في الآونة الأخيرة ، تحدث ايجور بودنيكوف ، محلل النظام في قسم التكنولوجيا في ABBYY ، في ياندكس في المؤتمر
البيانات والعلوم: القانون وإدارة السجلات . وقال كيف تعمل رؤية الكمبيوتر ، تحدث معالجة النصوص ، ما هو المهم الانتباه إليه عند استخراج المعلومات من الوثائق القانونية وأكثر من ذلك بكثير.
- قد تكون إحدى الشركات قد طورت منهجيات لتحليل البيانات وإدارة المستندات الإلكترونية ، في حين أن المستندات التي تم إنشاؤها في Word قد تأتي من عملاء أو من أقسام مجاورة ، مطبوعة أو نسخها ضوئيًا أو مسحها ضوئيًا وإحضارها إلى محرك أقراص محمول.
ماذا تفعل مع تدفق المستند ، والذي أصبح الآن ، مع المستندات "القذرة" ، مع تخزين الورق ، حتى حقيقة أنه يمكن تخزين المستندات لمدة تصل إلى 70 عامًا قبل أن يتم فحصها ضوئيًا ويجب الاعتراف بها؟
تقوم ABBYY بتطوير تقنيات الذكاء الاصطناعي لمهام العمل. يجب أن يكون الذكاء الاصطناعي قادراً على فعل نفس الشيء تقريباً الذي يقوم به الشخص في النشاط اليومي أو المهني ، ألا وهو: قراءة المعلومات حول العالم الحقيقي من صورة أو مجموعة من الصور. قد لا يكون هذا مجرد رؤية للكمبيوتر ، ولكن أيضًا السمع أو التعرف على البيانات من أجهزة الاستشعار ، على سبيل المثال ، من أجهزة استشعار الدخان أو درجة الحرارة. علاوة على ذلك ، فإن البيانات من هذه المجسات تدخل النظام ويجب أن تشارك في القرار. لتنفيذ هذه الوظيفة بنجاح ، يجب على النظام منع الأخطاء المنطقية الغبية ، كما في الصورة:
يصعب تحليل النصوص: تنوع اللغة وتطويرها يجعلها جميلة ومعبرة ، ولكن هذا يعقد مهمة معالجتها التلقائية. عادة ، يتم التغلب على غموض الكلمات من خلال حقيقة أنه يمكننا تحديد السياق معنى كلمة معينة ، ولكن في بعض الأحيان يترك السياق مجالًا للتفسير. في عبارة "
هذه الأنواع من الفولاذ موجودة في المخزون " ، يستحيل فهمها بدقة تامة من حيث السياق: سواء كان الأشخاص في الغرفة يتناولون الغداء ، أو هذه هي بعض أنواع الصلب التي يتم تخزينها في المستودع. من أجل حل هذا الغموض ، هناك حاجة إلى سياق أوسع.
الجزء السفلي من الكولاج هو إطار من فيلم "العملية" Y "ومغامرات Shurik الأخرى."في الحالة العامة ، يجب أن تكون الذكاء الاصطناعي أو الروبوت الذكي قادرًا على التحرك في الفضاء والتفاعل بنجاح مع الأشياء - على سبيل المثال ، التقط الصندوق مرارًا وتكرارًا ، والذي يخرج منه المدرب من يديه.
أخيرًا ، الذكاء العام وتمثيل المعرفة: المعرفة تختلف عن المعلومات في أن أجزائها تتفاعل بنشاط مع بعضها البعض ، وتولد معرفة جديدة. من أجل حل مشكلة خلط الكوكتيلات بفعالية ، يمكنك اتباع الطريقة البسيطة: سرد المكونات والإشارة إلى ترتيب مزجها. في هذه الحالة ، لن يتمكن النظام من الإجابة على الأسئلة التعسفية حول موضوع اهتمامه. على سبيل المثال ، ماذا يحدث إذا استبدلت عصير الطماطم بالأناناس. لكي يتقن النظام المادة بشكل أعمق ، قواعد البيانات ، تصنيفات (أشجار المفهوم مرتبطة منطقيا مع بعضها البعض) ، يجب إضافة إجراء الاستدلال المنطقي. في هذه الحالة ، يمكننا أن نقول حقًا أن النظام يفهم ما يفعله ، وسيكون قادرًا على الإجابة على سؤال تعسفي حول العملية.
