يستخدم GitHub MySQL كمستودع بيانات أساسي لكل ما لا يتعلق ب git ، لذلك فإن توفر MySQL هو مفتاح التشغيل العادي لـ GitHub. يتطلب الموقع نفسه وواجهة برمجة تطبيقات GitHub ونظام المصادقة والعديد من الميزات الأخرى الوصول إلى قواعد البيانات. نستخدم العديد من مجموعات MySQL للتعامل مع مختلف الخدمات والمهام. يتم تكوينها وفقًا للمخطط الكلاسيكي مع توفر عقدة رئيسية واحدة للتسجيل والنسخ المتماثلة الخاصة به. النسخ المتماثلة (عقد نظام المجموعة الأخرى) بشكل غير متزامن إنتاج التغييرات إلى العقدة الرئيسية وتوفير الوصول للقراءة.
توافر المواقع المضيفة أمر بالغ الأهمية. بدون العقدة الرئيسية ، لا تدعم المجموعة التسجيل ، مما يعني أنه لا يمكنك حفظ التغييرات الضرورية. إصلاح المعاملات ، وتسجيل المشاكل ، وإنشاء مستخدمين جدد ، ومستودعات ، والمراجعات ، وأكثر من ذلك بكثير سيكون ببساطة مستحيلاً.
لدعم التسجيل ، مطلوب العقدة يمكن الوصول إليها المقابلة - العقدة الرئيسية في الكتلة. ومع ذلك ، فإن القدرة على تحديد أو اكتشاف مثل هذه العقدة لا تقل أهمية.
في حالة فشل العقدة الرئيسية الحالية ، من المهم ضمان الظهور الفوري لخادم جديد ليحل محله ، وكذلك لتكون قادرًا على إخطار جميع الخدمات بسرعة بهذا التغيير. يتكون إجمالي وقت التعطل من الوقت المستغرق للكشف عن الفشل والفشل والإبلاغ عن عقدة رئيسية جديدة.

يصف هذا المنشور حلاً لضمان توفر MySQL على GitHub واكتشاف الخدمة الرئيسية ، مما يسمح لنا بإجراء عمليات موثوق بها تغطي العديد من مراكز البيانات ، والحفاظ على قابلية التشغيل عند عدم توفر بعض هذه المراكز ، وضمان الحد الأدنى من الوقت الضائع في حالة حدوث عطل.
ارتفاع توافر الأهداف
الحل الموصوف في هذه المقالة هو إصدار جديد ومحسّن من حلول التوافر العالي السابق (HA) المطبقة على GitHub. مع تقدمنا ، نحتاج إلى تكييف استراتيجية MySQL HA للتغيير. نحن نسعى جاهدين لاتباع أساليب مماثلة في MySQL وغيرها من الخدمات على جيثب.
للعثور على الحل المناسب للتوفر العالي واكتشاف الخدمة ، يجب أولاً الإجابة على بعض الأسئلة المحددة. وهنا قائمة عينة منهم:
- ما هي فترة التوقف القصوى غير الحاسمة بالنسبة لك؟
- ما مدى موثوقية أدوات الكشف عن الأخطاء؟ هل الإيجابيات الخاطئة (معالجة الفشل المبكر) أمر حاسم بالنسبة لك؟
- ما مدى موثوقية نظام الفشل؟ أين يمكن أن يحدث الفشل؟
- ما مدى فعالية الحل في مراكز بيانات متعددة؟ ما مدى فعالية الحل في شبكات الكمون المنخفض والعالي؟
- هل سيستمر الحل في العمل في حالة تعطل مركز البيانات (DPC) الكامل أو عزل الشبكة؟
- ما الآلية (إن وجدت) التي تمنع أو تخفف من عواقب ظهور خادمين رئيسيين في المجموعة التي تسجل بشكل مستقل؟
- هل فقدان البيانات أمر حاسم بالنسبة لك؟ إذا كان الأمر كذلك ، إلى أي مدى؟
من أجل التوضيح ، دعونا أولاً نفكر في الحل السابق ونناقش لماذا قررنا التخلي عنه.
