[الجزء 2 من 2]
[الجزء 1 من 2]

كيف فعلنا ذلك
قررنا التبديل إلى برنامج "شركاء Google المعتمدون" لتحسين أداء التطبيق - مع زيادة الحجم ، ولكن بدون تكاليف كبيرة. استغرقت العملية برمتها أكثر من شهرين. لحل هذه المشكلة ، قمنا بتشكيل مجموعة خاصة من المهندسين.
في هذا المنشور ، سنتحدث عن النهج المختار وتنفيذه ، وكذلك كيف تمكنا من تحقيق الهدف الرئيسي - لتنفيذ هذه العملية بسلاسة قدر الإمكان ونقل البنية التحتية بالكامل إلى Google Cloud Platform ، دون المساس بجودة خدمة المستخدم.
التخطيط
- تم إعداد قائمة مرجعية مفصلة تحدد كل خطوة محتملة. تم إنشاء مخطط انسيابي لوصف التسلسل.
- تم تطوير خطة إعادة تعيين يمكننا استخدامها ، إن وجدت.
عدد قليل من جلسات العصف الذهني - وقد حددنا أكثر الطرق المفهومة والأبسط لتنفيذ مخطط النشاط النشط. وهو يتألف من حقيقة أنه يتم استضافة مجموعة صغيرة من المستخدمين على سحابة واحدة ، والباقي على أخرى. ومع ذلك ، تسبب هذا النهج في حدوث مشكلات ، خاصة من جانب العميل (فيما يتعلق بإدارة DNS) ، وأدى إلى تأخيرات في نسخ قاعدة البيانات. وبسبب هذا ، كان من شبه المستحيل تنفيذه بأمان. لم تقدم الطريقة الواضحة الحل اللازم ، وكان علينا تطوير استراتيجية متخصصة.
بناءً على مخطط التبعية ومتطلبات السلامة التشغيلية ، قمنا بتقسيم خدمات البنية التحتية إلى 9 وحدات.
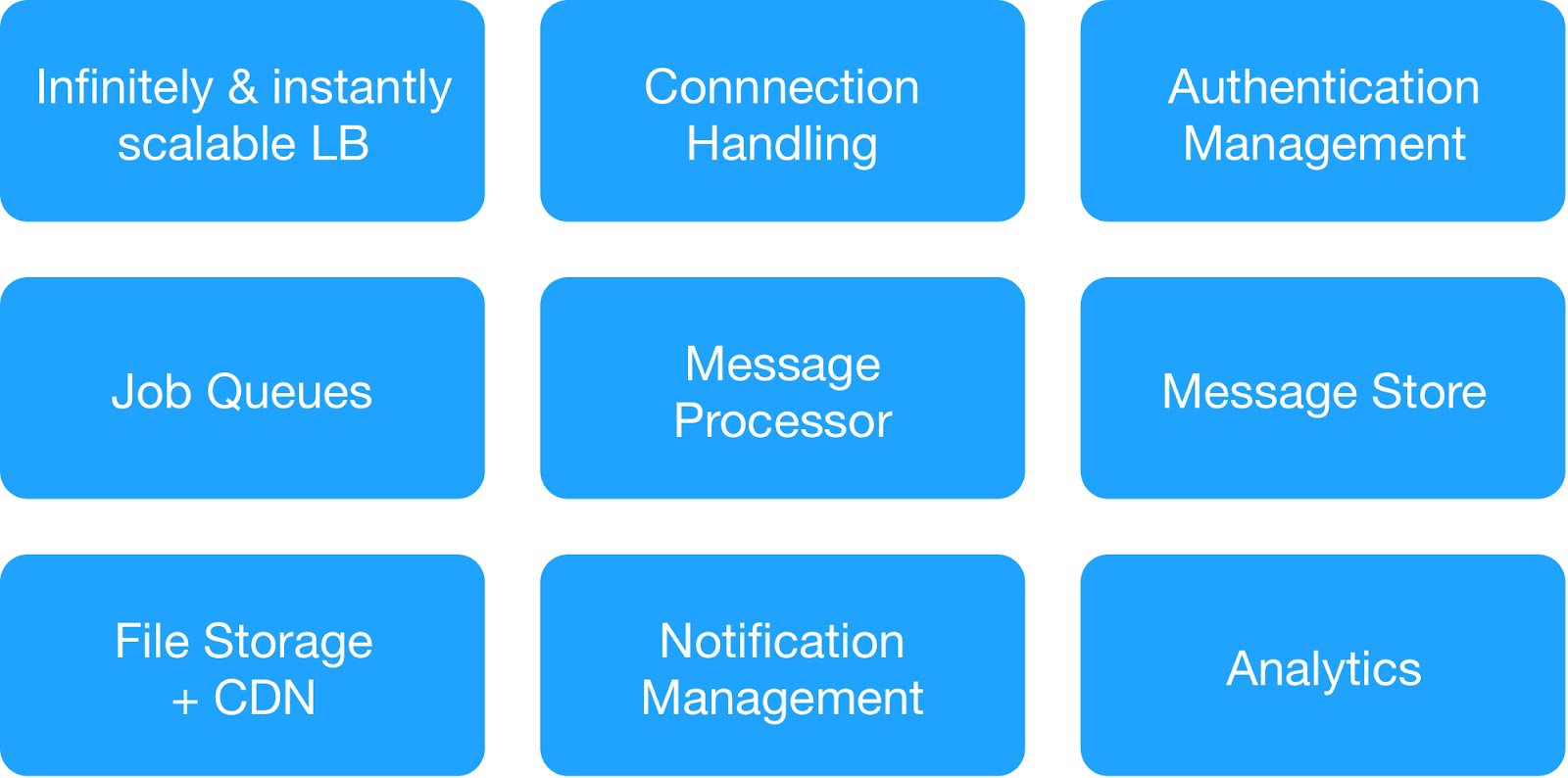
(الوحدات الأساسية لنشر البنية التحتية للاستضافة)
أدارت كل مجموعة بنية تحتية خدمات داخلية وخارجية مشتركة.
mess خدمة رسائل البنية التحتية : MQTT ، HTTPs ، Thrift ، خادم Gunicorn ، وحدة الانتظار ، عميل Async ، خادم Jetty ، مجموعة Kafka.
