واحدة من الوظائف غير واضحة ولكنها مهمة لمواقعنا
الإعلانية هي حفظ وعرض عدد مرات المشاهدة. تشاهد مواقعنا مرات مشاهدة الإعلانات لأكثر من 10 سنوات. نجح التنفيذ التقني للوظيفة في التغيير عدة مرات خلال هذا الوقت ، والآن هي خدمة (micro) قيد التشغيل ، تعمل مع Redis كقائمة انتظار مؤقت ومهمة ، ومع MongoDB كتخزين دائم. قبل بضع سنوات ، تعلم العمل ليس فقط مع مجموع مرات مشاهدة الإعلانات ، ولكن أيضًا مع إحصائيات كل يوم. لكنه تعلم أن يفعل كل هذا بسرعة حقا وموثوق بها مؤخرا جدا.

في المجموع ، تعالج الخدمة حوالي 300 ألف طلب قراءة و 9 آلاف طلب كتابة في الدقيقة ، يتم تنفيذ 99٪ منها حتى 5 مللي ثانية. هذه ، بالطبع ، ليست مؤشرات فلكية وليست إطلاق صواريخ على سطح المريخ - ولكنها ليست مهمة تافهة مثل التخزين البسيط للأرقام. اتضح أن القيام بكل هذا ، وضمان تخزين البيانات المفقودة وقراءة القيم المتسقة ذات الصلة ، يتطلب بعض الجهد الذي سنناقشه أدناه.
مهام المشروع ونظرة عامة
على الرغم من أن عدادات المشاهدة ليست حرجة بالنسبة إلى العمل مثل معالجة المدفوعات أو
طلبات الحصول على قرض ، على
سبيل المثال ، فهي مهمة في المقام الأول لمستخدمينا. الناس مفتونون بتتبع شعبية إعلاناتهم: حتى أن البعض يتصل بالدعم عندما يلاحظون معلومات عرض غير دقيقة (حدث هذا مع أحد تطبيقات الخدمة السابقة). بالإضافة إلى ذلك ، نقوم بتخزين وعرض إحصاءات مفصلة في حسابات المستخدمين الشخصية (على سبيل المثال ، لتقييم فعالية استخدام الخدمات المدفوعة). كل هذا يجعلنا نحرص على حفظ كل حدث عرض وعرض القيم الأكثر صلة.
بشكل عام ، تبدو وظائف ومبادئ المشروع كما يلي:
- تقدم صفحة الويب أو شاشة التطبيق طلبًا خلف عدادات عرض الإعلانات (يكون الطلب عادةً غير متزامن لتحديد أولويات إخراج المعلومات الأساسية). وإذا تم عرض صفحة الإعلان نفسه ، سيطلب منك العميل بدلاً من ذلك زيادة وإرجاع كمية المشاهدات المحدثة.
- من خلال معالجة طلبات القراءة ، تحاول الخدمة الحصول على معلومات من ذاكرة التخزين المؤقت لـ Redis ، وتكمل المجهول عن طريق إكمال طلب إلى MongoDB.
- يتم إرسال طلبات الكتابة إلى بنيتين في الفجل: قائمة انتظار التحديث التزايدي (تتم معالجتها في الخلفية ، بشكل غير متزامن) وذاكرة التخزين المؤقت لإجمالي عدد مرات المشاهدة.
- تقوم عملية الخلفية في نفس الخدمة بقراءة العناصر من قائمة الانتظار ، وتجميعها في المخزن المؤقت المحلي ، وتكتبها بشكل دوري إلى MongoDB.
سجل عرض عدادات: مطبات
على الرغم من أن الخطوات الموضحة أعلاه تبدو بسيطة جدًا ، إلا أن المشكلة هنا هي تنظيم التفاعل بين قاعدة البيانات ومثيلات الخدمة المصغرة بحيث لا تضيع البيانات ولا تتكرر ولا تتخلف.
باستخدام مستودع واحد فقط (على سبيل المثال ، MongoDB فقط) من شأنه أن يحل بعض هذه المشاكل. في الواقع ، كانت الخدمة تعمل من قبل ، حتى واجهنا مشاكل التوسع والاستقرار والسرعة.
قد يؤدي التنفيذ الساذج لنقل البيانات بين المستودعات ، على سبيل المثال ، إلى حدوث مثل هذه الحالات الشاذة:
- فقدان البيانات أثناء الكتابة التنافسية إلى ذاكرة التخزين المؤقت:
- تزيد العملية A من عدد المشاهدات في ذاكرة التخزين المؤقت لـ Redis ، لكنها تكتشف أنه لا توجد بيانات لهذا الكيان (يمكن أن تكون إما إعلان جديد أو إعلان قديم تم استخلاصه من ذاكرة التخزين المؤقت) ، لذلك يجب أن تحصل العملية أولاً على هذه القيمة من MongoDB.
- تحصل العملية A على عدد مرات المشاهدة من MongoDB - على سبيل المثال ، الرقم 5 ؛ ثم تضيف 1 إليها وسوف تكتب إلى Redis 6 .
