ترجمة معماريات الشبكات العصبيةاكتسبت خوارزميات الشبكات العصبية العميقة شعبية كبيرة اليوم ، والتي يتم ضمانها إلى حد كبير من خلال الهندسة المعمارية المدروسة جيدًا. دعونا نلقي نظرة على تاريخ تطورهم على مدى السنوات القليلة الماضية. إذا كنت مهتمًا بتحليل أعمق ، فارجع إلى
هذا العمل .
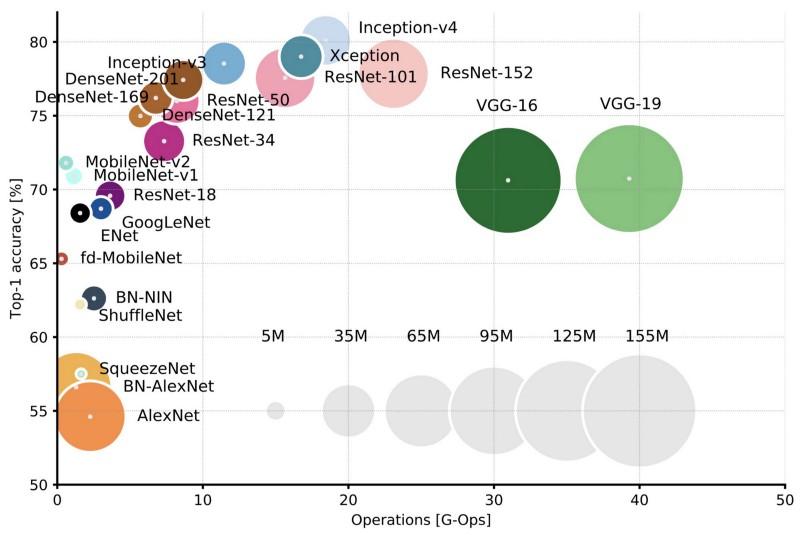 مقارنة بين البنيات الشعبية لدقة أعلى محصول واحد وعدد العمليات المطلوبة لمرور مباشر واحد. مزيد من التفاصيل هنا .
مقارنة بين البنيات الشعبية لدقة أعلى محصول واحد وعدد العمليات المطلوبة لمرور مباشر واحد. مزيد من التفاصيل هنا .لينيت 5
في عام 1994 ، تم تطوير واحدة من الشبكات العصبية التلافيفية الأولى ، والتي أرست الأساس للتعلم العميق. هذا العمل الرائد الذي قام به Yann LeCun ، بعد العديد من التكرارات الناجحة منذ عام 1988 ، أطلق عليه اسم
LeNet5 !

أصبحت بنية LeNet5 أساسية للتعلم العميق ، خاصة من حيث توزيع خصائص الصورة في جميع أنحاء الصورة. يسمح التلافيق مع معلمات التعلم باستخدام العديد من المعلمات لاستخراج نفس الخصائص بكفاءة من أماكن مختلفة. في تلك السنوات ، لم تكن هناك بطاقات فيديو يمكنها تسريع عملية التعلم ، وحتى المعالجات المركزية كانت بطيئة. لذلك ، كانت الميزة الرئيسية للبنية هي القدرة على حفظ المعلمات ونتائج الحساب ، على عكس استخدام كل بكسل كبيانات إدخال منفصلة لشبكة عصبية كبيرة متعددة الطبقات. في LeNet5 ، لا يتم استخدام وحدات البكسل في الطبقة الأولى ، لأن الصور مرتبطة ارتباطًا مكانيًا بقوة ، لذا فإن استخدام وحدات البكسل الفردية كخصائص إدخال لن يسمح لك بالاستفادة من هذه الارتباطات.
ميزات LeNet5:
- شبكة عصبية تلافيفية تستخدم سلسلة من ثلاث طبقات: طبقات الالتفاف ، طبقات التجميع والطبقات غير الخطية -> منذ نشر عمل Lekun ، ربما تكون هذه إحدى السمات الرئيسية للتعلم العميق فيما يتعلق بالصور.
- يستخدم الالتفاف لاستعادة الخصائص المكانية.
- الاختزال الجزئي باستخدام متوسط الخريطة المكانية.
- اللاخطية في شكل المماس الزائدي أو السيني.
- المصنف النهائي على شكل شبكة عصبية متعددة الطبقات (MLP).
- تعمل المصفوفة المتفرقة للربط بين الطبقات على تقليل كمية الحساب.
شكلت هذه الشبكة العصبية أساس العديد من البنيات اللاحقة وألهمت العديد من الباحثين.
