



تتناول هذه المقالة التحويلات الأكثر إثارة للاهتمام التي تقوم بها سلسلة من اثنين من
الناسخين (الأول يترجم رمز Python إلى رمز في
لغة البرمجة الجديدة 11 لتر ، والثاني يترجم الرمز إلى 11 لتر في C ++) ، ويقارن أيضًا الأداء مع أدوات التسريع الأخرى / تنفيذ كود Python (PyPy و Cython و Nuitka).
استبدال الشرائح \ الشرائح بنطاقات
الإشارة الصريحة للفهرسة من نهاية الصفيف
s[(len)-2] بدلاً من
s[-2] مطلوبة لإزالة الأخطاء التالية:
- عندما يكون ، على سبيل المثال ، مطلوبًا للحصول على الحرف السابق بواسطة
s[i-1] ، ولكن بالنسبة لـ i = 0 مثل هذا / هذا السجل بدلاً من خطأ سيعيد بصمت الحرف الأخير من السلسلة [ وعمليًا واجهت مثل هذا الخطأ - الالتزام ] . i = s.find(":") التعبير s[i:] بعد i = s.find(":") بشكل غير صحيح عندما لا يتم العثور على الحرف في السلسلة [ بدلاً من '' جزء من السلسلة بدءًا من الحرف الأول : ثم '' سيتم أخذ الحرف الأخير من السلسلة ] (وعمومًا ، أعتقد أن إرجاع -1 مع الدالة find() في Python غير صحيح أيضًا [ يجب إرجاع null / None [ وإذا كان -1 مطلوبًا ، فيجب كتابته بشكل صريح: i = s.find(":") ?? -1 ] ] )- لن تعمل كتابة
s[-n:] للحصول على آخر حرف n من السلسلة بشكل صحيح عندما تكون n = 0.
سلاسل عوامل المقارنة
للوهلة الأولى ، إنها ميزة بارزة في لغة Python ، ولكن من الناحية العملية يمكن التخلي عنها / الاستغناء عنها بسهولة باستخدام عامل التشغيل والنطاقات:
فهم القائمة
وبالمثل ، كما اتضح ، يمكنك رفض ميزة أخرى مثيرة للاهتمام لفهم قائمة Python.
في حين أن بعض
فهم القائمة يمجد ويفترض حتى التخلي عن `filter ()` و` map () ` ، وجدت أن:
في جميع الأماكن التي رأيت فيها فهمًا لقائمة Python ، يمكنك بسهولة الحصول عليها باستخدام الوظائف "filter ()` و "map ()`. dirs[:] = [d for d in dirs if d[0] != '.' and d != exclude_dir] dirs[:] = filter(lambda d: d[0] != '.' and d != exclude_dir, dirs) '[' + ', '.join(python_types_to_11l[ty] for ty in self.type_args) + ']' '[' + ', '.join(map(lambda ty: python_types_to_11l[ty], self.type_args)) + ']'
`filter ()` و `map ()` في 11l تبدو أجمل من Python dirs[:] = filter(lambda d: d[0] != '.' and d != exclude_dir, dirs) dirs = dirs.filter(d -> d[0] != '.' & d != @exclude_dir) '[' + ', '.join(map(lambda ty: python_types_to_11l[ty], self.type_args)) + ']' '['(.type_args.map(ty -> :python_types_to_11l[ty]).join(', '))']' outfile.write("\n".join(x[1] for x in fileslist if x[0])) outfile.write("\n".join(map(lambda x: x[1], filter(lambda x: x[0], fileslist)))) outfile.write(fileslist.filter(x -> x[0]).map(x -> x[1]).join("\n"))
وبالتالي ، فإن الحاجة إلى فهم القائمة في 11 لتر تختفي فعليًا [يتم استبدال استبدال القائمة مع filter() و / أو map() أثناء تحويل رمز Python إلى 11 لتر تلقائيًا ] .
قم بتحويل سلسلة if-elif-else للتبديل
على الرغم من أن Python لا يحتوي على بيان تبديل ، إلا أنه أحد أجمل التركيبات في 11 لتر ، ولذا قررت إدراج التبديل تلقائيًا:
للاستكمال ، إليك رمز C ++ الذي تم إنشاؤه switch (instr[i]) { case u'[': nesting_level++; break; case u']': if (--nesting_level == 0) goto break_; break; case u''': ending_tags.append(u"'"_S); break; // '' case u''': assert(ending_tags.pop() == u'''); break; }
تحويل القواميس الصغيرة إلى كود أصلي
ضع في اعتبارك هذا السطر من كود Python:
tag = {'*':'b', '_':'u', '-':'s', '~':'i'}[prev_char()]
على الأرجح ، هذا النوع من التسجيل ليس فعالًا جدًا
[ من حيث الأداء ] ، ولكنه ملائم للغاية.
في 11 لتر ، الإدخال المقابل لهذا الخط
[ والذي تم الحصول عليه بواسطة ناقل Python → 11l ] ليس مناسبًا فقط
[ ومع ذلك ، ليس أنيقًا كما هو الحال في Python ] ، ولكنه سريع أيضًا:
var tag = switch prev_char() {'*' {'b'}; '_' {'u'}; '-' {'s'}; '~' {'i'}}
يتم ترجمة السطر أعلاه إلى:
auto tag = [&](const auto &a){return a == u'*' ? u'b'_C : a == u'_' ? u'u'_C : a == u'-' ? u's'_C : a == u'~' ? u'i'_C : throw KeyError(a);}(prev_char());
[ سيتم تجميع استدعاء دالة لامدا بواسطة المترجم C ++ \ المضمنة أثناء عملية التحسين وستبقى فقط سلسلة المشغلين ?/: ]في حالة تعيين متغير ، يتم ترك القاموس كما يلي:
التقاط \ Ca التقاط المتغيرات الخارجية
في Python ، للإشارة إلى أن المتغير ليس محليًا ، ولكن يجب أخذه خارج
[ الوظيفة الحالية ] ، يتم استخدام الكلمة الأساسية غير المحلية
[ وإلا ، على سبيل المثال ، found = True سيتم التعامل معها على أنها إنشاء متغير محلي جديد found ، بدلاً من تعيين قيمة بالفعل المتغير الخارجي الموجود ] .