- العملية B (التي بدأها ، على سبيل المثال ، مستخدم آخر للموقع قام أيضًا بإدخال نفس الإعلان) تفعل نفس الشيء في نفس الوقت.
- عملية A يكتب قيمة 6 إلى Redis.
- عملية B يكتب قيمة 6 إلى Redis.
- نتيجة لذلك ، يتم فقد عرض واحد بسبب السباق عند تسجيل البيانات.
السيناريو ليس مرجحًا جدًا: على سبيل المثال ، لدينا خدمة مدفوعة تضع إعلانًا على الصفحة الرئيسية للموقع. للحصول على إعلان جديد ، يمكن أن يؤدي مسار الأحداث هذا إلى فقدان العديد من المشاهدات في آن واحد بسبب تدفقها المفاجئ.
- مثال على سيناريو آخر هو فقدان البيانات عند نقل طرق العرض من Redis إلى MongoDb:
- تلتقط العملية قيمة معلقة من Redis وتخزنها في الذاكرة لكتابتها لاحقًا على MongoDB.
- فشل طلب الكتابة (أو تعطل العملية قبل تنفيذها).
- يتم فقد البيانات مرة أخرى ، والتي ستصبح واضحة في المرة التالية التي يتم فيها دفع القيمة المخزنة مؤقتًا واستبدالها بالقيمة من قاعدة البيانات.
قد تحدث أخطاء أخرى ، والأسباب التي تكمن أيضا في الطبيعة غير الذرية للعمليات بين قواعد البيانات ، على سبيل المثال ، تعارض أثناء حذف وزيادة وجهات نظر نفس الكيان.
تسجيل عرض التهم: الحل
يعتمد أسلوبنا في تخزين ومعالجة البيانات في هذا المشروع على توقع أنه في أي وقت من الأوقات قد تفشل MongoDB على الأرجح أكثر من Redis. هذا ، بالطبع ، ليس
قاعدة مطلقة - على الأقل ليس لكل مشروع - ولكن في بيئتنا اعتدنا حقًا على مراقبة المهلات الدورية للاستعلامات في MongoDB الناجمة عن أداء عمليات القرص ، والتي كانت في السابق أحد أسباب فقدان بعض الأحداث.
لتجنب العديد من المشكلات المذكورة أعلاه ، نستخدم قوائم انتظار المهام من أجل الحفظ المؤجل والبرامج النصية ، والتي تتيح تغيير البيانات تلقائيًا في العديد من هياكل الفجل مرة واحدة. مع وضع ذلك في الاعتبار ، فإن تفاصيل حفظ المشاهدات هي كما يلي:
- عندما يقع طلب الكتابة في الخدمة المجهرية ، يتم تشغيل البرنامج النصي لوا IncrementIfExists لزيادة العداد فقط إذا كان موجودًا بالفعل في ذاكرة التخزين المؤقت. يعود البرنامج النصي على الفور -1 في حالة عدم وجود بيانات للكيان الذي يتم عرضه في الفجل ؛ وإلا ، فإنه يزيد من قيمة المشاهدات في ذاكرة التخزين المؤقت عبر HINCRBY ، ويضيف الحدث إلى قائمة الانتظار للتخزين اللاحق في MongoDB (تسمى قائمة الانتظار المعلقة من قبلنا) عبر LPUSH ، ويعيد كمية محدثة من المشاهدات.
- إذا قامت IncrementIfExists بإرجاع رقم موجب ، فسيتم إرجاع هذه القيمة إلى العميل وينتهي الطلب.
بخلاف ذلك ، تلتقط الخدمة الميكروية عداد العرض من MongoDb ، وتزيده بمقدار 1 وترسله إلى الفجل.
- تتم الكتابة إلى الفجل من خلال برنامج نصي آخر للغة - Upsert - مما يحفظ إجمالي عدد المشاهدات في ذاكرة التخزين المؤقت إذا كان لا يزال فارغًا ، أو يزيدها بمقدار 1 إذا تمكن شخص آخر من ملء ذاكرة التخزين المؤقت بين الخطوتين 1 و 3.
- يضيف Upsert أيضًا حدث عرض إلى قائمة الانتظار المعلقة ، ويعيد مبلغًا محدثًا ، يتم إرساله بعد ذلك إلى العميل.
نظرًا لحقيقة
تنفيذ نصوص lua
تلقائيًا ، فإننا نتجنب العديد من المشكلات المحتملة التي قد تنتج عن الكتابة التنافسية.
التفاصيل المهمة الأخرى هي ضمان النقل الآمن للتحديثات من قائمة الانتظار المعلقة إلى MongoDB. للقيام بذلك ، استخدمنا قالب "قائمة انتظار موثوقة" الموضحة في
وثائق Redis ، مما يقلل بشكل كبير من فرص فقدان البيانات عن طريق إنشاء نسخة من العناصر التي تمت معالجتها في قائمة انتظار منفصلة أخرى حتى يتم تخزينها أخيرًا في مخزن ثابت.