رفض استخدام VIP و DNS للاكتشاف
كجزء من الحل السابق ، استخدمنا:
- أوركسترا للكشف عن الأعطال والفشل ؛
- VIP و DNS لاكتشاف المضيف.
في هذه الحالة ، اكتشف العملاء عقدة تسجيل باسمها ، على سبيل المثال ، mysql-writer-1.github.net . تم استخدام الاسم لتحديد عنوان IP الظاهري (VIP) للعقدة الرئيسية.
وبالتالي ، في الحالة العادية ، كان على العملاء ببساطة حل الاسم والاتصال بعنوان IP المستلم ، حيث كانت العقدة الرئيسية تنتظرهم بالفعل.
خذ بعين الاعتبار طبولوجيا النسخ المتماثل التالي الذي يمتد ثلاثة مراكز بيانات مختلفة:
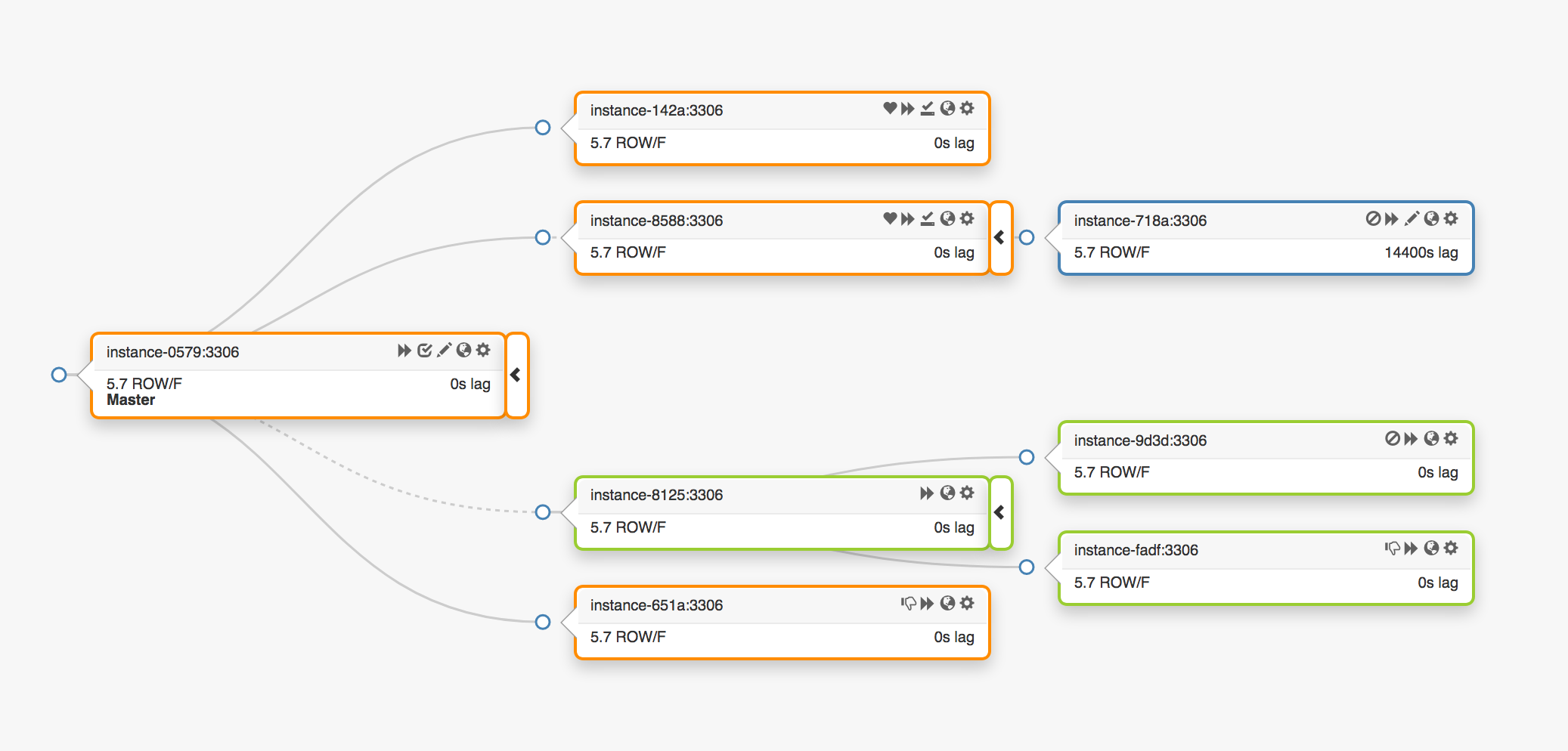
في حالة فشل العقدة الرئيسية ، يجب تعيين خادم جديد إلى مكانه (أحد النسخ المتماثلة).