Ware خدمات مستودع البيانات : الكتلة الموزعة MongoDB و Redis و Cassandra و Hbase و MySQL و MongoDB.
service خدمة تحليل البنية التحتية : مجموعة كافكا ، مجموعة مستودع البيانات (HDFS ، HIVE).
الاستعداد ليوم مهم:
plan خطة تفصيلية للتحول إلى برنامج "شركاء Google المعتمدون" لكل خدمة: التسلسل ، ومستودع البيانات ، وخطة إعادة التعيين.
interact تفاعلات الشبكة عبر المشروع (VPC السحابي الخاص الافتراضي المشترك [XPN]) في GCP لعزل أجزاء مختلفة من البنية التحتية وتحسين الإدارة وتحسين الأمان والاتصال.
✓ العديد من أنفاق VPN بين GCP والسحابة الافتراضية الخاصة العاملة (VPC) لتبسيط نقل كميات كبيرة من البيانات عبر الشبكة أثناء عملية النسخ المتماثل ، بالإضافة إلى النشر اللاحق المحتمل لنظام مواز.
✓ أتمتة التثبيت وتكوين المكدس بأكمله باستخدام نظام الشيف.
✓ البرامج النصية وأدوات الأتمتة للنشر والمراقبة والتسجيل وما إلى ذلك.
✓ تكوين جميع الشبكات الفرعية المطلوبة وقواعد جدار الحماية المدارة لدفق النظام.
✓ النسخ المتماثل في مراكز البيانات المتعددة (Multi-DC) لجميع أنظمة التخزين.
✓ تكوين موازنات التحميل (GLB / ILB) ومجموعات المثيلات المدارة (MIG).
✓ النصوص البرمجية والتعليمات البرمجية لنقل حاوية تخزين الكائن إلى GCP Cloud Storage مع نقاط التفتيش.
سرعان ما استوفينا جميع المتطلبات الأساسية اللازمة وأعدنا قائمة مرجعية بالعناصر لنقل البنية التحتية إلى منصة Google Cloud Platform. بعد العديد من المناقشات ، بالإضافة إلى النظر في عدد الخدمات والمخططات التبعية ، قررنا نقل البنية التحتية السحابية إلى GCP في ثلاث ليال لتغطية جميع خدمات جانب الخادم وتخزين البيانات.