يقوم الذكاء الاصطناعي الذي طورته ABBYY بمعالجة المستندات ، أي تحويل الورق والمسح الضوئي والوسائط الإلكترونية إلى معلومات منظمة مستخرجة من هذه المستندات. دعونا نتحدث عن مكونين ، مثل رؤية الكمبيوتر ومعالجة النصوص. تتيح لك رؤية الكمبيوتر تحويل ملفات PDF والصور الممسوحة ضوئيًا والصور إلى تنسيقات نصية قابلة للتحرير. لماذا هذه مهمة صعبة؟ أولاً ، يمكن أن يكون للوثائق هيكل تعسفي.
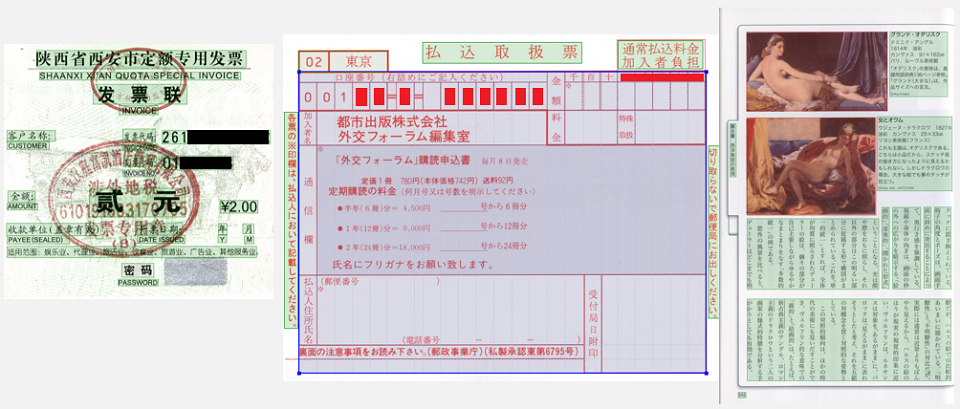
هذا يعني أنك تحتاج أولاً إلى حل مشكلة التحليل الهيكلي للوثائق: لفهم مكان وجود كتل النصوص والصور والجداول والقوائم ، ثم تحديد كيفية تفاعلها مع بعضها البعض. ثانياً ، يمكن أن تكون المستندات بلغات مختلفة. هذا يعني أنه من الضروري دعم اكتشاف أنواع مختلفة من الكتابة والقدرة على التعرف على الكلمات والحروف التي يمكن أن تكون مختلفة تمامًا عن بعضها البعض. ثالثًا ، تأتي الصور إلينا من العالم الحقيقي ، مما يعني أن أي شيء يمكن أن يحدث لهم. قد يتم تشويهها أو تصويرها بمنظور خاطئ أو قد يكون بها بقع قهوة أو خطوط من الطابعة ثم من الماسح الضوئي. كل هذا يجب أن تدار بطريقة ما من أجل استخراج المعلومات في وقت لاحق.
كيف يعمل التعرف على الصور معنا؟ في المرحلة الأولى ، نتلقى ونعالج الصور. تم تسوية المستند ، ويتم تصحيح التشوهات. ثم يتم إجراء تحليل لهيكل الصفحة ، في هذه المرحلة يتم العثور على أنواع الكتل وتحديدها. عندما يتم تعريف الكتل ، يتم محاذاة الصفوف أو الأعمدة ، يمكنك تقسيم هذه الخطوط إلى كلمات ورموز - على سبيل المثال ، بواسطة مدرج تكراري رأسي وأفقي لتوزيع اللون الأسود.
وبالتالي ، من الممكن تحديد مكان حدود الرموز والكلمات ، ثم التعرف على ماهية هذه الرموز والكلمات. أخيرًا ، يتم تجميع الكتل المعترف بها في مستندات نصية واحدة وتصديرها.
