في المنشور الأخير ، تحدثت عن Kubernetes ، عن كيفية استخدام ThoughtSpot لاحتياجات دعم التطوير الخاصة به. اليوم أود أن أستمر في الحديث عن قصير ، ولكن من ذلك التاريخ لا يقل أهمية عن تصحيح الأخطاء ، والذي حدث مؤخرًا. المقالة مبنية على حقيقة أن الحاوية! = المحاكاة الافتراضية. بالإضافة إلى ذلك ، تم توضيح كيف تتنافس العمليات المعبأة بالحاويات على الموارد حتى مع القيود المثلى على cgroup والأداء العالي للآلة.
في وقت سابق ، أطلقنا سلسلة من العمليات المتعلقة بتطوير b CI / CD في مجموعة Kubernetes الداخلية. سيكون كل شيء على ما يرام ، ولكن عند تشغيل تطبيق "مُرْكَس" ، ينخفض الأداء فجأة بشكل كبير. لم نبخل: في كل حاوية كانت هناك قيود على قوة الحوسبة والذاكرة (5 CPU / 30 GB RAM) تم ضبطها من خلال تكوين Pod. على جهاز افتراضي بمثل هذه المعلمات ، ستنتقل جميع طلباتنا من مجموعة بيانات صغيرة (10 كيلوبايت) للاختبارات. ومع ذلك ، في Docker & Kubernetes مع 72 CPU / 512 GB RAM ، تمكنا من إطلاق 3-4 نسخ من المنتج ، ثم بدأت الفرامل. تم تعليق الطلبات التي كانت تكتمل في بضع ملي ثانية الآن لمدة ثانية إلى ثانيتين ، وتسبب ذلك في جميع أنواع الفشل في مسار مهمة CI. كان علي التعامل عن كثب مع التصحيح.
كقاعدة ، يشتبه في جميع أنواع أخطاء التكوين عند حزم تطبيق في Docker. ومع ذلك ، لم نجد أي شيء يمكن أن يسبب نوعًا من التباطؤ على الأقل (عند مقارنته بالتثبيتات على الأجهزة العارية أو الأجهزة الافتراضية). يبدو أن كل شيء على ما يرام. بعد ذلك ، جربنا جميع أنواع الاختبارات من حزمة Sysbench . لقد تحققنا من أداء وحدة المعالجة المركزية والقرص والذاكرة - كان كل شيء كما هو الحال في المعدن العاري. بعض خدمات منتجنا تخزن معلومات تفصيلية حول جميع الإجراءات: يمكن بعد ذلك استخدامها في أداء التنميط. كقاعدة عامة ، عندما يكون هناك نقص في الموارد (وحدة المعالجة المركزية ، ذاكرة الوصول العشوائي ، القرص ، الشبكة) ، في بعض المكالمات يكون هناك فشل كبير في الوقت - لذلك نكتشف ما يبطئ بالضبط وأين. ومع ذلك ، لم يحدث شيء في هذه الحالة. لم تختلف نسب الوقت عن تكوين العمل - والفرق الوحيد هو أن كل مكالمة كانت أبطأ بكثير من المعدن العاري. لا شيء يشير إلى المصدر الحقيقي للمشكلة. كنا مستعدين للاستسلام عندما اكتشفنا ذلك فجأة.
في هذه المقالة ، يحلل المؤلف حالة غامضة مماثلة عندما قتلت عمليتان ضوئيتان ، من حيث المبدأ ، بعضهما البعض عند التشغيل داخل Docker على نفس الجهاز ، وتم تعيين حدود الموارد على قيم متواضعة للغاية. لقد توصلنا إلى استنتاجين هامين:
- السبب الرئيسي يكمن في نواة لينكس نفسها. بسبب هيكل كائنات مخبأ الأسنان في النواة ، أدى سلوك إحدى العمليات إلى إعاقة استدعاء نواة
__d_lookup_loop بشكل كبير ، مما أثر بشكل مباشر على أداء أخرى. - استخدم المؤلف
perf للكشف عن الخلل في النواة. أداة تصحيح أخطاء رائعة لم نستخدمها من قبل (وهي أمر مؤسف!).
perf (تسمى أحيانًا perf_events أو أدوات perf ؛ المعروفة سابقًا باسم عدادات الأداء لنظام التشغيل Linux ، PCL) هي أداة تحليل أداء Linux متاحة من إصدار kernel 2.6.31. تتوفر أداة إدارة مساحة المستخدم ، perf ، من سطر الأوامر وهي عبارة عن مجموعة من الأوامر الفرعية.
