هناك عدة طرق لمعالجة الأخطاء في لغات البرمجة:
- استثناءات قياسية للعديد من اللغات (Java و Scala و JVMs الأخرى و python والعديد من اللغات الأخرى)
- رموز الحالة أو الأعلام (Go ، bash)
- هياكل البيانات الجبرية المختلفة ، والتي يمكن أن تكون قيمها كل من النتائج الناجحة وأوصاف الخطأ (Scala ، haskell واللغات الوظيفية الأخرى)
تُستخدم الاستثناءات على نطاق واسع جدًا ، من ناحية أخرى يُقال إنها بطيئة. لكن معارضي النهج الوظيفي غالباً ما يروقون الأداء.
في الآونة الأخيرة ، كنت أعمل مع Scala ، حيث يمكنني استخدام كل من الاستثناءات وأنواع البيانات المختلفة بشكل متساوٍ لمعالجة الأخطاء ، لذلك أتساءل عن الطريقة الأكثر ملاءمة وأسرع.
سنتجاهل على الفور استخدام الرموز والأعلام ، نظرًا لأن هذا النهج غير مقبول بلغات JVM ، وفي اعتقادي ، معرض للخطأ جدًا (أعتذر عن التورية). لذلك ، سنقوم بمقارنة الاستثناءات وأنواع مختلفة من ADT. بالإضافة إلى ذلك ، يمكن اعتبار ADT استخدام رموز الخطأ بأسلوب وظيفي.
استكمال : تضاف الاستثناءات دون آثار مكدس للمقارنة
المتسابقين
أكثر قليلاً عن أنواع البيانات الجبريةبالنسبة لأولئك الذين ليسوا على دراية بـ ADT ( ADT ) - يتكون النوع الجبري من عدة قيم ممكنة ، يمكن أن تكون كل واحدة منها قيمة مركبة (بنية ، سجل).
مثال على ذلك هو Option[T] = Some(value: T) | None Option[T] = Some(value: T) | None ، يُستخدم بدلاً من القيم الخالية: يمكن أن تكون قيمة هذا النوع إما Some(t) إذا كانت هناك قيمة ، أو None إذا لم تكن كذلك.
مثال آخر سيكون Try[T] = Success(value: T) | Failure(exception: Throwable) Try[T] = Success(value: T) | Failure(exception: Throwable) ، الذي يصف نتيجة عملية حسابية يمكن أن تكتمل بنجاح أو مع وجود خطأ.
لذلك المتسابقين لدينا:
- استثناءات قديمة جيدة
- استثناءات بدون تتبع مكدس ، لأن ملء تتبع مكدس عملية بطيئة للغاية
Try[T] = Success(value: T) | Failure(exception: Throwable) Try[T] = Success(value: T) | Failure(exception: Throwable) - نفس الاستثناءات ، ولكن في غلاف وظيفيEither[String, T] = Left(error: String) | Right(value: T) Either[String, T] = Left(error: String) | Right(value: T) - نوع يحتوي إما على نتيجة أو وصف للخطأValidatedNec[String, T] = Valid(value: T) | Invalid(errors: List[String]) ValidatedNec[String, T] = Valid(value: T) | Invalid(errors: List[String]) - نوع من مكتبة Cats ، والذي في حالة وجود خطأ يمكن أن يحتوي على عدة رسائل حول أخطاء مختلفة (ليست List تستخدم هناك ، لكن لا يهم)
ملاحظة في جوهرها ، تتم مقارنة الاستثناءات مع تتبع المكدس ، بدون و ADT ، ولكن يتم تحديد عدة أنواع ، لأن Scala ليس لديه منهج واحد ومن المثير للاهتمام مقارنة العديد.
بالإضافة إلى الاستثناءات ، يتم استخدام السلاسل لوصف الأخطاء ، ولكن مع نفس النجاح في الموقف الحقيقي ، سيتم استخدام فئات مختلفة ( Either[Failure, T] ).
المشكلة
لاختبار معالجة الأخطاء ، نأخذ مشكلة التحليل والتحقق من صحة البيانات:
case class Person(name: String, age: Int, isMale: Boolean) type Result[T] = Either[String, T] trait PersonParser { def parse(data: Map[String, String]): Result[Person] }
أي امتلاك Map[String, String] بيانات أولية Map[String, String] تحتاج إلى الحصول على Person أو خطأ إذا كانت البيانات غير صالحة.
رمي
حل للجبهة باستخدام الاستثناءات (فيما يلي سوف أعطي وظيفة person فقط ، يمكنك رؤية الرمز الكامل على جيثب ):
Throwparser.scala
def person(data: Map[String, String]): Person = { val name = string(data.getOrElse("name", null)) val age = integer(data.getOrElse("age", null)) val isMale = boolean(data.getOrElse("isMale", null)) require(name.nonEmpty, "name should not be empty") require(age > 0, "age should be positive") Person(name, age, isMale) }
هنا string ، integer boolean التحقق من صحة وجود وشكل أنواع بسيطة وإجراء التحويل.
بشكل عام ، الأمر بسيط للغاية ومفهوم.
ThrowNST (بدون تتبع مكدس)
الكود هو نفسه كما في الحالة السابقة ، ولكن يتم استخدام الاستثناءات دون تتبع مكدس حيثما كان ذلك ممكنًا: ThrowNSTParser.scala
جرب
يكتشف الحل الاستثناءات في وقت سابق ويسمح بدمج النتائج for طريق (عدم الخلط بينه وبين الحلقات بلغات أخرى):
TryParser.scala
def person(data: Map[String, String]): Try[Person] = for { name <- required(data.get("name")) age <- required(data.get("age")) flatMap integer isMale <- required(data.get("isMale")) flatMap boolean _ <- require(name.nonEmpty, "name should not be empty") _ <- require(age > 0, "age should be positive") } yield Person(name, age, isMale)
أكثر غرابة قليلاً بالنسبة للعين الهشة ، ولكن نظرًا لاستخدامها ، فهي تشبه إلى حد كبير الإصدار مع وجود استثناءات ، بالإضافة إلى أن التحقق من وجود حقل والتحليل من النوع المرغوب يحدث بشكل منفصل (يمكن قراءة flatMap هنا كما يلي)
إما
هنا يتم إخفاء النوعين خلف الاسم المستعار للنتائج حيث يتم إصلاح نوع الخطأ:
EitherParser.scala
def person(data: Map[String, String]): Result[Person] = for { name <- required(data.get("name")) age <- required(data.get("age")) flatMap integer isMale <- required(data.get("isMale")) flatMap boolean _ <- require(name.nonEmpty, "name should not be empty") _ <- require(age > 0, "age should be positive") } yield Person(name, age, isMale)
نظرًا لأن المعيار Either مثل Try يشكل أحاديًا في Scala ، فقد تم عرض الكود بنفس الطريقة تمامًا ، والفرق هنا هو أن السلسلة تظهر هنا كخطأ وأن الاستثناءات يتم استخدامها بشكل ضئيل (فقط للتعامل مع الأخطاء عند تحليل عدد)
التحقق من صحة
هنا يتم استخدام مكتبة Cats من أجل عدم الحصول على أول ما حدث ، ولكن قدر الإمكان (على سبيل المثال ، إذا كانت عدة حقول غير صالحة ، فستتضمن النتيجة أخطاء تحليل لكل هذه الحقول)
ValidatedParser.scala
def person(data: Map[String, String]): Validated[Person] = { val name: Validated[String] = required(data.get("name")) .ensure(one("name should not be empty"))(_.nonEmpty) val age: Validated[Int] = required(data.get("age")) .andThen(integer) .ensure(one("age should be positive"))(_ > 0) val isMale: Validated[Boolean] = required(data.get("isMale")) .andThen(boolean) (name, age, isMale).mapN(Person) }
يشبه هذا الرمز بالفعل النسخة الأصلية مع وجود استثناءات ، ولكن لم يتم فصل التحقق من القيود الإضافية عن حقول التحليل وما زلنا نتلقى العديد من الأخطاء بدلاً من واحدة ، الأمر يستحق ذلك!
اختبار
للاختبار ، تم إنشاء مجموعة بيانات بنسبة مئوية مختلفة من الأخطاء وتحليلها في كل طريقة من الطرق.
النتيجة على جميع النسب المئوية للأخطاء:

بمزيد من التفاصيل ، عند نسبة مئوية منخفضة من الأخطاء (يختلف الوقت هنا منذ استخدام عينة أكبر):
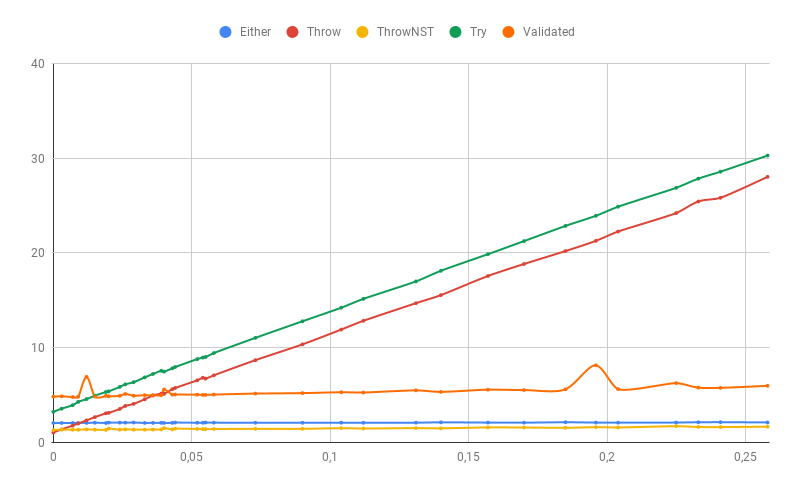
إذا كان جزء من الأخطاء لا يزال استثناءً في تتبع المكدس (في حالتنا ، فإن خطأ تحليل الرقم سيكون استثناءً لا نتحكم فيه) ، بالطبع سوف يتدهور أداء طرق معالجة الأخطاء "السريعة" بشكل كبير. Validated يتأثر بشكل خاص ، لأنه يجمع كل الأخطاء ونتيجة لذلك يتلقى استثناء بطيء أكثر من غيرها:

الاستنتاجات
كما أوضحت التجربة ، الاستثناءات مع تتبع المكدس تكون بطيئة جدًا (أخطاء 100٪ هي الفرق بين Throw و Either أكثر من 50 مرة!) ، وعندما لا توجد استثناءات عملياً ، يكون سعر استخدام ADT له. ومع ذلك ، فإن استخدام الاستثناءات بدون تتبعات المكدس يكون سريعًا (وبنسبة مئوية منخفضة من الأخطاء بشكل أسرع) مثل ADT ، ولكن إذا تجاوزت هذه الاستثناءات نفس التحقق ، فلن يكون تتبع مصدرها أمرًا سهلاً.
إجمالًا ، إذا كان احتمال حدوث استثناء هو أكثر من 1٪ ، فإن الاستثناءات دون آثار مكدس تعمل بسرعة أكبر أو يتم Validated أو بشكل منتظم Either بنفس السرعة. مع وجود عدد كبير من الأخطاء ، يمكن أن يكون Either أسرع قليلاً من Validated من Validated فقط بسبب دلالات فشل سريع.
يوفر استخدام ADT لمعالجة الأخطاء ميزة أخرى على الاستثناءات: يتم ربط إمكانية حدوث خطأ في النوع نفسه ويصعب تفويتها ، كما هو الحال عند استخدام Option بدلاً من القيم الخالية.