التنمية
من عام 1998 إلى عام 2010 ، كانت الشبكات العصبية في حالة حضانة. لم يلاحظ معظم الأشخاص قدراتهم المتنامية ، على الرغم من أن العديد من المطورين قاموا بصقل خوارزمياتهم تدريجيًا. بفضل ذروة كاميرات الهواتف المحمولة ورخص الكاميرات الرقمية ، أصبح لدينا المزيد والمزيد من بيانات التدريب المتاحة لنا. في الوقت نفسه ، نمت قدرات الحوسبة ، وأصبحت المعالجات أكثر قوة ، وتحولت بطاقات الفيديو إلى أداة الحوسبة الرئيسية. سمحت كل هذه العمليات بتطوير الشبكات العصبية ، وإن كان ذلك ببطء. تزايد الاهتمام بالمهام التي يمكن حلها بمساعدة الشبكات العصبية ، وأخيرًا أصبح الوضع واضحًا ...
دان سيريسان نت
في عام 2010 ، نشر Dan Claudiu Ciresan و Jurgen Schmidhuber أحد الأوصاف الأولى لتنفيذ
الشبكات العصبية GPU . احتوى عملهم على التنفيذ المباشر والعكسي لشبكة عصبية من 9 طبقات على
NVIDIA GTX 280 .
Alexnet
في عام 2012 ، نشر Alexei Krizhevsky
AlexNet ، وهي نسخة متعمقة وموسعة من LeNet ، والتي فازت بهامش كبير في مسابقة ImageNet.
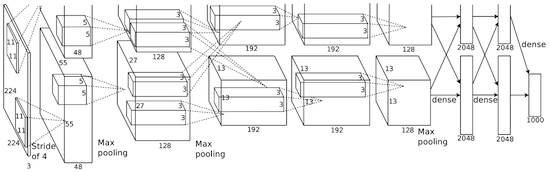
في AlexNet ، يتم تحجيم نتائج حسابات LeNet إلى شبكة عصبية أكبر بكثير ، قادرة على دراسة الأشياء الأكثر تعقيدًا وتسلسلها الهرمي. ميزات هذا الحل:
- استخدام وحدات التصحيح الخطي (ReLU) باعتبارها غير خطية.
- استخدام تقنيات تجاهل للتجاهل الانتقائي للخلايا العصبية الفردية أثناء التدريب ، والذي يتجنب التدريب المفرط للنموذج.
- التداخل الأقصى للتجنب ، والذي يتجنب آثار متوسط معدل التجميع.
- استخدام NVIDIA GTX 580 لتسريع التعلم.
بحلول ذلك الوقت ، ازداد عدد النوى في بطاقات الفيديو بشكل كبير ، مما سمح لهم بتقليل وقت التدريب بحوالي 10 مرات ، ونتيجة لذلك أصبح من الممكن استخدام مجموعات بيانات وصور أكبر بكثير.
أطلق نجاح AlexNet ثورة صغيرة ، وتحولت الشبكات العصبية التلافيفية إلى فرس من التعلم العميق - يعني هذا المصطلح الآن "شبكات عصبية كبيرة يمكنها حل المشكلات المفيدة".
إفراط
في ديسمبر 2013 ، نشر مختبر جامعة نيويورك في Jan Lekun وصفًا لـ
Overfeat ، وهو نوع من AlexNet. أيضا ، وصف المقال المربعات المحيطة المدربة ، وبعد ذلك تم نشر العديد من الأعمال الأخرى حول هذا الموضوع. نعتقد أنه من الأفضل تعلم كيفية تقسيم الأشياء ، بدلاً من استخدام المربعات المحيطة الاصطناعية.
Vgg
في شبكات
VGG التي تم تطويرها في أكسفورد ، في كل طبقة
تلافيفية ، لأول مرة ، تم استخدام مرشحات 3x3 ، وحتى تم دمج هذه الطبقات في سلسلة من الالتواءات.
هذا يتناقض مع المبادئ المنصوص عليها في LeNet ، والتي بموجبها تم استخدام تلافيف كبيرة لاستخراج نفس خصائص الصورة. بدلاً من مرشحات 9x9 و 11x11 المستخدمة في AlexNet ، بدأ استخدام مرشحات أصغر بكثير ، قريبة بشكل خطير من الالتواءات 1x1 ، والتي حاول مؤلفو LeNet تجنبها ، على الأقل في الطبقات الأولى من الشبكة. لكن الميزة الكبرى لـ VGG كانت اكتشاف أن العديد من اللفات 3x3 مجتمعة في تسلسل يمكن أن تحاكي الحقول الاستقبالية الأكبر ، على سبيل المثال ، 5x5 أو 7x7. سيتم استخدام هذه الأفكار لاحقًا في بنيتي التأسيس و ResNet.
