
يحتوي متجر Ozon على الإنترنت على كل شيء تقريبًا: الثلاجات ، أغذية الأطفال ، أجهزة الكمبيوتر المحمولة مقابل 100،000 ، إلخ. هذا يعني أن كل هذا موجود أيضًا في مستودعات الشركة - وكلما طالت مدة وجود البضائع ، زادت تكلفة الشركة. لمعرفة مقدار الطلب وما الذي يرغب الناس في طلبه ، وسيحتاج الأوزون إلى الشراء ، استخدمنا التعلم الآلي.
توقعات المبيعات: التحديات
قبل الخوض في بيان المشكلة ، نبدأ بمثال. هذا هو جدول مبيعات الأوزون الحقيقي لفترة من الوقت. السؤال: أين سوف يذهب بعد ذلك؟
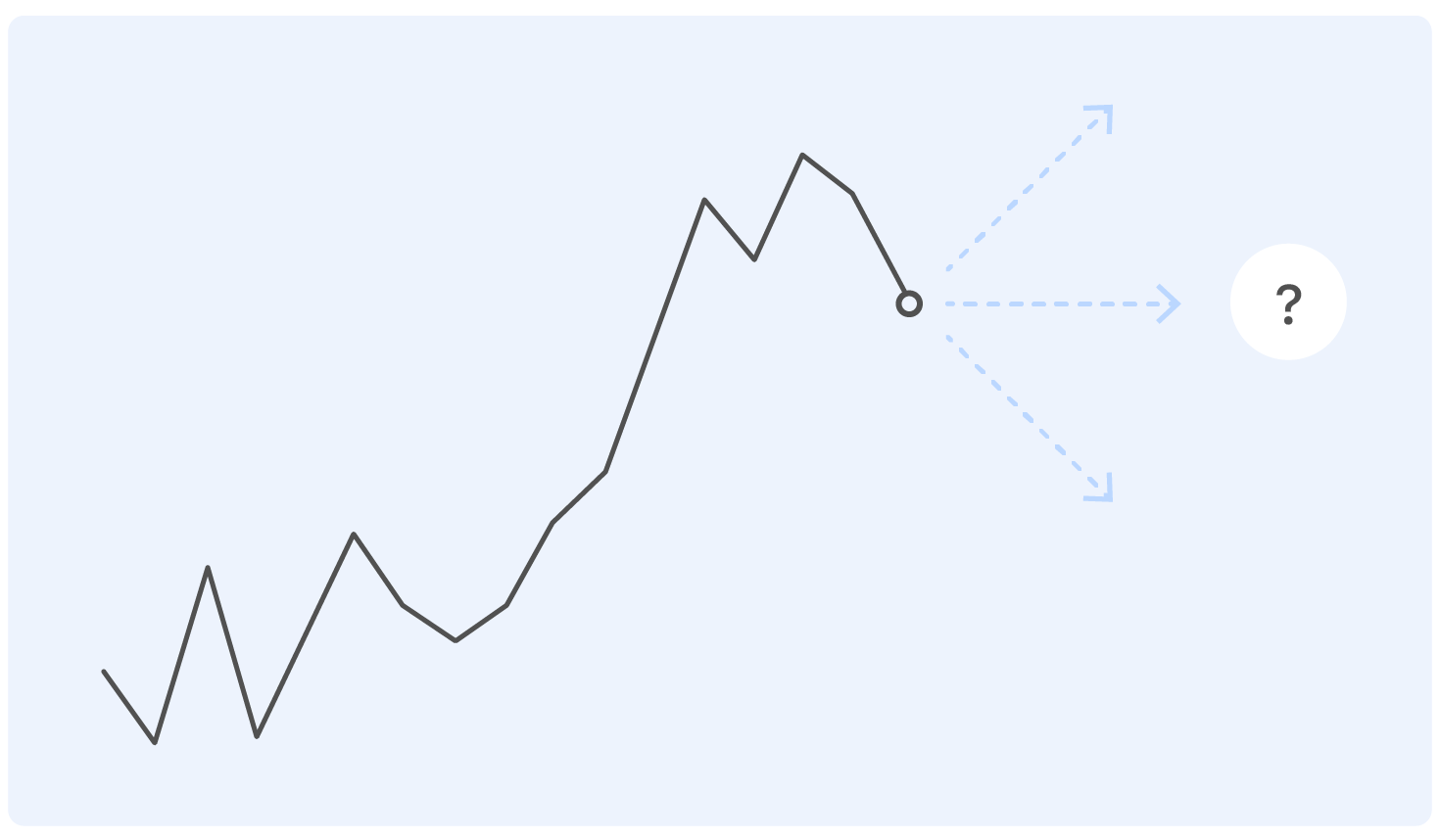
أي شخص لديه تعليم تقني تقريبًا لمثل هذه المشكلة سيكون لديه أسئلة: أين المحاور؟ وأي نوع من المنتجات؟ وفي أي وحدات؟ من المعهد الذي تخرجت منه؟ - والكثير غيرها غير المدرجة في هذه المقالة لأسباب أخلاقية.
في الواقع ، لا أحد يستطيع الإجابة بشكل صحيح على السؤال في مثل هذا البيان ، وإذا كان شخص ما يمكن ، فمن المرجح أنه سوف يكون مخطئا.
أضف بعض مزيد من المعلومات إلى هذا المخطط: الفؤوس وتغيرات الأسعار على موقع Ozon (الأزرق) وموقع المنافس (البرتقالي).
