
مرحبا يا هبر! قبل عامين
كتبنا عن كيفية التحول إلى 7.0 بيزو فلبيني ووفرنا مليون دولار. في ملف تعريف التحميل الخاص بنا ، تبين أن الإصدار الجديد فعال مرتين في استخدام وحدة المعالجة المركزية: الحمل الذي استخدمناه لخدمة 600 خادم ، بعد أن بدأ النقل في تقديم ~ 300. ونتيجة لذلك ، كان لدينا احتياطي من القدرات لمدة عامين.
لكن Badoo ينمو. يتزايد عدد المستخدمين النشطين باستمرار. نحن نعمل على تحسين وظائفنا وتطويرها ، والتي بفضلها يقضي المستخدمون المزيد والمزيد من الوقت في التطبيق. وهذا ، بدوره ، ينعكس في عدد الطلبات ، التي زادت خلال العامين الماضيين بمقدار 2.5-2 مرة.
وجدنا أنفسنا في موقف تم فيه تحقيق مكاسب مضاعفة في الأداء بأكثر من زيادة مضاعفة في الطلبات ، وبدأنا مرة أخرى في الاقتراب من حدود مجموعتنا. في صميم PHP ، من المتوقع مرة أخرى
تحسينات مفيدة (JIT ، التحميل المسبق) ، ولكن يتم التخطيط لها فقط لـ PHP 7.4 ، وسيتم إصدار هذا الإصدار في موعد لا يتجاوز العام. لذلك ، لا يمكن تكرار خدعة الانتقال الآن - تحتاج إلى تحسين رمز التطبيق نفسه.
بموجب هذا الخفض ، سأخبرك كيف نتعامل مع مثل هذه المهام ، والأدوات التي نستخدمها ، وسأعطي أمثلة على التحسينات والأفكار والأساليب التي نطبقها والتي ساعدتنا في عصرنا.
لماذا التحسين
أسهل طريقة وأكثرها وضوحًا لحل مشكلة الأداء هي إضافة الحديد. إذا تم تشغيل الرمز الخاص بك على نفس الخادم ، فإن إضافة رمز آخر سيضاعف أداء نظامك. عند نقل هذه التكاليف إلى وقت عمل المطور ، نسأل أنفسنا: هل سيكون قادرًا على الحصول على زيادة مضاعفة في الإنتاجية خلال هذا الوقت بسبب التحسينات؟ ربما نعم ، ولكن ربما لا: يعتمد ذلك على مدى عمل النظام على النحو الأمثل ومدى جودة المطور. من ناحية أخرى ، سيظل الخادم الذي تم شراؤه ملكًا للشركة ، ولن يتم إرجاع الوقت المنقضي.
اتضح أنه في الأحجام الصغيرة ، غالبًا ما يكون الحل الصحيح هو إضافة الحديد.
لكن خذ موقفنا. الآن ، بعد أن تم تعويض المكاسب من التحول إلى PHP 7.0 من خلال النمو في النشاط وعدد المستخدمين ، لدينا مرة أخرى 600 خادم يخدم طلبات تطبيق PHP. من أجل زيادة السعة مرة ونصف ، نحتاج إلى إضافة 300 خادم.
خذ لحساب متوسط تكلفة الخادم - 4000 دولار. 300 * 4000 = 1،200،000 دولار - تكلفة زيادة السعة مرة ونصف.
هذا ، في ظروفنا ، يمكننا استثمار قدر كبير من وقت العمل في تحسين النظام ، وسيظل أكثر ربحية من شراء الحديد.
تخطيط القدرات
قبل القيام بأي شيء ، من المهم أن تفهم ما إذا كانت هناك مشكلة. إذا لم تكن هناك ، فمن الجدير محاولة التنبؤ بموعد ظهورها. تسمى هذه العملية تخطيط القدرات.
وقت الاستجابة هو مؤشر ملموس لوجود مشاكل في الأداء. بعد كل شيء ، في الواقع ، لا يهم إذا تم تحميل وحدة المعالجة المركزية (أو موارد أخرى) بنسبة 6 ٪ أو 146 ٪: إذا تلقى العميل خدمة بالجودة المطلوبة في وقت مرضٍ ، فإن كل شيء يعمل بشكل جيد.
عيب التركيز على وقت الاستجابة هو أنه عادة ما يبدأ في الزيادة فقط عندما تظهر المشكلة بالفعل. إذا لم يكن الأمر كذلك بعد ، فمن الصعب التنبؤ بمظهره. بالإضافة إلى ذلك ، يعكس وقت الاستجابة نتائج تأثير جميع العوامل (خدمات الكبح ، والشبكة ، ومحركات الأقراص ، وما إلى ذلك) ولا يوفر فهمًا لأسباب المشكلات.
