Ceph عبارة عن تخزين كائن مصمم للمساعدة في إنشاء كتلة فشل. لا يزال ، الفشل يحدث. كل شخص يعمل مع Ceph يعرف الأسطورة عن CloudMouse أو Rosreestr. لسوء الحظ ، ليس من المعتاد أن نتشارك معنا في تجربة سلبية ، فغالبًا ما تتراكم أسباب الفشل ، ولا تسمح للأجيال القادمة بالتعلم من أخطاء الآخرين.
حسنًا ، دعنا ننشئ مجموعة اختبار ، ولكن بالقرب من المجموعة الحقيقية ، ونحلل الكارثة بالعظام. سنقوم بقياس جميع عمليات سحب الأداء ، والعثور على تسرب الذاكرة ، وتحليل عملية استرداد الخدمة. وكل هذا تحت قيادة Artemy Kapitula ، الذي قضى ما يقرب من عام في دراسة المزالق ، تسبب في فشل أداء المجموعة عند مستوى الصفر والكمون في عدم القفز إلى القيم غير اللائقة. وحصلت على رسم بياني أحمر ، وهو أفضل بكثير.
بعد ذلك ، ستجد نسخة فيديو
ونصية لأحد أفضل تقارير
DevOpsConf Russia 2018.
عن المتحدث: مهندس نظام أرتيمي كابيتولا RCNTEC. تقدم الشركة حلول الاتصال الهاتفي عبر بروتوكول الإنترنت (التعاون ، وتنظيم مكتب بعيد ، وأنظمة التخزين المعرفة بالبرمجيات وأنظمة إدارة وتوزيع الطاقة). تعمل الشركة بشكل رئيسي في قطاع المؤسسات ، وبالتالي فهي غير معروفة في سوق DevOps. ومع ذلك ، فقد تراكمت بعض الخبرة مع Ceph ، والتي تستخدم في العديد من المشاريع كعنصر أساسي في البنية التحتية للتخزين.
Ceph هو مستودع المعرفة بواسطة البرامج مع العديد من مكونات البرنامج.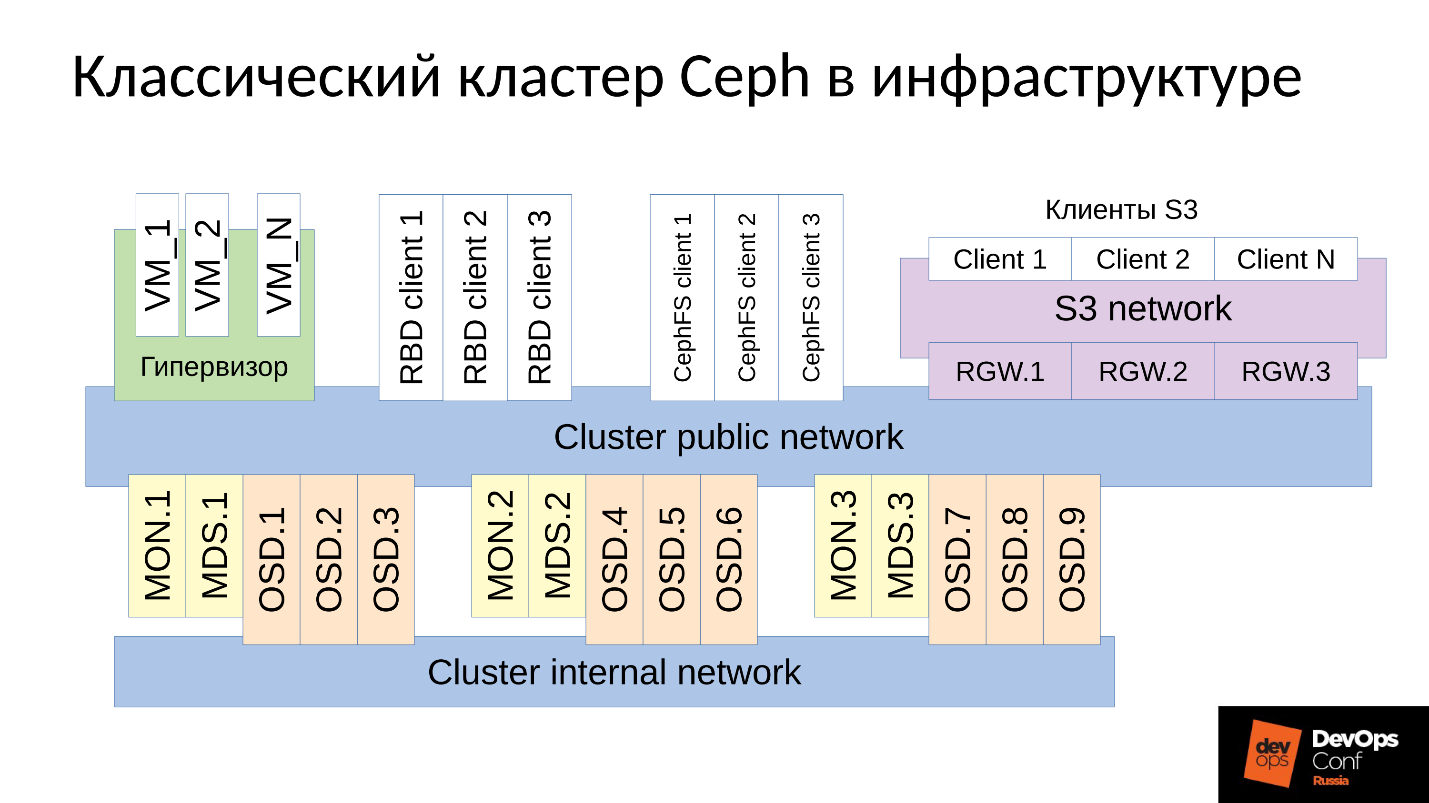
في المخطط:
- المستوى العلوي هو شبكة الكتلة الداخلية التي من خلالها تتواصل الكتلة نفسها ؛
- المستوى الأدنى - في الواقع Ceph - هو مجموعة من شياطين Ceph الداخلية (MON ، MDS و OSD) التي تخزن البيانات.
يتم نسخ كل البيانات ، كقاعدة عامة ، في المخطط ، قمت بتحديد ثلاث مجموعات عن عمد ، كل منها يحتوي على ثلاث واجهات OSD ، وعادةً ما تحتوي كل مجموعة من هذه المجموعات على نسخة متماثلة واحدة من البيانات. نتيجة لذلك ، يتم تخزين البيانات في ثلاث نسخ.
شبكة نظام المجموعة ذات المستوى الأعلى هي الشبكة التي يستطيع عملاء Ceph من خلالها الوصول إلى البيانات. من خلاله ، يتواصل العملاء مع الشاشة ، مع MDS (من يحتاج إليها) ومع OSD. كل عميل يعمل مع كل OSD ومع كل جهاز مستقل. وبالتالي ، فإن
النظام يخلو من نقطة واحدة من الفشل ، وهو السرور للغاية.
الزبائن
● عملاء S3
S3 هو API ل HTTP. يعمل عملاء S3 عبر HTTP والاتصال بمكونات Ceph Rados Gateway (RGW). هم دائما تقريبا التواصل مع مكون من خلال شبكة مخصصة. تستخدم هذه الشبكة (التي أسميتها شبكة S3) HTTP فقط ، والاستثناءات نادرة.
● برنامج Hypervisor مع الأجهزة الافتراضية
غالبًا ما يتم استخدام هذه المجموعة من العملاء. وهي تعمل مع الشاشات ومع OSD ، والتي يتلقون منها معلومات عامة حول حالة الكتلة وتوزيع البيانات. بالنسبة للبيانات ، يذهب هؤلاء العملاء مباشرةً إلى شياطين OSD من خلال شبكة Cluster العامة.
● عملاء RBD
هناك أيضًا مضيفو BR للمعادن ، وهم عادةً Linux. هم عملاء RBD والحصول على إمكانية الوصول إلى الصور المخزنة داخل كتلة Ceph (صور قرص الجهاز الظاهري).
● عملاء CephFS
المجموعة الرابعة من العملاء ، والتي لا يزال العديد منهم لا يزالون لديهم اهتمام متزايد ، هم عملاء نظام ملفات نظام المجموعة CephFS. يمكن تثبيت نظام مجموعة CephFS في وقت واحد من العديد من العقد ، وجميع العقد الوصول إلى نفس البيانات ، والعمل مع كل OSD. وهذا يعني ، لا توجد بوابات على هذا النحو (سامبا ، NFS وغيرها). المشكلة هي أن مثل هذا العميل لا يمكن إلا أن يكون Linux ، ونسخة حديثة إلى حد ما.