ينفذ التنميط الإحصائي للنظام بأكمله (النواة ومساحة المستخدم). تدعم هذه الأداة عدادات أداء الأجهزة والبرامج (على سبيل المثال ، hrtimer) ، ونقاط التتبع ، والعينات الديناميكية (على سبيل المثال ، kprobes أو uprobes). في عام 2012 ، اعترف اثنان من مهندسي IBM بالأداء (إلى جانب OProfile) كواحد من أكثر أدوات التنميط العكسي للأداء استخدامًا على Linux.
لذا فكرنا: ربما لدينا نفس الشيء؟ بدأنا المئات من العمليات المختلفة في الحاويات ، وكلها لها نفس اللب. شعرنا أننا هاجمنا الدرب! مسلحين perf ، كررنا تصحيح الأخطاء ، وفي النهاية كنا ننتظر اكتشافًا أكثر إثارة للاهتمام.
فيما يلي إدخالات perf للثواني العشر الأولى من ThoughtSpot التي تعمل على آلة صحية (سريعة) (يسار) وداخل الحاوية (يمين).
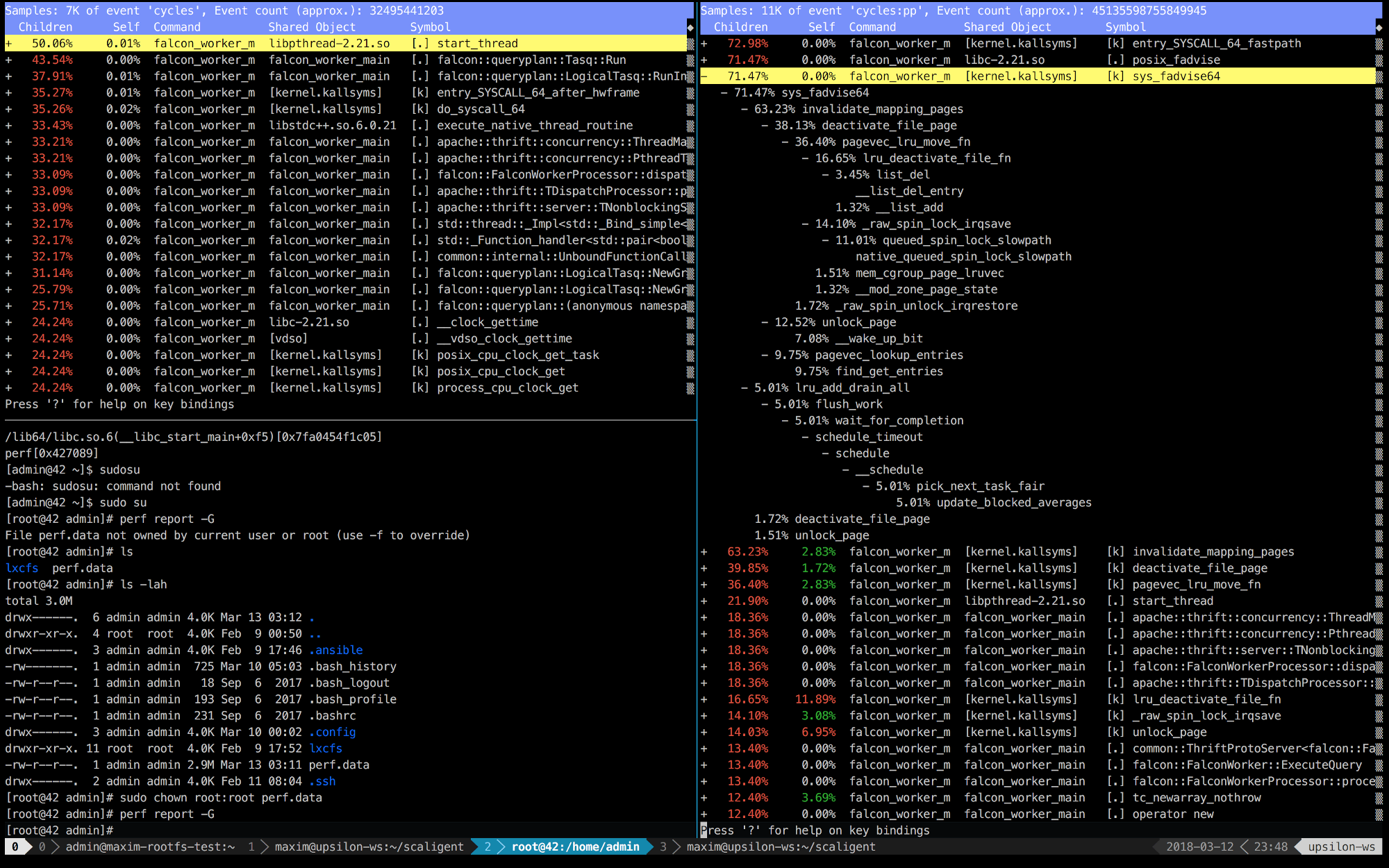