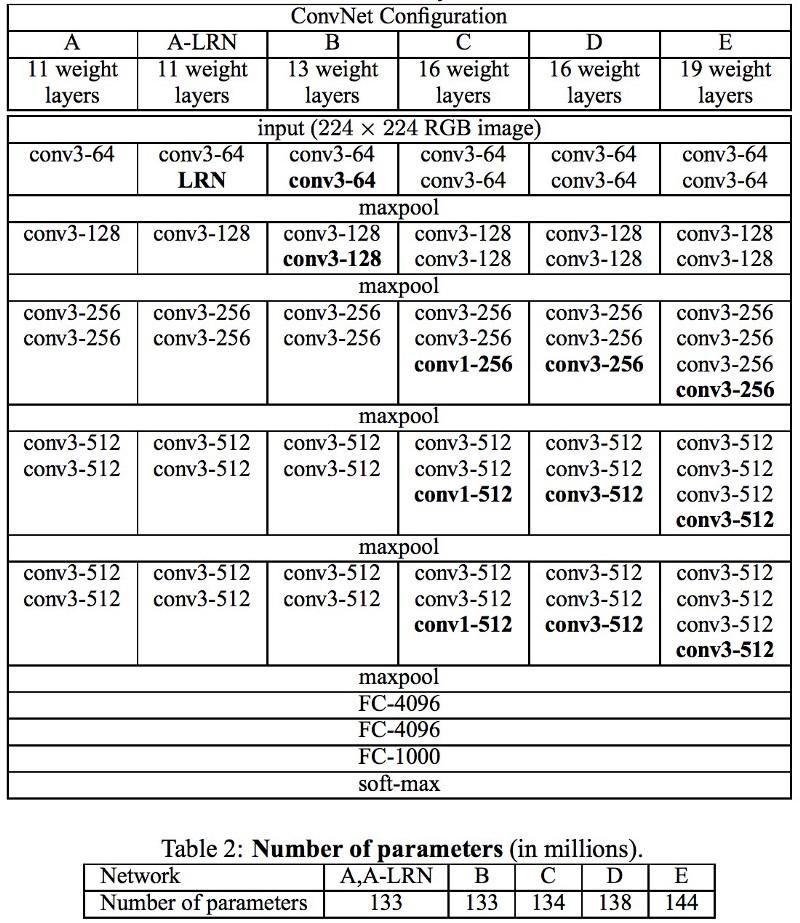
تستخدم شبكات VGG طبقات تلافيفية متعددة 3x3 لتمثيل الخصائص المعقدة. انتبه إلى الكتل 3 و 4 و 5 في VGG-E: لاستخراج خصائص أكثر تعقيدًا ودمجها ، يتم استخدام تسلسلات المرشح 256 × 256 و 512 × 512 3 × 3. هذا يعادل تصنيف تلافيفي كبير 512 × 512 بثلاث طبقات! هذا يعطينا عددًا كبيرًا من المعلمات وقدرات التعلم الممتازة. ولكن كان من الصعب تعلم مثل هذه الشبكات ؛ كان عليّ تقسيمها إلى شبكات أصغر ، بإضافة طبقات واحدة تلو الأخرى. كان السبب هو عدم وجود طرق فعالة لتنظيم النماذج أو بعض الطرق لتحديد مساحة بحث كبيرة ، والتي يتم الترويج لها بواسطة العديد من المعلمات.
تستخدم VGG في العديد من الطبقات عددًا كبيرًا من الخصائص ، لذلك كان التدريب
مكلفًا حسابيًا . يمكن تقليل الحمل عن طريق تقليل عدد الخصائص ، كما هو الحال في طبقات عنق الزجاجة في بنية Inception.
شبكة في شبكة
تعتمد بنية
Network-in-network (NiN) على فكرة بسيطة: استخدام تلافي 1 × 1 لزيادة اندماج الخصائص في الطبقات التلافيفية.
في NiN ، بعد كل الالتفاف ، يتم استخدام طبقات MLP المكانية لدمج الخصائص بشكل أفضل قبل التغذية إلى الطبقة التالية. قد يبدو أن استخدام اللفات 1x1 يتعارض مع مبادئ LeNet الأصلية ، ولكنه في الواقع يسمح بدمج الخصائص بشكل أفضل من حشو الطبقات التلافيفية. يختلف هذا النهج عن استخدام البكسلات العارية كمدخل للطبقة التالية. في هذه الحالة ، يتم استخدام اللفات 1x1 للتركيبة المكانية للخصائص بعد الالتفاف في إطار خرائط الخصائص ، بحيث يمكنك استخدام عدد أقل بكثير من المعلمات الشائعة لجميع وحدات البكسل لهذه الخصائص!