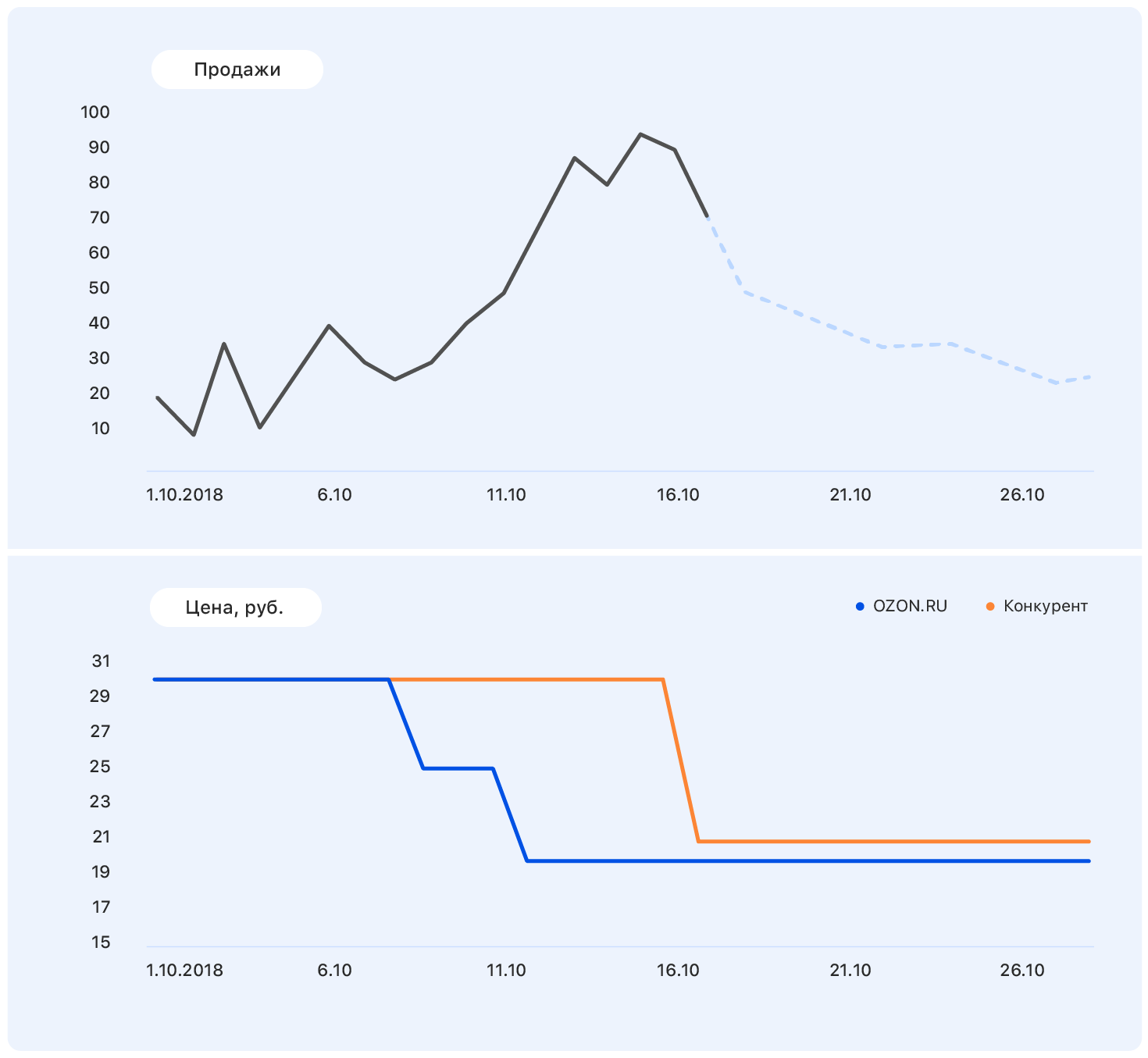
انخفض سعرنا عند نقطة ما ، لكن المنافسة بقيت على حالها - وارتفعت مبيعات الأوزون. نحن نعرف خطط التسعير: سيظل سعرنا عند نفس المستوى ، لكن المنافس ، بعد Ozon ، خفض السعر إلى سعرنا تقريبًا.
هذه البيانات كافية لإجراء افتراض ذي معنى - على سبيل المثال ، أن المبيعات ستعود إلى المستوى السابق. وإذا نظرت إلى الرسم البياني ، اتضح أنه سيكون كذلك.
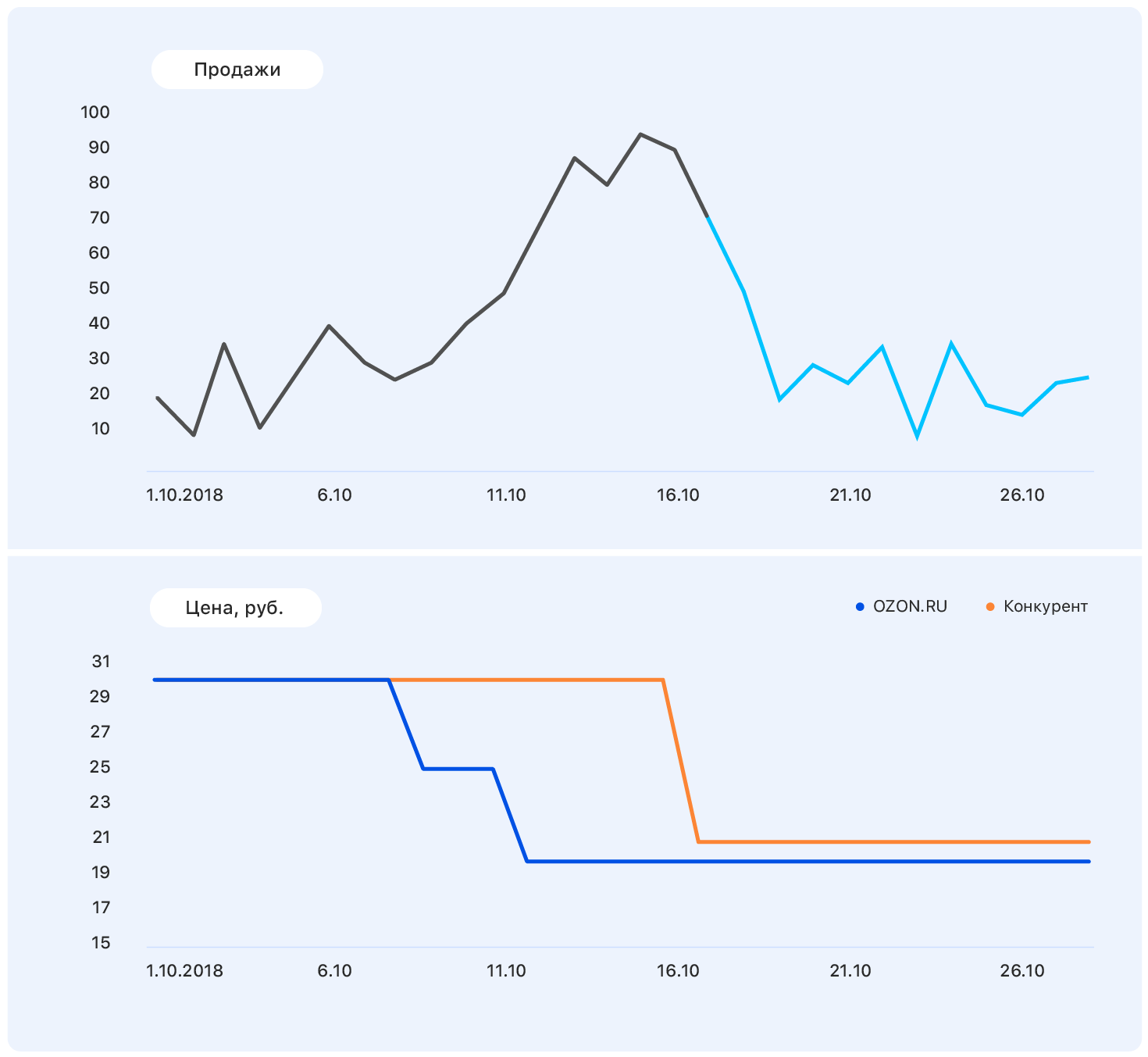
المشكلة هي في الواقع ، أن الطلب على هذا المنتج لا يتأثر كثيرًا بالسعر ، وكان نمو المبيعات ناتجًا ، في جملة أمور ، عن غياب معظم المنافسين لهذا المنتج في متجرنا. لا تزال هناك العديد من العوامل التي لم نأخذها في الاعتبار: هل تم الإعلان عن البضائع على التلفزيون؟ أو ربما انها حلوى ، وقريبا 8 مارس؟
شيء واحد واضح: وضع توقعات "على الركبة" لن ينجح. لقد اتبعنا المسار القياسي
لأشعل النار والعكازات لبناء أي خوارزمية ML. وهذا ما كان عليه الحال.