من الواضح على الفور أنه على اليمين ، تتصل المكالمات الخمس الأولى بالنواة. يتم إنفاق الوقت بشكل أساسي على مساحة النواة ، بينما على اليسار - يقضي معظم الوقت في عملياتنا الخاصة التي تعمل في مساحة المستخدم. ولكن الشيء الأكثر إثارة للاهتمام هو أن المكالمة posix_fadvise تستغرق كل الوقت.
تستخدم البرامج posix_fadvise () ، معلنةً عزمها الوصول إلى بيانات الملف وفقًا لنمط معين في المستقبل. هذا يعطي النواة الفرصة لأداء التحسين الضروري.
يتم استخدام المكالمة في أي حالات ، وبالتالي لا تشير إلى مصدر المشكلة بشكل صريح. ومع ذلك ، عند البحث في الشفرة ، وجدت مكانًا واحدًا فقط ، نظريًا ، أثر على كل عملية في النظام:
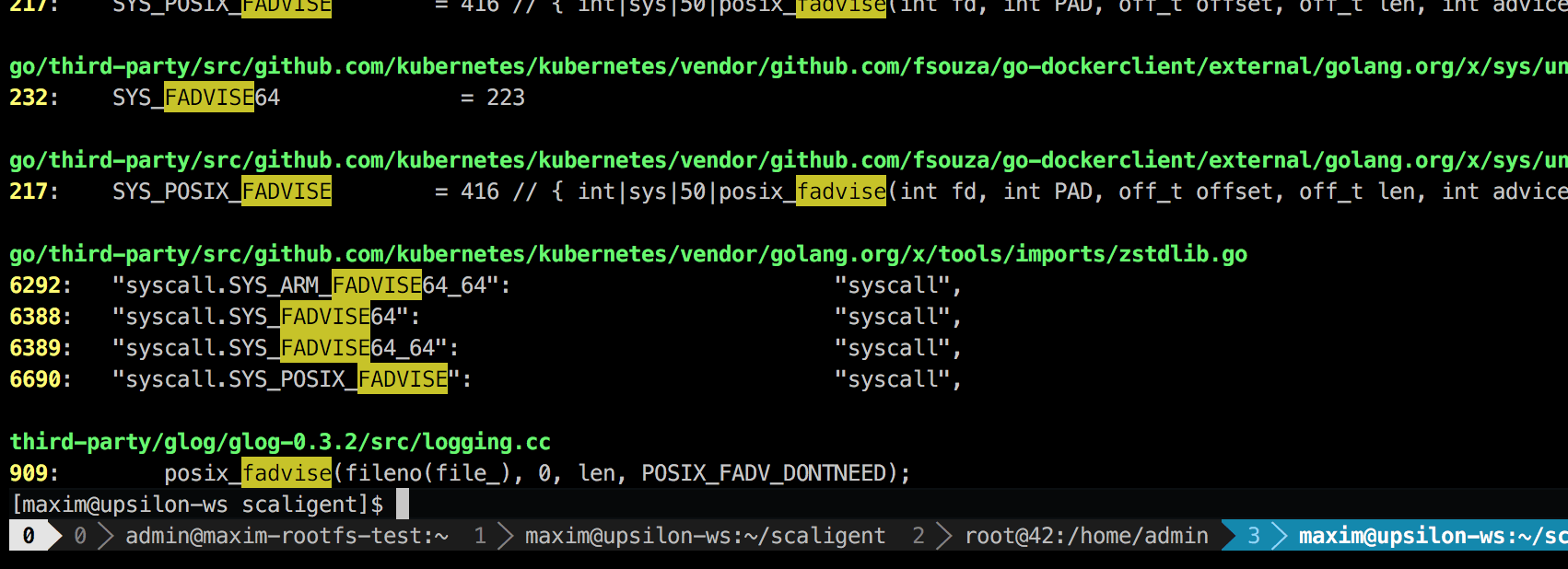
هذه مكتبة تسجيل من طرف ثالث تسمى glog . استخدمناها للمشروع. على وجه التحديد ، ربما يكون هذا السطر (في LogFileObject::Write ) هو المسار الأكثر أهمية للمكتبة بأكملها. يتم استدعاؤها لجميع الأحداث "تسجيل إلى ملف" (تسجيل إلى ملف) ، والعديد من مثيلات سجل منتجاتنا في كثير من الأحيان. تشير نظرة