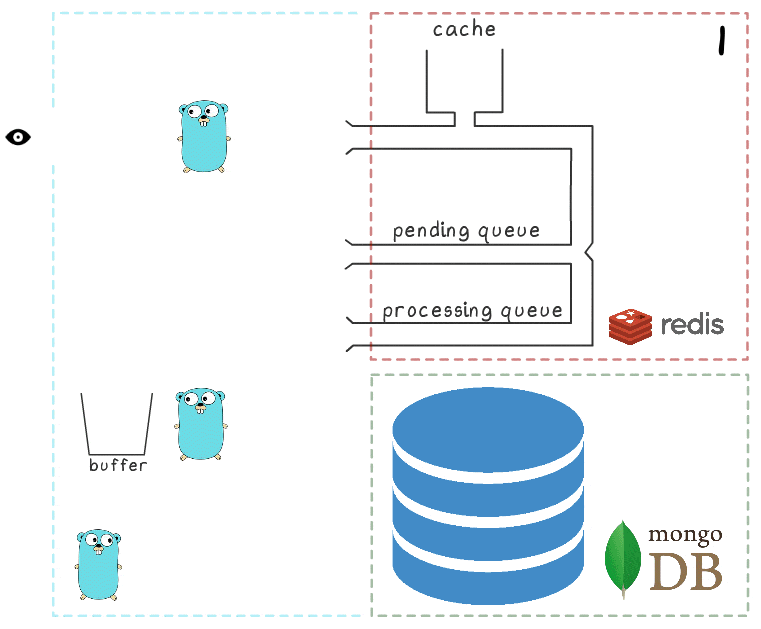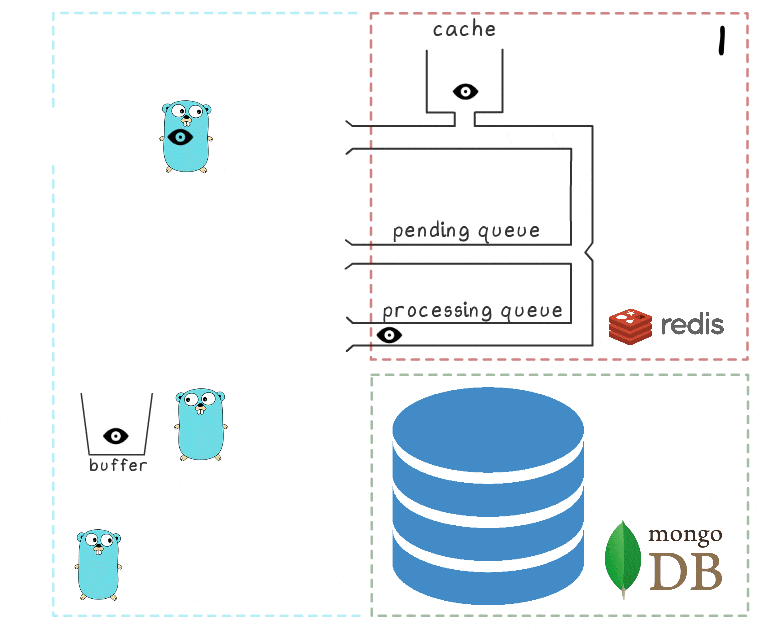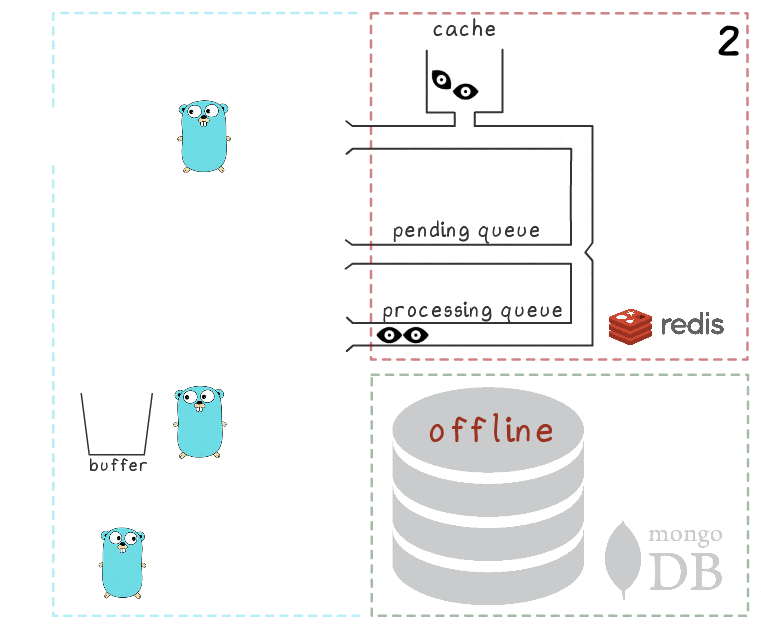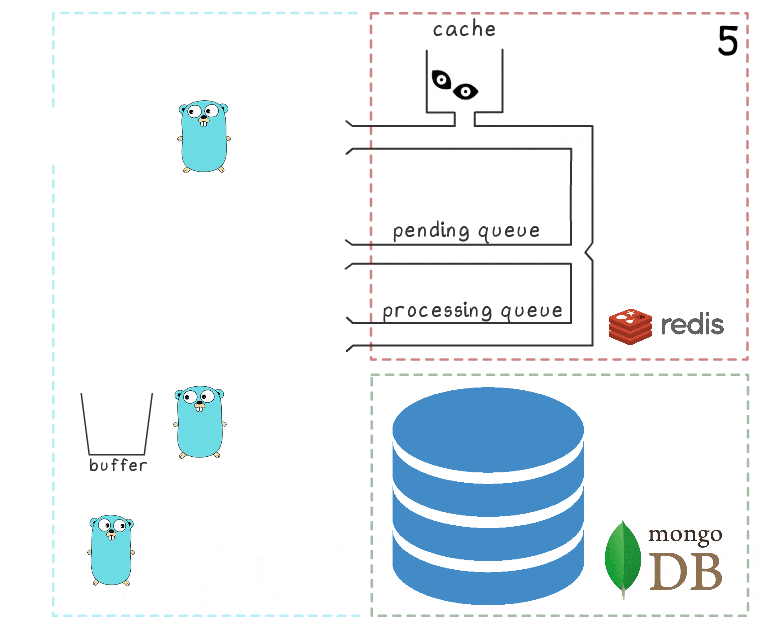
لفهم خطوات العملية بأكملها بشكل أفضل ، قمنا بإعداد تصور صغير. أولاً ، دعونا نلقي نظرة على سيناريو طبيعي وناجح (يتم ترقيم الخطوات في الركن الأيمن العلوي ووصفها بالتفصيل أدناه):
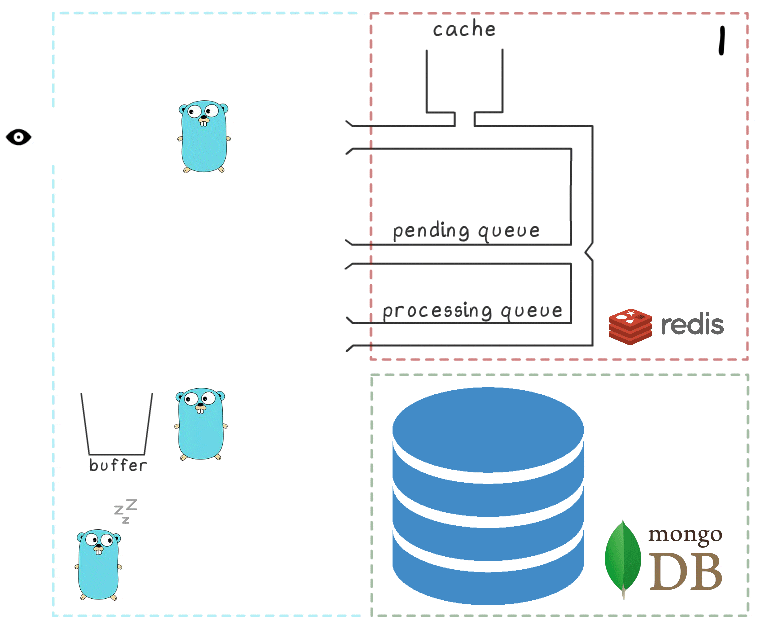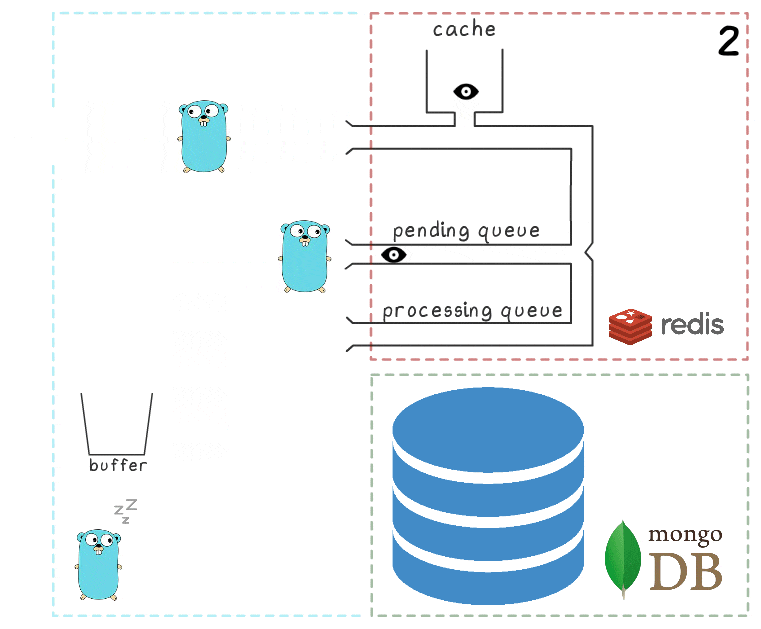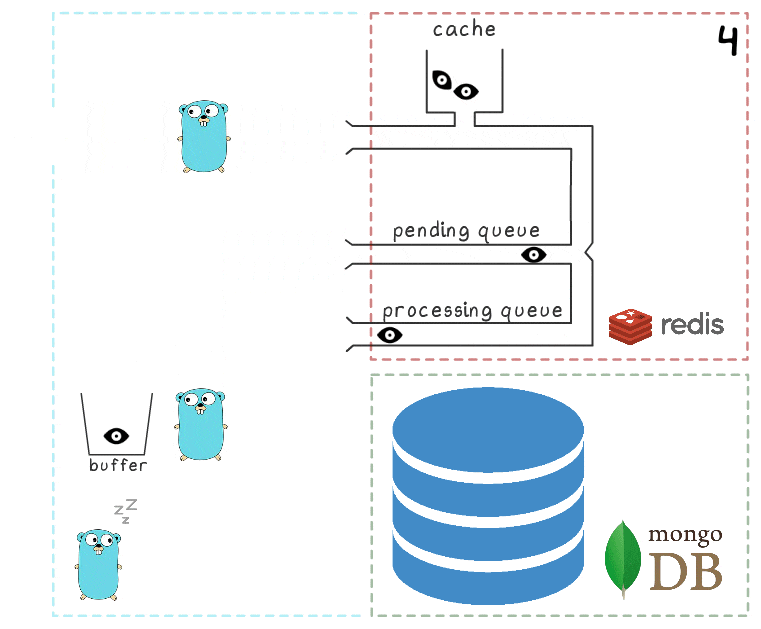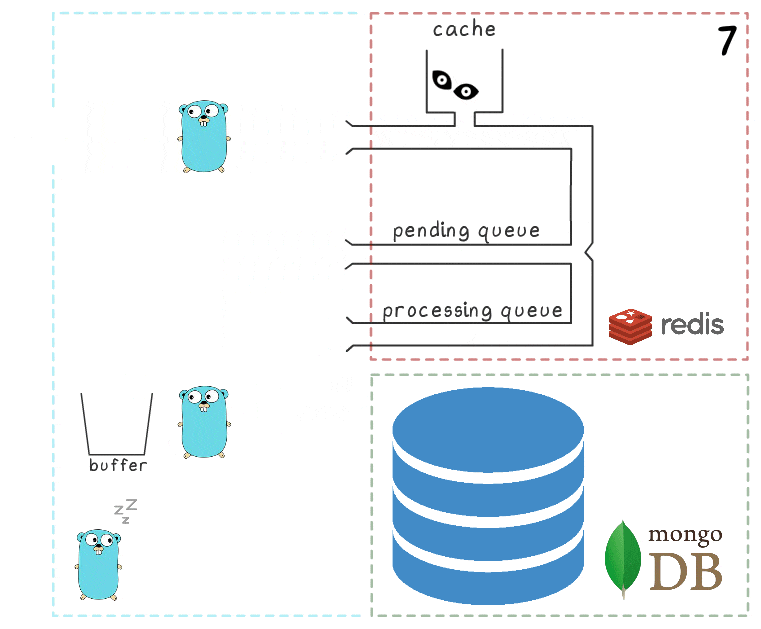
- خدمة microservice يتلقى طلب الكتابة