في حالتنا ، عادة ما تكون وحدة المعالجة المركزية هي عنق الزجاجة ، لذلك عند التخطيط لحجم وأداء المجموعات ، فإننا نولي اهتمامًا في المقام الأول للمقاييس المرتبطة باستخدامها. نجمع استخدام وحدة المعالجة المركزية من جميع أجهزتنا وننشئ الرسوم البيانية بمتوسط القيمة ، المتوسط ، 75 و 95 في المائة:
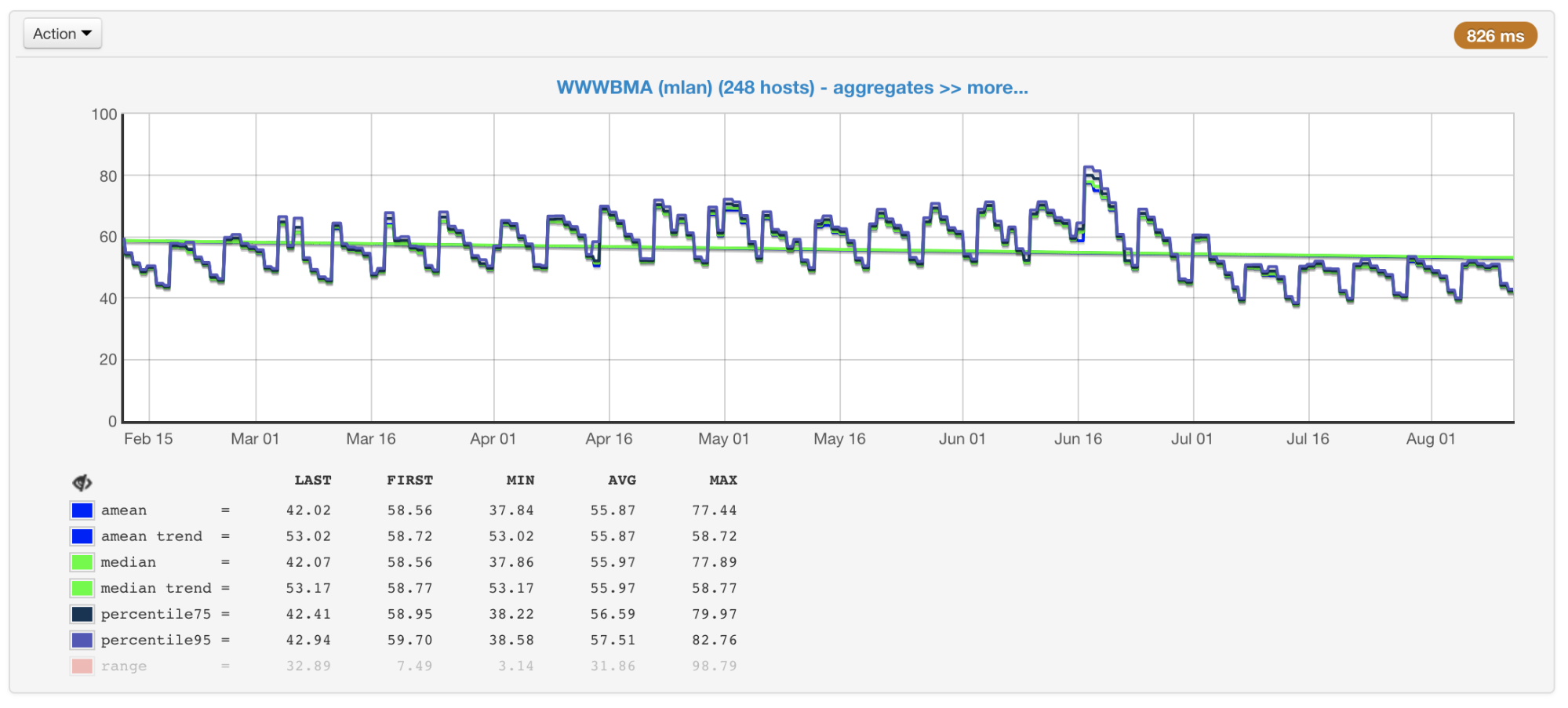 استخدام وحدة المعالجة المركزية لآلات الكتلة في المئة: متوسط ، متوسط ، مئوي
استخدام وحدة المعالجة المركزية لآلات الكتلة في المئة: متوسط ، متوسط ، مئويهناك مئات الآلات في مجموعاتنا التي تمت إضافتها هناك لسنوات عديدة. وهي مختلفة في التكوين والأداء (الكتلة ليست متجانسة). يأخذ موازننا هذا في الاعتبار (
المقالة والفيديو ) ويحمل الآلات وفقًا لقدراتها. من أجل التحكم في هذه العملية ، لدينا أيضًا جدول زمني للحد الأقصى والحد الأدنى من الآلات المحملة.
 أكثر آلات الكتلة تحميلا وأقلها
أكثر آلات الكتلة تحميلا وأقلهاإذا نظرت إلى هذه الرسوم البيانية (أو فقط عند إخراج الأمر العلوي) ورأيت حمل وحدة المعالجة المركزية بنسبة 50٪ ، فقد تعتقد أنه لا يزال لدينا هامش لزيادة مضاعفة في الحمل. ولكن في الواقع هذا ليس هو الحال عادة. وها هو السبب.
خيوط مفرطة
تخيل قلبًا واحدًا دون تضخم. نقوم بتحميله بخيط واحد مرتبط بوحدة المعالجة المركزية. سنرى 100٪ تحميل في الأعلى.
الآن قم بتشغيل hyperreading على هذه النواة وحمّلها بنفس الطريقة تمامًا. في الجزء العلوي ، سنرى بالفعل نطين منطقيين ، وسيكون إجمالي الحمل 50٪ (عادة على أحد 0٪ ، وعلى الآخر - 100٪).
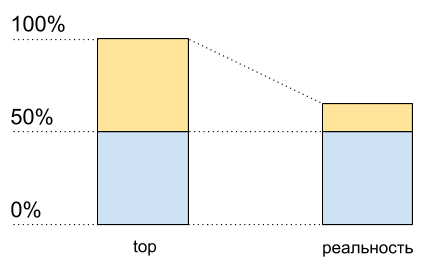 استخدام وحدة المعالجة المركزية: أعلى البيانات وما يحدث بالفعل
استخدام وحدة المعالجة المركزية: أعلى البيانات وما يحدث بالفعلكما لو أن المعالج محمل بنسبة 50٪ فقط. لكن بدنيا لم تظهر نواة حرة إضافية. يسمح Hypertreading
في بعض الحالات بالتنفيذ على جوهر مادي واحد أكثر من عملية واحدة في كل مرة. ولكن هذا أبعد ما يكون عن مضاعفة الأداء في المواقف النموذجية ، على الرغم من أن الرسم البياني لاستخدام وحدة المعالجة المركزية يبدو نصف الموارد: من 50٪ إلى 100٪.
وهذا يعني أنه بعد 50٪ من استخدام وحدة المعالجة المركزية عندما يتم تمكين hypertreading ، فلن تنمو كما كانت من قبل.
لقد كتبت هذا الرمز لإثبات (هذا نوع من الحالات الاصطناعية ، في الواقع ستختلف النتائج):
كود البرنامج النصي<?php $concurrency = $_SERVER['argv'][1] ?? 1; $hashes = 100000000; $chunkSize = intval($hashes / $concurrency); $t1 = microtime(true); $children = array(); for ($i = 0; $i < $concurrency; $i++) { $pid = pcntl_fork(); if (0 === $pid) { $first = $i * $chunkSize; $last = ($i + 1) * $chunkSize - 1; for ($j = $first; $j < $last; $j++) { $dummy = md5($j); } printf("[%d]: %d hashes in %0.4f sec\n", $i, $last - $first, microtime(true) - $t1); exit; } else { $children[$pid] = 1; } } while (count($children) > 0) { $pid = pcntl_waitpid(-1, $status); if ($pid > 0) { unset($children[$pid]); } else { exit("Got a error pid=$pid"); } }
لدي نوى فيزيائيان على حاسوبي المحمول. قم بتشغيل هذا الكود ببيانات إدخال مختلفة لقياس أدائه بعدد مختلف من العمليات المتوازية لـ C.
نرسم نتائج عمليات الإطلاق:
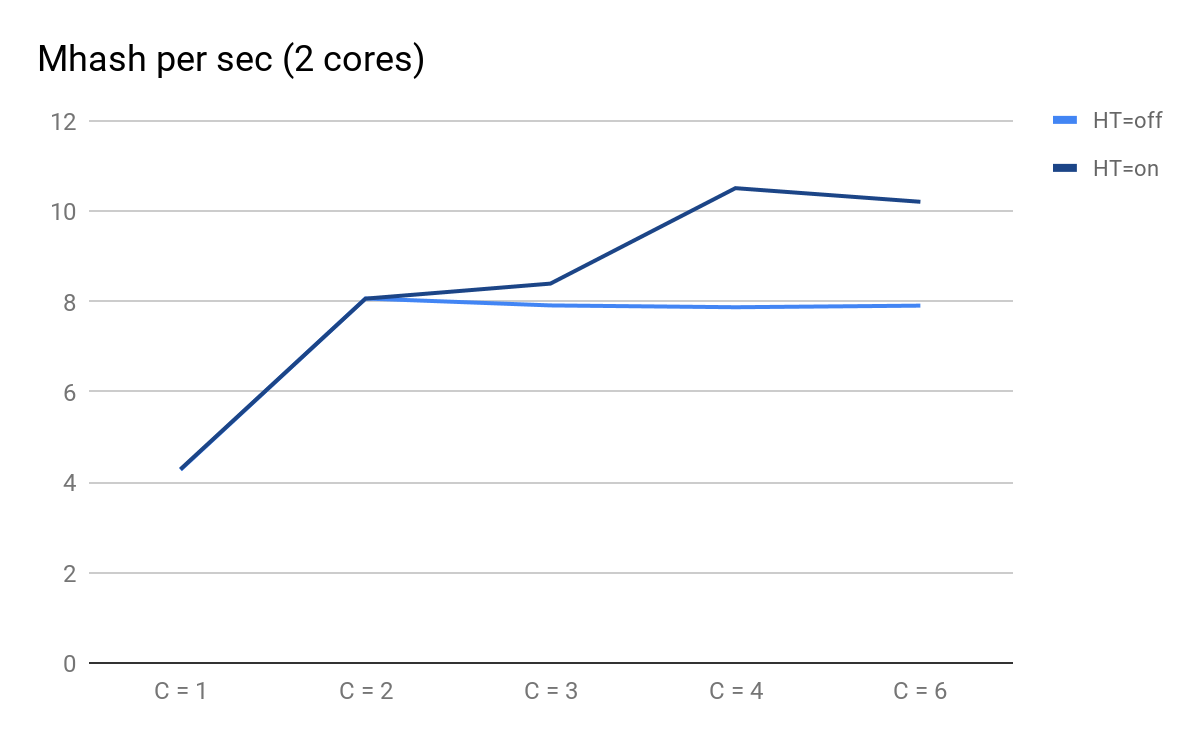 أداء البرنامج النصي يعتمد على عدد العمليات المتوازية
أداء البرنامج النصي يعتمد على عدد العمليات المتوازيةما يمكنك الانتباه إليه:
- من المتوقع أن يكون C = 1 و C = 2 متشابهين لـ HT = on و HT = off ، ويتضاعف الأداء عند إضافة نواة مادية ؛
- في C = 3 ، أصبحت مزايا HT ملحوظة: بالنسبة لـ HT = on ، تمكنا من الحصول على أداء إضافي ، بينما بالنسبة لـ HT = off مع C = 3 فصاعدًا ، تبدأ في الانخفاض ببطء بشكل متوقع ؛
- في C = 4 نرى جميع مزايا HT ؛ تمكنا من الحصول على 30٪ إضافية من الإنتاجية ، ولكن بالمقارنة مع C = 2 في هذا الوقت ، زاد استخدام وحدة المعالجة المركزية من 50٪ إلى 100٪.
الإجمالي ، بالنظر إلى أعلى 50٪ من حمل وحدة المعالجة المركزية ، عند تنفيذ هذا النص البرمجي ، نحصل على 8065 Mhash / sec ، وبنسبة 100٪ - 10،511 Mhash / sec. هذا يعني أنه عند حوالي 50٪ من القمة ، نحصل على 8.065 / 10.511 ~ 77٪ من الحد الأقصى لأداء النظام ، وفي الواقع لدينا حوالي 100٪ متبقية في الاحتياطي - 77٪ = 23٪ ، وليس 50٪ ، كما قد يبدو.
يجب مراعاة هذه الحقيقة عند التخطيط.
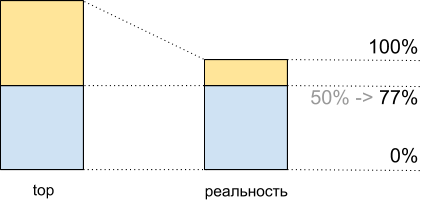 استخدام وحدة المعالجة المركزية ل demoscript: أعلى البيانات وما يحدث بالفعل
استخدام وحدة المعالجة المركزية ل demoscript: أعلى البيانات وما يحدث بالفعلالتضارب المروري
بالإضافة إلى التوجيه الفائق ، يؤدي التخطيط أيضًا إلى تعقيد عدم انتظام حركة المرور اعتمادًا على الوقت من اليوم ويوم الأسبوع والموسم والترددات الأخرى. بالنسبة لنا ، على سبيل المثال ، الذروة مساء الأحد.
 عدد الطلبات في الثانية ، ذروة مساء الأحد
عدد الطلبات في الثانية ، ذروة مساء الأحدلا يتغير عدد الطلبات دائمًا بطريقة واضحة. على سبيل المثال ، يمكن للمستخدمين التفاعل بطريقة أو بأخرى مع مستخدمين آخرين: قد يؤدي نشاط البعض إلى توليد الدفع / البريد الإلكتروني للآخرين وبالتالي إشراكهم في العملية. إلى هذا ، يتم إضافة حملات ترويجية تزيد من عدد الزيارات والتي تحتاج أيضًا إلى الاستعداد لها.
كل هذا مهم أيضًا في الاعتبار عند التخطيط: على سبيل المثال ، لبناء اتجاه قبل أيام الذروة مع مراعاة عدم الخطية المحتملة لنمو الذروة.