اختيار متري
اختيار المقياس هو المكان الذي تبدأ منه إذا كان شخص آخر على الأقل سيستخدم توقعاتك.
فكر في مثال: لدينا ثلاثة خيارات للتنبؤ. أيهما أفضل؟
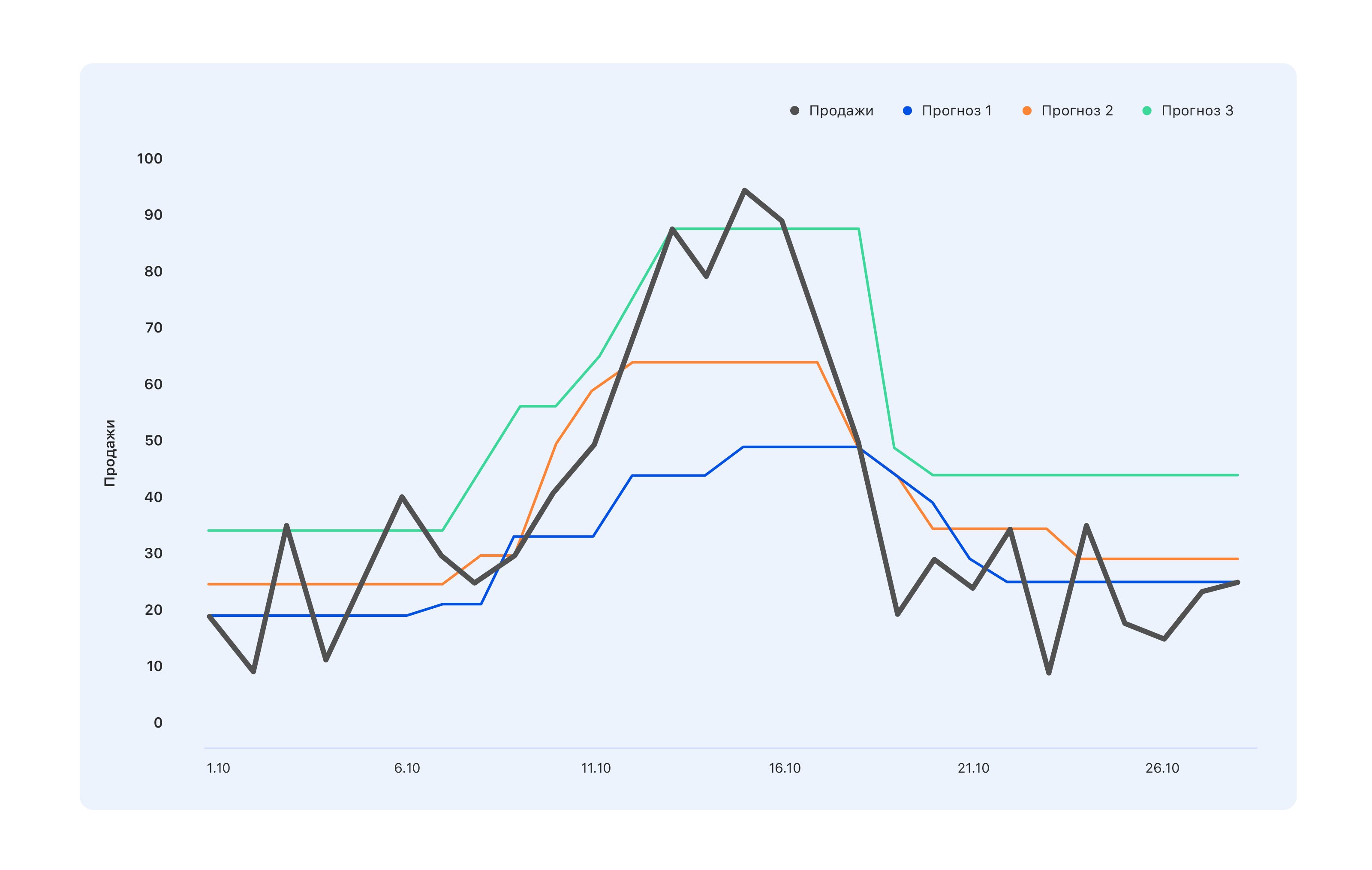
من وجهة نظر المتخصصين في المستودع ، نحتاج إلى توقعات زرقاء - سنشتري أقل قليلاً ، ولنفتقد القمة في منتصف شهر أكتوبر ، ولكن لن يبقى شيء في المستودع. الخبراء الذين يرتبط مؤشر KPI بالمبيعات لديهم رأي معاكس: حتى توقعات الفيروز ليست صحيحة تمامًا ، ولم تنعكس جميع القفزات في الطلب - اذهب تعديلها. ولكن من وجهة نظر شخص ما ، من الخارج ، هناك شيء أفضل يتم ترتيبه بشكل عام - بحيث يشعر الجميع بالرضا أو العكس.
لذلك ، قبل إجراء التنبؤ ، من الضروري تحديد من سيستخدمه ولماذا. بمعنى ، اختيار مقياس وفهم ما يمكن توقعه من توقعات مبنية على مثل هذا المقياس. وانتظر ذلك تماما.
لقد اخترنا MAE - متوسط الخطأ المطلق. هذا المقياس مناسب لعينة التدريب غير المتوازنة للغاية. نظرًا لأن التشكيلة واسعة جدًا (1.5 مليون عنصر) ، يتم بيع كل منتج على حدة في منطقة معينة بكميات صغيرة. وإذا قمنا في المجموع ببيع مئات الفساتين الخضراء ، فسيتم بيع فستان أخضر خاص مع القطط بسعر 2-3 في اليوم. نتيجة لذلك ، تنتقل العينة نحو القيم الصغيرة. من ناحية أخرى ، هناك iPhone ، المغازل ، كتاب جديد من تأليف Olga Buzova (نكتة) ، إلخ. - ويتم بيعها في أي مدينة بكميات ضخمة. تسمح لك MAE بعدم الحصول على غرامات ضخمة على أجهزة iPhone الشرطية وتعمل بشكل جيد على معظم السلع.