يمكنك إلقاء نظرة على هذه العملية من وجهة نظر الكيانات ذات المستويات المختلفة. أولاً لدينا وثيقة مرقمة. بعد ذلك ، يجب تقسيم هذه الصفحات إلى كتل ، وكتل في خطوط ، وخطوط في كلمات ، وكلمات إلى أحرف ، ومن ثم يجب التعرف على هذه الأحرف. بعد ذلك ، نقوم بتجميع الأحرف المعترف بها في كلمات ، كلمات في خطوط ، خطوط في كتل ، كتل في صفحات ، صفحات في وثيقة. علاوة على ذلك ، في طريق العودة ، قد يختلف القسم الأولي. أبسط مثال على ذلك هو ما إذا كانت الكتل المكسورة في البداية تنتمي إلى نفس القائمة المرقمة ، لذلك يجب أن تنتمي في النهاية إلى نفس الكتل بنوع القائمة المهيكلة. بمعنى آخر ، يمكن أن تؤثر الخطوات المجاورة على بعضها البعض من أجل تحسين جودة التعرف.
تم التعرف على المستند ، ثم تحتاج إلى استخراج معلومات منه. يمكن تقسيم المستندات إلى مستندات أكثر تنظيماً وأقل تنظيماً. وأكثر تنظيما تشمل بطاقات العمل والشيكات والفواتير. الأقل تنظيما تشمل التوكيل ، والمواثيق ، والمقالات في المجلات. إذا كان نوع المستند ثابتًا ، فهو منظم بشكل أو بآخر ولا تختلف المستندات الموجودة في هذا النوع كثيرًا عن بعضها البعض في البنية ، فيمكنك تطبيق أساليب تتعلم كيفية استخراج السمات الضرورية مباشرة من مستند نصي باستخدام سمات نصية ورسومات. على سبيل المثال ، باستخدام الشبكات العصبية المتكررة ، يمكنك استخراج عناصر المنتج من الفواتير. الفواتير هي المستندات التي يتم فيها عرض مواقف البضائع ووصف طرق الدفع لهذه البضائع.

مثال آخر هو الشيكات. باستخدام الشبكات العصبية التلافيفية ، يمكنك استرداد السمات الفردية ، مثل TIN ورقم التحقق والتاريخ والوقت الإجمالي. بصراحة ، يتم استخدام كل من الطرق والشيكات في الشيكات والفواتير ، ولكن لأغراض مختلفة. تعتبر الشبكات العصبية التلافيفية جيدة للسمات الفردية التي لها نوع من الموضع ، والشبكات المتكررة للعناصر المتكررة.
إذا كانت المستندات أقل تنظيماً ، فسيتم تشغيل معالجة اللغة الطبيعية أو معالجة اللغة الطبيعية أو أساليب البرمجة اللغوية العصبية. لماذا هو صعب؟ لقد تحدثت بالفعل عن polysemy الكلمات. على سبيل المثال ، يمكن أن تعني كلمة العنوان عنوان الشركة ، أو يمكن أن تعني التزامها بحل بعض مشكلات العملاء.
أيضًا ، غالبًا ما يتم حذف النصوص ، لكن الكلمات ضمنية. من أجل استخراج المعلومات ، تحتاج إلى استعادة هذه الكلمات المفقودة. ويسمى هذا التأثير في علم اللغة "القطع الناقص".
اللغة متنوعة ، وعادة ما تكون هناك طرق لا حصر لها للتعبير عن الفكر نفسه. من أجل معالجة النصوص تلقائيًا ، من الضروري تقليل هذا التباين بطريقة أو بأخرى: استخدام المرادفات والتركيبات المماثلة لاستبدال كلمة أو تعبير واحد ؛ التقليب من الكلمات أو تغيير الصوت النحوي. على سبيل المثال ، "أبرمت الشركات اتفاقية" و "اتفاقية أبرمت بين الشركات" لقول نفس الشيء. في حالة المرادفات ، يمكن للمرء أن يقدم ما يسمى الفضاء الدلالي ، مساحة متجه يتم فيها تمثيل الكلمات كنقاط. تشير نقاط الإغلاق إلى المفاهيم ذات الصلة ، وتشير النقاط البعيدة إلى مفاهيم بعيدة. لتقليل تباين التركيبات ، يمكنك إدخال أشجار تحليل النحوية والدلالية. في هذه الحالة ، يتم أيضًا حل مشكلة مماثلة ، وتكون خوارزمية استخراج المعلومات قادرة على استخراج المعلومات ، حتى لو واجهت إنشاءات أو كلمات لم يتم العثور عليها مسبقًا في مجموعة التدريب.