سريعة إلى شفرة المصدر إلى أنه يمكن تعطيل الجزء fadvise عن طريق تعيين --drop_log_memory=false معلمة --drop_log_memory=false :
if (file_length_ >= logging::kPageSize) {
الذي قمنا به بالطبع و ... في بولسي!
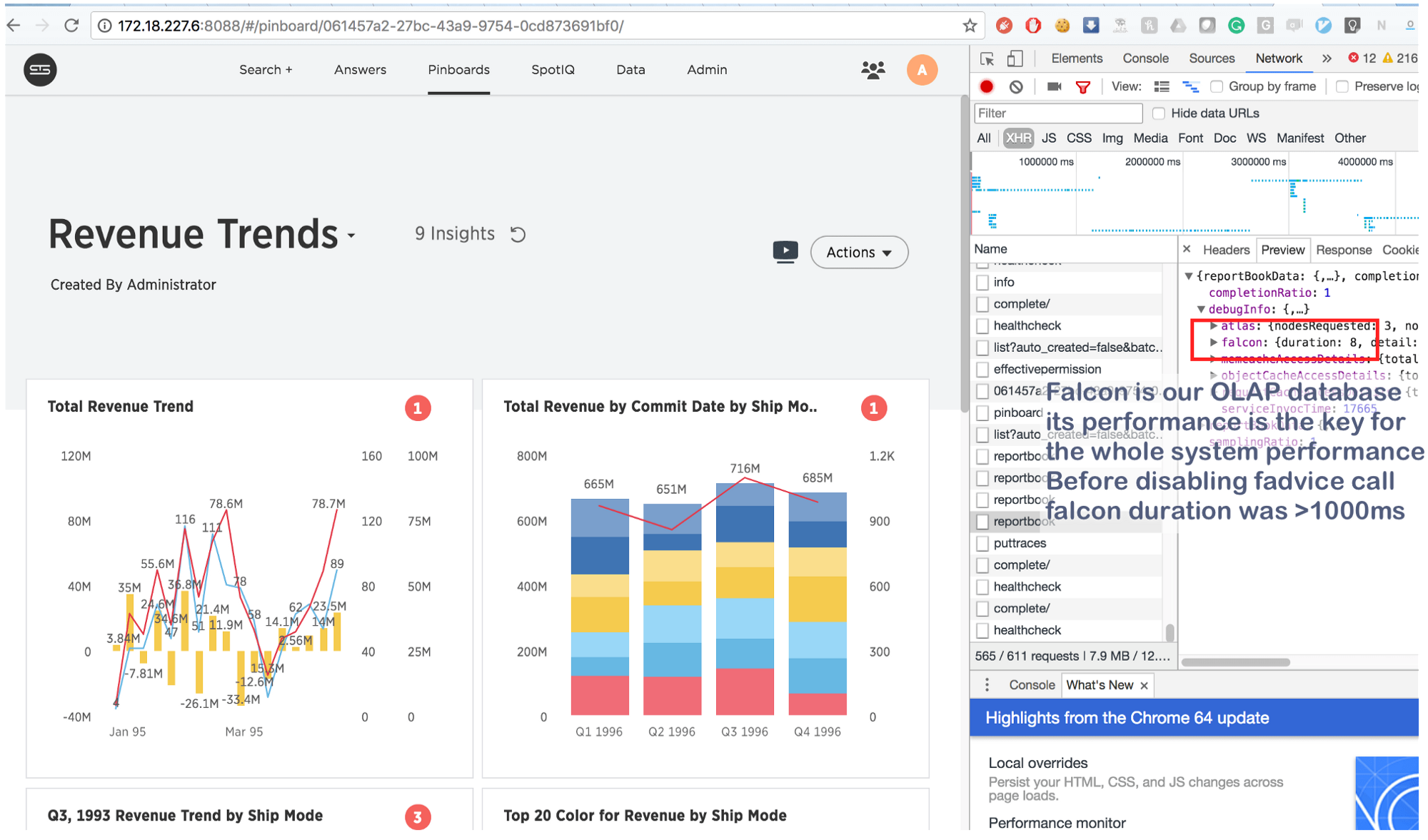
ما كان يستغرق بضع ثوانٍ يتم الآن في 8 (ثمانية!) مللي ثانية. القليل من googling ، وجدنا هذا: https://issues.apache.org/jira/browse/MESOS-920 وأيضًا هذا: https://github.com/google/glog/pull/145 ، والذي أكد مرة أخرى حدسنا حول السبب الحقيقي للتثبيط. على الأرجح ، حدث نفس الشيء على الآلة الافتراضية / المعدن العاري ، ولكن نظرًا لأن لدينا نسخة واحدة من العملية لكل آلة / نواة ، كانت كثافة المكالمة المذهلة أقل بكثير ، مما يفسر نقص استهلاك الموارد الإضافية. زيادة عمليات التسجيل بمقدار 3-4 مرات وإبراز نواة واحدة مشتركة لهم ، رأينا أنها متوقفة حقًا.
وفي الختام:
هذه المعلومات ليست جديدة ، ولكن لسبب ما ينسى الكثير من الأشخاص الشيء الرئيسي: في حالات الحاويات ، تتنافس العمليات "المعزولة" على جميع الموارد الأساسية ، وليس فقط على وحدة المعالجة المركزية وذاكرة الوصول العشوائي ومساحة القرص والشبكة . وبما أن النواة بنية معقدة للغاية ، يمكن أن تحدث الأعطال في أي مكان (على سبيل المثال ، في __d_lookup_loop من مقالة Sysdig ). ولكن هذا لا يعني أن الحاويات أسوأ أو أفضل من المحاكاة الافتراضية التقليدية. إنها أداة ممتازة تحل مهامهم. تذكر فقط: النواة مورد مشترك واستعد لتصحيح التعارضات غير المتوقعة في مساحة النواة. بالإضافة إلى ذلك ، تمثل هذه النزاعات فرصة كبيرة للمهاجمين لاختراق العزلة "الضعيفة" وإنشاء قنوات خفية بين الحاويات. وأخيرًا ، هناك perf - أداة ممتازة ستوضح ما يحدث في النظام وتساعد في تصحيح أي مشاكل في الأداء. إذا كنت تخطط لتشغيل تطبيقات عالية التحميل في Docker ، فتأكد من تخصيص بعض الوقت لتعلم perf .