في 11l ، يتم استخدام البادئة @ لهذا:
C ++:
auto writepos = 0; auto write_to_pos = [..., &outfile, &writepos](const auto &pos, const auto &npos) { outfile.write(...); writepos = npos; };
المتغيرات العالمية
على غرار المتغيرات الخارجية ، إذا نسيت الإعلان عن متغير عام في Python
[ باستخدام الكلمة الرئيسية العامة ] ، فستحصل على خطأ غير مرئي:
كود 11l
[ يمين ] ، على عكس Python
[ يسار ] ، break_label_index خطأ 'متغير
break_label_index ' غير معلن في
break_label_index الترجمة.
فهرس / رقم بند الحاوية الحالي
أستمر في نسيان ترتيب المتغيرات التي ترجعها دالة Python التعددية {تأتي القيمة أولاً ، ثم الفهرس ، أو العكس بالعكس}. السلوك التناظري في Ruby -
each.with_index - أسهل بكثير للتذكر: مع الفهرس يعني أن الفهرس يأتي بعد القيمة وليس قبلها. ولكن في 11l ، يسهل تذكر المنطق:
الأداء
يتم استخدام
برنامج تحويل ترميز الكمبيوتر إلى HTML كبرنامج اختبار ، ويتم استخدام التعليمات البرمجية المصدر
للمقالة حول ترميز الكمبيوتر الشخصي كبيانات المصدر
[ نظرًا لأن هذه المقالة هي حاليًا أكبر المقالات المكتوبة على ترميز الكمبيوتر الشخصي ] ، ويتم تكرارها 10 مرات ، أي تم الحصول عليها من 48.8 كيلوبايت حجم ملف المقالة 488 كيلوبايت.
في ما يلي مخطط يوضح عدد المرات التي تكون فيها الطريقة المقابلة لتنفيذ كود Python أسرع من التنفيذ الأصلي
[ CPython ] :
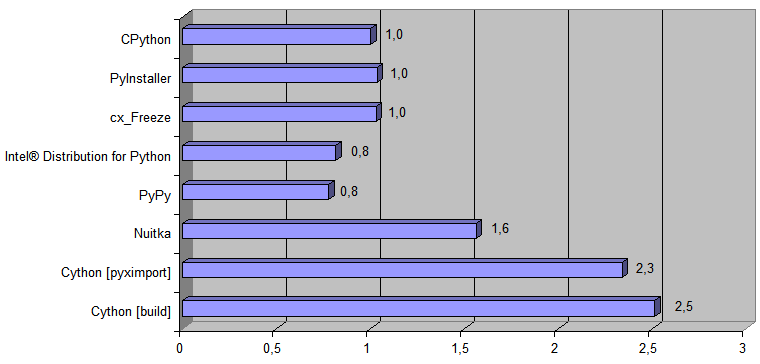
والآن أضف إلى الرسم البياني التنفيذ الذي تم إنشاؤه بواسطة Transpiler Python → 11l → C ++: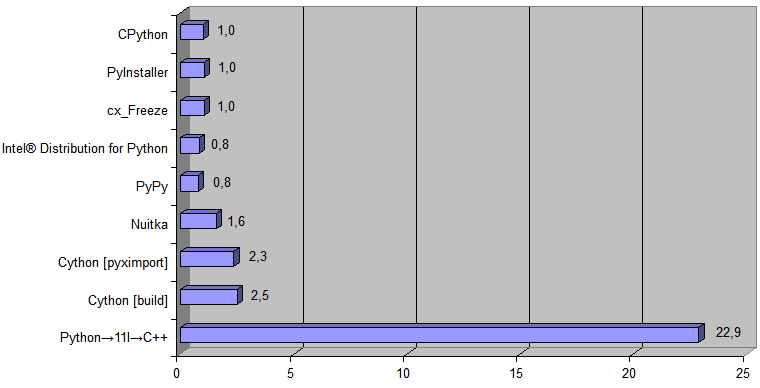
كان وقت التشغيل
[ وقت
تحويل ملف 488 كيلوبايت ] 868 مللي ثانية لـ CPython و 38 مللي ثانية لرمز C ++ الذي تم إنشاؤه
[ يتضمن هذا الوقت كامل [ أي ليس فقط العمل مع البيانات في ذاكرة الوصول العشوائي ] تشغيل البرنامج بواسطة نظام التشغيل وجميع المدخلات / الإخراج [ قراءة الملف المصدر [ .pq ] وحفظ الملف الجديد [ .html ] إلى القرص ] ] .
أردت أيضًا تجربة
Shed Skin ، لكنها لا تدعم الوظائف المحلية.
لا يمكن استخدام Numba أيضًا (يظهر خطأ "استخدام رمز تشغيل غير معروف LOAD_BUILD_CLASS").
هذا هو الأرشيف مع البرنامج المستخدم لمقارنة الأداء
[ ضمن Windows ] (يتطلب Python 3.6 أو أعلى وحزم Python التالية: pywin32، cython).
المصدر في Python وإخراج Transpilers -> 11l و 11 l -> C ++: