الفصول السابقة
منحنيات التعلم
28 تشخيص التحيز والتناثر: منحنيات التعلم
لقد درسنا عدة طرق لفصل الأخطاء إلى تحيز يمكن تجنبه ومبعثر. قمنا بذلك من خلال تقييم النسبة المثلى من الأخطاء ، وحساب الأخطاء في عينة التدريب من الخوارزمية وفي عينة التحقق. دعونا نناقش نهج أكثر إفادة: الرسوم البيانية لمنحنى التعلم.
الرسوم البيانية لمنحنيات التعلم هي الاعتماد على حصة الخطأ على عدد من أمثلة عينة التدريب.
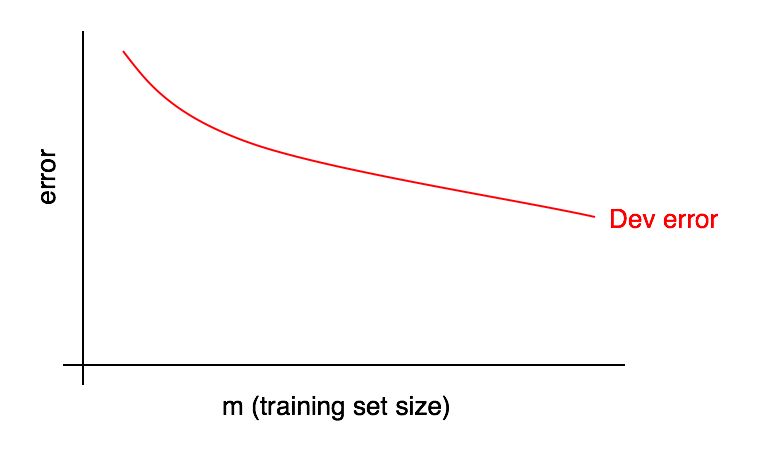
كلما زاد حجم عينة التدريب ، يجب أن ينخفض الخطأ في عينة التحقق.
سنركز غالبًا على بعض "حصة الأخطاء المطلوبة" التي نأمل أن تصل في نهاية المطاف إلى خوارزمياتنا. على سبيل المثال:
- إذا كنا نأمل في تحقيق مستوى من الجودة يمكن للإنسان الوصول إليه ، فيجب أن تصبح حصة الأخطاء البشرية "الحصة المطلوبة من الأخطاء"
- إذا تم استخدام خوارزمية التعلم في بعض المنتجات (مثل مزود صورة القط) ، فقد يكون لدينا فهم لمستوى الجودة الذي تحتاج إلى تحقيقه حتى يحصل المستخدمون على أكبر فائدة
- إذا كنت تعمل على تطبيق مهم لفترة طويلة ، فقد يكون لديك فهم معقول للتقدم الذي يمكنك تحقيقه في الربع / السنة القادمة.
أضف مستوى الجودة المطلوب لمنحنى التعلم لدينا:

يمكنك استقراء منحنى الخطأ الأحمر في عينة التحقق بصريًا وافتراض مدى قربك من مستوى الجودة المطلوب عن طريق إضافة المزيد من البيانات. في المثال الموضح في الصورة ، يبدو من المرجح أن مضاعفة حجم عينة التدريب سيحقق المستوى المطلوب من الجودة.
ومع ذلك ، إذا وصل منحنى جزء خطأ عينة التحقق إلى هضبة (أي تحول إلى خط مستقيم موازٍ لمحور الخراج) ، فإنه يشير على الفور إلى أن إضافة بيانات إضافية لن يساعد في تحقيق الهدف:
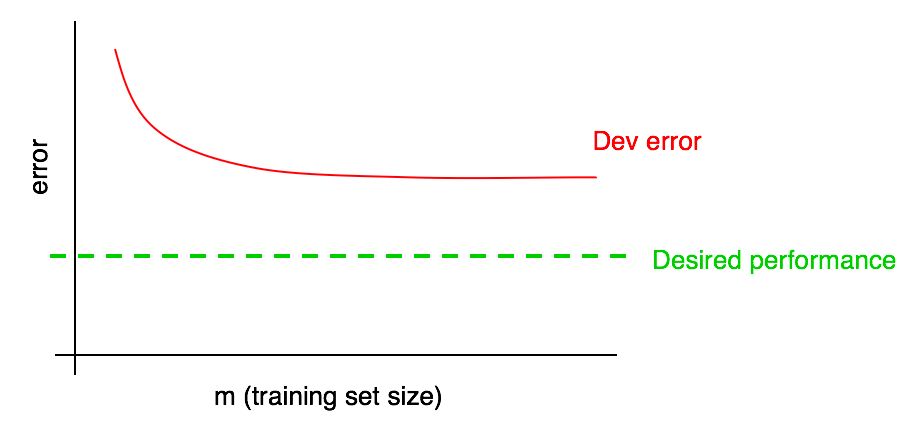
يمكن أن تساعدك نظرة على منحنى التعلم على تجنب قضاء أشهر في جمع ضعف بيانات التدريب فقط لإدراك أن إضافتها لا تساعد.
