كمهندس بنية أساسية في فريق تطوير النظام الأساسي السحابي ، أتيحت لي الفرصة للعمل مع العديد من أنظمة التخزين الموزعة ، بما في ذلك تلك المشار إليها في العنوان. يبدو أن هناك فهمًا لنقاط القوة والضعف لديهم ، وسأحاول مشاركة أفكاري معك حول هذا الموضوع. إذا جاز التعبير ، دعنا نرى من لديه وظيفة التجزئة لفترة أطول.

تنويه: في وقت سابق في هذه المدونة يمكن أن ترى مقالات عن GlusterFS. ليس لدي أي علاقة بهذه المقالات. هذه هي مدونة المؤلف لفريق المشروع في السحابة لدينا ويمكن لكل من أعضائها سرد قصتهم. مؤلف هذه المقالات مهندس في مجموعة عملياتنا ولديه مهامه الخاصة وخبرته التي شاركها. يرجى أخذ ذلك في الاعتبار إذا رأيت فجأة اختلاف في الرأي. أغتنم هذه الفرصة لأقدم تحياتي لمؤلف هذه المقالات!
ما سيتم مناقشته
دعونا نتحدث عن أنظمة الملفات التي يمكن بناؤها على أساس GlusterFS و CephFS. سنناقش بنية هذين النظامين ، وننظر إليهما من زوايا مختلفة ، وفي النهاية سوف أخاطر حتى بإصدار أي استنتاجات. لن تتأثر ميزات Ceph الأخرى ، مثل RBD و RGW.
المصطلحات
لجعل المقالة كاملة ومفهومة للجميع ، دعنا نلقي نظرة على المصطلحات الأساسية لكلا النظامين:
مصطلحات Ceph:
RADOS ( مخزن الأشياء الموزعة المستقلة الموثوقة) هو تخزين كائن قائم بذاته ، وهو أساس مشروع Ceph.
CephFS و RBD (RADOS Block Device) و RGW (RADOS Gateway) هي أدوات عالية المستوى لـ RADOS توفر للمستخدمين النهائيين واجهات مختلفة لـ RADOS.
على وجه التحديد ، يوفر CephFS واجهة نظام ملفات متوافقة مع POSIX. في الواقع ، يتم تخزين بيانات CephFS في RADOS.
OSD (Object Storage Daemon) هي عملية تخدم تخزين قرص / كائن منفصل في مجموعة RADOS.
تجمع RADOS (تجمع) - عدة OSD توحدها مجموعة مشتركة من القواعد ، على سبيل المثال ، سياسة النسخ المتماثل. من وجهة نظر التسلسل الهرمي للبيانات ، التجمع هو دليل أو مساحة اسم منفصلة (مسطحة ، بدون أدلة فرعية) للكائنات.
PG (مجموعة التنسيب) - سأقدم مفهوم PG بعد ذلك بقليل ، في السياق ، لفهم أفضل.
نظرًا لأن RADOS هو الأساس الذي تم بناء CephFS عليه ، فسوف أتحدث عنه كثيرًا وهذا ينطبق تلقائيًا على CephFS.
مصطلحات GlusterFS (فيما يلي gl):
الطوب هو عملية تخدم قرصًا واحدًا ، وهو نظير لـ OSD في مصطلحات RADOS.
الحجم - الحجم الذي يتم فيه توحيد الطوب. Tom هو نظير تجمع في RADOS ، ولديه أيضًا طوبولوجيا نسخ متماثل بين الطوب.
توزيع البيانات
لتوضيح الأمر ، ضع في اعتبارك مثالاً بسيطًا يمكن تنفيذه بواسطة كلا النظامين.
الإعداد المراد استخدامه كمثال:
- خادمان (S1 ، S2) مع 3 أقراص متساوية الحجم (sda ، sdb ، sdc) في كل منهما ؛
- حجم / تجمع مع النسخ المتماثل 2.
يحتاج كلا النظامين إلى 3 خوادم على الأقل للتشغيل العادي. لكننا نغض الطرف عن هذا ، لأن هذا مجرد مثال لمقال.
في حالة gl ، سيكون هذا حجمًا موزَّعًا ومكررًا يتألف من 3 مجموعات نسخ:

كل مجموعة نسخ متماثلة هي طوبان على خوادم مختلفة.
في الواقع ، تبين الحجم الذي يجمع بين RAID-1 الثلاثة.
عندما تقوم بتركيبه ، احصل على نظام الملفات المطلوب وابدأ في كتابة الملفات إليه ، ستجد أن كل ملف تكتبه يقع في إحدى مجموعات النسخ المتماثل هذه ككل.
يتم توزيع الملفات بين هذه المجموعات الموزعة بواسطة DHT (جداول التجزئة الموزعة) ، وهي في الأساس دالة تجزئة (سنعود إليها لاحقًا).
في "الرسم التخطيطي" ، سيبدو كما يلي:
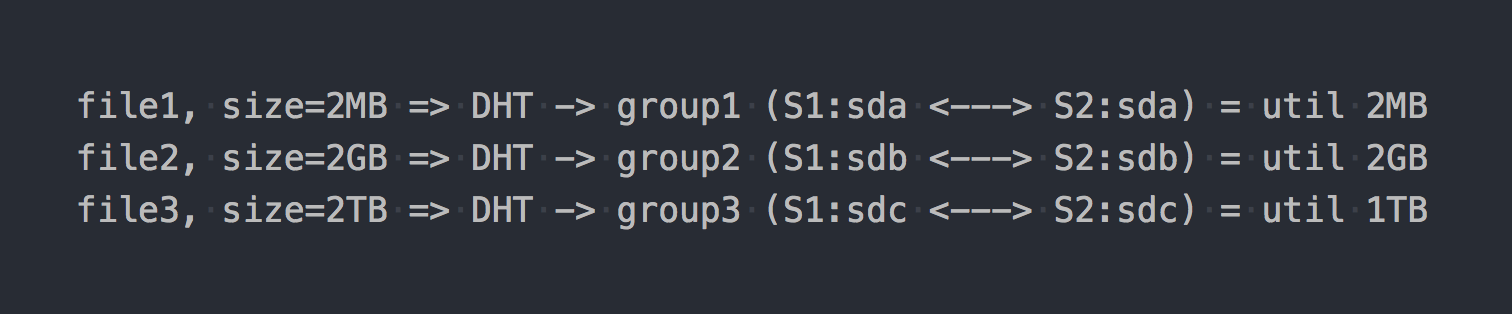
كما لو كانت السمات المعمارية الأولى قد ظهرت بالفعل:
- يتم التخلص من المكان في مجموعات بشكل غير متساوٍ ، ويعتمد على أحجام الملفات ؛
- عند كتابة ملف واحد ، يذهب IO إلى مجموعة واحدة فقط ، والباقي خاملاً ؛
- لا يمكنك الحصول على الإدخال / الإخراج لوحدة التخزين بالكامل عند كتابة ملف واحد ؛
- إذا لم تكن هناك مساحة كافية في المجموعة لكتابة الملف ، فسوف تحصل على خطأ ، ولن تتم كتابة الملف ولن يتم إعادة توزيعه على مجموعة أخرى.