orchestrator باكتشاف فشل ، ويحدد عقدة رئيسية جديدة ، ثم يعين الاسم / VIP. في الواقع ، لا يعرف العملاء هوية العقدة الرئيسية ، فهم يعرفون فقط الاسم الذي يجب أن يشير الآن إلى العقدة الجديدة. ومع ذلك ، انتبه لهذا.
تتم مشاركة عناوين VIP ، وتطلب خوادم قواعد البيانات نفسها وتملكها. لاستلام أو إطلاق VIP ، يجب أن يرسل الخادم طلب ARP. يجب على الخادم الذي يمتلك VIP إصداره أولاً قبل أن يتمكن الرئيسي الجديد من الوصول إلى هذا العنوان. هذا النهج يؤدي إلى بعض النتائج غير المرغوب فيها:
- في الوضع العادي ، سيقوم نظام تجاوز الفشل أولاً بالاتصال بالعقدة الرئيسية الفاشلة ويطلب منه تحرير VIP ، ثم ينتقل إلى الخادم الرئيسي الجديد مع طلب تعيين VIP. ولكن ماذا تفعل إذا كانت العقدة الرئيسية الأولى غير متوفرة أو ترفض طلبًا لإصدار عنوان VIP؟ نظرًا لأن الخادم في حالة فشل حاليًا ، فمن غير المحتمل أن يكون قادرًا على الاستجابة لطلب في الوقت المناسب أو الاستجابة له على الإطلاق.
- نتيجة لذلك ، قد ينشأ موقف عندما يطالب مضيفان بحقوقهما في نفس الشخصيات المهمة. يمكن للعملاء المختلفين الاتصال بأي من هذه الخوادم بناءً على أقصر مسار للشبكة.
- تعتمد العملية الصحيحة في هذا الموقف على تفاعل خادمين مستقلين ، ولا يمكن الاعتماد على مثل هذا التكوين.
- حتى إذا كانت العقدة الرئيسية الأولى تستجيب للطلبات ، فنحن نهدر وقتًا ثمينًا: لا يتم التبديل إلى الخادم الرئيسي الجديد أثناء الاتصال بالعنوان القديم.
- علاوة على ذلك ، حتى في حالة إعادة تعيين الشخصيات المهمة ، لا يوجد أي ضمان بأن اتصالات العميل الموجودة على الخادم القديم سيتم قطع اتصالها. مرة أخرى ، نواجه خطر الوقوع في موقف مع عقدتين رئيسيتين مستقلتين.
هنا وهناك ، ضمن بيئتنا ، ترتبط عناوين VIP بموقع مادي. يتم تعيينهم إلى التبديل أو جهاز التوجيه. لذلك ، لا يمكننا إعادة تعيين عنوان VIP إلا إلى خادم موجود في نفس البيئة مثل المضيف الأصلي. على وجه الخصوص ، في بعض الحالات ، لن نتمكن من تعيين خادم VIP في مركز بيانات آخر وسنحتاج إلى إجراء تغييرات على DNS.
- يستغرق توزيع التغييرات على DNS وقتًا أطول. يخزن العملاء أسماء DNS لفترة محددة مسبقًا من الوقت. يستلزم تجاوز الفشل لمراكز بيانات متعددة فترة توقف أطول ، حيث يستغرق مزيدًا من الوقت لتزويد جميع العملاء بمعلومات حول العقدة الرئيسية الجديدة.