كيف يتم استخراج المعلومات؟ في المرحلة الأولى ، يتم إجراء تحليل معجمي للوثيقة. النص مقسم إلى فقرات ، فقرات إلى جمل ، جمل إلى كلمات. قد لا يكون هذا أمرًا تافهًا: قد يكون من الصعب على من يعرفونك البرمجة اللغوية العصبية معرفة أنه حتى هذه المهمة البسيطة التي تبدو بسيطة مثل تقسيم النص إلى جمل قد تكون صعبة: لا تشير النقاط دائمًا إلى نهاية الجملة. قد تكون هذه اختصارات غير معروفة ، لذلك ، في التحليل المعجمي ، نحاول فرز جميع الخيارات الممكنة لتقسيم الجمل إلى كلمات وترك الاحتمال الأكبر. هذه المشكلة ، كقاعدة عامة ، نواجهها بلغات بها عدد صغير أو الغياب التام للمسافات ، مثل اليابانية أو الصينية. أو الذين لديهم تشكيل كلمة غنية. هذه ، على سبيل المثال ، لغة مثل اللغة الألمانية: تحتوي على كلمات طويلة جدًا تتكون من عدة كلمات (تسمى هذه الكلمات مركبة). أيضا ، لكل هذه الكلمات ، يتم حساب جميع التفسيرات الممكنة. على سبيل المثال ، إذا ظهرت كلمة "g" في النص مع نقطة ، فإن هذا قد يعني الكثير: المدينة ، السنة ، غرام ، الرجل المحترم ، وحتى الفقرة الرابعة (أ ، ب ، ج ، د).

ثم يتم تنفيذ التجزئة ، أي البحث عن الأقسام التي تهمنا. يتم إنتاجه لأسباب مختلفة ، على سبيل المثال ، لتسريع معالجة المستندات أو العثور على المعلومات التي تهمنا ؛ للعثور على جزء من المستند الذي يصف التزامات الطرف. أو هذا يعد تسريعًا للمعالجة ، على سبيل المثال ، قد تتكون وثيقتنا من عدة عشرات أو حتى مئات الصفحات في الحالات المتقدمة بشكل خاص ، بينما يتم تضمين معلومات مثيرة للاهتمام في بضع صفحات فقط. يسمح لك التقسيم بالعثور على هذه القطع المثيرة للاهتمام وتحليلها فقط. بعد ذلك ، قد يتم أو لا يمكن إجراء تحليل دلالي للوثيقة ، ويعتمد ذلك على المهمة ، وفي هذه المرحلة يتم البحث عن أفضل التفسيرات للجمل ، أو كل جمل الوثيقة أو فقط تلك التي وجدناها في المرحلة السابقة. يتم أيضًا إنشاء الميزات الدلالية للمصنف في الخطوة التالية.
وأخيرا ، مرحلة الاستخراج المباشر للسمات. يتم استخدام النماذج المدربة آليًا هنا أو تتم كتابة أنماط بسيطة. بطريقة أو بأخرى ، يعتمدون على العلامات الناتجة عن الخطوات السابقة. هذه هي السمات الهيكلية ، سواء المعجمية والدلالية. اعتمادًا على تعقيد المهمة ، نستخدم العديد من الطرق المختلفة: أساليب التعلم الآلي وطرق كتابة القالب. في هذه المرحلة ، نبحث عن السمات التي تهمنا. يمكن أن تكون أسماء الأطراف والالتزامات وتاريخ التوقيع ، إلخ.
أخيرًا ، قد تتطلب بعض السمات مرحلة ما بعد المعالجة. جلب إلى النموذج العادي أو الصب إلى قالب التاريخ. يمكن حساب بعض السمات من حيث المبدأ ، لا يتم استخراجها من العقد ، ولكن يتم حسابها على أساس تلك السمات التي يتم استخراجها من العقد. على سبيل المثال ، مدة العقد بناءً على بداية الإجراء ونهايته.