إذا كنت تستخدم أنواعًا أخرى من المجلدات ، على سبيل المثال ، Distributed-Striped-Replicated or Dis موزعed (Erasure Coding) ، فعندئذ فقط آليات توزيع البيانات داخل مجموعة واحدة ستتغير بشكل أساسي. ستحلل DHT أيضًا الملفات بالكامل في هذه المجموعات ، وفي النهاية سنحصل على نفس المشاكل. نعم ، إذا كانت وحدة التخزين تتكون من مجموعة واحدة فقط ، أو إذا كان لديك جميع الملفات من نفس الحجم تقريبًا ، فلن تكون هناك مشكلة. لكننا نتحدث عن الأنظمة العادية ، تحت مئات تيرابايت من البيانات ، بما في ذلك الملفات ذات الأحجام المختلفة ، لذلك نعتقد أن هناك مشكلة.
الآن دعونا نلقي نظرة على CephFS. يدخل RADOS المذكور أعلاه المشهد. في RADOS ، يتم تقديم كل قرص بعملية منفصلة - OSD. بناءً على إعدادنا ، نحصل على 6 منها فقط ، 3 على كل خادم. بعد ذلك ، نحتاج إلى إنشاء تجمع للبيانات وتعيين عدد PGs وعامل نسخ البيانات في هذا التجمع - في حالتنا 2.
لنفترض أننا أنشأنا مسبحًا مع 8 PG. سيتم توزيع PGs هذه بالتساوي تقريبًا عبر OSD:
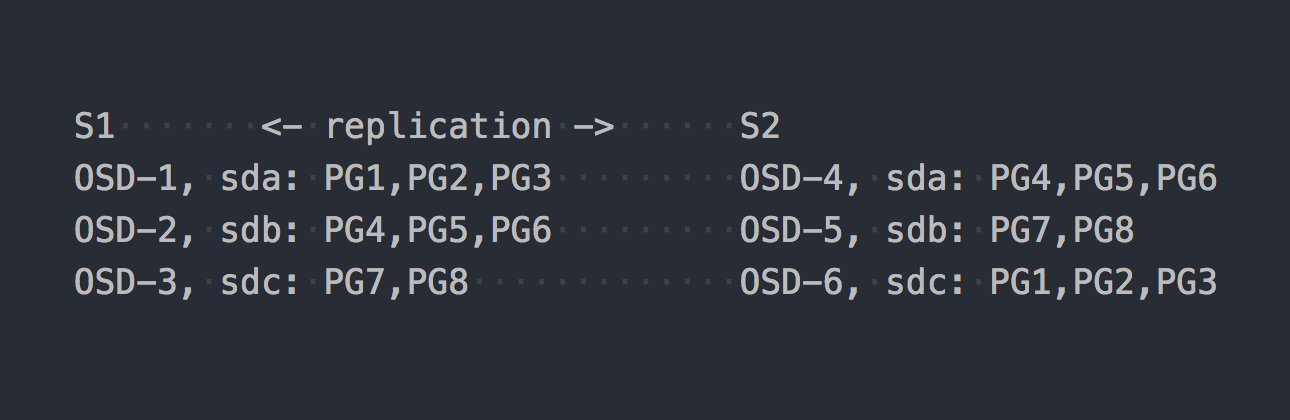
حان الوقت لتوضيح أن PG هي مجموعة منطقية تجمع بين عدد من الكائنات. نظرًا لأننا عيّننا حقيقة النسخ المتماثل 2 ، فإن لكل PG نسخة متماثلة على بعض OSD أخرى على خادم آخر (افتراضيًا). على سبيل المثال ، PG1 ، الموجود على OSD-1 على الخادم S1 ، لديه توأم على S2 على OSD-6. في كل زوج من PG (أو الثلاثي ، إذا كان التكرار 3) هو PG الأساسي PG ، الذي يتم تسجيله. على سبيل المثال ، PRIMARY لـ PG4 موجود على S1 ، لكن PRIMARY لـ PG3 موجود على S2.
الآن بعد أن عرفت كيف يعمل RADOS ، يمكننا الانتقال إلى كتابة الملفات إلى مجموعتنا الجديدة. على الرغم من أن RADOS عبارة عن وحدة تخزين كاملة ، إلا أنه لا يمكن تركيبها كنظام ملفات أو استخدامها كجهاز كتلة. لكتابة البيانات مباشرة ، تحتاج إلى استخدام أداة أو مكتبة خاصة.
نكتب نفس الملفات الثلاثة كما في المثال أعلاه:
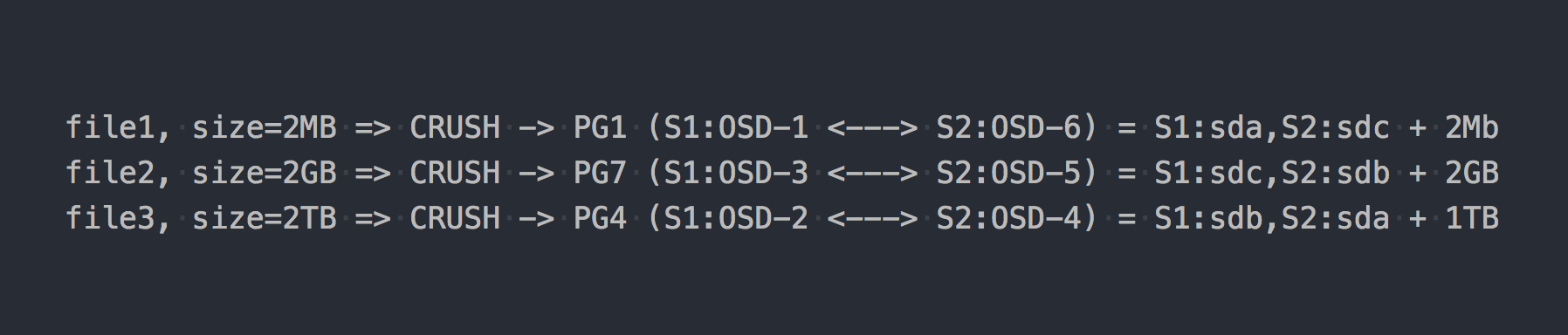
في حالة RADOS ، أصبح كل شيء أكثر تعقيدًا بطريقة أو بأخرى.
ثم ظهر CRUSH (النسخ المتماثل المتحكم به تحت التجزئة القابلة للتحجيم) في السلسلة. CRUSH هي الخوارزمية التي يعتمد عليها RADOS (سنعود إليها لاحقًا). في هذه الحالة بالذات ، باستخدام هذه الخوارزمية ، يتم تحديد مكان كتابة الملف الذي PG. هنا CRUSH تؤدي نفس وظيفة DHT في gl. نتيجة لهذا التوزيع العشوائي الزائف للملفات على PG ، حصلنا على جميع المشاكل نفسها مثل gl ، فقط على مخطط أكثر تعقيدًا.
لكنني سكتت عمدا حول نقطة واحدة مهمة. تقريبا لا أحد يستخدم RADOS في شكله النقي. للعمل المريح مع RADOS ، تم تطوير الطبقات التالية: RBD ، CephFS ، RGW ، التي ذكرتها بالفعل.
يوفر كل هؤلاء المترجمين (عملاء RADOS) واجهة عميل مختلفة ، لكنهم متشابهون في عملهم مع RADOS. التشابه الأكثر أهمية هو أن جميع البيانات التي تمر عبرها يتم قطعها إلى قطع ووضعها في RADOS ككائنات RADOS منفصلة. بشكل افتراضي ، يقطع العملاء الرسميون تدفق الإدخال إلى قطع بحجم 4 ميجابايت. بالنسبة لـ RBD ، يمكن تعيين حجم الشريط عند إنشاء وحدة التخزين. في حالة CephFS ، هذه هي سمة (xattr) للملف ويمكن إدارتها على مستوى الملفات الفردية أو لجميع ملفات الكتالوج. حسنًا ، يحتوي RGW أيضًا على معلمة مقابلة.
لنفترض الآن أننا قمنا بتكديس CephFS فوق مجموعة RADOS التي تم عرضها في المثال السابق. الآن أصبحت الأنظمة المعنية على قدم المساواة تمامًا وتوفر واجهة وصول متطابقة للملف.
إذا كتبنا ملفات الاختبار الخاصة بنا مرة أخرى إلى CephFS الجديد تمامًا ، فسوف نجد توزيعًا مختلفًا تمامًا وموحدًا تقريبًا للبيانات على OSD. على سبيل المثال ، سيتم تقسيم الملف 2 بحجم 2 غيغابايت إلى 512 قطعة ، والتي سيتم توزيعها عبر PGs المختلفة ، ونتيجة لذلك ، عبر OSD مختلفة بشكل موحد تقريبًا ، وهذا يحل عمليًا مشاكل توزيع البيانات الموضحة أعلاه.
في مثالنا ، يتم استخدام 8 PG فقط ، على الرغم من أنه يوصى باستخدام ~ 100 PG على OSD واحد. وتحتاج إلى مجموعتين لتعمل CephFS. وتحتاج أيضًا إلى بعض برامج الخدمة لكي يعمل RADOS من حيث المبدأ. لا تعتقد أن كل شيء بسيط للغاية ، فأنا أهمل الكثير على وجه التحديد ، حتى لا أخرج عن الجوهر.
لذا يبدو CephFS الآن أكثر إثارة للاهتمام ، أليس كذلك؟ لكنني لم أذكر نقطة مهمة أخرى ، هذه المرة عن gl. يحتوي Gl أيضًا على آلية لقطع الملفات إلى أجزاء وتشغيل تلك الأجزاء من خلال DHT. ما يسمى بالتجزئة ( Sharding ).
تاريخ خمس دقائق
في 21 أبريل 2016 ، أصدر فريق تطوير Ceph "الجوهرة" ، أول إصدار Ceph يعتبر فيه CephFS مستقرًا.
هذا هو الآن كل صيحة اليسار واليمين حول CephFS! وقبل 3-4 سنوات لاستخدامه سيكون قرارًا مريبًا على الأقل. بحثنا عن حلول أخرى ، ولم يكن التصميم المعماري الموصوف أعلاه جيدًا. لكننا كنا نؤمن بها أكثر من CephFS ، وانتظرنا التقسيم ، الذي كان يستعد للإفراج.
وها هو اليوم العاشر:
4 يونيو 2015 - أعلن مجتمع Gluster اليوم عن توفر برنامج التخزين المفتوح المحدد بالبرمجيات GlusterFS 3.7 بشكل عام.
3.7 - الإصدار الأول من gl ، حيث تم الإعلان عن التجزئة كفرصة تجريبية. كان لديهم ما يقرب من عام قبل الإطلاق المستقر لـ CephFS من أجل الحصول على موطئ قدم على المنصة ...
يعني ذلك التقسيم. مثل كل شيء في gl ، يتم تنفيذ هذا في مترجم منفصل ، والذي وقف فوق DHT (مترجم أيضًا) على المكدس. نظرًا لأنه أعلى من DHT ، يتلقى DHT شظايا جاهزة عند الإدخال ويوزعها على مجموعات النسخ المتماثل كملفات عادية. تم تمكين المشاركة على مستوى الصوت الفردي. يمكن تحديد حجم الشظية افتراضيًا - 4 ميجا بايت ، مثل مستحضرات Ceph.
