في 8 نوفمبر ، في القاعة الرئيسية لمؤتمر
HighLoad ++ 2018 ، في إطار قسم DevOps والعمليات ، تم إعداد تقرير بعنوان قواعد البيانات و Kubernetes. يتحدث عن توفر قواعد البيانات والمناهج العالية للتسامح مع Kubernetes ومعها ، فضلاً عن الخيارات العملية لوضع قواعد البيانات في مجموعات Kubernetes والحلول الحالية لهذا (بما في ذلك Stolon for PostgreSQL).

من الناحية التقليدية ، يسعدنا أن نقدم
مقطع فيديو مع تقرير (حوالي ساعة
وأكثر إفادة بكثير من المقال) والضغط الرئيسي في شكل نص. دعنا نذهب!
النظرية
ظهر هذا التقرير كإجابة على أحد أكثر الأسئلة شيوعًا التي طُرحت على مدار الأعوام القليلة الماضية بلا كلل في أماكن مختلفة: التعليقات على Habr أو YouTube ، والشبكات الاجتماعية ، إلخ. يبدو الأمر بسيطًا: "هل من الممكن تشغيل قاعدة البيانات في Kubernetes؟" ، وإذا أجبنا عادةً "عمومًا نعم ، ولكن ..." ، فمن الواضح أنه لم يكن هناك تفسير كاف لهؤلاء "بشكل عام" و "لكن" ، ولكن لملاءمتها في رسالة قصيرة لم تنجح.
ومع ذلك ، بالنسبة للمبتدئين ، ألخص المشكلة من "قاعدة البيانات [البيانات]" إلى الحالة ككل. إن نظام إدارة قواعد البيانات (DBMS) هو فقط حالة خاصة لقرارات الدولة ، يمكن تقديم قائمة أكثر اكتمالاً منها على النحو التالي:
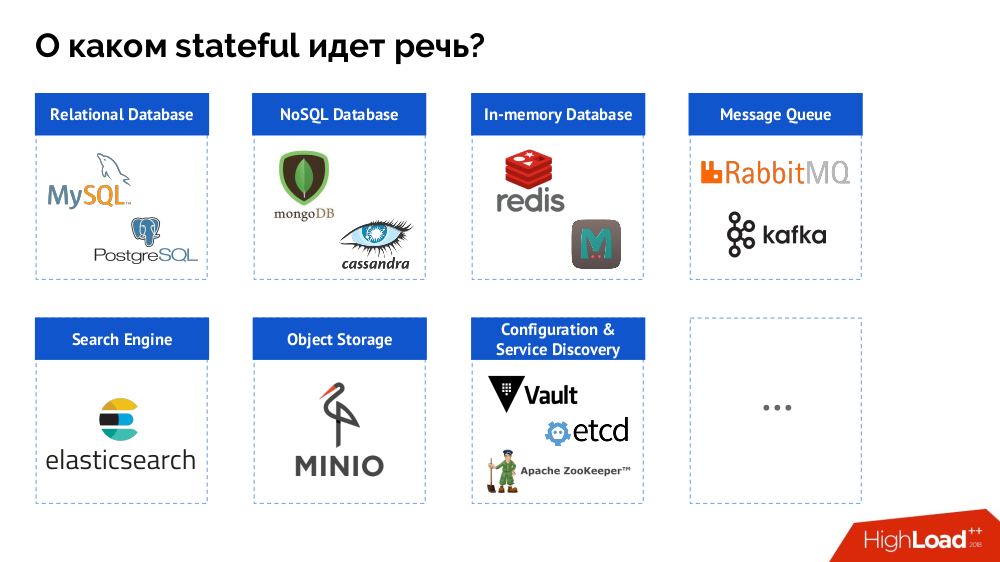
قبل النظر في حالات محددة ، سأتحدث عن ثلاث ميزات مهمة للعمل / استخدام Kubernetes.
1. Kubernetes عالية توافر الفلسفة
يعلم الجميع تشبيه "الحيوانات الأليفة
مقابل الماشية " ويفهم أنه إذا كانت Kubernetes قصة من عالم القطيع ، فإن قواعد إدارة قواعد البيانات الكلاسيكية هي حيوانات أليفة فقط.
وما شكل بنية "الحيوانات الأليفة" في النسخة "التقليدية"؟ مثال كلاسيكي لتثبيت MySQL هو النسخ المتماثل على خادمين حديديين مع توفير طاقة زائدة ، قرص ، شبكة ... وكل شيء آخر (بما في ذلك مهندس وأدوات مساعدة مختلفة) ، مما سيساعدنا على التأكد من أن عملية MySQL لن تفشل ، وإذا كانت هناك مشكلة في أي من العناصر الهامة لأنها مكونات ، سيتم احترام التسامح مع الخطأ:
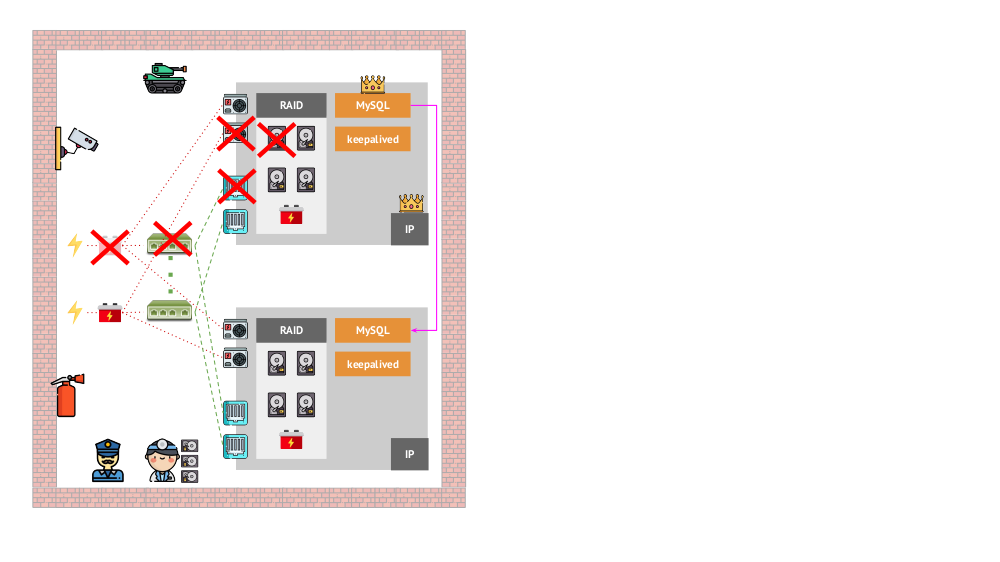
كيف سيكون نفس الشكل في Kubernetes؟ هنا ، عادة ما يكون هناك خوادم حديدية أكثر من ذلك بكثير ، فهي أبسط وليس لديها طاقة وشبكة زائدة عن الحاجة (بمعنى أن فقدان جهاز واحد لا يؤثر على أي شيء) - يتم دمج كل هذا في مجموعة. يتم توفير التسامح مع الخطأ بواسطة البرنامج: إذا حدث شيء ما للعقدة ، فإن Kubernetes يكتشف ويبدأ في تشغيل المثيلات اللازمة على العقدة الأخرى.