الخطوات الأولى
لقد بدأنا من خلال إنشاء أكثر التوقعات غباء التي يمكن أن تكون: سيتم بيع رقم عشوائي من 0 إلى 1000 خلال الأسبوع المقبل والحصول على مقياس MAE = 496. ربما ، يمكن أن يكون الأمر أسوأ ، ولكن هذا سيء جدًا بالفعل. إذن ، حصلنا على مبدأ توجيهي: إذا حصلنا على مثل هذه القيمة المترية ، فمن الواضح أننا نقوم بشيء خاطئ.
بعد ذلك ، بدأنا في لعب أشخاص يعرفون كيفية عمل التنبؤ دون تعلم آلي ، وحاولنا التنبؤ بمبيعات البضائع خلال الأسبوع القادم مساوية لمتوسط المبيعات لجميع الأسابيع الماضية ، وحصلنا على مقياس MAE = 1.45 - وهو أفضل بكثير.
واستمرارًا للسبب ، قررنا أن مبيعات الأسبوع الماضي لن تكون أكثر صلة بتنبؤ المبيعات في الأسبوع المقبل. لمثل هذه التوقعات ، كانت MAE 1.26. في الجولة التالية من الفكر النذير ، قررنا أن نأخذ في الاعتبار كلا من العوامل ونتنبأ بالمبيعات للأسبوع المقبل كمجموع 50 ٪ من متوسط المبيعات و 50 ٪ من المبيعات خلال الأسبوع الماضي - حصلنا على MAE = 1.23.
لكن بدا لنا بسيطًا للغاية ، وقررنا تعقيد الأمور. لقد جمعنا عينة تدريب صغيرة كانت فيها العلامات الماضية ومتوسط المبيعات ، والأهداف كانت المبيعات خلال الأسبوع المقبل ، وقمنا بالتدريب على ذلك انحدار خطي بسيط. حصلنا على أوزان 0.46 و 0.55 للمتوسط والأسابيع الماضية ، و MAE في عينة الاختبار تساوي 1.2.
الخلاصة: بياناتنا لديها إمكانات تنبؤية.
ميزة الهندسة
بعد أن قررنا أن بناء توقعات على سببين ليس بمستوىنا ، جلسنا لإنشاء ميزات معقدة جديدة. هذه هي معلومات حول المبيعات السابقة - منذ 1 ، 2 ، 3 ، 4 أسابيع ، أسبوع منذ عام بالضبط ، إلخ. وجهات النظر خلال الأسابيع الماضية ، والإضافات إلى السلة ، وتحويل وجهات النظر والإضافات إلى سلة في أوامر - وهذا كله لفترات مختلفة.
نحتاج إلى تقديم نموذج للمعرفة حول كيفية بيع المنتج ككل ، وكيف تغيرت ديناميكيات مبيعاته مؤخرًا ، وكيف يتطور الاهتمام به ، وكيف تعتمد مبيعاته على السعر وعوامل أخرى يمكن ، في رأينا ، أن تكون مفيدة.
عندما نفدت أفكارنا ، ذهبنا إلى خبراء قسم المبيعات. هناك ، على سبيل المثال ، علمنا أن العام المقبل هو عام الخنازير ، وبالتالي ، فإن البضائع على الأقل التي تشبه الخنازير عن بعد سوف تحظى بشعبية كبيرة. أو ، على سبيل المثال ، "عدم تجميد" شعبنا لا يشتريه مقدمًا ، ولكن بالضبط في يوم الصقيع الأول - لذا يرجى أخذ توقعات الطقس في الاعتبار. بشكل عام ، كان الجميع راضيا. نحن - لأننا تلقينا مجموعة من الأفكار الجديدة التي لم يكن من الممكن أن نفكر في أنفسنا ، ورجال الأعمال - أنه سيكون من الممكن قريبًا القيام بشيء أكثر إثارة للاهتمام من توقعات المبيعات.
لكنه لا يزال بسيطًا جدًا - وقد أضفنا أعراضًا مشتركة:
- التحويل من طرق العرض إلى المبيعات - كيف كانت ، وكيف تغيرت ؛
- نسبة المبيعات خلال 4 أسابيع إلى المبيعات خلال الأسبوع الماضي (إذا كان هذا الرقم مختلفًا تمامًا عن 4 ، في الوقت الحالي يخضع الطلب على هذا المنتج إلى "الاضطراب") ؛
- نسبة مبيعات المنتج إلى المبيعات في الفئة بأكملها - إذا كان هذا الرقم قريبًا من واحد ، فسيكون المنتج "محتكرًا".
في هذه المرحلة ، تحتاج إلى التوصل إلى أكبر قدر ممكن - التخلص من العلامات غير المفيدة في مرحلة التدريب.
نتيجة لذلك ، حصلنا على 170 علامة. إذا نظرنا إلى المستقبل ، فإن أكبر ميزة أهمية
- مبيعات للأسبوع الماضي (لمدة سنتين وثلاثة وأربعة).
- توفر المنتج في الأسبوع الماضي هو النسبة المئوية للوقت الذي كان فيه المنتج موجودًا على الموقع.
- المعامل الزاوي لجدول مبيعات البضائع لآخر 7 أيام.
- نسبة السعر الماضي إلى المستقبل - مع خصم كبير ، ابدأ في شراء السلع بشكل أكثر نشاطًا.
- عدد المنافسين المباشرين في موقعنا. على سبيل المثال ، إذا كان هذا القلم هو الوحيد في فئته ، فستكون المبيعات ثابتة تمامًا.
- أبعاد المنتج - اتضح أن الطول والعرض يؤثران بشكل كبير على إمكانية التنبؤ بالمبيعات. لسبب ما ، للأجسام الطويلة والضيقة - المظلات أو قضبان الصيد ، على سبيل المثال - يكون الجدول أكثر تقلبًا. لا نعرف بعد كيف نفسر هذا.
- رقم اليوم من العام - يُظهر ما إذا كانت السنة الجديدة قادمة ، 8 مارس ، بداية زيادة موسمية في المبيعات ، إلخ.