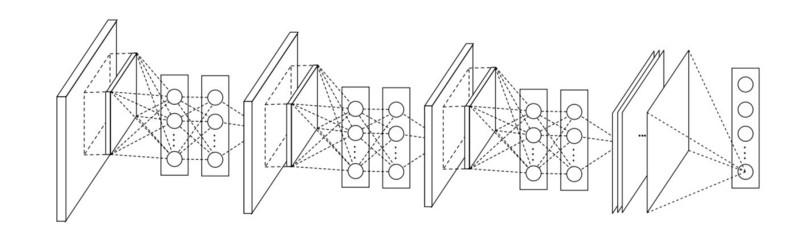
يمكن أن يزيد MLP بشكل كبير من فعالية الطبقات التلافيفية الفردية من خلال دمجها في مجموعات أكثر تعقيدًا. تم استخدام هذه الفكرة لاحقًا في بنى أخرى ، مثل ResNet و Inception ومتغيراتها.
GoogLeNet و Inception
يقلق Google Christian Szegedy من تخفيض الحسابات في الشبكات العصبية العميقة ، ونتيجة لذلك أنشأ
GoogLeNet ، أول بنية Inception .
بحلول خريف عام 2014 ، أصبحت نماذج التعلم العميق مفيدة للغاية في تصنيف محتوى الصور والإطارات من مقاطع الفيديو. لقد أدرك العديد من المشككين فوائد التعلم العميق والشبكات العصبية ، وأصبح عمالقة الإنترنت ، بما في ذلك Google ، مهتمين للغاية بنشر شبكات فعالة وكبيرة على قدرات الخادم الخاصة بهم.
كان كريستيان يبحث عن طرق لتقليل الحمل الحسابي في الشبكات العصبية ، وتحقيق أعلى أداء (على سبيل المثال ، في ImageNet). أو الحفاظ على مقدار الحساب ، ولكن مع زيادة الإنتاجية.
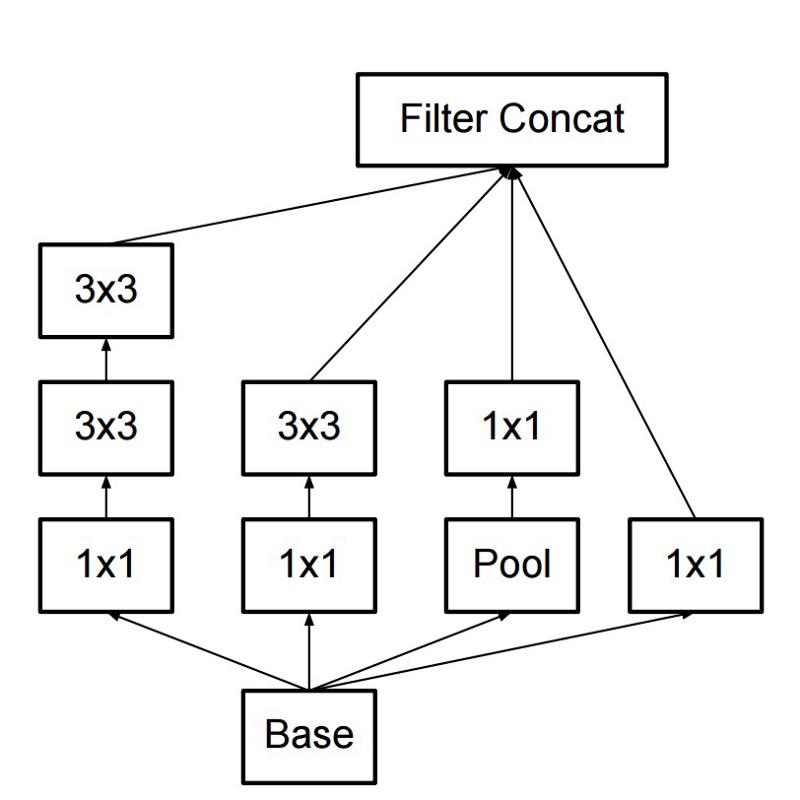
ونتيجة لذلك ، أنشأ الأمر وحدة بداية:

للوهلة الأولى ، هذه مجموعة متوازية من المرشحات التلافيفية 1x1 و 3 x3 و 5 x5. ولكن كان أبرزها استخدام كتل الالتفاف 1x1 (NiN) لتقليل عدد الخصائص قبل العرض في الكتل المتوازية "باهظة الثمن". عادة ما يسمى هذا الجزء اختناق ، يتم وصفه بمزيد من التفصيل في الفصل التالي.
يستخدم GoogLeNet جذعًا بدون وحدات Inception كطبقة أولية ، ويستخدم أيضًا متوسط تجميع ومصنف softmax مشابه لـ NiN. يقوم هذا المصنف بتنفيذ عدد قليل جدًا من العمليات مقارنة بـ AlexNet و VGG. كما ساعد في إنشاء
بنية شبكة عصبية فعالة للغاية .