ما هي آليات توافر عالية في K8s؟
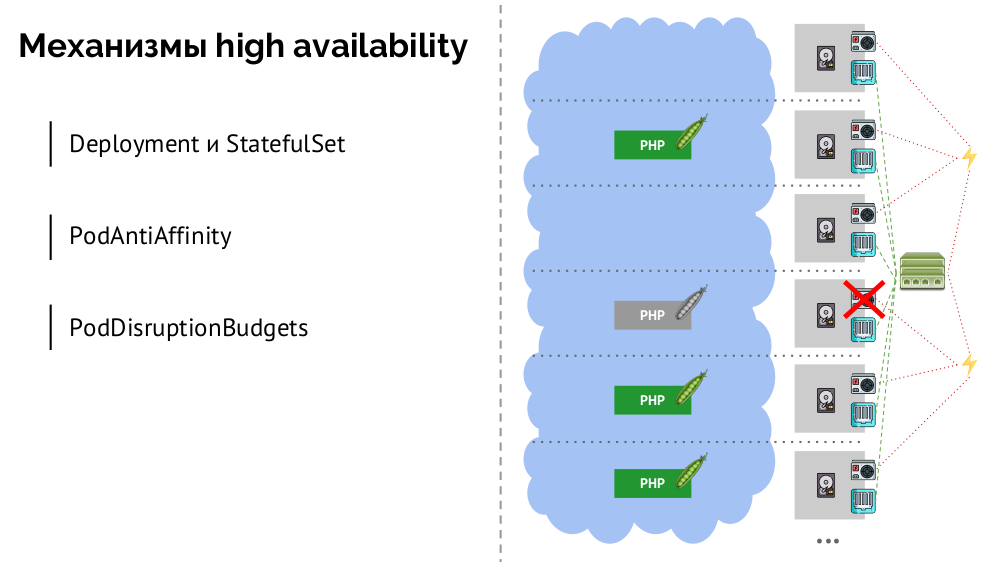
- تحكم هناك الكثير ، ولكن اثنين منها الرئيسية:
Deployment (للتطبيقات عديمي الجنسية) و StatefulSet (للتطبيقات ذات الحالة). يقومون بتخزين كل منطق الإجراءات المتخذة في حالة تعطل العقدة (عدم إمكانية الوصول إلى pod). PodAntiAffinity - القدرة على تحديد قرون محددة بحيث لا تكون على نفس العقدة.PodDisruptionBudgets - الحد من عدد حالات جراب التي يمكن إيقاف في نفس الوقت في حالة العمل المجدول.
2. ضمانات الاتساق Kubernetes
كيف يعمل نظام التسامح مع الأخطاء الفردية المألوف؟ خادومان (رئيسي ومستعد) ، أحدهما يتم الوصول إليه باستمرار بواسطة التطبيق ، والذي بدوره يستخدم من خلال موازن التحميل. ماذا يحدث في حالة وجود مشكلة في الشبكة؟
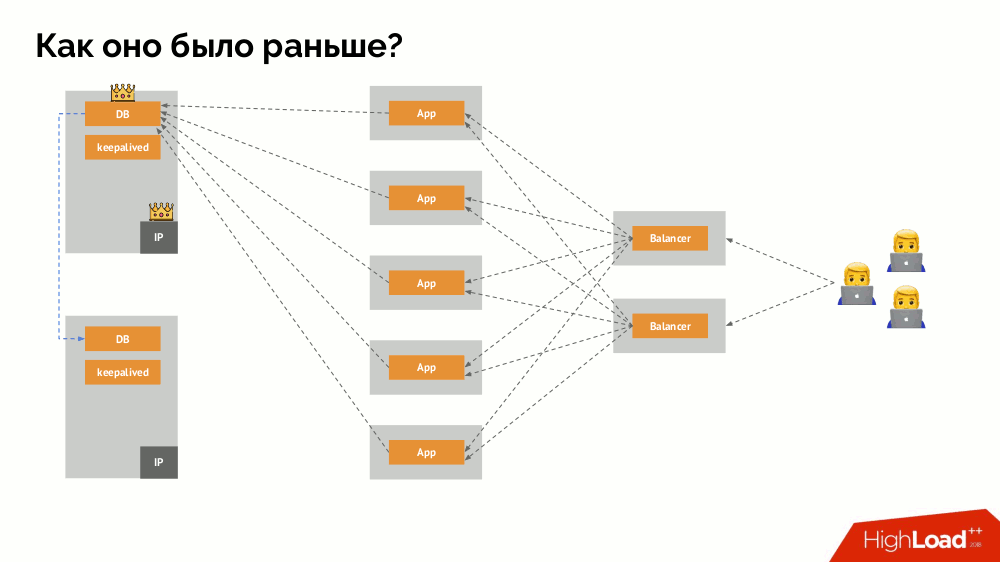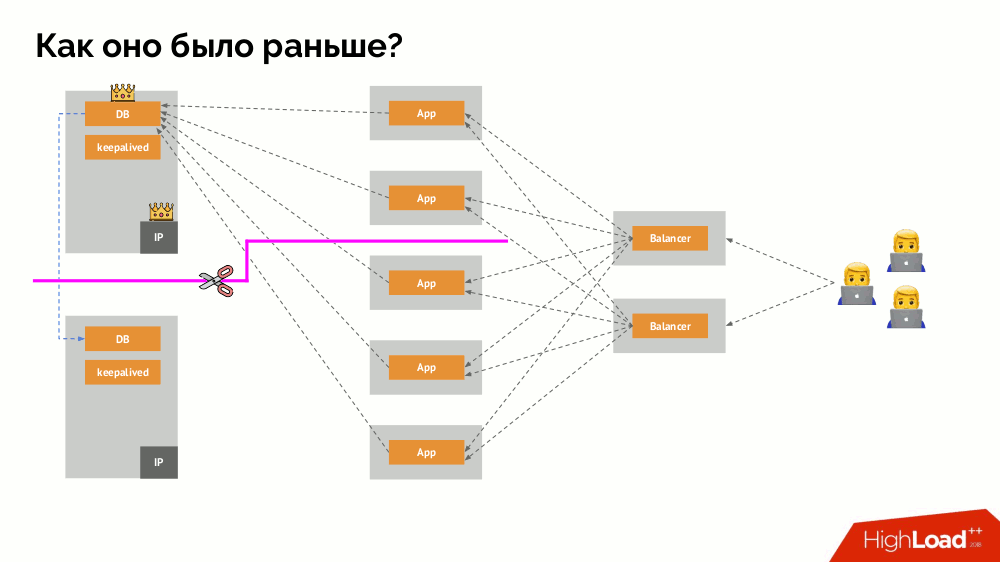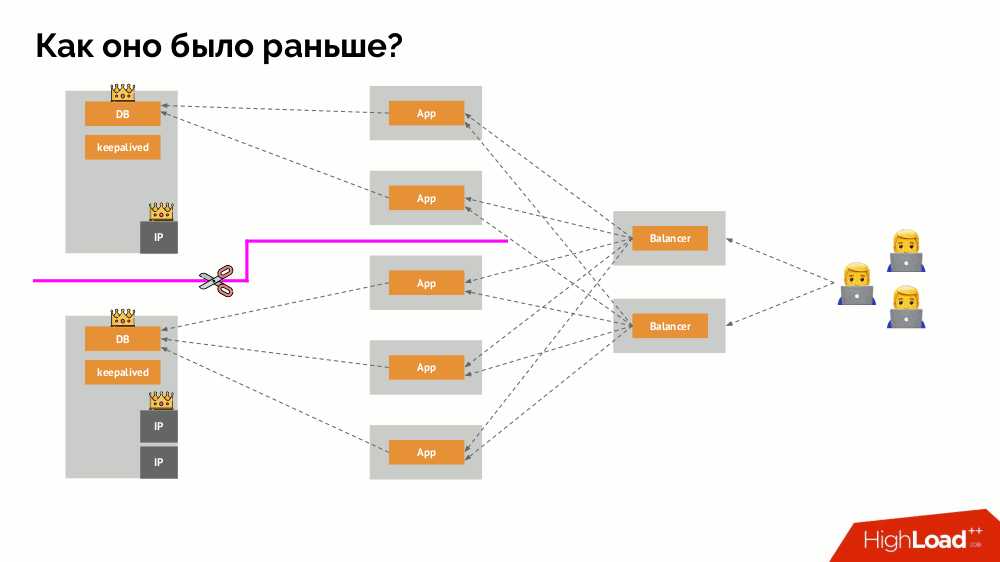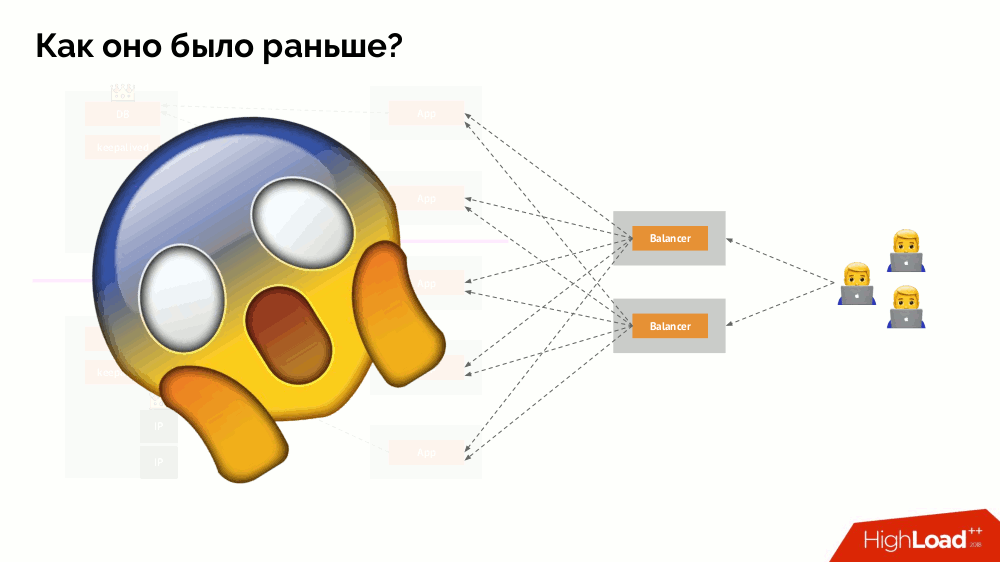
لعبة