الانتقال
إستراتيجية نقل موازن التحميل:
لقد استبدلنا مجموعة HAProxy المُدارة سابقًا بموازن تحميل عالمي لمعالجة عشرات الملايين من اتصالات المستخدم النشطة يوميًا.
1 المرحلة الأولى:
- يتم إنشاء MIGs بقواعد إعادة توجيه الحزم لإعادة توجيه كل حركة المرور إلى عناوين IP MQTT في السحابة الحالية.
- تم إنشاء موازن SSL و TCP Proxy مع MIG كجزء من الخادم.
- بالنسبة إلى MIG ، يتم إطلاق HAProxy مع خوادم MQTT كجزء من الخادم.
- في DNS ، أضافت سياسة التوجيه على أساس الوزن عنوان IP GLB خارجي.
يتم نشر اتصالات المستخدم تدريجياً أثناء تتبع أدائهم.
⊹ الخطوة 2: انتقال المعلم ، ابدأ نشر الخدمات في برنامج "شركاء Google المعتمدون".
⊹ المرحلة 3: المرحلة الأخيرة من الانتقال ، يتم نقل جميع الخدمات إلى برنامج "شركاء Google المعتمدون".
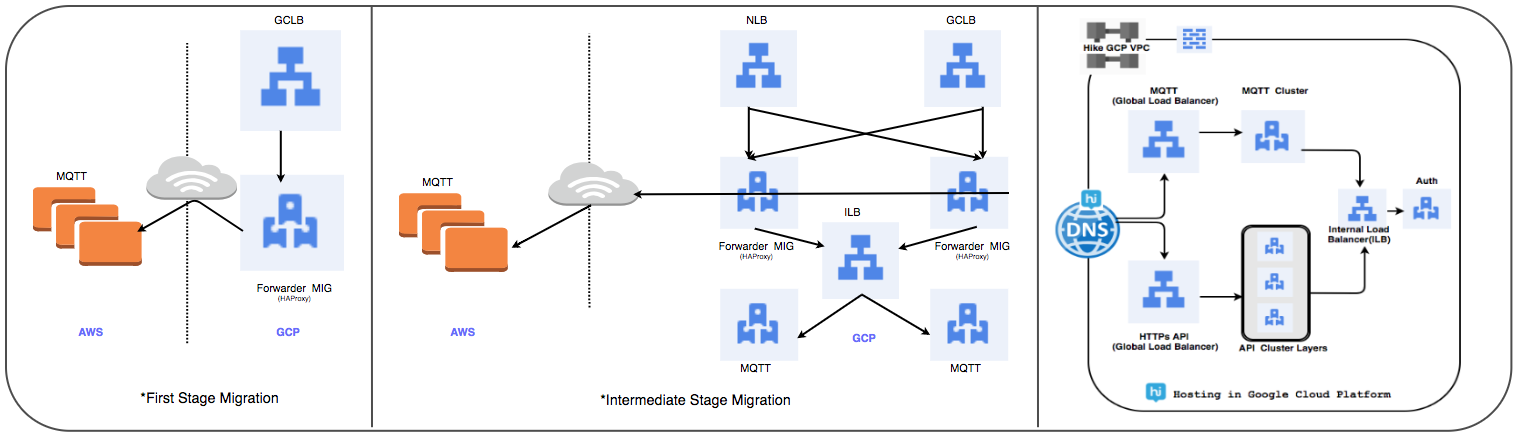
(مراحل نقل موازن التحميل)
في هذه المرحلة ، عمل كل شيء كما هو متوقع. سرعان ما حان الوقت لنشر العديد من خدمات HTTP الداخلية في GCP مع التوجيه - بالنظر إلى وزن المعاملات. قمنا برصد جميع المؤشرات عن كثب. عندما بدأنا في زيادة حركة المرور تدريجيًا ، في اليوم السابق للانتقال المخطط ، تم تسجيل التأخيرات في تفاعل VPC عبر VPN (التأخيرات من 40 مللي ثانية - 100 مللي ثانية ، على الرغم من أنها كانت في وقت سابق أقل من 10 مللي ثانية).