عندما أجريت الاختبارات الأولى كنت مسرورًا! أخبرت الجميع أن gl هو الآن أهم شيء ، وسنعيش الآن! مع تمكين التجزئة ، يذهب تسجيل ملف واحد بالتوازي مع مجموعات النسخ المتماثل المختلفة. يمكن أن يكون فك الضغط بعد الضغط "عند الكتابة" تدريجيًا إلى مستوى الجزء. في وجود تصوير ذاكرة التخزين المؤقت هنا أيضًا ، يصبح كل شيء جيدًا ويتم نقل شظايا منفصلة إلى ذاكرة التخزين المؤقت ، وليس الملفات بأكملها. بشكل عام ، فرحت ، لأنه يبدو أنه حصل على أداة رائعة للغاية في يديه.
وبقي انتظار الإصلاحات الأولى وحالة "جاهز للإنتاج". لكن كل شيء اتضح أنه ليس وردياً ... حتى لا نمد المقالة بقائمة من الأخطاء الحرجة المتعلقة بالتجزئة ، بين الحين والآخر تظهر في الإصدارات التالية ، لا يسعني إلا أن أقول أن "المشكلة الرئيسية" الأخيرة مع الوصف التالي:
قد يؤدي توسيع وحدة التخزين اللامعة التي تم تجزئتها إلى تلف الملف. عادةً ما يتم استخدام وحدات التخزين الممزوجة لصور VM ، إذا تم توسيع هذه الأحجام أو ربما تقلصت (أي إضافة / إزالة الطوب وإعادة التوازن) فهناك تقارير عن تلف صور VM.
تم إغلاقه في الإصدار 3.13.2 ، 20 يناير 2018 ... ربما هذا ليس الأخير؟
تعليق على أحد مقالاتنا حول هذا ، إذا جاز التعبير ، مباشرة.
تلاحظ RedHat في وثائقها الخاصة بـ RedHat Gluster Storage 3.4 الحالي أن حالة التقاسم الوحيدة التي تدعمها هي تخزين أقراص VM.
يحتوي Sharding على حالة استخدام مدعومة: في سياق توفير Red Hat Gluster Storage كمجال تخزين لـ Red Hat Enterprise Virtualization ، لتوفير تخزين لصور الجهاز الظاهري الحية. لاحظ أن التجميع هو أيضًا متطلب لحالة الاستخدام هذه ، لأنه يوفر تحسينات كبيرة في الأداء مقارنة بالتطبيقات السابقة.
أنا لا أعرف لماذا مثل هذا القيد ، ولكن يجب أن تعترف أنه مثير للقلق.
الآن لدي كل شيء هنا من أجلك
يستخدم كلا النظامين دالة التجزئة لتوزيع البيانات بشكل عشوائي على الأقراص.
بالنسبة لـ RADOS ، يبدو الأمر مثل هذا:
PG = pool_id + "." + jenkins_hash(object_name) % pg_coun # eg pool id=5 => pg = 5.1f OSD = crush_hash_based_on_jenkins(PG) # eg pg=5.1f => OSD = 12
يستخدم Gl ما يسمى التجزئة المتسقة . يحصل كل لبنة على "مدى داخل مساحة تجزئة 32 بت". أي أن جميع الطوب يشتركون في مساحة تجزئة العنوان الخطي بالكامل دون نطاقات أو ثقوب متقاطعة. يقوم العميل بتشغيل اسم الملف من خلال وظيفة التجزئة ، ثم يحدد نطاق التجزئة الذي يقع فيه. وهكذا يتم اختيار الطوب. إذا كان هناك العديد من الطوب في مجموعة النسخ المتماثل ، فكلها لها نفس نطاق التجزئة. شيء من هذا القبيل:
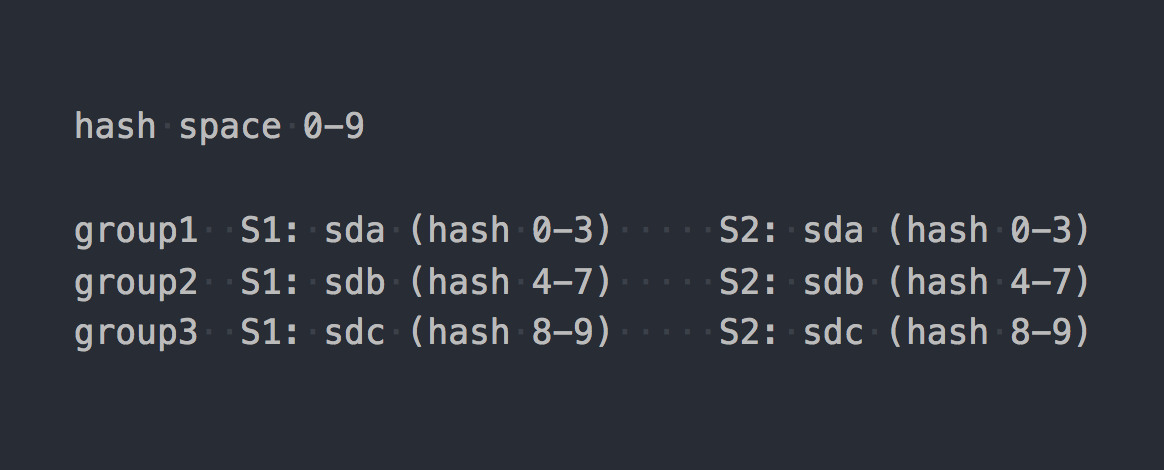
إذا جلبنا عمل نظامين إلى شكل منطقي معين ، فسيظهر شيء مثل هذا:
file -> HASH -> placement_unit
حيث placement_unit في حالة RADOS هو PG ، وفي حالة gl هي مجموعة نسخ من عدة طوب.