كانت هذه القيود كافية لإجبارنا على البدء في البحث عن حل جديد ، ولكن كان علينا أيضًا أن نأخذ بعين الاعتبار ما يلي:
- نقلت العقد الرئيسية بشكل مستقل حزم النبض من خلال خدمة
pt-heartbeat لقياس التأخير وتنظيم الحمل . تم نقل الخدمة إلى العقدة الرئيسية المعينة حديثًا. إذا كان ذلك ممكنًا ، فيجب تعطيله على الخادم القديم. - وبالمثل ، فإن العقد الرئيسية تسيطر بشكل مستقل على تشغيل Pseudo-GTID . كان من الضروري بدء هذه العملية على العقدة الرئيسية الجديدة ويفضل التوقف على العقدة القديمة.
- أصبحت العقدة الرئيسية الجديدة قابلة للكتابة. يجب أن تحتوي العقدة القديمة (إن أمكن) على
read_only (للقراءة فقط).
أدت هذه الخطوات الإضافية إلى زيادة التعطل الكلي وإضافة نقاط الفشل والمشاكل الخاصة بهم.
لقد نجح الحل ، ونجح GitHub في معالجة إخفاقات MySQL في الخلفية ، لكننا أردنا تحسين نهجنا تجاه HA على النحو التالي:
- ضمان الاستقلال عن مراكز بيانات محددة ؛
- ضمان التشغيل في حالة فشل مركز البيانات ؛
- التخلي عن سير العمل التعاوني غير الموثوق بها
- تقليل إجمالي وقت التوقف ؛
- أداء ، قدر الإمكان ، الفشل دون خسارة.
حل GitHub HA: أوركسترا ، قنصل ، GLB
استراتيجيتنا الجديدة ، إلى جانب التحسينات المصاحبة لها ، تزيل معظم المشكلات المذكورة أعلاه ، أو تخفف من عواقبها. يتكون نظام HA الحالي من العناصر التالية:
- أوركسترا للكشف عن الأخطاء والفشل. نحن نستخدم مخطط أوركسترا / طوف مع العديد من مراكز البيانات ، كما هو مبين في الشكل أدناه ؛
- Hashicorp القنصل لاكتشاف الخدمة.
- GLB / HAProxy كطبقة وكيل بين العملاء وتسجيل العقد. شفرة المصدر لمدير GLB مفتوحة ؛
anycast التكنولوجيا لتوجيه الشبكة.
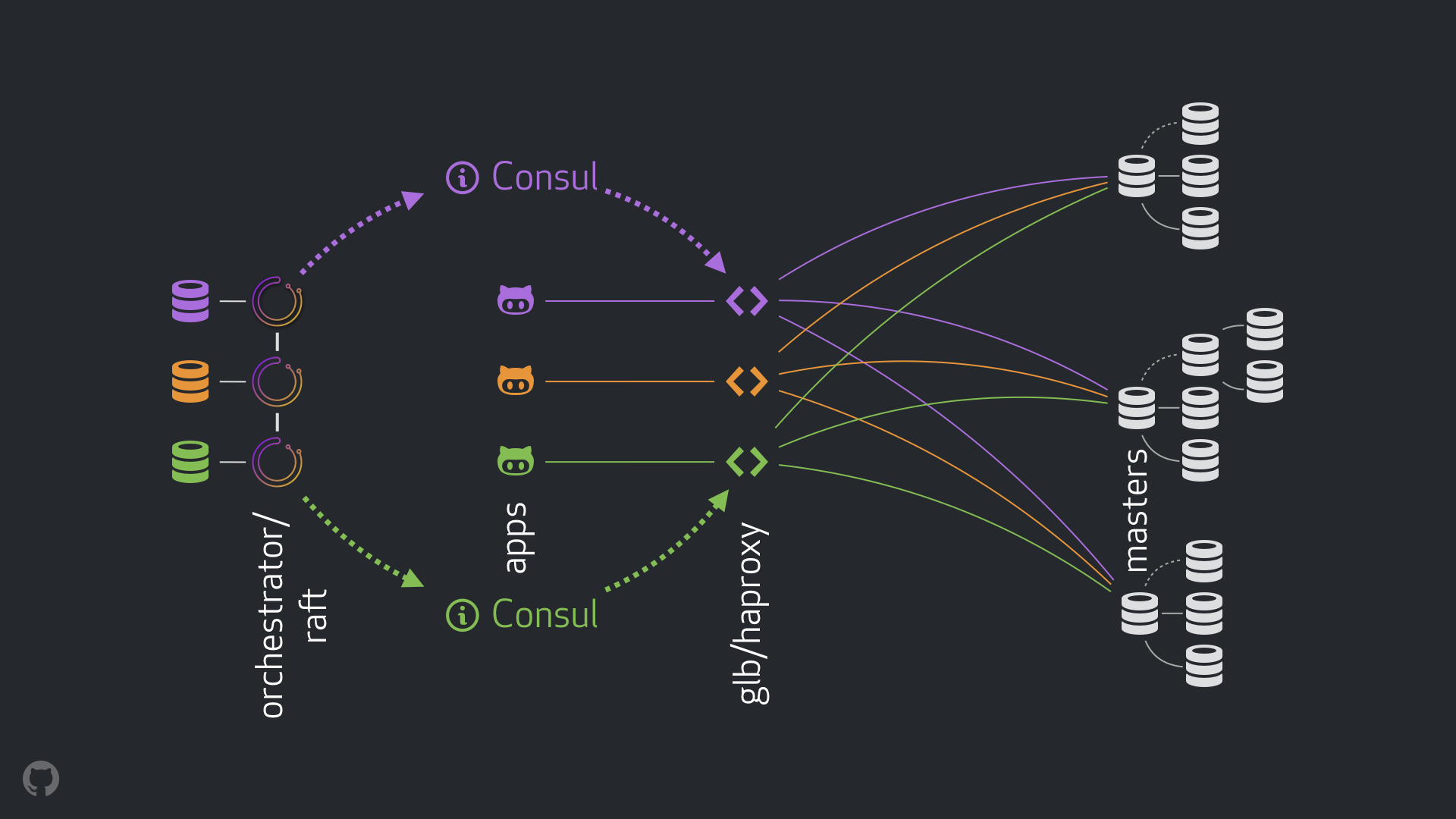
يسمح النظام الجديد بالتخلي عن إجراء تغييرات على VIP و DNS بالكامل. الآن عند تقديم مكونات جديدة ، يمكننا فصلها وتبسيط المهمة. بالإضافة إلى ذلك ، أتيحت لنا الفرصة لاستخدام حلول موثوقة ومستقرة. ويرد تحليل مفصل للحل الجديد أدناه.
التدفق الطبيعي
في الحالة العادية ، تتصل التطبيقات بعقد التسجيل عبر GLB / HAProxy.
لا تتلقى التطبيقات هوية الخادم الرئيسي. كما كان من قبل ، يستخدمون فقط الاسم. على سبيل المثال ، ستكون العقدة الرئيسية لـ cluster1 هي mysql-writer-1.github.net . ومع ذلك ، في التكوين الحالي لدينا ، يحل هذا الاسم إلى عنوان IP anycast .
بفضل تقنية anycast ، يتم حل الاسم على نفس عنوان IP في أي مكان ، ولكن يتم توجيه حركة المرور بشكل مختلف ، بالنظر إلى موقع العميل. على وجه الخصوص ، يتم نشر العديد من مثيلات GLB ، موازن التحميل المتاح للغاية لدينا ، في كل مركز من مراكز البيانات لدينا. mysql-writer-1.github.net توجيه حركة المرور على mysql-writer-1.github.net دائمًا إلى كتلة GLB في مركز البيانات المحلي. نتيجة لهذا ، يتم تقديم جميع العملاء من قبل الوكلاء المحليين.