أخذ العينات
عينة التدريب هي الألم. جمعناها لمدة 4 أسابيع ، ذهب اثنان منها فقط إلى أمناء بيانات مختلفين وطلبنا إلقاء نظرة على ما لديهم. يحدث هذا في كل مرة تحتاج فيها إلى بيانات لفترة طويلة. حتى في نظام مثالي لجمع البيانات ، لفترة طويلة ، سيحدث شيء بروح "اعتدنا أن نفكر في هذا الأمر ، لكن بعد ذلك بدأنا في التفكير بشكل مختلف وكتابة البيانات في نفس العمود". أو قبل عام أو عامين ، تعطل الخادم ، لكن لم يكتب أحد بالضبط متى - ولم تعد الأصفار تعني عدم وجود مبيعات.
نتيجة لذلك ، كانت لدينا معلومات حول ما قام به الأشخاص على الموقع وماذا وبكميات تم إضافتهم إلى المفضلة وسلة ، وشراءها. جمعنا عينة من حوالي 15 مليون عينة من 170 ميزة لكل منها ، وكان الهدف هو عدد المبيعات للأسبوع المقبل.
لقد كتبنا ألفي سطر من التعليمات البرمجية على Spark. كان يعمل ببطء ، ولكن سمح للمضغ على كميات هائلة من البيانات. يبدو أن حساب ميل الخط المستقيم بسيط. وللقيام بذلك مرات 10kk عندما يتم سحب المبيعات من عدة قواعد - المهمة ليست لضعاف القلوب.
لمدة أسبوع آخر ، كنا نشارك في تنظيف البيانات بحيث لا يصرف النموذج عن طريق الانبعاثات وميزات أخذ العينات المحلية ، ولكن استخراج فقط التبعيات الحقيقية الكامنة في مبيعات الأوزون. هنا 3 سيغما وطرق أكثر الماكرة للبحث عن الشذوذ سوف تذهب. أصعب الحالات هي استعادة المبيعات خلال فترات نقص البضائع الموجودة في المخازن. إن أبسط الحلول هو التخلص من الأسابيع التي خرج فيها المنتج خلال الأسبوع "المستهدف".
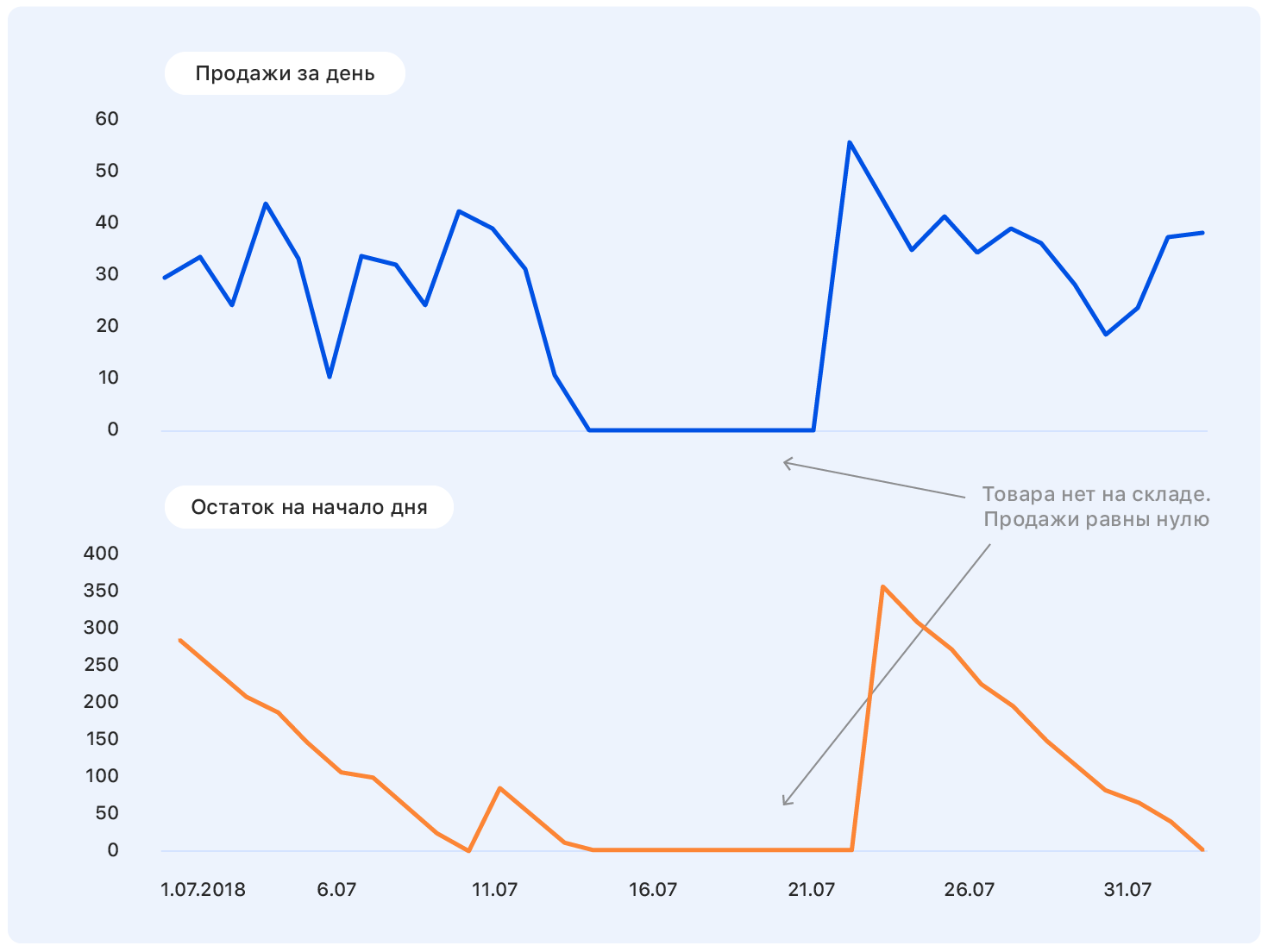
ونتيجة لذلك ، من بين 15 مليون عينة ، بقيت 10 ملايين عينة ، من المهم هنا عدم التملق وعدم فقد اكتمال العينة (في الواقع ، يعد نقص البضائع في المستودع سمة غير مباشرة لأهميتها بالنسبة للشركة ؛ وإزالة هذه البضائع من العينة ليست هي نفس طريقة التخلص من العينات العشوائية )
وقت ML
على عينة نظيفة وبدأت في تدريب النماذج. بطبيعة الحال ، بدأنا مع الانحدار الخطي وحصلنا على MAE = 1.15. يبدو أن هذه زيادة طفيفة للغاية ، ولكن عندما يكون لديك عينة من 10 ملايين يكون فيها متوسط القيم من 5 إلى 10 ، فإن التغيير الطفيف في القيمة المترية يعطي زيادة لا تضاهى في الجودة المرئية للتنبؤ. وبما أنه سيتعين عليك في نهاية المطاف تقديم الحل للعملاء من رجال الأعمال ، فإن رفع مستوى فرحتهم يعد عاملاً مهماً.