إذن ، دالة التجزئة ، ثم يقوم هذا بتوزيع الملفات وتوزيعها ، وفجأة اتضح أن أحد مواضع الإعلانات تم استخدام وحدة أكثر من الأخرى. هذه هي الميزة الأساسية لأنظمة توزيع التجزئة. ونحن نواجه مهمة شائعة جدًا - عدم توازن البيانات.
يمكن لـ Gl إعادة البناء ، ولكن نظرًا للهندسة المعمارية ذات نطاقات التجزئة الموضحة أعلاه ، يمكنك تشغيل إعادة البناء بقدر ما تريد ، ولكن لن يتزحزح نطاق التجزئة (ونتيجة لذلك ، البيانات). المعيار الوحيد لإعادة توزيع نطاقات التجزئة هو تغيير في سعة الحجم. ولديك خيار واحد متبقي - لإضافة الطوب. وإذا كنا نتحدث عن وحدة تخزين مع النسخ المتماثل ، فيجب علينا إضافة مجموعة نسخ كاملة ، أي طابوقان جديدان في إعدادنا. بعد توسيع الحجم ، يمكنك البدء في إعادة البناء - سيتم إعادة توزيع نطاقات التجزئة مع مراعاة المجموعة الجديدة وسيتم توزيع البيانات. عند حذف مجموعة النسخ المتماثل ، يتم تخصيص نطاقات التجزئة تلقائيًا.
RADOS لديه سيارة كاملة من الاحتمالات. في مقال Ceph ، اشتكت كثيرًا من مفهوم PG ، ولكن هنا ، مقارنة مع gl ، بالطبع ، RADOS على ظهور الخيل. لكل OSD وزنه الخاص ، وعادةً ما يتم تعيينه بناءً على حجم القرص. في المقابل ، يتم توزيع PGs بواسطة OSD اعتمادًا على وزن الأخير. كل شيء ، ثم نقوم فقط بتغيير وزن OSD لأعلى أو لأسفل ويبدأ PG (جنبًا إلى جنب مع البيانات) في الانتقال إلى OSDs الأخرى. أيضا ، كل OSD له وزن تعديل إضافي ، والذي يسمح لك بموازنة البيانات بين أقراص خادم واحد. كل هذا متأصل في CRUSH. الربح الرئيسي هو أنه ليس من الضروري توسيع سعة المجمع من أجل عدم توازن البيانات بشكل أفضل. وليس من الضروري إضافة أقراص في مجموعات ، يمكنك إضافة OSD واحد فقط وسيتم نقل جزء من PG إليها.
نعم ، من الممكن أنه عند إنشاء تجمع لم يخلقوا ما يكفي من PG واتضح أن كل من PGs كبير جدًا في الحجم ، وحيثما تحركوا ، سيبقى الخلل. في هذه الحالة ، يمكنك زيادة عدد PG ، ويتم تقسيمها إلى أصغر. نعم ، إذا كانت المجموعة مليئة بالبيانات ، فهذا مؤلم ، ولكن الشيء الرئيسي في مقارنتنا هو أن هناك مثل هذه الفرصة. الآن لا يُسمح إلا بزيادة عدد PGs ، وعليك أن تكون أكثر حذراً ، ولكن في الإصدار التالي من Ceph - Nautilus سيكون هناك دعم لتقليل عدد PG (دمج الصفحات).
نسخ البيانات
تشتمل معامل وأحجام اختباراتنا على عامل تكرار يبلغ 2. ومن المثير للاهتمام أن الأنظمة المعنية تستخدم أساليب مختلفة لتحقيق هذا العدد من النسخ المتماثلة.
في حالة RADOS ، يبدو نظام التسجيل شيئًا مثل هذا:
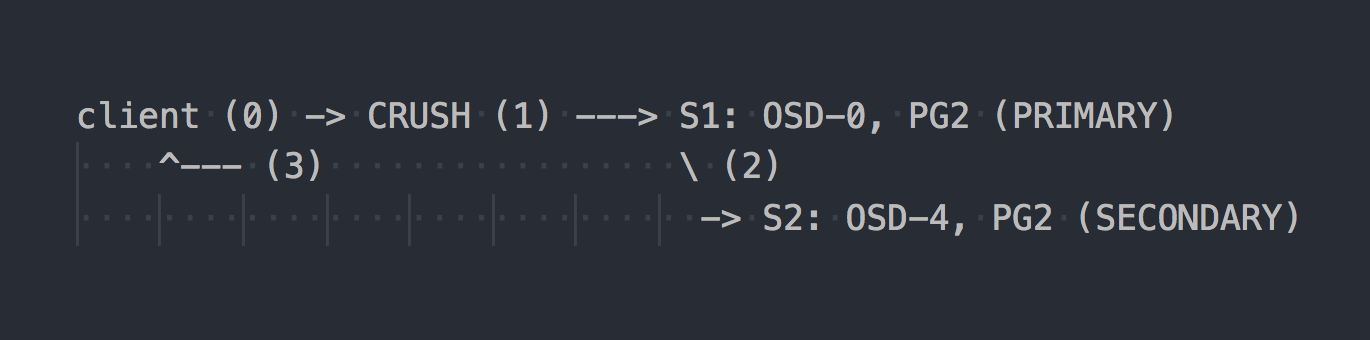
يعرف العميل طوبولوجيا المجموعة بأكملها ، ويستخدم CRUSH (الخطوة 0) لتحديد PG معين للكتابة ، ويكتب إلى PRIMARY PG على OSD-0 (الخطوة 1) ، ثم يقوم OSD-0 بتكرار البيانات بشكل متزامن إلى SECONDARY PG (الخطوة 2) ، وبعد ذلك فقط الخطوة 2 الناجحة / غير الناجحة ، تؤكد OSD / لا تؤكد العملية للعميل (الخطوة 3). يعتبر نسخ البيانات بين OSDs شفافًا للعميل. بشكل عام ، تستطيع OSDs استخدام شبكة منفصلة "أسرع" للنسخ المتماثل للبيانات.
إذا تم تكوين النسخ المتماثل الثلاثي ، فإنه يعمل أيضًا بشكل متزامن مع PRIMARY OSD على اثنين ثانويين ، شفافين للعميل ... حسنًا ، فقط هذا الخلل أعلى.