نحن ندير GLB على رأس HAProxy . يوفر خادم HAProxy تجمعات للكتابة : واحد لكل مجموعة MySQL. بالإضافة إلى ذلك ، يحتوي كل تجمع على خادم واحد فقط (العقدة الرئيسية للكتلة). تحتوي كافة مثيلات GLB / HAProxy في جميع مراكز البيانات على نفس التجمعات ، وتشير جميعها إلى نفس الخوادم في هذه التجمعات. وبالتالي ، إذا كان التطبيق يريد كتابة البيانات إلى قاعدة البيانات على mysql-writer-1.github.net ، فلا يهم خادم GLB الذي يتصل به. في كلتا الحالتين ، سيتم تنفيذ إعادة توجيه إلى كتلة نظام المجموعة الرئيسية الفعلي.
للتطبيقات ، ينتهي الاكتشاف على GLB ، ولا يعد إعادة اكتشافه ضروريًا. يقوم GLB بإعادة توجيه حركة المرور إلى المكان الصحيح.
من أين تحصل GLB على معلومات حول الخوادم التي يجب سردها؟ كيف يمكننا إجراء تغييرات على GLB؟
اكتشاف من خلال القنصل
تُعرف خدمة القنصل على أنها حل اكتشاف الخدمة ، كما أنها تستخدم وظائف DNS. ومع ذلك ، في حالتنا ، نستخدمها كتخزين يمكن الوصول إليه للغاية من القيم الرئيسية (KV).
في مستودع KV في القنصل ، نسجل هوية العقد العنقودية الرئيسية. لكل مجموعة ، هناك مجموعة من سجلات KV تشير إلى بيانات العقدة الرئيسية المقابلة: fqdn والمنفذ و ipv4 و ipv6.
تطلق كل عقدة GLB / HAProxy قالبًا قنصليًا ، وهي خدمة تتعقب التغييرات في بيانات القنصل (في حالتنا ، تغييرات في بيانات العقد الرئيسية). تنشئ consul-template ملف تكوين ويمكنها إعادة تحميل HAProxy عند تغيير الإعدادات.
لهذا السبب ، تتوفر معلومات حول تغيير هوية العقدة الرئيسية في القنصل لكل مثيل GLB / HAProxy. بناءً على هذه المعلومات ، يتم إجراء تكوين المثيلات ، ويشار إلى العقد الرئيسية الجديدة باعتبارها الكيان الوحيد في تجمع خادم الكتلة. بعد ذلك ، يتم إعادة تحميل المثيلات لتصبح التغييرات نافذة المفعول.
لقد قمنا بنشر مثيلات القنصل في كل مركز بيانات ، وكل حالة توفر توفرًا عاليًا. ومع ذلك ، فإن هذه الحالات مستقلة عن بعضها البعض. أنها لا تتكرر ولا تبادل أي بيانات.
من أين يحصل القنصل على معلومات حول التغييرات وكيف يتم توزيعها بين مراكز البيانات؟
أوركسترا / طوف
نحن نستخدم مخطط orchestrator/raft : تتواصل عقد orchestrator مع بعضها البعض من خلال إجماع الطوافة . في كل مركز بيانات ، لدينا عقد أو اثنين من orchestrator .
orchestrator هو المسؤول عن الكشف عن الفشل ، وفشل الخلية ، ونقل بيانات العقدة الرئيسية التي تم تغييرها إلى القنصل. تتم إدارة تجاوز الفشل من قِبل مضيف orchestrator/raft واحد ، لكن التغييرات والأخبار التي تشير إلى أن الكتلة أصبحت الآن رئيسية جديدة ، يتم نشرها على جميع عقد orchestrator باستخدام آلية raft .
عندما تتلقى عُقد orchestrator أخبارًا عن تغيير في بيانات العقدة الرئيسية ، يتصل كل منهم بمثيله المحلي الخاص في القنصل ويبدأ تسجيل KV. ستتلقى مراكز البيانات ذات الحالات المتعددة orchestrator عدة سجلات (متطابقة) في القنصل.
