حول لعبة Montezuma Revenge على Habré لم تكتب كثيرًا. هذه لعبة كلاسيكية معقدة كانت تحظى بشعبية كبيرة في السابق ، ولكن الآن يتم لعبها إما من قبل من يثيرون مشاعر الحنين أو من قبل الباحثين الذين يصابون بالذكاء الاصطناعى.
في هذا الصيف ، تم
الإبلاغ عن أن DeepMind كان قادرًا على تعليم الذكاء الاصطناعي كيفية لعب ألعاب Atari ، بما في ذلك لعبة Montezuma Revenge. باستخدام مثال اللعبة نفسها ، قام مؤلفو OpenAI أيضًا
بتدريس تطورهم. الآن أوبر قد اتخذت مشروع مماثل.
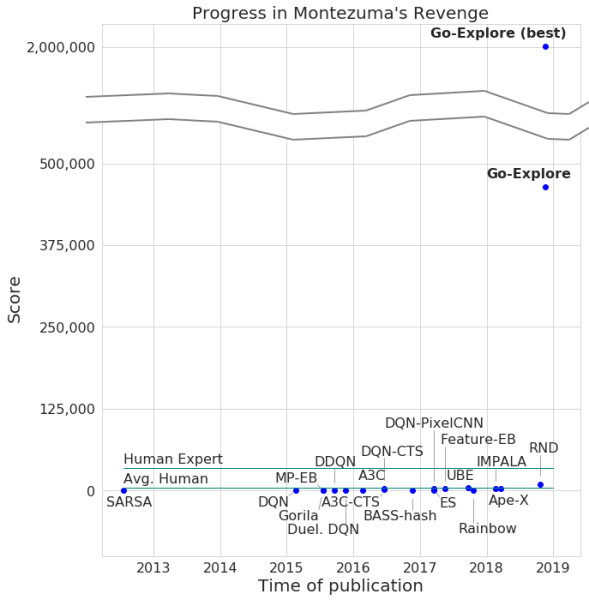
أعلن المطورون عن مرور اللعبة من خلال شبكتهم العصبية ، بحد أقصى قدره 2 مليون نقطة ، صحيح ، في المتوسط ، كسب النظام ما لا يزيد عن 400000 لكل محاولة. بالنسبة للممر ، وصل الكمبيوتر إلى المستوى 159.
بالإضافة إلى ذلك ، تعلمت Go-Explore كيفية اجتياز Pitfall ، مع نتيجة ممتازة متفوقة على اللاعب العادي ، ناهيك عن وكلاء AI الآخرين. عدد النقاط التي سجلها Go-Explore في هذه اللعبة هو 21000 نقطة.
الفرق بين Go-Explore و "زملائها" هو أن الشبكات العصبية لا تحتاج إلى إثبات اجتياز مستويات مختلفة للتدريب. يتعلم النظام كل شيء بنفسه أثناء اللعبة ، ويعرض نتائج أعلى بكثير من تلك التي تظهرها الشبكات العصبية التي تتطلب تدريبًا بصريًا. وفقًا لمطوري Go-Explore ، تختلف التقنية اختلافًا كبيرًا عن غيرها ، وقدراتها تسمح باستخدام الشبكة العصبية في عدد من المجالات ، بما في ذلك الروبوتات.
تجد معظم الخوارزميات صعوبة في التعامل مع لعبة Montezuma Revenge لأن اللعبة لا تحتوي على تعليقات واضحة جدًا. على سبيل المثال ، فإن الشبكة العصبية التي يتم "شحذها" لتلقي المكافآت في عملية اجتياز المستوى ستحارب العدو بدلاً من القفز على سلم يؤدي إلى الخروج وتتيح لك المضي قدمًا بشكل أسرع. تفضل أنظمة الذكاء الاصطناعى الأخرى الحصول على مكافأة هنا والآن ، وعدم المضي قدماً في "الأمل" للمزيد.
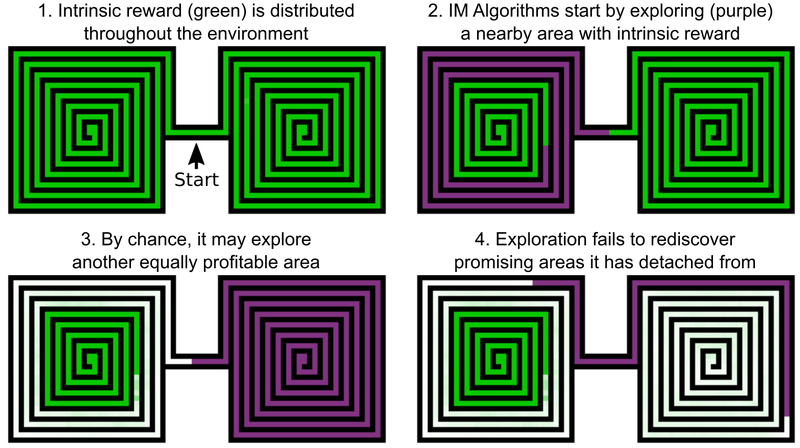
أحد قرارات مهندسي Uber هو إضافة مكافآت لاستكشاف عالم اللعبة ، ويمكن تسمية هذا الدافع الداخلي لمنظمة العفو الدولية. ولكن حتى عناصر الذكاء الاصطناعى ذات الدوافع الذاتية المضافة لا تحقق نتائج جيدة مع الانتقام و "السقوط" في مونتيزوما. المشكلة هي أن الذكاء الاصطناعي "ينسى" المواقع الواعدة بعد اجتيازها. ونتيجة لذلك ، فإن عالق الذكاء الاصطناعي عالق عند مستوى يبدو أنه تم التحقيق في كل شيء.
مثال على ذلك هو وكيل الذكاء الاصطناعي ، الذي يحتاج إلى دراسة متاهتين - الشرقية والغربية. يبدأ في المرور بواحد منهم ، ولكنه يقرر فجأة أنه سيكون من الممكن المرور بالثاني. بقيت الأولى تدرس بنسبة 50 ٪ ، والثانية بنسبة 100 ٪. ولا يعود العميل إلى المتاهة الأولى - ببساطة لأنه "نسي" أنه لم يكتمل حتى النهاية. وبما أن الممر بين المتاهة الشرقية والغربية قد تمت دراسته بالفعل ، ليس لدى منظمة العفو الدولية أي دافع للعودة.
يتضمن حل هذه المشكلة ، وفقًا لمطوري Uber ، مرحلتين: البحث والتضخيم. بالنسبة للجزء الأول ، يقوم الذكاء الاصطناعى هنا بإنشاء أرشيف لحالات اللعبة المختلفة - الخلايا (الخلايا) - والعديد من المسارات التي تؤدي إليها. تختار منظمة العفو الدولية الفرصة للحصول على أكبر عدد ممكن من النقاط عند اكتشاف المسار الأمثل.
الخلايا عبارة عن إطارات مبسطة للألعاب - 11 × 8 صور في ظلال رمادية بكثافة 8 بكسل ، مع إطارات تختلف بشكل كافٍ - حتى لا تمنع المزيد من مرور اللعبة.