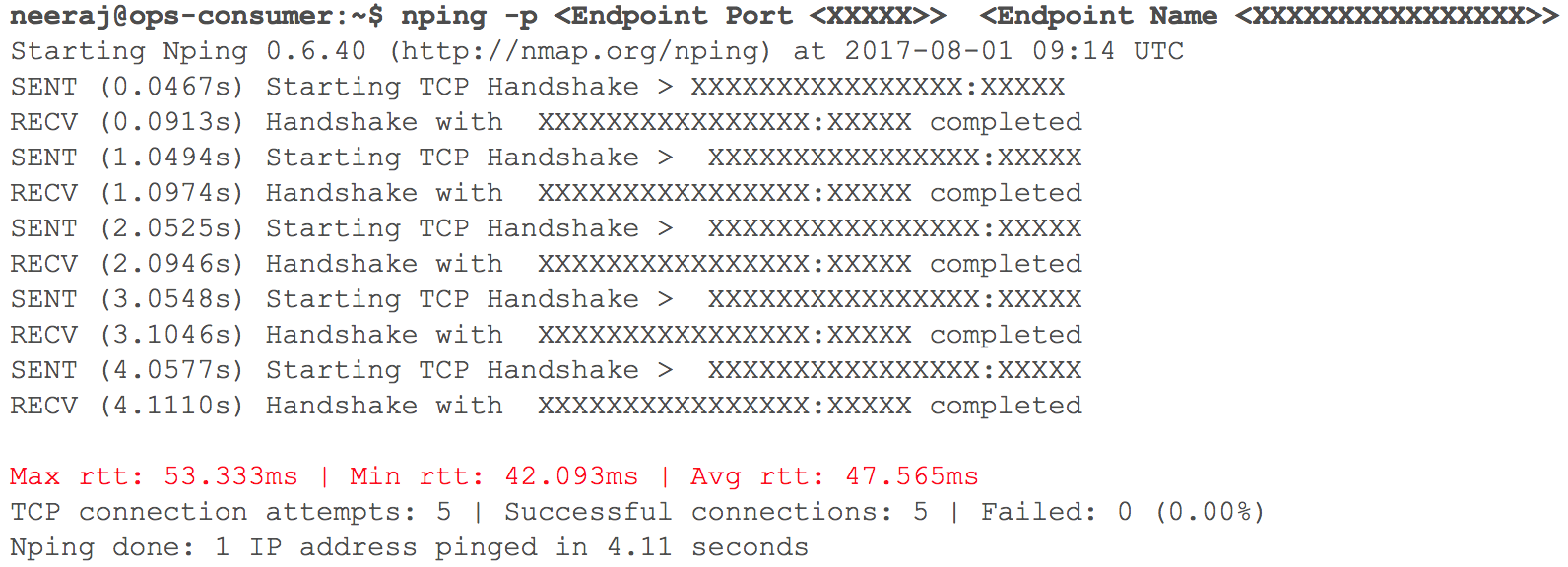
(لقطة للتحقق من تأخر الشبكة عند تفاعل جهازي VPCs)
أظهرت المراقبة بوضوح: كان هناك خطأ في كل من قنوات الشبكة السحابية باستخدام أنفاق VPN. حتى صبيب نفق VPN لم يصل إلى العلامة المثلى. بدأ هذا الموقف يؤثر سلبًا على بعض خدمات المستخدم لدينا. لقد أعدنا على الفور جميع خدمات HTTP التي تم ترحيلها سابقًا إلى حالتها الأصلية. اتصلنا بفرق دعم الخدمات TAM والخدمات السحابية ، وقدمنا البيانات الأولية اللازمة وبدأنا نفهم سبب تزايد التأخيرات. توصل متخصصو الدعم إلى استنتاج مفاده أنه تم تحقيق الحد الأقصى لعرض النطاق الترددي للشبكة في القناة السحابية بين اثنين من مزودي الخدمة السحابية. ومن هنا تزايد تأخيرات الشبكة أثناء نقل الأنظمة الداخلية.
أجبر هذا الحادث على تعليق الانتقال إلى السحابة. لم يتمكن مقدمو الخدمات السحابية من مضاعفة عرض النطاق الترددي بسرعة كافية. لذلك عدنا إلى مرحلة التخطيط وراجعنا الاستراتيجية. قررنا نقل البنية التحتية السحابية إلى GCP في ليلة واحدة بدلاً من ثلاث ، وأدرجنا في الخطة جميع خدمات جزء الخادم وتخزين البيانات. عندما وصلت الساعة "X" ، سار كل شيء بسلاسة: تم نقل أعباء العمل بنجاح إلى Google Cloud دون أن يلاحظها المستخدمون!