النظر في هذا في واحدة من السيناريوهات ، ويسمى "فتح حساب مع كيان قانوني." ما هو التحدي؟ يأتي كيان قانوني ، أو بالأحرى ممثله ، إلى البنك ويحضر مجموعة كبيرة من المستندات. في حالة جيدة ، قام بالفعل بمسح هذه المستندات ضوئيًا ، لكن ليس من الواضح ما هي الجودة. من أجل تحسين العملية ، تقليل عدد الأخطاء في إدخال هذه المعلومات في النظام ، وتسريع هذه العملية ، وبالتالي ، تسريع عملية صنع القرار وزيادة ولاء العملاء ، تم اقتراح المخطط التالي:
يتم فحص المستندات التأسيسية ، التي تتضمن الكثير من الأنواع المختلفة ، أولاً ، ثم يتم التعرف عليها. علاوة على ذلك ، بعد التعرف عليها ، يتم تصنيفها حسب أنواع مختلفة ، ووفقًا للنوع ، يمكن استخدام خوارزميات مختلفة للتعرف على المعلومات واستخراجها. بعد ذلك ، يتم إرسال هذه المعلومات المستخرجة ، إذا لزم الأمر ، إلى الأشخاص للتحقق منها ، وبعد ذلك أصبح من الممكن بالفعل اتخاذ قرار: فتح حساب ، أو هناك حاجة إلى بعض المستندات الإضافية الأخرى. والنتيجة الرئيسية لهذا القرار هي خفض تكلفة إدخال البيانات إلى النصف عند فتح حساب. النتائج بناء على قياسات عملائنا.
ما هي السمات التي تحتاجها لاسترجاعها؟ الكثير من الأشياء. لنفترض أن لدينا نوع من الميثاق القادمة. أولا نحن ندرك ذلك. كما نتذكر ، يمكن أن يكون هذا مشكلة كبيرة إذا كان المسح أو صورة فوتوغرافية. بعد ذلك ، نحدد نوع المستند ، وهذا مهم لأن المعلومات التي نحتاجها يمكن تضمينها في فصل أو بند فرعي معين ، وبالتالي فإن معرفة متى يبدأ هذا الفصل أو الفقرة الفرعية أو تنتهي به يساعد إلى حد كبير خوارزمية استخراج المعلومات.
ثم يسترد الجهاز جميع الكيانات الأساسية التي يمكنه الوصول إليها:
يعد ذلك ضروريًا حتى في المرحلة التالية لاستخراج السمات أو تحديد الأدوار ، لا يمكن للخوارزمية استخدام السياق فحسب ، بل أيضًا الخصائص التي تم إنشاؤها في المراحل السابقة. على سبيل المثال ، يمكنه تبسيط مهمة تحديد من هو مدير كيان قانوني ، وهي معلومات من نوع ما. وفقًا لذلك ، من بين مجموعة الأشخاص الذين يظهرون في المستند ، يجب أن نصنفهم ، سواء كانوا مديرًا أم لا. عندما يكون لدينا عدد محدود من الكائنات ، فإن هذا يبسط المهمة إلى حد كبير.
على مدار العامين الماضيين ، واجهنا العديد من مهام العملاء وحلناها بنجاح. على سبيل المثال ، مراقبة وسائل الإعلام لمخاطر الشركات.
ما هو التحدي التجاري هنا؟ على سبيل المثال ، لديك شريك أو عميل محتمل يريد الحصول على قرض منك. من أجل الإسراع في معالجة بيانات هذا العميل وتقليل مخاطر شراكة سيئة ، أو إفلاس هذا الكيان القانوني في المستقبل ، يُقترح مراقبة الوسائط بحثًا عن إشارات إلى هذا الفرد أو الكيان القانوني ولوجود ما يسمى مؤشرات المخاطر في الأخبار. أي أنه ، على سبيل المثال ، في الأخبار التي تنبثق باستمرار عن تورط كيان قانوني في الإجراءات القانونية أو تعطل شركة ما بسبب تعارضات المساهمين ، فمن الأفضل أن تكتشف ذلك مسبقًا من أجل نقل هذه المعلومات إلى المحللين أو النظام التحليلي وفهم مدى سوء أو جودة أعمالك . نتيجة حل هذه المشكلة هي الحصول على معلومات أكثر اكتمالا ودقيقة حول المقترض ، كما يتم تقليل مقدار الوقت اللازم للحصول على هذه المعلومات.
مثال آخر للتطبيق الذي يلزم فيه تقليل مقدار الروتين وعدد الأخطاء عند إدخال المعلومات في النظام وهو استخراج البيانات من العقود. يُقترح أن تتعرف العقود على المعلومات وتخرج منها وترسلها على الفور إلى النظام. بعد ذلك ، فإن قسم شؤون الموظفين يشكركم ويرحب بكم بحرارة في كل اجتماع.