التالي كان sklearn.ensemble.RandomForestRegressor ، والذي أظهر بعد MAE = 1.10 مجموعة مختارة من المقاييس الفائقة. بعد ذلك ، حاولنا تطبيق XGBoost (حيث بدونه) - كل شيء سيكون جيدًا و MAE = 1.03 - فقط وقت طويل جدًا. لسوء الحظ ، لم نتمكن من الوصول إلى GPU لتدريب XGBoost ، وتم تدريب نموذج واحد على المعالجات لفترة طويلة جدًا. حاولنا العثور على شيء بشكل أسرع ، واستقرنا على LightGBM - لقد تدرب مرتين أسرع وأظهر MAE أقل قليلاً - 1.01.
قسمنا جميع المنتجات إلى 13 فئة ، كما هو الحال في الكتالوج على الموقع: الجداول وأجهزة الكمبيوتر المحمولة والزجاجات ، ولكل فئة من الفئات قمنا بتدريب نماذج مع أعماق مختلفة للتنبؤ - من 5 إلى 16 يومًا.
استغرق التدريب حوالي خمسة أيام ، ولهذا قمنا بتجميع مجموعات حوسبة ضخمة. لقد طورنا خط أنابيب من هذا القبيل: البحث العشوائي يعمل لفترة طويلة ، ويعطي أفضل 10 مجموعات من المعلمات الفائقة ، ثم يعمل العالم معهم يدويًا - يبني مقاييس جودة إضافية (حسبنا MAE لنطاقات مختلفة من الأهداف) ، ونبني منحنيات التعلم (على سبيل المثال ، قمنا بإخراج جزء من التدريب العينات وتدريبها مرة أخرى ، والتحقق لمعرفة ما إذا كانت البيانات الجديدة تقلل من فقدان عينة الاختبار) والرسوم البيانية الأخرى.
مثال لتحليل مفصل لأحد مجموعات المقاييس الفوقية:
متري الجودة التفصيليةمجموعة القطار:
| مجموعة الاختبار:
|
| للهدف = 0 ، MAE = 0.142222484602 | لـ 0 MAE = 0.141900737761 |
| للهدف> 0 ، MAPE = 45.168530676 | لـ> 0 MAPE = 45.5771812826 |
| الأخطاء أكبر من 0 - 67.931341691٪ | الأخطاء أكبر من 0 - 51.6405939896٪ |
| الأخطاء أكبر من 1 - 19.0346986379٪ | الأخطاء أكبر من 1 - 12.1977096603٪ |
| الأخطاء أكثر من 2 - 8.94313926245٪ | الأخطاء أكثر من 2 - 5.16977226441٪ |
| الأخطاء أكثر من 3 - 5.42406856507٪ | الأخطاء أكثر من 3 - 3.12760834969٪ |
الأخطاء أكثر من 4 - 3.67938161595٪
| الأخطاء أكثر من 4 - 2.10263125679٪ |
الأخطاء أكثر من 5 - 2.67322988948 ٪
| الأخطاء أكثر من 5 - 1.56473158807٪
|
الأخطاء أكثر من 6 - 2.0618556701٪
| الأخطاء أكثر من 6 - 1.19599209102٪
|
| الأخطاء أكثر من 7 - 1.65887701209٪ | الأخطاء أكبر من 7 - 0.949300173983٪
|
الأخطاء أكثر من 8 - 1.36821095777٪
| الأخطاء أكثر من 8 - 0.78310772461٪ |
| الأخطاء أكثر من 9 - 1.15368611519٪ | الأخطاء أكبر من 9 - 0.659205318158٪
|
| الأخطاء أكثر من 10 - 0.99199395014٪ | الأخطاء أكثر من 10 - 0.554593106723٪ |
| الأخطاء أكثر من 11 - 0.863969667827٪ | الأخطاء أكثر من 11 - 0.490045146476٪
|
الأخطاء أكثر من 12 - 0.764347266082٪
| الأخطاء أكثر من 12 - 0.428835873827٪
|
| الأخطاء أكثر من 13 - 0.68086818247٪ | الأخطاء أكثر من 13 - 0.386545830907٪
|
| الأخطاء أكثر من 14 - 0.613446089087٪ | الأخطاء أكثر من 14 - 0.343884822697٪
|
الأخطاء أكثر من 15 - 0.556297016335٪
| الأخطاء أكثر من 15 - 0.316433391328٪
|
للهدف = 0 ، MAE = 0.142222484602
| للهدف = 0 ، MAE = 0.141900737761
|
للهدف = 1 ، MAE = 0.63978556493
| للهدف = 1 ، MAE = 0.660823509405 |
| للهدف = 2 ، MAE = 1.01528075312 | للهدف = 2 ، MAE = 1.01098070566 |
| للهدف = 3 ، MAE = 1.43762342295 | للهدف = 3 ، MAE = 1.44836233499 |
للهدف = 4 ، MAE = 1.82790678437
| للهدف = 4 ، MAE = 1.86539223382
|
للهدف = 5 ، MAE = 2.15369976552
| للهدف = 5 ، MAE = 2.16017884573 |
للهدف = 6 ، MAE = 2.51629758129
| للهدف = 6 ، MAE = 2.51987403661
|
للهدف = 7 ، MAE = 2.80225497415
| للهدف = 7 ، MAE = 2.97580015564
|
للهدف = 8 ، MAE = 3.09405048248
| للهدف = 8 ، MAE = 3.21914648525
|
للهدف = 9 ، MAE = 3.39256765159
| للهدف = 9 ، MAE = 3.54572928241
|
| للهدف = 10 ، MAE = 3.6640339953 | للهدف = 10 ، MAE = 3.84409605282
|
للهدف = 11 ، MAE = 4.02797747118
| للهدف = 11 ، MAE = 4.21828735273
|
للهدف = 12 ، MAE = 4.17163467899
| للهدف = 12 ، MAE = 3.92536509115
|
للهدف = 14 ، MAE = 4.78590364522
| للهدف = 14 ، MAE = 5.11290428675 |
للهدف = 15 ، MAE = 4.89409916994
| للهدف = 15 ، MAE = 5.20892023117
|
خسارة القطار = 0.535842111392
اختبار الخسارة = 0.895529959873
الرسم البياني التنبؤ (الهدف) لمجموعة التدريب الرسم البياني التنبؤ (الهدف) لعينة الاختبار فرز خطأ تصاعدي في عينة الاختبار إذا لم يكن هناك تطابق ، فقم بالبحث العشوائي مرة أخرى. هذه هي الطريقة التي قمنا بتدريب النموذج لمدة 5 أو 5 أيام بالسرعة الصناعية. كنا في الخدمة ، شخص ما في الليل ، استيقظ شخص ما في الصباح ، ونظر في أفضل 10 معلمات ، أعدنا تشغيل أو أنقذنا النموذج وذهبنا إلى الفراش. في هذا الوضع ، عملنا لمدة أسبوع ودربنا 130 نموذجًا - 13 نوعًا من البضائع و 10 أعماق من التوقعات ، وكان لكل منها 170 ميزة. متوسط MAE لسلسلة السلاسل الزمنية ذات 5 أضعاف حصلنا على 1.