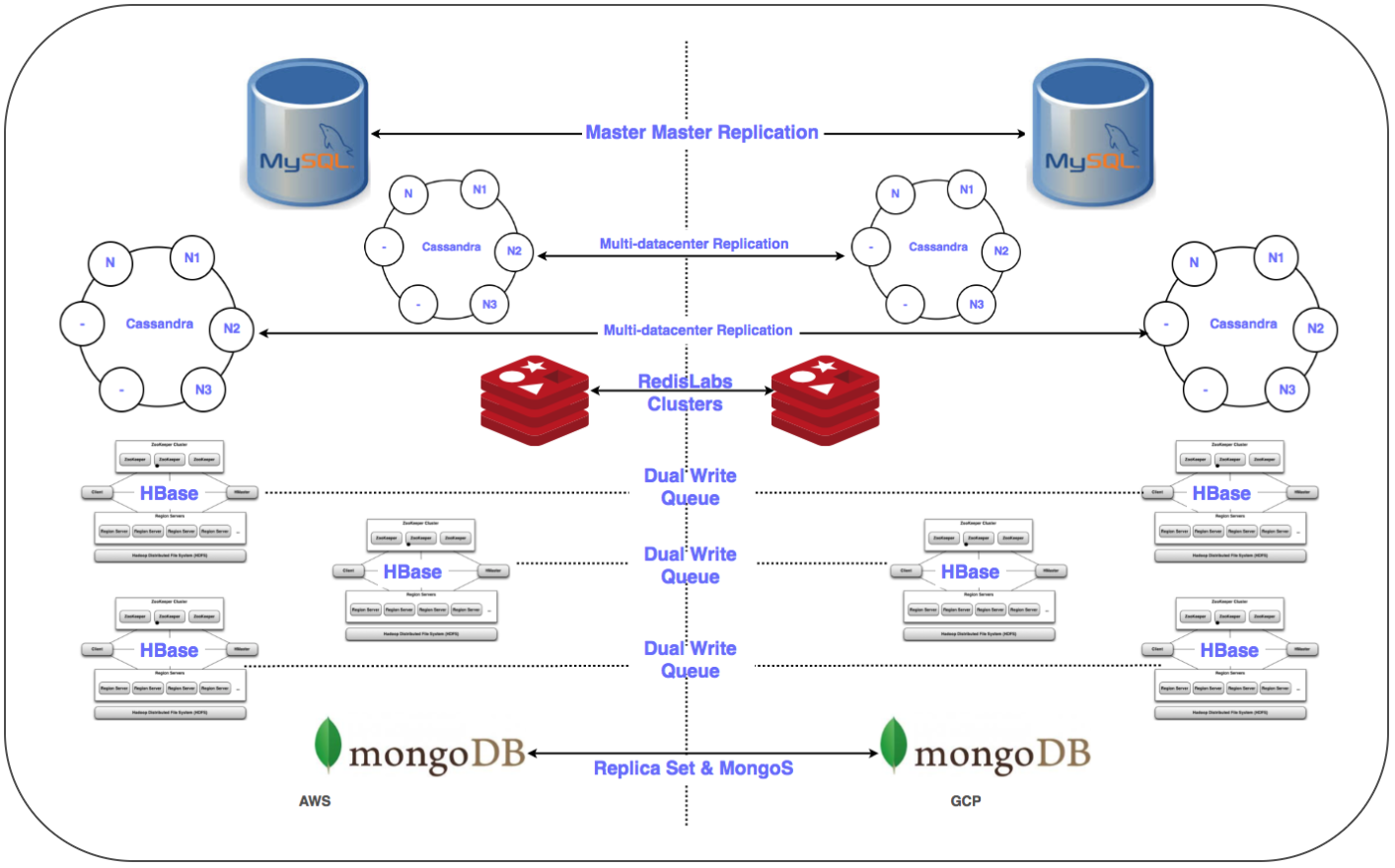
استراتيجية ترحيل قاعدة البيانات:
كان من الضروري نقل أكثر من 50 نقطة نهاية لقاعدة البيانات لنظام قواعد بيانات علائقية ، وتخزين في الذاكرة ، بالإضافة إلى NoSQL وكتل موزعة وقابلة للتطوير مع الكمون المنخفض. لقد وضعنا نسخًا متماثلة لجميع قواعد البيانات في برنامج "شركاء Google المعتمدون". تم ذلك لجميع عمليات النشر باستثناء HBase.
replic النسخ المتماثل للعبد الرئيسي: تم تنفيذه لمجموعات MySQL و Redis و MongoDB و MongoS.