أحد عيوب هذا النهج هو أنه إذا نظرت فقط إلى منحنى الخطأ في عينة التحقق من الصحة ، فقد يكون من الصعب الاستقراء والتنبؤ بدقة بكيفية تصرف المنحنى الأحمر إذا قمت بإضافة المزيد من البيانات. لذلك ، هناك رسم بياني إضافي آخر يمكن أن يساعد في تقييم تأثير بيانات التدريب الإضافية على نسبة الأخطاء: خطأ في التعلم.
29 جدول أخطاء التعلم
يجب أن تنخفض الأخطاء في عينات التحقق (والاختبار) مع زيادة عينة التدريب. ولكن في عينة التدريب ، ينمو الخطأ في إضافة البيانات عادة.
دعونا توضيح هذا التأثير بمثال. لنفترض أن عينة التدريب الخاصة بك تتكون من مثالين فقط: صورة واحدة مع قطط وصورة بدون قطط. في هذه الحالة ، يمكن أن تتذكر خوارزمية التعلم بسهولة كلا المثالين لعينة التدريب وتظهر خطأ 0 ٪ في عينة التدريب. حتى إذا تم تصنيف كل من أمثلة التدريب بشكل غير صحيح ، فإن الخوارزمية ستتذكر فصولها بسهولة.
تخيل الآن أن مجموعة التدريب الخاصة بك تتكون من 100 مثال. لنفترض أن عددًا معينًا من الأمثلة تم تصنيفه بشكل غير صحيح ، أو أنه من المستحيل إنشاء فئة في بعض الأمثلة ، على سبيل المثال ، في صور ضبابية ، حتى عندما لا يستطيع الشخص تحديد ما إذا كانت القطة موجودة في الصورة أم لا. لنفترض أن خوارزمية التعلم لا تزال "تتذكر" معظم أمثلة نماذج التدريب ، ولكن من الصعب الآن الحصول على دقة 100٪. بزيادة عينة التدريب من 2 إلى 100 مثال ، ستجد أن دقة الخوارزمية في عينة التدريب ستنخفض تدريجيًا.
في النهاية ، لنفترض أن مجموعة التدريب الخاصة بك تتكون من 10000 مثال. في هذه الحالة ، يصبح من الصعب بشكل متزايد على الخوارزمية تصنيف جميع الأمثلة بشكل مثالي ، خاصة إذا كانت مجموعة التدريب تحتوي على صور ضبابية وأخطاء تصنيف. وبالتالي ، ستعمل الخوارزمية بشكل أسوأ على مثل هذه العينة التدريبية.
دعنا نضيف الرسم البياني لخطأ التعلم إلى الرسم البياني السابق.
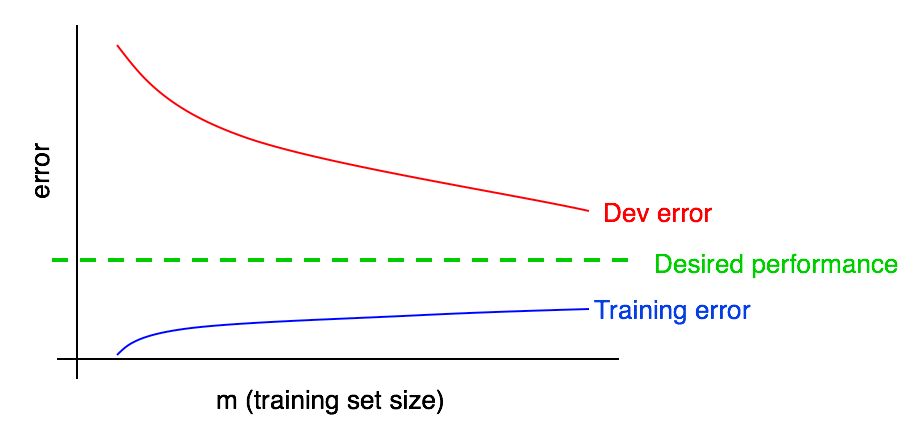
يمكنك أن ترى أن منحنى "أخطاء التعلم" الأزرق ينمو مع زيادة في عينة التدريب. علاوة على ذلك ، عادة ما تظهر خوارزمية التعلم جودة أفضل في عينة التدريب من عينة التحقق ؛ وبالتالي ، يقع منحنى الخطأ الأحمر في عينة التحقق فوق منحنى الخطأ الأزرق في عينة التدريب.
بعد ذلك ، دعنا نناقش كيفية تفسير هذه الرسوم البيانية.
استمرار