أدوات التنميط والقياس
افترض أننا اكتشفنا وجود مشاكل في الأداء ، ونفهم أن هذه ليست قاعدة البيانات / الخدمات / الأشياء ، ومع ذلك قررنا تحسين الشفرة. للقيام بذلك ، أولاً وقبل كل شيء ، نحتاج إلى ملف تعريف أو بعض الأدوات للعثور على الاختناقات ومن ثم رؤية نتائج التحسينات الخاصة بنا.
لسوء الحظ ، لا توجد أداة عالمية جيدة ل PHP اليوم.
الكمال
perf هي أداة تصنيف مدمجة في نواة لينكس. هو منشئ ملفات تعريف
لأخذ العينات يتم تشغيله من خلال عملية منفصلة ، وبالتالي لا يضيف مباشرة إلى البرنامج الذي يتم تحديده. "اللطخة" المضافة بشكل غير مباشر هي "تلطيخ" بشكل موحد ، لذلك لا تشوه القياسات.
مع كل مزاياها ، فإن perf قادرة على العمل فقط مع التعليمات البرمجية المترجمة ومع JIT ولا يمكنها العمل مع التعليمات البرمجية التي تعمل "تحت آلة افتراضية". لذلك ، لا يمكن تحديد كود PHP نفسه فيه ، ولكن يمكنك أن ترى بوضوح كيفية عمل PHP في الداخل ، بما في ذلك امتدادات PHP المختلفة ، ومقدار الموارد التي تنفق عليها.
على سبيل المثال ، مع perf ، وجدنا العديد من الاختناقات ، بما في ذلك مكان الضغط ، والذي سأناقشه أدناه.
مثال:
perf record --call-graph dwarf,65528 -F 99 -p $(pgrep php-cgi | paste -sd "," -) -- sleep 20
perf report(إذا تم تنفيذ العملية والأداء تحت مستخدمين مختلفين ، فيجب تشغيل الأداء من تحت sudo).
 مثال عن إخراج تقرير الأداء لـ PHP-FPM
مثال عن إخراج تقرير الأداء لـ PHP-FPMXHProf ومجمع XHProf
XHProf هو امتداد لـ PHP يضع الموقتات حول جميع المكالمات للوظائف / الأساليب ، ويحتوي أيضًا على أدوات لتصور النتائج التي تم الحصول عليها بهذه الطريقة. على عكس perf ، يسمح لك بالعمل باستخدام شروط PHP-code (في نفس الوقت ، ما يحدث في الامتدادات غير مرئي).
تشمل العيوب شيئين:
- يتم جمع جميع القياسات في إطار طلب واحد ، وبالتالي فهي لا تقدم معلومات حول الصورة ككل ؛
- النفقات العامة ، على الرغم من أنها ليست كبيرة مثل ، على سبيل المثال ، عند استخدام Xdebug ، ولكنها كذلك ، وفي بعض الحالات تكون النتائج مشوهة إلى حد كبير (كلما تم استدعاء وظيفة وأبسط ، كلما زاد التشوه).
هنا مثال يوضح النقطة الأخيرة:
function child1() { return 1; } function child2() { return 2; } function parent1() { child1(); child2(); return; } for ($i = 0; $i < 1000000; $i++) { parent1(); }
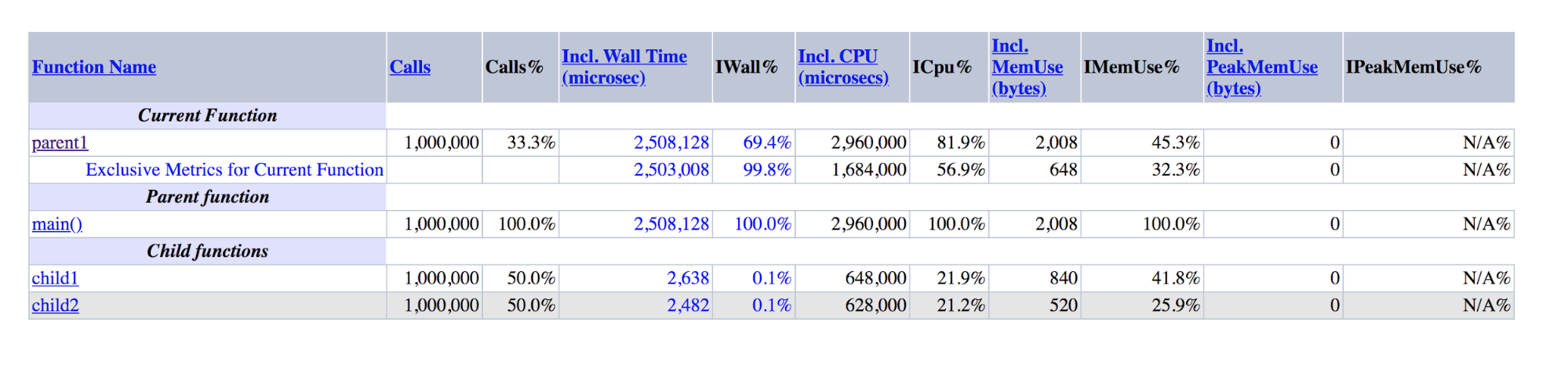 ناتج XHProf للعروض التوضيحية: الوالد 1 هو أوامر بحجم أكبر من مجموع child1 و child2
ناتج XHProf للعروض التوضيحية: الوالد 1 هو أوامر بحجم أكبر من مجموع child1 و child2يمكن ملاحظة أن الوالدين 1 () تم تنفيذهما ~ 500 مرة أطول من child1 () + child2 () ، على الرغم من أن هذه الأرقام في الواقع يجب أن تكون متساوية تقريبًا ، كما تساوي الرئيسي () والوالد 1 ().
إذا كان من الصعب مواجهة العيب الأخير ، فحينئذٍ لمكافحة الأولى قمنا بعمل إضافة لـ XHProf ، والتي تجمع ملفات تعريف الطلبات المختلفة وتصور البيانات المجمعة.
بالإضافة إلى XHProf ، هناك العديد من المحللون الأقل شهرة الذين يعملون على مبدأ مماثل. لديهم مزايا وعيوب مماثلة.