يعمل Gl بشكل مختلف:
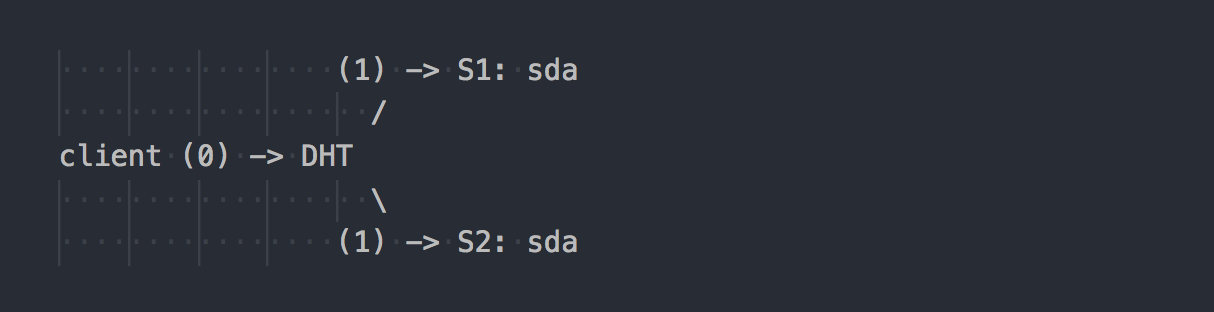
يعرف العميل هيكل الحجم ، ويستخدم DHT (الخطوة 0) لتحديد الطوب المطلوب ، ثم يكتب عليه (الخطوة 1). كل شيء بسيط وواضح. ولكن هنا نتذكر أن جميع الطوب في مجموعة النسخ لها نفس نطاق التجزئة. وهذه الميزة البسيطة تجعل العطلة بأكملها. يكتب العميل بالتوازي مع جميع الطوب الذي يحتوي على نطاق تجزئة مناسب.
في حالتنا ، مع النسخ المزدوج ، يقوم العميل بإجراء تسجيل مزدوج بالتوازي على طابقتين مختلفتين. أثناء النسخ المتماثل الثلاثي ، سيتم تنفيذ التسجيل الثلاثي ، على التوالي ، وسيتحول 1 ميجابايت من البيانات تقريبًا إلى 3 ميجابايت من حركة مرور الشبكة من العميل إلى جانب خوادم gl. موافق ، مفاهيم الأنظمة متعامدة.
في مثل هذا المخطط ، يتم تعيين المزيد من العمل للعميل gl ، ونتيجة لذلك ، يحتاج إلى المزيد من وحدة المعالجة المركزية ، حسنًا ، لقد قلت بالفعل عن الشبكة.
يتم إجراء النسخ المتماثل من قبل مترجم AFP (النسخ المتماثل التلقائي للملفات) - xlator من جانب العميل يقوم بإجراء النسخ المتزامن. Replicates يكتب على كل الطوب من النسخة المتماثلة ← يستخدم نموذج المعاملة.
إذا لزم الأمر ، قم بمزامنة النسخ المتماثلة في المجموعة (الشفاء) ، على سبيل المثال ، بعد عدم توفر مؤقت لبنة واحدة ، تقوم الشياطين العملاقة بذلك من تلقاء نفسها باستخدام وكالة فرانس برس المدمجة ، شفافة للعملاء وبدون مشاركتهم.
من المثير للاهتمام أنه إذا لم تعمل من خلال عميل gl الأصلي ، ولكن اكتب من خلال خادم NFS المدمج في gl ، فسوف نحصل على نفس السلوك مثل RADOS. في هذه الحالة ، سيتم استخدام AFP في da daemons لتكرار البيانات دون تدخل العميل. ولكن NFS المدمج مؤمن في gl v4 ، وإذا كنت تريد هذا السلوك ، فمن المستحسن استخدام NFS-Ganesha.
بالمناسبة ، بسبب السلوك المختلف جدًا عند استخدام NFS والعميل الأصلي ، يمكنك رؤية مؤشرات أداء مختلفة تمامًا.
هل لديك نفس الكتلة ، فقط "على الركبة"؟
غالبًا ما أرى في مناقشات الإنترنت جميع أنواع إعدادات الرضفة ، حيث يتم بناء مجموعة بيانات مما هو في متناول اليد. في هذه الحالة ، يمكن أن يمنحك الحل المستند إلى RADOS المزيد من الحرية عند اختيار محركات الأقراص. في RADOS ، يمكنك إضافة محركات من أي حجم تقريبًا. سيكون لكل قرص وزن يتوافق مع حجمه (عادة) ، وسيتم توزيع البيانات عبر الأقراص بشكل متناسب تقريبًا مع وزنها. في حالة gl ، لا يوجد مفهوم "أقراص منفصلة" في مجلدات مع النسخ المتماثل. يتم إضافة الأقراص في أزواج عند التكرار المزدوج أو ثلاث مرات في ثلاثية. إذا كانت هناك أقراص بأحجام مختلفة في مجموعة نسخ متماثلة واحدة ، فحينئذٍ ستركض إلى مكان على أصغر قرص في المجموعة وتفكك سعة الأقراص الكبيرة. في مثل هذا المخطط ، سيفترض gl أن سعة مجموعة النسخ المتماثل تساوي سعة أصغر قرص في المجموعة ، وهو أمر منطقي. في الوقت نفسه ، يُسمح بمجموعات النسخ المتماثل التي تتكون من أقراص بأحجام مختلفة - مجموعات بأحجام مختلفة. يمكن أن تتلقى المجموعات الأكبر نطاق تجزئة أكبر مقارنة بالمجموعات الأخرى ، ونتيجة لذلك ، تتلقى المزيد من البيانات.
نحن نعيش مع سيف للسنة الخامسة. بدأنا بأقراص من نفس الحجم ، والآن نقدم أقراصًا أكثر سعة. باستخدام Ceph ، يمكنك إزالة القرص واستبداله بآخر أكبر أو أصغر قليلاً دون أي صعوبات معمارية. مع gl ، كل شيء أكثر تعقيدًا - أخرج قرصًا بسعة 2 تيرابايت - ضع نفس القرص ، من فضلك. حسنًا ، أو اسحب المجموعة بأكملها ككل ، وهي ليست جيدة جدًا ، توافق على ذلك.