قد يبدو أن هذا ليس رائعًا - وهذا هو الحال ، ما لم يكن لديك جزء كبير في اختيار الوحدات. كما يظهر تحليل للنتائج ، من المتوقع أن الوحدات أسوأ من أي شيء آخر - حقيقة أن المنتج الذي تم شراؤه مرة واحدة في الأسبوع لا يوضح أي شيء حول ما إذا كان هناك طلب عليه. بمجرد بيع أي شيء - هناك شخص سيشتري تمثالًا من الخزف على شكل طبيب أسنان ، وهذا لا يقول شيئًا عن المبيعات المستقبلية أو عن المبيعات السابقة. بشكل عام ، لم نكن مستاء للغاية من هذا.
نصائح وحيل
ما الخطأ الذي حدث وكيف يمكن تجنب ذلك؟
المشكلة الأولى هي اختيار المعلمات. بدأنا باستخدام RandomizedSearchCV - أداة معروفة من sklearn لفرز المعلمات الفوقية. هذا هو المكان الذي انتظرنا فيه المفاجأة الأولى.
مثل هذاfrom sklearn.model_selection import ParameterSampler
from sklearn.model_selection import RandomizedSearchCV
estimator = lightgbm.LGBMRegressor(application='regression_l1', is_training_metric = True, objective = 'regression_l1', num_threads=72)
param_grid = {'boosting_type': boosting_type, 'num_leaves': num_leaves, 'max_depth': max_depth, 'learning_rate':learning_rate, 'n_estimators': n_estimators, 'subsample_for_bin': subsample_for_bin, 'min_child_samples': min_child_samples, 'colsample_bytree': colsample_bytree, 'reg_alpha': reg_alpha, 'max_bin': max_bin}
rscv = RandomizedSearchCV(estimator, param_grid, refit=False, n_iter=100, scoring='neg_mean_absolute_error', n_jobs=1, cv=10, verbose=3, pre_dispatch='1*n_jobs', error_score=-1, return_train_score='warn')
rscv .fit(X_train.values, y_train['target'].values)
print('Best parameters found by grid search are:', rscv.best_params_)
تتوقف العملية الحسابية ببساطة (وهو أمر مهم ، لا تسقط ، ولكنها تستمر في العمل ، ولكن على عدد أقل من النوى وفي بعض الأحيان يتوقف فقط).
اضطررت لموازنة العملية بسبب RandomizedSearchCVestimator = lightgbm.LGBMRegressor(application='regression_l1', is_training_metric = True, objective = 'regression_l1', num_threads=1)
rscv = RandomizedSearchCV(estimator, param_grid, refit=False, n_iter=100, scoring='neg_mean_absolute_error', n_jobs=72, cv=10, verbose=3, pre_dispatch='1*n_jobs', error_score=-1, return_train_score='warn')
rscv .fit(X_train.values, y_train['target'].values)
print('Best parameters found by grid search are:', rscv.best_params_)
لكن RandomizedSearchCV يمسك مجموعة البيانات بالكامل تقريبًا لكل "وظيفة". وفقًا لذلك ، من الضروري زيادة حجم ذاكرة الوصول العشوائي بشكل كبير ، وربما التضحية بعدد النوى.
من سيخبرنا بعد ذلك عن أشياء رائعة مثل hyperopt! منذ علمنا ، نستخدمها فقط.
هناك خدعة أخرى تتبادر إلى أذهاننا بالقرب من نهاية المشروع وهي اختيار النماذج التي تحتوي على معلمة colsample_bytree (هذه هي المعلمة LightGBM ، التي توضح النسبة المئوية من الميزات التي يجب تقديمها لكل ليرنر) في المنطقة من 0.2-0.3 ، لأنه عندما تكون السيارة إنه يعمل في الإنتاج ، وقد لا يكون هناك أي جداول ، وقد لا يتم حساب الميزات الفردية بشكل صحيح. يسمح لك هذا التنظيم بالتأكد من أن هذه الميزات التي لم يتم حسابها تؤثر على الأقل على جميع اللنرنات داخل النموذج.
من الناحية التجريبية ، توصلنا إلى استنتاج مفاده أننا بحاجة إلى بذل المزيد من المقدرين وتطور عملية التنظيم بشكل أصعب. هذه ليست قاعدة عمل مع LightGBM ، ولكن مثل هذا المخطط يعمل من أجلنا.
حسنا ، وبطبيعة الحال ، سبارك. على سبيل المثال ، هناك خطأ تعرفه Spark نفسها: إذا أخذت عدة أعمدة من جدول وقمت بإنشاء عمود جديد ، ثم أخذت أخرى من نفس الجدول وقمت بإنشاء جدول جديد ، ثم توليف في الجداول التي تتلقاها ، فسوف ينقطع كل شيء ، على الرغم من أنه يجب ألا يحدث. يمكنك حفظ فقط من خلال التخلص من جميع الحسابات البطيئة. حتى لقد كتبنا وظيفة خاصة - bumb_df ، فإنها تحول إطار البيانات إلى RDD مرة أخرى إلى إطار بيانات. وهذا هو ، فإنه يعيد تعيين جميع الحسابات البطيئة. هذا يمكن أن تحمي نفسك من معظم مشاكل سبارك.
bumb_dfdef bump_df(df):
# to avoid problem: AnalysisException: resolved attribute(s)
df_rdd = df.rdd
if df_rdd.isEmpty():
df = df_rdd.toDF(schema=df.schema)
return df
else:
return df_rdd.toDF(schema=df.schema)
التوقعات جاهزة: كم سنطلب؟
إن التنبؤ بالمبيعات مهمة رياضية بحتة ، وإذا كان التوزيع العادي لخطأ الصفر يعني انتصارًا لعالم الرياضيات ، ثم بالنسبة للتجار الذين تم حساب كل روبل ، فهذا غير مقبول.
إذا لم يكن أي فون إضافي أو فستانًا واحدًا أنيقًا في المستودع يمثل مشكلة ، بل هو سهم تأمين ، فإن غياب نفس iPhone في المستودع هو خسارة لا تقل عن هامش ، وكحد أقصى من الصور ، ولا يمكن السماح بذلك.
من أجل تعليم الخوارزمية لشراء قدر ما هو مطلوب ، كان علينا حساب تكلفة إعادة شراء وشراء كل منتج وتدريب نموذج بسيط من أجل تقليل الخسائر المحتملة في المال.
يتلقى النموذج توقعات المبيعات عند المدخلات ، ويضيف ضوضاء عشوائية موزعة عليها عادة (نحن نحاكي عيوب الموردين) ، ويتعلم إضافة الكثير بالضبط إلى التنبؤ لتقليل الخسائر في الأموال لكل منتج معين.
وبالتالي ، فإن الطلب عبارة عن مخزون أمان متوقع + ، والذي يضمن تغطية خطأ التنبؤ والعيوب في العالم الخارجي.
كما هو الحال في همز
يحتوي الأوزون على مجموعة الحوسبة الخاصة به ، والتي يتم تشغيل خط أنابيب بها كل ليلة (نستخدم تدفق الهواء) من أكثر من 15 وظيفة. يبدو مثل هذا:

كل ليلة ، يتم إطلاق الخوارزمية ، حيث تقوم بسحب حوالي 20 غيغابايت من البيانات من مجموعة متنوعة من المصادر إلى hdfs المحلية ، وتختار المورد لكل منتج ، وتجمع الميزات لكل منتج ، وتوقع المبيعات وتصدر الطلبات بناءً على جدول التسليم. بحلول الساعة 6-7 صباحًا ، نعطي المائدة المسؤولين عن العمل مع طاولات جاهزة للموردين تتنقل بنقرة زر واحدة إلى الموردين.
ليس توقعات واحدة
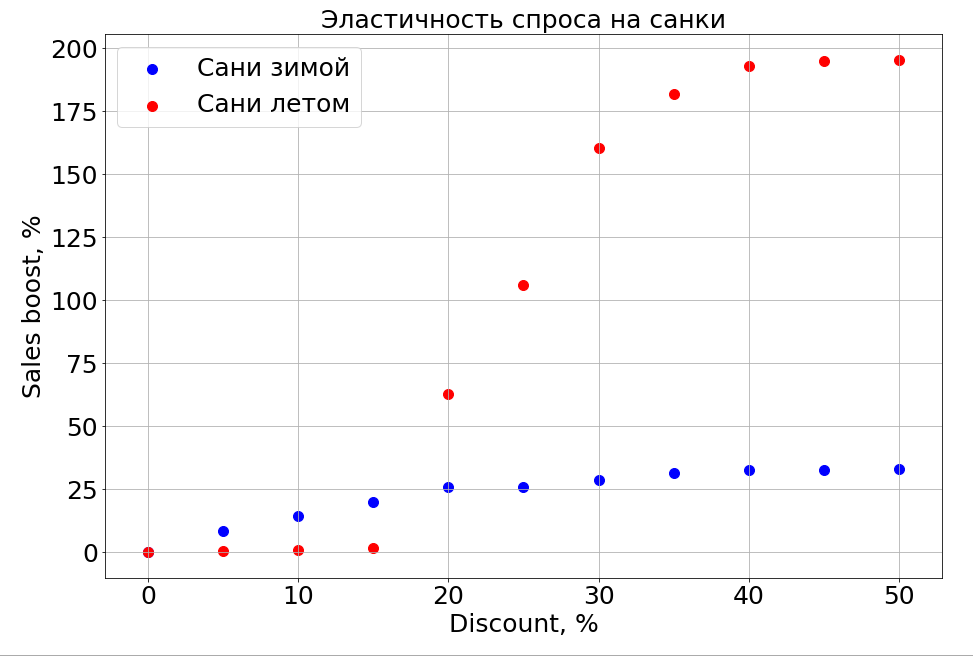
يعرف النموذج المدرب اعتماد الاعتماد على أي ميزة ، ونتيجة لذلك ، إذا قمت بتجميد علامات N-1 وبدأت في تغييرها ، فيمكنك ملاحظة كيفية تأثيرها على التنبؤ. بالطبع ، الشيء الأكثر إثارة للاهتمام حول هذا هو كيف تعتمد المبيعات على السعر.
من المهم أن نلاحظ أن الطلب لا يعتمد فقط على السعر. على سبيل المثال ، إذا قمت بإجراء تخفيضات صغيرة على الزلاجات في الصيف ، فلا يزال لا يساعدهم على البيع. نحن نحقق خصمًا أكبر ، ويبدو أن الأشخاص "يستعدون للتزلج في الصيف". ولكن حتى مستوى معين من الخصومات ، لا يزال يتعذر علينا الوصول إلى جزء الدماغ المسؤول عن التخطيط. في فصل الشتاء ، يعمل كما هو الحال مع أي منتج - يمكنك إجراء خصم ويبيع بشكل أسرع.
خطط
الآن نحن ندرس بنشاط تجميع سلاسل زمنية من أجل توزيع البضائع بين المجموعات على أساس طبيعة المنحنى الذي يصف مبيعاتها. على سبيل المثال ، موسمي ، يحظى بشعبية تقليدية في الصيف أو ، على العكس ، في فصل الشتاء. عندما نتعلم كيفية فصل المنتجات مع تاريخ مبيعات طويل ، فإننا نخطط لتسليط الضوء على الميزات المستندة إلى العنصر والتي سوف تخبرك بنمط المبيعات لمنتج جديد ظهر للتو - هذه هي مهمتنا الرئيسية الآن.
بالتأكيد سوف تكون الشبكات العصبية والنماذج البارامترية للسلاسل الزمنية وكل هذا في المجموعة.
وبصفة خاصة ، بفضل نظام التنبؤ الجديد ، تحول Ozon من شراء البضائع مع المخزونات إلى التسليم الدوري ، عندما نشتري من إمداد إلى آخر ولا نخزن الأرصدة في المخزون.
الآن علينا أن نقرر كيفية تعليم الخوارزمية للتنبؤ بمبيعات المنتجات الجديدة والفئات بأكملها. في العام المقبل ، تخطط الشركة لزيادة مبيعات X10 في فئات و x2.5 في مجالات الوفاء. ونحن بحاجة إلى إخبار النماذج بأن هذه البيانات القديمة ذات صلة ، ولكن لمتجر آخر مختلف. وبينما نفكر في كيفية القيام بذلك.
والثاني بطبيعته شيء غير عقلاني علينا أن نتعلمه للتنبؤ به هو الموضة. كيف يمكن للمرء أن يتوقع أن الدوار سوف تبيع مثل هذا؟ كيف تتنبأ بمبيعات كتب دان براون الجديدة إذا تم بيع أحد كتبه والآخر ليس كذلك؟ بينما نحن نعمل على ذلك.
إذا كنت تعرف كيفية القيام بعمل أفضل ، أو لديك قصص حول استخدام التعلم الآلي في المعركة في التعليقات ، سنناقشها.