ونتيجة لذلك ، تتذكر منظمة العفو الدولية المواقع الواعدة وتعود إليها بعد فحص أجزاء أخرى من عالم اللعبة. تعد "الرغبة" في استكشاف عالم الألعاب والمواقع الواعدة في Go-Explore أقوى من الرغبة في الحصول على جائزة هنا والآن. يستخدم Go-Explore أيضًا معلومات حول الخلايا التي يتم فيها تدريب وكيل AI. بالنسبة إلى Montezuma Revenge ، إنها بيانات بكسل مثل إحداثيات X و Y ، والغرفة الحالية ، وعدد المفاتيح التي تم العثور عليها.
تعمل مرحلة التضخيم كحماية ضد "الضوضاء". إذا كانت حلول الذكاء الاصطناعي غير مستقرة "للضوضاء" ، فإن الذكاء الاصطناعي يقويها بمساعدة شبكة عصبية متعددة المستويات ، تعمل على مثال الخلايا العصبية في الدماغ.

في الاختبارات ، يعمل Go-Explore جيدًا - في المتوسط ، يدرس الذكاء الاصطناعي 37 غرفة ويحل 65٪ من ألغاز المستوى الأول. هذا أفضل بكثير من المحاولات السابقة لغزو اللعبة - ثم درس الذكاء الاصطناعي في المتوسط 22 غرفة من المستوى الأول.

عند إضافة مكسب إلى الخوارزمية الحالية ، بدأت منظمة العفو الدولية في إكمال 29 مستوىًا في المتوسط (وليس الغرف) بمعدل متوسط قدره 469.209.
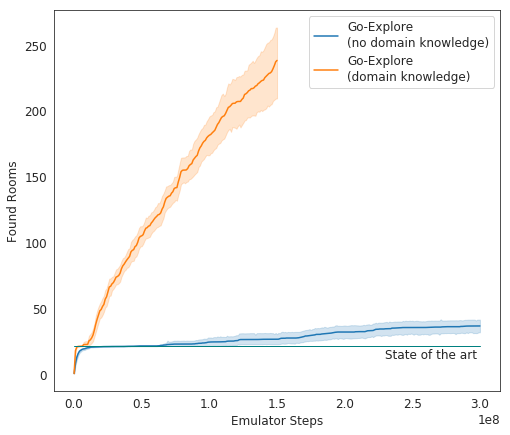
بدأ التجسيد النهائي لـ AI Uber في تشغيل اللعبة بشكل أفضل بكثير من عملاء AI الآخرين ، وأفضل من البشر. يعمل المطورون الآن على تحسين نظامهم بحيث يظهر نتيجة أكثر إثارة للإعجاب.