الفشل
لقد تعرفنا بالفعل على بنية الحلين والآن يمكننا التحدث عن كيفية التعايش معها وما هي الميزات عند الخدمة.
لنفترض أن sda على s1 مرفوض - وهو أمر شائع.
في حالة gl:
- لا يتم إعادة توزيع نسخة من البيانات الموجودة على القرص المباشر المتبقي في المجموعة تلقائيًا إلى مجموعات أخرى ؛
- حتى يتم استبدال القرص ، تبقى نسخة واحدة فقط من البيانات ؛
- عند استبدال قرص فاشل بقرص جديد ، يتم إجراء النسخ المتماثل من قرص عامل إلى قرص جديد (1 على 1).
هذا يشبه تقديم رف مع عدة RAID-1s. نعم ، مع النسخ المتماثل الثلاثي ، إذا فشل محرك أقراص واحد ، لم يتبقى نسخة واحدة ، ولكن نسختين ، ولكن لا يزال هذا النهج له عيوب خطيرة ، وسأظهر لهم مثالًا جيدًا مع RADOS.
افترض أن فشل sda على S1 (OSD-0) - شيء شائع:
- سيتم إعادة تعيين PGs الموجودة على OSD-0 تلقائيًا إلى OSDs الأخرى بعد 10 دقائق (افتراضي). في مثالنا ، على OSD 1 و 2. إذا كان هناك المزيد من الخوادم ، فعندئذٍ على عدد أكبر من OSD.
- ستقوم PGs التي تخزن النسخة الباقية من البيانات بنسخها تلقائيًا إلى تلك OSDs حيث يتم نقل PGs المستعادة. اتضح النسخ المتماثل بين العديد والعديد ، وليس النسخ من واحد لواحد مثل gl.
- عند إدخال قرص جديد ، بدلاً من قرص مكسور ، سيتم تجميع بعض PGs وفقًا لوزنه في OSD الجديدة وسيتم إعادة توزيع البيانات من OSDs الأخرى.
أعتقد أنه من غير المنطقي شرح المزايا المعمارية لـ RADOS. لا يمكنك الارتعاش عندما تتلقى رسالة تفيد بأن محرك الأقراص فشل. وعندما تأتي للعمل في الصباح ، اكتشف أن جميع النسخ المفقودة قد تم ترميمها بالفعل على عشرات OSDs الأخرى أو في طور المعالجة. على مجموعات كبيرة ، حيث تنتشر مئات PGs عبر مجموعة من الأقراص ، يمكن أن يتم استرداد البيانات من OSD بسرعات أعلى بكثير من سرعة قرص واحد بسبب حقيقة أن عشرات OSDs متورطة (القراءة والكتابة). حسنًا ، لا يجب أن تنسى موازنة الحمل أيضًا.
تحجيم
في هذا السياق ، ربما سأعطي قاعدة التمثال. في مقال عن Ceph ، كتبت بالفعل عن بعض تعقيدات تحجيم RADOS المرتبطة بمفهوم PG. إذا كان لا يزال من الممكن زيادة الزيادة في PG مع نمو الكتلة ، فماذا عن Ceph MDS غير واضح. يعمل CephFS فوق RADOS ويستخدم تجمع منفصل للبيانات الوصفية وعملية خاصة ، خادم بيانات التعريف ceph (MDS) ، لخدمة البيانات الوصفية لنظام الملفات وتنسيق جميع العمليات مع FS. أنا لا أقول أن وجود MDS يضع حداً لقابلية CephFS ، لا ، خاصة أنه يمكنك تشغيل عدة MDS في الوضع النشط النشط. أريد فقط أن أشير إلى أن gl خالٍ من كل هذا معماريًا. ليس لديها نظير PG ، لا شيء مثل MDS. يتطور Gl حقًا بشكل مثالي عن طريق إضافة مجموعات النسخ المتماثل تقريبًا بشكل خطي.
مرة أخرى في الأيام التي سبقت CephFS ، قمنا بتصميم الحل لبيتابايت البيانات ونظرنا في gl. ثم كانت لدينا شكوك حول قابلية التوسع لـ gl واكتشفنا من خلال القائمة البريدية. فيما يلي أحد الإجابات (س: سؤالي):
أنا أستخدم 60 خادمًا لكل منها 26x8 تيرابايت إجمالي أقراص 1560 قرص 16 + 4 EC حجم مع 9PB من المساحة القابلة للاستخدام.
س: هل تستخدم libgfapi أو FUSE أو NFS على جانب العميل؟
أستخدم FUSE ولدي ما يقرب من 1000 عميل.
س: كم عدد الملفات الموجودة في مجلدك؟
س: الملفات أكبر أم صغيرة؟
لدي أكثر من مليون ملف ويتم استخدام٪ 13 من المجموعة مما يجعل متوسط حجم الملف 1 جيجابايت.
الحد الأدنى / الأقصى لحجم الملف هو 100 ميجابايت / 2 جيجابايت. كل يوم 10-20TB يدخل حجم البيانات الجديدة.
س: ما مدى سرعة عمل "ls")؟
عمليات البيانات الوصفية بطيئة كما تتوقع. أحاول ألا أضع أكثر من 2-3 كيلوبايت في الدليل. حالة الاستخدام الخاصة بي للنسخ الاحتياطي / الأرشيف ، لذلك نادرًا ما أقوم بعمليات البيانات الوصفية.
إعادة تسمية الملفات
العودة إلى وظائف التجزئة مرة أخرى. اكتشفنا كيف يتم توجيه ملفات محددة إلى أقراص محددة ، والآن يصبح السؤال ذا صلة ، ولكن ماذا سيحدث عند إعادة تسمية الملفات؟
بعد كل شيء ، إذا قمنا بتغيير اسم الملف ، فستتغير التجزئة نيابة عنه أيضًا ، مما يعني أن مكان هذا الملف على قرص آخر (في نطاق تجزئة مختلف) أو على PG / OSD آخر في حالة RADOS. نعم ، نعتقد بشكل صحيح ، وهنا في نظامين ، كل شيء متعامد مرة أخرى.