ليس فقط إدارة الموارد البشرية تعاني من الكثير من العمل الروتيني مع الوثائق الواردة ، ولكن أيضا إدارات المحاسبة ، وإدارات المبيعات ، وإدارات الشراء. يتعين على الموظفين قضاء الكثير من الوقت في إدخال المعلومات من الفواتير والأفعال الواردة وما إلى ذلك.
في الواقع ، جميع هذه الوثائق مهيكلة ، وبالتالي فمن السهل التعرف عليها واستخراج المعلومات منها. يتم زيادة سرعة إدخال البيانات تصل إلى 5 مرات ، ويتم تقليل عدد الأخطاء ، لأنه يتم استبعاد العامل البشري. بشرط ، إذا عاد الموظف بعد الغداء ، فقد يبدأ في إدخال البيانات عن غير قصد. تشير قياساتنا الخاصة والصناعة ، التي تشارك بطريقة أو بأخرى في الإدخال اليدوي للمعلومات في الأنظمة ، إلى أنه إذا قام شخص ما بإدخال بيانات من مستند ، وقام بذلك بشكل مستمر وفي تدفق ، فنادراً ما يحصل على جودة أعلى من 95٪ ، و في كثير من الأحيان وأكثر من 90 ٪. لذلك ، يحتاج الشخص إلى حسابه ، والتحقق منه أكثر من وضعه خلف الآلة.
علاوة على ذلك ، إذا أعطت الآلة نوعًا من تقييم الثقة الذي لم تستخرجه - على سبيل المثال ، قد تكون بعض المستندات متسخة - والجهاز ليس متأكدًا من ذلك ، ولكنه يمكن أن يشير إلى المدقق أنه غير متأكد تمامًا من هذه النتيجة. : "الرجاء التحقق مرة أخرى." ويقوم الشخص بالتحقق من المعلومات الفردية بحيث تكون ذات جودة عالية. هذه ليست عملية روتينية: إنه يتحقق فقط من لحظات مهمة وصعبة حقًا ، وعيناه غير واضحة.
إذا كان يمكن استخراج المعلومات من المستندات ، فيمكن مقارنة هذه المعلومات.
هذا مهم في حالتين. أولاً ، لمقارنة الإصدارات المختلفة من وثيقة واحدة ، على سبيل المثال ، عقد ثابت منذ فترة طويلة ، يتم إجراء تعديلات عليه باستمرار من كلا الجانبين. ثانياً ، هذه مقارنة بين المستندات من أنواع مختلفة ، على سبيل المثال ، إذا كان هناك اتفاق يشير إلى ما يجب أن يأتي من شريكنا ، من ناحية أخرى ، هناك فواتير وتقارير مختلفة وتقديرات وما إلى ذلك. نحتاج إلى ربطهم وفهم أن كل شيء في محله ، وإن لم يكن بالترتيب ، فهذا يشير بطريقة أو بأخرى إلى المسؤولين.
التطور الحالي للتكنولوجيا في رؤية الكمبيوتر ، ومعالجة المستندات المهيكلة وغير المهيكلة عالية للغاية حتى الآن وفي السنوات المقبلة سيكون هناك تحول رقمي للعمليات الروتينية في الشركات ، لأنها أرخص وأسرع وغالبًا ما تكون أفضل.
علاوة على ذلك ، فإن كل هذه الأساليب لا تهدف بأي حال من الأحوال إلى استبدال الناس. بدلاً من ذلك ، أحب مثال المقارنة مع أداة Excel ، حيث يمكنك القيام بالكثير ولا تهدف هذه الأداة إلى استبدال المحللين أو المديرين أو أي شخص آخر. وهي مصممة لتوسيع القدرات البشرية وتبسيط حل المهام بالنسبة له.
وبالتالي ، تم تصميم الحلول المتعلقة بالذكاء الاصطناعي أيضًا لتقليل عدد العمليات الروتينية المتكررة التي غالباً ما يرتكب فيها الشخص أخطاء أكثر من الجهاز من أجل تفريغ موارد الشركة وتوجيهها إلى حل مهام أكثر إبداعًا وفكريًا. ويبدو أننا نتحرك هناك بكامل قوتها. شكرا لك