انقسام عقول كلاسيكية: يبدأ التطبيق في الوصول إلى كلتا الحالتين DBMS ، كل واحدة منها تعتبر نفسها هي الحالة الرئيسية. لتجنب ذلك ، تم استبدال keepalived بـ corosync بثلاث حالات بالفعل لتحقيق النصاب القانوني عند التصويت للسيد. ومع ذلك ، حتى في هذه الحالة ، هناك مشكلات: إذا حاولت مثيل DBMS سقط "قتل نفسه" بكل طريقة ممكنة (إزالة عنوان IP ، ترجمة قاعدة البيانات إلى للقراءة فقط ...) ، فإن الجزء الآخر من الكتلة لا يعرف ما حدث للسيد - يمكن أن يحدث ، أن هذه العقدة لا تزال تعمل بالفعل وتطلب الحصول عليها ، مما يعني أننا لا نزال لا نستطيع تبديل المعالج.
لحل هذا الموقف ، هناك آلية لعزل العقدة من أجل حماية الكتلة بأكملها من عملية غير صحيحة - تسمى هذه العملية
المبارزة . يتلخص الجوهر العملي في حقيقة أننا نحاول ببعض الوسائل الخارجية "قتل" السيارة الساقطة. يمكن أن تكون الطرق مختلفة: من إيقاف تشغيل الجهاز عبر IPMI وحظر المنفذ على التبديل إلى الوصول إلى واجهة برمجة التطبيقات لمزود الخدمة السحابية ، إلخ. وفقط بعد هذه العملية يمكنك تبديل المعالج. هذا يضمن ضمانًا
على الأكثر يضمن لنا
الاتساق .