بينبا
يسمح لك
Pinba بمراقبة الأداء من خلال البرامج النصية (الإجراءات) والموقتات المحددة مسبقًا. جميع القياسات في سياق البرامج النصية مصنوعة من العلبة ؛ لهذا ، لا يلزم اتخاذ خطوات إضافية. لكل برنامج نصي ومؤقت ، يتم
تنفيذ getrusage ، لذلك نحن نعرف بالضبط مقدار الوقت الذي يقضيه المعالج في جزء معين من التعليمات البرمجية (على عكس أدوات تحليل العينات ، حيث قد يتحول هذا الوقت إلى شبكة أو قرص ، إلخ). Pinba رائع لحفظ البيانات التاريخية والحصول على صورة بشكل عام وضمن أنواع محددة من الاستعلامات.
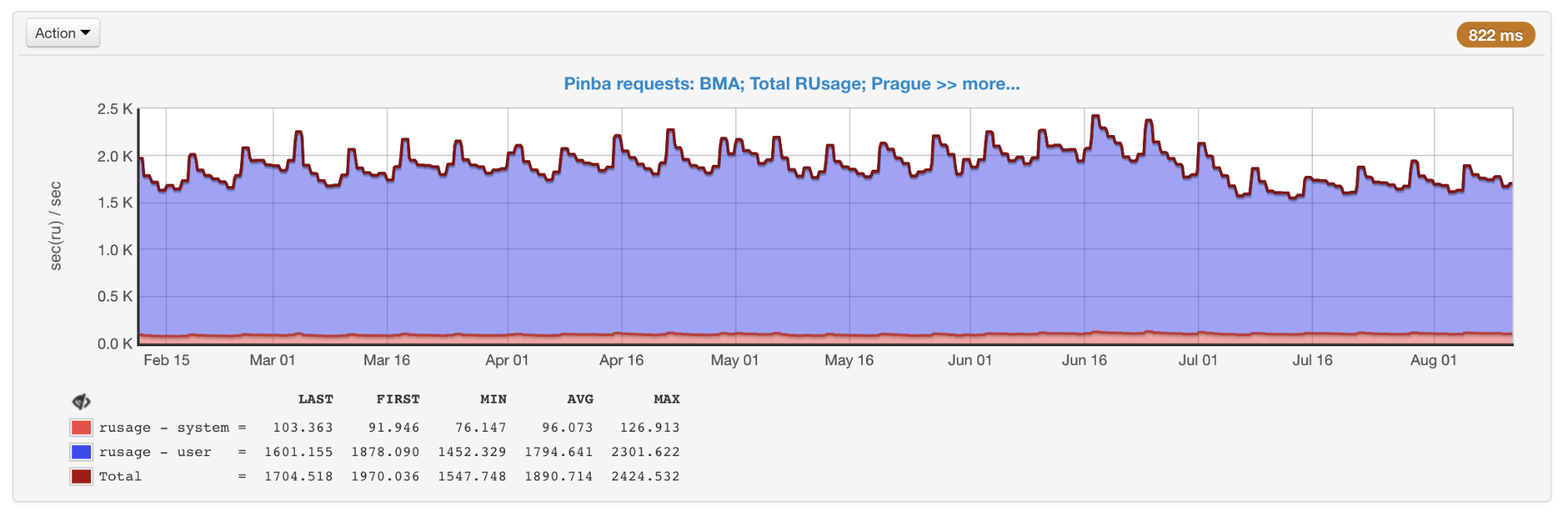 النقل العام لجميع النصوص التي تم الحصول عليها من Pinba
النقل العام لجميع النصوص التي تم الحصول عليها من Pinbaتشمل العيوب حقيقة أنه يجب ترتيب أجهزة ضبط الوقت التي تحدد أجزاء معينة من التعليمات البرمجية ، وليس النصوص البرمجية بالكامل ، مقدمًا في التعليمات البرمجية ، بالإضافة إلى وجود حمل علوي (مثل XHProf) يمكن أن يشوه البيانات.
phpspy
phpspy هو مشروع جديد نسبيًا (أول التزام على GitHub كان قبل نصف عام) ، والذي يبدو واعدًا ، لذلك نحن
نراقبه عن كثب.
من وجهة نظر المستخدم ، يشبه phpspy الأداء: يتم إطلاق عملية متوازية ، تقوم بنسخ أجزاء الذاكرة من عملية PHP بشكل دوري ، وتقوم بتحليلها واستلام آثار المكدس والبيانات الأخرى من هناك. يتم ذلك بطريقة محددة إلى حد ما. من أجل تقليل النفقات العامة ، لا يوقف phpspy عملية PHP وينسخ الذاكرة مباشرة أثناء تشغيلها. هذا يؤدي إلى حقيقة أن المحلل يمكن أن يحصل على حالة غير متناسقة ، يمكن كسر آثار المكدس. لكن phpspy يمكن أن يكتشف هذا ويتجاهل مثل هذه البيانات.
في المستقبل ، باستخدام هذه الأداة ، سيكون من الممكن جمع كل من البيانات على الصورة ككل وملفات تعريف لأنواع محددة من الاستعلامات.
جدول المقارنة
لتنظيم الاختلافات بين الأدوات ، لنقم بإنشاء جدول محوري:
 مقارنة بين الملامح الرئيسية للمحللينالرسوم البيانية اللهب
مقارنة بين الملامح الرئيسية للمحللينالرسوم البيانية اللهبالتحسين والنهج
باستخدام هذه الأدوات ، نراقب باستمرار أداء واستخدام مواردنا. عندما يتم استخدامها بدون مبرر أو نقترب من الحد الأدنى (بالنسبة لوحدة المعالجة المركزية ، فقد اخترنا تجريبيًا قيمة 55 ٪ من أجل الحصول على هامش من الوقت في حالة النمو) ، كما كتبت أعلاه ، فإن أحد حلول المشكلة هو التحسين.
حسنًا ، إذا كان التحسين قد تم بالفعل بواسطة شخص آخر ، كما كان الحال مع PHP 7.0 ، عندما تبين أن هذا الإصدار أكثر إنتاجية بكثير من الإصدارات السابقة. نحاول بشكل عام استخدام التقنيات والأدوات الحديثة ، بما في ذلك التحديثات في الوقت المناسب لأحدث إصدارات PHP. وفقًا
للمعايير العامة ، فإن PHP 7.2 أسرع بنسبة 5-12٪ من PHP 7.1. لكن هذا التحول ، للأسف ، أعطانا القليل.
طوال الوقت قمنا بتنفيذ عدد كبير من التحسينات. لسوء الحظ ، يرتبط معظمهم ارتباطًا وثيقًا بمنطق أعمالنا. سأتحدث عن تلك التي قد تكون ذات صلة ليس فقط بالنسبة لنا ، أو الأفكار والأساليب التي يمكن استخدامها خارج قانوننا.
ضغط Zlib => zstd
نستخدم الضغط لمفاتيح memkey الكبيرة. هذا يسمح لنا بإنفاق ذاكرة أقل من ثلاث إلى أربع مرات للتخزين بسبب تكاليف وحدة المعالجة المركزية الإضافية للضغط / إلغاء الضغط. استخدمنا zlib لهذا (يختلف امتدادنا للعمل مع memekes عن تلك التي تأتي مع PHP ، ولكن
تستخدم تلك الرسمية
أيضًا zlib).
في الكمال ، كان الإنتاج شيء من هذا القبيل:
+ 4.03% 0.22% php-cgi libz.so.1.2.11 [.] inflate
+ 3.38% 0.00% php-cgi libz.so.1.2.11 [.] deflateتم إنفاق 7-8٪ من الوقت على الضغط / تخفيف الضغط.
قررنا اختبار مستويات مختلفة وخوارزميات الضغط. اتضح أن zstd يعمل على بياناتنا أسرع عشر مرات تقريبًا ، حيث فقد في مكانه ~ 1.1 مرة. أنقذنا تغيير بسيط إلى حد ما في الخوارزمية ~ 7.5٪ من وحدة المعالجة المركزية (أتذكر ، في وحدات التخزين لدينا ما يعادل ~ 45 خادمًا).
من المهم أن نفهم أن نسبة أداء خوارزميات الضغط المختلفة يمكن أن تختلف اختلافًا كبيرًا اعتمادًا على بيانات الإدخال. هناك
مقارنات مختلفة ، ولكن بدقة أكبر لا يمكن تقدير ذلك إلا باستخدام أمثلة من العالم الحقيقي.
IS_ARRAY_IMMUTABLE كمستودع للبيانات النادرة التعديل
عند العمل بمهام حقيقية ، يجب عليك التعامل مع هذه البيانات التي تحتاجها كثيرًا وفي نفس الوقت نادرًا ما تتغير ولها حجم محدود. لدينا الكثير من البيانات المتشابهة ، والمثال الجيد هو تكوين
الاختبارات المقسمة . نتحقق مما إذا كان المستخدم يخضع لشروط اختبار معين ، واعتمادًا على ذلك ، نعرض له وظيفة تجريبية أو عادية (يحدث هذا تقريبًا خلال كل طلب). في المشاريع الأخرى ، يمكن أن تكون التكوينات والأدلة المختلفة مثل هذا: البلدان والمدن واللغات والفئات والعلامات التجارية وما إلى ذلك.
نظرًا لأن هذه البيانات غالبًا ما يتم طلبها ، يمكن أن يؤدي استلامها إلى وضع عبء إضافي ملحوظ على كل من التطبيق نفسه وعلى الخدمة التي يتم تخزين هذه البيانات فيها. يمكن حل المشكلة الأخيرة ، على سبيل المثال ، باستخدام APCu ، الذي يستخدم ذاكرة نفس الجهاز الذي يعمل PHP-FPM كمخزن. ولكن حتى ذلك الحين:
- ستكون هناك تكاليف تسلسل / إلغاء التسلسل ؛
- تحتاج إلى إبطال البيانات بطريقة أو بأخرى عند التغيير ؛
- هناك بعض النفقات العامة مقارنة بالوصول إلى متغير فقط في PHP.
يقدم PHP 7.0 تحسين
IS_ARRAY_IMMUTABLE . إذا أعلنت عن مصفوفة ، وجميع عناصرها معروفة في وقت التجميع ، فستتم معالجتها ووضعها في ذاكرة OPCache مرة واحدة ، وسيشير العاملون في PHP-FPM إلى هذه الذاكرة المشتركة دون قضاء وقتهم قبل محاولة التغيير. ويترتب على ذلك أيضًا أن تضمين مثل هذا المصفوفة سيستغرق وقتًا ثابتًا بغض النظر عن الحجم (عادة ~ 1 ميكروثانية).
للمقارنة: مثال على الوقت للحصول على صفيف 10000 عنصر من خلال include و apcu_fetch:
$t0 = microtime(true); $a = include 'test-incl-1.php'; $t1 = microtime(true); printf("include (%d): %d microsec\n", count($a), ($t1-$t0) * 1e6); $t0 = microtime(true); $a = apcu_fetch('a'); $t1 = microtime(true); printf("apcu_fetch (%d): %d microsec\n", count($a), ($t1-$t0) * 1e6);
التحقق من ما إذا كان قد تم تطبيق هذا التحسين يمكن أن يكون بسيطًا جدًا إذا نظرت إلى رموز التشغيل التي تم إنشاؤها:
$ cat immutable.php <?php return [ 'key1' => 'val1', 'key2' => 'val2', 'key3' => 'val3', ]; $ cat mutable.php <?php return [ 'key1' => \SomeClass::CONST_1, 'key2' => 'val2', 'key3' => 'val3', ]; $ php -d opcache.enable=1 -d opcache.enable_cli=1 -d opcache.opt_debug_level=0x20000 immutable.php $_main: ; (lines=1, args=0, vars=0, tmps=0) ; (after optimizer) ; /home/ubuntu/immutable.php:1-8 L0 (4): RETURN array(...) $ php -d opcache.enable_cli=1 -d opcache.opt_debug_level=0x20000 mutable.php $_main: ; (lines=5, args=0, vars=0, tmps=2) ; (after optimizer) ; /home/ubuntu/mutable.php:1-8 L0 (4): T1 = FETCH_CLASS_CONSTANT string("SomeClass") string("CONST_1") L1 (4): T0 = INIT_ARRAY 3 T1 string("key1") L2 (5): T0 = ADD_ARRAY_ELEMENT string("val2") string("key2") L3 (6): T0 = ADD_ARRAY_ELEMENT string("val3") string("key3") L4 (6): RETURN T0
في الحالة الأولى ، يمكن ملاحظة أنه لا يوجد سوى رمز تشغيل واحد في الملف - عودة المصفوفة النهائية. في الحالة الثانية ، يحدث تكوين عنصر بعد عنصر في كل مرة يتم فيها تنفيذ هذا الملف.
وبالتالي ، من الممكن إنشاء هياكل في شكل لا يتطلب المزيد من التحول في وقت التشغيل. على سبيل المثال ، بدلاً من تفكيك أسماء الفئات من خلال علامتي "_" و "\" في كل مرة للتحميل التلقائي ، يمكنك إنشاء خريطة المراسلات مسبقًا "Class => Path". في هذه الحالة ، سيتم تخفيض وظيفة التحويل إلى استدعاء جدول تجزئة واحد. يقوم الملحن بهذا النوع من التحسين إذا قمت بتمكين
خيار التحسين-التحميل التلقائي .
لإبطال هذه البيانات ، لا تحتاج إلى القيام بأي شيء على وجه التحديد - ستقوم PHP نفسها بإعادة تجميع الملف عند التغيير ، تمامًا كما تفعل مع نشر الرمز العادي. العيب الوحيد الذي يجب ألا تنساه: إذا كان الملف كبيرًا جدًا ، فإن الطلب الأول بعد تغييره سيتسبب في إعادة الترجمة ، الأمر الذي قد يستغرق وقتًا ملموسًا.
الأداء يشمل / يتطلب
على عكس مثال الصفيف الثابت ، فإن إرفاق الملفات بإعلانات الفئة والوظيفة ليس بهذه السرعة. على الرغم من وجود OPCache ، يجب أن يقوم محرك PHP بنسخها في ذاكرة العملية ، وربط التبعيات بشكل متكرر ، والذي يمكن أن يستغرق في النهاية مئات من الميكروثانية أو حتى المللي ثانية لكل ملف.
إذا قمت بإنشاء مشروع فارغ جديد على
Symfony 4.1 وقمت بوضع
get_included_files () كسطر أول في الإجراء ، يمكنك أن ترى أن 310 ملفات متصلة بالفعل. في مشروع حقيقي ، يمكن أن يصل هذا الرقم إلى الآلاف لكل طلب. يجدر الانتباه إلى الأشياء التالية.
عدم وجود ميزات الشحن التلقائييوجد
وظيفة التحميل التلقائي RFC ، ولكن لم
يلاحظ أي تطور منذ عدة سنوات. لذلك ، إذا كانت التبعية في Composer تحدد الوظائف خارج الفئة ويجب أن تكون هذه الوظائف متاحة للمستخدم ، فإن ذلك يتم عن طريق
ربط ملف بهذه الوظائف
الإلزامية مع كل عملية تهيئة لبرنامج التحميل التلقائي.
على سبيل المثال ، بإزالة إحدى التبعيات من composer.json ، التي تعلن عن العديد من الوظائف ويمكن استبدالها بسهولة بمائة سطر من التعليمات البرمجية ، فزنا بنسبة اثنين بالمائة من وحدة المعالجة المركزية.
يتم استدعاء اللودر التلقائي في كثير من الأحيان أكثر مما قد يبدو.لتوضيح الفكرة ، قم بإنشاء مثل هذا الملف مع فئة:
<?php class A extends B implements C { use D; const AC1 = \E::E1; const AC2 = \F::F1; private static $as3 = \G::G1; private static $as4 = \H::H1; private $a5 = \I::I1; private $a6 = \J::J1; public function __construct(\K $k = null) {} public static function asf1(\L $l = null) :? LR { return null; } public static function asf2(\M $m = null) :? MR { return null; } public function af3(\N $n = null) :? NR { return null; } public function af4(\P $p = null) :? PR { return null; } }
تسجيل محمل تلقائي: spl_autoload_register(function ($name) { echo "Including $name...\n"; include "$name.php"; });
وسنقوم بعمل العديد من حالات الاستخدام لهذه الفئة: include 'A.php' Including B... Including D... Including C... \A::AC1 Including A... Including B... Including D... Including C... Including E... new A() Including A... Including B... Including D... Including C... Including E... Including F... Including G... Including H... Including I... Including J...
قد تلاحظ أنه عندما نربط الصف بطريقة أو بأخرى ، لكننا لا ننشئ مثيله ، سيتم توصيل الأصل والواجهات والسمات. يتم ذلك بشكل متكرر لجميع الملفات المتصلة على أنها حل.
عند إنشاء مثيل ، تتم إضافة حل جميع الثوابت والحقول إلى هذا ، مما يؤدي إلى اتصال جميع الملفات اللازمة لذلك ، والذي بدوره سيؤدي أيضًا إلى اتصال متكرر للسمات والآباء وواجهات الطبقات المتصلة حديثًا.
 ربط الفئات ذات الصلة لعملية إنشاء المثيل والحالات الأخرى
ربط الفئات ذات الصلة لعملية إنشاء المثيل والحالات الأخرىلا يوجد حل عالمي لهذه المشكلة ، ما عليك سوى أن تضعها في الاعتبار وتراقب الاتصالات بين الفئات: يمكن لخط واحد سحب اتصال مئات الملفات.
إعدادات OPCacheإذا كنت تستخدم طريقة
النشر الذري عن طريق تغيير الرابط الرمزي الذي اقترحه Rasmus Lerdorf ، منشئ PHP ، ثم
لحل مشكلة "لصق" الارتباط الرمزي في الإصدار القديم ، يجب عليك تضمين opcache.revalidate_path ، على النحو الموصى به ، على سبيل المثال ، في هذه
المقالة حول OPCache المترجمة بواسطة البريد مجموعة رو.
تكمن المشكلة في أن هذا الخيار بشكل كبير (في المتوسط ، مرة ونصف إلى مرتين) يزيد من وقت تضمين كل ملف. في المجموع ، يمكن أن يستهلك هذا مقدارًا كبيرًا من الموارد (في حالتنا ، فإن تعطيل هذا الخيار أعطى مكاسب بنسبة 7-9 ٪).
لتعطيله ، تحتاج إلى القيام بأمرين:
- جعل خادم الويب يحل الروابط الرمزية ؛
- توقف عن ربط الملفات داخل البرنامج النصي PHP على طول المسارات التي تحتوي على روابط رمزية ، أو فرضها من خلال readlink () أو realpath ().
إذا كانت جميع الملفات متصلة بالمحمل التلقائي ، فسيتم تنفيذ العنصر الثاني تلقائيًا بعد اكتمال العنصر الأول: يستخدم ompomer ثابت __DIR__ ، والذي سيتم حله بشكل صحيح.
