصغيرة ، لأن Elasticsearch يعالجها بشكل أسرع.
- من المستحسن إنشاء شظايا مستقبلية ووضعها قبل بضعة أيام من نشاطها ، والبدء في الفهرسة ، وتحمل حمولة ثقيلة.
دالة التكلفة
تزن دالة التكلفة لدينا عددًا من العوامل المختلفة. على سبيل المثال ، نريد:
- تقليل اختلاف استعلامات الفهرسة والبحث لتقليل عدد "النقاط الفعالة" ؛
- الحفاظ على الحد الأدنى من التباين في استخدام القرص لتشغيل النظام المستقر ؛
- التقليل من عدد حركات الشظية حتى لا تبدأ "العواصف" مع تفاعل تسلسلي ، كما هو موضح أعلاه.
الحد من متغيرات LP
على مقياسنا ، يصبح حجم نماذج LP هذه مشكلة. أدركنا بسرعة أنه لا يمكن حل المشاكل في وقت معقول بأكثر من 60 مليون متغير. لذلك ، قمنا بتطبيق العديد من حيل التحسين والنمذجة لتقليل عدد المتغيرات بشكل كبير. من بينها أخذ العينات المتحيزة ، والاستدلال ، وطريقة فرق تسد ، والاسترخاء التكراري والتحسين.
 التين. 2. توضح الخريطة الحرارية الحمل غير المتوازن على مجموعة Elasticsearch. ويتجلى ذلك في تشتت كبير لاستخدام الموارد على الجانب الأيسر من الرسم البياني. من خلال التحسين المستمر ، يستقر الوضع تدريجياً
التين. 2. توضح الخريطة الحرارية الحمل غير المتوازن على مجموعة Elasticsearch. ويتجلى ذلك في تشتت كبير لاستخدام الموارد على الجانب الأيسر من الرسم البياني. من خلال التحسين المستمر ، يستقر الوضع تدريجياً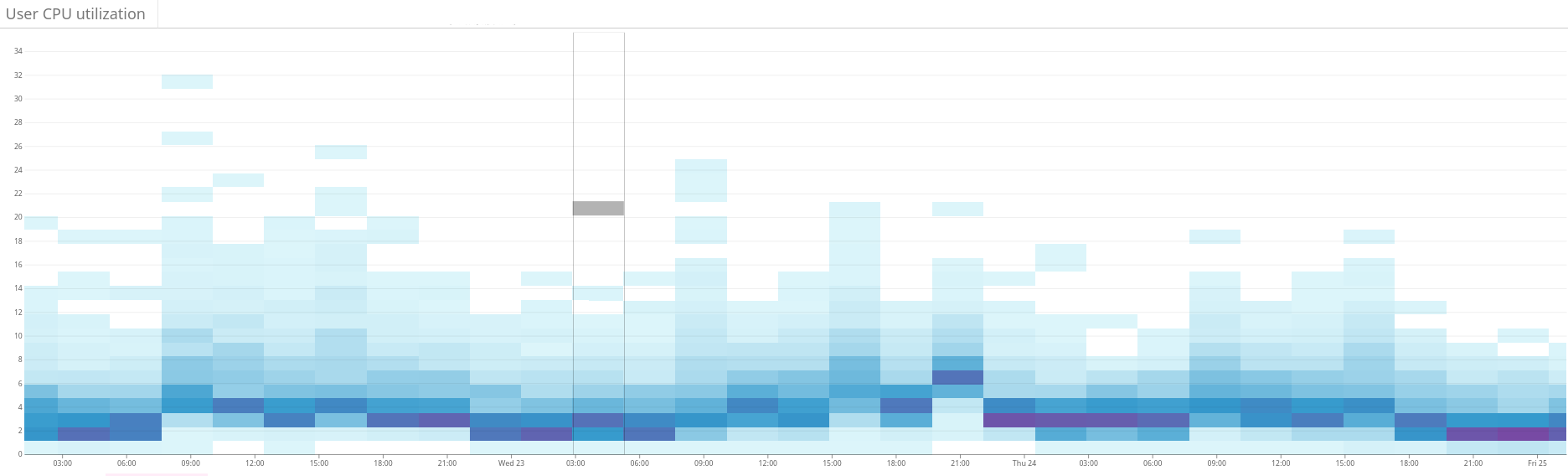 التين. 3. تُظهر الخريطة الحرارية استخدام وحدة المعالجة المركزية في جميع عُقد المجموعة قبل وبعد إعداد وظيفة التسخين في Shardonnay. يظهر تغيير كبير في استخدام وحدة المعالجة المركزية مع عبء العمل المستمر.
التين. 3. تُظهر الخريطة الحرارية استخدام وحدة المعالجة المركزية في جميع عُقد المجموعة قبل وبعد إعداد وظيفة التسخين في Shardonnay. يظهر تغيير كبير في استخدام وحدة المعالجة المركزية مع عبء العمل المستمر. التين. 4. توضح الخارطة الحرارية سرعة قراءة الأقراص خلال نفس الفترة كما في الشكل. 3. كما يتم توزيع عمليات القراءة بشكل متساو عبر المجموعة.
التين. 4. توضح الخارطة الحرارية سرعة قراءة الأقراص خلال نفس الفترة كما في الشكل. 3. كما يتم توزيع عمليات القراءة بشكل متساو عبر المجموعة.النتائج
نتيجة لذلك ، يجد LP حلالا حلولاً جيدة في بضع دقائق ، حتى بالنسبة لمجموعتنا الضخمة. وبالتالي ، يحسن النظام بشكل متكرر حالة الكتلة في اتجاه المثالية.
وأفضل جزء هو أن تشتت عبء العمل واستخدام القرص يتقارب كما هو متوقع - ويتم الحفاظ على هذه الحالة شبه المثلى بعد العديد من التغييرات المتعمدة وغير المتوقعة في حالة الكتلة منذ ذلك الحين!
نحن ندعم الآن توزيع عبء العمل الصحي في مجموعات Elasticsearch الخاصة بنا. كل ذلك بفضل التحسين الخطي وخدمتنا ، التي نحبها
شاردونيه .