تعمل شركتنا في سوق الشركات ، وهناك يحكم الكرة ESXi و HyperV وغيرها. وفقًا لذلك ، فإن مجموعة Ceph ، التي تُستخدم بطريقة ما في قطاع الشركات ، مطلوبة لدعم التقنيات المناسبة. لم يكن هذا كافيًا بالنسبة لنا في Ceph ، لذلك كان يتعين علينا تحسين وتوسيع نظام Ceph باستخدام مكوناتنا ، وفي الواقع ، قمنا ببناء شيء أكثر من Ceph ، النظام الأساسي الخاص بنا لتخزين البيانات.
بالإضافة إلى ذلك ، لا يعمل العملاء في قطاع الشركات على نظام Linux ، ولكن معظمهم من Windows ، وأحيانًا Mac OS ، لا يمكنهم الذهاب إلى نظام Ceph بأنفسهم. يجب عليهم المرور عبر عبّارات ، والتي تصبح في هذه الحالة اختناقات.
كان علينا أن نضيف كل هذه المكونات ، وحصلنا على مجموعة أوسع قليلاً.

لدينا مكونان رئيسيان:
مجموعة بوابات SCSI ، التي توفر الوصول إلى البيانات في كتلة Ceph من خلال FibreChannel أو iSCSI. تستخدم هذه المكونات لتوصيل HyperV و ESXi بمجموعة Ceph. لا يزال عملاء PROXMOX يعملون بطريقتهم الخاصة - من خلال RBD.
لا نسمح لعملاء الملفات مباشرة في شبكة نظام المجموعة ؛ فهناك عدة بوابات متسامحة مع الأخطاء مخصصة لهم. توفر كل بوابة الوصول إلى نظام مجموعة الملفات عبر NFS أو AFP أو SMB. وفقًا لذلك ، يمكن لأي عميل تقريبًا ، سواء كان Linux أو FreeBSD أو ليس عميلًا فقط (OS X ، Windows) ، الوصول إلى CephFS.
من أجل إدارة كل هذا ، اضطررنا بالفعل إلى تطوير أوركسترا Ceph الخاصة بنا وجميع مكوناتنا ، والتي تعد عديدة. لكن الحديث عنها الآن ليس له معنى ، لأن هذا هو تطورنا. سيكون معظمهم مهتمين بـ Ceph "العاري" نفسه.
يستخدم Ceph كثيرًا حيث تحدث أحيانًا حالات فشل. بالتأكيد كل من يعمل مع Ceph يعرف الأسطورة عن CloudMouse. هذه أسطورة حضرية فظيعة ، لكن كل شيء ليس سيئًا كما يبدو. هناك قصة خرافية جديدة عن Rosreestr. كان Ceph يدور في كل مكان ، وفي كل مكان كان يفشل. في مكان ما انتهت قاتلة ، تمكنت في مكان ما للقضاء بسرعة على العواقب.
لسوء الحظ ، ليس من المعتاد بالنسبة لنا مشاركة التجارب السلبية ، حيث يحاول الجميع إخفاء المعلومات ذات الصلة. الشركات الأجنبية أكثر انفتاحًا ، خاصة أن DigitalOcean (مزود معروف يوزع الأجهزة الظاهرية) عانى أيضًا من فشل Ceph لمدة يوم تقريبًا ، لقد كان يوم 1 أبريل - يومًا رائعًا! نشروا بعض التقارير ، سجل قصير أدناه.

بدأت المشاكل في الساعة السابعة صباحًا ، وفي الساعة الحادية عشر ، فهموا ما كان يحدث ، وبدأوا في القضاء على الفشل. للقيام بذلك ، قاموا بتخصيص أمرين: أحدهما لسبب ما كان يدور حول الخوادم ويثبت الذاكرة هناك ، والثاني لسبب ما بدأ خادم واحد يدويًا تلو الآخر ومراقبة جميع الخوادم بعناية. لماذا؟ لقد اعتدنا جميعًا على تشغيل كل شيء بنقرة واحدة.
ما الذي يحدث بشكل أساسي في النظام الموزع عندما يتم بناؤه بشكل فعال ويعمل تقريبًا في حدود إمكاناته؟للإجابة على هذا السؤال ، نحتاج إلى إلقاء نظرة على كيفية عمل نظام Ceph وكيف يحدث الفشل.

فشل فشل Ceph
في البداية ، تعمل المجموعة بشكل جيد ، كل شيء يسير على ما يرام. ثم يحدث شيء ما ، وبعده تفقد شياطين OSD ، حيث يتم تخزين البيانات ، الاتصال بالمكونات المركزية للكتلة (الشاشات). في هذه المرحلة ، تحدث مهلة وتحصل المجموعة بالكامل على حصة. تقف المجموعة لفترة من الوقت حتى تدرك أن هناك خطأ ما في ذلك ، وبعد ذلك يصحح معرفتها الداخلية. بعد ذلك ، تتم استعادة خدمة العملاء إلى حد ما ، وتعمل المجموعة مرة أخرى في وضع متدهور. والشيء المضحك هو أنه يعمل بشكل أسرع من الوضع العادي - هذه حقيقة مذهلة.
ثم نحن القضاء على الفشل. لنفترض أننا فقدنا السلطة ، تم قطع الحامل تمامًا. بدأ العاملون في مجال الكهرباء ، واستعادوا جميعهم ، وزودوا الطاقة ، وبدأ تشغيل الخوادم ، ثم
بدأت المتعة .
الجميع معتادون على حقيقة أنه عندما يفشل الخادم ، يصبح كل شيء سيئًا ، وعندما نشغل الخادم ، يصبح كل شيء جيدًا. كل شيء خاطئ تماما هنا.
تتوقف المجموعة عملياً ، وتجري التزامن الأساسي ، ثم تبدأ في استعادة سلسة وبطيئة ، والعودة تدريجياً إلى الوضع الطبيعي.

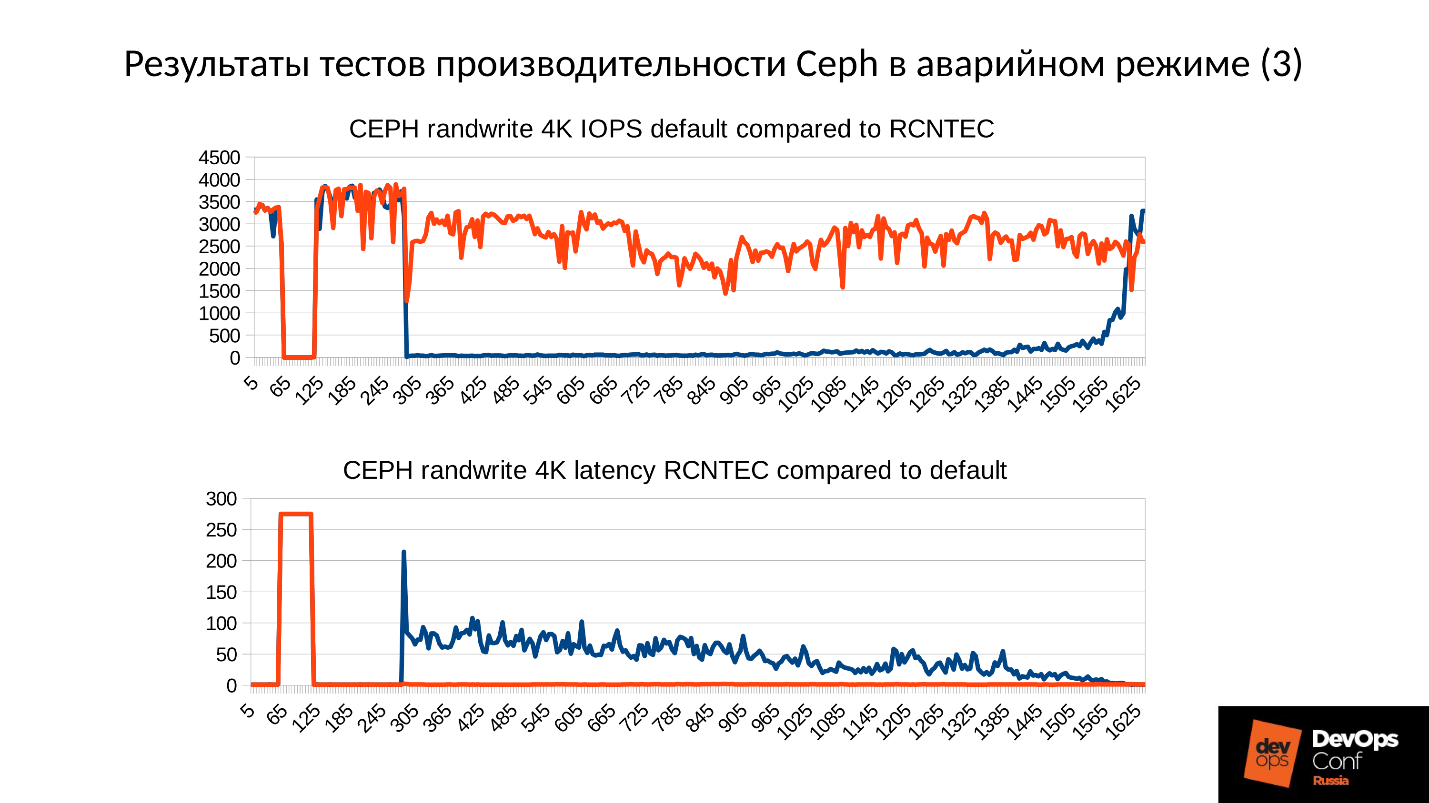
أعلاه هو رسم بياني لأداء الكتلة Ceph كما تطور الفشل. يرجى ملاحظة أنه يتم تتبع الفواصل الزمنية التي تحدثنا عنها بوضوح شديد:
- عملية عادية تصل إلى حوالي 70 ثانية ؛
- الفشل لمدة دقيقة إلى حوالي 130 ثانية ؛
- هضبة أعلى بشكل ملحوظ من التشغيل العادي هو عمل مجموعات متدهورة ؛
- ثم نقوم بتشغيل العقدة المفقودة - هذه مجموعة تدريب ، لا يوجد سوى 3 خوادم و 15 SSDs. نبدأ الخادم في مكان ما حوالي 260 ثانية.
- الخادم قيد التشغيل ، دخلت الكتلة - سقط IOPS'y.
دعنا نحاول معرفة ما حدث بالفعل هناك. أول ما يثير اهتمامنا هو الانخفاض في بداية الرسم البياني.
فشل OSD
النظر في مثال على كتلة مع ثلاثة رفوف ، عدة العقد في كل منها. إذا فشل الحامل الأيسر ، فكل شياطين OSD (وليس المضيفين!) تقوم باختبار اتصالهم برسائل Ceph في فاصل زمني معين. في حالة فقد العديد من الرسائل ، يتم إرسال رسالة إلى الشاشة: "أنا ، OSD كذا وكذا ، لا أستطيع الوصول إلى OSD كذا وكذا."