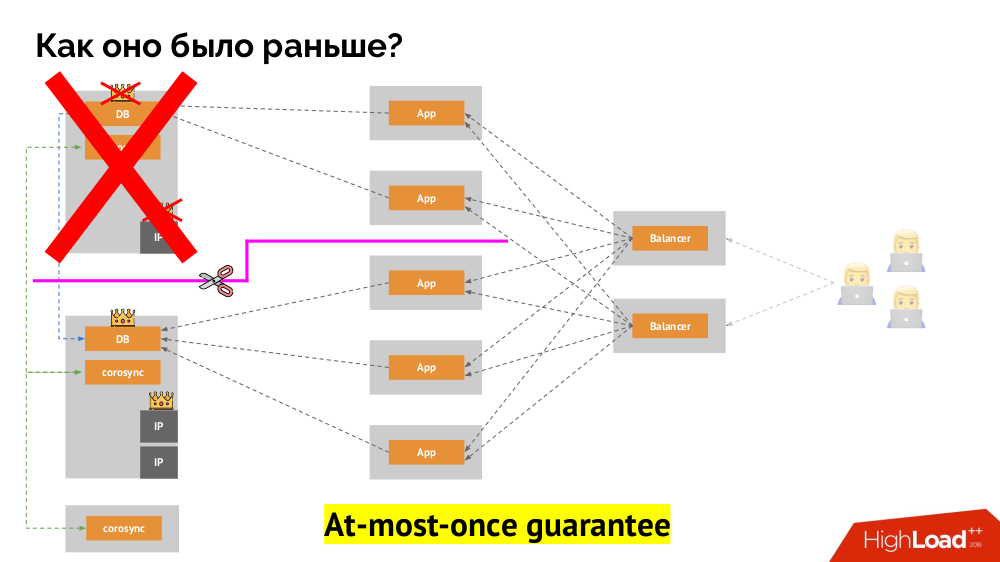
كيفية تحقيق الشيء نفسه في Kubernetes؟ للقيام بذلك ، هناك بالفعل وحدات تحكم مذكورة ، يختلف سلوكه في حالة عدم إمكانية الوصول إلى العقدة:
Deployment : "قيل لي أنه يجب أن يكون هناك 3 قرون ، والآن لا يوجد سوى 2 قرون - سأقوم بإنشاء واحدة جديدة" ؛StatefulSet : "قرنة ذهبت؟" سأنتظر: إما ستعود هذه العقدة ، أو ستخبرنا أن نقتلها " لا يتم إعادة إنشاء الحاويات نفسها (بدون إجراء المشغل). هكذا يتحقق الضمان نفسه.
ومع ذلك ، هنا ، في الحالة الأخيرة ، مطلوب سياج: نحن بحاجة إلى آلية تؤكد أن هذه العقدة قد ولت بالتأكيد. إن جعلها تلقائية أمر صعب للغاية (أولاً ، هناك حاجة إلى العديد من التطبيقات) ، وثانيًا ، والأسوأ من ذلك ، أنها تقتل العقد ببطء (يمكن أن يستغرق الوصول إلى IPMI ثواني أو عشرات ثوانٍ أو حتى دقائق). قليل من الناس راضون عن الانتظار في الدقيقة الواحدة لتحويل القاعدة إلى الرئيسي الجديد. ولكن هناك طريقة أخرى لا تتطلب آلية المبارزة ...
سأبدأ وصفه خارج Kubernetes. يستخدم موازن تحميل خاص يتم من خلاله الوصول إلى نظام إدارة قواعد البيانات. تكمن خصوصيته في حقيقة أن لديه خاصية الاتساق ، أي حماية ضد فشل