في حالة gl ، عند إعادة تسمية ملف ، يتم تشغيل الاسم الجديد من خلال وظيفة التجزئة ، ويتم تعريف لبنة جديدة ويتم إنشاء ارتباط خاص بها إلى الطوب القديم ، حيث يبقى الملف كما هو من قبل. توبوفكا ، أليس كذلك؟ لكي تنتقل البيانات حقًا إلى مكان جديد ، ولم ينقر العميل على الرابط دون داعٍ ، تحتاج إلى القيام بتمرد.
لكن RADOS بشكل عام ليس لديه طريقة لإعادة تسمية الكائنات لمجرد الحاجة إلى حركتها اللاحقة. يقترح استخدام النسخ العادل لإعادة التسمية ، مما يؤدي إلى حركة متزامنة للكائن. و CephFS ، التي تعمل على رأس RADOS ، لديها بطاقة رابحة في جعبتها في شكل تجمع مع البيانات الوصفية و MDS. لا يؤثر تغيير اسم الملف على محتويات الملف في تجمع البيانات.
التكرار 2.5
يحتوي Gl على ميزة رائعة جدًا أود ذكرها بشكل منفصل. يدرك الجميع أن النسخ المتماثل 2 ليس تكوينًا موثوقًا به ، ولكنه مع ذلك يحدث دوريًا لتبريره تمامًا. للحماية ضد الانقسام في الدماغ في مثل هذه المخططات ولضمان تناسق البيانات ، يتيح لك gl إنشاء وحدات تخزين باستخدام النسخة المتماثلة 2 وحكم إضافي. الحكم قابل للتطبيق لتكرار 3 أو أكثر. هذا هو نفس الطوب في المجموعة مثل الأخريين ، إلا أنه في الواقع يخلق فقط بنية ملف من الملفات والأدلة. تكون الملفات الموجودة على مثل هذا الطوب ذات حجم صفري ، ولكن يتم الحفاظ على سماتها الموسعة لنظام الملفات (السمات الموسعة) في حالة متزامنة مع ملفات كاملة الحجم في نفس النسخة المتماثلة. أعتقد أن الفكرة واضحة. أعتقد أن هذه فرصة رائعة.
اللحظة الوحيدة ... يتم تحديد حجم المكان في مجموعة النسخ المتماثل بحجم أصغر لبنة ، وهذا يعني أن الحكم يحتاج إلى انزلاق قرص على الأقل بنفس حجم بقية المجموعة. للقيام بذلك ، من المستحسن إنشاء LV وهمية (رقيقة) وهمية ، أحجام كبيرة ، حتى لا تستخدم قرص حقيقي.
وماذا عن العملاء؟
يتم تنفيذ API الأصلي للنظامين في شكل مكتبات libgfapi (gl) و libcephfs (CephFS). تتوفر أيضًا روابط للغات الشائعة. بشكل عام ، مع المكتبات ، كل شيء جيد بنفس القدر. يدعم NFS-Ganesha في كل مكان المكتبتين كـ FSAL ، وهو أيضًا القاعدة. يدعم Qemu أيضًا واجهة برمجة تطبيقات gl الأصلية عبر libgfapi.
لكن fio (اختبار الإدخال / الإخراج المرن) يدعم libgfapi لفترة طويلة وناجحة ، ولكنه لا يدعم libcephfs. هذا هو زائد ، لأنه استخدام fio أمر رائع حقًا لاختبار gl مباشرة. فقط من خلال مساحة المستخدمين من خلال libgfapi ستحصل على كل شيء يمكن من gl.
ولكن إذا كنا نتحدث عن نظام ملفات POSIX وكيفية تركيبه ، فيمكن لـ gl تقديم عميل FUSE فقط ، وتطبيق CephFS في نواة المنبع. من الواضح أنه في وحدة kernel ، يمكنك القيام بمثل هذه الحيلة التي ستظهر FUSE أداءً أفضل. ولكن من الناحية العملية ، فإن FUSE دائمًا ما يكون عاملاً في تبديل السياق. لقد رأيت شخصياً أكثر من مرة كيف قامت FUSE بتثبيت خادم مزدوج المقبس مع CS فقط.
قال لينوس بطريقة ما:
نظام ملفات المستخدمين؟ المشكلة هناك. لقد كان دائما. الأشخاص الذين يعتقدون أن أنظمة ملفات مساحة المستخدمين تكون واقعية لأي شيء ولكن الألعاب مضللة.
يعتقد مطورو Gl ، على العكس من ذلك ، أن FUSE رائع. يقال أن هذا يعطي مرونة أكبر وينفصل عن إصدارات النواة. بالنسبة لي ، يستخدمون FUSE لأن gl ليس عن السرعة. بطريقة ما هو مكتوب - حسنًا ، إنه أمر طبيعي ، والقلق من التنفيذ في النواة أمر غريب حقًا.
الأداء
لن تكون هناك مقارنات).
هذا معقد للغاية. من الصعب جدًا إجراء اختبار موضوعي ، حتى في حالة إعداد مماثل. على أي حال ، سيكون هناك شخص في التعليقات سيعطي 100500 معلمة "تسرع" أحد الأنظمة وتقول إن الاختبارات هراء. لذلك ، إذا كنت مهتما ، اختبر نفسك ، من فضلك.
الخلاصة
يعد RADOS و CephFS ، على وجه الخصوص ، حلاً أكثر تعقيدًا من حيث الفهم والإعداد والصيانة.
لكن شخصياً ، أحب هندسة RADOS وتعمل على CephFS أكثر من GlusterFS. المزيد من المقابض (PG ، وزن OSD ، هرمية CRUSH ، إلخ) ، البيانات الوصفية لـ CephFS تزيد من التعقيد ، ولكنها تعطي المزيد من المرونة وتجعل هذا الحل أكثر فعالية ، في رأيي.
Ceph هو أفضل بكثير لمعايير SDS الحالية ويبدو لي أكثر واعدة. ولكن هذا رأيي ، ما رأيك؟