النسخ المتماثل متعدد متعدد DC: تم تنفيذه لمجموعات كاساندرا.
⊹ الكتل المزدوجة: تم تكوين مجموعة متوازية لـ Gbase في GCP. تم ترحيل البيانات الموجودة ، وتم تكوين الإدخال المزدوج وفقًا لاستراتيجية الحفاظ على تناسق البيانات في كلا المجموعتين.
في حالة HBase ، كانت المشكلة تكمن في Ambari. واجهنا بعض الصعوبات عند وضع المجموعات في العديد من مراكز البيانات ، على سبيل المثال ، كانت هناك مشاكل في نظام أسماء النطاقات ، ونص برمجي للتعرف على الحامل ، وما إلى ذلك.
تضمنت الخطوات النهائية (بعد نقل الخوادم) نقل النسخ المتماثلة إلى الخوادم الرئيسية وإغلاق قواعد البيانات القديمة. كما هو مخطط ، تحديد أولوية نقل قاعدة البيانات ، استخدمنا Zookeeper للتكوين الضروري لمجموعات التطبيقات.
إستراتيجية ترحيل خدمات التطبيقات
لنقل أعباء عمل خدمات التطبيقات من الاستضافة الحالية إلى سحابة GCP ، استخدمنا نهج الرفع والتحويل. لكل خدمة تطبيق ، أنشأنا مجموعة من المثيلات المُدارة (MIG) مع التحجيم التلقائي.
وفقًا لخطة تفصيلية ، بدأنا في ترحيل الخدمات إلى برنامج "شركاء Google المعتمدون" ، مع مراعاة تسلسل مستودعات البيانات وتبعياتها. تم ترحيل جميع خدمات مكدس المراسلة إلى GCP بدون أي توقف. نعم ، كانت هناك بعض الأخطاء البسيطة ، لكننا تعاملنا معها على الفور.
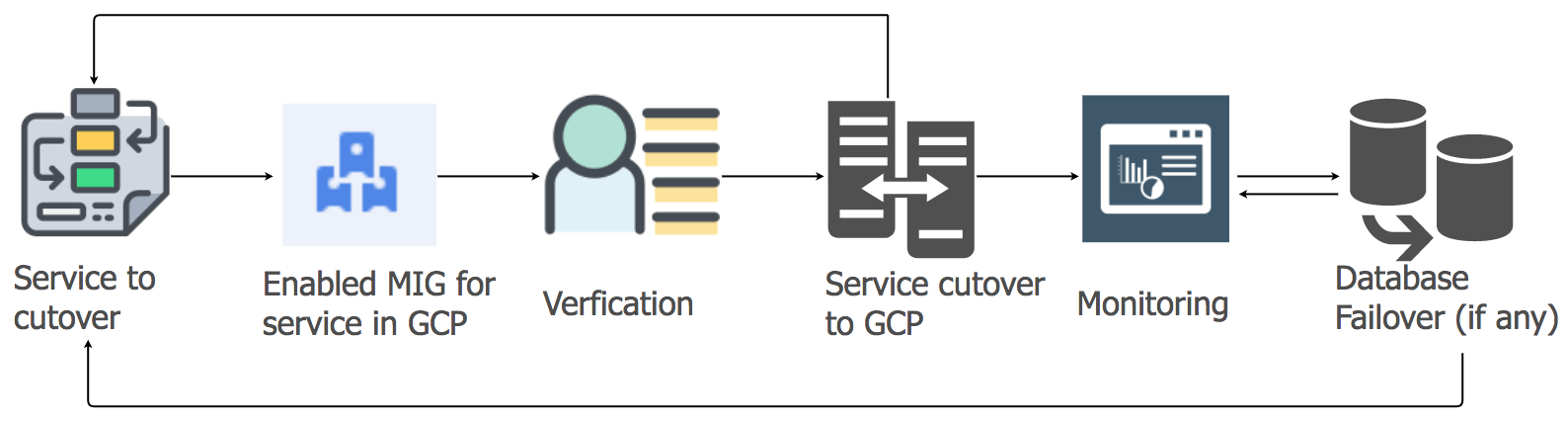
في الصباح ، مع زيادة نشاط المستخدم ، تابعنا بعناية جميع لوحات التحكم والمؤشرات لتحديد المشكلات بسرعة. نشأت بعض الصعوبات حقًا ، لكننا تمكنا من إزالتها بسرعة. كانت إحدى المشاكل بسبب قيود موازن التحميل الداخلي (ILB) ، والتي لا يمكنها التعامل مع أكثر من 20000 اتصال متزامن. ونحن بحاجة إلى 8 مرات أكثر! لذلك ، أضفنا ILBs إضافية إلى طبقة إدارة الاتصال الخاصة بنا.