الشبكة و split-brain ، لأنه يسمح لك بإزالة جميع الاتصالات للسيد الحالي ، انتظر المزامنة (النسخة المتماثلة) على عقدة أخرى والتبديل إليها. لم أجد مصطلحًا ثابتًا لهذا النهج ،
وسميته التبديل المستمر .
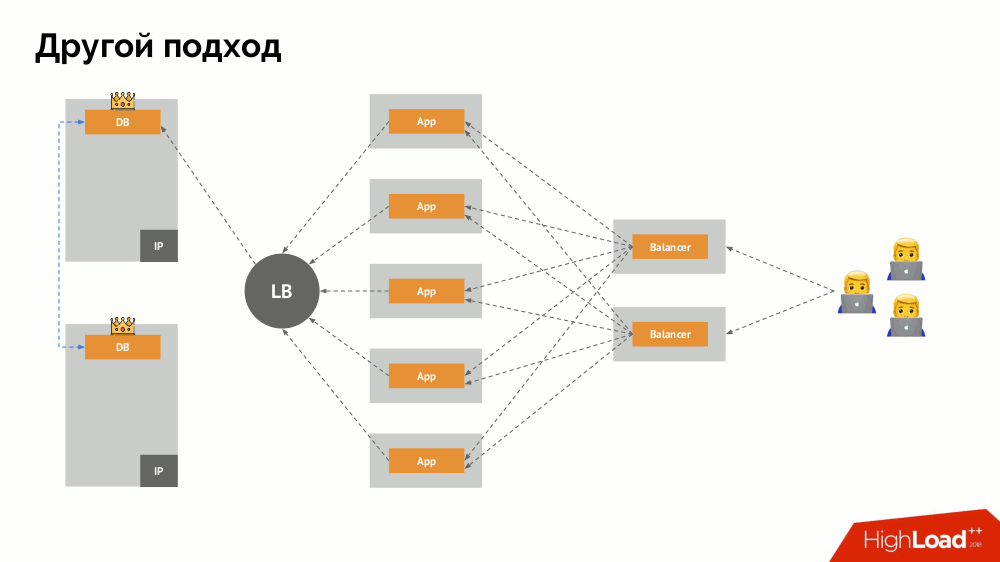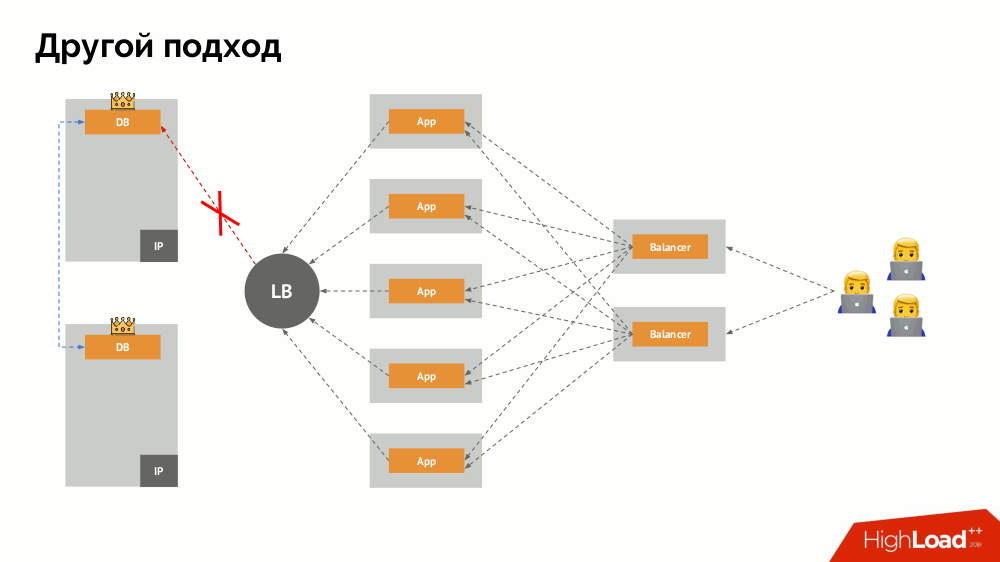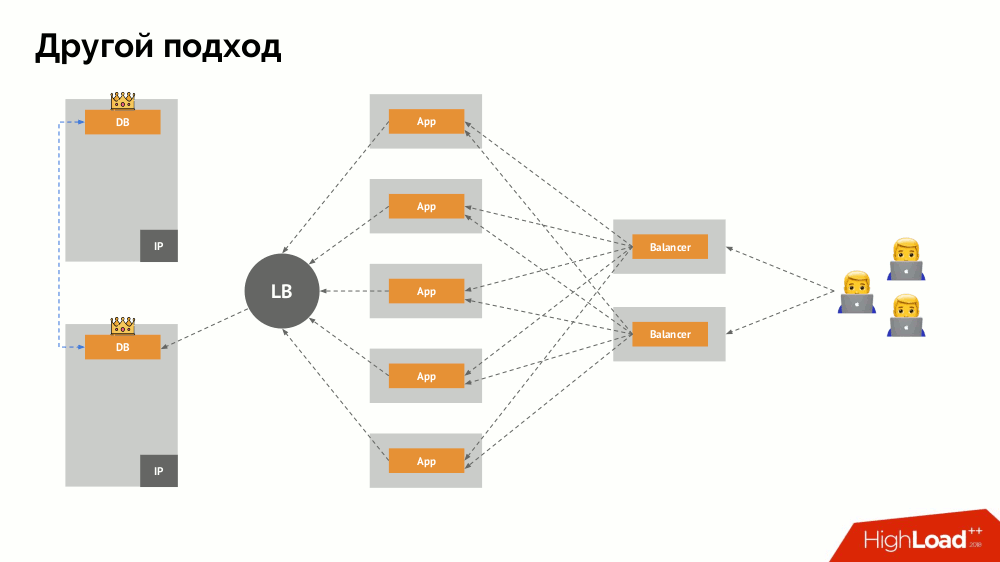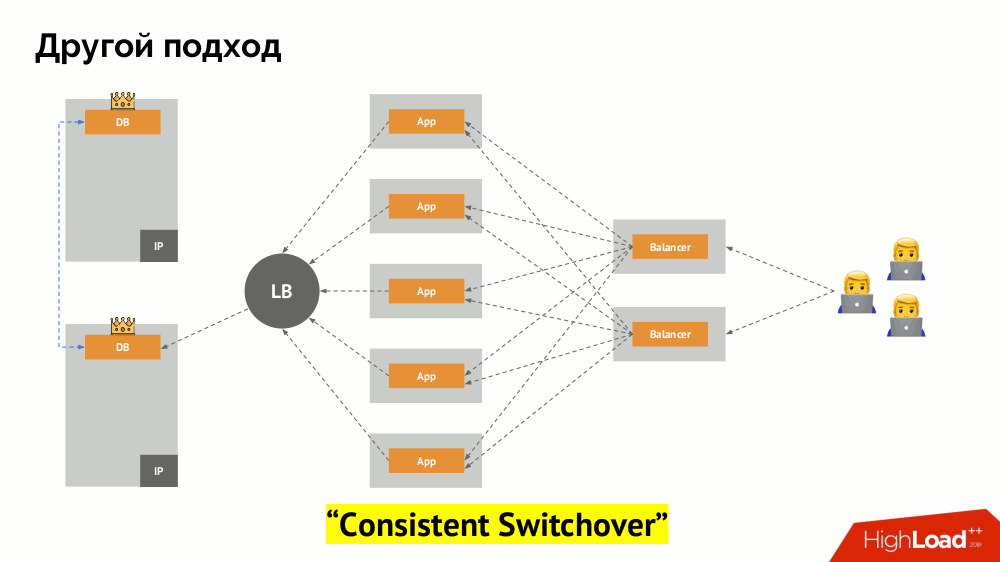
والسؤال الرئيسي معه هو كيفية جعلها عالمية ، وتوفير الدعم لكل من مقدمي سحابة والمنشآت الخاصة. لهذا ، تتم إضافة خوادم بروكسي إلى التطبيقات. سيقبل كل منهم الطلبات من التطبيق الخاص به (ويرسلها إلى DBMS) ، وسيتم جمع النصاب القانوني من كل منهم. حالما يفشل جزء من الكتلة ، فإن تلك الوكلاء الذين فقدوا النصاب القانوني يزيلون اتصالاتهم مباشرة بـ DBMS.
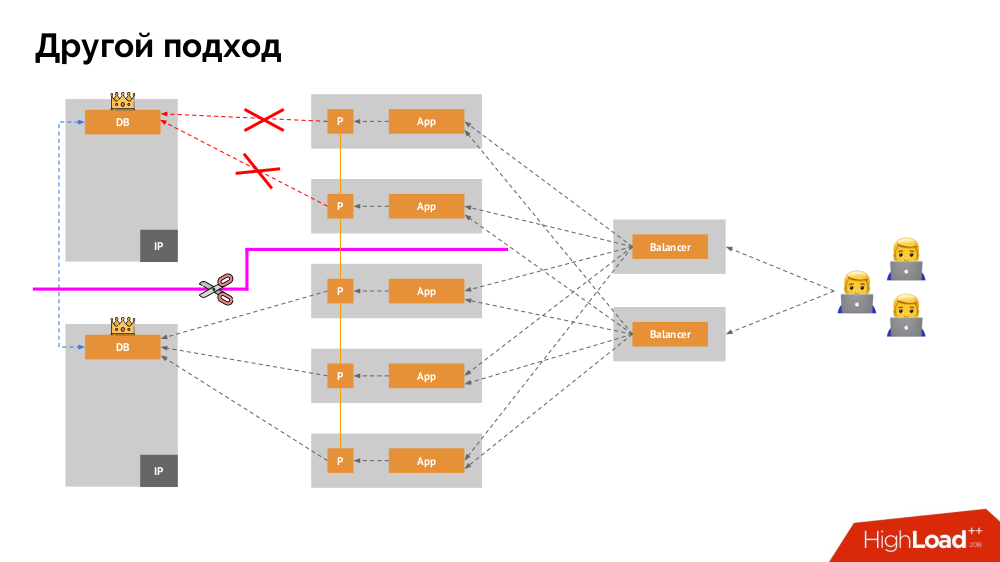
3. تخزين البيانات و Kubernetes
الآلية الرئيسية هي محرك الشبكة
Network Block Device (المعروف أيضًا باسم SAN) في تطبيقات مختلفة للخيارات السحابية المرغوبة أو المعدن العاري. ومع ذلك ، لن يعمل وضع قاعدة بيانات محمّلة (على سبيل المثال ، MySQL ، والتي تتطلب 50 ألف IOPS) في السحابة (AWS EBS) بسبب
الكمون .