عرض المعمم للتيار بأكمله
في حالة فشل العقدة الرئيسية:
- العقد
orchestrator الكشف عن الفشل ؛ orchestrator/raft ماجستير يبدأ الانتعاش. تم تعيين عقدة رئيسية جديدة ؛- يقوم مخطط
orchestrator/raft بنقل البيانات المتعلقة بتغيير العقدة الرئيسية إلى جميع عقد raft ؛ - يتلقى كل مثيل من
orchestrator/raft إخطارًا حول تغيير العقدة ويكتب هوية العقدة الرئيسية الجديدة إلى مخزن KV المحلي في القنصل ؛ - في كل مثيل GLB / HAProxy ، يتم إطلاق خدمة
consul-template ، والتي تراقب التغييرات في مستودع KV في القنصل ، وتعيد تكوين HAProxy وإعادة تشغيله ؛ - تتم إعادة توجيه حركة مرور العميل إلى العقدة الرئيسية الجديدة.
لكل عنصر ، يتم توزيع المسؤوليات بشكل واضح ، والهيكل بأكمله متنوع ومبسط. orchestrator لا يتفاعل مع موازن التحميل. لا يتطلب القنصل معلومات حول أصل المعلومات. خوادم بروكسي تعمل فقط مع القنصل. يعمل العملاء فقط مع خوادم بروكسي.
علاوة على ذلك:
- لا حاجة لإجراء تغييرات على DNS ونشر المعلومات عنها ؛
- لا يستخدم TTL.
- لا ينتظر مؤشر الترابط ردود من المضيف في حالة خطأ. بشكل عام ، يتم تجاهله.
لتحقيق الاستقرار في التدفق ، نطبق أيضًا الطرق التالية:
- يتم تعيين المعلمة
hard-stop-after HAProxy إلى قيمة صغيرة جدًا. عند إعادة تشغيل HAProxy باستخدام الخادم الجديد في تجمع الكتابة ، ينهي الخادم تلقائيًا جميع الاتصالات الحالية بالعقدة الرئيسية القديمة.
- يتيح لك تعيين المعلمة
hard-stop-after عدم انتظار أي إجراءات من العملاء ، بالإضافة إلى ذلك ، يتم تقليل الآثار السلبية لحدوث احتمال حدوث عقدتين رئيسيتين في الكتلة. من المهم أن نفهم أنه لا يوجد سحر هنا ، وعلى أي حال ، يمر بعض الوقت قبل قطع الروابط القديمة. ولكن هناك نقطة زمنية يمكننا بعدها التوقف عن انتظار المفاجآت غير السارة.
- نحن لا نطلب استمرار توافر خدمة القنصل. في الواقع ، نحن بحاجة إلى أن يكون متاحًا فقط أثناء الفشل. إذا لم تستجب خدمة القنصل ، فسيواصل GLB العمل بأحدث القيم المعروفة ولا يتخذ تدابير جذرية.
- تم تكوين GLB للتحقق من هوية العقدة الرئيسية المعينة حديثًا. كما هو الحال مع تجمعات MySQL الحساسة للسياق ، يتم إجراء فحص للتأكد من أن الخادم قابل للكتابة بالفعل. إذا حذفنا بطريق الخطأ هوية العقدة الرئيسية في القنصل ، فلن تكون هناك أية مشاكل ، سيتم تجاهل سجل فارغ. إذا كتبنا عن طريق الخطأ اسم خادم آخر (وليس الخادم الرئيسي) للقنصل ، فسيكون في هذه الحالة على ما يرام: لن تقوم GLB بتحديثه وستواصل العمل مع آخر حالة صالحة.
في الأقسام التالية ، نلقي نظرة على القضايا ونحلل أهداف التوافر العالي.
الكشف عن الأعطال مع أوركسترا / طوف
يتخذ orchestrator مقاربة شاملة لاكتشاف الأعطال ، مما يضمن موثوقية عالية للأداة. نحن لا نواجه نتائج إيجابية خاطئة ، لا يتم تنفيذ الإخفاقات المبكرة ، مما يعني أنه يتم استبعاد التوقف غير الضروري.