في هذه الحالة ، يتم عادةً تجميع الرسائل حسب المضيفين ، أي إذا وصلت رسالتان من مختلف أجهزة OSD إلى نفس المضيف ، يتم دمجها في رسالة واحدة. وفقًا لذلك ، إذا أبلغ OSD 11 و OSD 12 أنه لا يمكن الوصول إلى OSD 1 ، فسوف يتم تفسير ذلك على أنه يشكو المضيف 11 من OSD 1. عندما تم الإبلاغ عن OSD 21 و OSD 22 ، يتم تفسيرها على أنها Host 21 غير راضية عن OSD 1 بعد ذلك ترى الشاشة أن OSD 1 في حالة الهبوط ويبلغ جميع أعضاء المجموعة (عن طريق تغيير خريطة OSD) ، يستمر العمل في الوضع المتدهور.
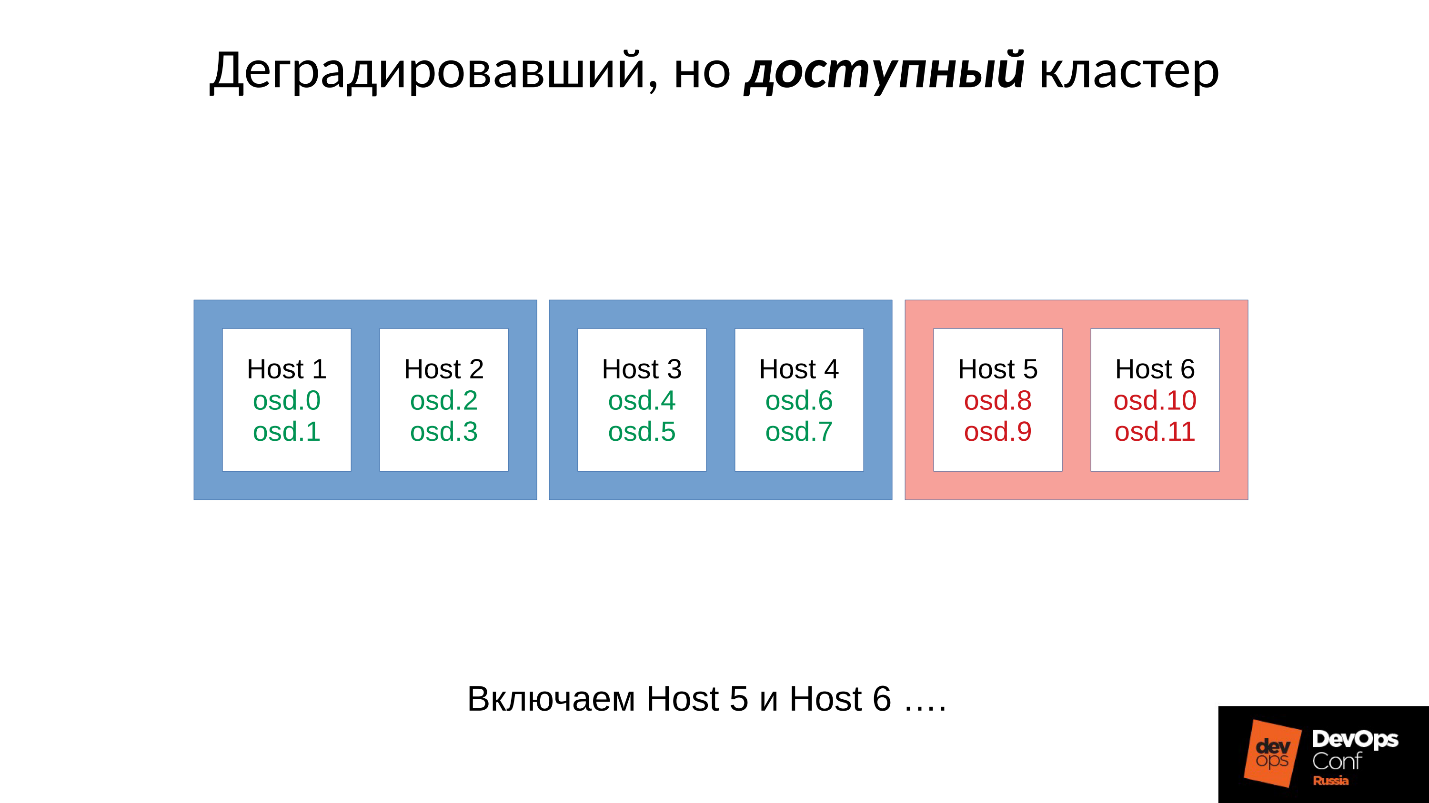
لذلك ، ها نحن لدينا رفوف العنقود والفشل (المضيف 5 والمضيف 6). نقوم بتشغيل Host 5 و Host 6 ، كما ظهرت القوة ، و ...
سلوك Ceph الداخلي
والآن الجزء الأكثر إثارة للاهتمام هو أننا بدأنا
التزامن الأولي للبيانات . نظرًا لوجود العديد من النسخ المتماثلة ، يجب أن تكون متزامنة وأن تكون في نفس الإصدار. في عملية بدء تشغيل OSD:
- يقرأ OSD الإصدارات المتوفرة ، السجل المتاح (pg_log - لتحديد الإصدارات الحالية من الكائنات).
- بعد ذلك تحدد OSD أحدث الإصدارات من الكائنات المتدهورة (missing_loc) التي تعمل وما هي الإصدارات السابقة.
- عند تخزين الإصدارات السابقة ، تكون المزامنة ضرورية ، ويمكن استخدام الإصدارات الجديدة كمرجع لقراءة البيانات وكتابتها.
يتم استخدام القصة التي يتم جمعها من جميع OSDs ، وهذه القصة يمكن أن يكون الكثير جدا ؛ يتم تحديد الموقع الفعلي لمجموعة الكائنات في الكتلة حيث توجد الإصدارات المقابلة. كم عدد الكائنات الموجودة في الكتلة ، وعدد السجلات التي يتم الحصول عليها ، إذا كانت الكتلة قد وقفت لفترة طويلة في وضع تدهور ، ثم القصة طويلة.
للمقارنة: الحجم المعتاد للكائن عندما نعمل مع صورة RBD هو 4 ميجابايت. عندما نعمل في محو مشفرة - 1MB. إذا كان لدينا قرص بسعة 10 تيرابايت ، فسنحصل على ملايين الكائنات على القرص. إذا كان لدينا 10 أقراص في الخادم ، فهناك بالفعل 10 ملايين كائن ، إذا كان هناك 32 قرصًا (نحن نبني مجموعة فعالة ، لدينا تخصيص محكم) ، ثم يجب حفظ 32 مليون كائن في الذاكرة. علاوة على ذلك ، في الواقع ، يتم تخزين المعلومات حول كل كائن في عدة نسخ ، لأن كل نسخة تشير إلى أنه يوجد في هذا المكان في هذا الإصدار ، وفي هذا - في هذا الإصدار.
اتضح كمية كبيرة من البيانات ، والتي تقع في ذاكرة الوصول العشوائي:
- لمزيد من الكائنات ، زاد تاريخ المفقودة ؛
- لمزيد من PG - أكثر pg_log وخريطة OSD.
بالإضافة إلى ذلك:
- أكبر حجم القرص.
- كلما زادت الكثافة (عدد الأقراص في كل خادم) ؛
- ارتفاع الحمل على الكتلة وأسرع الكتلة الخاصة بك ؛
- يعد OSD معطلاً (في حالة عدم الاتصال) ؛
بمعنى آخر ،
كلما كانت الكتلة التي قمنا بإنشائها أكثر حدة ، وكلما لم يستجب جزء من المجموعة ، ستكون هناك حاجة إلى المزيد من ذاكرة الوصول العشوائي عند بدء التشغيل .
التحسينات القصوى هي أصل كل الشرور
"... ويأتي OOM الأسود إلى الأولاد والبنات السيئين في الليل ويقتل جميع العمليات اليسار واليمين"
مدينة مسؤول النظام أسطورة
لذا ، تتطلب ذاكرة الوصول العشوائي الكثير ، ويزداد استهلاك الذاكرة (بدأنا على الفور في ثلث المجموعة) والنظام من الناحية النظرية يمكن أن يذهب إلى SWAP ، إذا قمت بإنشائه بالطبع. أعتقد أن هناك الكثير من الأشخاص الذين يعتقدون أن SWAP أمر سيئ ولا يقومون بإنشائه: "لماذا؟ لدينا الكثير من الذاكرة! " ولكن هذا هو النهج الخاطئ.
إذا لم يتم إنشاء ملف SWAP مسبقًا ، حيث تقرر أن Linux سيعمل بكفاءة أكبر ، فسيحدث ذلك عاجلاً أم آجلاً من قاتل الذاكرة (OOM-killer) ، وليس حقيقة أنه سيقتل الشخص الذي أكل كل الذاكرة ، وليس الشخص الذي كان سيئ الحظ في البداية. نحن نعرف ما هو موقع متفائل - نطلب ذكرى ، ونعده لنا ، نقول: "الآن أعطنا واحدًا" ، ردًا: "لكن لا!" - والخروج من الذاكرة القاتل.
هذه مهمة Linux منتظمة ، ما لم تتم تهيئتها في منطقة الذاكرة الظاهرية.
تنفد العملية من الذاكرة القاتلة وتندفع بسرعة وبلا رحمة. علاوة على ذلك ، لا تعرف العمليات الأخرى التي مات فيها. لم يكن لديه وقت لإخطار أي شخص بأي شيء ، لقد قاموا ببساطة بإنهائه.
بعد ذلك ، ستتم إعادة تشغيل العملية ، بالطبع - لدينا systemd ، وتطلق أيضًا ، إذا لزم الأمر ، OSDs التي سقطت. تبدأ OSDs الساقطة ، و ... يبدأ سلسلة من ردود الفعل.
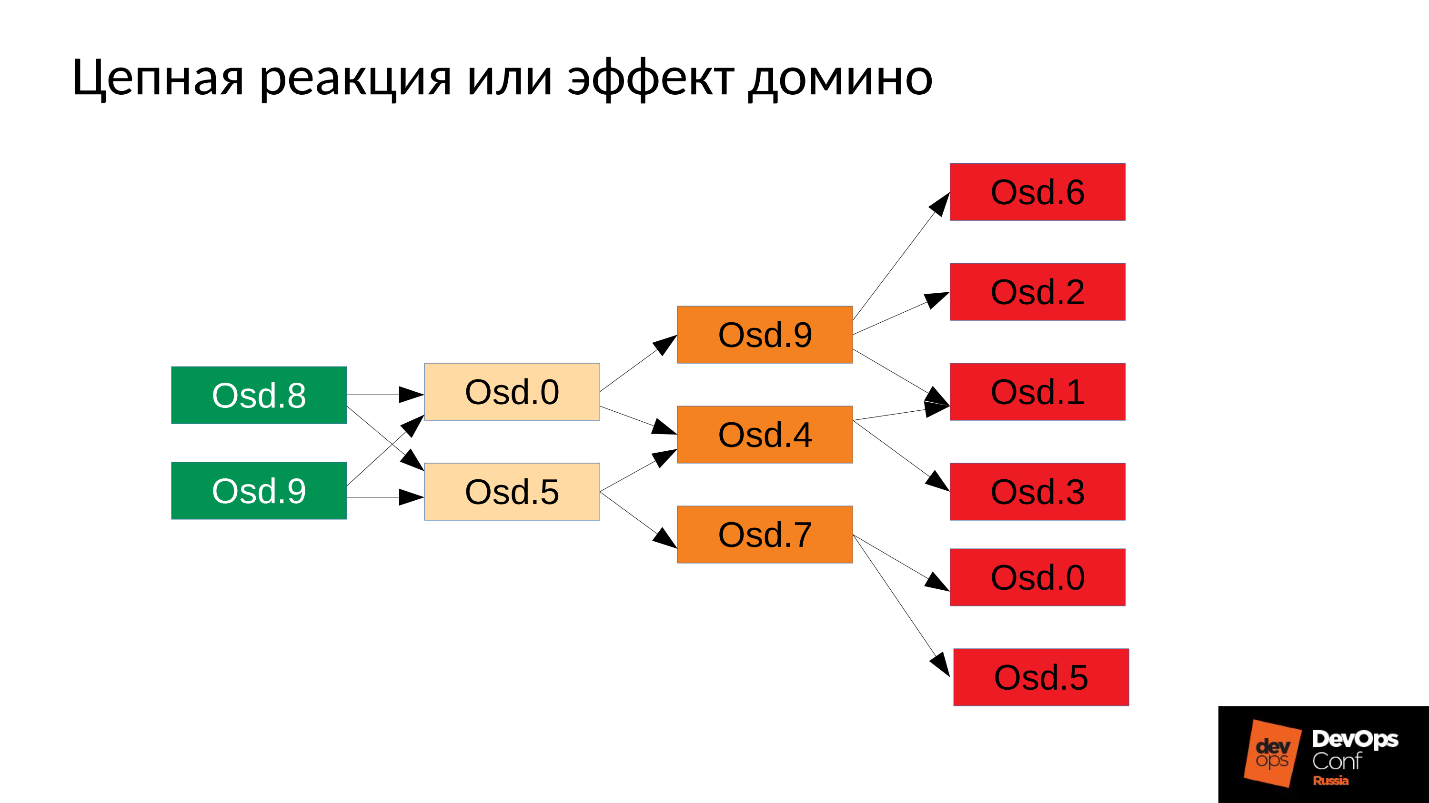
في حالتنا ، بدأنا OSD 8 و OSD 9 ، بدأوا في سحق كل شيء ، ولكن لم يحالفنا الحظ OSD 0 و OSD 5. قام قاتل نفاد الذاكرة بالوصول إليهم وإنهائهم. قاموا بإعادة التشغيل - قرأوا بياناتهم ، وبدأوا في المزامنة وسحق البقية. ثلاثة سيئ الحظ (OSD 9 و OSD 4 و OSD 7). هؤلاء الثلاثة إعادة تشغيل ، بدأت في الضغط على الكتلة بأكملها ، الحزمة التالية كان سيئ الحظ.
تبدأ الكتلة في الانهيار حرفيًا أمام أعيننا . يحدث التدهور بسرعة كبيرة ، وعادة ما يتم التعبير عن هذا "سريع جدًا" في دقائق ، بحد أقصى عشرات الدقائق. إذا كان لديك 30 عقدة (10 عقد لكل رف) ، وقطعت الرف بسبب انقطاع التيار الكهربائي - بعد 6 دقائق ، يقع نصف الكتلة.
لذلك ، نحصل على شيء مثل التالي.
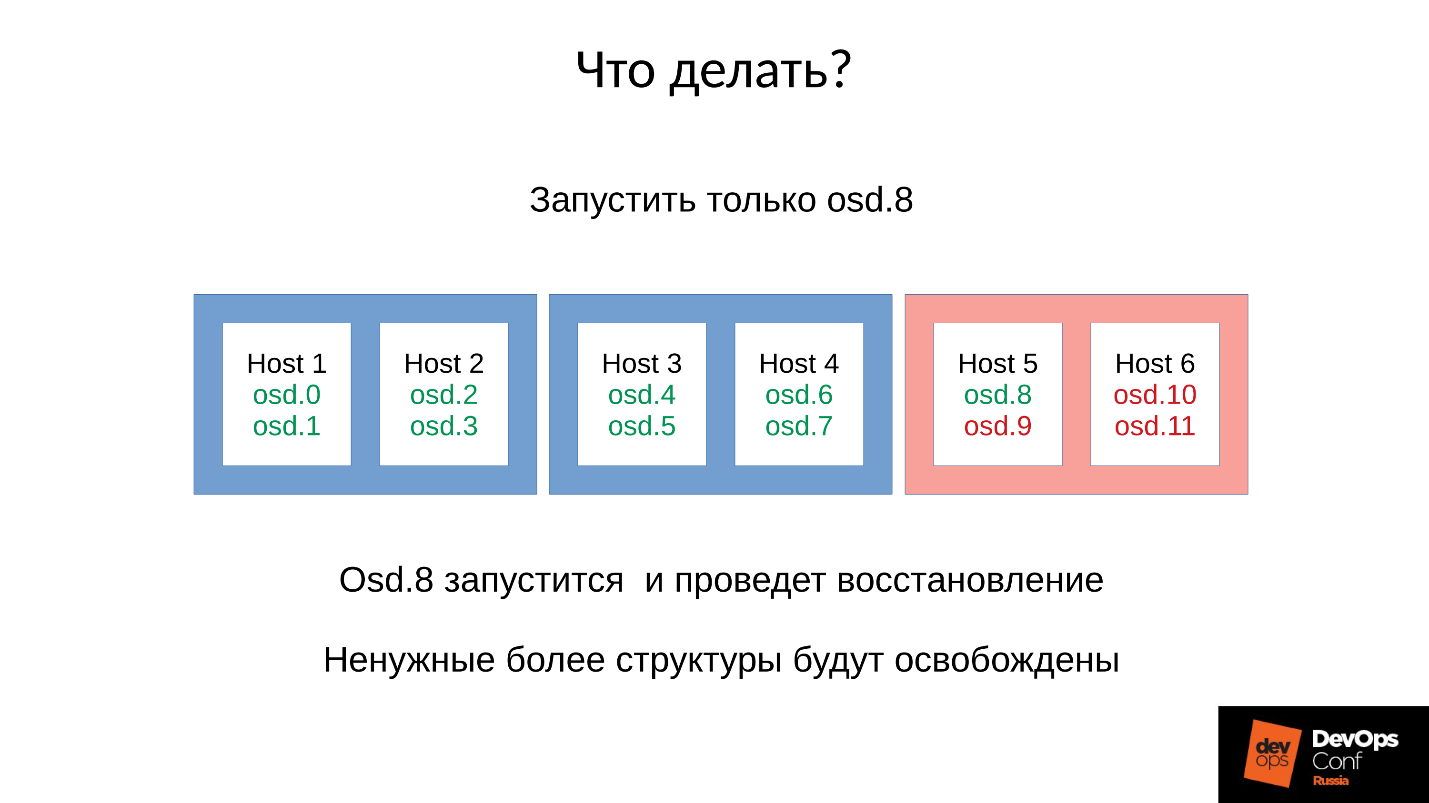
على كل خادم تقريبًا ، لدينا OSD فاشلة. وإذا كان موجودًا على كل خادم ، فهذا يعني أنه في كل مجال من مجالات الفشل لدينا من أجل OSD الفاشلة ، فإن
معظم بياناتنا لا يمكن الوصول إليها . يتم حظر أي طلب - للكتابة ، للقراءة - لا يوجد فرق. هذا كل شئ! لقد نهضنا.
ماذا تفعل في مثل هذه الحالة؟ بتعبير أدق ،
ما الذي يجب عمله ؟
الإجابة: لا تبدأ المجموعة على الفور ، أي الحامل بالكامل ، لكن ارفع كل شيطان بعناية.
لكننا لم نعرف ذلك. بدأنا على الفور ، وحصلنا على ما حصلنا عليه. في هذه الحالة ، أطلقنا أحد الشياطين الأربعة (8 ، 9 ، 10 ، 11) ، سيزداد استهلاك الذاكرة بحوالي 20٪. كقاعدة عامة ، نحن نقف مثل هذه القفزة. ثم ، يبدأ استهلاك الذاكرة في الانخفاض ، نظرًا لأن بعض الهياكل التي تم استخدامها للاحتفاظ بمعلومات حول كيفية مغادرة الكتلة المتدهورة. أي أن جزءًا من مجموعات المواضع قد عاد إلى حالته الطبيعية ، ويتم تحرير كل ما هو مطلوب للحفاظ على الحالة المتدهورة -
نظريًا يتم تحريره .
دعنا نرى مثالا. رمز C على اليسار واليمين متطابق تقريبًا ، والفرق هو فقط في الثوابت.

يطلب هذان المثالان مقدارًا مختلفًا من الذاكرة من النظام:
- اليسار - 2048 قطعة من 1 ميغابايت لكل منهما ؛
- حق - 2097152 قطعة من 1 كيلوبايت.
ثم كلا الأمثلة تنتظر منا لتصويرها في الأعلى. وبعد الضغط على المفتاح ENTER ، يقومون بتحرير الذاكرة - كل شيء ما عدا آخر قطعة. هذا مهم جدا - آخر قطعة تبقى. ومرة أخرى ينتظرون منا لتصويرهم.
أدناه هو ما حدث بالفعل.

- أولاً ، بدأت كلتا العمليتين وأكلت الذاكرة. يبدو وكأنه الحقيقة - 2 GB RSS.
- اضغط ENTER وتفاجأ. البرنامج الأول الذي وقفت في قطع كبيرة عاد الذاكرة. لكن البرنامج الثاني لم يعود.
الجواب لماذا حدث هذا يكمن في لينكس malloc.
إذا طلبنا الذاكرة بأجزاء كبيرة ، فسيتم إصدارها باستخدام آلية mmap المجهولة ، والتي تُعطى لمساحة عنوان المعالج ، حيث يتم بعد ذلك قطع الذاكرة لنا. عندما نفعل free () ، يتم تحرير الذاكرة ويتم إرجاع الصفحات إلى ذاكرة التخزين المؤقت للصفحة (النظام).
إذا قمنا بتخصيص الذاكرة في قطع صغيرة ، فنحن نفعل sbrk (). تحوّل sbrk () المؤشر إلى ذيل كومة الذاكرة المؤقتة ؛ نظريًا ، يمكن إرجاع الذيل المتحول بإرجاع صفحات من الذاكرة إلى النظام إذا لم يتم استخدام الذاكرة.
انظر الآن إلى الرسم التوضيحي. كان لدينا الكثير من السجلات في تاريخ موقع الكائنات المتدهورة ، ثم جاءت جلسة المستخدم - كائن طويل العمر. قمنا بمزامنة جميع الهياكل الإضافية وذهبنا ، ولكن الكائن الذي طال أمده بقي ، ولا يمكننا تحريك sbrk () للخلف.

لا يزال لدينا الكثير من المساحة غير المستخدمة التي يمكن تحريرها إذا كان لدينا SWAP. لكننا أذكياء - قمنا بتعطيل SWAP.
بالطبع ، سيتم استخدام جزء من الذاكرة من بداية الكومة ، لكن هذا جزء فقط ، وسيتم الاحتفاظ بالجزء المتبقي المهم للغاية.
ماذا تفعل في مثل هذه الحالة؟ الجواب أدناه.
إطلاق تسيطر عليها
- نبدأ واحد OSD الخفي.
- ننتظر حتى تتم مزامنتها ، ونحن نتحقق من ميزانيات الذاكرة.
- إذا فهمنا أننا سننجح من بداية الشيطان التالي ، سنبدأ الشيطان التالي.
- إذا لم يكن كذلك ، فقم بإعادة تشغيل البرنامج الخفي الذي احتل أكبر مساحة من الذاكرة بسرعة. كان قادرًا على النزول لفترة قصيرة ، وليس لديه الكثير من التاريخ ، ويفقد locs وأشياء أخرى ، لذلك سوف يأكل ذاكرة أقل ، وسوف تزيد ميزانية الذاكرة قليلاً.
- نحن نركض حول الكتلة ونتحكم فيها ونرفع كل شيء تدريجياً.
- نتحقق مما إذا كان من الممكن المتابعة إلى OSD التالي ، انتقل إليه.
قامت DigitalOcean بإنجاز هذا بالفعل:
"يقوم فريق Datacenter التابع لنا بإجراء زيادة في الذاكرة بينما يواصل فريق آخر ببطء إحضار العقد أثناء إدارة ميزانية الذاكرة لكل مضيف يدويًا."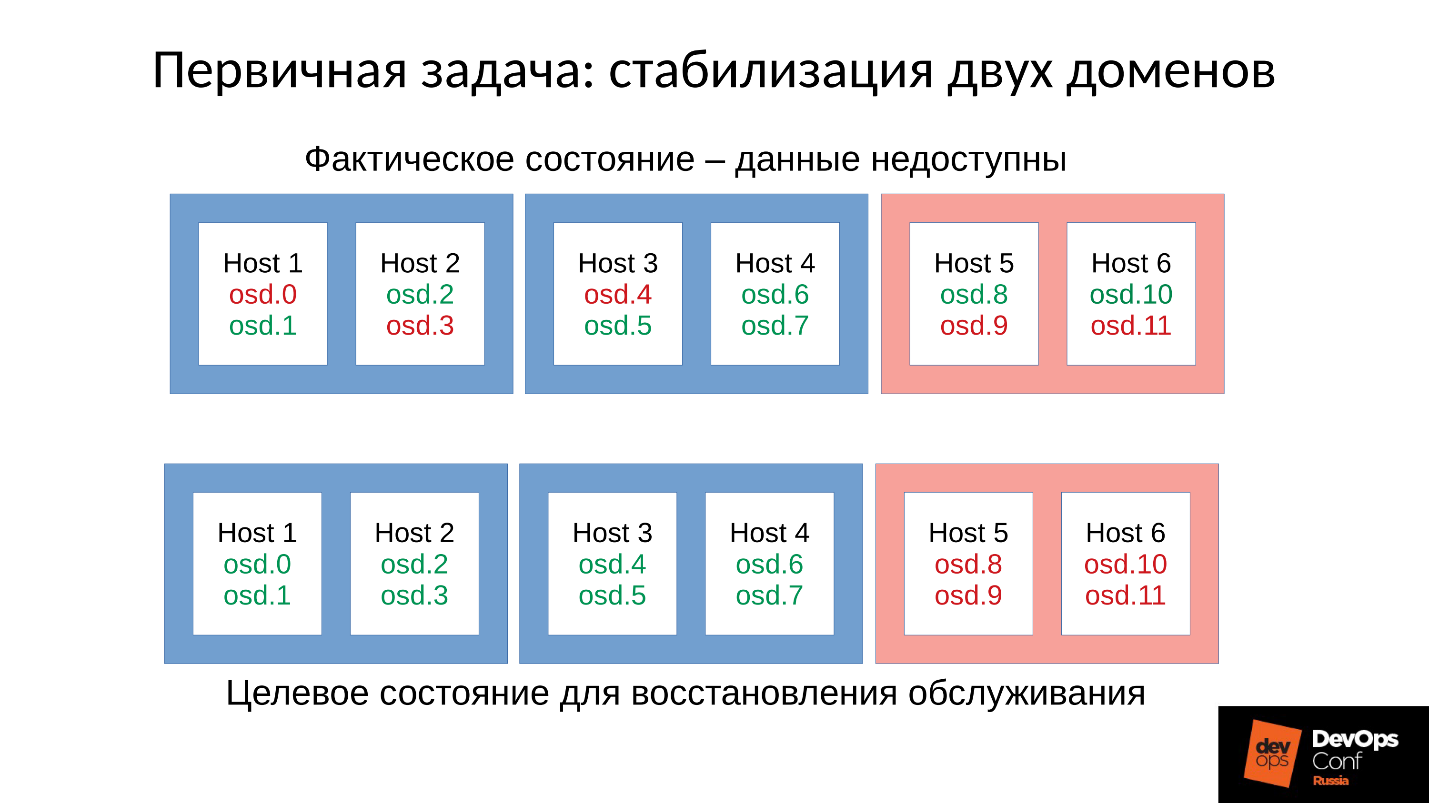
دعنا نعود إلى التكوين لدينا والوضع الحالي. الآن لدينا كتلة انهارت بعد سلسلة من ردود الفعل من قاتل الذاكرة. نحن نحظر إعادة التشغيل التلقائي لـ OSD في المجال الأحمر ، ونبدأ تشغيل العقد من المجالات الزرقاء واحدة تلو الأخرى. لأن
مهمتنا الأولى هي دائمًا استعادة الخدمة دون فهم سبب حدوث ذلك. سوف نفهم لاحقا ، عندما نستعيد الخدمة. في العملية ، وهذا هو الحال دائما.
نأتي المجموعة إلى الحالة المستهدفة من أجل استعادة الخدمة ، ثم نبدأ في تشغيل OSD واحد تلو الآخر وفقا لمنهجيتنا. ننظر إلى الأول ، إذا لزم الأمر ، أعد تشغيل الآخرين لضبط ميزانية الذاكرة ، التالي - 9 ، 10 ، 11 - ويبدو أن المجموعة متزامنة وجاهزة لبدء الصيانة.
المشكلة هي كيف يتم تنفيذ
صيانة الكتابة في Ceph .
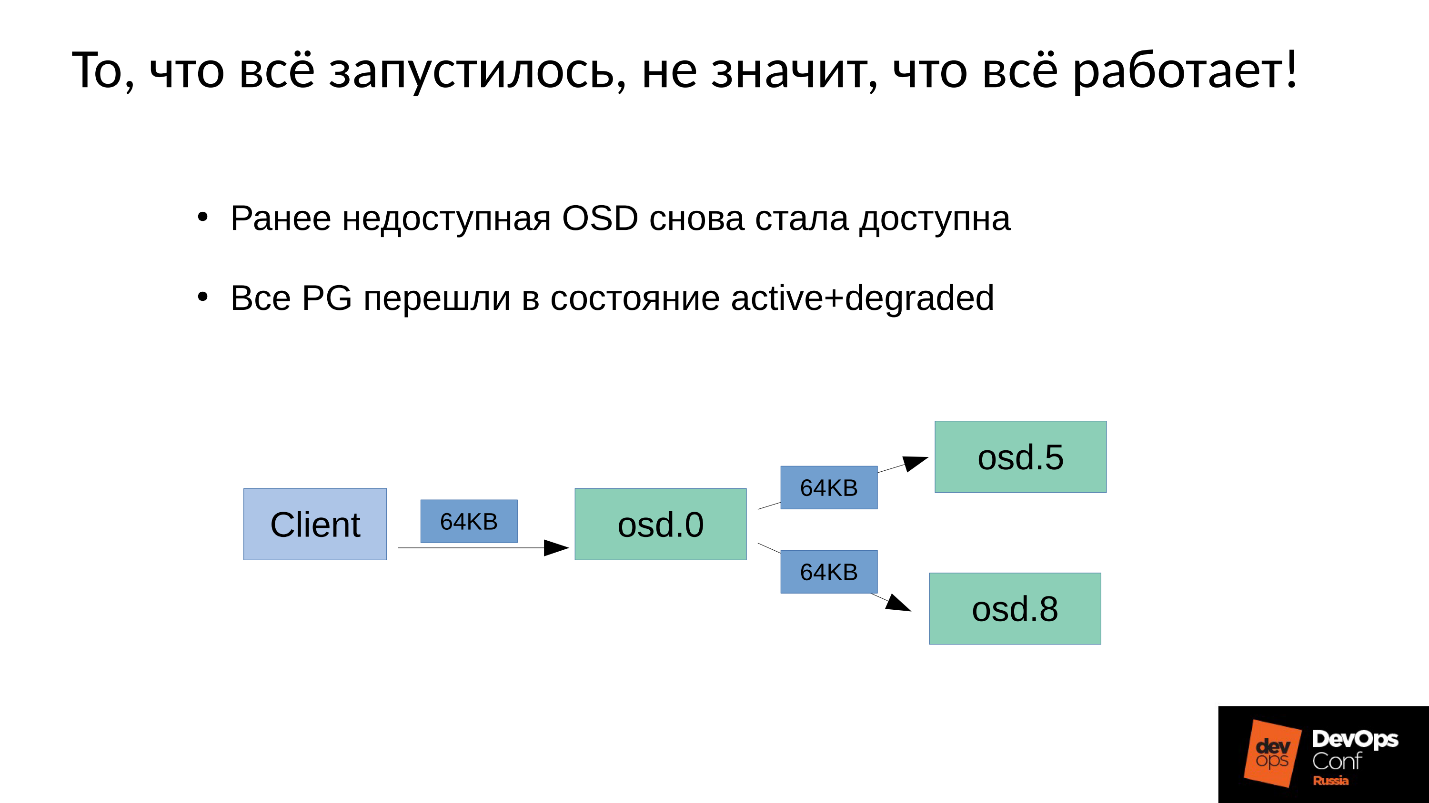
لدينا 3 نسخ متماثلة: واحد OSD سيد واثنين من العبيد لذلك. سنوضح أن السيد / العبد في كل مجموعة من مواضع الإعلانات له خاص به ، ولكن لكل منهما سيدًا واحدًا وعبدان.
تقع عملية الكتابة أو القراءة على برنامج الماجستير. عند القراءة ، إذا كان لدى السيد الإصدار الصحيح ، فسيقوم بإعطائها للعميل. التسجيل أكثر تعقيدًا قليلاً ، يجب تكرار التسجيل على جميع النسخ المتماثلة. وفقًا لذلك ، عندما يكتب العميل 64 كيلو بايت في OSD 0 ، فإن نفس 64 كيلو بايت في مثالنا يذهب إلى OSD 5 و OSD 8.
ولكن الحقيقة هي أن OSD 8 لدينا متدهورة للغاية ، لأننا قمنا بإعادة تشغيل العديد من العمليات.

نظرًا لأن أي تغيير في Ceph هو انتقال من إصدار إلى إصدار ، في OSD 0 و OSD 5 سيكون لدينا إصدار جديد ، على OSD 8 - الإصدار القديم. , , ( 64 ) OSD 8 — 4 ( ). 4 OSD 0, OSD 8, , . , 64 .
— .

:
- 4 1 , 1000 / 1 .
- 4 ( ) 22 , 45 /.
, , , , .
— .

4 22 , 22 , 1 4 . 45 SSD, 1 —
45 .
, .
- , — (45+1) / 2 = 23 .
- 75% , (45 * 3 + 1) / 4 = 34 .
- 90% —(45 * 9 + 1) / 10 = 41 — 40 , .
Ceph, . , , , .
Ceph .

- — : , , , , .
- — latency. latency , . 100% ( , ). Latency 60 , .

, . 10 , 1 200 /, 300 , , . 10 SSD — 300 , — , - 300 .
, .
, . 900 / ( SSD). 2 500 128 ( , ESXi HyperV 128 ). degraded, 225 . file store, object store, ( ), 110 , - .
SSD 110 — !
?1: —
.

: ; PG;
.
:
- , 45 — .
- ( . ), 14 .
- , 8 ( 10% PG).
, , , , , .
2: —
(order, objectsize) .
, , , 4 2 1 . , , . :
:
(32 ) — !
3: —
Ceph .
, -,
Ceph . , , . .
, — Latency. — , — . Latency 30% , , .
Community , preproduction . , . , .
الخاتمة
- , . , Ceph - , , .
●
- .
, . ,
. . , , production. , , , DigitalOcean , . , , , .
, , . , : « ! ?!» , , . , : , , down time.
●
(OSD)., , — , , - , .
OSD — — . , .
●
.OSD .
, . , , , .
●
RAM OSD.●
SWAP.SWAP Ceph' , Linux' . .
●
.100%, 10%. , , , .
●
RBD Rados Getway., .
SWAP — . , SWAP — , , , , .
— DevOpsConf Russia. . , youtube , DevOps-.