- يقوم معالج الطلب بتمريره إلى برنامج نصي lua يقوم بكتابة البحث إلى ذاكرة التخزين المؤقت (مما يجعله قابلاً للقراءة على الفور) وإلى قائمة الانتظار لمزيد من المعالجة.
- يقوم goroutine في الخلفية (بشكل دوري) بتنفيذ عملية BRPopLPush ، التي تنقل عنصرًا من قائمة انتظار إلى أخرى بشكل تلقائي (نسميها "قائمة انتظار المعالجة" - قائمة انتظار تحتوي على عناصر تمت معالجتها حاليًا). ثم يتم تخزين نفس العنصر في مخزن مؤقت في ذاكرة العملية.
- يصل طلب كتابة آخر ويجري معالجته ، مما يتركنا مع عنصرين في المخزن المؤقت وعنصران في قائمة انتظار المعالجة.
- بعد بعض المهلة ، تقرر عملية الخلفية لمسح المخزن المؤقت في MongoDB. تتم كتابة قيم متعددة من المخزن المؤقت من خلال طلب واحد ، مما يؤثر بشكل إيجابي على الإنتاجية. أيضًا ، قبل التسجيل ، تحاول العملية دمج عدة طرق عرض في عرض واحد ، مع تجميع قيمها لنفس الإعلانات.
في كل مشروع من مشاريعنا ، يتم استخدام 3 حالات من خدمات micros ، كل منها به مخزن مؤقت خاص به ، يتم حفظه في قاعدة البيانات كل ثانيتين. خلال هذا الوقت ، يتم تجميع حوالي 100 عنصر في مخزن مؤقت واحد.
- بعد الكتابة الناجحة ، تزيل العملية العناصر من قائمة انتظار المعالجة ، مما يشير إلى أن المعالجة اكتملت بنجاح.