تتواءم دارات orchestrator/raft أيضًا مع حالات العزلة الكاملة لشبكة مركز البيانات (سياج مركز البيانات). يمكن أن يؤدي عزل الشبكة لمركز البيانات إلى حدوث تشويش: يمكن للخوادم الموجودة داخل مركز البيانات التواصل مع بعضها البعض. كيف نفهم من هو المعزول فعلاً - خوادم داخل مركز بيانات معين أو جميع مراكز البيانات الأخرى ؟
في مخطط orchestrator/raft ، سيد orchestrator/raft هو الفشل. تصبح العقدة هي القائدة ، التي تتلقى دعم الأغلبية في المجموعة (النصاب القانوني). لقد قمنا بنشر عقدة orchestrator بطريقة لا يستطيع أي مركز بيانات واحد توفير الأغلبية ، بينما يمكن لأي مركز بيانات n-1 توفيرها.
في حالة العزلة الكاملة لشبكة مركز البيانات ، يتم فصل عقد orchestrator في هذا المركز عن العقد المشابهة في مراكز البيانات الأخرى. نتيجة لذلك ، لا يمكن أن تصبح العقد orchestrator في مركز بيانات معزول رائدة في مجموعة raft . إذا كانت هذه العقدة هي الرئيسية ، فستفقد هذه الحالة. سيتم تعيين مضيف جديد أحد عقد مراكز البيانات الأخرى. سيحصل هذا القائد على الدعم من جميع مراكز البيانات الأخرى التي يمكنها التفاعل مع بعضها البعض.
وبهذه الطريقة ، سيكون مدير orchestrator دائمًا خارج مركز البيانات المعزول بالشبكة. إذا كانت العقدة الرئيسية في مركز البيانات المعزول ، فإن orchestrator يبدأ في تجاوز الفشل لاستبداله بخادم أحد مراكز البيانات المتاحة. نحن نخفف من تأثير عزل مركز البيانات عن طريق تفويض القرارات إلى النصاب القانوني لمراكز البيانات المتاحة.
أسرع الإخطار
يمكن تقليل وقت التوقف الكلي عن طريق تسريع الإخطار بالتغيير في العقدة الرئيسية. كيف تحقق هذا؟
عندما يبدأ orchestrator الفشل ، فإنه يعتبر مجموعة من الخوادم ، واحد منها يمكن تعيينه كخادم رئيسي. نظرًا لقواعد النسخ المتماثل والتوصيات والقيود ، فإنه قادر على اتخاذ قرار مستنير حول أفضل مسار للعمل.
وفقًا للعلامات التالية ، يمكنه أيضًا فهم أن الخادم الذي يمكن الوصول إليه هو المرشح المثالي للموعد الرئيسي:
- لا شيء يمنع الخادم من أن يصبح مرتفعًا (وربما يوصي المستخدم بهذا الخادم) ؛
- من المتوقع أن يتمكن الخادم من استخدام كافة الخوادم الأخرى كنسخ متماثلة.
في هذه الحالة ، يقوم orchestrator أولاً بتهيئة الخادم على أنه قابل للكتابة ويعلن على الفور عن زيادة في حالته (في حالتنا ، يقوم بكتابة السجل إلى مستودع KV في القنصل). orchestrator , .
, , GLB , , . : !
MySQL , . : , , , .
, . , , . , , , .
: 500 . . ( ), .
( ) . , .
, . , , . , , , .
, / pt-heartbeat / , . , pt-heartbeat , read_only , .
pt-heartbeat , . . . , pt-heartbeat .
orchestrator
orchestrator :
- Pseudo-GTID;
- , ;
- (
read_only ), .
, . , , , . orchestrator .
- , , . , -, .
, .
, , , - . . STONITH . , , , «» - . , , .
: Consul , . . , , , , .
orchestrator/GLB/Consul :
- ;
- ;
- ;
- ;
- , ( );
- ;
10-13 .
20 , — 25 .
الخاتمة
«// » , , . . , .