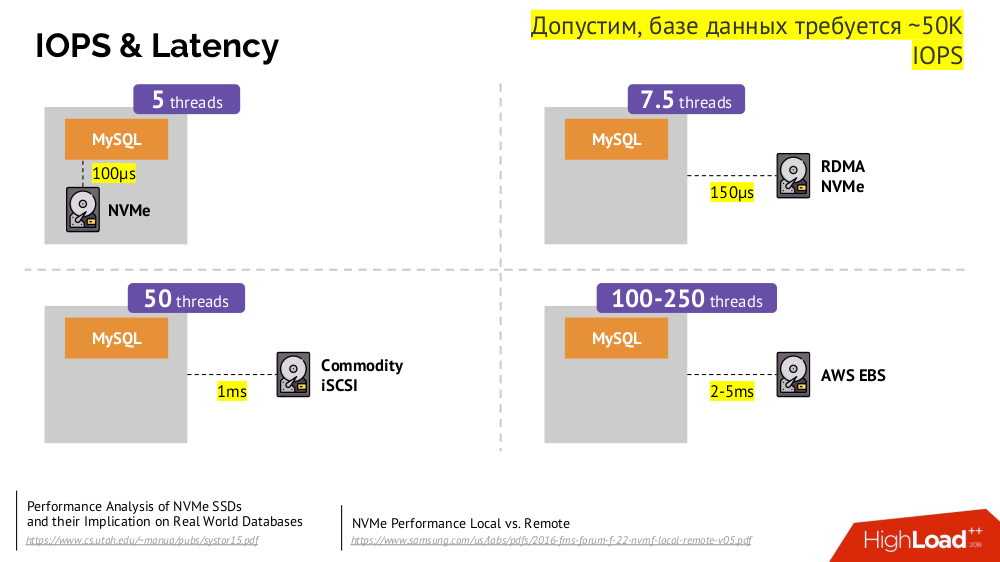
Kubernetes لمثل هذه الحالات لديه القدرة على توصيل القرص الصلب
المحلي -
التخزين المحلي . في حالة حدوث عطل (القرص لم يعد متوفراً في pod) ، فسنضطر إلى إصلاح هذا الجهاز - على غرار المخطط الكلاسيكي في حالة فشل خادم موثوق واحد.
ينتمي كلا الخيارين (
Network Block Device and
Local Storage ) إلى فئة
ReadWriteOnce : لا يمكن تركيب التخزين في مكانين (قرون) - لهذا القياس ، ستحتاج إلى إنشاء قرص جديد وتوصيله بقرنة جديدة (توجد آلية K8s مدمجة لهذا) ، ثم قم بملء البيانات اللازمة (تم القيام به بالفعل بواسطة قواتنا).
إذا كنا بحاجة إلى وضع
ReadWriteMany ، فإن تطبيقات
نظام ملفات الشبكة (أو NAS) متوفرة: بالنسبة إلى السحابة العامة ، فهذه هي
AzureFile و
AWSElasticFileSystem ،
AWSElasticFileSystem الخاصة بها CephFS و Glusterfs لمحبي الأنظمة الموزعة ، وكذلك NFS.

الممارسة
1. مستقل
يدور هذا الخيار حول الحالة التي لا يمنعك فيها أي شيء من بدء تشغيل DBMS في وضع خادم منفصل مع وحدة تخزين محلية. ليس هناك شك في توفر عالية ... على الرغم من أنه يمكن أن يكون إلى حد ما (أي ما يكفي لهذا التطبيق) تنفيذها على مستوى الحديد. هناك العديد من الحالات لهذا التطبيق. بادئ ذي بدء ، هذه كلها أنواع من بيئات التدريج والتطور ، ولكن ليس فقط: الخدمات الثانوية تقع هنا أيضًا ، وتعطيلها لمدة 15 دقيقة ليس أمرًا بالغ الأهمية. في Kubernetes ، يتم تطبيق هذا بواسطة
StatefulSet مع جراب واحد:
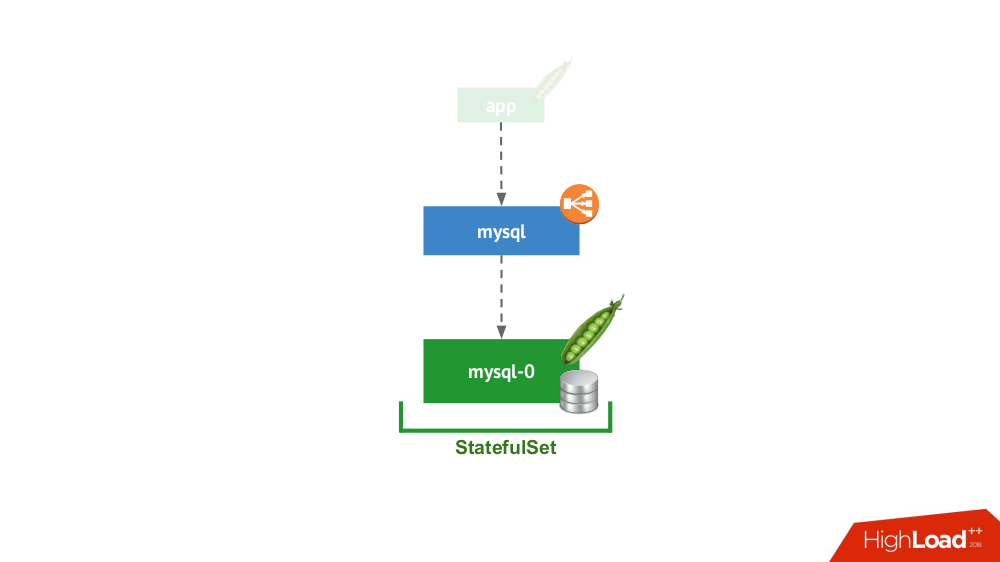
بشكل عام ، يعد هذا خيارًا قابلاً للتطبيق ، والذي ، من وجهة نظري ، ليس له أي سلبيات مقارنةً بتثبيت DBMS على جهاز افتراضي منفصل.