عندما تكون جميع النظم الفرعية سليمة ، قد تبدو بعض هذه الخطوات زائدة عن الحاجة. وقد يكون للقارئ المهتم أيضًا سؤال حول ما يفعله غوفر في الركن الأيسر السفلي.
يتم شرح كل شيء عند النظر في السيناريو عندما يكون MongoDB غير متوفر:
- الخطوة الأولى مماثلة للأحداث من السيناريو السابق: تتلقى الخدمة طلبين لتسجيل المشاهدات ومعالجتها.
- العملية تفقد الاتصال بـ MongoDB (العملية نفسها ، بالطبع ، لا تعرف ذلك بعد).
يحاول معالج Gorutin ، كما كان من قبل ، تدفق المخزن المؤقت الخاص به إلى قاعدة البيانات - ولكن هذه المرة دون نجاح. تعود إلى انتظار التكرار التالي.
- تستيقظ goroutine خلفية أخرى وتتحقق من قائمة انتظار المعالجة. تكتشف أن العناصر أضيفت إليها منذ زمن طويل ؛ خلصت إلى أن فشل معالجتها ، فإنها تعيدهم إلى قائمة الانتظار المعلقة.
- بعد فترة من الوقت ، تتم استعادة الاتصال مع MongoDB.
- يحاول goroutine الخلفية الأولى مرة أخرى إجراء عملية كتابة - هذه المرة بنجاح - وفي النهاية يزيل العناصر نهائيًا من قائمة انتظار المعالجة.
في هذا المخطط ، هناك العديد من المهلات الهامة والاستدلال المستمدة من الاختبار والحس السليم: على سبيل المثال ، يتم نقل العناصر من قائمة انتظار المعالجة إلى قائمة الانتظار المعلقة بعد 15 دقيقة من عدم النشاط. بالإضافة إلى ذلك ، يقوم goroutine المسؤول عن هذه المهمة بإجراء
قفل قبل التنفيذ بحيث لا تحاول عدة مثيلات من الخدمة المجهرية استعادة طرق العرض "المجمدة" في نفس الوقت.
بالمعنى الدقيق للكلمة ، حتى هذه التدابير لا توفر ضمانات مدعومة من الناحية النظرية (على سبيل المثال ، نحن نتجاهل سيناريوهات مثل العملية تتجمد لمدة 15 دقيقة) - لكنها في الواقع تعمل بشكل موثوق.
أيضًا في هذا المخطط ، يوجد على الأقل 2 من نقاط الضعف المعروفة لنا والتي يجب أن تكون على دراية بها:
- إذا تعطلت خدمة microservice مباشرة بعد الحفظ بنجاح إلى MongoDb ، ولكن قبل مسح قائمة انتظار المعالجة ، سيتم اعتبار هذه البيانات غير محفوظة - وبعد 15 دقيقة سيتم حفظها مرة أخرى.
لتقليل احتمالية حدوث مثل هذا السيناريو ، قدمنا محاولات متكررة للإزالة من قائمة انتظار المعالجة في حالة وجود أخطاء. في الواقع ، لم نلاحظ بعد مثل هذه الحالات في الإنتاج.
- عند إعادة التشغيل ، قد يفقد الفجل ليس فقط ذاكرة التخزين المؤقت ، ولكن أيضًا بعض المشاهدات غير المحفوظة من قوائم الانتظار ، حيث يتم تكوينه لحفظ لقطات RDB بشكل دوري كل بضع دقائق.
على الرغم من أن هذا من الناحية النظرية يمكن أن يكون مشكلة خطيرة (خاصة إذا كان المشروع يتعامل مع بيانات مهمة بالفعل) ، نادراً ما يتم إعادة تشغيل العقد في الممارسة. في الوقت نفسه ، وفقًا للرصد ، تنفق العناصر في قوائم الانتظار لمدة تقل عن 3 ثوانٍ ، أي أن مقدار الخسائر المحتمل محدود للغاية.
قد يبدو أن هناك مشاكل أكثر مما نود. ومع ذلك ، في الواقع ، اتضح أن السيناريو الذي دافعنا عنه في البداية - فشل MongoDB - هو بالفعل تهديد حقيقي أكثر ، وأن مخطط معالجة البيانات الجديد يضمن بنجاح توفر الخدمة ويمنع الخسائر.
كان أحد الأمثلة الحية على ذلك عندما كانت نسخة MongoDB في أحد المشاريع غير متاحة بشكل سخيف طوال الليل. طوال هذا الوقت ، قم بمشاهدة التعدادات المتراكمة وتدويرها في الفجل من قائمة انتظار إلى أخرى ، حتى يتم حفظها في نهاية المطاف في قاعدة البيانات بعد حل الحادث ؛ معظم المستخدمين لم يلاحظوا حتى الفشل.
قراءة عرض التهم
تكون طلبات القراءة أبسط بكثير من طلبات الكتابة: تقوم الخدمة الميكروية أولاً بفحص ذاكرة التخزين المؤقت في الفجل ؛ يتم تعبئة كل ما لم يتم العثور عليه في ذاكرة التخزين المؤقت ببيانات من MongoDb وإعادته إلى العميل.