في الساعات الأولى من ذروة الحمل بعد النقل ، قمنا بالتحكم في جميع المعلمات بعناية خاصة ، حيث تم نقل الحمولة الكاملة لمجموعة الرسائل إلى GCP. كانت هناك بعض الأخطاء البسيطة التي تعاملنا معها بسرعة كبيرة. عند ترحيل خدمات أخرى ، اتخذنا نفس النهج.
ترحيل تخزين الكائن:
نستخدم خدمة تخزين الكائن بشكل رئيسي بثلاث طرق.
⊹ تخزين ملفات الوسائط المرسلة إلى محادثة شخصية أو جماعية. يتم تحديد فترة الاحتفاظ من خلال سياسة إدارة دورة الحياة.
⊹ تخزين الصور والصور المصغرة لملف تعريف المستخدم.
⊹ تخزين ملفات الوسائط من قسمي "History" و "Timeline" والصور المصغرة المقابلة.
استخدمنا أداة نقل التخزين من Google لنسخ الكائنات القديمة من S3 إلى GCS. استخدمنا أيضًا MIG مخصصًا يستند إلى Kafka لنقل الكائنات من S3 إلى GCS عند الحاجة إلى منطق خاص.
تضمن الانتقال من S3 إلى GCS الخطوات التالية:
● في أول حالة استخدام لمخزن الكائنات ، بدأنا في كتابة بيانات جديدة إلى كل من S3 و GCS ، وبعد انتهاء الصلاحية بدأنا في قراءة البيانات من GCS باستخدام المنطق على جانب التطبيق. لا معنى لنقل البيانات القديمة ، وهذا النهج فعال من حيث التكلفة.
● بالنسبة لحالات الاستخدام الثانية والثالثة ، بدأنا في كتابة كائنات جديدة إلى GCS وقمنا بتغيير مسار قراءة البيانات بحيث يتم إجراء البحث لأول مرة في GCS وبعد ذلك فقط ، إذا لم يتم العثور على الكائن ، في S3.
لقد استغرق التخطيط لأشهر ، والتحقق من صحة المفهوم ، والتحضير والنموذج الأولي شهوراً ، ولكن بعد ذلك قررنا الانتقال وتنفيذه بسرعة كبيرة. قمنا بتقييم المخاطر وأدركنا أن الهجرة السريعة هي الأفضل وغير المحسوسة تقريبًا.
لقد ساعدنا هذا المشروع الواسع النطاق في الحصول على مكانة قوية وزيادة إنتاجية الفريق في العديد من المجالات ، نظرًا لأن معظم العمليات اليدوية في إدارة البنية التحتية السحابية كانت في الماضي الآن.
● أما بالنسبة للمستخدمين ، فقد تلقينا الآن كل ما هو ضروري لضمان أعلى جودة لخدمتهم. اختفى وقت التعطل تقريبًا ، ويتم تنفيذ الميزات الجديدة بشكل أسرع.
● يقضي فريقنا وقتًا أقل في مهام الصيانة ويمكنه التركيز على مشروعات الأتمتة وإنشاء أدوات جديدة.
● تمكنا من الوصول إلى مجموعة غير مسبوقة من الأدوات للعمل مع البيانات الضخمة ، بالإضافة إلى الوظائف الجاهزة للتعلم والتحليل الآلي. انظر التفاصيل هنا.
● إن التزام Google Cloud بالعمل مع مشروع Kubernetes مفتوح المصدر يتماشى أيضًا مع خطتنا التطويرية لهذا العام.