يحتوي OPCache على عدد قليل من الخيارات الأخرى التي يمكن أن تعطي تعزيزًا للأداء مقابل المرونة. يمكنك قراءة المزيد عن هذا في
المقالة التي ذكرتها أعلاه.
على الرغم من كل هذه التحسينات ، ستظل التضمين غير مجاني. لمكافحة هذا ، يخطط PHP 7.4 لإضافة
التحميل المسبق .
قفل APCu
على الرغم من أننا لا نتحدث عن قواعد البيانات والخدمات هنا ، يمكن أن تحدث أنواع مختلفة من الأقفال في الكود ، مما يزيد من وقت تنفيذ البرنامج النصي.
مع نمو الطلبات ، لاحظنا تباطؤًا حادًا في الاستجابة في أوقات الذروة. بعد معرفة الأسباب ، اتضح أنه على الرغم من أن APCu هو أسرع طريقة للحصول على البيانات (مقارنة بـ Memcache و Redis ووحدات التخزين الخارجية الأخرى) ، فإنه يمكن أن يعمل أيضًا ببطء مع الكتابة المتكررة على نفس المفاتيح.
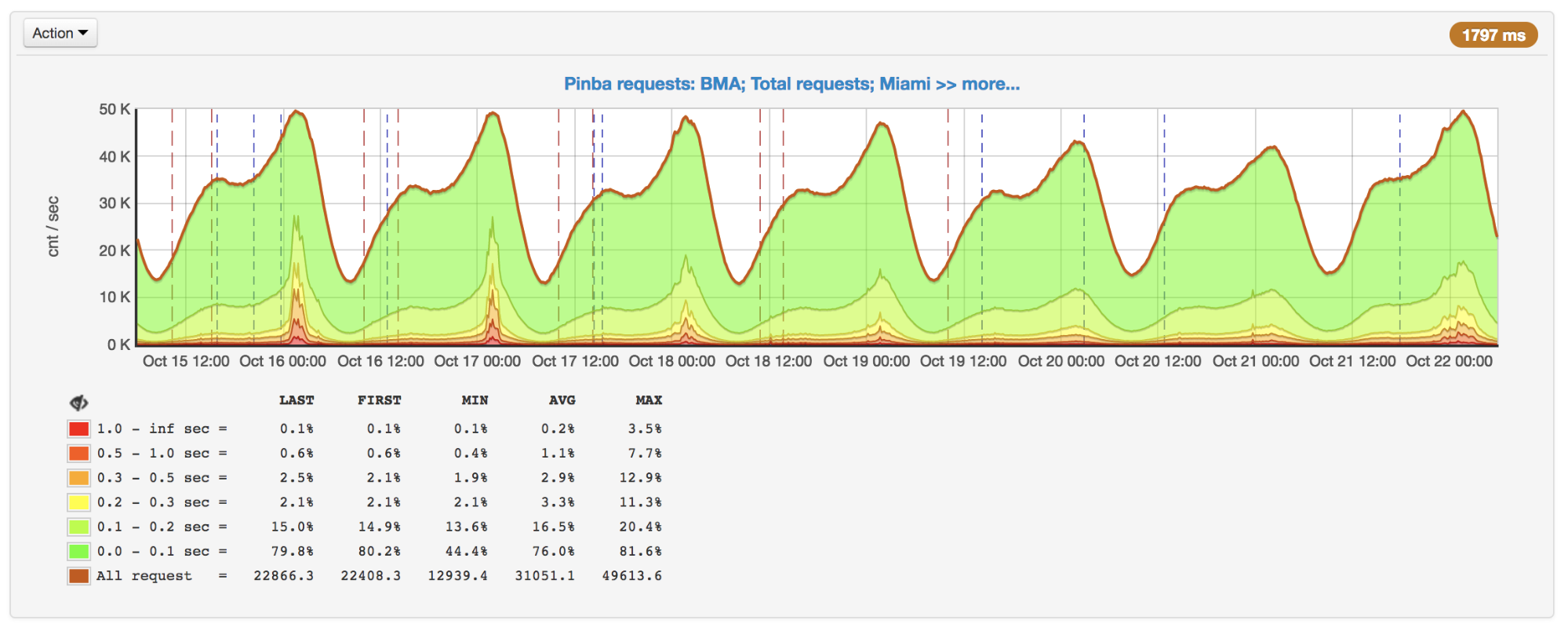 عدد الطلبات في الثانية ووقت التشغيل: القمم في 16 و 17 أكتوبر
عدد الطلبات في الثانية ووقت التشغيل: القمم في 16 و 17 أكتوبرعند استخدام APCu كذاكرة تخزين مؤقت ، فإن هذه المشكلة ليست ذات صلة ، لأن التخزين المؤقت عادة ما يتضمن كتابة نادرة وقراءة متكررة. لكن بعض المهام والخوارزميات (على سبيل المثال ،
قاطع الدائرة (
التنفيذ في PHP )) تتضمن أيضًا التسجيل المتكرر ، مما يسبب الأقفال.
لا يوجد حل شامل لهذه المشكلة ، ولكن في حالة Circuit Breaker يمكن حلها ، على سبيل المثال ، عن طريق وضعها في
خدمة منفصلة مثبتة على أجهزة مع PHP.
تجهيز الدفعات
حتى إذا لم تأخذ في الاعتبار تضمين ، عادةً ما يتم قضاء جزء كبير من وقت تنفيذ الاستعلام على التهيئة: إطار عمل (على سبيل المثال ، بناء حاوية DI وتهيئة جميع تبعياتها ، والتوجيه ، وتنفيذ جميع المستمعين) ، ورفع الجلسة ، والمستخدم ، وما إلى ذلك كذلك.
إذا كانت الواجهة الخلفية لواجهة برمجة تطبيقات داخلية لشيء ما ، فيمكن عندئذٍ تجميع بعض الطلبات على العملاء وإرسالها كطلب واحد. في هذه الحالة ، سيتم تنفيذ التهيئة مرة واحدة لعدة طلبات.
, , . - , . .
Badoo , . PHP-FPM, CPU, , , : IO, CPU .
PHP-FPM — , PHP.
(CPU, IO), . , , , , - , . , . , , .
الخلاصة
. PHP .
:
- ;
- ;
- - , : , ;
- : (, , );
- : ;
- , OPCache PHP, , , ;
- : (, , PHP 7.2 , );
- : , .
?
شكرا لاهتمامكم!