لا توجد الكتابة من البداية إلى النهاية إلى ذاكرة التخزين المؤقت أثناء عمليات القراءة لتجنب الحمل من الحماية ضد عمليات الكتابة التنافسية. بقيت ذاكرة التخزين المؤقت جيدة ، حيث أنه في أكثر الأحيان ، سيتم تسخينها بالفعل بفضل طلبات الكتابة الأخرى.
تتم قراءة إحصائيات العرض اليومي مباشرةً من MongoDB ، حيث يتم طلبها كثيرًا كثيرًا ، وتخزينها أكثر صعوبة. يعني أيضًا أنه عندما تكون قاعدة البيانات غير متوفرة ، تتوقف قراءة الإحصائيات عن العمل ؛ لكنه يؤثر فقط على جزء صغير من المستخدمين.
نظام تخزين البيانات MongoDB
يعتمد نظام تجميع MongoDB للمشروع على
هذه التوصيات من مطوري قاعدة البيانات أنفسهم ، ويبدو كما يلي:
- يتم حفظ المشاهدات في مجموعتين: واحدة في مجموع المبلغ الإجمالي ، في المجموعة الأخرى - إحصاءات يوما بعد يوم.
- يتم تنظيم البيانات في مجموعة الإحصائيات على أساس وثيقة واحدة لكل إعلان شهريًا . بالنسبة للإعلانات الجديدة ، يتم إدراج مستند مملوء بواحد وثلاثين صفر للشهر الحالي في المجموعة ؛ وفقًا للمقال المذكور أعلاه ، يتيح لك هذا على الفور تخصيص مساحة كافية لمستند على القرص حتى لا تضطر قاعدة البيانات إلى نقله عند إضافة البيانات.
يجعل هذا العنصر عملية قراءة الإحصائيات صعبة بعض الشيء (يجب إنشاء الطلبات بشهور على الجانب المصغر من الخدمات) ، ولكن بشكل عام ، يظل المخطط بديهيًا للغاية.
- تُستخدم عملية المغالاة في التسجيل ، من أجل التحديث ، وإذا لزم الأمر ، إنشاء مستند للكيان المطلوب في نفس الطلب.
لا نستخدم إمكانيات المعاملات الخاصة بـ MongoDb لتحديث عدة مجموعات في نفس الوقت ، مما يعني أننا نجازف بإمكانية كتابة البيانات في مجموعة واحدة فقط. في الوقت الحاضر ، نحن ببساطة تسجيل الدخول في مثل هذه الحالات ؛ هناك عدد قليل منهم ، وحتى الآن لا يمثل هذا نفس المشكلة المهمة مثل السيناريوهات الأخرى.
اختبار
لن أثق في كلماتي بأن السيناريوهات الموصوفة تعمل حقًا إذا لم تكن مغطاة بالاختبارات.
نظرًا لأن معظم رمز المشروع يعمل عن كثب مع الفجل و MongoDb ، فإن معظم الاختبارات الموجودة فيه عبارة عن اختبارات تكامل. يتم دعم بيئة الاختبار من خلال docker-compose ، مما يعني أنه يمكن نشرها بسرعة ، ويوفر إمكانية التكاثر عن طريق إعادة ضبط واستعادة الحالة في كل بداية ، ويجعل من الممكن التجربة دون التأثير على قواعد بيانات الآخرين.
في هذا المشروع ، هناك ثلاثة مجالات رئيسية للاختبار:
- التحقق من صحة منطق الأعمال في السيناريوهات النموذجية ، ما يسمى طريق سعيد. تجيب هذه الاختبارات على السؤال - عندما تكون جميع الأنظمة الفرعية في حالة جيدة ، هل تعمل الخدمة وفقًا للمتطلبات الوظيفية؟
- التحقق من السيناريوهات السلبية التي من المتوقع أن تستمر الخدمة في عملها. على سبيل المثال ، هل الخدمة لا تفقد البيانات عند تعطل MongoDb؟
هل نحن متأكدون من أن المعلومات تظل متسقة مع المهلات الدورية وعمليات التجميد التنافسية؟ - التحقق من السيناريوهات السلبية التي لا نتوقع استمرار الخدمة فيها ، ولكن يجب توفير الحد الأدنى من الوظائف. على سبيل المثال ، لا توجد فرصة لاستمرار الخدمة في حفظ البيانات وإعطاءها في حالة عدم توفر الفجل أو المونغو - لكننا نريد أن نتأكد من أنه في مثل هذه الحالات لا تتعطل ، ولكن يتوقع استرداد النظام ثم العودة إلى العمل.