2. منسوخ الزوج مع التبديل اليدوي
StatefulSet استخدام
StatefulSet مرة أخرى ، لكن المخطط العام يبدو كما يلي:
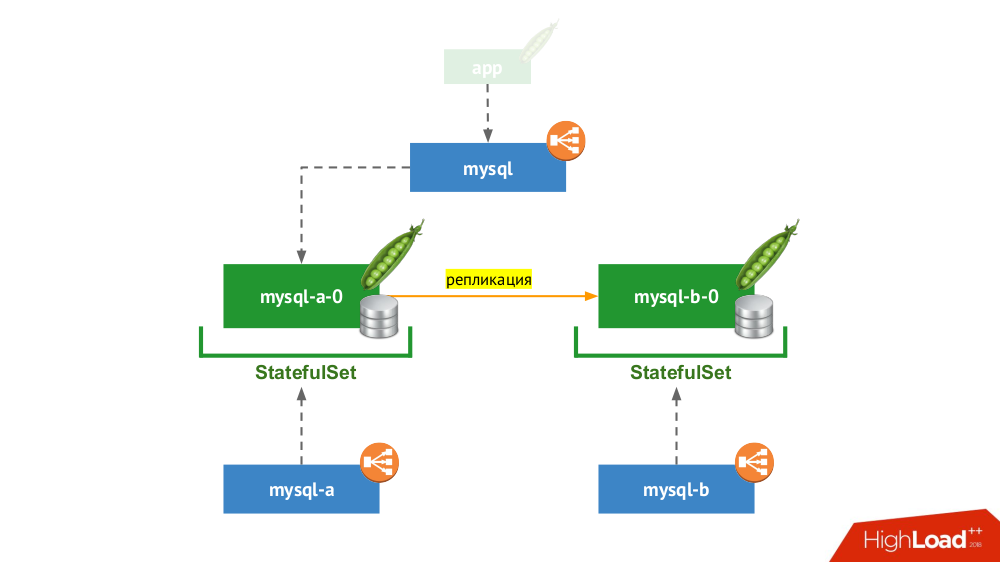
إذا تعطل أحد العقد (
mysql-a-0 ) ، فلن تحدث المعجزة ، ولكن لدينا نسخة متماثلة (
mysql-b-0 ) يمكننا تبديل حركة المرور إليها. في هذه الحالة ، حتى قبل تبديل حركة المرور ، من المهم ألا ننسى ليس فقط إزالة طلبات DBMS من خدمة
mysql ، ولكن أيضًا لتسجيل الدخول إلى DBMS يدويًا والتأكد من اكتمال جميع الاتصالات (قتلهم) ، وكذلك الانتقال إلى العقدة الثانية من DBMS وإعادة تكوين النسخة المتماثلة في الاتجاه المعاكس.
إذا كنت تستخدم حاليًا الإصدار الكلاسيكي مع خادمين (master + standby) دون
الفشل التلقائي ، فإن هذا الحل هو المكافئ في Kubernetes. مناسبة ل MySQL و PostgreSQL و Redis وغيرها من المنتجات.
3. التحجيم قراءة الحمل
في الواقع ، هذه الحالة ليست مفيدة ، لأننا نتحدث فقط عن القراءة. هنا ، يقع خادم DBMS الرئيسي خارج المخطط المدروس ، وفي إطار Kubernetes ، يتم إنشاء "مجموعة من خوادم الرقيق" ، وهي للقراءة فقط. تعتمد الآلية العامة - استخدام حاويات البداية لملء بيانات قواعد البيانات على كل حافظة جديدة من هذه المزرعة (باستخدام مكب حار أو المعتاد مع إجراءات إضافية ، إلخ - على نظام إدارة قواعد البيانات المستخدمة). للتأكد من أن كل مثيل لا يتخلف عن درجة الماجستير ، يمكنك استخدام اختبارات الثقل.

4. العميل الذكي
إذا قمت بإنشاء
StatefulSet من ثلاثة ملفات ، فإن Kubernetes تقدم خدمة خاصة لن تحقق التوازن بين الطلبات ، ولكنها ستقوم بإنشاء كل حافظة لمجالها الخاص. سيكون العميل قادرًا على العمل معهم إذا كان هو نفسه قادرًا على المشاركة والتكرار.
ليس عليك أن تذهب بعيدًا على سبيل المثال: هذه هي الطريقة التي يعمل بها تخزين الجلسة في PHP. لكل طلب جلسة ، يتم تقديم الطلبات في وقت واحد لجميع الخوادم ، وبعد ذلك يتم اختيار الإجابة الأكثر صلة منها (على غرار سجل).
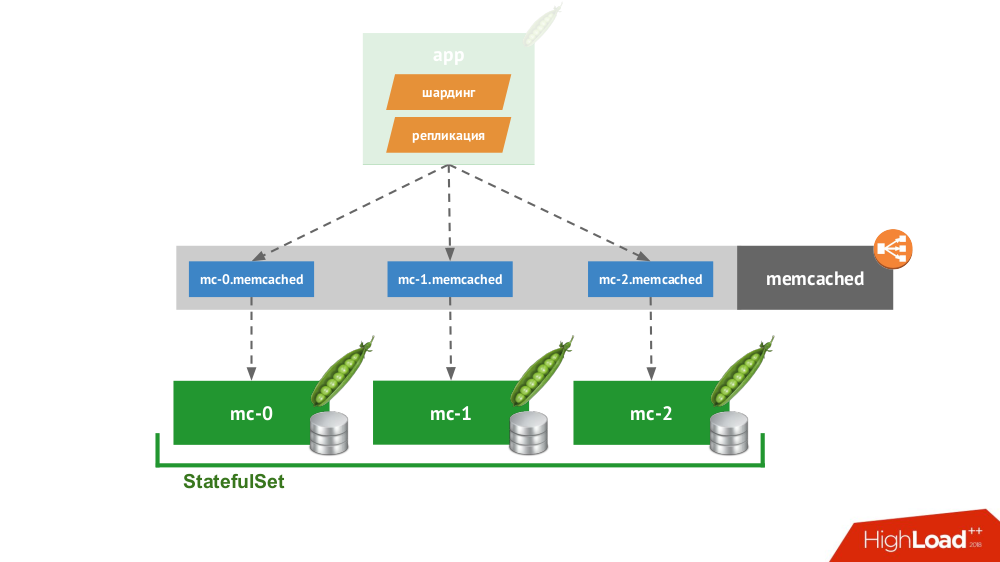
5. الحلول السحابية الأصلية
هناك العديد من الحلول التي تركز في البداية على فشل العقد ، أي هم أنفسهم يمكن أن تفعل
الفشل واسترداد العقد ، وتوفير ضمانات
الاتساق . هذه ليست قائمة كاملة بها ، ولكنها جزء فقط من الأمثلة الشائعة:

يتم وضع كل منهم ببساطة في
StatefulSet ، وبعد ذلك تجد العقد بعضها البعض وتشكل كتلة. تختلف المنتجات نفسها في كيفية تنفيذها لثلاثة أشياء:
- كيف تتعلم العقد عن بعضها البعض؟ هناك طرق مثل API Kubernetes ، وسجلات DNS ، والتكوين الثابت ، والعقد المتخصصة (البذور) ، واكتشاف خدمة الطرف الثالث ...