طبقة عنق الزجاجة
تقلل هذه الطبقة من عدد الخصائص (وبالتالي العمليات) في كل طبقة ، بحيث يمكن الحفاظ على سرعة الحصول على النتيجة على مستوى عال. قبل نقل البيانات إلى وحدات تلافيفية "باهظة الثمن" ، يتم تقليل عدد الخصائص ، على سبيل المثال ، 4 مرات. هذا يقلل بشكل كبير من كمية الحساب ، مما جعل العمارة شائعة.
دعونا معرفة ذلك. لنفترض أن لدينا 256 خاصية عند الإدخال و 256 عند الإخراج ، ودع الطبقة الداخلية تؤدي تلافيف 3x3 فقط. نحصل على 256x256x3x3 الالتواءات (589000 عمليات مضاعفة التراكم ، أي عمليات MAC). قد يتجاوز هذا متطلبات السرعة الحسابية ؛ لنفترض أن طبقة تتم معالجتها في 0.5 مللي ثانية على خادم Google. ثم قلل عدد خصائص الطي إلى 64 (256/4). في هذه الحالة ، نقوم أولاً بإجراء تحويل 1x1 من 256 -> 64 ، ثم تحويل 64 مرة أخرى في جميع الفروع Inception ، ثم مرة أخرى تطبيق التفاف 1x1 من 64 -> 256 خاصية. عدد العمليات:
- 256 × 64 × 1 × 1 = 16000
- 64 × 64 × 3 × 3 = 36000
- 64 × 256 × 1 × 1 = 16000
فقط حوالي 70،000 ، قلل عدد العمليات بما يقرب من 10 مرات! لكن في الوقت نفسه ، لم نفقد التعميم في هذه الطبقة. أظهرت طبقات عنق الزجاجة أداءً ممتازًا في مجموعة بيانات ImageNet ، وقد تم استخدامها في بنى لاحقة مثل ResNet. سبب نجاحها هو أن خصائص الإدخال مترابطة ، مما يعني أنه يمكنك التخلص من التكرار من خلال الجمع بين الخصائص بشكل صحيح مع لفات 1x1. وبعد الطي بخصائص أقل ، يمكنك نشرها مرة أخرى في تركيبة مهمة في الطبقة التالية.
البداية V3 (و V2)
أثبت كريستيان وفريقه أنهم باحثون فعالون للغاية. في فبراير 2015 ، تم تقديم بنية
Inception-تطبيع الدفعة كإصدار ثانٍ من
Inception . يحسب التسوية المجمعة المتوسط والانحراف المعياري لجميع خرائط توزيع الممتلكات في طبقة المخرجات ، ويعيد استجاباتهم بهذه القيم. هذا يتوافق مع "تبييض" البيانات ، أي أن استجابات جميع الخرائط العصبية تقع في نفس النطاق وبمتوسط صفري. هذا النهج يجعل التعلم أسهل ، لأن الطبقة التالية ليست مطلوبة لتذكر إزاحة بيانات الإدخال ويمكنها فقط البحث عن أفضل مجموعات من الخصائص.
في ديسمبر 2015 ، تم
إصدار إصدار جديد من وحدات Inception والبنية المقابلة . تشرح مقالة المؤلف بشكل أفضل بنية GoogLeNet الأصلية ، والتي تخبر المزيد عن القرارات المتخذة. الأفكار الرئيسية:
- تعظيم تدفق المعلومات في الشبكة بسبب التوازن الدقيق بين عمقها وعرضها. قبل كل تجمع ، تزيد خرائط العقارات.
- مع زيادة العمق ، يزداد عدد الخصائص أو عرض الطبقة بشكل منهجي أيضًا.
- يزداد عرض كل طبقة لزيادة تركيبة الخصائص قبل الطبقة التالية.
- إلى أقصى حد ممكن ، يتم استخدام لفائف 3x3 فقط. بالنظر إلى أن مرشحات 5x5 و 7x7 يمكن أن تتحلل باستخدام 3x3 متعددة
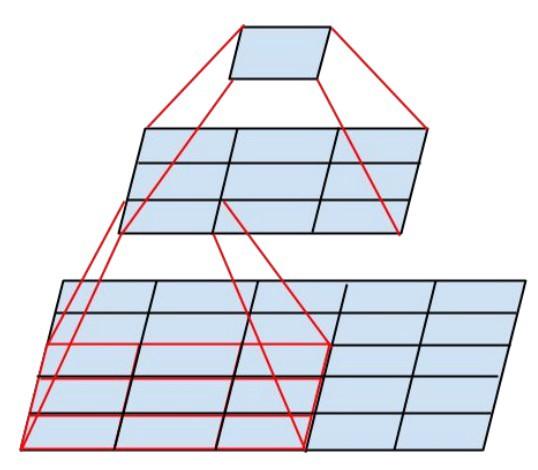
تبدو وحدة Inception الجديدة كما يلي:
- يمكن أيضًا أن تتحلل المرشحات باستخدام تلافيف سلس في وحدات أكثر تعقيدًا:

- يمكن أن تقلل وحدات Inception من حجم البيانات باستخدام التجميع أثناء حسابات Inception. هذا مشابه لأداء الالتفاف بخطوات متوازية مع طبقة تجميع بسيطة:

يستخدم Inception طبقة التجميع مع softmax كمصنف نهائي.
إعادة الشبكة
في ديسمبر 2015 ، في نفس الوقت تقريبًا الذي تم فيه تقديم بنية Inception v3 ، حدثت ثورة - نشروا
ResNet . أنه يحتوي على أفكار بسيطة: تقديم إخراج طبقتين تلافيفية ناجحة وتجاوز الإدخال للطبقة التالية!

وقد تم بالفعل اقتراح مثل هذه الأفكار ، على سبيل المثال ،
هنا . ولكن في هذه الحالة ، يتجاوز المؤلفون طبقتين ويطبقون النهج على نطاق واسع. لا يؤدي تجاوز طبقة واحدة إلى فائدة كبيرة ، وتجاوز طبقتين هو اكتشاف رئيسي. يمكن اعتبار هذا كمصنف صغير ، كشبكة في الشبكة!
كما كان أول مثال على الإطلاق لتدريب شبكة تتكون من عدة مئات وحتى آلاف الطبقات.
استخدم ResNet متعدد الطبقات طبقة عنق الزجاجة مماثلة لتلك المستخدمة في Inception:

تقلل هذه الطبقة من عدد الخصائص في كل طبقة ، أولاً باستخدام لفائف 1x1 مع إخراج أقل (عادة ربع المدخلات) ، ثم طبقة 3x3 ، ثم لف 1x1 مرة أخرى في عدد أكبر من الخصائص. كما هو الحال في وحدات Inception ، فإن هذا يوفر الموارد الحسابية مع الحفاظ على ثروة من تركيبات الملكية. قارن مع السيقان الأكثر تعقيدًا والأقل وضوحًا في Inception V3 و V4.
يستخدم ResNet طبقة تجميع مع softmax كمصنف نهائي.
كل يوم ، تظهر معلومات إضافية حول بنية ResNet:
- يمكن اعتباره نظامًا للوحدات المتوازية والمتسلسلة في وقت واحد: في العديد من الوحدات ، تأتي إشارة inout بالتوازي ، ويتم توصيل إشارات الخرج لكل وحدة في سلسلة.
- يمكن اعتبار ResNet عدة مجموعات من الوحدات المتوازية أو التسلسلية .
- اتضح أن ResNet تعمل عادةً مع كتل عمق صغيرة نسبيًا من 20-30 طبقة تعمل بالتوازي ، بدلاً من العمل بالتسلسل على طول الشبكة بالكامل.
- نظرًا لأن إشارة الخرج تعود ويتم تغذيتها كمدخل ، كما هو الحال في RNN ، يمكن اعتبار ResNet نموذجًا محسنًا وقويًا للقشرة الدماغية .
بداية V4
تفوق كريستيان وفريقه مرة أخرى بإصدار
جديد من Inception .
وحدة البداية التالية الجذعية هي نفسها في Inception V3:

في هذه الحالة ، يتم دمج وحدة Inception النمطية مع وحدة ResNet:

تحولت هذه العمارة ، حسب ذوقي ، إلى أكثر تعقيدًا وأقل أناقة ومليئة أيضًا بحلول إرشادية مبهمة. من الصعب فهم سبب اتخاذ المؤلفين لهذه القرارات أو تلك ، ومن الصعب أيضًا منحهم أي نوع من التقييم.
لذلك ، جائزة شبكة عصبية نظيفة وبسيطة ، سهلة الفهم والتعديل ، تذهب إلى ResNet.
عصارة
نشرت
SqueezeNet مؤخرا. هذا هو طبعة جديدة بطريقة جديدة للعديد من المفاهيم من ResNet و Inception. أظهر المؤلفون أن تحسين البنية يقلل من حجم الشبكة وعدد المعلمات بدون خوارزميات ضغط معقدة.
ENet
يتم دمج جميع ميزات الهياكل الحديثة في شبكة فعالة للغاية ومدمجة ، وذلك باستخدام عدد قليل جدًا من المعلمات وقوة الحوسبة ، ولكن في نفس الوقت تعطي نتائج ممتازة. كان يسمى العمارة
ENet ، تم تطويره من قبل Adam Paszke (
Adam Paszke ). على سبيل المثال ، استخدمناه لوضع علامات دقيقة للغاية على الأشياء على الشاشة وتحليل المشاهد.
بعض الأمثلة عن Enet . لا تتعلق مقاطع الفيديو هذه
بمجموعة بيانات التدريب .
هنا يمكنك العثور على التفاصيل الفنية لـ ENet. إنها شبكة تعتمد على التشفير وفك الشفرة. تم إنشاء برنامج التشفير وفقًا لنظام تصنيف CNN المعتاد ، كما أن أداة فك التشفير عبارة عن netowrk اختزال مصمم للتجزئة عن طريق توزيع الفئات إلى الصورة الأصلية بالحجم. لتجزئة الصورة ، تم استخدام الشبكات العصبية فقط ، ولا توجد خوارزميات أخرى.
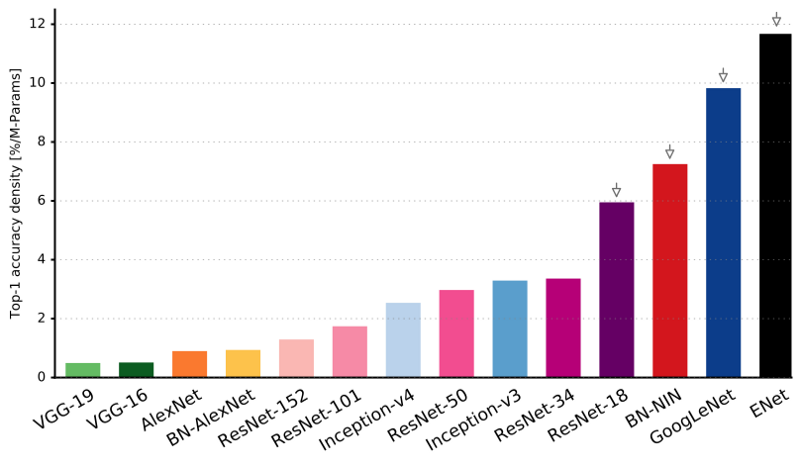
كما ترى ، تتمتع ENet بأعلى دقة محددة مقارنة بجميع الشبكات العصبية الأخرى.
تم تصميم ENet لاستخدام أقل عدد ممكن من الموارد منذ البداية. ونتيجة لذلك ، يشغل المشفر ومفكك التشفير معًا 0.7 ميغابايت فقط بدقة fp16. وبهذا الحجم الصغير ، فإن ENet ليست أقل من دقة التجزئة أو تفوقها في حلول الشبكات العصبية البحتة الأخرى.
تحليل الوحدة
نشر تقييم منهجي لوحدات CNN. اتضح أنها مفيدة:
- استخدم ELU غير الخطي بدون تسوية الدفعة (الدفعة) أو ReLU مع التطبيع.
- تطبيق التحول المُعلم لمساحة ألوان RGB.
- استخدم سياسة اضمحلال معدل التعلم الخطي.
- استخدم مجموع طبقة التجميع الوسطى والقصوى.
- استخدم حزمة صغيرة 128 أو 256. إذا كان هذا كثيرًا لبطاقة الفيديو الخاصة بك ، فقم بتقليل سرعة التعلم بما يتناسب مع حجم الحزمة.
- استخدم طبقات متصلة بالكامل كطبقات تلافيفية ومتوسط توقعات لإعطاء الحل النهائي.
- إذا قمت بزيادة حجم مجموعة بيانات التدريب ، فتأكد من أنك لم تصل إلى مرحلة التدريب. نظافة البيانات أكثر أهمية من الحجم.
- إذا لم تتمكن من زيادة حجم صورة الإدخال ، فقم بتقليل الخطوة في الطبقات اللاحقة ، فسيكون التأثير هو نفسه تقريبًا.
- إذا كانت شبكتك ذات بنية معقدة ومعقدة للغاية ، كما هو الحال في GoogLeNet ، فقم بتعديلها بحذر.
Xception
قدمت
Xception بنية أبسط وأكثر أناقة في وحدة Inception ، والتي لا تقل كفاءة عن ResNet و Inception V4.
هذا ما تبدو عليه وحدة Xception:
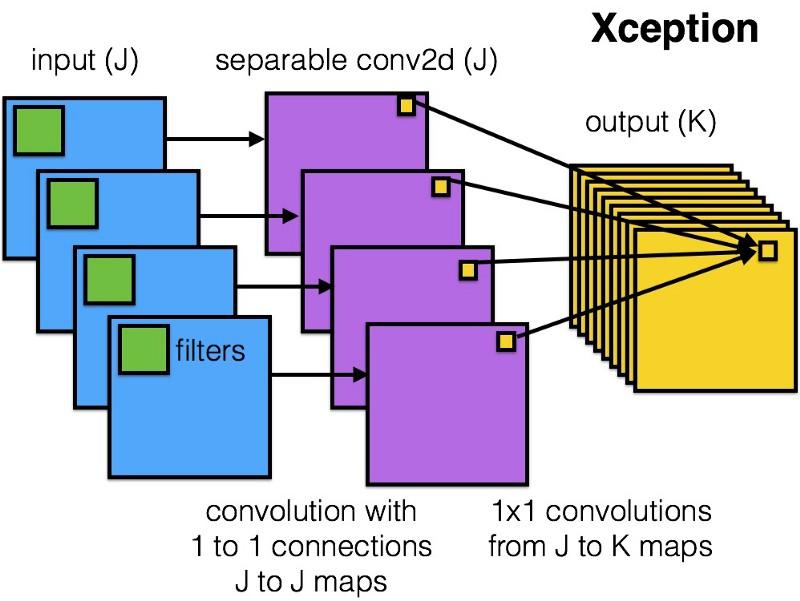
أي شخص سيحب هذه الشبكة بسبب بساطة وأناقة هندسته المعمارية:

يحتوي على 36 خطوة التفاف ، وهذا مشابه لـ ResNet-34. في نفس الوقت ، النموذج والرمز بسيطان ، كما هو الحال في ResNet ، وأكثر متعة بكثير من Inception V4.
يتوفر تطبيق torch7 لهذه الشبكة
هنا ، بينما يتوفر تطبيق Keras / TF هنا.
الغريب ، استلهم مؤلفو بنية Xception الحديثة أيضًا من
عملنا على الفلاتر التلافيفية المنفصلة.
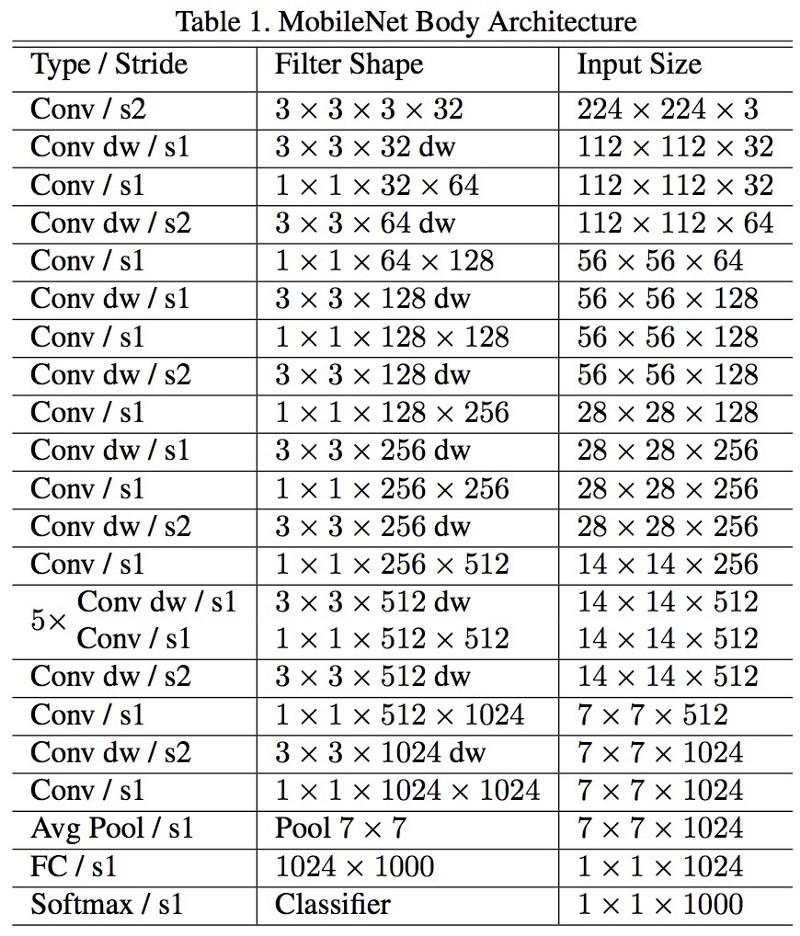
شبكات المحمول
تم إصدار البنية الجديدة لـ M
obileNets في أبريل 2017. لتقليل عدد المعلمات ، يستخدم تلافيف قابلة للفصل ، كما هو الحال في Xception. ويذكر أيضًا في العمل أن المؤلفين تمكنوا من تقليل عدد المعلمات بشكل كبير: حوالي النصف في حالة FaceNet. :
, 1 (batch of 1) Titan Xp. :
- resnet18: 0,002871
- alexnet: 0,001003
- vgg16: 0,001698
- squeezenet: 0,002725
- mobilenet: 0,033251
! , .
FractalNet , ImageNet ResNet.
, . , .
, , , , ? , .
.
, . , .
, .
.