للتحقق من السيناريوهات غير الناجحة ، يعمل كود منطق أعمال الخدمة مع واجهات عميل قاعدة البيانات ، والتي يتم استبدالها في الاختبارات الضرورية بالتطبيقات التي تعرض الأخطاء و / أو تحاكي تأخيرات الشبكة. نحن نحاكي أيضًا التشغيل المتوازي للعديد من مثيلات الخدمة باستخدام نمط "
كائن البيئة ". هذا هو البديل لنهج "التحكم الانعكاس" المعروف ، حيث لا تصل الدوال إلى التبعيات نفسها ، ولكنها تستقبلها من خلال كائن البيئة الذي تم تمريره في الوسائط. من بين المزايا الأخرى ، يتيح لك هذا النهج محاكاة عدة نسخ مستقلة من الخدمة في اختبار واحد ، لكل منها مجموعة خاصة بها من الاتصالات بقاعدة البيانات وتنتج بيئة الإنتاج بشكل أكثر أو أقل كفاءة. تعمل بعض الاختبارات على كل حالة من هذه الحالات بشكل متوازٍ وتأكد من أنها جميعًا ترى نفس البيانات ، ولا توجد شروط سباق.
لقد أجرينا أيضًا اختبار إجهاد بدائي ، لكن لا يزال مفيدًا جدًا بناءً على
الحصار ، مما ساعد تقريبًا على تقدير الحمل المسموح به وسرعة الاستجابة من الخدمة.
عن الأداء
بالنسبة إلى 90٪ من الطلبات ، يكون وقت المعالجة صغيرًا جدًا ، والأهم من ذلك - الاستقرار ؛ فيما يلي مثال للقياسات في أحد المشاريع على مدار عدة أيام:
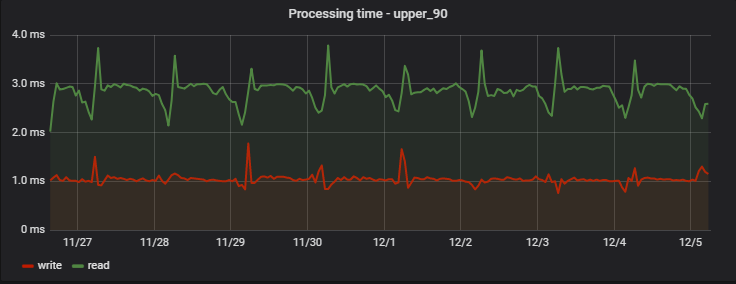
ومن المثير للاهتمام ، أن السجل (والذي هو في الواقع عملية كتابة + قراءة ، لأنه يُرجع قيمًا محدثة) أسرع قليلاً من القراءة (ولكن فقط من وجهة نظر العميل الذي لا يلاحظ الكتابة الفعلية المعلقة).
الزيادة الصباحية المنتظمة في التأخيرات هي أحد الآثار الجانبية لعمل فريق التحليلات لدينا ، الذي يجمع إحصائياته الخاصة يوميًا استنادًا إلى بيانات الخدمة ، مما يخلق "حملاً ثقيلًا اصطناعيًا" لنا.
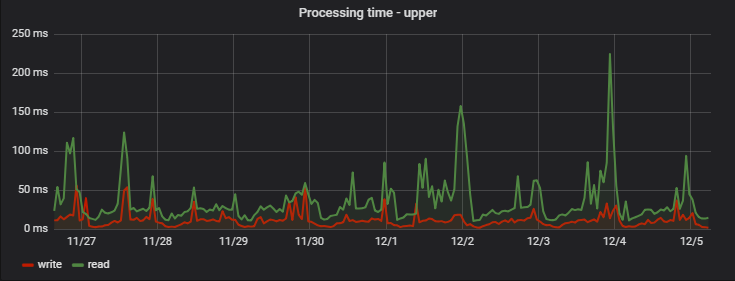
: ( — MongoDB), ( ), :
الخاتمة
لقد أظهرت الممارسة ، إلى حد ما بطريقة عكسية ، أن استخدام Redis كمستودع رئيسي لخدمة المشاهدة أدى إلى زيادة الاستقرار العام وتحسين سرعته الإجمالية.الحمل الرئيسي للخدمة هو قراءة الطلبات ، والتي يتم إرجاع 95٪ منها من ذاكرة التخزين المؤقت ، وبالتالي تعمل بسرعة كبيرة. يتم تأخير طلبات التسجيل ، على الرغم من أنها من وجهة نظر المستخدم النهائي تعمل أيضًا بسرعة وتصبح مرئية لجميع العملاء على الفور. بشكل عام ، يتلقى جميع العملاء تقريبًا ردودًا في أقل من 5 مللي ثانية.ونتيجة لذلك ، فإن الإصدار الحالي من الخدمة المصغرة المستندة إلى Go و Redis و MongoDB يعمل بنجاح تحت الحمل وقادر على التغلب على عدم التوافر الدوري لأحد متاجر البيانات. استنادًا إلى خبرتنا السابقة في مشاكل البنية الأساسية ، حددنا سيناريوهات الخطأ الرئيسية ودافعنا عنها بنجاح ، حتى لا يعاني معظم المستخدمين من الإزعاج. ونحن بدورنا نتلقى عددًا أقل بكثير من الشكاوى والتنبيهات والرسائل في السجلات - ونحن مستعدون لزيادة الحركة.