- كيف يتصل العميل؟ من خلال موازن التحميل الذي يوزع على المضيفين ، أو يحتاج العميل إلى معرفة جميع المضيفين ، وسوف يقرر كيفية المتابعة.
- كيف يتم القياس الأفقي؟ بأي حال من الأحوال ، كاملة أو صعبة / مع قيود.
بغض النظر عن الحلول المختارة لهذه القضايا ، تعمل جميع هذه المنتجات بشكل جيد مع Kubernetes ، لأنها تم إنشاؤها أصلاً كـ "قطيع"
(ماشية) .
6. Stolon بوستجرس
يتيح لك
Stolon بالفعل تحويل برنامج PostgreSQL ، الذي تم إنشاؤه
كحيوان أليف ، إلى
ماشية . كيف يتحقق هذا؟
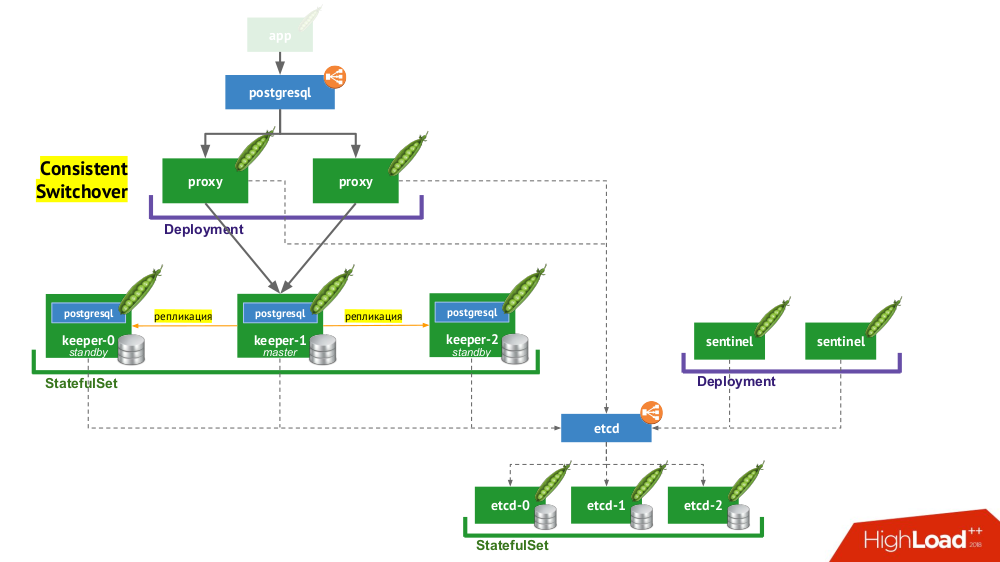
- أولاً ، نحتاج إلى اكتشاف الخدمة ، الذي قد يكون دوره وما إلى ذلك (تتوفر خيارات أخرى) - يتم وضع مجموعة منها في
StatefulSet . - جزء آخر من البنية التحتية هو
StatefulSet مع مثيلات PostgreSQL. بالإضافة إلى قاعدة بيانات نظام إدارة قواعد البيانات (DBMS) ، بجانب كل عملية تثبيت أيضًا مكون يسمى keeper ، يقوم بإجراء تكوين نظام إدارة قواعد البيانات. - يتم نشر مكون آخر ، الحارس ، كنشر ومراقبة تكوين الكتلة. هو الذي يقرر من سيكون السيد والاستعداد ، يكتب هذه المعلومات إلى etcd. ويقر keeper البيانات من etcd ويقوم بتنفيذ إجراءات تتوافق مع الوضع الحالي مع مثيل PostgreSQL.
- مكون آخر تم نشره في
Deployment ويواجه مثيلات PostgreSQL ، الوكيل ، هو تنفيذ نمط التبديل المتسق المذكور سابقًا. هذه المكونات متصلة بـ etcd ، وفي حالة فقد هذا الاتصال ، يقتل الوكيل على الفور الاتصالات الصادرة ، لأنه من هذه اللحظة لا يعرف دور خادمه (هل هو الآن رئيسي أم في وضع الانتظار؟). - أخيرًا ، تواجه مثيلات الوكيل
LoadBalancer LoadBalancer المعتادة.
الاستنتاجات
فهل من الممكن أن يكون مقرها في Kubernetes؟ نعم ، بالطبع ، من الممكن ، في بعض الحالات ... وإذا كان ذلك مناسبًا ، فسيتم ذلك مثل (راجع سير العمل Stolon) ...
يعلم الجميع أن التكنولوجيا تتطور في الأمواج. في البداية ، قد يكون من الصعب جدًا استخدام أي جهاز جديد ، ولكن بمرور الوقت ، يتغير كل شيء: تصبح التكنولوجيا متاحة. إلى أين نحن ذاهبون؟ نعم ، سيبقى في الداخل ، لكننا لا نعرف كيف ستعمل. Kubernetes تعمل بنشاط على تطوير
المشغلين . لا يوجد الكثير منهم حتى الآن ، وهم ليسوا على ما يرام ، ولكن هناك حركة في هذا الاتجاه.
أشرطة الفيديو والشرائح
فيديو من الأداء (حوالي ساعة):
عرض التقرير:
ملحوظة: وجدنا أيضًا على شبكة الإنترنت نصًا قصيرًا جدًا (!) قصيرًا من هذا التقرير - شكرًا لنيكولاي فولينكين.
PPS
تقارير أخرى على مدونتنا:
قد تكون مهتمًا أيضًا بالمنشورات التالية: